26 de jul. de 2025·8 min
Como construir um web app para rastrear exceções de processos de negócio
Aprenda os passos para projetar, construir e lançar um web app que registra, roteia e resolve exceções de processos de negócio com workflows claros e relatórios.
O que são exceções de processo de negócio (e por que rastreá‑las)
Uma exceção de processo de negócio é qualquer coisa que quebre o “caminho feliz” de um fluxo de trabalho rotineiro — um evento que precisa de atenção humana porque as regras padrão não cobriram o caso, ou porque algo deu errado.
Pense em exceções como o equivalente operacional de “edge cases”, mas para o trabalho cotidiano da empresa.
Exemplos familiares
Exceções aparecem em quase todos os departamentos:
- Divergência na fatura: o total da fatura não bate com a ordem de compra, as quantidades diferem ou um item da linha está faltando.
- Aprovação faltante: um contrato é executado sem a assinatura correta, ou uma despesa é submetida acima do limite sem aprovação.
- Remessa atrasada: a entrega não chegou na data prometida, chegou parcialmente ou foi enviada a SKU errada.
Isso não é “raro”. É comum — e causa atrasos, retrabalho e frustração quando você não tem uma forma clara de capturar e resolver os casos.
Por que planilhas e threads de e‑mail falham
Muitas equipes começam com uma planilha compartilhada mais e‑mails ou mensagens de chat. Funciona — até que não funcione mais.
Uma linha de planilha pode dizer o que aconteceu, mas costuma perder o resto:
- Contexto perdido: detalhes chave ficam em caixas de entrada (prints, respostas de fornecedores, aprovações), não anexados ao registro.
- Sem responsabilidade clara: as pessoas supõem que outra está lidando com o caso, especialmente quando exceções cruzam equipes.
- Histórico fraco: é difícil ver quem mudou o quê e por quê, o que importa quando surgem perguntas depois.
Com o tempo, a planilha vira um amontoado de atualizações parciais, entradas duplicadas e campos de “status” que ninguém confia.
O que você ganha ao rastrear exceções corretamente
Um aplicativo simples de rastreamento de exceções (um registro de incidentes/problemas adaptado ao seu processo) gera valor operacional imediato:
- Resolução mais rápida: a pessoa certa é notificada, as informações de suporte ficam com a exceção e o status é visível.
- Menos recorrência: padrões emergem (mesmo fornecedor, mesma etapa, mesma lacuna de aprovação), permitindo corrigir causas raízes.
- Responsabilidade clara: cada exceção tem um responsável, prazos (SLA/objetivos) e um resultado documentado.
Defina expectativas: comece simples e itere
Você não precisa de um fluxo perfeito no primeiro dia. Comece capturando o básico — o que aconteceu, quem é o responsável, status atual e próximo passo — e depois evolua campos, roteamento e relatórios conforme aprende quais exceções se repetem e quais dados realmente orientam decisões.
Defina usuários, escopo e métricas de sucesso
Antes de rascunhar telas ou escolher ferramentas, tenha clareza sobre quem o app atende, o que ele cobrirá na versão 1 e como você saberá que está funcionando. Isso evita que um “app de rastreamento de exceções” vire um sistema genérico de tickets.
Identifique os papéis principais
A maioria dos fluxos de exceção precisa de alguns atores claros:
- Solicitante: registra a exceção e fornece contexto (o que aconteceu, quando, impacto).
- Aprovador: decide se a exceção é aceitável e sob quais condições.
- Executor / Resolver: corrige o problema, aplica o workaround ou atualiza os dados.
- Dono do processo: responsável pelo processo subjacente e por ações de prevenção.
- Auditor/visualizador: acesso somente leitura para fiscalização e conformidade.
Para cada papel, descreva 2–3 permissões chave (criar, aprovar, reatribuir, fechar, exportar) e as decisões pelas quais são responsáveis.
Esclareça os objetivos
Mantenha os objetivos práticos e observáveis. Objetivos comuns incluem:
- Capturar exceções de forma consistente (mesmo conjunto mínimo de dados sempre).
- Atribuir responsabilidade clara para que nada fique sem tratamento.
- Documentar decisões (por que uma exceção foi aprovada/negada e por quem).
