20 de mar. de 2025·8 min
Como construir um aplicativo web de suporte ao cliente para tickets e SLAs
Planeje, desenhe e construa um aplicativo web de suporte ao cliente com fluxos de tickets, rastreamento de SLA e uma base de conhecimento pesquisável — além de papéis, análises e integrações.
Defina objetivos, usuários e escopo
Um produto de ticketing fica confuso quando é construído em torno de recursos em vez de resultados. Antes de projetar campos, filas ou automatizações, alinhe quem será o público do app, qual dor ele remove e como «bom» será medido.
Identifique seus usuários (e suas tarefas diárias)
Comece listando os papéis e o que cada um precisa realizar em uma semana típica:
- Agentes: triagem, resposta, resolução e documentação de soluções rapidamente.
- Líderes de equipe: rebalancear carga, identificar tickets travados, aplicar SLAs, treinar agentes.
- Administradores: configurar canais, categorias, automações, permissões e modelos.
- Clientes (opcional): enviar solicitações, acompanhar status, adicionar detalhes e buscar respostas em um portal.
Se você pular essa etapa, acabará otimizando para administradores enquanto os agentes lutam na fila.
Escreva os problemas que você está resolvendo
Mantenha isso concreto e ligado a comportamentos observáveis:
- SLAs perdidos: tickets envelhecem sem sinalização; escalonamentos acontecem tarde demais.
- Filas bagunçadas: propriedade incerta, trabalho duplicado e a confusão “onde isso deve ir?”.
- Perguntas repetidas: as mesmas respostas são digitadas repetidas vezes, atrasando a resolução.
Decida onde o app será usado
Seja explícito: isto é uma ferramenta interna apenas, ou você também vai entregar um portal voltado para clientes? Portais alteram requisitos (autenticação, permissões, conteúdo, identidade visual, notificações).
Escolha métricas de sucesso cedo
Escolha um pequeno conjunto que você irá acompanhar desde o primeiro dia:
- Tempo até a primeira resposta
- Tempo de resolução
- Taxa de deflexão (problemas resolvidos via base de conhecimento em vez de tickets)
Crie uma declaração simples de escopo para o v1
Escreva 5–10 frases descrevendo o que entra no v1 (fluxos obrigatórios) e o que fica para depois (extras como roteamento avançado, sugestões de IA ou relatórios aprofundados). Isso vira seu limite quando pedidos começarem a se acumular.
Projete o modelo de ticket e o ciclo de vida
Seu modelo de ticket é a “fonte da verdade” para todo o resto: filas, SLAs, relatórios e o que os agentes veem na tela. Acertar isso cedo evita migrações dolorosas depois.
Mapeie um ciclo de vida que dê para explicar em uma frase
Comece com um conjunto claro de estados e defina o que cada um significa operacionalmente:
- Novo: criado, ainda não triado
- Atribuído: pertencente a um agente ou equipe
- Em andamento: está sendo trabalhado ativamente
- Aguardando: bloqueado (resposta do cliente, terceiro, engenharia)
- Resolvido: o agente considera resolvido (frequentemente dispara notificação)
- Fechado: estado final (bloqueado ou com edição limitada)
Adicione regras para transições de estado. Por exemplo, somente tickets Atribuídos/Em andamento podem ser marcados como Resolvidos, e um ticket Fechado não pode reabrir sem criar um follow-up.
Decida como os tickets entram no sistema
Liste todos os caminhos de entrada que você suportará agora (e o que adicionará depois): formulário web, e-mail inbound, chat e API. Cada canal deve criar o mesmo objeto de ticket, com alguns campos específicos por canal (como cabeçalhos de e-mail ou IDs de transcrição de chat). Consistência mantém automação e relatório simples.
Escolha campos obrigatórios (e mantenha-os mínimos)
No mínimo, exija:
- Assunto e descrição
- Solicitante (identidade do cliente)
- Prioridade (quão urgente)
- Categoria (que tipo de problema)
Todo o resto pode ser opcional ou derivado. Um formulário inchado reduz a qualidade de preenchimento e desacelera os agentes.
Planeje tags e campos personalizados para equipes reais
Use tags para filtragem leve (por exemplo, “billing”, “bug”, “vip”) e campos personalizados quando precisar de relatórios ou roteamento estruturado (por exemplo, “Área do produto”, “ID do pedido”, “Região”). Garanta que campos possam ser escopados por equipe para que um departamento não polua o outro.
