O que é Sharding (e o que não é)
Sharding (também chamado de particionamento horizontal) significa apresentar ao aplicativo o que parece ser um banco de dados e dividir seus dados entre múltiplas máquinas, chamadas shards. Cada shard mantém apenas um subconjunto das linhas, mas juntos representam o conjunto de dados completo.
Uma tabela lógica, muitos lugares físicos
Um modelo mental útil é a diferença entre estrutura lógica e colocação física.
- Lógico: você ainda tem uma tabela “Users” (mesmas colunas, mesmo significado).
- Físico: as linhas dessa tabela são armazenadas em lugares diferentes — talvez usuários com IDs 1–1.000.000 estejam no shard A, e o próximo milhão no shard B.
Do ponto de vista do app, você quer executar consultas como se fosse uma única tabela. Por baixo, o sistema precisa decidir qual(is) shard(s) contatar.
Não é replicação, nem “comprar uma máquina maior”
Sharding é diferente de replicação. Replicação cria cópias dos mesmos dados em vários nós, principalmente para alta disponibilidade e escalabilidade de leitura. Sharding divide os dados para que cada nó possua registros diferentes.
Também é diferente de scaling vertical, onde você mantém um banco de dados, mas o move para uma máquina maior (mais CPU/RAM/discos mais rápidos). Escalar verticalmente pode ser mais simples, mas tem limites práticos e pode ficar caro rapidamente.
O que sharding não resolve magicamente
Sharding aumenta capacidade, mas não torna automaticamente seu banco “fácil” ou todas as consultas mais rápidas.
- Joins podem ficar caros se linhas relacionadas estiverem em shards diferentes.
- Transações entre shards são mais difíceis; atualizações “tudo-ou-nada” podem exigir coordenação.
- Complexidade operacional aumenta: roteamento, reequilíbrio, debugging e tratamento de falhas viram parte do sistema.
Portanto, sharding é melhor entendido como uma maneira de escalar armazenamento e throughput — não uma atualização gratuita em todos os aspectos do comportamento do banco.
Por que equipes shardam: os problemas que isso tenta resolver
Sharding raramente é a primeira escolha. Equipes geralmente chegam a ele depois que um sistema bem-sucedido atinge limites físicos — ou quando dores operacionais se tornam frequentes demais para ignorar. A motivação é menos “queremos sharding” e mais “precisamos continuar crescendo sem que um banco se torne ponto único de falha e custo”.
Pontos de dor que empurram para o sharding
Um único nó de banco pode ficar sem espaço de várias maneiras:
- Limites de armazenamento: tabelas e índices crescem até o disco ficar apertado, backups ficam lentos e operações de manutenção ficam arriscadas.
- Limites de throughput de escrita: CPU, WAL/redo ou contenção de locks limitam quantas gravações por segundo você pode sustentar.
- Limites de throughput de leitura: mesmo com cache e réplicas, alguns workloads sobrecarregam o primário (ou réplicas ficam caras de escalar).
- Vizinhos barulhentos: um tenant, cliente ou padrão de workload monopoliza recursos e degrada os outros.
Quando esses problemas aparecem regularmente, o foco raramente é uma query ruim isolada — é que uma máquina carrega responsabilidade demais.
Objetivos: escalar horizontalmente, isolar e controlar custos
Sharding de banco de dados espalha dados e tráfego por múltiplos nós para que a capacidade cresça adicionando máquinas em vez de escalando verticalmente um único nó. Bem feito, também pode isolar workloads (para que um pico de um tenant não arruine latência para os outros) e controlar custos evitando instâncias premium cada vez maiores.
Sinais de alerta de que você está se aproximando do teto
Padrões recorrentes incluem aumento constante da p95/p99 em picos, maior lag de replicação, backups/restores ultrapassando janelas aceitáveis e mudanças pequenas de schema virando eventos grandes.
Por que sharding costuma ser o último passo
Antes de se comprometer, equipes normalmente esgotam opções mais simples: indexação e correção de queries, cache, réplicas de leitura, particionamento dentro de um único banco, arquivamento de dados antigos e upgrades de hardware. Sharding pode resolver escala, mas também adiciona coordenação, complexidade operacional e novos modos de falha — então a barra deveria ser alta.
