Esclareça o objetivo e o escopo do app
Antes de desenhar telas ou escolher uma stack tecnológica, deixe explícito o que “risco operacional” significa na sua organização. Algumas equipes usam para cobrir falhas de processo e erro humano; outras incluem indisponibilidades de TI, problemas com fornecedores, fraude ou eventos externos. Se a definição for vaga, seu app virará um local de despejo — e os relatórios ficarão pouco confiáveis.
Defina o que vocês irão rastrear
Escreva uma afirmação clara do que conta como risco operacional e o que não conta. Você pode estruturar em quatro categorias (processo, pessoas, sistemas, eventos externos) e adicionar 3–5 exemplos para cada uma. Este passo reduz debates posteriores e mantém os dados consistentes.
Concorde sobre os resultados
Seja específico sobre o que o app deve alcançar. Resultados comuns incluem:
- Visibilidade: um único lugar para ver riscos, controles, incidentes e ações
- Propriedade: cada item tem um dono nomeado e uma data de vencimento
- Acompanhamento de remediação: ações evoluem de “aberto” para “verificado” com evidência
- Relatórios e prontidão para auditoria: você consegue explicar o que mudou, quando e por quê
Se você não consegue descrever o resultado, provavelmente é um pedido de funcionalidade — não um requisito.
Identifique os usuários principais
Liste os papéis que usarão o app e o que eles mais precisam:
- Donos de risco (identificam e atualizam riscos)
- Donos de controle (atestam controles, anexam evidência)
- Revisores (aprovar alterações, solicitar atualizações)
- Auditores (acesso somente leitura, rastreabilidade)
- Admins (acesso de usuários, configuração)
Isso evita construir para “todos” e não atender ninguém.
Defina um escopo v1 realista
Um v1 prático para rastreamento de risco operacional geralmente foca em: um registro de riscos, pontuação básica, acompanhamento de ações e relatórios simples. Deixe capacidades mais profundas (integrações avançadas, gestão complexa de taxonomia, construtores de workflow personalizados) para fases posteriores.
Defina métricas de sucesso
Escolha sinais mensuráveis como: porcentagem de riscos com dono, completude do registro de riscos, tempo para fechar ações, taxa de ações em atraso e conclusão de revisões no prazo. Essas métricas facilitam julgar se o app está funcionando — e o que melhorar em seguida.
Um app de registro de riscos só funciona se corresponder a como as pessoas realmente identificam, avaliam e acompanham o risco operacional. Antes de falar de funcionalidades, converse com quem usará (ou será avaliado pelos) os resultados.
Quem envolver (e por quê)
Comece com um grupo pequeno e representativo:
- Donos das unidades de negócio que levantam e gerenciam riscos no dia a dia
- Risco/Conformidade que definem terminologia, expectativas de pontuação e necessidades de relatório
- Auditoria interna que se preocupa com evidências, aprovações e completude da trilha de auditoria
- TI/Segurança que revisarão controle de acesso, retenção de dados e integrações
- Executivos/contatos do conselho que consomem resumos e relatórios de tendência
Mapeie o processo atual de ponta a ponta
Em workshops, mapeie o fluxo real passo a passo: identificação do risco → avaliação → tratamento → monitoramento → revisão. Registre onde decisões ocorrem (quem aprova o quê), o que significa “concluído” e o que aciona uma revisão (baseado em tempo, incidente ou limite).
Capture pontos de dor que você deve resolver
Peça que stakeholders mostrem a planilha ou o rastro de e-mails atual. Documente problemas concretos como:
- Falta de propriedade (dono de risco vs. dono de controle vs. dono da ação não claros)
- Pontuação inconsistente (equipes interpretam probabilidade/impacto de formas diferentes)
- Trilhas de auditoria fracas (sem registro de quem mudou o quê e por quê)
- Confusão de versões (múltiplas cópias do “último” registro)
Documente os workflows e eventos necessários
Anote os workflows mínimos que o app deve suportar:
- Criar um novo risco (com campos obrigatórios e regras de aprovação)
- Atualizar um risco (re-pontuar, mudar status, adicionar notas)
- Registrar incidentes e vinculá-los a riscos/controles
- Registrar resultados de testes de controle e evidência
- Criar e acompanhar planos de ação (datas de vencimento, lembretes, escalonamento)
Defina os relatórios dos quais as pessoas dependem
Concorde sobre as saídas cedo para evitar retrabalho. Necessidades comuns incluem resumos para o conselho, visões por unidade de negócio, ações em atraso e principais riscos por pontuação ou tendência.
