Qual problema o NoSQL tentava resolver?
NoSQL surgiu quando muitas equipes enfrentaram um descompasso entre o que suas aplicações precisavam e o que bancos relacionais tradicionais (bancos SQL) eram otimizados para fazer. O SQL não “falhou” — mas em escala web, algumas equipes começaram a priorizar objetivos diferentes.
As duas pressões: escala e mudança
Primeiro, escala. Aplicações de consumo populares passaram a ver picos de tráfego, escritas constantes e volumes massivos de dados gerados pelos usuários. Para essas cargas, “só comprar um servidor maior” ficou caro, lento de implantar e, no fim, limitado pelo maior equipamento que você poderia operar razoavelmente.
Segundo, mudança. Recursos de produto evoluíam rapidamente, e os dados por trás deles nem sempre cabiam bem em um conjunto fixo de tabelas. Adicionar novos atributos a perfis de usuário, armazenar múltiplos tipos de eventos ou ingerir JSON semiestruturado de diferentes fontes muitas vezes significava migrações repetidas de esquema e coordenação entre equipes.
Por que bancos relacionais tinham dificuldades em certos casos
Bancos relacionais são excelentes em impor estrutura e habilitar consultas complexas entre tabelas normalizadas. Mas algumas cargas em alta escala tornaram essas forças mais difíceis de aproveitar:
- Muitas escritas concorrentes em várias tabelas podem criar contenção.
- Consultas pesadas baseadas em joins podem ficar caras à medida que os dados crescem rapidamente.
- Escalar horizontalmente por várias máquinas é possível, mas operar isso mantendo consistência estrita pode ser complicado.
O resultado: algumas equipes buscaram sistemas que trocassem certas garantias por escalabilidade mais simples e iteração mais rápida.
NoSQL: uma família de abordagens, não uma coisa só
NoSQL não é um único banco ou design. É um termo-ombrella para sistemas que enfatizam alguma combinação de:
- Escala horizontal (adicionar mais máquinas)
- Modelos de dados flexíveis
- Padrões de acesso afinados para necessidades específicas da aplicação
Uma redefinição de expectativas
NoSQL nunca foi pensado como substituto universal do SQL. É um conjunto de trade-offs: você pode ganhar escalabilidade ou flexibilidade de esquema, mas aceitar garantias de consistência mais fracas, menos opções de consultas ad-hoc ou mais responsabilidade no modelamento de dados na aplicação.
Por que a escalabilidade tradicional começou a falhar
Por anos, a resposta padrão para um banco lento era direta: compre um servidor maior. Adicione mais CPU, mais RAM, discos mais rápidos e mantenha o mesmo esquema e modelo operacional. Esse approach de “escalar verticalmente” funcionou — até deixar de ser prático.
Escalar verticalmente esbarra em limites duros
Máquinas de ponta ficam rapidamente caras, e a curva preço/desempenho eventualmente fica desfavorável. Upgrades frequentemente exigem aprovações orçamentárias grandes e janelas de manutenção para mover dados e realizar o cutover. Mesmo se você puder pagar hardware maior, um único servidor ainda tem um teto: um barramento de memória, um subsistema de armazenamento e um nó primário absorvendo a carga de escrita.
Conforme produtos cresceram, bancos enfrentaram pressão constante de leitura/escrita em vez de picos ocasionais. O tráfego passou a ser 24/7, e certas funcionalidades criaram padrões de acesso desiguais. Um pequeno número de linhas ou partições muito acessadas podia dominar o tráfego, gerando tabelas (ou chaves) “quentes” que prejudicavam o resto.
Gargalos operacionais tornaram-se comuns:
- Inchaço de índices conforme novos recursos demandavam índices secundários
- Contenção por muitas escritas concorrentes batendo nas mesmas tabelas
- Espera por locks que tornava a latência imprevisível sob carga
- Lag na replicação e failovers mais lentos conforme os datasets cresciam
Servidores maiores não resolviam disponibilidade global
Muitas aplicações também precisavam estar disponíveis por várias regiões, não apenas rápidas em um data center. Um banco “principal” em um único local aumenta a latência para usuários distantes e torna falhas mais catastróficas. A questão passou de “como compramos uma caixa maior?” para “como executamos o banco em muitas máquinas e locais?”.