- Reduzir recorrências rastreando causa raiz e ações de prevenção.
Decida o escopo da v1
Escolha 1–2 fluxos de alto volume onde exceções ocorrem com frequência e o custo do atraso é real (por exemplo, divergências em faturas, retenção de pedidos, onboarding com documentos faltantes). Evite começar com “todos os processos de negócio”. Um escopo estreito permite padronizar categorias, status e regras de aprovação mais rapidamente.
Escreva 3–5 métricas de sucesso
Defina métricas que você possa medir desde o primeiro dia:
- Tempo de resolução (mediana e % dentro do SLA)
- Taxa de reabertura (qualidade do encerramento)
- Volume de exceções por tipo (principais causadores)
- Tempo do ciclo de aprovação (solicitação → decisão)
- Exceções recorrentes ligadas à mesma causa raiz
Essas métricas viram sua linha de base para iteração e justificam automações futuras.
Mapeie o ciclo de vida da exceção e os status
Um ciclo de vida claro mantém todos alinhados sobre onde está uma exceção, quem é o responsável e o que deve acontecer a seguir. Mantenha os status poucos, inequívocos e ligados a ações reais.
Um ciclo de vida prático por padrão
Criada → Triagem → Revisão → Decisão → Resolução → Fechada
- Criada: uma exceção é registrada com os detalhes mínimos necessários.
- Triagem: alguém valida, atribui um responsável e define a urgência.
- Revisão: a equipe certa coleta evidências e avalia opções.
- Decisão: aprovar/negar a exceção (ou solicitar alterações) com justificativa registrada.
- Resolução: a ação corretiva é executada e verificada.
- Fechada: o registro é finalizado para relatórios e auditoria.
Defina “pronto” com critérios de entrada/saída
Documente o que precisa ser verdadeiro para entrar e sair de cada etapa:
- Criada (saída): campos obrigatórios preenchidos; categoria selecionada; solicitante identificado.
- Triagem (saída): responsável atribuído; impacto + data de vencimento definidos; duplicatas verificadas.
- Revisão (saída): evidências anexadas; stakeholders consultados; recomendação documentada.
- Decisão (saída): decisão registrada; aprovador identificado; condições (se houver) capturadas.
- Resolução (saída): ações concluídas; resultado validado; SLA cumprido ou motivo de violação registrado.
- Fechada (saída): notas finais adicionadas; sem tarefas abertas; trilha de auditoria completa.
Regras de escalonamento que previnem estagnação
Adicione escalonamento automático quando uma exceção estiver atrasada (além do prazo/SLA), bloqueada (dependência externa demorando demais) ou de alto impacto (acima de um limiar de severidade). Escalonamento pode significar: notificar um gerente, reencaminhar para um nível superior de aprovação ou aumentar a prioridade.
Reabertura e tratamento de duplicatas
- Reabrir quando a mesma exceção reaparecer (por exemplo, correção falhou). Exigir uma razão e enviar de volta para Triagem ou Revisão.
- Duplicata quando dois registros descrevem o mesmo problema subjacente. Marcar um como “primário”, vincular as duplicatas e fechar as duplicatas com um resultado “Mesclado” para que relatórios permaneçam precisos.
Projete o modelo de dados e os campos necessários
Um bom app de rastreamento de exceções depende do modelo de dados. Se a estrutura for muito solta, o relatório vira coisa de sorte. Se for excessivamente rígida, os usuários não preencherão de forma consistente. Mire em um conjunto pequeno de campos obrigatórios e um conjunto maior de campos opcionais bem definidos.
Entidades centrais a incluir
Comece com alguns registros centrais que cobrem a maioria dos cenários reais:
- Exceção: o registro principal (o que aconteceu, onde e o que precisa ser resolvido).
- Comentário: discussões, esclarecimentos e atualizações de progresso.
- Anexo: screenshots, PDFs, e‑mails, exports.
- Tarefa: ações discretas atribuídas a responsáveis específicos.
- Decisão: aprovações/negações, exceções de política ou registros de fechamento.
- Categoria: lista controlada que mantém os relatórios limpos.
- Usuário: solicitantes, responsáveis, aprovadores e visualizadores.