Defina colaboração dentro de um ticket
Agentes precisam de um local seguro para coordenar:
- Notas internas (não visíveis ao cliente)
- @menções e listas de seguidores/CC
- Tickets vinculados (duplicados, incidente pai/filho)
Sua UI do agente deve deixar esses elementos a um clique da linha do tempo principal.
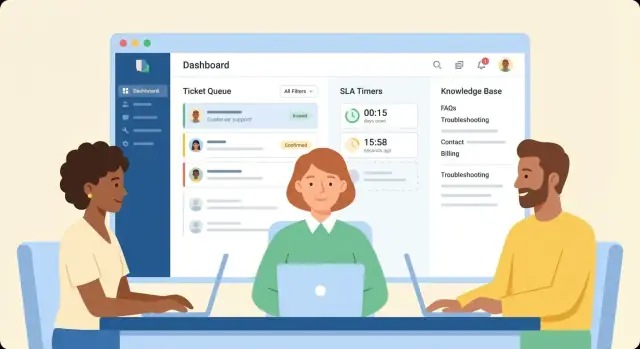
Construa filas de tickets e fluxos de atribuição
Filas e atribuições são o ponto em que um sistema de tickets deixa de ser uma caixa de entrada compartilhada e passa a se comportar como uma ferramenta operacional. Seu objetivo é simples: todo ticket deve ter uma “próxima melhor ação” óbvia, e todo agente deve saber o que trabalhar agora.
Desenhe uma fila de agente que responda “qual o próximo?”
Crie uma visão de fila que dê prioridade ao trabalho mais sensível ao tempo. Opções de ordenação comuns que agentes realmente usarão são:
- Prioridade (ex.: P1–P4)
- Tempo até o SLA (do mais próximo)
- Última atualização (para capturar conversas paradas)
Adicione filtros rápidos (equipe, canal, produto, nível de cliente) e uma busca rápida. Mantenha a lista densa: assunto, solicitante, prioridade, status, contagem regressiva do SLA e agente atribuído geralmente bastam.
Regras de atribuição: automático quando possível, manual quando necessário
Suporte alguns caminhos de atribuição para que equipes possam evoluir sem trocar de ferramenta:
- Atribuição manual para casos limite e momentos de treinamento
- Round-robin para distribuir carga de forma equilibrada
- Roteamento por habilidade (idioma, área do produto, cobrança vs. técnico)
- Roteamento por equipe (ex.: “Pagamentos”, “Enterprise”, “Devoluções”)
Torne as decisões das regras visíveis (“Atribuído por: Habilidades → Francês + Cobrança”) para que agentes confiem no sistema.
Status e modelos que mantêm o trabalho em movimento
Status como Aguardando cliente e Aguardando terceiro evitam que tickets pareçam “inativos” quando a ação está bloqueada, além de deixarem os relatórios mais honestos.
Para acelerar respostas, inclua respostas prontas e modelos de resposta com variáveis seguras (nome, número do pedido, data do SLA). Os modelos devem ser pesquisáveis e editáveis por líderes autorizados.
Previna colisões (dois agentes, um ticket)
Adicione tratamento de colisão: quando um agente abre um ticket, coloque um bloqueio de visualização/edição de curta duração ou uma faixa “atualmente sendo tratado por”. Se outra pessoa tentar responder, avise e exija confirmação para enviar (ou bloqueie o envio) para evitar respostas duplicadas ou contraditórias.
Implemente regras de SLA, timers e escalonamentos
SLAs só ajudam se todos concordarem sobre o que está sendo medido e se o app fizer a aplicação consistente. Comece transformando “respondemos rápido” em políticas que seu sistema consegue calcular.
Defina políticas de SLA (o que você vai medir)
A maioria das equipes começa com dois timers por ticket:
- Tempo até primeira resposta: tempo da criação do ticket até a primeira resposta de um agente (ou primeiro contato público não automatizado).
- Tempo de resolução: tempo da criação do ticket até “Resolvido/Fechado”.
Mantenha as políticas configuráveis por prioridade, canal ou nível de cliente (por exemplo: VIP tem 1 hora para primeira resposta, Padrão tem 8 horas úteis).
