13 de ago. de 2025·6 min
Conceitos de sistemas distribuídos: ideias de Kleppmann para escalar um SaaS
Conceitos de sistemas distribuídos explicados através das escolhas reais que equipes enfrentam ao transformar um protótipo em um SaaS confiável: fluxo de dados, consistência e controle de carga.
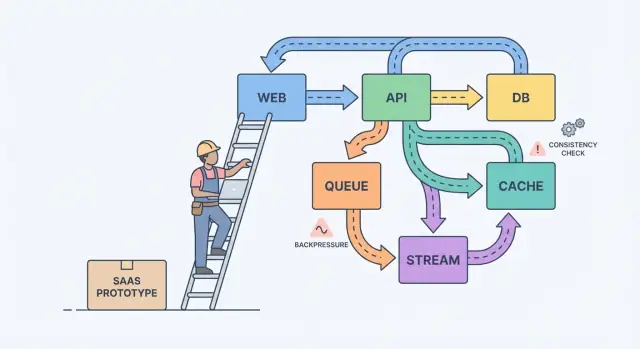
Do protótipo a SaaS: onde começa a confusão
Um protótipo prova uma ideia. Um SaaS precisa sobreviver ao uso real: picos de tráfego, dados bagunçados, retentativas e clientes que percebem cada falha. É aí que as coisas ficam confusas, porque a pergunta muda de “funciona?” para “continua funcionando?”
Com usuários de verdade, “funcionou ontem” falha por motivos mundanos. Um job de background roda mais tarde que o normal. Um cliente envia um arquivo 10x maior que seus dados de teste. Um provedor de pagamentos trava por 30 segundos. Nada disso é exótico, mas os efeitos colaterais ficam altos quando partes do sistema dependem umas das outras.
A maior parte da complexidade aparece em quatro lugares: dados (o mesmo fato existe em vários lugares e diverge), latência (chamadas de 50 ms às vezes levam 5 segundos), falhas (timeouts, atualizações parciais, retentativas) e equipes (pessoas diferentes entregando serviços em ritmos diferentes).
Um modelo mental simples ajuda: componentes, mensagens e estado.
Componentes fazem trabalho (app web, API, worker, banco de dados). Mensagens movem trabalho entre componentes (requisições, eventos, jobs). Estado é o que você lembra (pedidos, configurações do usuário, status de cobrança). A dor de escalar normalmente vem de um desalinhamento: você envia mensagens mais rápido do que um componente consegue processar, ou atualiza estado em dois lugares sem uma fonte de verdade clara.
Um exemplo clássico é cobrança. Um protótipo pode criar uma fatura, enviar um e-mail e atualizar o plano do usuário em uma única requisição. Sob carga, o envio de e-mail desacelera, a requisição expira, o cliente reenvia e agora você tem duas faturas e uma mudança de plano. Trabalho de confiabilidade é, em grande parte, prevenir que essas falhas do dia a dia virem bugs visíveis ao cliente.
Transforme conceitos em decisões escritas
A maioria dos sistemas fica mais difícil porque crescem sem acordo sobre o que deve estar correto, o que só precisa ser rápido e o que deve acontecer quando algo falha.
Comece desenhando um limite ao redor do que você promete aos usuários. Dentro desse limite, nomeie as ações que devem estar corretas sempre (movimentação de dinheiro, controle de acesso, propriedade da conta). Depois, nomeie as áreas onde “correto eventualmente” é aceitável (contadores de analytics, índices de busca, recomendações). Essa divisão transforma teoria vaga em prioridades.
Em seguida, escreva sua fonte de verdade. É onde fatos são registrados uma vez, de forma durável, com regras claras. Todo o resto é dado derivado, construído para velocidade ou conveniência. Se uma visão derivada for corrompida, você deve ser capaz de reconstruí-la a partir da fonte de verdade.
Quando equipes ficam travadas, essas perguntas normalmente mostram o que importa:
- Que dados nunca devem ser perdidos, mesmo que isso atrase o sistema?
