15 de mai. de 2025·8 min
Como construir um web app para enriquecimento de dados de clientes
Aprenda a construir uma aplicação web que enriquece registros de clientes: arquitetura, integrações, correspondência, validação, privacidade, monitoramento e dicas de implantação.
Defina objetivos, usuários e escopo do enriquecimento
Antes de escolher ferramentas ou desenhar diagramas de arquitetura, seja preciso sobre o que “enriquecimento” significa para sua organização. Times frequentemente misturam vários tipos de enriquecimento e depois têm dificuldade em medir progresso — ou discutem sobre o que significa “concluído”.
O que conta como enriquecimento?
Comece nomeando as categorias de campos que você quer melhorar e por quê:
- Firmográficos: tamanho da empresa, setor, sede, estágio de funding
- Contato: cargo, e-mail/telefone verificado, senioridade, função
- Comportamentais: sinais de uso do produto, intenção, pontuações de engajamento
- Campos customizados: território interno, nível de conta, pontuação de fit com ICP
Anote quais campos são obrigatórios, quais são desejáveis e quais nunca devem ser enriquecidos (por exemplo, atributos sensíveis).
Quem usará o app — e para quê?
Identifique seus usuários principais e suas tarefas principais:
- Sales ops: reduzir duplicatas, padronizar contas, melhorar roteamento
- Marketing ops: enriquecer leads para segmentação e melhor direcionamento
- Suporte: mostrar contexto da conta durante tickets
- Analistas: datasets confiáveis para relatórios
Cada grupo tende a precisar de um fluxo de trabalho diferente (processamento em lote vs. revisão por registro), então capture essas necessidades cedo.
Defina resultados, limites de escopo e métricas de sucesso
Liste resultados em termos mensuráveis: maior taxa de correspondência, menos duplicatas, roteamento de leads/contas mais rápido ou melhor performance de segmentação.
Estabeleça limites claros: quais sistemas estão dentro do escopo (CRM, billing, analytics do produto, helpdesk) e quais não estão — pelo menos para a primeira versão.
Por fim, concorde sobre métricas de sucesso e taxas de erro aceitáveis (por exemplo, cobertura de enriquecimento, taxa de verificação, taxa de duplicatas e regras de “falha segura” quando o enriquecimento é incerto). Isso será sua estrela guia para o restante da construção.
Modele seus dados de clientes e identifique lacunas
Antes de enriquecer qualquer coisa, defina claramente o que “um cliente” significa no seu sistema — e o que você já sabe sobre ele. Isso evita pagar por enriquecimento que você não consegue armazenar e previne merges confusos depois.
Faça inventário dos seus campos e fontes atuais
Comece com um catálogo simples de campos (ex.: nome, e-mail, empresa, domínio, telefone, endereço, cargo, setor). Para cada campo, anote de onde vem: input do usuário, importação CRM, sistema de billing, ferramenta de suporte, formulário de signup do produto ou um provedor de enriquecimento.
Também registre como ele é coletado (obrigatório vs opcional) e com que frequência muda. Por exemplo, cargo e tamanho da empresa mudam com o tempo, enquanto um ID interno do cliente nunca deveria mudar.
Defina seu modelo de identidade: pessoa, empresa, conta
A maioria dos fluxos de enriquecimento envolve pelo menos duas entidades:
- Pessoa (contato/lead): indivíduo com e-mails, telefones, cargos
- Empresa (organização): negócio com domínio, localização, firmográficos
Decida se também precisa de uma Conta (relação comercial) que conecte várias pessoas a uma empresa com atributos como plano, datas de contrato e status.
Escreva as relações que você suporta (ex.: muitas pessoas → uma empresa; uma pessoa → múltiplas empresas ao longo do tempo).
Documente problemas comuns de dados
Liste os problemas que aparecem repetidamente: valores faltantes, formatos inconsistentes ("US" vs "United States"), duplicatas geradas por importações, registros obsoletos e fontes conflitantes (endereço do billing vs CRM).
Escolha chaves obrigatórias e defina níveis de confiança
Escolha os identificadores que você usará para correspondência e atualizações — tipicamente e-mail, domínio, telefone e um ID interno do cliente.
Atribua a cada um um nível de confiança: quais chaves são autoritativas, quais são “melhor esforço” e quais nunca devem ser sobrescritas.