Decida quando os relógios de SLA começam e param
Escreva as regras antes de começar a codar, porque casos de borda aparecem rápido:
- Horas úteis vs. 24/7: defina um calendário (fuso horário, dias da semana, feriados).
- Estados de pausa: pare o relógio quando o ticket estiver em “Aguardando cliente” ou “Pendente fornecedor externo”.
- Condições de retomada: reinicie quando o cliente responder ou o estado voltar para “Aberto/Em andamento”.
Armazene eventos de SLA (iniciado, pausado, retomado, violado) para que depois você consiga explicar por que algo violou o SLA.
Torne o status de SLA óbvio na UI
Agentes não devem abrir um ticket para descobrir que ele está prestes a violar. Adicione:
- Um timer regressivo (tempo restante)
- Bandeiras de atraso com severidade clara (aviso vs. violado)
- Alertas opcionais (in-app, e-mail ou chat) quando um limite estiver próximo
Construa caminhos de escalonamento
Escalonamento deve ser automático e previsível:
- Notificar um líder de equipe aos 80% do tempo permitido
- Reatribuir para uma fila de plantão se violar
- Aumentar prioridade ou adicionar uma tag “Escalonado”
Planeje reportes de SLA
No mínimo, acompanhe contagem de violações, taxa de violação e tendência ao longo do tempo. Também registre razões da violação (pausa longa demais, prioridade errada, fila com pouca equipe) para que relatórios levem a ações, não a culpabilizações.
Crie uma Base de Conhecimento que reduza tickets repetidos
Uma boa base de conhecimento (KB) não é apenas uma pasta de FAQs — é um recurso de produto que deve reduzir perguntas repetidas e acelerar resoluções. Projete-a como parte do fluxo de tickets, não como um “site de documentação” separado.
Estrutura: facilite a manutenção do conteúdo
Comece com um modelo de informação simples que escale:
- Categorias → seções → artigos (navegação fácil para clientes e agentes)
- Tags para tópicos transversais (cobrança, login, integrações) sem duplicar artigos
- Propriedade clara (quem revisa o quê) para manter o conteúdo atualizado
Mantenha templates de artigo consistentes: declaração do problema, solução passo a passo, capturas de tela opcionais e “Se isso não ajudou…” com orientação para o formulário ou canal correto.
Busca que realmente encontra respostas
A maioria dos fracassos de KB é falha de busca. Implemente busca com:
- Ajuste de relevância (impulsionar título/cabeçalho, impulsionar conteúdo recente)
- Sinônimos (ex.: “invoice” ↔ “bill”, “2FA” ↔ “código de autenticação”) — traduza conforme necessário
- Tolerância a erros de digitação e stemming (plural/singular)
Também indexe assuntos de tickets (anonimizados) para aprender a linguagem real dos clientes e alimentar sua lista de sinônimos.
Rascunhos, revisões e aprovações de publicação
Adicione um fluxo leve: rascunho → revisão → publicado, com publicação agendada opcional. Armazene histórico de versões e inclua metadados de “última atualização”. Combine isso com papéis (autor, revisor, publicador) para que nem todo agente possa editar conteúdo público.
Meça o que reduz tickets
Acompanhe mais que visualizações de página. Métricas úteis incluem:
- Votos de utilidade (sim/não) e “o que faltou?” como feedback
- Sinais de deflexão: busca → artigo visto → nenhum ticket criado nas X horas seguintes
- Principais buscas sem bons resultados (lacunas de conteúdo)
Vincule artigos aos tickets onde o trabalho acontece
Dentro do compositor de resposta do agente, mostre artigos sugeridos com base no assunto do ticket, tags e intenção detectada. Um clique deve inserir um link público (ex.: /help/account/reset-password) ou um trecho interno para respostas mais rápidas.
Feita corretamente, a KB vira sua primeira linha de suporte: clientes resolvem por conta própria e agentes tratam menos tickets repetidos com mais consistência.
Configure papéis, permissões e auditabilidade
Conecte seus canais de entrada
Crie endpoints de API e webhooks para eventos de ticket e conecte e-mail, chat e CRM.
Permissões são onde uma ferramenta de tickets ou permanece segura e previsível — ou vira um caos rápido. Não espere até depois do lançamento para “trancar isso”. Modele acesso cedo para que equipes possam avançar sem expor tickets sensíveis ou permitir que a pessoa errada mude regras do sistema.
