Defina escopo e necessidades dos usuários
Antes de desenhar telas ou escolher um parser de arquivos, seja específico sobre quem está movendo dados para dentro e para fora do seu produto e por quê. Um app web de importação de dados feito para operadores internos terá aparência muito diferente de uma ferramenta self-serve de importação Excel usada por clientes.
Quem são os usuários?
Comece listando os papéis que vão lidar com importações/exportações:
- Admins que configuram mapeamentos, regras e permissões
- Operadores que executam importações regularmente e tratam exceções
- Clientes que enviam seus próprios arquivos CSV/Excel e esperam orientação clara
Para cada papel, defina o nível de habilidade esperado e a tolerância à complexidade. Clientes normalmente precisam de menos opções e explicações muito melhores dentro do produto.
Casos de uso principais (e o que significa “feito”)
Anote seus cenários principais e priorize-os. Comuns incluem:
- Carga inicial em massa durante onboarding (alto volume, dados bagunçados)
- Sincronização periódica (atualizações semanais/mensais, consistência importa)
- Exportes pontuais para relatórios, migração ou backup
Depois defina métricas de sucesso mensuráveis: menos importações falhas, menor tempo para resolver erros e menos tickets de suporte sobre “meu arquivo não carrega”. Essas métricas ajudam a fazer trade-offs depois (por exemplo, investir em relatórios de erro mais claros vs. suportar mais formatos de arquivo).
Seja explícito sobre o que você suportará no dia um:
- Formatos de arquivo: CSV, Excel (XLSX), JSON
- Tamanho máximo de arquivo e limites de linhas (e o que acontece quando excedido)
- Expectativas de codificação (ex.: UTF-8) e regras de fuso horário para datas
Finalmente, identifique necessidades de conformidade cedo: se os arquivos contêm PII, requisitos de retenção (por quanto tempo armazenar uploads) e requisitos de auditoria (quem importou o quê, quando e o que mudou). Essas decisões afetam armazenamento, logging e permissões em todo o sistema.
Escolha arquitetura e stack
Antes de pensar numa UI sofisticada de mapeamento de colunas ou regras de validação CSV, escolha uma arquitetura que sua equipe consiga entregar e operar com confiança. Importações e exportações são infraestrutura “chata”—velocidade de iteração e facilidade de depuração valem mais que novidade.
Qualquer stack web mainstream pode suportar um app de importação de dados. Escolha com base em habilidades existentes e realidade de contratação:
- React + Node (TypeScript) se quiser full-stack numa única linguagem e ecossistema forte para jobs em background.
- Django se quiser admin opinativo, ORM maduro e entrega rápida.
- Rails se valoriza convenções, CRUD rápido e padrões consolidados para jobs em background.
O importante é consistência: a stack deve facilitar adicionar novos tipos de importação, novas regras de validação e novos formatos de exportação sem reescritas.
Se quiser acelerar scaffolding sem prender-se a um protótipo único, uma plataforma de vibe-coding como Koder.ai pode ajudar: você descreve o fluxo de importação (upload → preview → mapping → validation → background processing → history) em chat, gera uma UI React com backend em Go + PostgreSQL, e itera rapidamente usando modo de planejamento e snapshots/rollback.
Armazenamento: separe “arquivo bruto” de “registros normalizados”
Use um banco relacional (Postgres/MySQL) para registros estruturados, upserts e logs de auditoria para mudanças de dados.
Armazene uploads originais (CSV/Excel) em object storage (S3/GCS/Azure Blob). Manter arquivos brutos é inestimável para suporte: você pode reproduzir problemas de parsing, reexecutar jobs e explicar decisões de tratamento de erro.
Decida como as importações rodam
Arquivos pequenos podem rodar sincronicamente (upload → validar → aplicar) para uma UX responsiva. Para arquivos maiores, mova o trabalho para jobs em background:
- upload → enfileirar job → mostrar progresso/histórico → notificar na conclusão
Isso também permite retries e gravações com rate limit.
Multi-tenant vs single-tenant
Se você está construindo SaaS, decida cedo como separar dados por tenant (escopo por linha, schemas separados ou bancos separados). Essa escolha afeta sua API de exportação, permissões e performance.
