Por que essas escolhas não são independentes
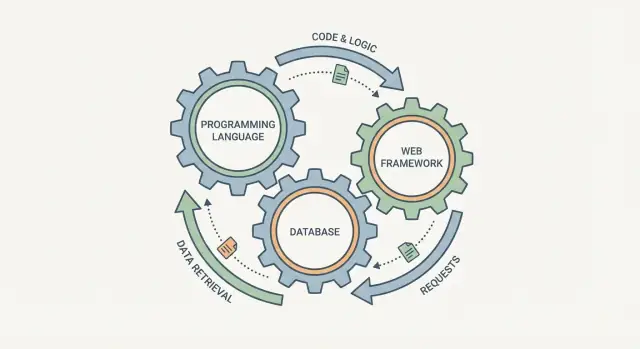
É tentador escolher uma linguagem de programação, um banco de dados e um framework web como três checkboxes separados. Na prática, eles se comportam mais como engrenagens conectadas: você muda uma e as outras sentem.
Um framework web molda como requisições são tratadas, como dados são validados e como erros aparecem. O banco de dados define o que é “fácil de armazenar”, como você consulta informações e quais garantias obtém quando vários usuários agem ao mesmo tempo. A linguagem fica no meio: determina quão seguro é expressar regras, como você gerencia concorrência e que bibliotecas e ferramentas estão disponíveis.
O que significa “um sistema"
Tratar a stack como um único sistema significa que você não otimiza cada parte isoladamente. Você escolhe uma combinação que:
- Representa seus dados naturalmente (para não ficar lutando contra conversões)
- Suporta suas necessidades de consistência (para que bugs não se escondam em casos de borda)
- Se encaixa no fluxo de trabalho da equipe (para que enviar e manter seja previsível)
Este artigo é prático e intencionalmente não excessivamente técnico. Você não precisa memorizar teoria de banco de dados ou internals de linguagem—apenas ver como escolhas reverberam em toda a aplicação.
Um exemplo rápido: usar um banco sem esquema para dados empresariais altamente estruturados e orientados a relatórios frequentemente leva a “regras” espalhadas no código da aplicação e análises confusas depois. Uma combinação melhor é parear esse mesmo domínio com um banco relacional e um framework que incentive validação consistente e migrations, para que os dados permaneçam coerentes conforme o produto evolui.
Quando você planeja a stack em conjunto, está projetando um conjunto de compensações — não três apostas separadas.
Um modelo mental simples: requisição entra, dados saem
Uma forma útil de pensar sobre “stack” é como um único pipeline: uma requisição do usuário entra no sistema e uma resposta (mais dados salvos) sai. A linguagem de programação, o framework web e o banco de dados não são escolhas independentes — são três partes da mesma jornada.
A jornada de uma requisição
Imagine um cliente atualizando seu endereço de entrega.
- Requisição entra: O framework recebe uma requisição HTTP. O roteamento decide qual handler executa (por exemplo,
/account/address). A validação verifica se os dados são completos e coerentes.
- Trabalho acontece: O código da aplicação (na linguagem escolhida) executa as regras de negócio: “o usuário está logado?”, “o formato do endereço é aceitável?”, “devemos marcar este pedido para rechecagem?”
- Dados saem: A camada de banco lê e grava registros—frequentemente dentro de uma transação—para que a atualização seja aplicada por completo ou não seja aplicada.
- Resposta sai: O framework formata o resultado (HTML/JSON), define códigos de status e retorna ao usuário.
- Depois: Jobs em background podem rodar (enviar e-mail de confirmação, atualizar índice de busca, notificar o armazém).
Do que cada escolha realmente é responsável
- Linguagem: Como o código roda (runtime/modelo de concorrência), quão fácil é testar e depurar, e se as habilidades da equipe e as ferramentas tornam mudanças seguras e rápidas.
- Framework: O “controle de tráfego” para requisições—roteamento, validação, hooks de autenticação, tratamento de erros e padrões embutidos para jobs em background.
- Banco de dados: Como os dados são armazenados e consultados, que constraints impedem dados ruins e como transações mantêm atualizações relacionadas consistentes.
Quando esses três se alinham, uma requisição flui limpidamente. Quando não, você obtém atrito: acesso a dados desconfortável, validação que vaza e bugs sutis de consistência.