Esclareça propriedade e permissões de edição
Concorde quem é dono de quais campos (Sales ops, Suporte, Marketing, Customer Success) e defina regras de edição: o que um humano pode mudar, o que a automação pode alterar e o que requer aprovação.
Essa governança economiza tempo quando resultados de enriquecimento conflitam com dados existentes.
Escolha fontes de enriquecimento e contratos de dados
Antes de escrever código de integração, decida de onde os dados de enriquecimento virão e o que você tem permissão para fazer com eles. Isso previne um modo de falha comum: entregar um recurso que funciona tecnicamente, mas quebra expectativas de custo, confiabilidade ou conformidade.
Fontes típicas de enriquecimento
Você normalmente combinará várias entradas:
- Sistemas internos: CRM, billing, tickets de suporte, analytics do produto, plataforma de e-mail, data warehouse
- APIs de terceiros: firmográficos de empresas, validação de contatos, códigos de setor, technographics, sinais de risco
- Listas carregadas: CSVs de vendas, eventos, parceiros ou provedores de dados
- Webhooks: atualizações em tempo real de ferramentas que já observam mudanças (ex.: verificação de e-mail, provedores de identidade)
Como avaliar as fontes
Para cada fonte, avalie em cobertura (com que frequência retorna algo útil), frescura (quão rápido atualiza), custo (por chamada/por registro), limites de taxa e termos de uso (o que você pode armazenar, por quanto tempo e para qual propósito).
Verifique também se o provedor retorna scores de confiança e proveniência clara (de onde veio cada campo).
Defina um contrato de dados
Trate cada fonte como um contrato que especifica nomes/formatos de campos, campos obrigatórios vs opcionais, frequência de atualização, latência esperada, códigos de erro e semântica de confiança.
Inclua um mapeamento explícito (“campo do provedor → seu campo canônico”) e regras para nulos e valores conflitantes.
Decisões de fallback e armazenamento
Planeje o que acontece quando uma fonte está indisponível ou retorna resultados de baixa confiança: repetir com backoff, enfileirar para mais tarde ou recorrer a uma fonte secundária.
Decida o que você armazena (atributos estáveis necessários para busca/relatórios) versus o que calcula sob demanda (consultas caras ou sensíveis ao tempo).
Por fim, documente restrições sobre armazenar atributos sensíveis (ex.: identificadores pessoais, inferências demográficas) e defina regras de retenção apropriadas.
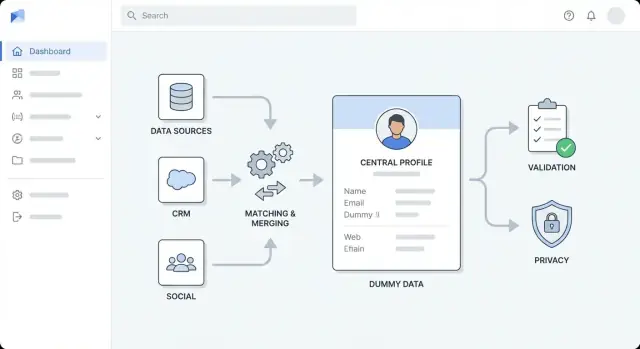
Desenhe a arquitetura de alto nível
Antes de escolher ferramentas, decida como o app será moldado. Uma arquitetura de alto nível clara mantém o trabalho de enriquecimento previsível, evita que "gambiarras" virem sujeira permanente e ajuda a equipe a estimar esforço.
Escolha um estilo de arquitetura que caiba no seu time
Para a maioria das equipes, comece com um monólito modular: uma única aplicação deployável, internamente dividida em módulos bem definidos (ingestão, matching, enriquecimento, UI). É mais simples de construir, testar e depurar.