Liste regras que moldam requisitos — por exemplo, períodos de retenção de dados, restrições de privacidade para dados de incidentes, segregação de funções, evidência de aprovação e restrições de acesso por região ou entidade. Mantenha factual: você está reunindo restrições, não afirmando conformidade automaticamente.
Desenhe seu framework de risco e terminologia
Antes de construir telas ou workflows, alinhe o vocabulário que o app de rastreamento aplicará. Terminologia clara evita problemas de “mesmo risco, palavras diferentes” e torna os relatórios confiáveis.
Defina como riscos serão agrupados e filtrados no registro. Mantenha útil para gestão diária e para dashboards/relatórios.
Níveis típicos de taxonomia incluem categoria → subcategoria, mapeados para unidades de negócio e (quando útil) processos, produtos ou localizações. Evite uma taxonomia tão detalhada que os usuários não consigam escolher consistentemente; refine conforme padrões emergirem.
Padronize a declaração de risco e campos obrigatórios
Concorde com um formato consistente de declaração (ex.: “Devido a causa, evento pode ocorrer, levando a impacto”). Então decida o que é obrigatório:
- Causa, evento, impacto (para análise significativa)
- Dono do risco e equipe responsável (para direcionar ações)
- Status (rascunho, ativo, em revisão, aposentado)
- Datas (identificado, última avaliação, próxima revisão)
Essa estrutura vincula controles e incidentes a uma narrativa única em vez de notas dispersas.
Defina dimensões de avaliação e pontuação
Escolha as dimensões de avaliação que suportarão seu modelo de pontuação. Probabilidade e impacto são o mínimo; velocidade e detectabilidade podem agregar valor se as pessoas realmente as avaliarem de forma consistente.
Decida como lidar com risco inerente vs. residual. Uma abordagem comum: risco inerente é pontuado antes dos controles; risco residual é o score pós-controles, com controles vinculados explicitamente para que a lógica seja explicável em revisões e auditorias.
Por fim, concorde com uma escala simples (frequentemente 1–5) e escreva definições em linguagem simples para cada nível. Se “3 = médio” significar coisas diferentes para equipes, sua avaliação gerará ruído em vez de insight.
Crie o modelo de dados (Registro de Riscos, Controles, Ações)
Um modelo de dados claro transforma um registro estilo planilha em um sistema confiável. Mire em um conjunto pequeno de registros principais, relacionamentos limpos e listas de referência consistentes para que os relatórios permaneçam confiáveis conforme o uso cresce.
Entidades principais (seu esquema mínimo viável)
Comece com algumas tabelas que mapeiam diretamente para como as pessoas trabalham:
- Usuários e Papéis: quem está no sistema e o que pode fazer
- Riscos: entrada do registro (título, descrição, dono, área de negócio, pontuações inerente/residual, status)
- Avaliações: avaliações pontuais (data, avaliador, inputs de pontuação, notas). Manter avaliações separadas evita sobrescrever a “visão atual”.
- Controles: salvaguardas vinculadas a riscos (projeto/efetividade operacional, cadência de teste, dono do controle)
- Incidentes/Eventos: o que aconteceu (data, impacto, causa raiz, risco(s) vinculado(s), falhas de controle vinculadas)
- Ações: tarefas de remediação vinculadas a risco, controle ou incidente
- Comentários: discussão e decisões, idealmente com @menções e timestamps
Relacionamentos importantes para rastreabilidade
Modele links muitos-para-muitos explicitamente:
- Risco ↔ Controles (via tabela de junção) para mostrar quais controles mitigam quais riscos
- Risco ↔ Incidentes para conectar perdas/near-misses ao registro
- Ações → Risco/Controle/Incidente (link polimórfico ou três chaves estrangeiras nulas) para que a remediação esteja sempre ancorada
Essa estrutura responde a perguntas como “Quais controles reduzem nossos principais riscos?” e “Quais incidentes provocaram mudança de pontuação?”.
