O que este web app deve resolver
A maioria das equipes não fracassa por falta de ideias—fracassa porque os resultados ficam espalhados. Um produto tem gráficos numa ferramenta de analytics, outro tem uma planilha, um terceiro tem um slide com screenshots. Alguns meses depois, ninguém responde perguntas simples como “Já testamos isso?” ou “Qual versão ganhou, usando qual definição de métrica?”
O problema central: resultados fragmentados e verdade inconsistente
Um web app de rastreamento de experimentos deve centralizar o que foi testado, por que, como foi medido e o que aconteceu—através de múltiplos produtos e times. Sem isso, equipes perdem tempo refazendo relatórios, discutindo números e reexecutando testes antigos porque aprendizados não são pesquisáveis.
Para quem é (e o que cada grupo precisa)
Isso não é só uma ferramenta para analistas.
- Product managers precisam ver rapidamente resultados, confiança e status da decisão.
- Analistas precisam de um lugar confiável para documentar pressupostos, definições de métricas e ressalvas.
- Engenheiros precisam de clareza sobre feature flags, variantes e condições de rollout que estavam no escopo.
- Liderança precisa de uma visão consistente de impacto entre produtos, sem decks sob medida.
Resultados a otimizar
Um bom tracker gera valor ao possibilitar:
- Decisões mais rápidas (menos tempo caçando links e aprovações)
- Menos erros de reporte (uma fonte única para “os números finais”)
- Aprendizados compartilhados (histórico pesquisável de vitórias, derrotas e testes neutros)
Limites de escopo claros
Seja explícito: este app é primariamente para rastrear e reportar resultados de experimentos—não para executar experimentos end‑to‑end. Ele pode linkar para ferramentas existentes (feature flagging, analytics, data warehouse) enquanto possui o registro estruturado do experimento e sua interpretação final acordada.
Requisitos: o tracker mínimo viável de experimentos
Um tracker mínimo viável deve responder duas perguntas sem caçar documentos ou planilhas: o que estamos testando e o que aprendemos. Comece com um conjunto pequeno de entidades e campos que funcionem entre produtos e expanda só quando as equipes sentirem dor real.
Entidades principais a suportar
Mantenha o modelo de dados simples o bastante para que todo time use do mesmo jeito:
- Product: a superfície (app/site/API) onde a mudança é lançada.
- Experiment: uma hipótese e uma decisão.
- Variant: controle e uma ou mais treatments.
- Metric: uma medição nomeada com um owner e definição.
- Segment: cortes de audiência opcionais (novos usuários, usuários pagantes, região) usados para reporting.
Tipos de experimento (comece pequeno, mantenha flexível)
Suporte aos padrões mais comuns desde o dia 1:
- A/B tests (controle vs treatment)
- Testes multivariados (múltiplas variantes)
- Rollouts com feature flag (exposição por porcentagem)
Mesmo que rollouts não usem estatística formal no começo, rastreá‑los junto com experimentos evita repetir “testes” sem registro.
Campos mínimos que todo experimento precisa
No momento da criação, exija somente o necessário para rodar e interpretar o teste depois:
- Hipótese (que mudança, para quem e por quê)
- Owner (pessoa única responsável)
- Datas de início/fim (planejadas e reais)
- Targeting (regras de elegibilidade) e allocation (divisão de tráfego)
- Links para rollout/flag, ticket ou spec (URLs relativas como /projects/123)
Critérios de sucesso e status de decisão
Faça os resultados comparáveis forçando estrutura:
- Métrica primária (medida principal de sucesso)
- Guardrails (métricas que não podem piorar)
- Status da decisão: proposed → running → analyzed → shipped/rolled back → archived
Se você construir só isso, equipes conseguem encontrar experimentos, entender o setup e registrar resultados—ainda antes de adicionar analytics avançado ou automação.
Modelo de dados que funciona entre múltiplos produtos
Um tracker cross‑product vence ou perde pelo seu modelo de dados. Se IDs colidem, métricas derivam ou segmentos são inconsistentes, seu dashboard pode parecer “certo” enquanto conta a história errada.