A necessidade de modelos de dados flexíveis
Bancos relacionais brilham quando a forma dos dados é estável. Mas muitos produtos modernos não param no mesmo ponto. Um esquema de tabela é intencionalmente estrito: cada linha segue o mesmo conjunto de colunas, tipos e restrições. Essa previsibilidade é valiosa — até você estar iterando rápido.
Esquemas rígidos e o custo real da mudança
Na prática, mudanças frequentes de esquema podem ser caras. Uma atualização aparentemente pequena pode exigir migrações, backfills, atualização de índices, planejamento de compatibilidade para caminhos de código antigos e deploys coordenados. Em tabelas grandes, até adicionar uma coluna ou mudar um tipo pode se tornar uma operação demorada com risco operacional real.
Essa fricção empurra equipes a adiar mudanças, acumular workarounds ou armazenar blobs desorganizados em campos de texto — nada disso é ideal para iteração rápida.
Muitos dados de aplicação são naturalmente semiestruturados: objetos aninhados, campos opcionais e atributos que evoluem ao longo do tempo.
Por exemplo, um “perfil de usuário” pode começar com nome e email, depois crescer para incluir preferências, contas vinculadas, endereços de entrega, configurações de notificação e flags de experimentos. Nem todo usuário tem todos os campos, e novos campos surgem gradualmente. Modelos estilo documento conseguem armazenar formas aninhadas e desiguais diretamente sem forçar cada registro a seguir o mesmo template rígido.
Iteração mais rápida, menos joins desconfortáveis
A flexibilidade também reduz a necessidade de joins complexos para certas formas de dados. Quando uma tela precisa de um objeto composto (um pedido com itens, informações de envio e histórico de status), designs relacionais podem exigir múltiplas tabelas e joins — além de camadas ORM que tentam ocultar essa complexidade, mas frequentemente adicionam atrito.
Opções NoSQL facilitaram modelar dados mais próximos de como a aplicação lê e escreve, ajudando equipes a entregar mudanças mais rápido.
A mudança em escala web que alterou requisitos de banco de dados
Aplicações web não só ficaram maiores — mudaram de forma. Em vez de atender um número previsível de usuários internos em horário comercial, produtos passaram a servir milhões de usuários globais o tempo todo, com picos súbitos impulsionados por lançamentos, notícias ou compartilhamento social.
Expectativas de disponibilidade contínua elevaram a barra: downtime virou manchete, não apenas inconveniente. Ao mesmo tempo, equipes eram pressionadas a entregar recursos mais rápido — muitas vezes antes que alguém soubesse qual seria o modelo de dados “final”.
Distribuído virou caminho padrão para crescer
Para acompanhar, escalar verticalmente um único servidor deixou de ser suficiente. Quanto mais tráfego você atendia, mais queria capacidade que pudesse ser adicionada incrementalmente — adicionar outro nó, espalhar carga, isolar falhas.
Isso empurrou a arquitetura para frotas de máquinas em vez de uma “caixa principal” e mudou o que as equipes esperavam de bancos: não só correção, mas desempenho previsível sob alta concorrência e comportamento gracioso quando partes do sistema estão com problemas.
Padrões adotados antes dos bancos evoluírem
Antes do termo “NoSQL” entrar no mainstream, muitas equipes já estavam adaptando sistemas às realidades de escala web:
- Camadas de cache (frequentemente em memória) para reduzir leituras repetidas
- Desnormalização para evitar joins caros e reduzir round-trips
- Visões pré-computadas e rollups materializados para feeds, timelines e dashboards
Essas técnicas funcionavam, mas deslocavam complexidade para o código da aplicação: invalidação de cache, manter dados duplicados consistentes e construir pipelines para registros “prontos para servir”.
Como isso forçou bancos a evoluir
À medida que esses padrões se tornaram padrão, bancos tiveram que suportar distribuir dados por máquinas, tolerar falhas parciais, lidar com altas taxas de escrita e representar dados que evoluem de forma limpa. Bancos NoSQL surgiram em parte para tornar estratégias comuns de escala web em funcionalidades de primeira classe em vez de gambiarras constantes.
Trade-offs distribuídos e o teorema CAP
Entregue com esquemas mutáveis
Modele registros flexíveis e evolutivos em um app que você pode alterar conforme os requisitos mudam.
