18 de jul. de 2025·7 min
Como construir um app móvel para monitoramento remoto de dispositivos
Aprenda a planejar, construir e lançar um app móvel para monitoramento remoto de dispositivos: arquitetura, fluxo de dados, atualizações em tempo real, alertas, segurança e testes.
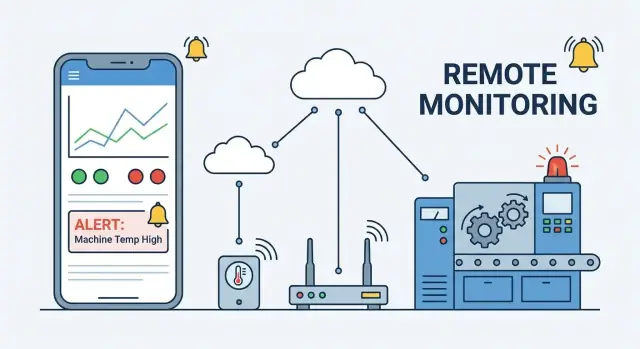
O que um app de monitoramento remoto faz
Monitoramento remoto de dispositivos significa que você pode ver o que um dispositivo está fazendo — e se ele está saudável — sem estar fisicamente ao lado dele. Um app móvel de monitoramento é a “janela” para uma frota de dispositivos: ele puxa sinais de cada dispositivo, transforma-os em um status compreensível e permite que as pessoas certas ajam rapidamente.
Dispositivos comuns que as pessoas monitoram
O monitoramento remoto aparece onde quer que equipamentos estejam distribuídos ou de difícil acesso. Exemplos típicos incluem:
- Sensores em prédios, câmaras frias, agricultura ou sistemas de água (temperatura, umidade, vibração)
- HVAC e sistemas prediais (estado de operação, códigos de erro, vida útil de filtro)
- Máquinas industriais em fábricas (contagens de ciclo, alarmes, indicadores de manutenção)
- Veículos e ativos móveis (localização, dados de bateria/motor, utilização)
- Totens e sinalização digital (online/offline, versão do app, saúde do hardware)
Em todos os casos, o trabalho do app é reduzir suposições e substituí-las por informação clara e atual.
O que os usuários esperam do app
Um bom app de monitoramento remoto normalmente entrega quatro básicos:
- Status de relance: online/offline, última vez visto, leituras principais e um sinal claro de “precisa de atenção”.
- Histórico e tendências: o que mudou ao longo do tempo — para responder “quando isso começou?” e “está piorando?”.
- Alertas: notificações proativas quando limites são excedidos ou um dispositivo deixa de reportar.
- Controles simples: ações seguras e limitadas como reboot, mudar modo, reconhecer um alarme ou rodar um diagnóstico — sem transformar o app móvel em um console de engenharia.
Os melhores apps também facilitam buscar e filtrar por site, modelo, severidade ou responsável — porque monitorar uma frota é menos sobre um dispositivo e mais sobre prioridades.
Como definir sucesso
Antes de construir funcionalidades, defina o que “melhor monitoramento” significa para sua equipe. Métricas comuns de sucesso incluem:
- Visibilidade de uptime: menos estados desconhecidos e detecção mais rápida de dispositivos offline
- Resposta mais rápida: redução do tempo médio para reconhecer e resolver incidentes
- Menos falhas: intervenção antecipada baseada em tendências de telemetria (por exemplo, temperatura subindo ou saúde da bateria diminuindo)
Quando essas métricas melhoram, o app de monitoramento não está apenas reportando dados — está ativamente prevenindo downtime e reduzindo custo operacional.
Defina usuários, casos de uso e o MVP
Antes de escolher protocolos ou desenhar gráficos, decida para quem o app é e o que “sucesso” parece no dia um. Apps de monitoramento remoto frequentemente falham quando tentam satisfazer todo mundo com o mesmo fluxo.
Papéis de usuário principais (e o que cada um precisa)
- Operador (NOC/dispatcher): triagem rápida, “o que está quebrado” claro, filtragem por site/status e habilidade de reconhecer problemas.
- Admin: gestão de usuários, permissões, regras de onboarding de dispositivos, limites de alerta e visibilidade de auditoria.