Campos obrigatórios (mantenha curtos)
Torne obrigatórios, em cada Exceção:
- Título e descrição (em linguagem simples: o que aconteceu e por que importa)
- Categoria
- Impacto (por exemplo, financeiro, cliente, conformidade, operacional)
- Área do processo (por exemplo, faturamento, atendimento, devoluções)
- Data de vencimento (ou data alvo de resolução)
Valores estruturados que você deve padronizar
Use valores controlados em vez de texto livre para:
- Status (Criada, Triagem, Revisão, Decisão, Resolução, Fechada)
- Prioridade (Baixa/Média/Alta/Crítica)
- Causa raiz (Erro humano, defeito do sistema, falta de dados, problema com fornecedor, política pouco clara)
- Tipo de resolução (Dados corrigidos, reembolso emitido, workaround, processo atualizado, treinamento, sem ação)
Vinculação e rastreabilidade
Planeje campos para conectar exceções a objetos de negócio reais:
- Referências de registros afetados (ID do pedido, ID da fatura, ID do cliente)
- IDs de sistemas externos (ticket ERP, caso CRM)
- Exceções relacionadas (duplicatas, padrões recorrentes, pai/filho)
Esses links facilitam identificar reincidências e construir relatórios precisos depois.
Planeje a experiência do usuário e as telas principais
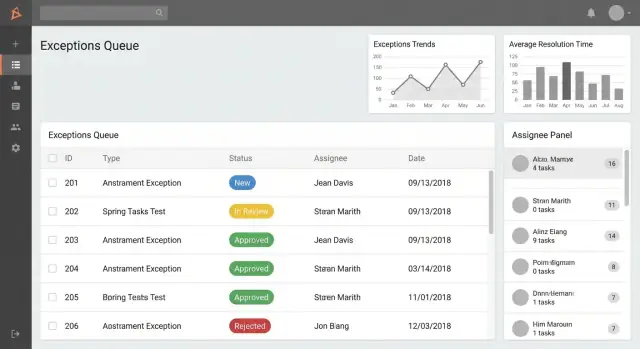
Um bom app de rastreamento de exceções parece uma caixa de entrada compartilhada: todos devem ver rapidamente o que precisa de atenção, o que está bloqueado e o que está atrasado. Comece projetando um pequeno conjunto de telas que cubram 90% do trabalho diário, depois adicione recursos avançados (relatórios, integrações) depois.
Telas principais para projetar primeiro
1) Lista / fila de exceções (tela inicial)
Aqui é onde os usuários vivem. Faça rápido, fácil de escanear e orientado para ação.
Crie filas baseadas em papel como:
- Minhas exceções (criadas por mim ou atribuídas a mim)
- Precisa da minha aprovação (itens aguardando decisão)
- Atrasadas (além do SLA ou data alvo)
Adicione busca e filtros que reflitam como as pessoas falam sobre o trabalho:
- Status, categoria, área do processo
- Intervalo de datas (criado, vencimento, fechado)
- Responsável / equipe
2) Formulário de criação de exceção
Mantenha o primeiro passo leve: poucos campos obrigatórios, com detalhes opcionais em “Mais”. Considere salvar rascunhos e permitir valores “desconhecido” (por exemplo, “responsável a definir”) para evitar gambiarras.
3) Página de detalhe da exceção
Deve responder “O que aconteceu? Qual o próximo passo? Quem é o responsável?” Inclua:
- Resumo, status, responsável, data de vencimento/SLA
- Ações principais claras (Atribuir, Solicitar aprovação, Fechar)
- Painel lateral para metadados chave
Colaboração básica (sem virar chat)
Inclua:
- Comentários com @menções para chamar as pessoas certas
- Anexos para evidências (screenshots, PDFs)
- Uma linha do tempo de atividade que registre mudanças (atualizações de status, reatribuições, aprovações) para que os usuários não precisem perguntar “quem mudou isso?”
Configurações de admin (mínimas, mas necessárias)
Forneça uma pequena área de admin para gerenciar categorias, áreas de processo, metas de SLA e regras de notificação — assim operações podem evoluir o app sem redeploy.
Escolha uma abordagem técnica e arquitetura
Crie um rastreador de exceções
Crie seu rastreador de exceções no Koder.ai via chat simples e itere com segurança.