Tabelas de histórico e “por que isso mudou?”
Rastreamento de risco operacional frequentemente precisa de histórico defensável. Adicione tabelas de histórico/auditoria para Riscos, Controles, Avaliações, Incidentes e Ações com:
- quem mudou, quando e quais campos mudaram
- motivo da mudança opcional (texto livre ou códigos selecionáveis)
Evite armazenar apenas “última atualização” se aprovações e auditorias forem esperadas.
Tabelas de referência para consistência
Use tabelas de referência (não strings hard-coded) para taxonomia, status, escalas de severidade/probabilidade, tipos de controle e estados de ação. Isso evita que relatórios quebrem por erros de digitação (“High” vs. “HIGH”).
Trate evidência como dado de primeira classe: uma tabela Anexos com metadados do arquivo (nome, tipo, tamanho, uploader, registro vinculado, data de upload), mais campos para data de retenção/exclusão e classificação de acesso. Armazene arquivos em object storage, mas mantenha regras de governança no banco de dados.
Planeje workflows, aprovações e propriedade
Um app de risco falha rapidamente quando “quem faz o quê” não está claro. Antes de construir telas, defina estados de workflow, quem pode mover itens entre estados e o que deve ser registrado em cada etapa.
Papéis e permissões (mantenha simples)
Comece com um conjunto pequeno de papéis e expanda somente quando necessário:
- Criador: pode rascunhar novos riscos, controles, incidentes e ações
- Dono do risco: responsável pela precisão e revisão contínua
- Aprovador: valida entradas e pode marcá-las como “oficiais”
- Auditor / somente leitura: pode visualizar, exportar e (opcionalmente) comentar, mas não editar
- Admin: gerencia configuração, usuários e permissões
Deixe permissões explícitas por tipo de objeto (risco, controle, ação) e por capacidade (criar, editar, aprovar, fechar, reabrir).
Fluxo de aprovação: rascunho → revisão → aprovado → reavaliação
Use um ciclo de vida claro com portões previsíveis:
- Rascunho: editável; campos incompletos permitidos
- Em revisão: mudanças restritas; exigir comentários do revisor
- Aprovado: campos principais bloqueados; mudanças exigem solicitação formal de atualização
- Revisão periódica: checkpoints agendados (ex.: trimestral) para confirmar que nada mudou
SLAs, lembretes e lógica de atraso
Associe SLAs a ciclos de revisão, testes de controle e datas de ação. Envie lembretes antes dos vencimentos, escale após SLAs perdidos e destaque itens atrasados (para donos e gestores).
Delegação, reatribuição e responsabilização
Cada item deve ter um dono responsável mais colaboradores opcionais. Suporte delegação e reatribuição, mas exija um motivo (e opcionalmente uma data efetiva) para que leitores entendam por que a propriedade mudou e quando a responsabilidade foi transferida.
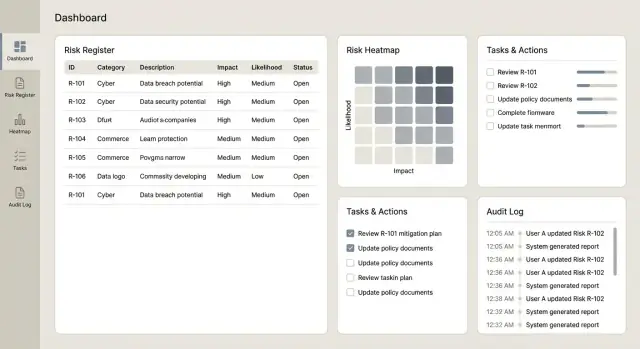
Desenhe a experiência do usuário e telas-chave
Torne as alterações rastreáveis
Crie visualizações de histórico de alterações append-only e relatórios fáceis de exportar que apoiem revisões e auditorias.
Um app de risco tem sucesso quando as pessoas o usam. Para usuários não técnicos, a melhor UX é previsível, de baixo atrito e consistente: rótulos claros, jargão mínimo e orientação suficiente para evitar entradas vagas “diversas”.