- Técnico de campo: tarefas acionáveis, detalhes amigáveis ao uso offline, último estado conhecido e checagens simples de “recuperou?” após um reparo.
- Viewer (stakeholder/cliente): dashboards somente leitura, escopo de dispositivo limitado e resumos de saúde em alto nível.
Transforme papéis em casos de uso
Escreva 5–10 cenários concretos que seu app deve suportar, por exemplo:
- “Operador recebe um alerta para Site A e precisa identificar dispositivos afetados em menos de 30 segundos.”
- “Técnico de campo escaneia um ID de dispositivo no local e checa telemetria recente e resultado do último comando.”
- “Admin adiciona uma nova localização e restringe viewers apenas a essa localização.”
Esses cenários ajudam a evitar a construção de funcionalidades que parecem úteis, mas não reduzem o tempo de resposta.
Telas chave para incluir no MVP
No mínimo, planeje:
- Lista de dispositivos: busca, filtros (status, localização, modelo) e badges de status claros.
- Detalhes do dispositivo: status atual, telemetria recente, última vez visto e histórico de comandos.
- Gráficos: tendências simples (bateria, temperatura, sinal) com intervalos de tempo sensatos.
- Alertas: ativos vs reconhecidos, severidade, notas e atribuição.
- Configurações: perfil, preferências de notificação e (para admins) usuários/papéis.
Checklist do MVP: imprescindível vs desejável
Imprescindível: autenticação + papéis, inventário de dispositivos, status em tempo real (mais ou menos), gráficos básicos, alertas + notificações push e um fluxo mínimo de incidentes (reconhecer/encerrar).
Desejável: vista em mapa, análises avançadas, regras de automação, onboarding por QR, chat in-app e dashboards customizados.
Plataformas: iOS, Android ou ambos?
Escolha com base em quem carrega o telefone no mundo real. Se técnicos de campo padronizam em um SO, comece por ele. Se precisar de ambos rapidamente, uma abordagem cross-platform pode funcionar — mas mantenha o escopo do MVP enxuto para que desempenho e comportamento de notificações permaneçam previsíveis.
Se você quer validar o MVP rápido, plataformas como Koder.ai podem ajudar a prototipar uma UI de monitoramento e fluxos de backend a partir de uma especificação orientada por chat (por exemplo: lista de dispositivos + detalhe do dispositivo + alertas + papéis), e então iterar rumo à produção assim que os workflows centrais estiverem validados.
Mapeie os dados: telemetria, comandos e histórico
Antes de escolher protocolos ou desenhar dashboards, seja específico sobre que dados existem, onde se originam e como devem viajar. Um “mapa de dados” claro previne duas falhas comuns: coletar tudo (e pagar por isso para sempre) ou coletar de menos (e ficar cego durante incidentes).
Identifique suas fontes de dados
Comece listando os sinais que cada dispositivo pode produzir e quão confiáveis eles são:
- Sensores: temperatura, vibração, nível de bateria, consumo de energia, estado de porta aberta.
- Logs: logs de firmware, códigos de erro, dumps de crash, eventos de conectividade.
- Checagens de saúde: pings de “estou vivo”, resultados de self-test, resets por watchdog.
- Localização: GPS, triangulação Wi‑Fi/celular, geofences, última posição conhecida.
Para cada item, anote unidades, faixas esperadas e o que significa “ruim”. Isso vira a base para regras de alerta e limites na UI.
Defina necessidades de frequência de atualização
Nem todo dado merece entrega em tempo real. Decida o que deve atualizar em segundos (ex.: alarmes de segurança, estado crítico de máquina), o que pode ser minutos (bateria, força de sinal) e o que pode ser hora/diário (resumos de uso). A frequência impacta bateria do dispositivo, custos de dados e a sensação de “ao vivo” do app.
Uma abordagem prática é definir camadas:
- Telemetria quente: frequente, payloads pequenos.
- Telemetria morna: status periódico.
- Telemetria fria: uploads em lote quando conveniente.
Decida retenção: raw vs resumos
Retenção é uma decisão de produto, não apenas uma configuração de armazenamento. Mantenha dados brutos tempo suficiente para investigar incidentes e validar correções, depois amostre em resumos (min/max/avg, percentis) para gráficos de tendência. Exemplo: raw por 7–30 dias, agregados horários por 12 meses.