Separe papéis (e mantenha simples)
Comece com alguns papéis claros e adicione nuances só se surgir necessidade real:
- Agente: trabalha tickets, adiciona notas, responde, atualiza campos.
- Líder: tudo que um agente faz, mais reatribuição, gestão de filas e fluxos de coaching.
- Admin: configurações do sistema como canais, gestão de usuários e configuração.
- Editor de conteúdo: cria e publica artigos da base de conhecimento.
- Somente leitura: auditoria, finanças, legal ou stakeholders que precisam ver sem alterar.
Defina permissões por capacidade
Evite acesso “tudo ou nada”. Trate ações maiores como permissões explícitas:
- Visualizar vs. editar tickets (incluindo notas privadas)
- Gerenciar macros/respostas prontas
- Editar regras de SLA, timers e políticas de escalonamento
- Publicar/despublicar conteúdo da KB
Isso facilita conceder acesso de menor privilégio e suportar crescimento (novas equipes, novas regiões, contratados).
Acesso baseado em equipe para filas sensíveis
Algumas filas devem ser restritas por padrão — cobrança, segurança, VIP ou solicitações relacionadas a RH. Use participação em equipe para controlar:
- Quais filas são visíveis
- Quem pode reatribuir ou mesclar tickets
- Se campos de dados do cliente são mascarados
Logs de auditoria que você realmente usará
Registre ações chave com quem, o quê, quando e valores antes/depois: mudanças de atribuição, exclusões, edições de SLA/políticas, mudanças de papel e publicações da KB. Torne os logs pesquisáveis e exportáveis para que investigações não exijam acesso ao banco.
Planeje multi-brand ou multi-inbox cedo
Se você suporta múltiplas marcas ou caixas de entrada, decida se usuários trocam de contexto ou se o acesso é particionado. Isso afeta checagens de permissão e relatórios e deve ser consistente desde o início.
Projete a experiência do agente e do administrador
Um sistema de tickets ganha ou perde pela velocidade com que agentes entendem uma situação e tomam a próxima ação. Trate a área de trabalho do agente como sua “tela inicial”: ela deve responder imediatamente três perguntas — o que aconteceu, quem é este cliente e o que devo fazer a seguir.
Layout do espaço de trabalho do agente
Comece com uma visualização dividida que mantenha o contexto visível enquanto os agentes trabalham:
- Thread de conversa (e-mail/chat/mensagens) com timestamps claros, anexos e citações.
- Painel do cliente com identidade, plano/nível, organização, tickets anteriores e notas-chave.
- Campos do ticket (status, prioridade, fila, responsável, tags, timers de SLA) agrupados logicamente, não espalhados.
Mantenha a thread legível: diferencie cliente vs agente vs eventos do sistema, e destaque visualmente notas internas para que nunca sejam enviadas por engano.
Ações de um clique que removem atrito
Coloque ações comuns onde o cursor já está — perto da última mensagem e no topo do ticket:
- Atribuir / reatribuir
- Mudar status (incluindo “aguardando cliente”)
- Adicionar nota interna
- Aplicar macro (resposta pré-preenchida + atualizações de campo)
Busque fluxos “um clique + comentário opcional”. Se uma ação exigir modal, mantenha-o curto e navegável por teclado.
Recursos de velocidade para equipes de alto volume
Suporte de alto throughput precisa de atalhos previsíveis:
- Atalhos de teclado para responder, anotar, atribuir a mim, fechar e próximo ticket
- Ações em massa nas listas (tag, atribuir, fechar, mesclar)
- Um palette de comandos rápido para usuários avançados
Acessibilidade e segurança da UI
Construa acessibilidade desde o dia um: contraste suficiente, estados de foco visíveis, navegação por tabulação completa e labels para leitores de tela em controles e timers. Também evite erros custosos com pequenas salvaguardas: confirme ações destrutivas, rotule claramente “resposta pública” vs “nota interna” e mostre o que será enviado antes do envio.
UX do admin e do portal do cliente
Admins precisam de telas simples e guiadas para filas, campos, automações e modelos — evite esconder itens essenciais em configurações profundas.
Se clientes puderem enviar e acompanhar problemas, projete um portal leve: criar ticket, ver status, adicionar atualizações e ver artigos sugeridos antes de submeter. Mantenha-o consistente com sua marca pública e linke-o em /help.