Seu formulário de entrada deve parecer uma conversa guiada. Acrescente texto de ajuda curto sob campos (não instruções longas) e marque como obrigatórios apenas campos realmente essenciais.
Inclua essenciais como: título, categoria, processo/área, dono, status atual, pontuação inicial e “por que isso importa” (narrativa de impacto). Se usar pontuação, incorpore tooltips ao lado de cada fator para que usuários entendam as definições sem sair da página.
2) Lista de riscos: triagem e acompanhamento em um só lugar
A maioria dos usuários viverá na vista de lista, então facilite responder: “O que precisa de atenção?”
Forneça filtros e ordenações por status, dono, categoria, pontuação, data da última revisão e ações em atraso. Destaque exceções (revisões atrasadas, ações vencidas) com badges discretos — não use cores alarmantes em todo lugar — para que a atenção vá aos itens certos.
3) Página de detalhe do risco: uma história, registros conectados
A tela de detalhe deve ler como um resumo primeiro e, depois, detalhes de apoio. Mantenha a área superior focada: descrição, pontuação atual, última revisão, próxima revisão e dono.
Abaixo, mostre controles vinculados, incidentes e ações como seções separadas. Adicione comentários para contexto (“por que mudamos a pontuação”) e anexos como evidência.
Ações precisam de atribuição, datas de vencimento, progresso, uploads de evidência e critérios claros de encerramento. Torne o fechamento explícito: quem aprova o encerramento e qual prova é necessária.
Se precisar de um layout de referência, mantenha a navegação simples e consistente nas telas (ex.: /risks, /risks/new, /risks/{id}, /actions).
Implemente pontuação de risco e lógica de revisão
A pontuação é onde o app de rastreamento se torna acionável. O objetivo não é “dar nota” às equipes, mas padronizar como comparar riscos, decidir prioridades e evitar que itens fiquem obsoletos.
Escolha (e documente) um modelo de pontuação
Comece com um modelo simples e explicável que funcione entre equipes. Um padrão comum é escala 1–5 para Probabilidade e Impacto, com uma pontuação calculada:
- Score = Probabilidade × Impacto
Escreva definições claras para cada valor (o que significa “3”, não apenas o número). Coloque essa documentação ao lado dos campos na UI (tooltips ou um painel “Como a pontuação funciona”) para que usuários não precisem procurar.
Torne limites significativos e vincule-os a ações
Números sozinhos não geram comportamento — limites geram. Defina fronteiras para Baixo / Médio / Alto (e opcionalmente Crítico) e decida o que cada nível aciona.
Exemplos:
- Alto: exige dono, data-alvo e aprovação da gestão antes do fechamento
- Médio: exige plano de mitigação, mas pode não precisar de aprovação
- Baixo: acompanhar e revisar; sem ação imediata
Mantenha limites configuráveis, pois o que é “Alto” varia por unidade de negócio.
Acompanhe risco inerente vs. residual
Discussões sobre risco frequentemente empatam quando as pessoas falam de coisas diferentes. Resolva isso separando:
- Risco inerente: antes dos controles
- Risco residual: após considerar controles existentes
Na UI, mostre ambas as pontuações lado a lado e demonstre como controles afetam o residual (por exemplo, um controle pode reduzir Probabilidade em 1 ou Impacto em 1). Evite esconder lógica atrás de ajustes automatizados que os usuários não consigam explicar.
Construa regras configuráveis de revisão
Adicione lógica de revisão baseada em tempo para que riscos não se tornem obsoletos. Uma linha de base prática é:
- Riscos altos: revisar trimestralmente
- Riscos médios: revisar semestralmente
- Riscos baixos: revisar anualmente
Torne a frequência de revisão configurável por unidade de negócio e permita overrides por risco. Então automatize lembretes e o status “revisão atrasada” com base na última data de revisão.
Evite pontuação caixa-preta
Torne o cálculo visível: mostre Probabilidade, Impacto, quaisquer ajustes de controle e a pontuação residual final. Usuários devem responder “Por que isso é Alto?” num relance.