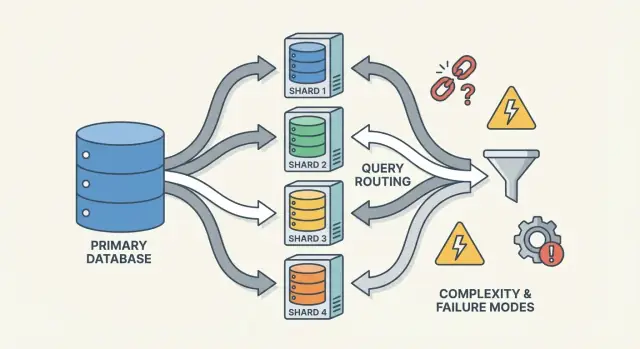
Um banco shardado não é uma coisa só — é um pequeno sistema de peças cooperantes. A razão pela qual sharding pode parecer “difícil de raciocinar” é que corretude e desempenho dependem de como essas peças interagem, não apenas do motor de banco.
Um shard é um subconjunto dos dados, normalmente armazenado em seu próprio servidor ou cluster. Cada shard tipicamente tem:
- armazenamento (arquivos de dados)
- índices (para que queries sejam rápidas dentro daquele shard)
- limites locais (CPU, memória, disco, conexões)
Do ponto de vista da aplicação, uma configuração shardada costuma tentar parecer um banco lógico único. Mas por baixo, uma consulta que seria “um lookup de índice” num banco de nó único pode virar “encontre o shard certo, depois faça o lookup”.
Roteadores/coordenadores: como as requisições alcançam o shard certo
Um roteador (às vezes chamado de coordenador, query router ou proxy) é o policial de tráfego. Ele responde à pergunta prática: dada essa requisição, qual shard deve tratá-la?
Há dois padrões comuns:
- Roteamento no cliente: sua biblioteca de aplicação conhece o mapa de shards e conecta diretamente ao shard correto.
- Roteamento por proxy: o app conecta a um serviço roteador, que encaminha a requisição.
Roteadores reduzem complexidade no app, mas também podem virar gargalo ou novo ponto de falha se não forem bem projetados.
Sharding depende de metadata — uma fonte de verdade que descreve:
- o mapa de shards (qual shard possui quais ranges/buckets/IDs)
- propriedade (especialmente durante migrações, quando a propriedade pode se sobrepor temporariamente)
- saúde e membros (quais nós estão up, papéis primário/replica, status de draining)
Essa informação costuma viver num serviço de config (ou num pequeno banco “plano de controle”). Se a metadata estiver stale ou inconsistente, roteadores podem enviar tráfego para o lugar errado — mesmo se cada shard estiver saudável.
Jobs em background: balanceamento, migrações e backups
Finalmente, sharding depende de processos de background que mantêm o sistema operacional ao longo do tempo:
- reequilíbrio de dados quando um shard cresce mais rápido que outros
- migrações ao mover propriedade entre shards
- backup/restore que funcionem através de muitos shards (e correspondam aos seus objetivos de recuperação)
Esses jobs são fáceis de ignorar cedo, mas é onde muitas surpresas de produção acontecem — porque mudam a forma do sistema enquanto ele ainda atende tráfego.
Escolhendo uma chave de shard: a primeira grande troca
Uma chave de shard é o campo (ou combinação de campos) que seu sistema usa para decidir qual shard deve armazenar uma linha/documento. Essa escolha única determina silenciosamente desempenho, custo e até que recursos estarão “fáceis” mais tarde — porque controla se as requisições podem ser roteadas a um shard ou precisam fazer fan-out para muitos.
O que torna uma chave de shard “boa”
Uma boa chave tende a ter:
- Alta cardinalidade: muitos valores possíveis (ex.:
user_id em vez de country).
- Distribuição uniforme: valores espalham gravações e leituras pelos shards em vez de se acumular em um só.
- Padrões de acesso estáveis: ela combina com como você mais frequentemente consulta os dados hoje e como espera consultá-los no próximo trimestre.
