Defina o problema: custos, uso e quem precisa de respostas
Antes de construir telas ou pipelines, seja específico sobre as perguntas que seu app deve responder. “Custos na nuvem” pode significar um total da fatura, o gasto mensal de uma equipe, a economia unitária de um único serviço ou o custo de uma funcionalidade voltada ao cliente. Se você não definir o problema desde o início, acabará com dashboards que parecem impressionantes, mas não resolvem disputas.
Um enquadramento útil: seu primeiro entregável não é “um painel”, é uma definição compartilhada da verdade (o que os números significam, como são calculados e quem é responsável por agir sobre eles).
Quem usará o app?
Comece nomeando os usuários primários e o que eles precisam decidir:
- Finanças / FinOps: fechar o mês, explicar variações, definir políticas e aplicar responsabilidade orçamentária.
- Engenharia: identificar desperdício, comparar ambientes (prod vs dev) e vincular gasto a deploys ou serviços.
- Líderes de equipe / proprietários de produto: entender sua “conta”, justificar investimentos e planejar capacidade.
- Executivos (geralmente somente leitura): visibilidade de tendência e sinais de risco.
Usuários diferentes exigem níveis distintos de detalhe. Finanças pode querer números mensais estáveis e auditáveis; engenheiros podem querer granularidade diária e possibilidade de drill-down.
Defina resultados (não features)
Seja explícito sobre quais destes você entregará primeiro:
- Showback: visibilidade por equipe/serviço sem faturamento interno.
- Chargeback: faturas internas reais e alocações que atingem orçamentos.
- Previsão: gasto esperado no fim do mês e planejamento de cenários.
- Controle de orçamento: orçamentos, limites de alerta e fluxos de aprovação.
Uma forma prática de manter o escopo enxuto é escolher um “resultado primário” e tratar os outros como follow-ons. A maioria começa com showback mais detecção básica de anomalias, e depois parte para chargeback.
Liste as clouds e entidades de faturamento que você deve suportar no dia 1: contas pagadoras da AWS, assinaturas e grupos de gerenciamento do Azure, contas/projetos de faturamento do GCP, além de serviços compartilhados (logging, redes, segurança). Decida se incluirá cobranças de marketplace e SaaS de terceiros.
Frescor e retenção
Escolha uma cadência alvo de atualização: diária é suficiente para finanças e a maioria das equipes; quase em tempo real ajuda resposta a incidentes e orgs de alta velocidade, mas aumenta complexidade e custo. Também defina retenção (por exemplo, 13–24 meses) e se você precisa de snapshots imutáveis de “fechamento de mês” para auditoria.
Decida o que medir: modelo de dados e dimensões-chave
Antes de ingerir um único CSV ou chamar uma API de faturamento, decida como “a verdade” será representada no seu app. Um modelo de medição claro evita debates sem fim depois (“Por que isto não bate com a fatura?”) e torna relatórios multi-cloud previsíveis.
No mínimo, trate cada linha de faturamento como um registro com um conjunto consistente de medidas:
- Custo: custo pré-imposto, custo efetivo (após descontos) e custo faturado (total da fatura).
- Uso: quantidade + unidade (horas, GB-mês, requisições). Mantenha a unidade como dado, não como texto de UI.
- Créditos e descontos: compromissos, créditos promocionais, descontos empresariais.
- Reembolsos e ajustes: linhas negativas devem ser cidadãs de primeira classe.
- Impostos e taxas: frequentemente reportados separadamente; modele explicitamente para que finanças possa reconciliar.
Uma regra prática: se um valor pode mudar o que finanças paga ou o que uma equipe é cobrada, merece sua própria métrica.
Defina dimensões centrais (os campos de “group by”)
Dimensões tornam custos exploráveis e alocáveis. As comuns:
- Conta / assinatura / entidade de faturamento
- Projeto / aplicação
- Equipe / centro de custo / proprietário
- Ambiente (prod, staging, dev)
- Serviço / SKU / medidor
- Região / zona
Mantenha dimensões flexíveis: você vai adicionar mais depois (por exemplo, “cluster”, “namespace”, “fornecedor”).