- O que pode ser recriado a partir de outros dados, mesmo que demore horas?
- O que pode ficar defasado, e por quanto tempo, do ponto de vista do usuário?
- Qual falha é pior para você: duplicatas, eventos faltantes ou atrasos?
Se um usuário atualiza seu plano de cobrança, um dashboard pode ficar atrasado. Mas você não pode tolerar uma discrepância entre o status de pagamento e o acesso real.
Streams, filas e logs: escolhendo o formato certo de trabalho
Se um usuário clica um botão e precisa ver o resultado imediatamente (salvar perfil, carregar dashboard, checar permissões), uma API request-response normal geralmente é suficiente. Mantenha direto.
Assim que o trabalho puder acontecer depois, mova para async. Pense em enviar e-mails, cobrar cartões, gerar relatórios, redimensionar uploads ou sincronizar dados para busca. O usuário não deve esperar por isso, e sua API não deve ficar ocupada enquanto rodarem.
Uma fila é uma lista de afazeres: cada tarefa deve ser tratada uma vez por um worker. Um stream (ou log) é um registro: eventos são mantidos em ordem para que múltiplos leitores possam reproduzi-los, atualizar-se ou construir novas funcionalidades depois sem mudar o produtor.
Uma forma prática de escolher:
- Use request-response quando o usuário precisa de uma resposta imediata e o trabalho for pequeno.
- Use uma fila para trabalho em background com retentativas onde apenas um worker deve executar cada job.
- Use um stream/log quando você precisa de replay, trilha de auditoria ou múltiplos consumidores que não devem ficar acoplados a um serviço.
Exemplo: seu SaaS tem um botão “Create invoice”. A API valida a entrada e armazena a fatura no Postgres. Então uma fila cuida de “send invoice email” e “charge card”. Se mais tarde você adicionar analytics, notificações e verificações de fraude, um stream de InvoiceCreated permite que cada funcionalidade se inscreva sem transformar seu serviço principal em um labirinto.
Design de eventos: o que publicar e o que guardar
À medida que o produto cresce, eventos deixam de ser “bom ter” e viram uma rede de segurança. Bom design de eventos resume-se a duas perguntas: que fatos você registra e como outras partes do produto podem reagir sem chutar.
Comece com um pequeno conjunto de eventos de negócio. Escolha momentos que importam para os usuários e para o dinheiro: UserSignedUp, EmailVerified, SubscriptionStarted, PaymentSucceeded, PasswordResetRequested.
Nomes sobrevivem ao código. Use tempo passado para fatos completos, mantenha específicos e evite wording de UI. PaymentSucceeded continua significativo mesmo se você adicionar cupons, retentativas ou múltiplos provedores de pagamento.
Trate eventos como contratos. Evite um “UserUpdated” genérico com um saco de campos que muda a cada sprint. Prefira o menor fato que você consiga garantir por anos.
Para evoluir com segurança, favoreça mudanças aditivas (novos campos opcionais). Se precisar de uma mudança breaking, publique um novo nome de evento (ou versão explícita) e rode ambos até os consumidores antigos saírem.
O que você deve armazenar? Se você guarda só as linhas mais recentes em um banco, perde a história de como chegou até ali.
Eventos brutos são ótimos para auditoria, replay e debugging. Snapshots são ótimos para leituras rápidas e recuperação rápida. Muitos produtos SaaS usam ambos: armazenam eventos brutos para fluxos chave (cobrança, permissões) e mantêm snapshots para telas voltadas ao usuário.
Compromissos de consistência que os usuários realmente percebem
Build and earn credits
Share what you build or refer others and earn credits to keep iterating.
Consistência aparece em momentos como: “mudei meu plano, por que ainda aparece Free?” ou “mandei um convite, por que meu colega ainda não consegue entrar?”
Consistência forte significa que, uma vez que você recebe uma mensagem de sucesso, toda tela deve refletir o novo estado imediatamente. Consistência eventual significa que a mudança se propaga com o tempo, e por uma janela curta partes diferentes do app podem discordar. Nenhuma é “melhor”. Você escolhe com base no dano que uma discrepância pode causar.