Um exemplo comum é shardar por tenant_id em um app multi-tenant: a maioria das leituras e gravações de um tenant fica em um shard, e tenants são numerosos o suficiente para espalhar a carga.
O que torna uma chave “ruim” (e por que isso dói)
Algumas chaves quase garantem dor:
- Chaves monotônicas baseadas em tempo (timestamps, IDs autoincrement): novos dados se concentram no shard “mais recente”, criando hotspot de gravação.
- Campos de baixa cardinalidade (status, plan_tier, country): poucos valores distintos significam que alguns shards fazem a maior parte do trabalho.
- Identificadores mutáveis (email, usernames mutáveis): se a chave muda, mover dados entre shards fica caro e arriscado.
Mesmo que um campo de baixa cardinalidade pareça conveniente para filtragem, ele frequentemente transforma consultas rotineiras em consultas scatter-gather, porque as linhas correspondentes vivem por toda parte.
O trade-off real: conveniência de consulta vs qualidade de distribuição
A melhor chave de shard para balanceamento de carga nem sempre é a melhor para consultas de produto.
- Escolha uma chave alinhada ao seu padrão de acesso primário (ex.:
user_id), e algumas consultas “globais” (ex.: relatórios admin) ficam mais lentas ou exigem pipelines separados.
- Escolha uma chave alinhada a relatórios (ex.:
region), e você corre o risco de hotspots e capacidade desigual.
A maioria das equipes projeta em torno desse trade-off: otimiza a chave de shard para as operações mais frequentes e sensíveis à latência — e trata o resto com índices, denormalização, réplicas ou tabelas analíticas dedicadas.
Estratégias comuns de sharding (Range, Hash, Directory)
Não existe uma única maneira “melhor” de shardar um banco. A estratégia que você escolhe molda quão fácil é roteador queries, quão uniformemente os dados se espalham e que tipos de padrões de acesso vão doer.
Range sharding
Com range sharding, cada shard é dono de uma fatia contígua de um espaço de chave — por exemplo:
- Shard A: customer_id 1–1.000.000
- Shard B: customer_id 1.000.001–2.000.000
O roteamento é simples: olhe a chave, escolha o shard.
O porém são hotspots. Se novos usuários sempre recebem IDs crescentes, o shard “final” vira o gargalo de escrita. Range sharding também é sensível ao crescimento desigual (uma faixa fica popular, outra fica quieta). O lado bom: consultas por intervalo (“todos os pedidos de 1–31 de out”) podem ser eficientes porque os dados estão fisicamente agrupados.
Hash sharding
Hash sharding passa a chave de shard por uma função de hash e usa o resultado para escolher um shard. Normalmente isso espalha dados mais uniformemente, ajudando a evitar o problema de “tudo indo para o shard mais recente”.
Trade-off: consultas por intervalo ficam caras. Uma query como “customers com IDs entre X e Y” não mapeia mais para um pequeno conjunto de shards; pode tocar muitos.
Um detalhe prático que equipes subestimam é o hash consistente. Em vez de mapear diretamente ao número de shards (o que redistribui tudo ao adicionar shards), muitos sistemas usam um anel de hash com “nós virtuais” para que adicionar capacidade mova apenas parte das chaves.
Directory (lookup) sharding
Directory sharding armazena um mapeamento explícito (uma tabela/serviço de lookup) de key → local do shard. É a mais flexível: você pode posicionar tenants específicos em shards dedicados, mover um cliente sem mover todo mundo e suportar tamanhos de shards desiguais.
O lado ruim é uma dependência extra. Se o diretório estiver lento, stale ou indisponível, o roteamento sofre — mesmo que os shards estejam saudáveis.
Chaves compostas e sub-sharding
Sistemas reais frequentemente misturam abordagens. Uma chave composta (ex.: tenant_id + user_id) mantém tenants isolados enquanto espalha carga dentro de um tenant. Sub-sharding é similar: roteie primeiro por tenant, depois faça hash dentro do grupo de shards daquele tenant para evitar que um “big tenant” domine um shard.