Aqui você equilibra velocidade, flexibilidade e manutenibilidade a longo prazo. A “resposta certa” depende de quão complexo é o ciclo de exceção, quantas equipes usarão a ferramenta e quão rigorosos são os requisitos de auditoria.
Três abordagens práticas de construção
1) Build customizado (controle total). Você constrói UI, API, banco de dados e integrações do zero. Ideal quando precisa de workflows sob medida (roteamento, SLAs, trilha de auditoria, integrações ERP/ticketing) e espera evoluir o processo. O tradeoff é custo inicial maior e necessidade de suporte de engenharia contínuo.
2) Low‑code (lançamento mais rápido). Plataformas de construtor interno produzem formulários, tabelas e aprovações básicas rapidamente. Ideal para piloto ou implantação em um único departamento. Tradeoff: limites em permissões complexas, relatórios customizados, performance em escala ou portabilidade de dados.
3) Vibe‑coding / construção assistida por agentes (iteração rápida com código real). Se quiser velocidade sem perder uma base de código mantível, plataformas como Koder.ai ajudam a criar um web app funcional a partir de uma especificação em conversação — e exportar o código‑fonte quando precisar de controle total. Times costumam gerar a UI React e um backend Go + PostgreSQL rapidamente, iterar em “modo planejamento” e usar snapshots/rollback enquanto o workflow se estabiliza.
Uma arquitetura simples e escalável
Busque separação clara de responsabilidades:
- UI web para usuários submeterem, revisarem e resolverem exceções
- API que aplique validações, permissões e regras de workflow
- Banco de dados que armazene exceções, comentários, metadados de anexos, decisões, tarefas e eventos de auditoria
- Jobs em background para notificações, escalonamentos, timers de SLA e relatórios agendados
Essa estrutura permanece compreensível à medida que o app cresce e facilita adicionar integrações depois.
Hospedagem e ambientes
Planeje ao menos dev → staging → prod. O staging deve espelhar prod (especialmente autenticação e e‑mail) para testar roteamento, SLAs e relatórios com segurança antes do release.
Se quer reduzir overhead operacional no início, considere uma plataforma que inclua deploy e hospedagem embutidos (Koder.ai, por exemplo, suporta deploy/hosting, domínios customizados e regiões AWS globais) — e reavalie uma configuração bespoke quando o fluxo estiver provado.
Custos e tradeoffs de complexidade
Low‑code reduz tempo até a primeira versão, mas necessidades de customização e compliance podem aumentar custos depois (gambiarras, add‑ons, restrições do fornecedor). Builds customizados custam mais inicialmente, mas podem sair mais baratos ao longo do tempo se o manejo de exceções for central para as operações. Um caminho intermediário — lançar rápido, validar o fluxo e manter um plano de migração claro (por exemplo, exportação de código) — frequentemente oferece melhor relação custo/controle.
Configure autenticação, papéis e controle de acesso
Registros de exceção frequentemente contêm dados sensíveis (nomes de clientes, ajustes financeiros, violações de política). Se o acesso for muito aberto, há risco de privacidade e “edições sombra” que minam a confiança no sistema.
Login e sessões seguras
Comece com autenticação comprovada em vez de construir gerenciamento de senhas. Se a organização já tem um provedor de identidade, use SSO (SAML/OIDC) para que usuários façam login com a conta corporativa e você herde controles como MFA e offboarding.
Independente de SSO ou login por e‑mail, trate sessões como recurso crítico: sessões de curta duração, cookies seguros, proteção CSRF para apps de navegador e logout automático por inatividade para papéis de alto risco. Também registre eventos de autenticação (login, logout, tentativas falhas) para investigar atividades incomuns.
Papéis e permissões (o que cada pessoa pode fazer)
Defina papéis em termos de negócio e vincule‑os a ações no app. Pontos iniciais típicos:
- Solicitante: criar exceções, adicionar notas/anexos, ver itens próprios
- Responsável/Executor: editar campos, propor resolução, atualizar status
- Aprovador/Gerente: aprovar ou rejeitar, pedir mais info, fechar itens
- Admin: configurar o sistema (não o processamento do dia a dia)
Seja explícito sobre quem pode deletar. Muitas equipes desativam deleções permanentes e permitem apenas arquivamento por admins, preservando o histórico.