Consistência forte geralmente se aplica a dinheiro, acesso e segurança: cobrar um cartão, mudar senha, revogar chaves de API, impor limites de assentos. Consistência eventual costuma servir bem a feeds de atividade, busca, analytics, “última vez visto” e notificações.
Se você aceita obsolescência, projete para isso em vez de esconder. Mantenha a UI honesta: mostre um estado “Atualizando…” após um write até a confirmação chegar, ofereça um refresh manual para listas e use UI otimista apenas quando puder reverter com segurança.
Retentativas são onde a consistência fica traiçoeira. Redes caem, clientes clicam duas vezes e workers reiniciam. Para operações importantes, torne requisições idempotentes para que repetir a mesma ação não gere duas faturas, dois convites ou dois reembolsos. Uma abordagem comum é uma chave de idempotência por ação mais uma regra no servidor para retornar o resultado original em repetições.
Backpressure: evitar que o sistema derreta
Backpressure é o que você precisa quando requisições ou eventos chegam mais rápido do que o sistema consegue processar. Sem ele, trabalho se acumula em memória, filas crescem e a dependência mais lenta (frequentemente o banco) decide quando tudo falha.
Em termos simples: seu produtor continua mandando enquanto o consumidor está se afogando. Se você continuar aceitando trabalho, não só fica mais lento. Você desencadeia uma reação em cadeia de timeouts e retentativas que multiplica a carga.
Os sinais de aviso costumam ser visíveis antes de um outage: backlog só cresce, latência pula após picos ou deploys, retentativas aumentam com timeouts, endpoints não relacionados falham quando uma dependência desacelera e conexões de banco ficam no limite.
Quando você chega a esse ponto, escolha uma regra clara para o que acontece quando está cheio. O objetivo não é processar tudo a qualquer custo. É sobreviver e recuperar rápido. Equipes normalmente começam com um ou dois controles: rate limits (por usuário ou API key), filas limitadas com política definida de descarte/atraso, circuit breakers para dependências com erro e prioridades para que requisições interativas ganhem sobre jobs de background.
Proteja o banco primeiro. Mantenha pools de conexão pequenos e previsíveis, defina timeouts de query e imponha limites rígidos em endpoints caros como relatórios ad-hoc.
Um caminho passo a passo para confiabilidade (sem reescrever tudo)
Confiabilidade raramente requer uma grande reescrita. Normalmente vem de algumas decisões que tornam falhas visíveis, contidas e recuperáveis.
Comece pelos fluxos que geram ou perdem confiança, e então adicione trilhos de segurança antes de lançar mais features:
-
Mapear caminhos críticos. Anote os passos exatos para signup, login, reset de senha e qualquer fluxo de pagamento. Para cada passo, liste suas dependências (banco, provedor de e-mail, worker). Isso força clareza sobre o que deve ser imediato versus o que pode ser consertado “eventualmente”.
-
Adicionar observabilidade básica. Dê a cada requisição um ID que apareça nos logs. Monitore um pequeno conjunto de métricas que reflitam a dor do usuário: taxa de erro, latência, profundidade de filas e queries lentas. Adicione tracing apenas onde pedidos cruzam serviços.
-
Isolar trabalho lento ou instável. Tudo que conversa com um serviço externo ou rotineiramente leva mais de um segundo deve ser movido para jobs e workers.
-
Projetar para retentativas e falhas parciais. Presuma que timeouts acontecem. Torne operações idempotentes, use backoff, defina limites de tempo e mantenha ações visíveis ao usuário curtas.
-
Treinar recuperação. Backups só importam se você consegue restaurá-los. Use releases pequenos e mantenha um caminho de rollback rápido.
Se sua ferramenta suporta snapshots e rollback (Koder.ai faz), integre isso nos hábitos normais de deploy em vez de tratar como truque de emergência.
