Esclareça o Caso de Uso e as Métricas de Sucesso
Antes de desenhar telas ou escolher stack, defina com precisão o problema que você resolve. Um app de dependências falha quando vira “mais um lugar para atualizar”, enquanto a dor real—surpresas e entregas atrasadas entre equipes—continua.
Defina o problema central
Comece com uma frase simples que você repita em todas as reuniões:
Dependências cross‑funcionais estão causando atrasos e surpresas de última hora porque propriedade, cronograma e status não estão claros.
Torne isso específico para sua organização: quais times são mais afetados, que tipos de trabalho ficam bloqueados e onde vocês perdem tempo hoje (handoffs, aprovações, entregáveis, acesso a dados etc.).
Identifique os usuários-alvo (e o que precisam)
Liste os usuários principais e como usarão o app:
- Gerentes de projeto: precisam de uma visão confiável de bloqueios futuros e do que escalar.
- Líderes de time: precisam de clareza sobre o que seu time deve, até quando, e os trade‑offs.
- Sponsors executivos: precisam de visão de risco em alto nível e prestação de contas.
- Contribuintes individuais (ICs): precisam de pedidos acionáveis, contexto e prazos.
Capture os principais jobs-to-be-done
Mantenha os “jobs” curtos e testáveis:
- Descobrir dependências cedo (no planejamento, não só na entrega).
- Criar pedidos de dependência com escopo e datas claras.
- Validar (aceitar/rejeitar) com prazos negociados.
- Rastrear progresso e mudanças ao longo do tempo.
- Escalar quando o risco aumenta ou compromissos falham.
Decida o que “dependência” significa aqui
Escreva uma definição de um parágrafo. Exemplos: um handoff (Time A fornece dados), uma aprovação (assinado pelo Jurídico), ou um entregável (especificação de design). Essa definição vira seu modelo de dados e a espinha dorsal do fluxo de trabalho.
Defina métricas de sucesso
Escolha um pequeno conjunto de resultados mensuráveis:
- Menos bloqueios ativos por projeto (ou menos dependências “descobertas tarde”).
- Tempo médio menor de pedido → aceitação → entrega.
- Maior previsibilidade (menos deslocamentos de datas, maior taxa de entrega no prazo).
Se não der para medir, não dá pra provar que o app melhora a execução.
Mapeie Stakeholders e o Fluxo Atual
Antes de desenhar telas ou bancos, entenda quem participa das dependências e como o trabalho se movimenta. A gestão de dependências falha mais por expectativas desalinhadas do que por ferramenta ruim: “Quem é dono?”, “O que significa pronto?”, “Onde vemos status?”.
Encontre onde os dados de dependência vivem hoje
A informação costuma estar espalhada. Faça um inventário rápido e capture exemplos (prints ou links) de:
- Planilhas com “pedidos” e datas
- Tickets e épicos no Jira/Asana/Trello
- Docs e notas de reunião (Google Docs/Notion/Confluence)
- Threads no Slack/Teams onde decisões e promessas aparecem
Isso mostra quais campos as pessoas já usam (datas, links, prioridade) e o que falta (dono claro, critérios de aceitação, status).
Mapeie o fluxo de trabalho ponta a ponta
Escreva o fluxo atual em linguagem clara, tipicamente:
pedido → aceitar → entregar → verificar
Para cada passo, anote:
- Quem o aciona (papel/time, não pessoa)
- Que informação é necessária para avançar
- Onde está registrado hoje
- O que significa “completo” (e quem assina)
Identifique pontos de falha e rankeie dores
Procure padrões como donos pouco claros, datas faltando, status “silencioso” ou dependências descobertas tarde. Peça aos stakeholders para ranquear os cenários mais dolorosos (ex.: “aceito mas nunca entregue” vs. “entregue mas não verificado”). Otimize os 1–2 principais primeiro.
Escreva 5–8 user stories que reflitam a realidade, por exemplo:
- “Como PM solicitante, posso submeter uma dependência com data necessária e contexto para que o time responsável avalie.”
- “Como líder responsável, posso aceitar/rejeitar com uma data de compromisso para que expectativas fiquem explícitas.”
- “Como stakeholder, posso ver o status de relance para não ficar caçando atualizações em reuniões.”
Essas stories viram guardrails de escopo quando pedidos de features começarem a se acumular.