Construa trilha de auditoria, versionamento e gestão de evidências
Transforme requisitos em um plano de desenvolvimento
Use o Modo de Planejamento para mapear funções, aprovações, regras de pontuação e relatórios antes de gerar o código.
Um instrumento de rastreamento é tão credível quanto seu histórico. Se uma pontuação muda, um controle é marcado como “testado” ou um incidente é reclassificado, você precisa de um registro que responda: quem fez o quê, quando e por quê.
Decida o que auditar (e seja explícito)
Comece com uma lista clara de eventos para não perder ações importantes nem encher o log de ruído. Eventos comuns incluem:
- Criação/atualização/exclusão em objetos principais (riscos, controles, incidentes, ações)
- Decisões de aprovação (submetido, aprovado, rejeitado) e reatribuição de propriedade
- Exports (CSV/PDF), especialmente para times regulados
- Eventos de autenticação (tentativas de login, reset de senha) e mudanças de permissão
Capture o “quem/quando/o quê” mais contexto
No mínimo, armazene ator, timestamp, tipo/ID do objeto e campos que mudaram (valor antigo → novo). Adicione uma nota opcional de “motivo da mudança” — isso evita idas e vindas confusas depois (“mudou a pontuação residual após revisão trimestral”).
Mantenha o log de auditoria append-only. Evite permitir edições, mesmo por admins; se uma correção for necessária, crie um novo evento que referencia o anterior.
Forneça uma vista read-only do log de auditoria
Auditores e administradores normalmente precisam de uma vista dedicada e filtrável: por intervalo de datas, objeto, usuário e tipo de evento. Facilite exportar desta tela enquanto também registra o próprio evento de exportação. Se tiver uma área admin, linke-a a partir de /admin/audit-log.
Versione evidências e evite sobrescritas silenciosas
Arquivos de evidência (screenshots, resultados de teste, políticas) devem ser versionados. Trate cada upload como uma nova versão com timestamp e uploader, e preserve arquivos anteriores. Se substituições forem permitidas, exija uma nota de motivo e mantenha ambas as versões.
Defina retenção e acesso para evidências sensíveis
Defina regras de retenção (ex.: manter eventos de auditoria por X anos; purgar evidências após Y, salvo em retenção legal). Trave evidências com permissões mais restritas que o registro de risco quando contiverem dados pessoais ou detalhes de segurança.
Aborde segurança, privacidade e controle de acesso
Segurança e privacidade não são “extras” — elas moldam o quanto as pessoas se sentem confortáveis em registrar incidentes, anexar evidência e atribuir responsabilidade. Comece mapeando quem precisa de acesso, o que deve ver e o que precisa ser restrito.
Autenticação: SSO vs. e-mail/senha
Se sua organização já usa um provedor de identidade (Okta, Azure AD, Google Workspace), priorize Single Sign-On via SAML ou OIDC. Reduz risco de senhas, simplifica onboarding/offboarding e alinha-se às políticas corporativas.
Se você constrói para times menores ou usuários externos, e-mail/senha pode funcionar — mas combine com regras fortes de senha, recuperação segura de conta e (onde suportado) MFA.
RBAC que reflita como o trabalho acontece
Defina papéis que reflitam responsabilidades reais: admin, dono de risco, revisor/aprovador, colaborador, somente leitura, auditor.
Risco operacional frequentemente exige limites mais rígidos que uma ferramenta interna típica. Considere RBAC que restrinja acesso:
- Por unidade de negócio/departamento (ex.: Finanças não vê incidentes de RH)
- Por nível de registro (ex.: só uma equipe de investigação específica acessa um incidente sensível)
Mantenha permissões inteligíveis — as pessoas devem entender por que podem ou não ver um registro.
Princípios básicos de proteção de dados
Use criptografia em trânsito (HTTPS/TLS) sempre e siga o princípio do menor privilégio para serviços da aplicação e bancos de dados. Sessões devem usar cookies seguros, timeouts curtos por inatividade e invalidação do lado servidor no logout.
Sensibilidade por campo e redação
Nem todo campo tem o mesmo risco. Narrativas de incidentes, notas de impacto ao cliente ou detalhes de funcionários podem precisar de controles mais rígidos. Dê suporte a visibilidade por campo (ou pelo menos redação) para que usuários colaborem sem expor conteúdo sensível amplamente.