Quando dados vivem em uma máquina, as regras parecem simples: há uma única fonte da verdade e toda leitura ou escrita pode ser verificada imediatamente. Quando você espalha dados por servidores (às vezes entre regiões), surge uma nova realidade: mensagens podem atrasar, nós podem falhar e partes do sistema podem parar de se comunicar temporariamente.
O trade-off central (em linguagem simples)
Um banco distribuído deve decidir o que fazer quando não pode coordenar com segurança. Deve continuar atendendo requisições para que o app fique “no ar”, mesmo que os resultados possam estar um pouco desatualizados? Ou deve recusar algumas operações até confirmar que as réplicas concordam, o que pode parecer downtime para os usuários?
Essas situações ocorrem durante falhas de roteador, redes sobrecarregadas, deploys rodando, configurações de firewall equivocadas e atrasos de replicação entre regiões.
CAP em uma moldura: C, A e P
O teorema CAP é um atalho para três propriedades que você gostaria de ter ao mesmo tempo:
- Consistência (C): toda leitura retorna a escrita mais recente (ou um erro). Na prática, “todo mundo vê a mesma resposta agora.”
- Disponibilidade (A): toda requisição recebe uma resposta (não necessariamente com o dado mais novo).
- Tolerância a partições (P): o sistema continua operando mesmo que a rede se parta em grupos isolados.
O ponto chave não é “escolha dois para sempre.” É: quando acontece uma partição de rede, você deve escolher entre consistência e disponibilidade. Em sistemas de escala web, partições são tratadas como inevitáveis — especialmente em setups multi-região.
Partições conectam-se diretamente a falhas reais
Imagine que sua aplicação roda em duas regiões para resiliência. Um corte de fibra ou problema de roteamento impede a sincronização.
- Se você prioriza disponibilidade, ambas as regiões continuam aceitando escritas, e os dados podem divergir temporariamente.
- Se você prioriza consistência, uma região pode rejeitar escritas (ou leituras) até confirmar acordo.
Diferentes sistemas NoSQL (e diferentes configurações do mesmo sistema) fazem compromises dependendo do que importa mais: experiência do usuário durante falhas, garantias de correção, simplicidade operacional ou comportamento de recuperação.
Escalar horizontalmente: sharding e replicação como ideias centrais
Scale-out (escala horizontal) significa aumentar capacidade adicionando mais máquinas (nós) em vez de comprar um servidor maior. Para muitas equipes, isso foi uma mudança financeira e operacional: nós commodity podiam ser adicionados incrementalmente, falhas eram esperadas e o crescimento não exigia migrações arriscadas para “caixas grandes”.
Sharding (particionamento): espalhando o trabalho
Para tornar muitos nós úteis, sistemas NoSQL se apoiaram em sharding (também chamado de particionamento). Em vez de um banco lidar com todas as requisições, os dados são divididos em partições e distribuídos pelos nós.
Um exemplo simples é particionar por uma chave (como user_id):
- Nó A armazena usuários 1–1.000.000
- Nó B armazena usuários 1.000.001–2.000.000
Leituras e escritas se espalham, reduzindo hotspots e deixando a taxa de transferência crescer conforme você adiciona nós. A chave de partição vira uma decisão de design: escolha uma chave alinhada com padrões de consulta, ou você pode acidentalmente canalizar muito tráfego para um shard.
Replicação: disponibilidade e escala de leitura
Replicação significa manter cópias múltiplas dos mesmos dados em nós diferentes. Isso melhora:
- Disponibilidade: se um nó falha, outra réplica pode atender requisições.
- Capacidade de leitura: leituras podem ser servidas por múltiplas réplicas.
Replicação também permite espalhar dados por racks ou regiões para sobreviver a falhas localizadas.
O custo escondido: rebalanceamento e operações
Sharding e replicação introduzem trabalho operacional contínuo. Conforme os dados crescem ou nós mudam, o sistema precisa rebalancear — mover partições enquanto permanece online. Se mal feito, o rebalanceamento pode causar picos de latência, carga desigual ou faltas temporárias de capacidade.
Esse é um trade-off central: escalabilidade mais barata via mais nós em troca de distribuição mais complexa, monitoramento e tratamento de falhas.