Como as consultas funcionam: roteamento vs scatter-gather
Compare estratégias de sharding
Compare rapidamente padrões de sharding por faixa, hash e diretório em protótipos separados.
Um banco shardado tem dois caminhos de consulta bem diferentes. Entender em qual caminho você está explica a maioria das surpresas de desempenho — e por que sharding pode parecer imprevisível.
Consultas single-shard: o caminho rápido
O resultado ideal é rotear uma consulta para exatamente um shard. Se a requisição inclui a chave de shard (ou algo que o roteador pode mapear), o sistema pode enviá-la direto para o lugar certo.
Por isso equipes se preocupam em tornar leituras comuns “conscientes da chave de shard”. Um shard significa menos hops de rede, execução mais simples, menos locks e bem menos coordenação. A latência é principalmente o banco fazendo o trabalho, não o cluster discutindo quem deve fazê-lo.
Leituras scatter-gather: fan-out e latência de cauda
Quando uma consulta não pode ser roteada precisamente (por exemplo, filtra por um campo que não é chave de shard), o sistema pode broadcastá-la para muitos ou todos os shards. Cada shard executa a query localmente, então o roteador (ou um coordenador) mescla resultados — ordenando, deduplicando, aplicando limits e combinando agregações parciais.
Esse fan-out amplifica a latência de cauda: mesmo que 9 shards respondam rápido, um shard lento pode manter a requisição inteira refém. Também multiplica carga: uma requisição de usuário pode virar N requisições aos shards.
Joins e agregações cross-shard
Joins entre shards são caros porque dados que se encontrariam “dentro” do banco agora precisam viajar entre shards (ou até um coordenador). Mesmo agregações simples (COUNT, SUM, GROUP BY) podem requerer um plano em duas fases: calcular resultados parciais em cada shard, depois mesclá-los.
Limitações de indexação: local vs global
A maioria dos sistemas usa por padrão índices locais: cada shard indexa apenas seus próprios dados. Eles são baratos de manter, mas não ajudam o roteamento — então queries podem continuar a scatter. Índices globais podem permitir roteamento direcionado em campos que não são chave de shard, mas adicionam overhead nas gravações, coordenação extra e seus próprios desafios de escala e consistência.
Gravações e transações através de shards
Gravações é onde sharding deixa de parecer “apenas escalar” e começa a mudar como você projeta features. Uma gravação que toca um shard pode ser rápida e simples. Uma gravação que atravessa shards pode ser lenta, sujeita a falhas e surpreendentemente difícil de deixar correta.
Gravações single-shard: o caminho feliz
Se cada requisição puder ser roteada para exatamente um shard (tipicamente via chave de shard), o banco pode usar sua máquina normal de transações. Você obtém atomicidade e isolamento dentro daquele shard, e a maioria dos problemas operacionais se parecem com problemas familiares de um único nó — só repetidos N vezes.
Gravações multi-shard: onde a complexidade dispara
No momento em que você precisa atualizar dados em dois shards numa mesma ação lógica (ex.: transferir dinheiro, mover um pedido entre clientes, atualizar um agregado armazenado em outro lugar), você entra em território de transações distribuídas.
Transações distribuídas são difíceis porque exigem coordenação entre máquinas que podem ser lentas, particionadas ou reiniciadas a qualquer momento. Protocolos estilo two-phase commit adicionam viagens extras, podem bloquear em timeouts e tornam falhas ambíguas: o shard B aplicou a mudança antes do coordenador morrer? Se o cliente re-fizer a requisição, você aplica em dobro? Se não re-tentar, você perde a mudança?
Padrões para evitar gravações cross-shard
Algumas táticas comuns reduzem a necessidade de transações multi-shard:
- Localidade de dados: co-locar registros relacionados no mesmo shard (ex.: tudo de um cliente).
- Roteamento de requisições: garantir que uma operação seja de propriedade de um shard e tratar outros como entradas só de leitura.
- Denormalização: duplicar pequenos pedaços de dados para que atualizações não precisem se espalhar.