Exemplo: transformar um pequeno SaaS em algo confiável
From concept to code
Model components, messages, and state, then implement them directly from chat.
Imagine um pequeno SaaS que ajuda equipes a onboarding de novos clientes. O fluxo é simples: um usuário se cadastra, escolhe um plano, paga e recebe um e-mail de boas-vindas mais alguns passos de “como começar”.
No protótipo, tudo acontece em uma requisição: criar conta, cobrar cartão, marcar “paid” no usuário, enviar e-mail. Funciona até o tráfego crescer, retentativas acontecerem e serviços externos desacelerarem.
Para torná-lo confiável, a equipe transforma ações chave em eventos e mantém um histórico append-only. Eles introduzem alguns eventos: UserSignedUp, PaymentSucceeded, EntitlementGranted, WelcomeEmailRequested. Isso dá trilha de auditoria, facilita analytics e permite que trabalhos lentos ocorram em background sem bloquear o signup.
Algumas escolhas resolvem a maior parte do problema:
- Trate pagamentos como fonte de verdade para acesso, não apenas uma flag “paid”.
- Conceda direitos a partir de
PaymentSucceededcom uma clara chave de idempotência para que retentativas não concedam duplicado. - Envie e-mails a partir de uma fila/worker, não da requisição de checkout.
- Registre eventos mesmo se um handler falhar, assim você pode dar replay e recuperar.
- Adicione timeouts e um circuit breaker em torno de provedores externos.
Se o pagamento for bem-sucedido mas o acesso ainda não estiver concedido, usuários se sentem enganados. A solução não é “consistência perfeita em todo lugar”. É decidir o que deve ser consistente agora e refletir isso na UI com um estado como “Ativando seu plano” até EntitlementGranted chegar.
Numa manhã ruim, backpressure faz a diferença. Se a API de e-mail travar durante uma campanha, o design antigo expira checkouts e usuários reencaminham, criando cobranças e e-mails duplicados. No design melhor, o checkout completa, pedidos de e-mail enfileiram e um job de replay drena o backlog quando o provedor se recupera.
Armadilhas comuns quando os sistemas escalam
A maioria dos outages não vem de um bug heróico. Vem de pequenas decisões que faziam sentido no protótipo e depois viraram hábito.
Uma armadilha comum é fragmentar em microserviços cedo demais. Você acaba com serviços que se chamam entre si, propriedade pouco clara e mudanças que exigem cinco deploys em vez de um.
Outra armadilha é usar “consistência eventual” como passe livre. Usuários não se importam com o termo. Eles querem que, ao clicar em Salvar, a página não mostre dados antigos depois, ou que o status de uma fatura não oscile. Se você aceita atraso, ainda precisa de feedback para o usuário, timeouts e uma definição de “bom o suficiente” em cada tela.
Outros culpados frequentes: publicar eventos sem plano de reprocessamento, retentativas não limitadas que multiplicam carga durante incidentes e permitir que todo serviço fale diretamente com o mesmo esquema de banco de dados, de modo que uma mudança quebra muitas equipes.
Verificações rápidas antes de chamar de “pronto para produção”
Get everyone on the same page
Align product and engineering by building the critical flows together in one workspace.
“Pronto para produção” é um conjunto de decisões que você consegue apontar às 2 da manhã. Clareza vence esperteza.
Comece nomeando suas fontes de verdade. Para cada tipo de dado chave (clientes, assinaturas, faturas, permissões), decida onde o registro final vive. Se seu app lê a “verdade” de dois lugares, você eventualmente mostrará respostas diferentes para usuários diferentes.
Depois olhe para retentativas. Presuma que toda ação importante será executada duas vezes em algum momento. Se a mesma requisição atingir seu sistema duas vezes, você consegue evitar cobranças duplicadas, envios duplicados ou duplicação de registros?
Uma pequena checklist que pega a maioria das falhas dolorosas:
- Para cada tipo de dado, você consegue apontar uma fonte de verdade e nomear o que é derivado.