Escolha chaves de tempo para relatórios
Geralmente você precisa de múltiplos conceitos de tempo:
- Período da fatura (para reconciliação financeira)
- Dia (para tendências e detecção de anomalias)
- Mês (para relatórios executivos e orçamentos)
“Alocado” vs “não alocado” deve ser inequívoco
Escreva uma definição estrita:
- Custo alocado: custo atribuído a um proprietário/equipe via tags ou regras de alocação.
- Custo não alocado: custo com propriedade ausente/inválida que deve permanecer visível (não descartado silenciosamente).
Essa definição única moldará seus dashboards, alertas e a confiança nos números.
Coletar dados de faturamento: exports, APIs e fluxo de ingestão
A ingestão de faturamento é a base de um app de gestão de custos na nuvem: se as entradas brutas estiverem incompletas ou difíceis de reproduzir, todo dashboard e regra de alocação vira discussão.
Planeje seus conectores (e aceite que eles diferem)
Comece suportando a “verdade nativa” de cada cloud:
- AWS: Cost and Usage Report (CUR) entregue no S3 (frequentemente por hora ou diário), além de APIs opcionais para metadata.
- Azure: exports do Cost Management para um Storage Account (tipicamente diário), com endpoints separados para escopos diferentes (assinatura, management group).
- GCP: export de billing para BigQuery (mais conveniente), ou arquivos de export se você preferir pipeline baseado em arquivos.
Projete cada conector para produzir os mesmos outputs centrais: um conjunto de arquivos/linhas brutas, mais um log de ingestão (o que você buscou, quando e quantos registros).
Ingestão pull vs push
Você geralmente escolherá um dos dois padrões:
- Pull (importação agendada): seu app faz polling em S3/Blob/BigQuery em uma agenda. Mais fácil de raciocinar e de fazer retry, mas pode ser mais lento para refletir mudanças.
- Push (event-driven): eventos de storage (por exemplo, “novo objeto criado”) disparam a ingestão. Mais rápido e mais barato em escala, mas precisa de deduplicação cuidadosa porque eventos podem chegar duas vezes.
Muitas equipes usam um híbrido: push para frescor, mais um pull diário “varredor” para arquivos perdidos.
Tempo, moeda e limites de faturamento
A ingestão deve preservar a moeda original, o fuso horário e a semântica do período de faturamento. Não “corrija” nada ainda — capture o que o provedor diz e armazene o início/fim do período do provedor para que ajustes tardios caiam no mês certo.
Mantenha uma área de staging imutável
Armazene os exports brutos em um bucket/container/dataset de staging imutável e versionado. Isso dá auditabilidade, suporta reprocessamento quando mudar a lógica de parsing e torna disputas solucionáveis: você pode apontar para o arquivo exato que gerou um número.
Normalizar e validar: tornar clouds diferentes comparáveis
Se você ingerir AWS CUR, exports do Azure e dados de billing do GCP tal quais, seu app vai parecer inconsistente: a mesma coisa é chamada de “service” em um arquivo, “meter” em outro, e “SKU” em outro. Normalização é onde você transforma esses termos específicos do provedor em um esquema previsível para que cada gráfico, filtro e regra de alocação se comporte igual.
Projete um esquema unificado
Comece mapeando campos dos provedores para um conjunto comum de dimensões que você pode confiar em qualquer lugar:
- Service (por exemplo, “Compute”, “Object Storage”)
- SKU (o item faturável, frequentemente o identificador mais granular)
- Usage type (horas, GB-mês, requisições, etc.)
Mantenha também os IDs nativos do provedor (como AWS ProductCode ou GCP SKU ID) para que você possa rastrear até o registro original quando um usuário disputar um número.
Limpe problemas comuns de dados
Normalização não é só renomear colunas — é higiene de dados.
Trate tags ausentes ou malformadas separando “desconhecido” de “não alocado” para não esconder problemas. Deduplicate linhas usando uma chave estável (ID da linha de origem + data + custo) para evitar dupla contagem por retries. Observe dias parciais (especialmente perto de “hoje” ou durante atrasos de export) e marque-os como provisórios para que dashboards não oscilem inesperadamente.