Escolha identificadores estáveis (e mantenha‑os)
Comece com uma estratégia clara de identificadores:
- product_id: estável através de renomeações (não use nomes de exibição como chave)
- experiment_key: slug legível (ex.:
checkout_free_shipping_banner) mais um experiment_id imutável
- variant_key: labels estáveis como
control, treatment_a
Isso permite comparar resultados entre produtos sem adivinhar se “Web Checkout” e “Checkout Web” são o mesmo.
Coleções/tabelas centrais
Mantenha as entidades centrais pequenas e explícitas:
- experiments: product_id, hypothesis, primary_metric_def_id, start/end, status
- variants: experiment_id, variant_key, traffic_split
- assignments: experiment_id, user_id (ou anonymous_id), variant_key, assigned_at
- metric_defs: nome da métrica, lógica numerador/denominador, unidade (user/session/order), owner
- results: experiment_id, metric_def_id, time_window_id, segment_id, computed_at, effect, uncertainty
Mesmo que o cálculo ocorra em outro lugar, armazenar os outputs (results) permite dashboards rápidos e um histórico confiável.
Janelas de tempo e versionamento
Métricas e experimentos não são estáticos. Modele:
- time windows (ex.: “primeiros 7 dias após assignment”, “semanas do calendário”)
- definições de métricas versionadas: quando a fórmula muda, crie uma nova versão em vez de editar a antiga
Isso evita que experimentos do mês passado mudem quando alguém atualiza a lógica do KPI.
Segmentos e trilha de auditoria
Planeje segmentos consistentes entre produtos: país, dispositivo, plano, novo vs recorrente.
Finalmente, adicione uma audit trail que capture quem mudou o quê e quando (mudanças de status, splits de tráfego, atualizações de definição de métricas). É essencial para confiança, revisões e governança.
Definições de métricas e cálculos consistentes
Se seu tracker errar a matemática das métricas (ou for inconsistente entre produtos), o “resultado” vira apenas uma opinião com um gráfico. A forma mais rápida de evitar isso é tratar métricas como ativos compartilhados, não pedaços de query ad‑hoc.
Construa um catálogo canônico de métricas
Crie um catálogo que seja a fonte única de verdade para definições, lógica de cálculo e ownership. Cada entrada de métrica deve incluir:
- Uma definição em inglês simples (que decisão apoia)
- Um owner (pessoa/time responsável por mudanças)
- A fórmula exata e eventos/campos necessários
- Regras de inclusão/exclusão (usuários internos, bots, pedidos reembolsados)
- Níveis de agregação válidos e produtos suportados
Mantenha o catálogo próximo à jornada das pessoas (ex.: linkado no fluxo de criação de experimentos) e versionado para explicar resultados históricos.
Padronize níveis de agregação
Decida desde o início qual é a “unidade de análise” de cada métrica: por usuário, por sessão, por conta ou por pedido. Uma taxa de conversão “por usuário” pode divergir de “por sessão” mesmo quando ambas estão corretas.
Para reduzir confusão, armazene a escolha de agregação com a definição da métrica e exija isso na configuração do experimento. Não deixe cada time escolher a unidade ad hoc.
Muitos produtos têm janelas de conversão (ex.: cadastro hoje, compra em até 14 dias). Defina regras de atribuição consistentemente:
- Quando o relógio começa (tempo de exposição, primeira visita, momento do assignment)?
- O que conta como conversão se o usuário for exposto várias vezes?
- Como lidar com jornadas cross‑device ou cross‑product?
Deixe essas regras visíveis no dashboard para que leitores saibam o que estão vendo.
Armazene contagens brutas e estatísticas computadas
Para dashboards rápidos e auditabilidade, armazene ambos:
- Contagens brutas (exposições, conversores, somas de receita, inputs de variância)
- Estatísticas computadas (lift, intervalos de confiança, p‑values)
Isso permite renderização rápida e ainda possibilita recomputar quando definições mudarem.
Convenções de nomes evitam proliferação de métricas
Adote um padrão de nomes que encode significado (ex.: activation_rate_user_7d, revenue_per_account_30d). Exija IDs únicos, implemente aliases e alerte sobre quase‑duplicatas durante a criação para manter o catálogo limpo.