Salvaguardas administrativas
Adicione algumas medidas práticas:
- Logs de atividade admin (quem mudou permissões, exports, configurações)
- Allowlists de IP opcionais para ambientes de alto risco
- MFA para admins (mesmo que outros não usem)
Feito corretamente, esses controles protegem dados preservando fluxos de relatório e remediação.
Entregue dashboards, relatórios e exports
Dashboards e relatórios são onde o app prova valor: transformam um registro longo em decisões claras para donos, gestores e comitês. A chave é tornar os números rastreáveis até regras de pontuação e registros subjacentes.
Dashboards que as pessoas realmente usarão
Comece com um pequeno conjunto de visões de alto sinal que respondam perguntas comuns rapidamente:
- Principais riscos por pontuação residual (com opção de alternar para inerente)
- Tendências ao longo do tempo (ex.: tendência de risco residual por mês/trimestre)
- Distribuição residual vs. inerente, incluindo uma visão simples “antes vs. depois dos controles”
- Um heatmap de risco (probabilidade × impacto) que vincula cada célula aos riscos subjacentes
Faça cada bloco clicável para o usuário detalhar a lista exata de riscos, controles, incidentes e ações por trás do gráfico.
Visões operacionais para gestão do dia a dia
Dashboards de decisão são diferentes de visões operacionais. Adicione telas focadas no que precisa de atenção nesta semana:
- Ações em atraso (por dono/time, com dias em atraso)
- Próximas revisões (riscos ou controles com revisão prevista)
- Testes de controle falhos (falhas recentes, severidade e remediação em aberto)
- Frequência de incidentes (contagens e taxas ao longo do tempo, com filtros por processo/categoria)
Essas visões combinam bem com lembretes e propriedade de tarefas para que o app seja visto como ferramenta de fluxo, não apenas um banco de dados.
Exports que funcionam para comitês e auditorias
Planeje exports cedo, pois comitês frequentemente dependem de pacotes offline. Suporte CSV para análise e PDF para distribuição somente leitura, com:
- Filtros (unidade de negócio, categoria, dono, status)
- Intervalos de data (incidentes no período, ações criadas/fechadas no período)
- Rótulos claros (inerente vs. residual, datas de versão e filtros aplicados)
Se já existe um template de governance pack, espelhe-o para facilitar adoção.
Consistência e desempenho em escala
Assegure que cada definição de relatório corresponda às regras de pontuação. Por exemplo, se o dashboard ranqueia “principais riscos” por pontuação residual, isso deve alinhar com o mesmo cálculo usado no registro e nos exports.
Para grandes registros, desenhe pensando em performance: paginação em listas, cache para agregados comuns e geração assíncrona de relatórios (gerar em background e notificar quando pronto). Se mais tarde adicionar relatórios agendados, mantenha links internos (ex.: salvar uma configuração de relatório que pode ser reaberta em /reports).
Planeje integrações e migração de dados
Alinhe as partes interessadas em um só lugar
Reúna proprietários de risco, revisores e auditores em um só espaço de trabalho para testar permissões e fluxos.
Integrações e migração determinam se seu app vira o sistema de registro — ou só mais um lugar que as pessoas esquecem de atualizar. Planeje cedo, mas implemente incrementalmente para manter o produto central estável.
A maioria das equipes não quer “outra lista de tarefas”. Quer que o app se conecte a onde o trabalho acontece:
- Jira ou ServiceNow para criar e acompanhar ações de remediação (e sincronizar status de volta)
- Slack ou Microsoft Teams para alertas quando um risco é escalado, revisão está próxima ou evidência é solicitada
- E-mail para lembretes de revisões e aprovações (útil para usuários ocasionais)
Uma abordagem prática é manter o app de risco como dono dos dados de risco, enquanto ferramentas externas gerenciam detalhes de execução (tickets, responsáveis, datas) e alimentam progresso de volta.