Planeje integrações, APIs e entrada omnicanal
Itere sem quebrar as operações
Teste regras de SLA e roteamento com segurança usando Snapshots e rollback rápido durante pilotos.
Um app de tickets fica útil quando conecta aos lugares onde clientes já falam com você — e às ferramentas que sua equipe usa para resolver problemas.
Comece com os sistemas que você precisa conectar
Liste suas integrações “dia um” e quais dados precisa de cada uma:
- E-mail (caixas compartilhadas, regras de encaminhamento, SMTP de saída)
- Chat (widget no site, WhatsApp, ferramentas estilo Intercom)
- CRM (contexto da conta, dono, nível do plano)
- Cobrança (status de assinatura, faturas, reembolsos)
- Provedor de identidade (SSO via Google/Microsoft, provisionamento SCIM)
Escreva a direção do fluxo de dados (somente leitura vs. escrita) e quem é dono de cada integração internamente.
Projete sua API e webhooks cedo
Mesmo que você lance integrações depois, defina primitivas estáveis agora:
- Endpoints de API para criar, atualizar e buscar tickets, além de comentários/mensagens e mudanças de status.
- Webhooks para eventos chave (ticket.created, ticket.updated, message.received, sla.breached) para que sistemas externos reajam.
Mantenha autenticação previsível (chaves de API para servidores; OAuth para apps instalados por usuários) e versionamento da API para evitar quebrar clientes.
Previna tickets duplicados com threading sólido por e-mail
E-mail é onde casos de borda bagunçados aparecem primeiro. Planeje como você irá:
- Encadear respostas usando cabeçalhos Message-ID / In-Reply-To / References
- Analisar mensagens encaminhadas e assinaturas comuns com segurança
- Desduplicar detectando payloads inbound repetidos (especialmente de provedores de e-mail)
Um pequeno investimento aqui evita desastres como “cada resposta cria um novo ticket”.
Trate anexos com segurança
Suporte anexos, mas com guardrails: limites de tipo/tamanho de arquivo, armazenamento seguro e ganchos para escaneamento de vírus (ou serviço de varredura). Considere remover formatos perigosos e jamais renderizar HTML não confiável inline.
Documente a configuração como um recurso de produto
Crie um guia curto de integração: credenciais necessárias, passos de configuração, solução de problemas e testes. Se você mantiver docs, linke seu hub de integrações em /docs para que administradores não precisem de engenharia para conectar sistemas.
Adicione análises e relatórios para performance de suporte
Análises transformam seu sistema de tickets de “um lugar para trabalhar” em “uma forma de melhorar”. O essencial é capturar os eventos certos, computar algumas métricas consistentes e apresentá-las para diferentes públicos sem expor dados sensíveis.
Comece com uma trilha de eventos (não apenas o estado atual do ticket)
Guarde os momentos que explicam por que um ticket está como está. No mínimo, rastreie: mudanças de status, respostas do cliente e do agente, atribuições e reatribuições, atualizações de prioridade/categoria e eventos de timer SLA (início/parada, pausas e violações). Isso permite responder perguntas como “Violamos porque tínhamos pouca equipe, ou porque esperamos o cliente?”.
Mantenha eventos preferencialmente append-only; isso torna auditoria e relatórios mais confiáveis.
Dashboards para líderes de equipe
Líderes geralmente precisam de visões operacionais acionáveis hoje:
- Backlog por fila, prioridade e categoria
- Tickets envelhecidos (ex.: mais antigos abertos, mais antigos aguardando cliente)
- Risco de SLA (tickets com probabilidade de violar nas próximas X horas)
- Carga de trabalho do agente (contagem atribuída, trabalho ativo e tempo desde a última atualização)
Faça esses dashboards filtráveis por intervalo de tempo, canal e equipe — sem forçar gerentes a usar planilhas.
Relatórios para executivos
Executivos se importam menos com tickets individuais e mais com tendências:
- Volume por categoria/canal, incluindo dias/horários de pico
- Tendências de primeira resposta e resolução (mediana e percentil 90)
- Tendências de CSAT (e taxa de resposta, para não enganar nas pontuações)
Se você ligar resultados a categorias, pode justificar dimensionamento, treinamento ou correções de produto.