Coleta de dados: eventos, pipelines e checagens de qualidade
Seu tracker é tão crível quanto os dados que ingere. O objetivo é responder de forma confiável duas perguntas para cada produto: quem foi exposto a qual variante, e o que fez depois? Todo o resto—métricas, estatísticas, dashboards—depende dessa fundação.
Escolha uma abordagem de ingestão
A maioria das equipes escolhe um destes padrões:
- Stream de eventos (near real‑time): ótimo para leituras rápidas e debug mais veloz. Requer maturidade de engenharia para manter estável.
- Batch diário: mais simples de operar e mais barato. Melhor quando decisões não precisam ser horárias.
- Híbrido: stream de exposições e eventos críticos (para validar assignments rápido), batch do resto para completude e controle de custo.
Seja qual for, padronize o conjunto mínimo de eventos entre produtos: exposure/assignment, eventos de conversão chave e contexto suficiente para juntá‑los (user ID/device ID, timestamp, experiment ID, variant).
Mapeie eventos do produto para métricas (e valide completude)
Defina um mapeamento claro de eventos brutos para as métricas que o tracker reporta (ex.: purchase_completed → Revenue, signup_completed → Activation). Mantenha esse mapeamento por produto, mas com nomes consistentes entre produtos para comparar corretamente.
Valide a completude cedo:
- Confirme cada exposição tem experiment ID e variant.
- Garanta que eventos de conversão incluam os mesmos campos de identidade usados para juntar exposições.
- Fique de olho em perdas de eventos entre cliente, servidor e warehouse (SDKs mobile são culpados comuns).
Checagens de qualidade de dados que você deve automatizar
Construa checagens que rodem em cada carga e falhem visivelmente:
- Exposições faltantes: conversões sem exposição prévia (falhas de instrumentação ou mismatch de identidade).
- Alocações enviesadas: variantes com 70/30 quando esperava 50/50 (pode indicar bug de targeting).
- Sanidade de timestamps: exposições após conversões, ou delays grandes sugerindo problema de relógio.
Mostre isso no app como avisos anexados ao experimento, não escondidos em logs.
Backfills e reprocessamento
Pipelines mudam. Quando você corrige um bug de instrumentação ou lógica de deduplicação, será necessário reprocessar dados históricos para manter métricas e KPIs consistentes.
Planeje para:
- Transformações versionadas (para saber qual lógica produziu qual resultado).
- Backfills seguros (limitando por data/produto/experimento).
- Uma trilha de auditoria da recomputação.
Documente integrações
Trate integrações como features de produto: documente SDKs suportados, esquemas de evento e passos de troubleshooting. Se tiver uma área de docs, linke como caminho relativo, por exemplo /docs/integrations.
Estatística e cálculo de resultados confiáveis
Adicione RBAC desde o primeiro dia
Defina os papéis Viewer, Editor e Admin para manter o acesso entre produtos organizado.
Se as pessoas não confiam nos números, não usarão o tracker. O objetivo não é impressionar com matemática—é tornar decisões repetíveis e defensáveis entre produtos.
Escolha um “dialeto” estatístico e mantenha‑o
Decida se o app reportará frequentista (p‑values, intervalos de confiança) ou bayesiano (probabilidade de melhoria, intervalos críveis). Ambos funcionam, mas misturá‑los entre produtos confunde (“Por que este teste mostra 97% de chance de vencer, enquanto aquele mostra p=0.08?”).
Uma regra prática: escolha o que a organização já entende e padronize terminologia, defaults e thresholds.
Defina exatamente o que a UI mostra
No mínimo, a vista de resultados deve deixar claro:
- Lift (absoluto e/ou relativo) versus controle
- Intervalo (intervalo de confiança ou intervalo crível) mostrado como faixa, não só estimativa pontual
- Força da evidência (p‑value no frequentista, ou probabilidade de vencer no bayesiano)
Mostre também a janela de análise, unidades contadas (usuários, sessões, pedidos) e a versão da definição da métrica usada. Esses detalhes fazem a diferença entre reporte consistente e debate.