Muitas organizações começam no Excel. Ofereça uma importação que aceite formatos comuns, mas acrescente proteções:
- Regras de validação (campos obrigatórios, formatos de data, intervalos numéricos)
- Detecção de duplicatas (ex.: mesmo título + processo + dono) com opção “mesclar/ignorar”
- Aplicação de taxonomia (unidade de negócio, processo, categoria) para evitar relatórios confusos depois
Mostre uma prévia do que será criado, o que será rejeitado e por quê. Essa tela pode economizar horas de retrabalho.
Fundamentos de API que reduzem dores futuras
Mesmo que comece com uma integração, desenhe a API como se tivesse várias:
- Mantenha endpoints consistentes e nomes (ex.: /risks, /controls, /actions)
- Garanta audit logging nas escritas (quem mudou o quê, quando e de onde)
- Adicione rate limiting e códigos de erro claros para integrações falharem com graça
Integrações falham por motivos normais: mudanças de permissão, timeouts de rede, tickets deletados. Planeje isso:
- Enfileire requisições de saída e repita com backoff
- Registre um status de integração em cada item vinculado (“Synced”, “Pending”, “Failed”)
- Forneça mensagens acionáveis (“Token do ServiceNow expirou — reconectar”) e um botão manual “Retry now”
Isso mantém a confiança alta e evita divergência silenciosa entre o registro e ferramentas de execução.
Um app de rastreamento vira valioso quando as pessoas confiam e usam consistentemente. Trate testes e rollout como parte do produto, não um checklist final.
Construa uma estratégia prática de testes
Comece com testes automatizados para partes que devem se comportar igual sempre — especialmente pontuação e permissões:
- Testes unitários para pontuação: verifique cálculos de probabilidade/impacto, limites, arredondamento e casos de borda (ex.: “N/A”, campos faltando, overrides)
- Testes de workflow para aprovações: garanta que mudanças de estado sigam regras (rascunho → submetido → aprovado), incluindo reatribuição e rejeição
- Testes de permissão: confirme que visualizadores não editam, donos não aprovam suas próprias submissões (se essa for a política) e admins auditam sem quebrar segregação de função
UAT funciona melhor quando replica trabalho real. Peça a cada unidade de negócio um pequeno conjunto de riscos, controles, incidentes e ações, e então execute cenários típicos:
- criar um risco, vincular controles e submeter para aprovação
- atualizar após um incidente e anexar evidência
- concluir uma ação e verificar mudanças em relatórios
Capture não só bugs, mas rótulos confusos, status ausentes e campos que não batem com a linguagem das equipes.
Pilote antes do rollout em toda a empresa
Faça o lançamento para um time primeiro (ou uma região) por 2–4 semanas. Mantenha o escopo controlado: um workflow único, poucas campos e uma métrica clara de sucesso (ex.: % de riscos revisados no prazo). Use o feedback para ajustar:
- nomes de campos e campos obrigatórios
- etapas de aprovação e regras de propriedade
- tempo de lembretes e escalonamento
Treinamento, documentação e adoção
Forneça guias curtos e um glossário de uma página: o que cada pontuação significa, quando usar cada status e como anexar evidência. Uma sessão ao vivo de 30 minutos mais clipes gravados costuma funcionar melhor que um manual extenso.
Se quiser chegar a um v1 crível rapidamente, uma plataforma de vibe-coding como Koder.ai pode ajudar a prototipar e iterar workflows sem ciclo de setup longo. Você descreve telas e regras (intake de risco, aprovações, pontuação, lembretes, views de auditoria) em chat e refina o app gerado conforme stakeholders reagem à UI real.
Koder.ai cobre entrega end-to-end: geração de web apps (comum: React), serviços backend (Go + PostgreSQL) e recursos práticos como export de código-fonte, deploy/hosting, domínios customizados e snapshots com rollback — útil quando você muda taxonomias, escalas de pontuação ou fluxos de aprovação e precisa iterar com segurança. Equipes podem começar no plano gratuito e evoluir para pro, business ou enterprise conforme governança e escala exigirem.
Mantenha o app saudável após o lançamento
Planeje operações contínuas cedo: backups automatizados, monitoramento básico de uptime/erros e um processo leve de mudança para taxonomia e escalas de pontuação, assim atualizações permanecem consistentes e auditáveis ao longo do tempo.