Filtros, exportações e controles de acesso
Adicione exportação CSV para visões comuns, mas proteja com permissões (e idealmente controles por campo) para evitar vazamento de e-mails, corpos de mensagem ou identificadores de clientes. Registre quem exportou o quê e quando.
Retenção de dados sem promessas arriscadas
Defina por quanto tempo você guarda eventos de ticket, conteúdo de mensagens, anexos e agregados analíticos. Prefira configurações de retenção configuráveis e documente o que é realmente deletado vs. anonimizado para não prometer garantias que não pode verificar.
Escolha uma arquitetura prática e stack tecnológico
Um produto de tickets não precisa de arquitetura complexa para ser eficaz. Para a maioria das equipes, uma configuração simples é mais rápida de entregar, mais fácil de manter e ainda escala bem.
Comece com um diagrama de sistema direto
Um baseline prático se parece com isto:
- Front-end web: UI do agente/admin e formulários/portal para clientes
- Backend de API: regras de negócio para tickets, SLAs, usuários e KB
- Banco de dados: fonte da verdade para tickets, usuários, eventos e configurações
- Jobs em background: tudo que é baseado em tempo ou execução longa
Essa abordagem de “monólito modular” (um backend, módulos claros) mantém o v1 manejável e deixa espaço para dividir serviços depois, se necessário.
Se quiser acelerar o v1 sem reinventar pipeline de entrega, uma plataforma de vibe-coding como Koder.ai pode ajudar a prototipar o painel do agente, ciclo de vida de tickets e telas administrativas via chat — e depois exportar o código-fonte quando estiver pronto para controle total.
Saiba o que deve rodar em background
Sistemas de tickets parecem em tempo real, mas muito trabalho é assíncrono. Planeje jobs em background cedo para:
- Timers de SLA e escalonamentos (ex.: “primeira resposta em 30 minutos”)
- Notificações (e-mail, in-app, webhooks)
- Indexação de busca (tickets e artigos da KB)
- Processamento de e-mail inbound (parsing, anexos, threading)
Se o processamento em background for deixado para depois, SLAs ficam pouco confiáveis e agentes perdem confiança.
Armazene dados para correção, busque para velocidade
Use um banco relacional (PostgreSQL/MySQL) para registros principais: tickets, comentários, status, atribuições, políticas de SLA e tabela de eventos/auditoria.
Para busca rápida e relevância, mantenha um índice de busca separado (Elasticsearch/OpenSearch ou equivalente gerenciado). Não tente forçar seu banco relacional a fazer busca full-text em escala se seu produto depende disso.
Decida construir ou comprar (e por quê)
Três áreas costumam economizar meses se compradas:
- Autenticação: use um provedor testado (SSO, MFA, políticas de senha)
- Envio de e-mails: serviço de e-mail transacional para entregabilidade e tratamento de bounces
- Busca: busca gerenciada, se não houver expertise interna
Construa o que diferencia você: regras de workflow, comportamento de SLAs, lógica de roteamento e a experiência do agente.
Planeje marcos com uma lista clara para o v1
Estime esforço por marcos, não por features. Uma lista sólida de marcos v1 é: CRUD de tickets + comentários, atribuição básica, timers de SLA (núcleo), notificações por e-mail, relatórios mínimos. Mantenha “bonitinhos” (automação avançada, papéis complexos, análises profundas) fora do escopo até o uso do v1 provar o que importa.
Cubra segurança, privacidade e confiabilidade básicas
Construa sua v1 mais rápido
Prototipe um app de tickets com filas, SLAs e um portal descrevendo-o no chat.
Decisões de segurança e confiabilidade são mais fáceis (e baratas) quando incorporadas cedo. Um app de suporte manipula conversas sensíveis, anexos e detalhes de contas — trate-o como um sistema central, não como ferramenta acessória.
Proteja dados de clientes por padrão
Comece com criptografia em trânsito em todos os lugares (HTTPS/TLS), incluindo chamadas entre serviços internos se houver vários serviços. Para dados em repouso, criptografe bancos e storage de objetos (anexos) e guarde segredos em um cofre gerenciado.
Use acesso de menor privilégio: agentes só devem ver tickets que podem tratar e admins devem ter direitos elevados só quando necessário. Adicione logs de acesso para responder “quem viu/exportou o quê e quando?” sem achismos.