Comparações múltiplas e políticas de “peeking”
Se equipes testam muitas variantes, muitas métricas ou checam resultados diariamente, falsos positivos aparecem. Seu app deve codificar uma política:
- Comparações múltiplas: decida se ajusta (ex.: controlar false discovery rate) ou rotule claramente como “exploratório, sem ajuste”.
- Peeking repetido: ou (1) desencoraje com data final fixa e status “finalizado”, ou (2) suporte métodos sequenciais e mostre orientação “safe‑to‑stop”.
Guardrails que pegam falhas comuns
Adicione flags automáticas que apareçam ao lado dos resultados:
- Sample Ratio Mismatch (SRM): aviso quando divisão de tráfego diverge do esperado.
- Detecção de anomalia: sinalize quedas/picos súbitos que indiquem breaks de tracking, outages ou tráfego de bots.
Explicações em linguagem simples
Ao lado dos números, acrescente uma breve explicação que um leitor não técnico confie, por exemplo: “A melhor estimativa é +2.1% de lift, mas o efeito verdadeiro pode estar entre -0.4% e +4.6%. Não temos evidência forte para declarar um vencedor ainda.”
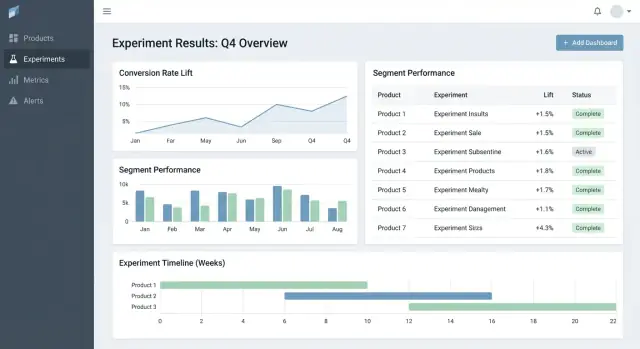
UX e dashboards para decisões rápidas
Boa ferramenta de experimentos ajuda a responder duas perguntas rápido: O que devo olhar a seguir? e O que devemos fazer sobre isso? A UI deve minimizar caçar contexto e tornar o “estado da decisão” explícito.
Páginas-chave para ancorar o workflow
Comece com três páginas que cobrem a maior parte do uso:
- Lista de experimentos: fila ordenável para a org (ou por produto).
- Detalhe do experimento: fonte única de verdade para setup, resultados e decisão.
- Visão do produto: rollup de testes ativos, decisões recentes e saúde de métricas para um produto.
Nas páginas de lista e produto, faça filtros rápidos e persistentes: product, owner, date range, status, primary metric e segment. As pessoas devem conseguir reduzir para “experimentos de Checkout, owned pela Maya, rodando este mês, métrica = conversão, segmento = novos usuários” em segundos.
Estados de decisão que inspiram confiança
Trate status como vocabulário controlado, não texto livre:
Draft → Running → Stopped → Shipped / Rolled back
Mostre o status em toda parte (linhas da lista, cabeçalho do detalhe e links compartilháveis) e registre quem mudou e por quê. Isso evita “lançamentos silenciosos” e resultados ambíguos.
Uma tabela de resultados que deixa a decisão óbvia
Na vista de detalhe, lidere com uma tabela compacta de resultados por métrica:
- Baseline
- Variante
- Lift
- Incerteza (intervalo de confiança ou crível)
- Notas (caveats de instrumentação, peculiaridades de segmento)
Mantenha gráficos avançados em “Mais detalhes” para não sobrecarregar tomadores de decisão.
Compartilhamento e exportações sem perder controle
Adicione export CSV para analistas e links compartilháveis para stakeholders, mas imponha acesso: links devem respeitar roles e permissões por produto. Um botão “Copy link” e uma ação “Export CSV” cobrem a maioria das necessidades colaborativas.
Permissões, privacidade e governança
Configure um catálogo de métricas
Crie definições de métricas versionadas para manter os resultados comparáveis ao longo do tempo.