Acompanhe lineage e versões
Toda linha normalizada deve carregar metadata de lineage: arquivo/export de origem, hora da importação e uma versão de transformação (por exemplo, norm_v3). Quando regras de mapeamento mudarem, você pode reprocessar com confiança e explicar diferenças.
Valide e resuma para os usuários
Construa checagens automatizadas: totais por dia, regras de custo negativo, consistência de moeda e “custo por conta/assinatura/projeto.” Depois publique um resumo de importação na UI: linhas ingeridas, linhas rejeitadas, cobertura temporal e o delta vs. totais do provedor. A confiança cresce quando usuários podem ver o que aconteceu, não apenas o número final.
Dados de custo só são úteis quando alguém pode responder “quem é o dono disso?” de forma consistente. Tagging (AWS), labels (GCP) e resource tags (Azure) são a forma mais simples de conectar gasto a equipes, apps e ambientes — mas só se você tratá-las como dados de produto, não como hábito casual.
Defina regras: chaves obrigatórias e valores permitidos
Comece publicando um pequeno conjunto de chaves obrigatórias que seu motor de alocação e dashboards vão depender:
teamappcost-centerenv (prod/stage/dev)
Torne as regras explícitas: quais recursos devem ser etiquetados, quais formatos de tag são aceitos (por exemplo, lowercase kebab-case), e o que acontece quando uma tag está faltando (por exemplo, bucket “Unassigned” mais um alerta). Mantenha essa política visível dentro do app e linke para orientações mais profundas como /blog/tagging-best-practices.
Construa uma UI de mapeamento para a realidade bagunçada
Mesmo com políticas, você verá deriva: TeamA, team-a, team_a, ou uma equipe renomeada. Adicione uma camada leve de “mapeamento” para que finanças e donos de plataforma possam normalizar valores sem reescrever histórico:
- Mapeie muitos valores brutos para um valor canônico (por exemplo,
TeamA, team-a → team-a)
- Suporte mapeamentos com validade temporal (nome antigo válido até uma data de corte)
- Registre quem fez a mudança e por quê (notas de auditoria)
Essa UI de mapeamento também é onde você pode enriquecer tags: se app=checkout estiver presente mas cost-center faltar, você pode inferir a partir de um registro de aplicações.
Trate exceções sem quebrar responsabilidade
Alguns custos não tagueiam bem:
- Recursos compartilhados (clusters Kubernetes, VPCs compartilhadas, NAT gateways)
- Custos de plataforma (CI, observabilidade, tooling interno)
- Ferramentas de segurança (scanners centralizados, SIEM)
Modele esses como “serviços compartilhados” com regras de alocação claras (por exemplo, dividir por headcount, métricas de uso ou gasto proporcional). O objetivo não é atribuição perfeita — é propriedade consistente para que cada dólar tenha um lar e uma pessoa que possa explicá-lo.
Motor de alocação: regras, divisões e estratégias de custo compartilhado
Itere sem quebrar a confiança
Use instantâneos e reversão para alterar esquemas ou regras sem receio.
Um motor de alocação transforma linhas de faturamento normalizadas em “quem é dono deste custo, e por quê.” O objetivo não é só matemática — é produzir resultados que stakeholders possam entender, contestar e melhorar.
Métodos de alocação principais
A maioria das equipes precisa de uma mistura porque nem todos os custos chegam com propriedade limpa:
- Tags/labels diretas: se uma linha já tem uma tag de dono (team, product, cost center), atribua diretamente.
- Divisão por drivers de uso: aloque serviços compartilhados com base em consumo mensurável (horas de CPU, GB armazenados, requisições, ingest de logs, node-hours).
- Percentuais fixos: útil para acordos estáveis (por exemplo, time de plataforma cobre 30% de redes compartilhadas), mas deve ser revisado regularmente.