Requisitos não-funcionais a documentar agora
Anote metas de uptime, tamanho máximo de arquivo, linhas esperadas por importação, tempo para completar e limites de custo. Esses números guiam a escolha de filas, estratégia de batching e indexação—muito antes da UI ficar polida.
Construa o fluxo de entrada (import intake)
O fluxo de entrada define o tom de cada importação. Se for previsível e permissivo, usuários tentarão novamente quando algo der errado—e tickets de suporte diminuem.
Pontos de entrada: upload via UI e API
Ofereça uma área drag-and-drop além do seletor clássico de arquivo para UI web. Drag-and-drop é rápido para usuários avançados, enquanto o seletor é mais acessível e familiar.
Se seus clientes importam de outros sistemas, adicione um endpoint de API também. Ele pode aceitar multipart (arquivo + metadados) ou fluxo com URL pré-assinada para arquivos maiores.
Parse seguro: cabeçalhos, codificações e amostragem
No upload, faça um parsing leve para criar um “preview” sem persistir dados ainda:
- Detecte cabeçalhos e mostre uma amostra de linhas (ex.: primeiras 20–100)
- Trate codificações comuns (UTF‑8, UTF‑16) e delimitadores (vírgula, tab, ponto-e-vírgula)
- Normalize quebras de linha e remova problemas óbvios de formatação
Esse preview alimenta etapas posteriores como mapeamento de colunas e validação.
Armazene o arquivo original para replay
Sempre armazene o arquivo original de forma segura (object storage é típico). Mantenha-o imutável para que você possa:
- Reexecutar a importação quando suas regras de validação mudarem
- Investigar bugs com o input exato
- Oferecer uma opção “baixar original” no histórico de importações
Trate cada upload como um registro de primeira classe. Salve metadados como quem enviou, timestamp, sistema de origem, nome do arquivo e checksum (para detectar duplicatas e garantir integridade). Isso é valioso para auditoria e depuração.
Pré-checagens antes do usuário investir tempo
Execute pré-checagens rápidas imediatamente e falhe cedo quando necessário:
- Tipo de arquivo e limites de tamanho
- Legibilidade básica (conseguimos parsear?)
- Presença de colunas obrigatórias (baseado no tipo de import)
Se uma pré-checagem falhar, retorne uma mensagem clara e mostre o que corrigir. O objetivo é bloquear arquivos realmente inválidos rapidamente—sem bloquear dados válidos, mas imperfeitos, que podem ser mapeados e limpos depois.
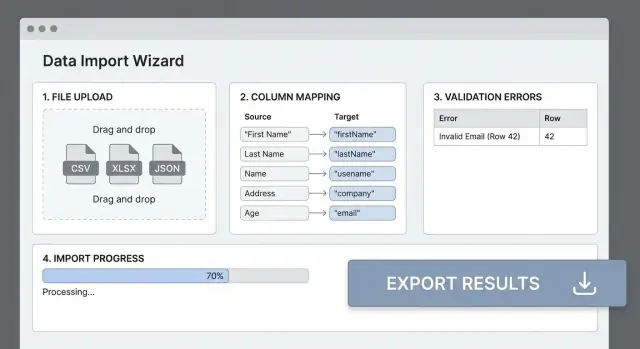
A maioria das falhas de importação acontece porque os cabeçalhos do arquivo não correspondem aos campos da sua aplicação. Uma etapa clara de mapeamento transforma um CSV “bagunçado” em entrada previsível e evita tentativas e erros do usuário.
Uma UI de mapeamento que as pessoas entendem
Mostre uma tabela simples: Coluna de origem → Campo destino. Autodetecte possíveis correspondências (comparação case-insensitive, sinônimos como “E-mail” → email), mas sempre permita que o usuário sobreponha.