Migre para serviços separados quando houver razão clara — por exemplo, throughput de enriquecimento alto, necessidade de escalonamento independente ou equipes diferentes que gerenciem partes distintas. Uma divisão comum é:
- Serviço API (requisições síncronas, auth, CRUD de registros)
- Serviço Worker (enriquecimento assíncrono, retries)
- UI (revisão, aprovações, ações em lote)
Separe responsabilidades em camadas
Mantenha limites explícitos para que mudanças não se propaguem:
- Camada de ingestão: importações de CRM/arquivos e normalização de entradas
- Camada de enriquecimento: chamadas a vendors/fontes internas e armazenamento de resultados
- Camada de validação: aplica regras de qualidade de dados e sinaliza exceções
- Camada de armazenamento: perfis de clientes, payloads brutos de fontes, histórico de auditoria
- Camada de apresentação: views da UI, filas de revisão, aprovações
Projete para enriquecimento assíncrono desde o dia 1
Enriquecimento é lento e sujeito a falhas (limites de taxa, timeouts, dados parciais). Trate enriquecimento como jobs:
- A API cria um job e responde rapidamente
- Workers processam jobs via fila (com retries e backoff)
- A UI mostra status do job e permite re-execução quando necessário
Planeje ambientes e configuração
Configure dev/staging/prod cedo. Mantenha chaves de vendors, thresholds e feature flags em configuração (não em código) e facilite trocar provedores por ambiente.
Alinhe com um diagrama de uma página
Faça um diagrama simples mostrando: UI → API → banco de dados, mais fila → workers → provedores de enriquecimento. Use-o em revisões para que todos concordem sobre responsabilidades antes da implementação.
Protótipo de via rápida (opcional)
Se o objetivo é validar fluxos e telas antes de um ciclo de engenharia completo, uma plataforma de prototipagem como Koder.ai pode ajudar a prototipar o app central rapidamente: UI em React para revisão/aprovações, camada API em Go e armazenamento em PostgreSQL.
Isso é especialmente útil para provar o modelo de jobs (enriquecimento assíncrono com retries), histórico de auditoria e padrões de acesso por papel, e depois exportar código-fonte quando pronto para produção.
Configure armazenamento, filas e serviços de suporte
Antes de começar a conectar provedores de enriquecimento, ajuste a “encanação” certa. Decisões sobre armazenamento e processamento em background são difíceis de mudar depois e impactam confiabilidade, custo e auditabilidade.
Banco de dados primário: perfis + histórico
Escolha um banco primário para perfis de clientes que suporte dados estruturados e atributos flexíveis. Postgres é uma escolha comum porque permite armazenar campos centrais (nome, domínio, setor) junto com campos semi-estruturados de enriquecimento (JSON).
Igualmente importante: armazene histórico de mudanças. Em vez de sobrescrever valores silenciosamente, capture quem/o que mudou um campo, quando e por quê (ex.: “vendor_refresh”, “manual_approval”). Isso facilita aprovações e protege durante rollbacks.
Fila: enriquecimento e retries
Enriquecimento é inerentemente assíncrono: APIs têm limites, redes falham e alguns vendors respondem lentamente. Adicione uma fila de jobs para trabalho em background:
- Requests de enriquecimento (registro único e em lote)
- Retries com backoff
- Refresh agendado (ex.: a cada 30/90 dias)
- Tratamento de dead-letter para jobs que continuam falhando
Isso mantém a UI responsiva e evita que problemas de provedores derrubem o app.
Cache: buscas rápidas e rastreamento de limites
Um cache pequeno (frequentemente Redis) ajuda buscas frequentes (ex.: “empresa por domínio”) e rastrear limites de taxa e janelas de cooldown dos vendors. Também é útil para chaves de idempotência, evitando que imports repetidos disparem enriquecimento duplicado.
Armazenamento de arquivos e retenção
Planeje storage para objetos (importações/exports CSV, relatórios de erro e arquivos de “diff” usados em fluxos de revisão).
Defina regras de retenção cedo: mantenha payloads brutos de vendors só pelo tempo necessário para debug/auditoria e expire logs conforme sua política de conformidade.
Construa pipelines de ingestão e normalização
Do esquema à interface
Transforme seu modelo de dados e contratos em telas CRUD e APIs funcionais para iterar.
Seu app de enriquecimento só é tão bom quanto os dados que recebe. Ingestão é onde você decide como a informação entra no sistema, e normalização é onde você torna essa informação consistente o suficiente para casar, enriquecer e relatar.