Desenhe o Modelo de Dados de Dependência
Um app de dependências nasce ou morre pela confiança nos dados. O objetivo do modelo é capturar quem precisa de quê, de quem, para quando, e manter um registro limpo de como compromissos mudam ao longo do tempo.
Registro central de dependência
Comece com uma entidade única “Dependência” que seja legível sozinha:
- Título: curto, específico (ex.: “Fornecer revisão jurídica para o texto de checkout atualizado”)
- Descrição: contexto, critérios de aceitação, links
- Tipo: lista controlada (ex.: revisão, entrega, aprovação, acesso a dados)
- Time responsável: time esperado para entregar
- Solicitante: pessoa ou time pedindo
Mantenha esses campos obrigatórios onde possível; campos opcionais tendem a ficar vazios.
Datas e compromissos
Dependências são sobre tempo, então armazene datas explicitamente e separadas:
- Data solicitada (data que o solicitante precisa)
- Data comprometida (data prometida pelo time responsável)
- Entregue em (data efetiva de conclusão)
- Janela de revisão (intervalo para validação/assinatura)
Essa separação evita discussões depois (“solicitado” ≠ “comprometido”).
Status e relacionamentos
Use um modelo de status simples: proposto → pendente → aceito → entregue, com exceções como em risco e rejeitado.
Modele relacionamentos como links one‑to‑many para que cada dependência possa conectar a:
- Projetos (uma dependência pode impactar várias iniciativas)
- Marcos (vincule a um checkpoint específico)
- Tickets (ex.: issues do Jira para execução)
Auditabilidade e confiança
Torne mudanças rastreáveis com:
- Criado/atualizado por
- Histórico de mudanças (atualizações campo a campo ao longo do tempo)
- Comentários (notas de decisão, esclarecimentos, aprovações)
Se acertar o rastro de auditoria cedo, evitará debates do tipo “ele disse/ela disse” e facilitará handoffs.
Modele Projetos, Marcos e Propriedade de Times
Um app de dependências só funciona se todo mundo concorda sobre o que é “projeto”, o que é “marco” e quem responde quando algo escapa. Mantenha o modelo simples o suficiente para que times realmente o mantenham.
Projetos e marcos: escolha a granularidade certa
Rastreie projetos no nível em que as pessoas planejam e reportam—normalmente uma iniciativa de semanas a meses com resultado claro. Evite criar um projeto para cada ticket; isso pertence às ferramentas de entrega.
Marcos devem ser poucos e significativos, checkpoints que desbloqueiam outros (ex.: “Contrato de API aprovado”, “Lançamento beta”, “Revisão de segurança concluída”). Se marcos ficarem muito detalhados, as atualizações viram tarefa e a qualidade dos dados cai.
Regra prática: projetos com 3–8 marcos, cada um com dono, data alvo e status. Se precisar de mais, considere reduzir o escopo do projeto.
Diretório de times: torne a propriedade descobrível
Dependências falham quando ninguém sabe com quem falar. Adicione um diretório leve com:
- Nome e função do time (ex.: Pagamentos, Plataforma de Dados, Jurídico)
- Contato primário (pessoa) e backup/on‑call
- Canal preferido (email, Slack, fila de tickets)
Esse diretório deve ser usável por parceiros não técnicos—mantenha campos legíveis e pesquisáveis.
Regras de propriedade: responsabilidade sem confusão
Decida se permite propriedade compartilhada. A regra mais limpa é:
- Um responsável por item/marco/dependência (uma pessoa)
- Colaboradores opcionais (muitas pessoas)
Se dois times realmente compartilham responsabilidade, modele como dois marcos (ou duas dependências) com handoff claro, em vez de itens “co‑responsáveis” que ninguém conduz.
Dependências cross‑projeto e rollups de programa
Represente dependências como links entre projeto/marco solicitante e projeto/marco provedor, com direção (“A precisa de B”). Isso permite visões de programa: você pode agregar por iniciativa, trimestre ou portfólio sem alterar o trabalho diário dos times.
Tags ajudam no slicing de relatórios sem forçar hierarquia. Comece com um conjunto pequeno e controlado:
- Área de produto
- Trimestre (ou janela de release)
- Nome da iniciativa/programa
- Prioridade (ex.: P0–P3)
Prefira dropdowns às entradas livres para evitar “Pagamentos”, “payments” e “paymnts” virarem categorias diferentes.