Se seu tracker abrange múltiplos produtos, controle de acesso e auditabilidade não são opcionais. São o que torna a ferramenta segura para adoção e confiável em revisões.
Controle de acesso baseado em papel (RBAC)
Comece com um conjunto simples de papéis e mantenha consistente:
- Viewer: acesso apenas leitura a experimentos, resultados e dashboards.
- Editor: criar/editar experimentos, subir docs de suporte, alterar status (draft → running → concluded).
- Admin: gerenciar usuários, permissões, definições de métricas, regras de retenção e integrações.
Centralize decisões de RBAC (uma camada de política) para que UI e API apliquem as mesmas regras.
Permissões por produto e por linha
Muitas orgs precisam de acesso escopado por produto: Time A vê Produto A mas não Produto B. Modele isso explicitamente (ex.: user ↔ product memberships) e garanta que toda query seja filtrada por produto.
Para casos sensíveis (dados de parceiros, segmentos regulados), adicione restrições por linha sobre o escopo do produto. Uma abordagem prática é taggear experimentos (ou slices de resultados) com nível de sensibilidade e exigir permissão adicional para visualizá‑los.
Trilha de auditoria: histórico de mudanças + acesso
Registre separadamente:
- Change logs: quem editou um experimento, definição de métrica ou decisão—o que mudou e quando.
- Access logs: quem visualizou ou exportou resultados (especialmente experimentos sensíveis).
Exponha o histórico de mudanças na UI para transparência e mantenha logs mais profundos para investigações.
Regras de retenção e exclusão
Defina regras de retenção para:
- Metadados do experimento (hipótese, owners, datas, notas de decisão)
- Resultados computados (efeitos, intervalos, flags de significância)
Torne a retenção configurável por produto e sensibilidade. Quando dados precisarem ser removidos, mantenha um registro mínimo (tombstone: ID, hora da exclusão, motivo) para preservar integridade de relatórios sem reter conteúdo sensível.
Recursos de workflow: da ideia à biblioteca de aprendizados
Um tracker vira realmente útil quando cobre o ciclo de vida completo do experimento, não só o p‑value final. Recursos de workflow transformam docs, tickets e gráficos dispersos em um processo repetível que melhora qualidade e facilita reaproveitar aprendizados.
Workflow de lifecycle: idea → review → run → post‑mortem
Modele experimentos como estados (Draft, In Review, Approved, Running, Ended, Readout Published, Archived). Cada estado deve ter critérios claros de saída para que experimentos não entrem em produção sem essenciais como hipótese, métrica primária e guardrails.
Aprovações não precisam ser pesadas. Um passo simples de reviewer (ex.: produto + dados) mais uma trilha de auditoria de quem aprovou e quando pode evitar erros evitáveis. Após conclusão, exija um post‑mortem curto antes de marcar “Published” para garantir que contexto e resultados sejam capturados.
Templates que padronizam o raciocínio
Adicione templates para:
- Brief do experimento (objetivo, hipótese, audiência alvo, métricas de sucesso, guardrails, plano de rollout)
- Notas de análise (fontes de dados, exclusões, checagens de sanidade, interpretação, riscos)
Templates reduzem atrito do “papel em branco” e aceleram reviews porque todo mundo sabe onde olhar. Mantenha‑os editáveis por produto preservando um núcleo comum.
Aprendizados: linke tudo e mantenha pesquisável
Experimentos raramente vivem sozinhos—pessoas precisam do contexto. Permita anexar links para tickets/specs e relatórios relacionados (por exemplo: /blog/how-we-define-guardrails, /blog/experiment-analysis-checklist). Armazene campos estruturados de “Learning” como:
- O que mudou (decisão)
- O que aprendemos (insight)
- Próximos passos (follow‑up)
Alertas para guardrails e mudanças em resultados
Suporte notificações quando guardrails regredirem (ex.: taxa de erro, cancelamentos) ou quando resultados mudarem materialmente após dados tardios ou recalculação de métricas. Faça alertas acionáveis: mostre métrica, threshold, período e um owner para reconhecer ou escalar.