Acesso por registro (quem vê quais exceções)
Além de papéis, adicione regras que limitem visibilidade por departamento, equipe, localidade ou área do processo. Padrões comuns:
- Usuários veem itens que criaram e itens atribuídos à sua equipe
- Gerentes veem todos os itens dentro de sua unidade organizacional
- Funções de compliance/auditoria veem transversalmente, em modo somente leitura
Isso evita “navegação aberta” e ainda permite colaboração.
Capacidades de admin necessárias
Admins devem poder gerenciar categorias e subcategorias, regras de SLA (prazos, limiares de escalonamento), templates de notificação e atribuições de papéis. Mantenha ações de admin auditáveis e peça confirmação elevada para mudanças de grande impacto (como edição de SLAs), pois essas configurações afetam relatórios e responsabilidade.
Construa workflows, roteamento e notificações
Mapeie o ciclo de vida das exceções
Use o modo de planejamento do Koder.ai para mapear de Criado a Fechado e gerar a interface e o backend.
Workflows transformam um simples “registro” em um app de exceção no qual as pessoas confiam. O objetivo é movimento previsível: cada exceção deve ter um responsável claro, próximo passo e prazo.
Regras de roteamento: quem recebe o quê e quando
Comece com um pequeno conjunto de regras fáceis de explicar. Você pode rotear por:
- Categoria (ex.: qualidade de dados, desvio de política, queda de sistema)
- Impacto (valor financeiro, número de clientes afetados, severidade)
- Área do processo (AP/AR, onboarding, atendimento)
- Limiares (por exemplo, “Valor > $10.000” ou “Alta severidade”)
Mantenha regras determinísticas: se várias regras combinarem, defina uma ordem de prioridade. Inclua também um fallback seguro (por exemplo, rotear para uma fila “Triagem de Exceções”) para que nada fique sem atribuição.
Aprovações: simples, multi‑etapa e overrides
Muitas exceções precisam de aprovação antes de serem aceitas, remediadas ou fechadas.
Projete para dois padrões comuns:
- Aprovador único: uma pessoa aprova/nega (mais rápido de implementar).
- Aprovação multi‑etapa: sequência como Gerente → Compliance → Financeiro.
Se overrides forem permitidos, deixe explícito quem pode fazê‑los (e em quais condições). Ao permitir override, exija uma razão e registre‑a na trilha de auditoria (por exemplo: “Aprovado por override devido a risco de SLA”).
Notificações que não viram ruído
Adicione e‑mail e notificações in‑app para momentos que alteram propriedade ou urgência:
- Atribuição e reatribuição
- Novos comentários ou menções
- Pedido de aprovação / aprovado / rejeitado
- Itens atrasados e lembretes de “vencendo em breve”
Permita que usuários controlem notificações opcionais, mas mantenha críticas (atribuição, atraso) ativadas por padrão.
Torne a resolução visível com tarefas/checklists
Exceções falham frequentemente porque o trabalho ocorre “por fora”. Adicione tarefas ou checklists leves vinculados à exceção: cada tarefa tem dono, data de vencimento e status. Isso torna o progresso mensurável, melhora a passagem de bastão e dá aos gestores uma visão em tempo real do que bloqueia o fechamento.
Adicione relatórios e dashboards operacionais
Relatórios são onde um app de exceção deixa de ser um “registro” e vira uma ferramenta operacional. O objetivo é ajudar líderes a detectar padrões cedo e equipes a decidir o que trabalhar a seguir — sem abrir cada registro.
Relatórios padrão a incluir
Comece com um conjunto pequeno de relatórios que respondam perguntas comuns de forma confiável:
- Volume ao longo do tempo (diário/semanal/mensal): as exceções estão subindo, caindo ou sazonais?
- Por categoria/causa: quais tipos geram mais impacto?
- Por equipe/responsável: onde a carga está concentrada?
- Por status: quanto está em cada etapa (Criada, Triagem, Revisão, Decisão, Resolução, Fechada)?
Mantenha os gráficos simples (linhas para tendências, barras para quebras). O principal valor é consistência — os usuários devem confiar que o relatório bate com o que veem na lista de exceções.