Inclua alguns recursos de qualidade de vida:
- Marcar campos destino obrigatórios e mostrar se estão mapeados
- Permitir “Ignorar esta coluna” para dados irrelevantes
- Destacar colunas não mapeadas para que o usuário não perca nada
Templates de mapeamento salvos (por cliente ou dataset)
Se clientes importam o mesmo formato toda semana, torne isso um clique. Permita salvar templates escopados a:
- uma conta/cliente
- um dataset/tipo (ex.: Contatos vs. Faturas)
- opcionalmente, uma integração ou sistema de origem específico
Ao subir um novo arquivo, sugira um template com base na sobreposição de colunas. Também suporte versionamento para que usuários atualizem um template sem quebrar execuções antigas.
Adicione transformações leves por campo mapeado:
- remover espaços; converter strings vazias para null
- parse de datas (MM/DD/YYYY vs. DD.MM.YYYY) com opções de fuso
- normalização de moeda (ex.: “$1,200.00” → 1200.00 + moeda)
- enums (ex.: “Active”, “enabled”, “1” → ACTIVE)
- dividir/unir campos (Nome Completo → Primeiro/Sobrenome, ou vice-versa)
Mantenha transformações explícitas na UI (“Aplicado: Trim → Parse Date”) para que o resultado seja explicável.
Preview antes de confirmar
Antes de processar o arquivo inteiro, mostre um preview dos resultados mapeados para (por exemplo) 20 linhas. Exiba o valor original, o valor transformado e avisos (como “Não foi possível parsear data”). Aqui os usuários detectam problemas cedo.
Detecte duplicatas e campos-chave
Peça ao usuário para escolher um campo-chave (email, external_id, SKU) e explique o que acontece em duplicatas. Mesmo que você trate upserts depois, essa etapa define expectativas: você pode avisar sobre chaves duplicadas no arquivo e sugerir qual registro “vence” (primeiro, último, ou erro).
Projete o sistema de validação
Validação é o que diferencia um “uploader” qualquer de um recurso de importação confiável. O objetivo não é ser estrito por si só—é evitar que dados ruins se espalhem dando aos usuários feedback claro e acionável.
Separe validação em camadas
Trate validação como três checagens distintas, cada uma com propósito diferente:
- Validação de esquema (tipos & campos obrigatórios): “
email é string?”, “amount é número?”, “customer_id está presente?” Isso é rápido e pode rodar imediatamente após o parse.
- Regras de negócio: “Amount deve ser positivo”, “Status deve ser um de Active/Paused”, “Data de início não pode ser no passado.” Essas refletem como seu produto funciona.
- Regras cross-field e relacionais: “Se
country=US, state é obrigatório”, “end_date deve ser depois de start_date”, “Nome do plano deve existir neste workspace.” Essas normalmente requerem contexto (outras colunas ou lookups no banco).
Manter as camadas separadas facilita estender o sistema e explicar os erros na UI.
Modo estrito vs leniente (e por que importa)
Decida cedo se uma importação deve:
- Falhar todo o arquivo (modo estrito): ideal para dados financeiros, permissões ou qualquer coisa onde atualizações parciais criem risco.
- Aceitar linhas válidas parcialmente (modo leniente): ideal para listas grandes onde usuários esperam corrigir apenas registros problemáticos.
Você pode suportar ambos: estrito como padrão, com uma opção “Permitir importação parcial” para admins.
Todo erro deve responder: o que aconteceu, onde e como consertar.
Exemplo: “Linha 42, Coluna ‘Data de Início’: deve ser uma data válida no formato YYYY-MM-DD.”
Diferencie:
- Erros: bloqueiam o processamento daquela linha (ou do arquivo todo em modo estrito)
- Avisos: são permitidos, mas destacados (ex.: “Departamento desconhecido; será deixado em branco”)
Habilite loops “corrigir e re-enviar”
Usuários raramente acertam tudo de primeira. Facilite re-uploads mantendo resultados de validação amarrados a uma tentativa de import e permitindo que o usuário reenvie um arquivo corrigido. Combine isso com relatórios de erro para download para que resolvam problemas em lote.
Motor de regras: configurável quando necessário, só em código quando mais seguro
Uma abordagem prática é híbrida:
- Regras configuráveis para requisitos específicos do tenant (ex.: “ID do funcionário deve ser único dentro deste workspace”).