Uma vista de biblioteca para reaproveitar trabalho passado
Forneça uma biblioteca que filtre por produto, área de feature, audiência, métrica, resultado e tags (ex.: “pricing”, “onboarding”, “mobile”). Adicione sugestões de “experimentos similares” baseadas em tags/métricas compartilhadas para evitar reruns desnecessários e incentivar construir sobre aprendizados anteriores.
Arquitetura e opções de stack técnico
Você não precisa de uma stack “perfeita” para construir um web app de rastreamento de experimentos—mas precisa de limites claros: onde os dados vivem, onde os cálculos rodam e como equipes acessam resultados consistentemente.
Stack baseline prático
Para muitas equipes, uma configuração simples e escalável é:
- Frontend: React (ou Vue) para dashboards e workflows
- Backend API: Node.js/Express, Python/FastAPI, ou Java/Spring—escolha o que seu time mantém
- Banco: Postgres para dados de app (experimentos, definições de métricas, permissões)
- Data warehouse: BigQuery/Snowflake/Redshift para eventos e agregações pesadas
Essa separação mantém workflows transacionais rápidos enquanto o warehouse trata computação em larga escala.
Se quiser prototipar a UI de workflow rapidamente (lista de experiments → detalhe → readout) antes de um ciclo de engenharia completo, uma plataforma de low‑code como Koder.ai pode gerar uma base React + backend a partir de uma especificação em chat. É útil para obter entidades, formulários, RBAC e CRUD com auditoria no lugar, e depois iterar nos contratos de dados com o time de analytics.
Onde as métricas devem ser calculadas?
Normalmente há três opções:
- Warehouse‑first: modelos SQL computam métricas e tabelas de resultados. O app só lê.
- Jobs no backend: um worker computa resultados em agendamento ou quando experimentos mudam.
- Híbrido: agregações canônicas no warehouse, com pós‑processamento no backend (formatação, guardrails, cache).
Warehouse‑first é muitas vezes o mais simples se o time de dados já controla SQL confiável. Backend‑heavy funciona quando precisa de baixa latência, mas aumenta complexidade.
Dashboards de experimentos repetem queries (KPIs top‑line, séries temporais, cortes por segmento). Planeje:
- Pré‑computar rollups (agregados diários por experiment/variant/segment)
- Cache de leituras caras na camada API (ex.: Redis) com regras claras de invalidação
- Usar materialized views ou tabelas agendadas no warehouse para dashboards comuns
Multi‑tenant vs single‑tenant
Se suportar muitos produtos/unidades de negócio, decida cedo:
- Single‑tenant (schema compartilhado): mais fácil de operar, mas exige filtragem rígida de permissões.
- Multi‑tenant: esquemas/projetos separados por produto para isolamento mais forte, com mais overhead.
Um compromisso comum é infraestrutura compartilhada com um forte modelo tenant_id e acesso por linha aplicado rigidamente.
Defina as APIs centrais
Mantenha a superfície de API pequena e explícita. A maioria dos sistemas precisa de endpoints para experiments, metrics, results, segments e permissions (além de leituras compatíveis com auditoria). Isso facilita adicionar produtos sem reescrever a infra.
Testes, monitoramento e operações confiáveis
Entregue painéis prontos para tomada de decisão
Crie páginas de lista de experimentos, detalhes e visão geral do produto sem código repetitivo.
Um tracker só é útil se as pessoas confiam nele. Essa confiança vem de testes disciplinados, monitoramento claro e operações previsíveis—especialmente quando múltiplos produtos e pipelines alimentam os mesmos dashboards.
Observabilidade alinhada ao uso do app
Comece com logs estruturados para cada passo crítico: ingestão de eventos, assignment, rollups de métricas e cálculo de resultados. Inclua identificadores como product, experiment_id, metric_id e pipeline run_id para que suporte rastreie um resultado até suas entradas.
Adicione métricas de sistema (latência de API, tempo de jobs, tamanho de filas) e métricas de dados (eventos processados, % eventos tardios, % descartados por validação). Complementar com tracing entre serviços ajuda a responder “Por que este experimento está faltando dados de ontem?”