Planeje comportamento offline e sincronização atrasada
Dispositivos e telefones ficarão offline. Defina o que fica bufferizado no dispositivo, o que pode ser descartado e como rotular dados atrasados no app (ex.: “última atualização há 18 min”). Garanta que timestamps venham do dispositivo (ou sejam corrigidos no servidor) para que o histórico permaneça preciso após reconexões.
Escolha uma arquitetura que caiba nos seus dispositivos
Um app de monitoramento remoto é tão confiável quanto o sistema por trás dele. Antes de telas e dashboards, escolha uma arquitetura que combine com as capacidades dos dispositivos, a realidade de rede e o quão “tempo real” você realmente precisa ser.
Blocos construtivos principais
A maioria das arquiteturas parece com esta cadeia:
Dispositivo → (opcional) Gateway → Backend na nuvem → App móvel
- Dispositivo: mede telemetria (temperatura, bateria, erros) e recebe comandos (reiniciar, mudar intervalo).
- Gateway: agrega dispositivos locais (BLE/Zigbee/Modbus), bufferiza dados e faz a ponte para a internet.
- Nuvem: autentica dispositivos/usuários, armazena histórico de séries temporais, dispara alertas e expõe APIs.
- App móvel: mostra status atual, histórico e incidentes; envia comandos do usuário.
Direto para nuvem vs baseado em gateway
Dispositivos direto-para-nuvem funcionam melhor quando têm conectividade IP confiável (Wi‑Fi/LTE) e energia/CPU suficiente.
- Prós: menos peças, operações mais simples, menor latência.
- Contras: cada dispositivo precisa lidar com conectividade segura, atualizações e redes intermitentes.
Arquitetura com gateway encaixa em dispositivos restritos ou ambientes industriais.
- Prós: gateways podem bufferizar durante quedas, traduzir protocolos e reduzir custos celulares ao agrupar.
- Contras: hardware extra para gerenciar; falha do gateway pode afetar muitos dispositivos.
REST/HTTP vs WebSockets vs MQTT (visão geral)
- REST/HTTP: ótimo para configuração, listas de dispositivos, “pegar último status” e comandos ocasionais. Simples e amplamente suportado.
- WebSockets: ideal para o app móvel receber atualizações ao vivo enquanto o app está aberto (streaming de mudanças de status).
- MQTT: comumente usado entre dispositivos/gateways e a nuvem para telemetria frequente em redes não confiáveis; leve e publish/subscribe.
Uma divisão comum é MQTT para dispositivo→nuvem e WebSockets + REST para nuvem→móvel.
Diagrama de fluxo de dados copiável
[Device Sensors]
|
| telemetry (MQTT/HTTP)
v
[Gateway - optional] ---- local protocols (BLE/Zigbee/Serial)
|
| secure uplink (MQTT/HTTP)
v
[Cloud Ingest] -\u003e [Rules/Alerts] -\u003e [Time-Series Storage]
|
| REST (queries/commands) + WebSocket (live updates)
v
[Mobile App Dashboard]
Escolha a arquitetura mais simples que ainda funcione nas suas piores condições de rede — então projete todo o resto (modelo de dados, alertas, UI) em torno dessa escolha.
Conectividade de dispositivo e gestão de ciclo de vida
Implemente o backend central
Gere um backend em Go com PostgreSQL para dispositivos, usuários, RBAC e regras de alerta.
Um app de monitoramento é tão confiável quanto a forma como identifica dispositivos, rastreia seu estado e gerencia a “vida” deles desde o onboarding até a aposentadoria. Boa gestão de ciclo de vida previne dispositivos misteriosos, registros duplicados e telas com status obsoletos.
Identidade do dispositivo e provisionamento
Comece com uma estratégia de identidade clara: todo dispositivo deve ter um ID único que nunca mude. Pode ser número de série de fábrica, identificador de hardware seguro ou UUID gerado e armazenado no dispositivo.
Durante o provisionamento, capture metadados mínimos mas úteis: modelo, proprietário/site, data de instalação e capacidades (ex.: tem GPS, suporta OTA). Mantenha fluxos de provisionamento simples — escaneie um QR code, reivindique o dispositivo e confirme que ele aparece na frota.