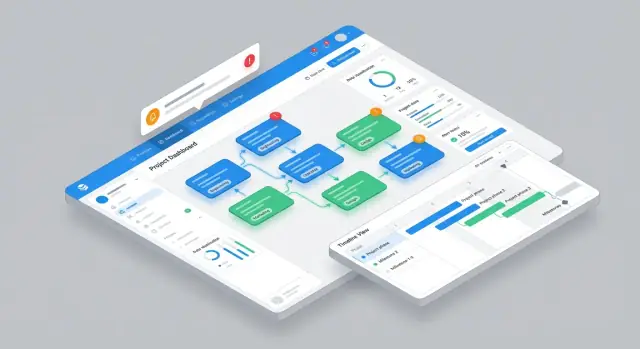
Planeje a UI e a Navegação Principais
Um app de dependências funciona quando as pessoas conseguem responder em segundos: “O que eu devo?” e “O que está me bloqueando?”. Projete a navegação em torno desses jobs-to-be-done, não dos objetos do banco.
Comece com quatro vistas centrais, cada uma otimizada para um momento na semana:
- Lista de dependências para triagem e ordenação (bom para check‑ins diários)
- Grafo de dependências para entender impacto upstream/downstream rapidamente
- Linha do tempo para detectar colisões de datas e handoffs que estão deslizando
- Caixa de entrada do time como landing default para contribuintes (“pedidos esperando por mim”)
Mantenha a navegação global mínima (ex.: Caixa de entrada, Dependências, Linha do tempo, Relatórios), e permita pular entre vistas sem perder filtros.
Criação rápida sem sacrificar clareza
Fazer uma dependência deve ser tão rápido quanto enviar uma mensagem. Forneça modelos (ex.: “Contrato de API”, “Revisão de design”, “Exportação de dados”) e um painel Adicionar rápido.
Exija apenas o necessário para rotear o trabalho: time solicitante, time responsável, data, descrição curta e status. O resto pode ser opcional ou exibido progressivamente.
Filtros, busca e vistas salvas
Pessoas vão viver em filtros. Suporte busca e filtros por time, intervalo de datas, risco, status, projeto, além de “atribuído a mim”. Permita salvar combinações comuns (“Meus lançamentos do Q1”, “Alto risco este mês”).
Acessibilidade e orientação em estados vazios
Use indicadores de risco legíveis em cores (ícone + rótulo, não apenas cor) e assegure navegação por teclado para criação, filtragem e atualização.
Estados vazios devem ensinar. Quando uma lista estiver vazia, mostre um exemplo curto de uma boa dependência:
“Time de Pagamentos: fornecer chaves sandbox para Checkout v2 até 14 de mar; necessário para início do QA mobile.”
Esse tipo de orientação melhora a qualidade dos dados sem adicionar processo.
Construa Workflows: Solicitar, Aceitar, Entregar, Fechar
Lançar a caixa de entrada da equipa
Crie uma vista da caixa de entrada da equipa para que cada colaborador saiba o que lhe está pendente.
Um bom sistema de dependências espelha como times colaboram—sem forçar reuniões longas. Desenhe o fluxo em poucos estados reconhecíveis e faça cada mudança responder: “O que acontece depois e quem é o dono?”
Fluxo de pedido: criar → rotear → aceitação
Comece com um formulário guiado “Criar dependência” que capture o mínimo para agir: projeto solicitante, resultado necessário, data alvo e impacto se perder. Depois roteie automaticamente para o time responsável com uma regra simples (dono do serviço/componente, diretório de times, ou seleção manual).
Aceitação deve ser explícita: o time receptor aceita, rejeita ou pede esclarecimento. Evite “aceitação suave”—faça um botão que crie responsabilidade e registre timestamp.
Critérios de aceitação: definição de pronto e sign‑off
Ao aceitar, exija uma definição de pronto leve: entregáveis (ex.: endpoint de API, revisão de spec, exportação de dados), teste de aceitação e o responsável pelo sign‑off do lado solicitante.
Isso evita o modo comum de falha em que algo é “entregue” mas não utilizável.