Modelos de consistência: da estrita à eventual
Uma vez que dados são distribuídos, o banco precisa definir o que “correto” significa quando atualizações acontecem concorrentemente, redes ficam lentas ou nós não se comunicam.
Consistência estrita
Com consistência forte, uma vez que uma escrita é confirmada, todo leitor deve vê-la imediatamente. Isso corresponde à experiência de “fonte única da verdade” que muitos associam a bancos relacionais.
O desafio é a coordenação: garantias estritas entre nós exigem múltiplas mensagens, espera por respostas suficientes e lidar com falhas no meio do caminho. Quanto mais distantes os nós (ou mais ocupados), mais latência você pode introduzir — às vezes em cada escrita.
Consistência eventual
Consistência eventual relaxa essa garantia: após uma escrita, diferentes nós podem retornar respostas diferentes por um tempo, mas o sistema converge.
Exemplos:
- Um contador de “likes” pode mostrar 101 likes em uma réplica enquanto outra ainda mostra 100 por alguns segundos.
- Uma nova postagem pode aparecer no feed de alguns usuários antes de outros, especialmente entre regiões.
Para muitas experiências de usuário, essa discrepância temporária é aceitável se o sistema permanecer rápido e disponível.
Conflitos e como são resolvidos
Se duas réplicas aceitarem atualizações quase ao mesmo tempo, o banco precisa de uma regra de merge.
Abordagens comuns incluem:
- Timestamps (last-write-wins): manter a atualização com o timestamp mais novo. Simples, mas pode perder dados se os relógios divergirem ou se o “mais novo” não for semanticamente correto.
- Vetores de versão (conceitualmente): rastrear quais réplicas viram quais updates, detectar escritas concorrentes e ou mesclar ou expor conflitos.
Onde consistência forte ainda importa
Consistência forte normalmente vale o custo para movimentação de dinheiro, limites de inventário, nomes de usuário únicos, permissões e qualquer fluxo onde “duas verdades por um momento” possa causar dano real.
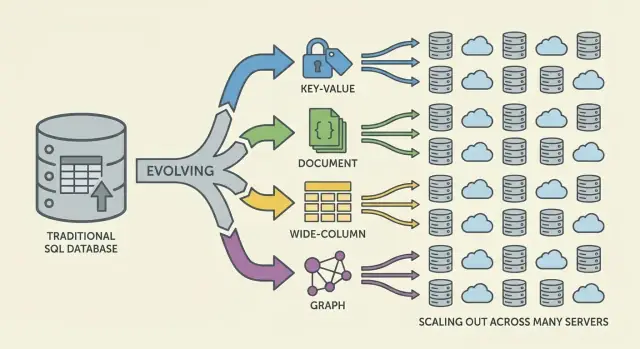
As principais famílias de bancos NoSQL (e o que otimizaram)
Compartilhe uma demo executável
Lance uma demo interna com hospedagem e compartilhe para receber feedback.
NoSQL é um conjunto de modelos que fazem trade-offs diferentes em torno de escala, latência e forma dos dados. Entender a “família” ajuda a prever o que será rápido, o que será penoso e por quê.
Stores chave-valor: velocidade pela simplicidade
Bancos chave-valor armazenam um valor por uma chave única, como um hashmap distribuído gigante. Como o padrão de acesso é tipicamente “get por chave” / “set por chave”, eles podem ser extremamente rápidos e escaláveis horizontalmente.
São ótimos quando você já conhece a chave de lookup (sessions, cache, feature flags), mas limitados para consultas ad-hoc: filtrar por múltiplos campos muitas vezes não é o objetivo do sistema.
Bancos de documentos armazenam documentos parecidos com JSON (geralmente agrupados em coleções). Cada documento pode ter uma estrutura ligeiramente diferente, o que suporta flexibilidade de esquema conforme produtos evoluem.
Eles são otimizados para ler e escrever documentos inteiros e consultar por campos dentro deles — sem forçar tabelas rígidas. O trade-off: modelar relacionamentos pode ficar complicado, e joins (se suportados) podem ser mais limitados que em sistemas relacionais.
Wide-column (coluna larga): alto throughput de escrita em escala gigantesca
Bancos wide-column (inspirados pelo Bigtable) organizam dados por chaves de linha, com muitas colunas que podem variar por linha. Eles brilham em taxas massivas de escrita e armazenamento distribuído, sendo uma boa escolha para séries temporais, eventos e logs.