Regras que se comportam como política
Modele alocação como regras ordenadas com prioridade e datas de vigência. Isso permite responder: “Qual regra foi aplicada em 10 de março?” e atualizar políticas com segurança sem reescrever histórico.
Um esquema de regra prático frequentemente inclui:
- Condições de match (cloud, conta/assinatura, serviço, SKU, presença de tag, projeto, região)
- Alvo de alocação (team/product/environment)
- Método de alocação (direto, baseado em uso, percentual)
- Janela de validade (start/end) e prioridade
Custos compartilhados — clusters Kubernetes, rede, plataformas de dados — raramente mapeiam 1:1 para uma única equipe. Trate-os primeiro como “pools” e depois distribua.
Exemplos:
- Kubernetes: agrupe custos do cluster e depois divida por uso por namespace (requests de CPU/memória ou uso real).
- Rede: aloque NAT gateways e egress por bytes transferidos por VPC/projeto.
- Plataformas de dados: aloque warehouses/streams por tempo de query, créditos ou GB processados.
Torne os resultados explicáveis
Forneça vistas antes/depois: linhas originais do fornecedor vs resultados alocados por proprietário. Para cada linha alocada, armazene uma “explicação” (ID da regra, campos de match, valores do driver, percentuais de divisão). Essa trilha de auditoria reduz disputas e constrói confiança — especialmente durante chargeback e showback.
Exports de billing na nuvem crescem rápido: linhas por recurso, por hora, através de múltiplas contas e provedores. Se seu app ficar lento, os usuários vão parar de confiar — então design de armazenamento é design de produto.
Escolha um warehouse + views amigáveis a OLAP
Uma configuração comum é um warehouse relacional para a verdade e joins simples (Postgres para implantações menores; BigQuery ou Snowflake quando o volume cresce), além de views/materializações estilo OLAP para análise.
Armazene linhas brutas de faturamento exatamente como recebidas (mais alguns campos de ingestão como hora de importação e arquivo de origem). Depois construa tabelas curadas para seu app consultar. Isso mantém “o que recebemos” separado de “como reportamos”, o que torna auditorias e reprocessamentos mais seguros.
Se você está construindo do zero, considere acelerar a primeira iteração com uma plataforma que possa scaffolder a arquitetura rapidamente. Por exemplo, Koder.ai (uma plataforma vibe-coding) pode ajudar equipes a gerar um app web funcional via chat — comumente com frontend React, backend Go e PostgreSQL — para que você gaste mais tempo validando o modelo de dados e a lógica de alocação (as partes que determinam confiança) em vez de refazer boilerplate.
Particione para as perguntas que as pessoas fazem
A maioria das consultas filtra por tempo e por boundary (conta/assinatura/projeto). Particione e cluster/indice de acordo:
- Particione por data de uso (partições diárias funcionam bem para billing)
- Faça cluster/index por conta/provedor
- Mantenha campos de alta cardinalidade (IDs de recurso) fora dos caminhos primários dos dashboards
Isso mantém “últimos 30 dias para Equipe A” rápido mesmo quando o histórico total é enorme.
Pré-agregue para dashboards
Dashboards não devem escanear linhas brutas. Crie tabelas agregadas no grão que os usuários exploram:
- Custo diário por equipe, serviço e ambiente
- Uso diário por serviço/SKU onde importa
- Resumos mensais para rollups amigáveis ao financeiro
Materialize essas tabelas em uma agenda (ou incrementalmente) para que gráficos carreguem em segundos.
Planeje backfills e recomputação
Regras de alocação, mapeamentos de tags e definições de propriedade vão mudar. Projete para recomputar histórico:
- Versione seus outputs de alocação (ID do conjunto de regras + timestamp da execução)
- Suporte backfills direcionados (intervalos de data/contas específicas)
- Mantenha raw + curated imutáveis para reruns sem perder proveniência
Essa flexibilidade é o que transforma um dashboard de custos em um sistema confiável.
UX e dashboards: torne os custos fáceis de explorar e explicar
Configure fluxos de ingestão de faturação
Estruture fluxos de ingestão e importe logs para que os seus números se mantenham explicáveis.