Modelo de dados em primeiro lugar: o condutor oculto do ajuste da stack
Muitas discussões sobre “stack” começam pela linguagem ou pelo banco. Um ponto de partida melhor é seu modelo de dados — porque ele dita silenciosamente o que vai parecer natural (ou doloroso) em todos os lugares: validação, consultas, APIs, migrations e até o fluxo de trabalho da equipe.
Aplicações usualmente lidam com quatro formas ao mesmo tempo:
- Objetos no código (classes, structs, registros tipados)
- Linhas em tabelas relacionais
- Documentos em armazenamento estilo JSON ou APIs
- Eventos em logs/streams (“OrderPlaced”, “EmailSent”)
Um bom ajuste é quando você não passa o dia traduzindo entre formas. Se seus dados centrais são altamente conectados (usuários ↔ pedidos ↔ produtos), linhas e joins podem manter a lógica simples. Se os dados são majoritariamente “um blob por entidade” com campos variáveis, documentos reduzem cerimônias—até que você precise de relatórios entre entidades.
Esquema vs estrutura flexível (e onde as regras vivem)
Quando o banco tem um esquema forte, muitas regras podem ficar perto dos dados: tipos, restrições, chaves estrangeiras, unicidade. Isso frequentemente reduz verificações duplicadas entre serviços.
Com estruturas flexíveis, regras migram para a aplicação: código de validação, payloads versionados, backfills e leitura cuidadosa (“se campo existir, então…”). Isso funciona bem quando requisitos de produto mudam semanalmente, mas aumenta o peso sobre o framework e os testes.
Como escolhas de modelagem afetam a complexidade do código
Seu modelo decide se seu código é principalmente:
- Consultas e joins (foco relacional)
- Transformação de JSON aninhado (foco em documentos)
- Reprodução e agregação de eventos (foco em eventos)
Isso, por sua vez, influencia necessidades de linguagem e framework: tipagem forte pode evitar desvios sutis em campos JSON, enquanto ferramentas maduras de migration importam mais quando esquemas evoluem frequentemente.
Exemplos: perfil de usuário, pedidos, log de auditoria
- Perfil de usuário: frequentemente parecido com documento (preferências, campos opcionais) mas se beneficia de constraints relacionais para identidade e unicidade.
- Pedidos: tipicamente relacionais (itens, totais, status) porque consistência e relatórios importam.
- Log de auditoria: naturalmente em formato de evento—entradas append-only que raramente são atualizadas, otimizadas para consultas por tempo, ator ou entidade.
Escolha o modelo primeiro; a escolha “certa” de framework e banco frequentemente fica clara depois.
Transações e consistência: onde os bugs geralmente começam
Transações são as garantias “tudo ou nada” das quais sua aplicação depende silenciosamente. Quando um checkout funciona, você espera que o registro do pedido, o status do pagamento e a atualização de inventário ou tudo aconteçam—ou nada aconteça. Sem essa promessa, aparecem os bugs mais difíceis: raros, caros e difíceis de reproduzir.
O que transações realmente fazem
Uma transação agrupa múltiplas operações de banco em uma unidade de trabalho. Se algo falha no meio (erro de validação, timeout, processo que caiu), o banco pode fazer rollback para o estado seguro anterior.
Isso importa além de fluxo de dinheiro: criação de conta (linha de usuário + linha de perfil), publicação de conteúdo (post + tags + ponteiros de índice de busca) ou qualquer workflow que toque mais de uma tabela.
Consistência vs velocidade (em termos simples)
Consistência significa “leituras batem com a realidade”. Velocidade significa “retornar algo rapidamente”. Muitos sistemas fazem trade-offs aqui:
- Consistência forte: usuários veem os dados mais recentes confirmados, menos surpresas, geralmente maior custo de coordenação.
- Consistência eventual: atualizações propagam ao longo do tempo, normalmente mais rápido e mais fácil de escalar, mas sua aplicação deve lidar com discrepâncias temporárias.
O padrão de falha comum é escolher uma configuração eventualmente consistente e depois codar como se fosse fortemente consistente.
Como frameworks e ORMs influenciam os resultados
Frameworks e ORMs não criam transações automaticamente só porque você chamou vários métodos de “save”. Alguns exigem blocos de transação explícitos; outros iniciam uma transação por requisição, o que pode esconder problemas de desempenho.
Retries também são complicados: ORMs podem reexecutar em deadlocks ou falhas transitórias, mas seu código precisa ser seguro para rodar duas vezes.
Armadilhas comuns
Gravações parciais acontecem quando você atualiza A e falha antes de atualizar B. Ações duplicadas acontecem quando uma requisição é reexecutada após um timeout—especialmente se você cobrou um cartão ou enviou um e-mail antes do commit.