Decida como os dados entram
A maioria das equipes precisa de uma mistura de pontos de entrada:
- Endpoints de API para seu produto ou ferramentas internas enviarem novos/atualizados clientes
- Webhooks de CRMs ou sistemas de billing para mudanças quase em tempo real
- Pulls agendados (sync diário) para sistemas que não suportam push
- Importações CSV para backfills e uploads pontuais
Seja qual for o suporte, mantenha a etapa de “ingestão bruta” leve: aceite dados, autentique, registre metadados e enfileire trabalho para processamento.
Normalize e padronize cedo
Crie uma camada de normalização que transforme entradas bagunçadas em uma forma interna consistente:
- Nomes: trim de espaços, separar nomes completos quando possível, tratar maiúsculas/minúsculas
- Telefones: converter para formato E.164 e armazenar suposições de país explicitamente
- Endereços: padronizar campos (rua, localidade, região, CEP) e manter o texto original
- Domínios/e-mails: lowercase, remover parâmetros de rastreamento de URLs, validar sintaxe
Valide, coloque em quarentena e mantenha idempotência
Defina campos obrigatórios por tipo de registro e rejeite ou coloque em quarentena registros que falhem checagens (ex.: falta de e-mail/domínio para matching de empresa). Itens em quarentena devem ser visualizáveis e corrigíveis na UI.
Adicione chaves de idempotência para evitar processamento duplicado quando ocorrem retries (comum em webhooks e redes instáveis). Uma abordagem simples é fazer hash de (source_system, external_id, event_type, event_timestamp).
Acompanhe a linhagem por campo
Armazene proveniência para cada registro e, idealmente, para cada campo: fonte, timestamp de ingestão e versão da transformação. Isso permite responder depois: “Por que este telefone mudou?” e “Qual importação produziu este valor?”
Implemente matching, deduplicação e merge
Acertar o enriquecimento depende de identificar com confiança quem é quem. Seu app precisa de regras claras de matching, comportamento previsível de merge e um mecanismo de segurança quando o sistema não tiver certeza.
Defina regras de matching (e thresholds de confiança)
Comece com identificadores determinísticos:
- Chaves exatas: e-mail (normalizado em lowercase), ID do cliente, número fiscal, ou domínio verificado
Depois adicione matching probabilístico para casos sem chaves exatas:
- Matches fuzzy: nome + domínio da empresa, nome + localização, similaridade de telefone
Atribua uma pontuação de match e defina thresholds, por exemplo:
- Auto-merge apenas acima de um threshold alto
- Fila para revisão manual na faixa “talvez”
- Rejeitar abaixo do threshold inferior
Planeje lógica de deduplicação e merge
Quando dois registros representam o mesmo cliente, decida como os campos são escolhidos:
- Precedência de campo: “e-mail verificado vence e-mail não verificado”, “timestamp mais novo vence”, “CRM sobrescreve enrichments para proprietário do contato”
- Scores de confiança de fontes: ranqueie fontes (CRM, billing, provedores de enriquecimento) para resolver conflitos
- Tratamento de conflitos: mantenha ambos os valores quando possível (ex.: múltiplos telefones) ou armazene o valor que perdeu no histórico
Trilha de auditoria e fluxo de revisão
Todo merge deve criar um evento de auditoria: quem/o que acionou, valores antes/depois, quando, pontuação de match e IDs dos registros envolvidos.
Para matches ambíguos, forneça uma tela de revisão com comparação lado-a-lado e opções “mesclar / não mesclar / pedir mais dados”.
Salvaguardas contra merges em massa acidentais
Exija confirmação extra para merges em lote, limite merges por job e suporte a previews em “dry run”.
Adicione também um caminho de undo (ou reversão de merge) usando o histórico de auditoria para que erros não sejam permanentes.
Integre APIs de enriquecimento e trate confiabilidade
Enriquecimento é onde seu app encontra o mundo externo — múltiplos provedores, respostas inconsistentes e disponibilidade imprevisível.
Trate cada provedor como um “conector” plugável para que você possa adicionar, trocar ou desabilitar fontes sem tocar o resto do pipeline.
Construa conectores de provedores (auth, retries, mapeamento de erros)
Crie um conector por provedor de enriquecimento com uma interface consistente (ex.: enrichPerson(), enrichCompany()). Mantenha lógica específica do provedor dentro do conector:
- Autenticação (API keys, tokens OAuth, refresh de token)
- Retries padronizados para falhas transitórias
- Mapeamento de erros (transformar erros do provedor em categorias do seu sistema como
invalid_request,not_found,rate_limited,provider_down)
Isso simplifica fluxos a jusante: eles lidam com seus tipos de erro, não com as idiossincrasias de cada provedor.