Idempotência e segurança em retries
Em sistemas shardados, retries não são opcionais — são inevitáveis. Torne gravações idempotentes usando IDs de operação estáveis (ex.: uma chave de idempotência) e fazendo o banco armazenar marcadores de “já aplicado”. Assim, se um timeout ocorrer e o cliente re-tentar, a segunda tentativa vira um no-op em vez de cobrança dupla, pedido duplicado ou contador inconsistente.
Consistência e replicação: mantendo os dados corretos
Leve o código com você
Mantenha a propriedade total exportando o código-fonte quando seu design estiver pronto.
Sharding divide seus dados entre máquinas, mas não elimina a necessidade de redundância. Replicação é o que mantém um shard disponível quando um nó morre — e também é o que complica a resposta à pergunta “o que é verdade agora?”.
Replicação dentro de cada shard
A maioria dos sistemas replica dentro de cada shard: um primário (leader) aceita gravações, e uma ou mais réplicas copiam essas mudanças. Se o primário falha, o sistema promove uma réplica (failover). Réplicas também podem servir leituras para reduzir carga.
O trade-off é timing. Uma réplica de leitura pode estar alguns milissegundos — ou segundos — atrás. Essa lacuna é normal, mas importa quando usuários esperam “acabei de atualizar, então devo ver agora”.
Modelos de consistência em termos simples
- Consistência forte: depois de uma gravação bem-sucedida, leituras vão refletir essa gravação (do ponto de vista que o sistema promete). Normalmente isso significa ler do leader ou esperar confirmações de réplicas.
- Consistência eventual: o sistema vai convergir, mas uma leitura pode temporariamente retornar dados antigos.
Em setups shardados, frequentemente você acaba com consistência forte dentro de um shard e garantias mais fracas entre shards, especialmente quando operações multi-shard estão envolvidas.
“Fonte única da verdade” quando os dados estão divididos
Com sharding, “fonte única da verdade” tipicamente significa: para cada pedaço de dado, existe um lugar autoritativo para escrevê-lo (geralmente o leader do shard). Mas globalmente não há uma máquina que possa confirmar instantaneamente o estado mais recente de tudo. Você tem muitas verdades locais que devem ser mantidas em sincronia via replicação.
Restrições globais: unicidade, foreign keys, contadores
Restrições são complicadas quando os dados a checar vivem em shards diferentes:
- Unicidade (ex.: username): fazer valer “sem duplicatas em qualquer lugar” pode exigir um índice centralizado, um “shard de restrição” dedicado ou um fluxo de reserva no aplicativo.
- Foreign keys: se parent e child estiverem em shards diferentes, o banco não pode facilmente impor integridade referencial sem coordenação cross-shard.
- Contadores (totais globais, IDs sequenciais): abordagens ingênuas criam gargalo. Correções comuns incluem ranges por shard, batching ou aceitar contagens aproximadas.
Essas escolhas não são apenas detalhes de implementação — elas definem o que “correto” significa para seu produto.
Reequilíbrio e resharding sem downtime
Reequilíbrio é o que mantém um banco shardado utilizável conforme a realidade muda. Dados crescem de forma desigual, uma chave aparentemente balanceada deriva para skew, você adiciona novos nós por capacidade ou precisa aposentar hardware. Qualquer um desses pode transformar um shard em gargalo — mesmo que o design original parecesse perfeito.
Por que é difícil
Ao contrário de um banco único, o sharding incorpora a localização dos dados na lógica de roteamento. Quando você move dados, não está apenas copiando bytes — está mudando onde consultas precisam ir. Isso significa que reequilibrar é tanto sobre metadata e clientes quanto sobre armazenamento.
Padrão de migração online (copiar → sobreposição → cutover)
A maioria das equipes mira num fluxo online que evita uma grande janela de "parar o mundo":
- Copiar: backfill dos shards fonte para os shards alvo enquanto o sistema está ao vivo.
- Dual-write (às vezes dual-read): durante a transição, escreva novas mudanças tanto no local antigo quanto no novo. Leituras podem consultar ambos (ou usar regra “novo vence”) até você ter confiança.
- Cutover: atualize o mapa de shards para que roteadores/clients enviem tráfego ao novo local.
- Limpeza: pare dual-writes, remova a cópia antiga e compacte/recupere espaço.