Tendem a recompensar design cuidadoso em torno de padrões de acesso: você consulta eficientemente por chave primária e regras de clustering, não por filtros arbitrários.
Grafos: consultas focadas em relacionamentos
Bancos em grafo tratam relacionamentos como dado de primeira classe. Em vez de fazer joins repetidos, eles percorrem arestas entre nós, tornando consultas do tipo “como essas coisas estão conectadas?” naturais e rápidas (análise de fraude, recomendações, grafos sociais).
Guia rápido: quando cada modelo é melhor
- Chave-valor: lookups mais rápidos por ID; cache, sessions, contadores
- Documento: dados de produto que evoluem; perfis, catálogos, conteúdo
- Coluna larga: ingestão intensa em escala; telemetria, logs, séries temporais
- Grafo: consultas profundas de relacionamento; grafos sociais, roteamento, análise de fraude
Mudanças no modelamento de dados: menos joins, design mais intencional
Bancos relacionais encorajam normalização: dividir dados em muitas tabelas e remontar com joins em tempo de consulta. Muitos sistemas NoSQL empurram você a projetar em torno dos padrões de acesso mais importantes — às vezes ao custo de duplicação — para manter a latência previsível entre nós.
Por que desnormalizar é tão comum
Em bancos distribuídos, um join pode exigir buscar dados em múltiplas partições ou máquinas. Isso adiciona saltos de rede, coordenação e latência imprevisível. Desnormalizar (armazenar dados relacionados juntos) reduz round-trips e mantém uma leitura “local” o máximo possível.
Uma consequência prática: você pode armazenar o mesmo nome de cliente em um registro orders mesmo que ele também exista em customers, porque “mostrar as últimas 20 ordens” é uma consulta central.
Restrições de consulta: menos joins, mais modelagem na aplicação
Muitos bancos NoSQL suportam joins limitados (ou nenhum), então a aplicação assume mais responsabilidade:
- Buscar um documento/linha por chave e renderizar diretamente
- Ler dois datasets separadamente e mesclar no código
- Pré-computar modelos de leitura (counts, resumos) para evitar scans caros
Por isso o modelamento NoSQL frequentemente começa com: “Quais telas precisamos carregar?” e “Quais são as consultas principais que devemos acelerar?”
Índices secundários — e seus custos ocultos
Índices secundários podem habilitar novas consultas (“encontre usuários por email”), mas não são gratuitos. Em sistemas distribuídos, cada escrita pode atualizar múltiplas estruturas de índice, levando a:
- Amplificação de escrita: uma escrita lógica vira várias escritas físicas
- Armazenamento extra: entradas de índice podem rivalizar com o tamanho dos dados
- Complexidade operacional: índices podem ficar defasados ou exigir tuning cuidadoso
- Embedar em vez de referenciar: armazenar itens do pedido dentro do documento do pedido para ler um pedido em uma única requisição
- Agrupar dados de séries temporais: manter eventos por dispositivo por dia para evitar partições sem limite
- Materializar modelos de leitura: manter um registro
user_profile_summary para servir uma página de perfil sem escanear posts, likes e follows
Benefícios e trade-offs que as equipes aceitaram
Planeje antes de escolher
Use o Planning Mode para mapear consultas, formatos de dados e trade-offs antes de se comprometer.
NoSQL não foi adotado porque era “melhor” em tudo. Foi adotado porque equipes aceitaram trocar certas conveniências dos bancos relacionais por velocidade, escala e flexibilidade sob pressão de escala web.
O que as equipes ganharam
Escala horizontal por design. Muitos sistemas NoSQL tornaram prático adicionar máquinas em vez de atualizar continuamente um servidor único. Sharding e replicação passaram a ser capacidades centrais, não detalhes.
Esquemas flexíveis. Sistemas de documento e chave-valor permitiram que aplicações evoluíssem sem passar cada mudança de campo por uma definição de tabela estrita, reduzindo atrito quando requisitos mudavam semanalmente.
Padrões de alta disponibilidade. Replicação entre nós e regiões tornou mais fácil manter serviços no ar durante falhas de hardware ou manutenção.