Trate limites de taxa com throttling e backoff
A maioria das APIs impõe quotas. Adicione throttling por provedor (e às vezes por endpoint) para manter requisições dentro dos limites.
Quando alcançar um limite, use backoff exponencial com jitter e respeite headers Retry-After quando fornecidos.
Planeje também falhas “lentas”: timeouts e respostas parciais devem ser consideradas eventos re-tentáveis, não quedas silenciosas.
Armazene confiança e evidências (dentro da política)
Resultados de enriquecimento raramente são absolutos. Armazene scores de confiança do provedor quando disponíveis, além do seu próprio score baseado na qualidade de match e completude dos campos.
Quando permitido por contrato e política de privacidade, guarde evidências brutas (URLs de origem, identificadores, timestamps) para suportar auditoria e confiança do usuário.
Estratégia multi-provedor: seleção do “melhor disponível”
Suporte múltiplos provedores definindo regras de seleção: mais barato primeiro, maior confiança, ou campo-a-campo “melhor disponível”.
Registre qual provedor forneceu cada atributo para que você possa explicar mudanças e reverter se necessário.
Regras de refresh agendado
Enriquecimento fica defasado. Implemente políticas de refresh como “re-enriquecer a cada 90 dias”, “rever quando um campo-chave mudar” ou “re-enriquecer somente se a confiança cair”.
Torne os agendamentos configuráveis por cliente e por tipo de dado para controlar custo e ruído.
Adicione regras de qualidade de dados e validação
Prototipe o fluxo de enriquecimento
Prototipe seu app de enriquecimento a partir de um plano de chat e refine-o com o modo de planejamento.
Enriquecimento só ajuda se os valores novos forem confiáveis. Trate validação como recurso de primeira classe: ela protege seus usuários de imports bagunçados, respostas de terceiros não confiáveis e corrupção acidental durante merges.
Defina regras de validação por campo
Comece com um “catálogo de regras” por campo, compartilhado por formulários da UI, pipelines de ingestão e APIs públicas.
Regras comuns incluem checagens de formato (e-mail, telefone, CEP), valores permitidos (códigos de país, listas de setores), ranges (faixa de funcionários, faixas de receita) e dependências requeridas (se country = US, então state é obrigatório).
Mantenha regras versionadas para poder alterá-las com segurança ao longo do tempo.
Adicione checagens de qualidade que reflitam uso real
Além da validação básica, rode checagens de qualidade que respondam perguntas de negócio:
- Completude: temos os campos mínimos para usar o registro?
- Unicidade: identificadores “únicos” (domínio, número fiscal) estão duplicados?
- Consistência: campos relacionados batem (país vs prefixo do telefone)?
- Oportunidade: há quanto tempo um valor existe; precisa de refresh?
Pontue registros e fontes
Converta checagens em um score: por registro (health geral) e por fonte (com que frequência fornece valores válidos e atualizados).
Use o score para guiar automações — por exemplo, só aplicar enriquecimentos automaticamente acima de um threshold.
Roteie falhas de forma previsível
Quando um registro falha validação, não o descarte.
Envie para uma fila “data-quality” para retry (problemas transitórios) ou revisão manual (entrada ruim). Armazene o payload falhado, violações de regras e sugestões de correção.
Torne erros compreensíveis
Retorne mensagens claras e acionáveis para imports e clientes de API: qual campo falhou, por quê e um exemplo de valor válido.
Isso reduz carga no suporte e acelera a limpeza de dados.
Crie a UI para revisão, aprovações e trabalho em lote
Seu pipeline de enriquecimento só entrega valor quando pessoas conseguem revisar o que mudou e empurrar atualizações para sistemas downstream com confiança.
A UI deve tornar “o que aconteceu, por quê e o que eu faço a seguir?” óbvio.
Telas principais a projetar
Perfil do cliente é a base. Mostre identificadores chave (e-mail, domínio, nome da empresa), valores atuais dos campos e um badge de status de enriquecimento (ex.: Não enriquecido, Em progresso, Precisa de revisão, Aprovado, Rejeitado).