Um app de alocação de custos vence quando as pessoas conseguem responder perguntas comuns em segundos: “Por que o gasto aumentou?”, “Quem é o dono deste custo?” e “O que podemos fazer sobre isso?” Sua UI deve contar uma história clara dos totais aos detalhes, sem forçar usuários a entender jargões de faturamento.
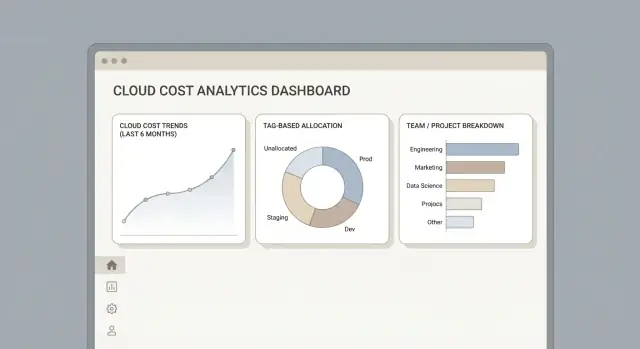
Páginas centrais que os usuários realmente precisam
Comece com um pequeno conjunto de vistas previsíveis:
- Overview: gasto total, tendência vs período anterior, principais drivers de custo e um painel rápido de “o que mudou”.
- Team view: custos por responsável (equipe/centro de custo), incluindo alocações compartilhadas e itens não alocados.
- Service breakdown: gasto por produto cloud (por exemplo, compute, storage), com habilidade de pivotar por região ou conta/assinatura.
- Anomalias: lista priorizada de picos incomuns com explicações em linguagem simples e links para as linhas subjacentes.
Filtros consistentes e um modelo mental estável
Use a mesma barra de filtros em todo lugar: intervalo de datas, cloud, equipe, projeto e ambiente (prod/stage/dev). Mantenha o comportamento dos filtros consistente (mesmos defaults, “aplica a todos os gráficos”), e torne filtros ativos visíveis para que screenshots e links compartilhados sejam autoexplicativos.
Drill-down sem becos sem saída
Projete um caminho intencional:
Total da fatura → total alocado → serviço/categoria → conta/projeto → SKU/linhas.
Em cada etapa, mostre o “porquê” ao lado do número: regras de alocação aplicadas, tags usadas e quaisquer suposições. Quando o usuário chegar a uma linha, forneça ações rápidas como “ver mapeamento de dono” (link para /settings/ownership) ou “reportar tags faltando” (link para /governance/tagging).
Exports e compartilhamento que respeitam permissões
Adicione exports CSV de cada tabela, mas também suporte links compartilháveis que preservem filtros. Trate links como relatórios: devem honrar controle baseado em papéis, incluir trilha de auditoria e, opcionalmente, expirar. Isso facilita colaboração mantendo dados sensíveis sob controle.
Orçamentos, alertas e anomalias: gerar ação, não apenas relatórios
Dashboards explicam o que aconteceu. Orçamentos e alertas mudam o que acontece a seguir.
Se seu app não consegue dizer a uma equipe “você está prestes a estourar o orçamento mensal” (e notificar a pessoa certa), ele permanece uma ferramenta de relatório — não operacional.
Orçamentos que as pessoas podem possuir
Comece com orçamentos no mesmo nível que você aloca custos: equipe, projeto, ambiente ou produto. Cada orçamento deve ter:
- Um dono claro (pessoa ou rotação on-call) e observadores opcionais
- Um período (mensal é o mais simples; adicione semanal para times rápidos)
- Limiares (por exemplo, 50/80/100% do orçamento) com urgência de notificação diferenciada
- Regras de escopo alinhadas com seu modelo de alocação (tags, contas/assinaturas, centros de custo)
Mantenha a UI simples: uma tela para definir valor + escopo + dono, e uma pré-visualização de “gasto do mês passado neste escopo” para sanity-check.