- Regras definidas em código para invariantes do produto (ex.: limites de permissão, relacionamentos obrigatórios) para evitar má-configuração.
Isso mantém validação flexível sem transformá-la num “labirinto de configurações” difícil de depurar.
Implemente processamento confiável e retries
Configure Funções e Acessos
Modele permissões multi-tenant desde cedo e gere as interfaces de administração que você precisa.
Importações tendem a falhar por motivos chatos: banco lento, picos de arquivos, ou uma única linha “ruim” que bloqueia o lote. Confiabilidade é, em grande parte, tirar trabalho pesado do caminho request/response e tornar cada etapa segura para reexecução.
Use jobs em background para arquivos grandes
Execute parsing, validação e gravações em jobs em background (queues/workers) para que uploads não atinjam timeouts web. Isso também permite escalar workers independentemente quando clientes começarem a importar planilhas maiores.
Um padrão prático é dividir o trabalho em chunks (por exemplo 1.000 linhas por job). Um job “pai” agenda jobs de chunks, agrega resultados e atualiza progresso.
Rastreie estados e transições claras
Modele a importação como uma máquina de estados para que a UI e o time de ops saibam sempre o que está acontecendo:
- queued → running → completed
- queued/running → failed (com razão)
- queued/running → canceled (pelo usuário ou sistema)
Armazene timestamps e contagens de tentativas por transição de estado para responder “quando começou?” e “quantos retries?” sem vasculhar logs.
Progresso que os usuários possam confiar
Mostre progresso mensurável: linhas processadas, linhas restantes e erros encontrados até o momento. Se você puder estimar taxa, adicione um ETA aproximado—prefira “~3 min” a uma contagem regressiva precisa.
Torne o processamento idempotente (seguro para retries)
Retries não devem criar duplicatas nem aplicar updates em dobro. Técnicas comuns:
- Use um
import_id + row_number (ou hash da linha) como chave de idempotência estável.
- Upsert usando uma chave natural (como
external_id) em vez de “insert sempre”.
- Gravar em transações por chunk para que falhas parciais não corrompam estado.
Faça throttle para proteger todos
Rate-limit imports concorrentes por workspace e limite etapas de escrita intensiva (ex.: máximo N linhas/seg) para evitar sobrecarregar o banco e degradar experiência de outros usuários.
Relatórios de erro e histórico de importações
Se as pessoas não entenderem o que deu errado, vão reenviar o mesmo arquivo até desistirem. Trate cada importação como uma “execução” de primeira classe com trilha clara e erros acionáveis.
Crie um registro de execução de importação
Comece criando uma entidade import run no momento em que um arquivo é submetido. Esse registro deve capturar o essencial:
- Quem iniciou (usuário + organização)
- O que foi importado (nome do arquivo, tamanho, checksum, tipo de entidade)
- Quando ocorreu (timestamps de início/término)
- Como foi interpretado (configuração de mapeamento usada, versão de transformação)
- Resultado (sucesso/erro/parcial, linhas processadas, linhas rejeitadas)
Isso vira sua tela de histórico de importações: uma lista simples de execuções com status, contagens e uma página de “ver detalhes”.
Armazene erros a nível de linha (não apenas logs)
Logs de aplicação ajudam engenheiros, mas usuários precisam de erros consultáveis. Armazene erros como registros estruturados vinculados à import run, idealmente em dois níveis:
- Nível de linha: número da linha, identificador primário (se detectado), snapshot dos valores brutos
- Nível de campo: nome da coluna, código de erro (ex.: REQUIRED, INVALID_DATE), mensagem humana, severidade
Com essa estrutura você habilita filtros rápidos e insights agregados como “Top 3 tipos de erro desta semana”.
Torne erros utilizáveis: UI + relatório para download
Na página de detalhes da execução, ofereça filtros por tipo, coluna e severidade, além de um campo de busca (ex.: “email”). Depois ofereça um CSV de erros para download que inclua a linha original mais colunas extras como error_columns e error_message, com orientação clara como “Corrija o formato de data para YYYY-MM-DD.”