Checagens de frescor de dados evitam falhas silenciosas. Se SLA é “diário até 9h”, monitore frescor por produto e fonte e alerte quando:
- a partição mais recente estiver ausente
- o volume de eventos divergir fortemente do baseline
- jobs de rollup terminarem mas gerarem zero rows
Testes automatizados: proteja dados e matemática
Crie testes em três níveis:
- Schema e constraints: campos obrigatórios, unicidade (ex.: um assignment por usuário por experimento), chaves estrangeiras e intervalos de datas válidos.
- Permissões: testes RBAC (viewer/editor/admin) e escopo por produto para garantir visibilidade correta.
- Math de resultados: testes unitários para lift, intervalos, flags de significância e casos extremos (amostras pequenas, denominador zero, múltiplas variantes).
Mantenha um pequeno “golden dataset” com saídas conhecidas para pegar regressões antes do deploy.
Deploys, migrations e segurança histórica
Trate migrations como parte das operações: version your metric definitions and result computation logic, e evite reescrever experimentos históricos a menos que solicitado. Quando mudanças forem necessárias, forneça um caminho de backfill controlado e documente o que mudou na trilha de auditoria.
Ferramentas admin para incidentes e reprocessamento
Forneça uma visão admin para reexecutar pipeline para um experimento/período específico, inspecionar erros de validação e marcar incidentes com status. Linke notas de incidentes diretamente dos experimentos afetados para que usuários entendam atrasos e não tomem decisões com dados incompletos.
Plano de rollout e armadilhas comuns a evitar
Lançar um tracker across products é menos sobre “dia do lançamento” e mais sobre reduzir ambiguidade: o que é rastreado, quem é dono e se os números batem com a realidade.
Sequência prática de rollout
Comece com um produto e um conjunto pequeno e de alta confiança de métricas (por exemplo: conversão, ativação, receita). O objetivo é validar o fluxo end‑to‑end—criar experimento, capturar exposição e outcomes, calcular resultados e registrar a decisão—antes de escalar complexidade.
Quando o primeiro produto estiver estável, expanda produto a produto com cadence previsível de onboarding. Cada novo produto deve ser um setup repetível, não um projeto customizado.
Se sua org tende a ciclos longos de “construção de plataforma”, considere uma abordagem de duas trilhas: construa contratos de dados duráveis (eventos, IDs, definições de métricas) em paralelo com uma camada de app fina. Equipes às vezes usam Koder.ai para levantar essa camada fina rapidamente—forms, dashboards, permissões e export—depois endurecendo conforme adoção cresce (incluindo export de código e rollbacks iterativos via snapshots quando requisitos mudam).
Checklist de rollout por produto
Use um checklist leve para onboardar produtos e esquemas de eventos consistentemente:
- Confirme taxonomia e convenções de nomes de eventos (e quem pode mudá‑los)
- Verifique existência de eventos de exposição e atributo único a um usuário/sessão
- Mapeie métricas para o esquema de eventos do produto (incluindo casos de borda como reembolsos)
- Rode um backfill ou um período de paralelismo para comparar com analytics existente
- Atribua ownership para setup do experimento, validação de dados e notas finais de decisão
Quando ajudar a adoção, linke “próximos passos” dos resultados do experimento para áreas relevantes do produto (por exemplo, experimentos de precificação podem linkar para /pricing). Mantenha links informativos e neutros—sem implicar resultados.
Meça adoção para corrigir fricção cedo
Meça se a ferramenta está virando o lugar padrão para decisões:
- Weekly active users por papel (PM, analista, engenheiro)
- Experimentos criados e completados
- Percentual com notas de decisão preenchidas (não só visualizados)
- Tempo do fim do experimento → decisão registrada
Armadilhas comuns
Na prática, a maioria dos rollouts tropeça em alguns problemas recorrentes:
- Definições de métricas inconsistentes entre produtos (mesmo nome, matemática diferente)
- Tracking de exposição faltante ou defeituoso, levando a resultados viesados
- Ownership pouco claro para validação e sign‑off, gerando “experimentos zumbi”
- Mudanças silenciosas de schema que quebram tendências sem avisar
- Escalar para muitas métricas cedo demais, antes do fluxo central ganhar confiança