Alertas que são mais que “gasto alto”
Orçamentos pegam deriva lenta, mas equipes também precisam de sinais imediatos:
- Picos de gasto (hoje vs média recente)
- Tags faltando (novos recursos criados sem labels obrigatórias)
- Mudanças incomuns de uso (por exemplo, egress de dados dobrou, horas de CPU dispararam)
Torne alertas acionáveis: inclua principais drivers (serviço, região, projeto), uma breve explicação e um link para a visão exploratória (por exemplo, /costs?scope=team-a&window=7d).
Lógica simples de anomalia antes de ML
Antes de machine learning, implemente comparações baselines fáceis de depurar:
- Escolha uma janela baseline (por exemplo, últimos 14 dias excluindo o último 1 dia)
- Compare a janela atual (por exemplo, últimas 24h) contra a média/mediana baseline
- Dispare quando tanto mudança relativa (por exemplo, +60%) quanto delta absoluto (por exemplo, +$200) excederem limiares
Isso evita alertas ruidosos em categorias de gasto pequenas.
Feche o ciclo: registre resultados
Armazene cada evento de alerta com status: acknowledged, muted, false positive, fixed ou expected. Rastreie quem agiu e quanto tempo levou.
Com o tempo, use esse histórico para reduzir ruído: suprimir alertas repetidos, ajustar limiares por escopo e identificar “sempre não tagueado” para ações de processo em vez de mais notificações.
Segurança, controle de acesso e auditabilidade
Dados de custo são sensíveis: podem revelar preços de fornecedores, projetos internos e até compromissos com clientes. Trate seu app de custos como um sistema financeiro — porque para muitas equipes ele efetivamente é.
Papéis e permissões que refletem workflows reais
Comece com um pequeno conjunto de papéis e torne-os fáceis de entender:
- Admin: gerencia conectores de cloud, configurações globais e acesso.
- Finanças: pode editar regras de alocação e aprovar exports de chargeback/showback.
- Líder de equipe: pode ver custos da sua equipe, gerenciar tags/ownership no nível da equipe e propor mudanças de regra.
- Viewer: dashboards em leitura e drill-down.
Aplique isso na API (não só na UI) e adicione escopo por recurso (por exemplo, um líder de equipe não vê projetos de outras equipes).
Conectores seguros e rotação de segredos
Exports e APIs de uso exigem credenciais. Armazene segredos em um secret manager dedicado (ou criptografados em repouso com KMS), nunca em campos de banco de dados em texto plano. Suporte rotação segura permitindo múltiplas credenciais ativas por conector com uma “data de vigência”, para que ingestão não quebre durante a troca de chaves.
Detalhes práticos da UI ajudam: mostrar último sync bem-sucedido, avisos sobre escopo de permissões e um fluxo de “reautenticar” claro.
Logs de auditoria confiáveis
Adicione logs append-only para:
- mudanças de regra de alocação (antes/depois, quem, quando)
- imports/exports e relatórios baixados
- alterações de conectores e credenciais
Torne logs pesquisáveis e exportáveis (CSV/JSON) e vincule cada entrada ao objeto afetado.
Tratamento e retenção de dados no produto
Documente retenção e configurações de privacidade na UI: por quanto tempo arquivos brutos de billing são mantidos, quando tabelas agregadas substituem raw e quem pode excluir dados. Uma página simples “Data Handling” (por exemplo, /settings/data-handling) reduz tickets de suporte e aumenta confiança de finanças e segurança.
Integrações e APIs: conectar onde as pessoas já trabalham
Construa e seja recompensado
Partilhe o que constrói ou recomende colegas e obtenha créditos para o seu uso do Koder.ai.
Um app de alocação só muda comportamento quando aparece onde as pessoas já trabalham. Integrações reduzem “overhead de relatório” e transformam dados de custo em contexto operacional compartilhado — finanças, engenharia e liderança veem os mesmos números em suas ferramentas diárias.
Alertas em chat (Slack / Microsoft Teams)
Comece com notificações porque geram ação imediata. Envie mensagens concisas com o dono, o serviço, o delta e um link de volta para a visão exata no seu app (filtrada para time/projeto e janela).