Adicione um modo dry run
Um “dry run” valida tudo usando o mesmo mapeamento e regras, mas não grava dados. É ideal para importações iniciais e permite iteração segura antes de confirmar mudanças.
Modelo de dados, upserts e auditabilidade
Itere Sem Medo
Faça mudanças arriscadas com segurança usando snapshots e rollback enquanto ajusta regras de validação.
Importações parecem “concluídas” quando linhas chegam no banco—mas o custo de longo prazo normalmente está em updates bagunçados, duplicatas e histórico de mudança obscuro. Esta seção trata de projetar seu modelo de dados para que importações sejam previsíveis, reversíveis e explicáveis.
Decida: criar, atualizar ou ambos
Defina como uma linha importada mapeia para seu modelo de domínio. Para cada entidade, decida se a importação pode:
- Criar novos registros apenas
- Atualizar registros existentes apenas
- Fazer ambos (caso comum em SaaS)
Essa decisão deve ser explícita na UI de configuração de import e armazenada com o job para que o comportamento seja reprodutível.
Escolha chaves de upsert e regras de colisão
Se suportar “criar ou atualizar”, você precisa de chaves de upsert estáveis—campos que identificam o mesmo registro toda vez. Escolhas comuns:
external_id (melhor quando vem de outro sistema)- Email (funciona para usuários/contatos, mas pode mudar)
- Chaves compostas (ex.:
account_id + sku)
Defina regras de colisão: o que acontece se duas linhas compartilham a mesma chave, ou se uma chave bate em vários registros? Bons defaults são “falhar a linha com erro claro” ou “última linha vence”, mas escolha deliberadamente.
Transações sem bloquear tudo
Use transações onde protegerem consistência (ex.: criar um pai e seus filhos). Evite uma transação gigante para um arquivo de 200k linhas; ela pode travar tabelas e tornar retries dolorosos. Prefira gravações em chunks (ex.: 500–2.000 linhas por lote) com upserts idempotentes.
Proteja integridade referencial
Imports devem respeitar relacionamentos: se uma linha referencia um registro pai (como Company), ou exija que exista ou crie-o numa etapa controlada. Falhar cedo com “pai ausente” evita dados meio-conectados.
Audite tudo que imports mudam
Adicione logs de auditoria para mudanças feitas por importações: quem disparou, quando, arquivo de origem e um resumo por registro do que mudou (old vs new). Isso facilita suporte, gera confiança e simplifica rollbacks.
Construa exportações que escalem
Exportes parecem simples até clientes tentarem “baixar tudo” no último minuto. Um sistema de exportação escalável deve lidar com grandes volumes sem degradar seu app ou gerar arquivos inconsistentes.
Ofereça os tipos de export adequados
Comece com três opções:
- Export completo: tudo que o usuário pode acessar.
- Export filtrado: respeita mesmos filtros/buscas da UI (status, intervalo de datas, proprietário, etc.).
- Export incremental: “mudanças desde X” para jobs de sincronização e pipelines de relatório.
Exportes incrementais são especialmente úteis para integrações e reduzem carga comparado a dumps completos repetidos.
- CSV é padrão para planilhas e análise em massa.
- JSON é melhor para API de exportação de dados e automação.
- Excel só quando necessário (múltiplas abas, formatação rica ou fluxos não técnicos).
Seja qual for a escolha, mantenha cabecalhos consistentes e ordem de colunas estável para que processos a jusante não quebrem.
Stream e paginação para evitar picos de memória
Exportes grandes não devem carregar todas as linhas na memória. Use paginação/streaming para escrever linhas conforme são buscadas. Isso evita timeouts e mantém o app responsivo.
Para datasets grandes, gere exportes em job em background e notifique o usuário quando estiver pronto. Padrão comum:
- Usuário solicita export.
- App enfileira um job.
- Job escreve o arquivo no object storage.
- UI mostra link de download e mantém histórico de exportes.
Isso combina bem com seus jobs de import e com o mesmo padrão de “histórico de execuções + artefato para download” usado para relatórios de erro.
