Por que o MySQL se tornou uma base para a web inicial
O MySQL virou o banco de dados preferido da web inicial por uma razão simples: ele correspondia ao que os sites precisavam na época — armazenar e recuperar dados estruturados rapidamente, rodar em hardware modesto e ser fácil de operar por equipes pequenas.
Era acessível. Você conseguia instalar rápido, conectar a partir das linguagens mais comuns e fazer um site funcionar sem contratar um DBA dedicado. Essa mistura de “desempenho bom o suficiente” e baixo custo operacional tornou-o padrão para startups, projetos pessoais e empresas em crescimento.
O que “escalar” realmente significa aqui
Quando as pessoas dizem que o MySQL “escalou”, geralmente querem dizer uma combinação de:
- Crescimento de tráfego: mais usuários concorrentes e mais consultas por segundo.
- Crescimento de dados: tabelas saindo de milhares de linhas para milhões ou bilhões.
- Expectativas de confiabilidade: manter-se online durante crashes, deploys e falhas de hardware.
- Restrições de custo: alcançar o anterior sem orçamentos apenas para empresas.
Empresas da web iniciais não precisavam só de velocidade; precisavam de desempenho previsível e uptime mantendo o gasto com infraestrutura controlado.
As alavancas principais que vamos revisitar
A história do escalonamento do MySQL é, na prática, uma história de trade-offs práticos e padrões repetíveis:
- Design de esquema e consultas (o que armazenar, como juntar, o que evitar)
- Índices (a diferença entre “funciona no dev” e “funciona em produção”)
- Cache (não bater no banco a cada visualização)
- Replicação e réplicas de leitura (espalhar tráfego de leitura)
- Sharding/particionamento (dividir dados quando um banco único não dá conta)
Escopo deste artigo
Este é um passeio pelos padrões que equipes usaram para manter o MySQL performando sob tráfego web real — não um manual completo do MySQL. O objetivo é explicar como o banco se encaixou nas necessidades da web e por que as mesmas ideias ainda aparecem em sistemas de produção massivos hoje.
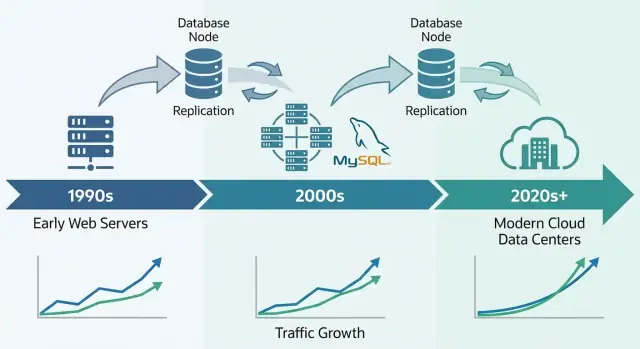
A era LAMP: como a simplicidade ajudou o MySQL a se espalhar
O momento do breakout do MySQL esteve fortemente ligado à ascensão da hospedagem compartilhada e de equipes pequenas construindo apps web rapidamente. Não era só que o MySQL era “bom o suficiente” — ele se encaixava em como a web inicial era deployada, gerida e paga.
O LAMP (Linux, Apache, MySQL, PHP/Perl/Python) funcionava porque alinhava com o servidor padrão que a maioria podia pagar: uma única máquina Linux rodando servidor web e banco de dados lado a lado.
Provedores de hospedagem podiam templatear esse setup, automatizar instalações e oferecê-lo barato. Desenvolvedores podiam assumir o mesmo ambiente básico quase em todos os lugares, reduzindo surpresas ao mover do desenvolvimento local para produção.
Simplicidade como estratégia de distribuição
O MySQL era simples de instalar, iniciar e conectar. Falava SQL familiar, tinha um cliente de linha de comando simples e integrava-se bem com linguagens e frameworks populares da época.
Igualmente importante, o modelo operacional era acessível: um processo principal, alguns arquivos de configuração e modos de falha claros. Isso tornava realista que sysadmins generalistas (e muitas vezes desenvolvedores) rodassem um banco sem treinamento especializado.
Custo, acessibilidade e momentum da comunidade
Ser open-source removeu atritos de licença iniciais. Um projeto estudantil, um fórum hobby e um pequeno site comercial podiam usar o mesmo motor de banco que empresas maiores.
Documentação, listas de discussão e, depois, tutoriais online criaram momentum: mais usuários significavam mais exemplos, mais ferramentas e resolução de problemas mais rápida.
As cargas iniciais que o MySQL atendia bem
A maioria dos sites iniciais era orientada a leitura e bem simples: fóruns, blogs, páginas CMS e catálogos de e‑commerce modestos. Essas aplicações tipicamente precisavam de buscas rápidas por ID, posts recentes, contas de usuário e filtros básicos — exatamente o tipo de workload que o MySQL tratava eficientemente em hardware modesto.
Pressões iniciais de escalabilidade: mais usuários, mais leituras, mais escritas
Implantações iniciais do MySQL frequentemente começavam como “um servidor, um banco, um app”. Isso funcionava bem para um fórum hobby ou site pequeno — até o app ficar popular. Visualizações se transformavam em sessões, sessões viravam tráfego constante, e o banco deixou de ser um componente silencioso nos bastidores.
Por que as leituras geralmente dominavam
A maioria das apps web era (e continua sendo) orientada a leitura. Uma homepage, lista de produtos ou página de perfil pode ser vista milhares de vezes para cada atualização única. Esse desequilíbrio moldou decisões iniciais de escalonamento: se você pudesse tornar as leituras mais rápidas — ou evitar bater no banco para leituras —, poderia servir muito mais usuários sem reescrever tudo.
O problema: mesmo apps com muitas leituras têm escritas críticas. Cadastros, compras, comentários e atualizações administrativas não podem ser perdidos. À medida que o tráfego cresce, o sistema precisa lidar com um dilúvio de leituras e escritas “que devem ter sucesso” ao mesmo tempo.
Os primeiros pontos de dor que as equipes sentiram
Com mais tráfego, problemas tornaram-se visíveis em termos simples:
- Consultas lentas: uma página que antes carregava instantaneamente agora “travava” quando uma consulta de relatório varria muitas linhas.
- Locks em tabelas: em alguns setups antigos, escritas podiam bloquear leituras (e vice‑versa), criando engarrafamentos.
- RAM limitada: índices e dados quentes não cabiam na memória, então o servidor bateva no disco com mais frequência — muito mais lento que RAM.
Separar responsabilidades cedo
Equipes aprenderam a dividir responsabilidades: o app trata a lógica de negócio, um cache absorve leituras repetidas, e o banco foca em armazenamento preciso e consultas essenciais. Esse modelo mental preparou o terreno para passos posteriores como tuning de queries, melhores índices e escalonamento com réplicas.