Adicione uma linha do tempo de mudanças que explique atualizações em linguagem simples: “Tamanho da empresa atualizado de 11–50 para 51–200.” Faça cada entrada clicável para ver detalhes.
Forneça sugestões de merge quando duplicatas forem detectadas. Exiba os dois (ou mais) registros candidatos lado a lado com o registro “sobrevivente” recomendado e uma prévia do resultado do merge.
Trabalho em lote que corresponda às operações reais
A maioria dos times trabalha em lotes. Inclua ações em massa como:
- Enriquecer registros selecionados (ou enfileirar para processamento noturno)
- Aprovar/rejeitar merges sugeridos
- Exportar resultados (CSV) para auditoria ou revisão offline
Use uma etapa de confirmação clara para ações destrutivas (merge, sobrescrever) com uma janela de “undo” quando possível.
Busca rápida, filtros e proveniência por campo
Adicione busca global e filtros por e-mail, domínio, empresa, status e score de qualidade.
Permita que usuários salvem views como “Precisa de revisão” ou “Atualizações de baixa confiança”.
Para cada campo enriquecido, mostre proveniência: fonte, timestamp e confiança.
Um painel simples “Por que esse valor?” constrói confiança e reduz idas-e-vindas.
Workflows guiados para usuários não técnicos
Mantenha decisões binárias e guiadas: “Aceitar valor sugerido”, “Manter existente” ou “Editar manualmente”. Se precisar de controle mais profundo, deixe-o numa aba “Avançado”, em vez de padrão.
Segurança, privacidade e noções básicas de conformidade
Leve-o aos usuários
Faça o deploy e hospede seu novo app, depois adicione um domínio personalizado quando estiver pronto para produção.
Apps de enriquecimento tocam identificadores sensíveis (e-mails, telefones, dados de empresas) e frequentemente puxam dados de terceiros. Trate segurança e privacidade como recursos centrais, não tarefas “para depois”.
Controle de acesso baseado em papéis (RBAC)
Comece com papéis claros e privilégios mínimos:
- Admin: gerencia usuários, papéis, conectores, políticas de retenção
- Ops: roda jobs de enriquecimento, resolve conflitos, aprova merges
- Viewer: acesso somente leitura para relatórios e suporte
Mantenha permissões granulares (ex.: “exportar dados”, “ver PII”, “aprovar merges”) e separe ambientes para que dados de produção não estejam disponíveis em dev.
Proteja dados sensíveis
Use TLS em todo o tráfego e criptografia em repouso para bancos e object storage.
Armazene chaves de API em um secrets manager (não em arquivos/variáveis em controle de versão), rode trocas periodicamente e escopo chaves por ambiente.
Se você exibe PII na UI, adote padrões seguros como mascarar campos (ex.: mostrar os 2–4 últimos dígitos) e exigir permissão explícita para revelar valores completos.
Consentimento e restrições de uso dos dados
Se o enriquecimento depende de consentimento ou termos contratuais, codifique essas restrições no workflow:
- Rastreie fonte dos dados, propósito e usos permitidos por campo
- Documente o que você armazena e por quê (uma página interna curta como /privacy ou /docs/data-handling ajuda)
- Evite coletar campos desnecessários — menos dados reduzem risco
Auditoria, retenção e exclusão
Crie trilhas de auditoria tanto para acesso quanto para mudanças:
- Log de quem visualizou/exportou registros
- Log de quem mudou o quê e quando (valores antes/depois, job ID, provedor de enriquecimento)
Finalmente, suporte requests de privacidade com ferramentas práticas: políticas de retenção, exclusão de registros e workflows de “esquecimento” que também removam cópias em logs, caches e backups quando viável (ou as marquem para expiração).
Monitoramento, analytics e controles operacionais
Monitoramento não é só uptime — é como você mantém o enriquecimento confiável à medida que volumes, provedores e regras mudam.
Trate cada execução de enriquecimento como um job mensurável com sinais claros que você pode analisar ao longo do tempo.
Métricas que realmente ajudam
Comece com um pequeno conjunto de métricas operacionais ligadas a resultados:
- Throughput de jobs (registros/min) e tempo para completar por execução
- Taxa de sucesso vs taxa de falha, separadas por tipo de falha (validação, matching, provedor)
- Latência dos provedores (p50/p95) e timeouts por fonte de enriquecimento
- Taxa de match (com que frequência você conecta enriquecimento com confiança)
- Duplicatas evitadas (quantos merges incorretos foram prevenidos)
Esses números respondem rapidamente: “Estamos melhorando os dados ou apenas movendo-os?”