Gestão de mudanças: datas, escopo, reatribuições
Mudanças são normais; surpresas não. Cada mudança deve:
- registrar o que mudou (data, escopo, dono)
- requerer uma breve justificativa
- notificar ambos os times
- manter histórico visível para evitar disputas
Caminho de escalonamento: flags de risco e SLAs
Dê um flag claro em risco com níveis de escalonamento (ex.: Líder de Time → Líder de Programa → Sponsor Executivo) e SLAs opcionais (resposta em X dias, atualização a cada Y dias). Escalonamento deve ser uma ação de workflow, não um thread de mensagens raivosas.
Fluxo de fechamento: evidência, verificação, notas retrospectivas
Feche uma dependência só após dois passos: evidência de entrega (link, anexo ou nota) e verificação pelo solicitante (ou fechamento automático após janela definida). Capture um campo de retrospectiva curto (“o que nos bloqueou?”) para melhorar o planejamento futuro sem rodar um postmortem completo.
Adicione Papéis, Permissões e Auditabilidade
A gestão de dependências quebra quando não se sabe quem pode comprometer, editar ou quem mudou o quê. Um modelo claro de permissões evita mudanças acidentais, protege trabalhos sensíveis e constrói confiança.
Comece com um conjunto pequeno e expanda só quando necessário:
- Admin: gerencia configurações do workspace, integrações e permissões globais
- Program manager: supervisiona portfolios, define governança e resolve disputas
- Líder de time: aprova compromissos e aceita pedidos recebidos
- Contribuidor: cria/atualiza dependências envolvidas, adiciona notas, propõe mudanças
- Visualizador: acesso somente leitura para stakeholders
Permissões por objeto (e por ação)
Implemente permissões por objeto—dependências, projetos, marcos, comentários—e então por ação:
- Criar/editar dependências
- Mudar status (ex.: Proposto → Aceito → Entregue → Fechado)
- Editar datas comprometidas vs. sugeridas
- Deletar (geralmente restrito a Admin/Program manager)
Um padrão bom é least‑privilege: novos usuários não devem poder deletar ou sobrepor compromissos.
Visibilidade de dados e trabalho sensível
Nem todos os projetos devem ser igualmente visíveis. Adicione escopos de visibilidade:
- Interno (padrão): visível a usuários autenticados no workspace
- Sensível: limitado a times específicos ou grupos de segurança
- Notas privadas de time: observações candidas visíveis só ao time responsável, enquanto o status permanece visível a stakeholders
Controles de aprovação e auditoria
Defina quem pode aceitar/rejeitar e quem pode mudar datas comprometidas—tipicamente o líder do time receptor (ou delegado). Mostre a regra na UI: “Só o time responsável pode comprometer datas.”
Adicione um log de auditoria para eventos chave: mudanças de status, edição de datas, mudanças de dono, atualizações de permissões e exclusões (com quem/quando/o que). Se usar SSO, combine com o log para clareza de acesso e responsabilidade.
Implemente Alertas e Notificações
Manter o código portátil
Gere a aplicação rapidamente e exporte o código-fonte quando estiver pronto para produção.
Alertas fazem a diferença entre um app útil e ruído ignorado. Objetivo: manter o trabalho em movimento notificando as pessoas certas na hora certa, com urgência apropriada.
Defina eventos que importam para dependências cross‑funcionais:
- Novo pedido criado (time receptor precisa confirmar)
- Pedido aceito / rejeitado (solicitante precisa de certeza)
- Data se aproximando (evitar surpresas de última hora)
- Status para “em risco” ou “bloqueado” (exigir ação)
Associe cada gatilho a um dono e um “próximo passo”, assim a notificação não é só informativa—é acionável.
Ofereça canais sem forçar
Suporte múltiplos canais:
- Notificações in‑app para trilha limpa e triagem
- Email para quem vive na caixa de entrada
- Slack/Teams para visibilidade rápida de time
Mantenha configurável por usuário e time. Um líder pode querer pings no Slack; um sponsor pode preferir resumo diário por email.
Mensagens em tempo real são melhores para decisões e escalonamentos. Digests servem para awareness (datas próximas, itens aguardando). Tenha configurações como: “imediato para atribuições”, “digest diário para datas” e “resumo semanal de saúde”. Isso reduz fadiga de notificações.
Lembretes e lógica de escalonamento
Lembretes devem respeitar dias úteis, fusos e horários de silêncio. Ex.: enviar lembrete 3 dias úteis antes e nunca fora de 9h–18h do horário local.