Alertas típicos:
- Limite de orçamento atingido (80%, 100%)
- Pico de gasto incomum vs semana passada
- Tags faltando em recursos de alto custo
SSO e identidade (Okta, Azure AD, Google Workspace)
Se o acesso for difícil, as pessoas não adotam. Suporte SAML/OIDC SSO e mapeie grupos de identidade para “donos” de custo (teams, centers). Isso também simplifica offboarding e mantém permissões alinhadas com mudanças organizacionais.
Uma API de Cost interna (para portais e automação)
Forneça uma API estável para que sistemas internos possam buscar “custo por equipe/projeto” sem screen-scraping de dashboards.
Um formato prático:
GET /api/v1/costs?team=payments&start=2025-12-01&end=2025-12-31&granularity=day- Incluir: custo alocado, custo não alocado, unidades de uso e a versão/ID do conjunto de regras usado
Documente limites de taxa, cabeçalhos de cache e semântica idempotente para que consumidores construam pipelines confiáveis.
Webhooks para eventos
Webhooks tornam seu app reativo. Dispare eventos como budget.exceeded, import.failed, anomaly.detected e tags.missing para acionar workflows em outros sistemas.
Destinos comuns incluem criação de tickets em Jira/ServiceNow, ferramentas de incidente ou runbooks customizados.
Exports para BI (Looker, Power BI, Tableau)
Algumas equipes insistem em seus próprios dashboards. Ofereça um export governado (ou um esquema read-only do warehouse) para que relatórios BI usem a mesma lógica de alocação — não fórmulas reimplementadas.
Se você empacotar integrações como add-ons, linke usuários para /pricing para detalhes de plano.
Testes, monitoramento e rollout: manter confiança nos números
Um app de alocação só funciona se as pessoas acreditarem nele. Essa confiança é conquistada por meio de testes repetíveis, checagens visíveis de qualidade de dados e um rollout que permita às equipes comparar seus números conhecidos com os seus.
Comece construindo uma pequena biblioteca de exports e faturas do provedor que representam casos de borda comuns: créditos, reembolsos, impostos/VAT, taxas de revenda, free tiers, descontos por uso comprometido e cobranças de suporte. Mantenha versões dessas amostras para reexecutar testes sempre que mudar parsing ou lógica de alocação.
Foque testes em resultados, não só parsing:
- Um “mês conhecido” onde você pode predizer totais por serviço/conta.
- Mudanças de regra de alocação (por exemplo, divisão 60/40) que devem atualizar apenas saídas específicas.
- Comportamento de arredondamento em níveis diário vs mensal.
Adicione verificações automatizadas que reconciliem seus totais computados com os totais reportados pelo provedor dentro de uma tolerância (por exemplo, devido a arredondamento ou diferenças de timing). Acompanhe essas checagens ao longo do tempo e armazene resultados para responder “Quando essa divergência começou?”
Asserções úteis:
- Custo total por período de faturamento bate com a fatura/export
- Não há custos negativos, a menos que explicitamente esperados (reembolsos/créditos)
- Tratamento de moeda e taxas de câmbio é consistente
Monitoramento: ingestão, frescor e saúde de consultas
Configure alertas para falhas de ingestão, pipelines estagnados e limites de “dados não atualizados desde”. Monitore queries lentas e tempos de carregamento de dashboard, e registre quais relatórios geram scans pesados para otimizar as tabelas certas.
Plano de rollout: piloto, treinamento e canais de feedback
Faça um piloto com algumas equipes primeiro. Forneça a elas uma visão comparativa contra as planilhas existentes, concorde em definições e depois faça rollout amplo com treinamento curto e um canal de feedback claro. Publique um changelog (mesmo simples /blog/changelog) para que stakeholders vejam o que mudou e por quê.
Se você está iterando rápido nos requisitos do produto durante o piloto, ferramentas como Koder.ai podem ser úteis para prototipar fluxos de UI (filtros, caminhos de drill-down, editores de regras de alocação) e regenerar versões funcionais conforme definições evoluem — mantendo você no controle de exportação de código-fonte, deploy e rollback enquanto o app amadurece.