Alertas e guardrails
Adicione alertas que disparem por mudança, não por ruído:
- Picos em falhas ou registros em quarentena
- Backlogs na fila ou consumidores lentos (sinal de pipeline travado)
- Explosões de erro de provedores (429/5xx), latência elevada ou timeouts crescentes
Vincule alertas a ações concretas, como pausar um provedor, reduzir concorrência ou alternar para dados em cache/obsoletos.
Painel administrativo para operadores
Forneça uma visão admin das execuções recentes: status, contagens, retries e uma lista de registros em quarentena com razões.
Inclua controles de “replay” e ações em massa seguras (retentar timeouts de provedores, re-executar apenas matching).
Rastreabilidade com logs
Use logs estruturados e um correlation ID que acompanhe um registro de ponta a ponta (ingestão → match → enriquecimento → merge).
Isso torna suporte ao cliente e debugging de incidentes muito mais rápidos.
Playbooks de incidente e rollback
Escreva playbooks curtos: o que fazer quando um provedor degrada, quando a taxa de match colapsa ou quando duplicatas escapam.
Mantenha uma opção de rollback (ex.: reverter merges por uma janela de tempo) e documente em /runbooks.
Testes, rollout e plano de iteração
Testes e rollout são onde um app de enriquecimento se torna seguro de confiar. O objetivo não é “mais testes” — é confiança de que matching, merge e validação se comportam de forma previsível com dados do mundo real.
Teste as partes de maior risco primeiro
Priorize testes em lógica que pode danificar registros silenciosamente:
- Regras de matching: testes unitários para matches exatos, fuzzy e compostos (ex.: e-mail + domínio). Inclua near-duplicates e campos trocados.
- Resultados de merge: teste precedência de campo (prioridade de fonte), tratamento de conflitos e regras de “não sobrescrever”.
- Edge cases de validação: e-mails malformados, formatos internacionais de telefone, falta de país, identificadores duplicados e valores “desconhecidos”.
Use datasets sintéticos (nomes, domínios, endereços gerados) para validar precisão sem expor dados reais de clientes.
Mantenha um “golden set” versionado com outputs esperados de match/merge para detectar regressões.
Estageamento do rollout para reduzir blast radius
Comece pequeno e expanda:
- Piloto: um time ou um segmento (ex.: apenas SMB leads)
- Ações limitadas: comece com “atualizações sugeridas” que exigem aprovação antes de escrever no CRM
- Ramp-up: aumente volume e então habilite writes automáticos para campos de baixo risco
Defina métricas de sucesso antes de começar (precisão de match, taxa de aprovação, redução de edições manuais e tempo para enriquecer).
Documente fluxos e checklist de integração
Crie docs curtos para usuários e integradores (link no seu produto ou em /pricing se você restringe features). Inclua um checklist de integração:
- Método de auth da API, limites de taxa e comportamento de retry
- Campos obrigatórios para requests de enriquecimento
- Payloads de webhooks/eventos (e versionamento)
- Códigos de erro e regras de “enriquecimento parcial”
- Expectativas de log de auditoria e retenção de dados
Para melhoria contínua, agende revisões leves: analise validações falhadas, overrides manuais frequentes e mismatches, então atualize regras e adicione testes.
Uma referência prática para apertar regras: /blog/data-quality-checklist.
Construir vs acelerar: uma nota prática
Se você já conhece workflows-alvo mas quer encurtar tempo de spec → app funcional, considere usar Koder.ai para gerar uma implementação inicial (UI React, serviços em Go, armazenamento PostgreSQL) a partir de um plano estruturado por chat.
Times frequentemente usam essa abordagem para levantar a UI de revisão, processamento de jobs e histórico de auditoria rapidamente — depois iteram com modo de planejamento, snapshots e rollback conforme requisitos evoluem. Quando precisar de controle total, exporte o código-fonte e continue no pipeline existente. Koder.ai oferece planos free, pro, business e enterprise, que ajudam a equilibrar experimentação vs produção.