Modelo de estado do dispositivo (o que “status” realmente significa)
Defina um modelo de estado consistente para que o app móvel mostre status em tempo real sem adivinhações:
- Online/offline: baseado em heartbeat ou última mensagem.
- Última vez visto: timestamp e onde estava conectado por último (se relevante).
- Versão de firmware: para detectar dispositivos desatualizados.
- Bateria: último nível reportado e estado de carregamento (se aplicável).
Torne as regras explícitas (ex.: “offline se nenhum heartbeat por 5 minutos”) para que suporte e usuários interpretem o dashboard da mesma forma.
Noções básicas de comando e controle
Comandos devem ser tratados como tarefas rastreadas:
- Enviar comando (com ID de comando único)
- Confirmar recepção (dispositivo reconhece)
- Reportar resultado (sucesso/falha + detalhes)
Essa estrutura ajuda a mostrar progresso no app e evita confusões do tipo “funcionou ou não?”.
Lidando com redes não confiáveis
Dispositivos vão desconectar, roamear ou dormir. Projete para isso:
- Retries e timeouts: retry com backoff; mostrar “pendente” quando apropriado.
- Idempotência: requisições repetidas com mesmo ID não devem executar duas vezes.
- Falha graciosa: armazenar comandos para entrega posterior quando o dispositivo reconectar.
Quando você gerencia identidade, estado e comandos assim, o restante do app de monitoramento remoto fica muito mais fácil de operar e confiar.
Backend, armazenamento e APIs para dados de monitoramento
Mantenha a propriedade total do código
Exporte o código-fonte quando estiver pronto para migrar do protótipo para fluxos de produção.
Seu backend é a “sala de controle” para um app de monitoramento remoto: recebe telemetria, armazena eficientemente e serve APIs rápidas e previsíveis para o app móvel.
Serviços backend centrais
A maioria das equipes acaba com um conjunto pequeno de serviços (codebases separadas ou módulos bem separados):
- API de ingestão: aceita telemetria de dispositivos (via MQTT/HTTP), valida payloads, adiciona timestamps e enfileira trabalho.
- Registro de dispositivos: fonte da verdade para identidade do dispositivo, metadados (modelo, firmware, site) e estado de ciclo de vida (provisionado, ativo, aposentado).
- Gestão de usuários: organizações, papéis, permissões e logs de auditoria — para que as pessoas certas vejam as frotas certas.
Escolhendo armazenamento: séries temporais vs relacional
- Armazenamento de séries temporais (ou uma tabela/índice otimizado) é melhor para telemetria de alto volume: inserts rápidos, queries por intervalo de tempo e gráficos eficientes.
- Armazenamento relacional é ideal para “dados de negócio”: usuários, dispositivos, localidades, regras de alerta, tickets de manutenção e controle de acesso.
Muitos sistemas usam ambos: relacional para dados de controle, séries temporais para telemetria.
Agregação e downsampling
Dashboards móveis precisam de gráficos que carreguem rápido. Armazene raw, mas também pré-compute:
- Rollups (ex.: médias/min/max de 1 min, 15 min, 1 hora)
- Séries downsampleadas para intervalos longos
- Último status conhecido por dispositivo (um registro compacto que o app pode buscar instantaneamente)
APIs que seu app realmente chamará
Mantenha APIs simples e amigáveis ao cache:
GET /devices(lista + filtros como site, status)GET /devices/{id}/status(último estado conhecido, bateria, conectividade)GET /devices/{id}/telemetry?from=\u0026to=\u0026metric=(queries de histórico)GET /alertsePOST /alerts/rules(ver e gerenciar alertas)
Projete respostas em torno da UI móvel: priorize “qual é o status atual?” primeiro, e permita histórico mais profundo quando o usuário aprofundar.
Atualizações em tempo real sem drenar a bateria
“Tempo real” em um app de monitoramento remoto raramente significa “cada milissegundo”. Geralmente significa “fresco o suficiente para agir”, sem manter o rádio acordado ou bombardear seu backend.