O que as equipes pagaram
Duplicação de dados e desnormalização. Evitar joins frequentemente significa duplicar dados. Isso melhora leitura, mas aumenta armazenamento e introduz complexidade de manter tudo atualizado.
Surpresas de consistência. Consistência eventual pode ser aceitável — até que não seja. Usuários podem ver dados obsoletos ou casos de borda confusos, a menos que a aplicação seja desenhada para tolerar ou resolver conflitos.
Analytics mais difíceis (às vezes). Alguns stores NoSQL são ótimos para leituras/escritas operacionais, mas tornam consultas ad-hoc, relatórios ou agregações complexas mais trabalhosas do que em sistemas centrados em SQL.
Adoção inicial de NoSQL frequentemente deslocou esforço das features do banco para disciplina de engenharia: monitorar replicação, gerenciar partições, rodar compactação, planejar backups/restores e testar cenários de falha. Equipes com maturidade operacional forte se beneficiaram mais.
Como avaliar os trade-offs
Escolha com base nas realidades da carga: latência esperada, pico de throughput, padrões de consulta dominantes, tolerância a leituras desatualizadas e requisitos de recuperação (RPO/RTO). A escolha “certa” costuma ser a que combina com a forma como sua aplicação falha, escala e precisa ser consultada — não a que tem a lista de recursos mais impressionante.
Como decidir se NoSQL é apropriado hoje
Escolher NoSQL não deve começar por marcas ou hype — deve começar pelo que sua aplicação precisa fazer, como ela vai crescer e o que “correto” significa para seus usuários.
Comece por requisitos e padrões de acesso
Antes de escolher um datastore, escreva:
- As 5–10 principais consultas/operações que você precisa suportar (leituras, escritas, busca, agregações)
- Tráfego esperado agora vs. em 12–24 meses
- Sua tolerância a dados desatualizados (milissegundos, segundos, nunca)
- Expectativas de falha (o que acontece se um nó ou região cair?)
Se você não consegue descrever padrões de acesso claramente, qualquer escolha será um palpite — especialmente com NoSQL, onde o modelamento costuma ser guiado por como se lê e escreve.
Checklist simples (SQL vs NoSQL vs híbrido)
Use isso como filtro rápido:
- Escolha SQL se você precisa de consistência forte por padrão, consultas ad-hoc complexas e muitas relações que se beneficiam de joins.
- Escolha NoSQL se você precisa de escala horizontal fácil para padrões de acesso específicos, pode modelar dados para esses padrões e aceita consistência relaxada para alguns fluxos.
- Escolha híbrido se diferentes partes da aplicação têm necessidades distintas (comum em produtos reais).
Um sinal prático: se sua “verdade central” (pedidos, pagamentos, inventário) deve estar correta o tempo todo, mantenha isso no SQL ou outro store fortemente consistente. Se você serve conteúdo de alto volume, sessões, cache, feeds ou dados gerados por usuários e flexíveis, NoSQL pode encaixar bem.
Considere persistência poliglota (de propósito)
Muitas equipes têm sucesso com múltiplos stores: por exemplo, SQL para transações, um banco de documentos para perfis/conteúdo e um store chave-valor para sessions. O objetivo não é complexidade por si só — é casar cada workload com a ferramenta que o trata bem.
Isso também depende do fluxo de trabalho do desenvolvedor. Se você está iterando na arquitetura (SQL vs NoSQL vs híbrido), conseguir rodar um protótipo funcional rapidamente — API, modelo de dados e UI — pode reduzir riscos. Plataformas como Koder.ai ajudam equipes a isso gerando apps full-stack a partir de chat, tipicamente com frontend em React e backend em Go + PostgreSQL, permitindo exportar o código. Mesmo que mais tarde você introduza um store NoSQL para workloads específicos, ter um forte SQL “sistema de registro” combinado com prototipagem rápida, snapshots e rollback pode tornar experimentos mais seguros e rápidos.
Seja qual for a escolha, prove-a:
- Rode testes de carga com consultas e tamanhos de dados realistas.
- Faça drills de falha (matar nós, simular problemas de rede, testar restores).
- Crie um plano de evolução de esquema: como adicionar campos, migrar registros e manter versões antigas/novas compatíveis durante rollout.
Se você não consegue testar esses cenários, sua decisão de banco continua teórica — e a produção acabará testando por você.