Uma regra simples ajuda: faça efeitos colaterais (e-mails, webhooks) após o commit do banco, e torne ações idempotentes com constraints de unicidade ou chaves de idempotência.
Camada de acesso ao banco: ORM, queries e migrations
Esta camada é a “tradução” entre seu código e o banco. As escolhas aqui frequentemente importam mais no dia a dia do que a marca do banco em si.
ORM vs construtor de queries vs SQL cru (em termos simples)
Um ORM (Object-Relational Mapper) permite tratar tabelas como objetos: criar um User, atualizar um Post e o ORM gera SQL por trás. Pode ser produtivo porque padroniza tarefas comuns e esconde repetição.
Um query builder é mais explícito: você constrói uma query estilo SQL usando código (cadeias ou funções). Você ainda pensa em “joins, filtros, grupos”, mas ganha segurança de parâmetros e composabilidade.
SQL cru é escrever SQL diretamente. É mais direto e muitas vezes mais claro para consultas complexas de relatório—ao custo de mais trabalho manual e convenções.
Como recursos da linguagem moldam padrões de acesso
Linguagens com tipagem forte (TypeScript, Kotlin, Rust) tendem a empurrar para ferramentas que validam queries e formatos de resultado cedo. Isso reduz surpresas em tempo de execução, mas pressiona equipes a centralizar acesso a dados para que tipos não se dispersem.
Linguagens com metaprogramação flexível (Ruby, Python) muitas vezes fazem ORMs parecerem naturais e rápidos para iterar—até que queries ocultas ou comportamentos implícitos fiquem difíceis de entender.
Migrations: manter código e esquema em sincronia
Migrations são scripts de mudança versionados para seu esquema: adicionar coluna, criar índice, backfill de dados. O objetivo é simples: qualquer pessoa consegue fazer deploy do app e ter a mesma estrutura de banco. Trate migrations como código que você revisa, testa e reverte quando necessário.
Quando abstrações “fáceis” prejudicam
ORMs podem gerar silenciosamente N+1 queries, buscar linhas enormes que você não precisa ou tornar joins complicados. Query builders podem virar cadeias ilegíveis. SQL cru pode ser duplicado e inconsistente.
Uma boa regra: use a ferramenta mais simples que mantenha a intenção óbvia—e, para caminhos críticos, inspecione o SQL que realmente roda.
Valide sua stack rapidamente
Transforme suas hipóteses sobre a stack em um app funcional que você pode testar em dias, não semanas.
As pessoas frequentemente culpam “o banco” quando uma página está lenta. Mas a latência visível pelo usuário é a soma de múltiplas pequenas esperas ao longo de toda a requisição.
De onde a latência realmente vem
Uma única requisição costuma pagar por:
- Tempo de rede (cliente → load balancer → app → banco e retorno)
- Tempo de query (SQL lento, índices ausentes, muitos round trips)
- Serialização/deserialização (JSON, mapeamento do ORM, compressão)
- Lógica do app (validação, permissões, renderização, chamadas externas)
Mesmo que seu banco responda em 5 ms, um app que faz 20 queries por requisição, bloqueia em I/O e gasta 30 ms serializando uma resposta gigante ainda parecerá lento.
Abrir uma conexão de banco é caro e pode sobrecarregar o BD sob carga. Um connection pool reutiliza conexões existentes para que requisições não paguem esse custo repetidamente.
O problema: o “tamanho certo” do pool depende do modelo de runtime. Um servidor assíncrono altamente concorrente pode criar demanda massiva; sem limites, você terá enfileiramento, timeouts e falhas barulhentas. Com limites muito restritos, seu app vira gargalo.
Cache: o que resolve — e o que não resolve
Cache pode ficar no navegador, CDN, cache em processo ou cache compartilhado (como Redis). Ajuda quando muitas requisições precisam dos mesmos resultados.
Mas cache não resolverá:
- Caminhos de escrita ineficientes
- Respostas altamente personalizadas
- Endpoints lentos dominados por APIs externas
Runtime importa: threads vs async
O runtime da linguagem molda rendimento. Modelos thread-per-request podem desperdiçar recursos enquanto aguardam I/O; modelos async aumentam concorrência, mas também tornam backpressure (como limites de pool) essenciais. Por isso ajuste de performance é uma decisão de stack, não apenas de banco.