Escalonamentos disparam quando:
- Um pedido fica sem resposta após SLA definido (ex.: 48h)
- Uma data atrasou ou a dependência está em risco
Escalone para a próxima camada responsável (líder de time, program manager) e inclua contexto: o que está bloqueado, por quem e qual decisão é necessária.
Planeje Integrações e Sincronização de Dados
Integrações tornam o app útil desde o dia 1 porque times já rastreiam trabalho em outros lugares. O objetivo não é “substituir o Jira”, e sim conectar decisões aos sistemas onde a execução acontece.
Integrações a priorizar
Comece com ferramentas que representam trabalho, tempo e comunicação:
- Jira / Linear para issues, status, responsáveis e contexto de sprint
- GitHub para pull requests, releases e sinais de deploy
- Google Calendar para datas de marcos, janelas de mudança e reuniões-chave
- Slack para notificações e aprovações leves
Escolha 1–2 para pilotar primeiro. Muitas integrações cedo tornam debugging seu trabalho principal.
Estratégia de importação: CSV primeiro, depois sync
Use uma importação CSV única para bootstrap de dependências, projetos e donos. Mantenha o formato opinativo (ex.: título, time solicitante, time provedor, data, status).
Depois, adicione sincronização contínua apenas para campos que devem permanecer consistentes (como status ou data). Isso reduz mudanças surpresa e facilita troubleshooting.
Linkar vs sincronizar (quando cada um)
Nem todo campo externo deve ser copiado:
- Linkar: armazene o ID externo (ex.: chave do Jira) e deep‑link. Bom quando a ferramenta externa é fonte da verdade.
- Sincronizar: guarde uma cópia local de campos selecionados (status, data, assignee) para relatórios, alertas e histórico—especialmente se você precisa de “o que mudou quando”.
Padrão prático: sempre armazene IDs externos, sincronize um pequeno conjunto de campos, e permita overrides manuais só onde seu app é fonte da verdade.
Webhooks + APIs: sincronização orientada a eventos
Polling é simples mas barulhento. Prefira webhooks quando possível:
- Ouça mudanças de status (ex.: “In Progress” → “Done”)
- Ouça mudanças de data (muitas vezes o gatilho mais importante para risco)
Quando um evento chega, enfileire um job em background para buscar o registro via API e atualizar seu objeto de dependência.
Defina fronteiras de propriedade de dados
Escreva qual sistema é dono de cada campo:
- Jira/Linear dona de status da issue e assignee
- Seu app dona de relacionamento de dependência, data de compromisso e decisões de aceitar/recusar
- Slack dona de canal de entrega e histórico de mensagens (não tente replicar)
Regras claras de fonte da verdade evitam “guerras de sincronização” e facilitam governança/auditoria.
Crie Relatórios e Dashboards de Saúde
Dashboards são onde o app ganha confiança: líderes param de pedir “mais um slide” e times param de correr atrás de atualizações em chats. O objetivo não é um muro de gráficos—é responder rápido: “O que está em risco, por quê e quem é o próximo responsável?”
Defina sinais claros de saúde
Comece com um pequeno conjunto de flags de risco computáveis consistentemente:
- Vencido: data prometida passou e não foi entregue
- Bloqueado: marcado como bloqueado ou falta input necessário
- Sem dono: nenhum time/pessoa atribuída
- Datas conflitantes: solicitante precisa depois da entrega planejada do provedor (ou vice‑versa)
Esses sinais devem ser visíveis no nível da dependência e agregados para projeto/programa.
Construa vistas prontas para reunião
Crie vistas que casem com reuniões de direção:
- Dependências críticas próximas: próximas 2–4 semanas, ordenadas por risco e data
- Impacto na capacidade do time: onde pedidos excedem a banda do time (um indicador simples baixo/médio/alto já ajuda)
- Rollups de programa: agrupe por iniciativa, trimestre ou release train para comparar streams sem agregação manual
Um padrão útil é uma página que responda: “O que mudou desde a semana passada?” (novos riscos, bloqueios resolvidos, mudanças de data).
Facilite o compartilhamento
Dashboards precisam sair do app. Adicione exportações que preservem contexto:
- CSV para análise/filtering
- PDF para reuniões de direção
Ao exportar, inclua dono, datas, status e o comentário mais recente para que o arquivo seja autoexplicativo. Assim dashboards substituem slides manuais em vez de criar mais trabalho.