Polling vs streaming: escolha a ferramenta mais leve que funcione
Polling (o app pergunta periodicamente ao servidor pelo último status) é simples e econômico em bateria quando atualizações são esparsas. É suficiente para dashboards vistos algumas vezes por dia ou quando dispositivos reportam a cada alguns minutos.
Streaming (o servidor empurra mudanças para o app) parece instantâneo, mas mantém uma conexão aberta e pode aumentar o consumo de energia — especialmente em redes instáveis.
Uma abordagem prática é híbrida: poll em background em baixa taxa e mudar para streaming somente quando o usuário estiver ativamente observando uma tela.
Quando WebSockets fazem sentido (e quando não fazem)
Use WebSockets (ou canais push similares) quando:
- Operadores precisam observar mudanças de estado em tempo real (ex.: alarmes, abertura/fechamento de portas).
- Você mostra métricas que se movem rapidamente durante uma investigação.
- É possível restringir ao “foreground only” e desconectar quando o app estiver ocioso.
Prefira polling quando:
- Usuários precisam principalmente do último status conhecido, não de cada mudança intermediária.
- Redes são instáveis (loops de reconexão desperdiçam energia).
- O app fica frequentemente em background.
Projete para escala: reduza o chatter antes que faça mal
Bateria e problemas de escala frequentemente compartilham a raiz: muitas requisições. Agrupe atualizações (busque vários dispositivos em uma chamada), pagine históricos longos e aplique rate limits para que uma única tela não possa pedir centenas de dispositivos por segundo. Se você tem telemetria de alta frequência, downsample para móvel (ex.: 1 ponto por 10–30 segundos) e deixe o backend agregar.
Deixe o frescor óbvio na UI
Mostre sempre:
- Última atualização por dispositivo (e por widget se necessário)
- Status de conexão (online/offline/unknown)
- Distinção clara entre dados ao vivo e dados em cache
Isso constrói confiança e evita que usuários ajam com base em status "em tempo real" obsoletos.
Alertas, notificações e fluxo de incidentes
Traga sua equipe
Convide colegas ou parceiros com um link de indicação e ganhe créditos quando eles começarem a construir.
Alertas são onde um app de monitoramento remoto ganha confiança — ou a perde. O objetivo não é “mais notificações”; é levar a pessoa certa a tomar a ação certa com contexto suficiente para resolver rápido.
Tipos de alerta que importam
Comece com um conjunto pequeno de categorias que mapeiam para problemas operacionais reais:
- Alertas por limite: uma métrica cruza um limite (temperatura, bateria, taxa de erro). Use níveis “aviso” e “crítico” separados quando muda o que se espera que alguém faça.
- Flags de anomalia: um serviço detecta comportamento incomum (picos de energia, sensores travados). São úteis, mas só se o app mostrar por que foi sinalizado.
- Offline / heartbeat perdido: o dispositivo não checou. Trate diferente de “dados ruins” e inclua última vez visto + histórico de conectividade recente.
Canais de notificação (e quando usá-los)
Use notificações in-app como registro completo (pesquisável, filtrável). Adicione push notifications para questões sensíveis ao tempo e considere email/SMS apenas para severidade alta ou escalonamento fora de horário. Push deve ser breve: nome do dispositivo, severidade e uma ação clara.
Controle de ruído de alerta
Ruído mata taxa de resposta. Incorpore:
- Cooldowns (não re-alertar a cada minuto)
- Deduplicação (agrupar falhas repetidas em um único incidente)
- Regras de escalonamento (se não reconhecido em X minutos, notificar o próximo on-call)
Fluxo de incidente e trilha de auditoria
Trate alertas como incidentes com estados: Triggered → Acknowledged → Investigating → Resolved. Cada passo deve ser registrado: quem reconheceu, quando, o que mudou, e notas opcionais. Essa trilha de auditoria ajuda em conformidade, postmortems e ajuste de limites para que sua seção /blog/monitoring-best-practices possa se basear em dados reais depois.
Perguntas frequentes
What does “success” look like for a remote device monitoring app?
Comece definindo o que significa “melhor monitoramento” para sua equipe:
- Menos estados desconhecidos (online/offline claros e última verificação)
- Resposta mais rápida (redução no tempo para reconhecer/resolver)
- Menos falhas (intervenção antecipada a partir de tendências)
Use esses itens como critérios de aceitação para o MVP, assim as funcionalidades ficam ligadas a resultados operacionais, não apenas a dashboards bonitos.