Segurança e confiabilidade: responsabilidade compartilhada na stack
Segurança não é algo que você “adiciona” com um plugin do framework ou uma configuração de banco. É o acordo entre linguagem/runtime, framework web e banco sobre o que deve sempre ser verdade—mesmo quando um desenvolvedor erra ou um novo endpoint é adicionado.
Autenticação vs autorização: camadas diferentes, mesmo resultado
Autenticação (quem é este?) costuma viver na borda do framework: sessions, JWTs, callbacks OAuth, middleware. Autorização (o que ele pode fazer?) deve ser aplicada de forma consistente tanto na lógica da aplicação quanto nas regras de dados.
Um padrão comum: o app decide a intenção (“usuário pode editar este projeto”) e o banco reforça limites (tenant IDs, constraints de propriedade e—quando faz sentido—políticas por linha). Se autorização existe apenas em controllers, jobs e scripts internos podem contorná-la acidentalmente.
Validação: framework, banco ou ambos?
Validação no framework dá feedback rápido e mensagens amigáveis. Constraints no banco fornecem uma rede de segurança final.
Use ambos quando importar:
- Framework: campos obrigatórios, formatos, mensagens amigáveis.
- Banco: unicidade, chaves estrangeiras,
CHECK, NOT NULL.
Isso reduz “estados impossíveis” que surgem quando duas requisições concorrem ou um novo serviço escreve dados diferente.
Segredos, criptografia e auditoria
Segredos devem ser tratados pelo runtime e workflow de deploy (env vars, secret managers), não hardcoded no código ou migrations. Criptografia pode acontecer na aplicação (criptografia por campo) e/ou no banco (encriptação em repouso, KMS gerenciado), mas é preciso clareza sobre quem rotaciona chaves e como funciona a recuperação.
Auditoria também é compartilhada: o app deve emitir eventos significativos; o banco deve guardar logs imutáveis quando apropriado (por exemplo, tabelas de auditoria append-only com acesso restrito).
Modos comuns de falha
Confiar demais na lógica da aplicação é o clássico: constraints faltando, nulos silenciosos, flags de “admin” sem verificações. A correção é simples: assuma que bugs vão acontecer e desenhe a stack para que o banco recuse gravações inseguras—mesmo vindas do seu próprio código.
Caminhos de escalabilidade: o que cada escolha desbloqueia ou bloqueia
Conecte UI e API
Levante um front-end em React conectado a endpoints reais para que o fluxo de requisições fique claro.
Escalar raramente falha porque “o banco não aguenta”. Falha porque a stack inteira reage mal quando a carga muda de forma: um endpoint fica popular, uma query vira hot, um workflow começa a reexecutar.
Quando o tráfego cresce, a dor aparece em lugares específicos
A maioria das equipes encontra os mesmos gargalos iniciais:
- Queries quentes: uma query de “página top” ou dashboard roda constantemente e domina CPU/IO.
- Contention de locks: atualizações se acumulam atrás de poucas linhas (contadores de inventário,
last_seen, tabelas de fila), deixando tudo lento.
- Pressão de conexões: workers abrem conexões demais; o banco gasta tempo gerenciando sessões em vez de trabalhar.
Se você pode responder rápido depende de quão bem seu framework e ferramentas do banco expõem planos de query, migrations, pooling e padrões seguros de cache.
Réplicas de leitura, sharding e filas: quando aparecem
Movimentos de escalabilidade comuns tendem a surgir nesta ordem:
- Réplicas de leitura quando leituras superam escritas e você tolera dados ligeiramente defasados. Seu ORM/framework deve suportar dividir leitura/escrita (ou facilitar roteamento de queries).
- Filas/jobs quando trabalho “faça agora” começa a prejudicar latência de requisição (e-mails, exports, chamadas de cobrança). Aqui retries e deduplicação viram requisitos reais.
- Sharding/particionamento quando um único primário não suporta throughput de escrita ou crescimento de armazenamento. Isso exige modelagem cuidadosa: chaves de shard, consultas cross-shard e limites de transação.
Trabalho em background e idempotência são funcionalidades do framework, não detalhes
Uma stack escalável precisa de suporte nativo a tarefas em background, agendamento e retries seguros.
Se seu sistema de jobs não consegue impor idempotência (o mesmo job rodar duas vezes sem cobrança dupla ou envio duplicado), você vai “escalar” para corrupção de dados. Escolhas iniciais—como confiar em transações implícitas, constraints fracas ou comportamentos opacos do ORM—podem bloquear a introdução limpa de filas, patterns de outbox ou workflows aproximadamente "exactly-once" mais tarde.