Mapas de shards e comportamento do cliente
Uma mudança no mapa de shards é um evento disruptivo se clientes cachearem decisões de roteamento. Bons sistemas tratam metadata de roteamento como configuração: versionam, atualizam com frequência e são explícitos sobre o que acontece quando um cliente alcança uma chave movida (redirecionar, retry ou proxy).
Riscos operacionais para planejar
Reequilíbrio costuma causar quedas temporárias de desempenho (gravações extras, perda de cache, carga de cópia em background). Movimentos parciais são comuns — alguns ranges migram antes de outros — então você precisa de boa observabilidade e um plano de rollback (por exemplo, reverter o mapa e drenar dual-writes) antes do cutover.
Sharding pressupõe que o trabalho vai se espalhar. A surpresa é que um cluster pode parecer “uniforme” no papel (mesmo número de linhas por shard) enquanto se comporta de forma muito desigual em produção.
Partições quentes (hot keys)
Um hotspot acontece quando uma pequena fatia do espaço de chave recebe a maior parte do tráfego — pense numa conta de celebridade, um produto popular, um tenant rodando batch pesado ou uma chave baseada em tempo onde “hoje” atrai todas as gravações. Se essas chaves mapearem para um shard, aquele shard vira gargalo mesmo que os outros estejam ociosos.
Skew: tamanho dos dados vs tráfego
“Skew” não é uma coisa só:
- Skew de dados: um shard guarda mais bytes/linhas (pressão de armazenamento, backups mais longos, scans mais lentos).
- Skew de tráfego: um shard atende mais QPS ou queries mais pesadas (saturação de CPU, enfileiramento, picos de latência).
Eles nem sempre coincidem. Um shard com menos dados pode ser o mais quente se possuir as chaves mais requisitadas.
Como detectar rapidamente
Você não precisa de tracing sofisticado para achar skew. Comece com dashboards por shard:
- p95 por shard (um p95 divergente é sinal de alerta)
- QPS (e write QPS) por shard
- Armazenamento usado / tamanho de tabela por shard
Se a latência de um shard sobe com seu QPS enquanto os outros ficam estáveis, provavelmente você tem um hotspot.
Mitigações
Correções normalmente trocam simplicidade por balanceamento:
- Escolha uma chave de shard que espalhe tráfego, não apenas registros.
- Adicione bucketing/salting para chaves quentes (divida uma chave lógica entre múltiplos buckets físicos).
- Use cache para itens de leitura pesada.
- Aplique rate limits ou quotas por tenant para proteger o cluster.
- Divida shards quentes (ou mova ranges quentes) quando um shard não puder ser resfriado.
Modos de falha e debugging em um sistema shardado
Escolha uma chave de shard
Use o Modo de Planejamento para mapear chaves de shard, caminhos de consulta e etapas de migração antes de codificar.
Sharding não só adiciona mais servidores — adiciona mais maneiras de algo dar errado e mais lugares para olhar quando isso acontece. Muitos incidentes não são “o banco está fora”, mas “um shard está fora” ou “o sistema não concorda sobre onde os dados vivem”.
Modos de falha comuns
Alguns padrões aparecem repetidamente:
- Um shard indisponível (crash, disco cheio, longos pauses de GC), causando outages parciais: alguns clientes funcionam, outros falham.
- Roteador enviando tráfego para o lugar errado, frequentemente após mudança de config ou deploy ruim. Leituras podem retornar silenciosamente vazio se forem ao shard errado.
- Metadata stale ou inconsistente (ex.: mapa de shards, tabela de diretório). Durante moves ou splits, componentes diferentes podem rotear a mesma chave de formas distintas.
- Problemas de rede parcial: timeouts entre roteadores e um subconjunto de shards podem parecer erros “aleatórios” e disparar retries que amplificam carga.
Como o debugging muda
Num banco de nó único você taila um log e checa um conjunto de métricas. Num sistema shardado, você precisa de observabilidade que siga uma requisição pelos shards.