Which user roles should I design for first?
As funções típicas se mapeiam para workflows diferentes:
- Operador/NOC: triagem, filtragem, reconhecimento rápido de problemas
- Admin: usuários/perfis, regras de provisionamento, limites de alerta, auditorias
- Técnico de campo: último estado conhecido, detalhes amigáveis para uso offline, verificação de recuperação
- Viewer: somente leitura, escopo limitado, resumos de saúde em alto nível
Projete telas e permissões por função para não forçar todo mundo a usar o mesmo fluxo.
What should be in the MVP for a mobile monitoring app?
Inclua o fluxo principal para ver problemas, entendê-los e agir:
- Inventário de dispositivos com busca + filtros (site/status/modelo)
- Último status conhecido e “última vez visto” por dispositivo
- para algumas métricas chave (bateria/temperatura/sinal)
How do I decide what telemetry to collect and how often?
Faça um mapa de dados por modelo de dispositivo:
- Sinais disponíveis (telemetria, logs, checagens de saúde, localização)
- Unidades, faixas esperadas e o que parece “ruim”
- Frescor requerido (segundos vs minutos vs diário)
- O que precisa ser armazenado como raw vs agregado
Isso evita coletar demais (custo) ou coletar de menos (pontos cegos em incidentes).
How long should I retain device telemetry data?
Use uma abordagem em camadas:
- Dados brutos de curto prazo para investigações (por exemplo, 7–30 dias)
- Rollups/aggregados para longo prazo e gráficos (por exemplo, agregados horários por 12 meses)
- Um registro compacto de último status conhecido por dispositivo para carregamentos rápidos no móvel
Isso mantém o app responsivo e ainda permite análise pós-incidente.
Should I use direct-to-cloud devices or a gateway architecture?
Escolha com base em restrições do dispositivo e realidade de rede:
- Direct-to-cloud: melhor quando dispositivos têm conectividade IP confiável e energia/CPU suficientes; é mais simples e tem menor latência.
- Arquitetura com gateway: indicada para dispositivos restritos ou protocolos industriais; gateways podem armazenar durante quedas e traduzir protocolos, mas são um ponto adicional de falha.
Escolha a opção mais simples que funcione nas suas piores condições de conectividade.
Which protocols should I use: REST, WebSockets, or MQTT?
Uma divisão prática comum é:
- MQTT para dispositivo/gateway → nuvem (leve, resiliente)
- REST/HTTP para consultas/configuração do móvel e comandos ocasionais
- WebSockets para atualizações ao vivo enquanto o app estiver aberto
Evite streaming permanente se os usuários só precisarem do último status conhecido; híbrido (poll em background, stream em foreground) costuma ser o ideal.
How should command-and-control work in a monitoring app?
Trate comandos como tarefas rastreadas para que os usuários confiem nos resultados:
- Envie o comando com um ID de comando único
- Dispositivo confirma recepção
- Dispositivo informa o resultado (sucesso/falha + detalhes)
Adicione retries/timeouts e (mesmo ID não executa duas vezes) e mostre estados como vs vs na UI.
What’s the best way to handle offline devices and delayed sync?
Projete para conectividade não confiável em dispositivo e telefone:
- Defina o que o dispositivo bufferiza vs descarta
- Rotule dados atrasados claramente (ex.: “Atualizado pela última vez há 18 min”)
- Use timestamps do dispositivo (ou correção no servidor) para manter o histórico preciso
- Torne estados offline explícitos (online/offline/unknown) em vez de chutar
O objetivo é clareza: o usuário deve saber imediatamente quando os dados estão desatualizados.
How do I secure a remote device monitoring app and control access?
Use RBAC e separe “visualizar” de “controlar” capacidades:
- Viewer: dashboards e histórico somente leitura
- Operator/Admin: reconhecer incidentes, gerenciar alertas, enviar comandos
Proteja toda a cadeia com TLS, armazene tokens no keychain/keystore do SO e mantenha um audit trail para logins, mudanças de papel e tentativas de comando. Trate endpoints de controle de dispositivo como de maior risco que leituras de status.