Alinhamento inicial compensa: escolha um banco que case com suas necessidades de consistência e um ecossistema de framework que torne o próximo passo de escala (réplicas, filas, particionamento) um caminho suportado, não uma reescrita.
Experiência do desenvolvedor e operações: um único fluxo de trabalho
Uma stack parece “fácil” quando desenvolvimento e operações compartilham as mesmas suposições: como você inicia o app, como os dados mudam, como testes rodam e como saber o que aconteceu quando algo quebra. Se essas peças não se alinham, equipes perdem tempo com glue code, scripts frágeis e runbooks manuais.
Velocidade de desenvolvimento local
Configuração local rápida é um recurso. Prefira um fluxo onde um novo colega clone, instale, rode migrations e tenha dados de teste realistas em minutos—não horas.
Isso geralmente significa:
- Um comando para subir o app e dependências (frequentemente via containers).
- Migrations que rodam de forma confiável em qualquer máquina.
- Dados seed que correspondam ao formato de produção (não apenas linhas “hello world”).
Se o tooling de migrations do framework briga com sua escolha de banco, cada mudança de esquema vira um pequeno projeto.
Sua stack deve tornar natural escrever:
- Testes unitários que não exigem banco.
- Testes de integração que usam o esquema real do banco e consultas.
- Testes end-to-end que exercitam todo o caminho da requisição.
Um modo de falha comum: equipes se apoiam demais em unit tests porque testes de integração são lentos ou difíceis. Isso normalmente é um desajuste de stack/ops—provisionamento de banco de teste, migrations e fixtures não estão automatizados.
Observabilidade no app e no banco
Quando a latência sobe, você precisa seguir uma requisição pelo framework até o banco.
Busque logs estruturados, métricas básicas (taxa de requisições, erros, tempo em BD) e traces que incluam tempo de queries. Mesmo um ID de correlação simples que apareça em logs do app e do banco transforma “adivinhação” em “encontro do problema”.
Ajuste operacional: mudanças seguras e recuperação
Operações não são separadas do desenvolvimento; são sua continuação.
Escolha ferramentas que suportem:
- Backups e restores testados (não apenas configurados).
- Mudanças de esquema que possam avançar com segurança (e ocasionalmente reverter).
- Um caminho claro do que acontece durante o deploy para que releases não dependam do conhecimento tribal.
Se você não consegue ensaiar um restore ou migration localmente com confiança, não fará bem sob pressão.
Checklist prático para escolher uma stack coerente
Escolher uma stack é menos sobre ferramentas “melhores” e mais sobre ferramentas que se encaixam sob suas restrições reais. Use este checklist para forçar alinhamento cedo.
1) Checklist rápido (encaixe antes de recursos)
- Habilidades da equipe: O que sua equipe consegue entregar e manter com confiança por 12–24 meses?
- Forma do domínio: Principalmente workflows e registros, regras complexas ou muitos relatórios?
- Necessidades de dados: Integridade relacional, documentos flexíveis, séries temporais, busca full-text, analytics?
- Restrições: Compliance, metas de latência, modelo de deploy, orçamento, infraestrutura existente.
- Tolerância a falhas: Aceita consistência eventual ou precisa de transações estritas?
2) Mapeie seu produto para padrões comuns
- App CRUD-heavy (ferramentas internas, back office, SaaS inicial): Framework web convencional + BD relacional costuma ser o caminho mais rápido porque migrations, transações e fluxos administrativos são diretos.
- Foco em analytics (dashboards, tracking): Planeje uma store OLAP ou data warehouse cedo; tentar “fazer Postgres virar um sistema de BI” pode prejudicar consultas e evolução do produto.
- Tempo real (chat, colaboração, streaming): Priorize suporte a WebSocket, pub/sub e concorrência previsível. A escolha de linguagem/runtime influencia o quanto isso é doloroso.
- SaaS multi-tenant: Decida cedo: bancos separados, schemas separados ou tenancy por linha. Essa escolha se espalha para auth, migrations e operações de suporte.
3) Execute um pequeno proof of concept (sem overbuild)
Time-box para 2–5 dias. Construa uma fatia vertical fina: um workflow central, um job em background, uma consulta tipo relatório e auth básica. Meça fricção do desenvolvedor, ergonomia de migrations, clareza das queries e facilidade de testar.