Exportes frequentemente são auditados. Sempre inclua:
- Política clara de fuso horário (ex.: armazenar em UTC, exportar no fuso do usuário)
- Formatação consistente de datas (ISO-8601 para JSON; formatos explícitos para CSV/Excel)
- Timestamp “gerado em” e, para export incremental, o cutoff usado
Esses detalhes reduzem confusão e suportam reconciliações confiáveis.
Segurança, permissões e privacidade de dados
Imports e exports movem muita informação rapidamente. Isso também os torna pontos comuns para bugs de segurança: uma role permissiva demais, uma URL de arquivo vazada, ou um log com dados pessoais. Tome cuidado.
Comece com a mesma autenticação usada no app—não crie um caminho “especial” só para import/export.
Se usuários trabalham em navegador, auth por sessão (mais SSO/SAML opcional) geralmente é ideal. Se importações/exportações são automatizadas (jobs noturnos, parceiros de integração), considere chaves de API ou tokens OAuth com escopo e rotação.
Regra prática: a UI de import e a API de import devem aplicar as mesmas permissões, mesmo que sejam usadas por públicos distintos.
Acesso baseado em papéis: defina quem pode fazer o quê
Trate capacidades de import/export como privilégios explícitos. Papéis comuns incluem:
- Pode importar (enviar arquivos, rodar importações)
- Pode exportar (gerar e baixar exportes)
- Pode ver histórico (ver execuções de import, erros, contagens)
- Pode baixar arquivos (uploads originais, relatórios de erro)
Faça de “baixar arquivos” uma permissão separada. Muitos vazamentos sensíveis acontecem quando alguém pode ver uma execução e o sistema assume que pode também baixar a planilha original.
Considere também limites por linha ou por tenant: um usuário só deve importar/exportar dados da conta/workspace a que pertence.
Proteja dados sensíveis end-to-end
Para arquivos armazenados (uploads, CSVs de erro, arquivos de export), use object storage privado e links de download de curta duração. Encripte em repouso quando requerido por conformidade e seja consistente: upload original, arquivo de staging processado e relatórios gerados devem seguir mesmas regras.
Cuidado com logs. Reduza campos sensíveis (emails, telefones, IDs, endereços) e nunca logue linhas brutas por padrão. Quando debug for necessário, habilite “log detalhado de linhas” apenas para admins e assegure expiração.
Valide e escaneie uploads antes do processamento
Trate todo upload como input não confiável:
- Faça checagens de tipo de arquivo (não confie só no nome)
- Defina limites de tamanho para prevenir DoS e uploads gigantes acidentais
- Considere escaneamento de malware se seu perfil de risco ou indústria exigir
Também valide estrutura cedo: rejeite arquivos obviamente malformados antes de chegarem aos jobs em background e forneça mensagem clara ao usuário sobre o problema.
Trilhas de auditoria para eventos relevantes à segurança
Registre eventos que você gostaria de ter numa investigação: quem enviou arquivo, quem iniciou import, quem baixou export, mudanças de permissão e tentativas de acesso falhas.
Entradas de auditoria devem incluir ator, timestamp, workspace/tenant e o objeto afetado (import run ID, export ID), sem armazenar dados sensíveis por linha. Isso combina com seu histórico de import e ajuda a responder “quem mudou o quê e quando?” rapidamente.
Testes, monitoramento e operabilidade
Vá do Build ao Deploy
Implemente e hospede seu app de importação e exportação sem precisar integrar ferramentas extras.
Se imports/exports tocam dados de clientes, você eventualmente terá casos de borda: codificações estranhas, células mescladas, linhas parcialmente preenchidas, duplicatas e “ontem funcionou”. Operabilidade é o que impede esses casos de virar pesadelos de suporte.
Testes que refletem arquivos reais
Comece com testes focados nas partes mais sujeitas a falha: parsing, mapeamento e validação.
- Testes de parsing: use um conjunto pequeno de fixtures representativas CSV/XLSX (delimitadores diferentes, formatos de data, colunas vazias, números grandes, UTF‑8 vs Windows-1252). Afirme contagens de linhas e que campos-chave parseiam consistentemente.