Monitoramento de performance e SLA
Adicione métricas operacionais que reflitam saúde do serviço:
- Tempo médio de resolução (e mediana, se possível)
- Taxa de violação de SLA (percentual de exceções que excederam a meta)
- Tamanho do backlog (exceções abertas) e aging (há quanto tempo itens estão abertos)
Se você armazenar timestamps como created_at, assigned_at e resolved_at, essas métricas ficam diretas e explicáveis.
Drill‑down, exportações e resumos agendados
Cada gráfico deve suportar drill‑down: clicar em uma barra ou segmento leva o usuário à lista filtrada de exceções (por exemplo, “Categoria = Remessa, Status = Aberto”). Isso mantém dashboards acionáveis.
Para compartilhar e analisar offline, forneça exportação CSV tanto da lista quanto dos relatórios-chave. Se stakeholders quiserem visibilidade regular, adicione resumos agendados (digest semanal por e‑mail ou in‑app) que destacam mudanças de tendência, principais categorias e violações de SLA, com links de volta às views filtradas (ex.: /exceptions?status=open&category=shipping).
Garanta auditabilidade e requisitos básicos de compliance
Se seu app influencia aprovações, pagamentos, resultados para clientes ou relatórios regulatórios, você precisará responder: “Quem fez o quê, quando e por quê?” Construir auditabilidade desde o início evita retrabalhos dolorosos e dá confiança de que o registro é confiável.
Capture um log de atividades incontestável
Crie um log completo de atividade para cada exceção. Registre o ator (usuário ou sistema), timestamp (com timezone), tipo de ação (criado, campo alterado, transição de status) e valores antes/depois.
Mantenha o log append‑only. Edições devem adicionar novos eventos em vez de sobrescrever o histórico. Se for preciso corrigir um erro, registre um evento de “correção” com explicação.
Armazene decisões com razões e evidências
Aprovações e negações devem ser eventos de primeira classe, não apenas uma mudança de status. Capture:
- Decisão (aprovado/negado/devolvido)
- Código de razão + nota em texto livre (obrigatória para decisões chave)
- Anexos (prints, PDFs, e‑mails) e quem os enviou
Isso acelera revisões e reduz idas e vindas quando alguém pergunta por que uma exceção foi aceita.
Regras de retenção e exclusão (defina intencionalmente)
Defina por quanto tempo exceções, anexos e logs são retidos. Para muitas organizações, um padrão seguro é:
- Reter registros e eventos de auditoria por período fixo (ex.: 3–7 anos)
- Restringir exclusão a um grupo pequeno de admins, com justificativa obrigatória
- Preferir “soft delete” (oculto das views normais) mantendo a trilha de auditoria intacta
Alinhe a política à governança interna e a quaisquer requisitos legais.
Projete para revisões e auditorias
Auditores e revisores de compliance precisam de velocidade e clareza. Adicione filtros pensados para auditoria: por intervalo de datas, responsável/equipe, status, códigos de razão, violação de SLA e resultados de aprovação.
Forneça resumos imprimíveis e relatórios exportáveis que incluam o histórico imutável (linha do tempo de eventos, notas de decisão e lista de anexos). Uma boa regra: se você não consegue reconstruir a história completa a partir do registro e seu log, o sistema não está pronto para auditoria.
Teste, pilote e faça rollout
Torne as decisões auditáveis
Comece com registros de atividade, notas de decisão e anexos para facilitar as revisões.
Testes e rollout são onde um app de exceção deixa de ser “boa ideia” e vira ferramenta confiável. Foque nos fluxos que acontecem todo dia e depois amplie.
Teste os fluxos chave de ponta a ponta
Crie um roteiro de testes simples (uma planilha serve) que percorra todo o ciclo:
- Criar uma exceção, anexar um arquivo e confirmar que campos obrigatórios são exigidos.
- Atribuir à pessoa/equipe correta e verificar que ela vê imediatamente.
- Caminhos de aprovar e rejeitar: confirme que cada decisão captura razão e timestamp.
- Fechar a exceção e confirmar que fica somente leitura (ou edição limitada) como pretendido.
- Reabrir e garantir que o histórico/trilha mostre claramente o que mudou.