Se quiser acelerar, uma ferramenta de vibe-coding como Koder.ai pode ajudar a gerar rapidamente uma fatia vertical funcional (UI, API e banco) a partir de uma especificação por chat—então iterar com snapshots/rollback e exportar o código quando decidir seguir adiante.
4) Escreva um registro de decisão de uma página
Title:
Date:
Context (what we’re building, constraints):
Options considered:
Decision (language/framework/database):
Why this fits (data model, consistency, ops, hiring):
Risks \u0026 mitigations:
When we’ll revisit:
Desajustes comuns (e como evitá-los)
Experimente duas stacks, rápido
Gere duas variantes pequenas e compare migrações, consultas e atrito para desenvolvedores lado a lado.
Mesmo equipes fortes acabam com mismatches de stack—escolhas que parecem bem isoladamente, mas criam atrito quando o sistema está em produção. A boa notícia: a maioria é previsível e evitável com alguns checagens.
Cheiros a observar
Um cheiro clássico é escolher um banco ou framework porque está em alta enquanto seu modelo de dados ainda é vago. Outro é escalar prematuramente: otimizar para milhões de usuários antes de lidar bem com centenas, o que frequentemente leva a infraestrutura extra e mais modos de falha.
Também fique atento a stacks onde a equipe não consegue explicar por que cada peça existe. Se a resposta é “todo mundo usa”, você está acumulando risco.
Riscos de integração que mordem depois
Muitos problemas aparecem nas bordas:
- Drivers e features incompatíveis: o driver da sua linguagem não suporta totalmente recursos do banco que você presumiu (tipos, streaming, retries).
- Migrations fracas: mudanças de esquema gerenciadas manualmente ou ferramentas que não acompanham evolução do app, causando drift entre ambientes.
- Pooling ruim: frameworks que abrem conexões demais, ou deploys que multiplicam pools entre processos/containers, levando a timeouts sob carga.
Isso não é “problema do banco” nem “problema do framework”—são problemas de sistema.
Como simplificar (e reduzir risco)
Prefira menos partes móveis e um caminho claro para tarefas comuns: uma abordagem de migrations, um estilo de query para a maioria das features e convenções consistentes entre serviços. Se o framework incentiva um padrão (lifecycle de requisição, injeção de dependência, pipeline de jobs), siga-o em vez de misturar estilos.
Revise escolhas quando houver incidentes recorrentes em produção, fricção persistente de desenvolvedor ou quando novos requisitos de produto mudarem fundamentalmente o acesso a dados.
Mude com segurança isolando a seam: introduza uma camada adaptadora, migre incrementalmente (dual-write ou backfill quando necessário) e prove paridade com testes automatizados antes de redirecionar o tráfego.
Conclusão: trate a stack como um único sistema
Escolher linguagem, framework web e banco de dados não são três decisões independentes—é um design de sistema expresso em três lugares. A “melhor” opção é a combinação que se alinha com a forma dos seus dados, suas necessidades de consistência, o fluxo de trabalho da equipe e como você espera que o produto cresça.
O que levar
- Escolha a stack em torno do seu modelo de dados central e das operações que você realiza com mais frequência.
- Consistência e transações também são preocupações de aplicação—projete de ponta a ponta, não apenas no banco.
- Gargalos de performance normalmente cruzam limites (esquema, queries, cache, serialização, filas).
- Segurança e confiabilidade são responsabilidade compartilhada entre código, configuração e operações.
- Experiência do desenvolvedor importa porque determina quão rápido você pode entregar com segurança.
Documente suposições (antes que virem restrições)
Anote as razões por trás de suas escolhas: padrões de tráfego esperados, latência aceitável, regras de retenção de dados, modos de falha toleráveis e o que você não está otimizando agora. Isso torna trade-offs visíveis, ajuda novos colegas a entender o “porquê” e evita drift arquitetural quando requisitos mudarem.
Próximos passos
Passe seu setup atual pelo checklist e anote onde decisões não se alinham (por exemplo, um esquema que disputa com o ORM, ou um framework que torna jobs de background desconfortáveis).
Se estiver explorando uma nova direção, ferramentas como Koder.ai também podem ajudar a comparar suposições de stack rapidamente gerando um app base (comum: React na web, serviços em Go com PostgreSQL e Flutter para mobile) que você pode inspecionar, exportar e evoluir—sem se comprometer com um ciclo longo de desenvolvimento inicial.
Para acompanhamento mais profundo, navegue por guias relacionados em /blog, procure detalhes de implementação em /docs ou compare opções de suporte e deploy em /pricing.