Use correlation IDs em cada requisição e propague-os da camada de API pelos roteadores até cada shard. Combine isso com tracing distribuído para que uma consulta scatter-gather mostre qual shard foi lento ou falhou. Métricas devem ser quebradas por shard (latência, profundidade de fila, taxa de erro), caso contrário um shard quente se perde em médias do fleet.
Incidentes de correção de dados
Falhas em sharding frequentemente aparecem como bugs de correção:
- Duplicados após retries ou gravações não idempotentes.
- Linhas faltando quando uma migração moveu dados, mas roteamento ainda aponta para o local antigo.
- Writes em split-brain se duas visões de metadata aceitarem gravações para a mesma faixa.
Backup, restore e recuperação de desastre
“Restaurar o banco” vira “restaurar muitas partes na ordem certa”. Você pode precisar restaurar metadata primeiro, depois cada shard, e então verificar que limites de shard e regras de roteamento batem com o ponto no tempo restaurado. Planos de DR devem incluir ensaios que provem que você consegue remontar um cluster consistente — não apenas recuperar máquinas individuais.
Quando não shardar: alternativas práticas e checklist de decisão
Sharding costuma ser tratado como o “botão de escala”, mas também é um aumento permanente de complexidade do sistema. Se você pode atingir metas de desempenho e confiabilidade sem dividir dados entre nós, normalmente terá uma arquitetura mais simples, debugging mais fácil e menos casos-limite operacionais.
Alternativas práticas que compram muito fôlego
Antes de shardar, tente opções que preservem um banco lógico único:
- Melhor indexação + tuning de queries: corrija caminhos lentos primeiro — índices faltantes, queries sem limites, joins caros e padrões N+1.
- Cache: coloque respostas de leitura estáveis atrás de cache (cache na app, CDN para conteúdo público ou um cache em memória para chaves quentes).
- Réplicas de leitura: descarregue tráfego de leitura sem mudar o caminho de escrita (aceitando lag de réplica quando OK).
- Particionamento de tabelas num nó: muitos bancos suportam particionamento que melhora manutenção e performance sem roteamento cross-node.
Onde ferramentas ajudam: prototipar serviços shard-aware sem se comprometer demais
Uma forma prática de reduzir risco é prototipar o encanamento (limites de roteamento, idempotência, workflows de migração e observabilidade) antes de comprometer o banco de produção.
Por exemplo, com Koder.ai você pode rapidamente levantar um serviço pequeno e realista a partir de um chat — muitas vezes uma UI admin em React mais um backend em Go com PostgreSQL — e experimentar APIs conscientes da chave de shard, chaves de idempotência e comportamentos de “cutover” em um sandbox seguro. Como Koder.ai suporta modo de planejamento, snapshots/rollback e exportação de código, você pode iterar em decisões de design relacionadas a sharding (como roteamento e forma da metadata) e então levar o código e runbooks resultantes para a stack principal quando estiver confiante.
Quando sharding faz sentido (e quando não)
Sharding é mais adequado quando seu dataset ou throughput de escrita claramente excede limites de um nó e seus padrões de query conseguem usar uma chave de shard (poucas joins entre shards, mínimo de consultas scatter-gather).
É uma má escolha quando seu produto precisa de muitas queries ad-hoc, transações multi-entidade frequentes, restrições globais de unicidade ou quando a equipe não pode suportar a carga operacional (reequilíbrio, resharding, resposta a incidentes).
Checklist rápido de decisão
Pergunte:
- Workload: O gargalo é CPU, I/O, memória ou contenção de locks — e isso pode ser resolvido sem sharding?
- Padrões de query: 90%+ das queries críticas podem ser roteadas por uma chave de shard?
- Capacidade da equipe: Quem é responsável pelo mapa de shards, runbooks on-call e comportamento de transações cross-shard?
- SLOs: Você pode tolerar degradação parcial (um shard down) e latências de cauda mais longas?
Planeje para crescimento, não apenas um diagrama
Mesmo se você adiar sharding, projete um caminho de migração: escolha identificadores que não bloqueiem uma futura chave de shard, evite hardcode de suposições de nó único e ensaie como moveria dados com downtime mínimo. O melhor momento para planejar resharding é antes de você precisar dele.