Selecione uma Stack Técnica Prática e Arquitetura
Lançar uma versão piloto
Hospede a sua aplicação piloto para que 2 a 3 equipas a possam testar em trabalho real.
Objetivo não é escolher a tecnologia “perfeita”—é uma stack que sua equipe possa construir e operar com confiança, mantendo vistas rápidas e dados confiáveis.
Linha base prática:
- App web (server‑rendered ou SPA) para uso diário
- Uma API única (REST ou GraphQL) para UI e integrações
- Banco relacional
- Jobs em background para notificações, sincronizações agendadas e geração de relatórios
Ações do usuário são síncronas; trabalhos lentos (alertas, métricas) são assíncronos.
Banco: modele links como intencionalmente ligados
Gestão de dependências é pesada em consultas “encontre tudo bloqueado por X”. Modelo relacional com índices adequados funciona bem.
Planeje ao menos tabelas: Projects, Milestones/Deliverables, Dependencies (from_id, to_id, type, status, datas, donos). Adicione índices para filtros comuns (time, status, data, projeto) e para travessias (from_id, to_id).
Grafos de dependência e timelines/Gantt podem ficar caros. Escolha bibliotecas que suportem virtualização (renderizar só o que está visível) e atualizações incrementais. Trate “mostrar tudo” como modo avançado; padrão deve ser views por projeto/time/faixa de data.
Mantenha vistas rápidas: cache e paginação
Pagine listas por padrão e faça cache de resultados computados comuns (ex.: contagem de bloqueados por projeto). Para grafos, pré‑carregue apenas a vizinhança de um nó selecionado e expanda sob demanda.
Boas práticas de deploy que você vai agradecer
Use ambientes separados (dev/staging/prod), monitore e rastreie erros, e logue eventos relevantes de auditoria. Um app de dependências vira fonte da verdade—downtime e falhas silenciosas custam coordenação.
Caminho rápido para protótipo
Se seu objetivo é validar workflows e UI rápido (inbox, aceitação, escalonamento, dashboards) antes de gastar engenharia, é possível prototipar numa plataforma vibe‑coding como Koder.ai. Ela permite iterar no modelo de dados, papéis/permissões e telas por chat, e exportar código quando pronto para produção (comum: React no front, Go + PostgreSQL no backend). Útil para um piloto com 2–3 times quando velocidade importa mais que arquitetura perfeita no dia 1.
Um app só ajuda se as pessoas confiam. Essa confiança vem de testes cuidadosos, um piloto contido e rollout que não atrapalhe times em entregas.
Teste o fluxo ponta a ponta
Valide o “caminho feliz”: um time solicita, o time responsável aceita, o trabalho é entregue e a dependência é fechada com resultado claro.
Depois ataque casos de borda que quebram uso real:
- Reatribuições: mover propriedade e confirmar histórico intacto
- Rejeições: rejeitar com motivo; permitir revisão/reenviar
- Mudanças de data: atualizar marcos e verificar timelines, SLAs e relatórios se ajustam
Cheque permissões e auditoria
Testes comuns:
- Um solicitante pode editar seu pedido, mas não editar campos de entrega do provedor
- Só donos designados podem aceitar/comprometer datas
- Admins podem intervir e cada mudança crítica fica no log de auditoria (quem/o que/quando)
Notificações sem ruído
Verifique:
- Sem notificações duplicadas para múltiplas mudanças simultâneas
- Throttling funciona (ex.: um resumo em vez de 10 pings)
- Emails/Slack de digest incluem contexto suficiente (projeto, dependência, data, dono)
Pré-carregue dados de demo para validação
Antes de envolver times, carregue projetos, marcos e dependências realistas. Bons dados de demo expõem rótulos confusos, statuses faltantes e lacunas de relatório mais rápido que registros sintéticos.
Rode um piloto pequeno, depois expanda
Pilote com 2–3 equipes que dependem entre si por 2–4 semanas:
- Colete feedback semanal e itere em campos obrigatórios, nomes de status e regras de notificação
Quando equipes do piloto confirmarem economia de tempo, faça rollout por ondas e publique um documento claro “como trabalhamos agora” (até um doc interno simples vinculado do cabeçalho do app) para alinhar expectativas.