- Testes de mapeamento + transformação: dado um conjunto de colunas de entrada, verifique que a app mapeia para os campos internos corretos e aplica transformações (trim, normalização de caixa, conversão de moeda/porcentagem).
- Testes de regras de validação: para cada regra (required, unique, range, existência FK), inclua linhas “boas” e “ruins” e afirme códigos/mensagens de erro exatas.
Depois adicione pelo menos um teste end-to-end para o fluxo completo: upload → processamento em background → geração de relatório. Esses testes pegam incompatibilidades entre UI, API e workers (por exemplo, payload de job faltando configuração de mapeamento).
Monitoramento que responde “o que quebrou?”
Monitore sinais que refletem impacto ao usuário:
- Falhas de jobs (contagem e taxa)
- Tempo de processamento (p50/p95)
- Taxa de erro de validação (picos súbitos muitas vezes indicam mudança de template)
- Profundidade da fila e throughput de workers
Ligue alertas a sintomas (aumento de falhas, fila crescendo) em vez de cada exceção.
Ferramentas admin e ajuda ao usuário
Dê aos times internos uma pequena superfície admin para re-executar jobs, cancelar imports travados e inspecionar falhas (metadados do arquivo, mapeamento usado, resumo de erro e link para logs/traces).
Para usuários, reduza erros evitáveis com dicas inline, templates de exemplo para download e passos claros nas telas de erro. Mantenha uma página de ajuda central e link nela a partir da UI de import (por exemplo: /docs).
Deploy, rollout e melhorias futuras
Entregar um sistema de import/export não é só “push pra produção”. Trate como recurso de produto com padrões seguros, caminhos claros de recuperação e espaço para evoluir.
Ambientes: dev, staging, prod
Configure ambientes dev/staging/prod com bancos isolados e buckets de object storage separados (ou prefixes) para uploads e exportes gerados. Use chaves/credenciais diferentes por ambiente e garanta que workers de jobs apontem para as filas corretas.
Staging deve espelhar produção: mesma concorrência de jobs, timeouts e limites de tamanho de arquivo. É aí que você valida performance e permissões sem arriscar dados reais de clientes.
Migrations e templates versionados
Importações tendem a “viver para sempre” porque clientes guardam planilhas antigas. Use migrações de banco normalmente, mas também versione seus templates de import (e presets de mapeamento) para que uma mudança de esquema não quebre o CSV do último trimestre.
Uma abordagem prática é armazenar template_version com cada import run e manter código de compatibilidade para versões antigas até poder depreciá-las.
Use feature flags para liberar mudanças com segurança:
- Novas regras de validação (warn-only primeiro, depois erro)
- Novos formatos de export (ex.: adicionar JSON além de CSV)
- Novas opções de mapeamento (ex.: dividir “Nome Completo”)
Flags permitem testar com usuários internos ou um pequeno cohort de clientes antes de liberar amplamente.
Fluxos de suporte e diagnóstico
Documente como o suporte deve investigar falhas usando histórico de import, IDs de job e logs. Um checklist simples ajuda: confirme versão do template, revise a primeira linha que falhou, cheque acesso ao storage, depois inspecione logs do worker. Linke isso no runbook interno e, quando apropriado, na UI admin (ex.: /admin/imports).
Próximos passos: integrações
Quando o fluxo core estiver estável, estenda além de uploads:
- Imports via API para pipelines automatizados
- Webhooks para “import concluído” ou “export pronto”
- Conectores para ferramentas comuns (Google Sheets, S3, Snowflake)
Esses upgrades reduzem trabalho manual e fazem seu app de importação parecer nativo nos processos existentes dos clientes.
Se estiver construindo isso como feature de produto e quiser reduzir o tempo até a “primeira versão utilizável”, considere usar Koder.ai para prototipar o assistente de importação, as páginas de status de jobs e o histórico de execuções end-to-end, e então exportar o código-fonte para um fluxo de engenharia convencional. Essa abordagem é prática quando o objetivo é confiabilidade e velocidade de iteração (não perfeição da UI no dia 1).