Inclua variações “da vida real”: mudança de prioridade, reatribuições e itens atrasados para validar cálculos de SLA e tempo de resolução.
Adicione validação e tratamento de erros que evitem dados ruins
A maioria dos problemas de relatório vem de entradas inconsistentes. Coloque guardrails cedo:
- Campos obrigatórios (ex.: área do processo, tipo de exceção, responsável, data de vencimento).
- Limites de upload de arquivos (tamanho/tipo) com mensagens claras.
- Detecção de duplicatas (ex.: mesmo cliente/pedido/data) com opção “vincular ao existente”.
- Tratamento seguro de casos extremos: responsável ausente, datas inválidas, usuários deletados.
Também teste caminhos de erro: interrupções de rede, sessões expiradas e erros de permissão.
Execute um piloto com uma equipe primeiro
Escolha uma equipe com volume suficiente para aprender rápido, mas pequena o bastante para ajustar rápido. Pilote por 2–4 semanas e então revise:
- Os campos estão capturando o que as pessoas realmente precisam?
- Os status batem com a maneira como o trabalho acontece?
- As notificações são úteis ou barulhentas?
Faça mudanças semanalmente, mas congele o workflow na última semana para estabilizar.
Lance com um kit de lançamento enxuto
Mantenha o rollout simples:
- Uma página “Como usamos o app” (status, regras de responsabilidade, SLAs)
- Treinamento curto (15–30 minutos) e gravação
- Checklist de lançamento: acessos/papéis, roteamento padrão, templates e contato de suporte
Após o lançamento, monitore adoção e saúde do backlog diariamente na primeira semana e depois semanalmente.
Mantenha, melhore e escale ao longo do tempo
Lançar o app é o começo do trabalho real: manter o registro de exceções preciso, rápido e alinhado ao jeito que o negócio opera.
Monitore uso e gargalos
Trate o fluxo de exceções como um pipeline operacional. Reveja onde os itens estagnam (por status, equipe e responsável), quais categorias dominam o volume e se SLAs são realistas.
Uma checagem mensal simples costuma bastar:
- Tempo de resolução mediano e 90º percentil por categoria
- Contagens por aging (aberto > 7/30/60 dias)
- Taxas de reabertura e ciclos de “enviado de volta”
- Campos mais frequentemente vazios (sinal de fricção UX)
Use esses dados para ajustar definições de status, campos obrigatórios e regras de roteamento — sem acrescentar complexidade o tempo todo.
Mantenha um backlog de iteração
Crie um backlog leve que capture pedidos de operadores, aprovadores e compliance. Itens típicos:
- Novos campos (só quando relatórios ou decisões realmente precisarem)
- Automações (autoatribuição por categoria, padrões de data de vencimento)
- Templates para tipos comuns de exceção
- Pequenos consertos de UI que reduzem má classificação
Priorize mudanças que reduzam tempo de ciclo ou previnam exceções recorrentes.
Integrações: comece seguro, depois aprofunde
Integrações multiplicam valor, mas aumentam risco e manutenção. Comece com links somente leitura:
- Armazene IDs de registros externos (ERP/CRM/ticketing)
- Deep‑links para o sistema fonte (ex.: pedido, cliente, fatura)
Quando estável, passe para write‑backs seletivos (atualização de status, comentários) e sincronização baseada em eventos.
Defina propriedade clara
Atribua donos para as partes que mudam mais:
- Taxonomia de categorias (quando mesclar/aposentar)
- Definições de SLA e regras de escalonamento
- Regras de workflow/roteamento e políticas de notificação
Com propriedade explícita, o app permanece confiável à medida que o volume cresce e as equipes se reorganizam.
Uma nota sobre manter alta velocidade de entrega
Rastreamento de exceções raramente fica “pronto” — evolui à medida que as equipes aprendem o que deve ser evitado, automatizado ou escalado. Se espera mudanças frequentes de workflow, escolha uma abordagem que torne a iteração segura (feature flags, staging, rollback) e mantenha você no controle de código e dados. Plataformas como Koder.ai costumam ser usadas para entregar a versão inicial rápido (planos Free/Pro bastam para pilotos) e depois crescer para Business/Enterprise conforme governança, controle de acesso e requisitos de deployment ficarem mais rigorosos.