Escolha autenticação que combine com seu público
Autenticação não é one-size-fits-all. Para times pequenos, e-mail + senha pode bastar. Se você vende para organizações maiores, SSO (SAML/OIDC) pode ser requisito. Para portais leves ao cliente, magic links reduzem atrito.
Seja qual for a escolha, garanta sessões seguras (tokens de curta duração, refresh, cookies seguros) e adicione MFA para contas administrativas.
Previna ataques comuns antes que comecem
Coloque rate limiting em login, criação de tickets e endpoints de busca para frear brute-force e spam. Valide e sanitize entradas para prevenir injeção e HTML inseguro em comentários.
Se usar cookies, adicione proteção CSRF. Para APIs, aplique regras CORS estritas. Para uploads de arquivos, escaneie por malware e restrinja tipos/tamanhos.
Backups, recuperação e metas mensuráveis
Defina objetivos RPO/RTO (quanto dado pode-se perder, quão rápido voltar). Automatize backups de DB e storage de arquivos e — crucial — teste restaurações regularmente. Um backup que você não consegue restaurar não é backup.
Noções básicas de privacidade que seus usuários vão pedir
Apps de suporte costumam ter requests de privacidade. Ofereça forma de exportar e excluir dados do cliente e documente o que é removido vs retido por razões legais/auditoria. Mantenha trilhas de auditoria e logs de acesso disponíveis para admins (veja /security) para investigar incidentes rapidamente.
Teste, lance e melhore com times de suporte reais
Lançar um app web de suporte ao cliente não é o fim — é o começo de aprender como agentes reais trabalham sob pressão real. O objetivo de testes e rollout é proteger o suporte diário enquanto você valida que o sistema de tickets e a gestão de SLAs se comportam corretamente.
Escreva cenários de ponta a ponta que correspondam ao trabalho real
Além de testes unitários, documente (e automatize quando possível) um pequeno conjunto de cenários E2E que reflitam os fluxos de maior risco:
- Criação de ticket: entrada por e-mail/web form/API cria um ticket com os campos certos, identidade do cliente e status inicial corretos.
- Respostas e threading: respostas do cliente se vinculam ao ticket certo, respostas de agentes notificam o cliente, notas internas permanecem internas.
- Violações de SLA: timers iniciam/param corretamente (ex.: pause em “Aguardando cliente”), violações disparam escalonamentos certos e a trilha de auditoria registra o ocorrido.
- Busca na base de conhecimento: agentes encontram artigos relevantes rápido a partir da vista do ticket, e clientes veem sugestões antes de submeter.
Se tiver um ambiente de staging, popule-o com dados realistas (clientes, tags, filas, horas úteis) para que os testes não passem apenas “na teoria”.
Rode um piloto e colete feedback semanalmente
Comece com um grupo pequeno de suporte (ou uma única fila) por 2–4 semanas. Estabeleça um ritual semanal de feedback: 30 minutos para revisar o que atrapalhou, o que confundiu clientes e quais regras surpreenderam.
Mantenha o feedback estruturado: “Qual era a tarefa?”, “O que você esperava?”, “O que aconteceu?” e “Com que frequência isso ocorre?”. Isso ajuda a priorizar correções que impactam throughput e conformidade com SLAs.
Crie um checklist de onboarding para admins e agentes
Torne o onboarding repetível para que rollout não dependa de uma pessoa.
Inclua essenciais: login, vistas de fila, responder vs nota interna, atribuir/menções, mudar status, usar macros, ler indicadores de SLA e encontrar/criar artigos da KB. Para admins: gestão de papéis, horas úteis, tags, automações e relatórios básicos.
Planeje um rollout em etapas (com opção de rollback)
Lance por equipe, canal ou tipo de ticket. Defina um caminho de rollback antes: como temporariamente redirecionar intake, que dados podem precisar de re-sincronização e quem toma a decisão.
Times que constroem com Koder.ai costumam usar snapshots e rollback durante pilotos iniciais para iterar com segurança em workflows (filas, SLAs e formulários de portal) sem interromper operações ao vivo.
Defina um roadmap de iteração
Quando o piloto estabilizar, planeje melhorias em ondas:
- Melhor automação (macros, triggers, auto-tagging)
- Roteamento avançado (atribuição por habilidade, balanceamento de carga)
- Workflows de KB mais ricos (revisões de artigos, loops de feedback, métricas de deflexão)
Trate cada onda como um pequeno release: test, pilot, medir e então expandir.