- Toda escrita importante é segura para retentar (chave de idempotência ou constraint única).
- Seu trabalho assíncrono não cresce sem limite (você monitora lag, idade da mensagem mais antiga e alerta antes que usuários percebam).
- Você tem um plano para mudança (migrações reversíveis, versionamento de eventos).
- Você consegue fazer rollback e restaurar com confiança porque já praticou.
Próximos passos: tome uma decisão de cada vez
Escalar fica mais fácil quando você trata design de sistema como uma lista curta de escolhas, não um monte de teoria.
Escreva 3 a 5 decisões que espera enfrentar no próximo mês, em linguagem simples: “Movemos envio de e-mail para job em background?” “Aceitamos analytics levemente defasado?” “Quais ações precisam ser imediatamente consistentes?” Use essa lista para alinhar produto e engenharia.
Depois escolha um fluxo que hoje é síncrono e converta apenas esse para async. Recibos, notificações, relatórios e processamento de arquivos são movimentos iniciais comuns. Meça duas coisas antes e depois: latência percebida pelo usuário (a página ficou mais rápida?) e comportamento em falhas (retentativas criaram duplicatas ou confusão?).
Se quer prototipar essas mudanças rápido, Koder.ai (koder.ai) pode ser útil para iterar em um SaaS React + Go + PostgreSQL mantendo rollback e snapshots à mão. A régua é simples: entregue uma melhoria, aprenda com tráfego real e então decida a próxima.
Perguntas frequentes
What’s the real difference between a prototype and a production SaaS?
A prototype answers “can we build it?” A SaaS must answer “will it keep working when users, data, and failures show up?”
The biggest shift is designing for:
- slow dependencies (email, payments, file processing)
- retries and duplicates
- data that grows and gets messy
- clear rules about what must be correct vs what can be slightly stale
How do I decide what must be strongly consistent vs eventually consistent?
Pick a boundary around what you promise users, then label actions by impact.
Start with must be correct every time:
- charging/refunding money
- access control and entitlements
- account ownership and security actions
Then mark can be eventually correct:
What does “source of truth” mean in a SaaS, and how do I pick it?
Choose one place where each “fact” is recorded once and treated as final (often Postgres for a small SaaS). That is your source of truth.
Everything else is derived for speed or convenience (caches, read models, search indexes). A good test: if the derived data is wrong, can you rebuild it from the source of truth without guessing?
When should I move work to async instead of keeping it in the API request?
Use request-response when the user needs an immediate result and the work is small.
Move work to async when it can happen later or can be slow:
- sending emails
- charging cards (often after validation)
- report generation
- file processing
Async keeps your API fast and reduces timeouts that trigger client retries.
What’s the difference between a queue and a stream, and which should I use?
A queue is a to-do list: each job should be handled once by one worker (with retries).
A stream/log is a record of events in order: multiple consumers can replay it to build features or recover.
Practical default:
- queue for background tasks (“send welcome email”)
- stream/log for business events you may want to replay or audit (“PaymentSucceeded”)
How do I prevent duplicate charges or duplicate invoices when retries happen?
Make important actions idempotent: repeating the same request should return the same outcome, not create a second invoice or charge.
Common pattern:
- client sends an idempotency key per action
- server stores the result keyed by that value
- repeats return the original result
Also use unique constraints where possible (for example, one invoice per order).
What makes an event “well designed” as my product grows?
Publish a small set of stable business facts, named in past tense, like PaymentSucceeded or SubscriptionStarted.
Keep events:
- specific (avoid “UserUpdated” catch-alls)
- durable (treat as a contract)
- easy to evolve (add optional fields; if breaking, publish a new name/version)
This keeps consumers from guessing what happened.
What are the warning signs I need backpressure, and what should I implement first?
Common signs your system needs backpressure:
- queue backlog only grows
- latency spikes after traffic bursts or deploys
- retries increase because of timeouts
- one slow dependency causes unrelated endpoints to fail
- database connections hit limits
Good first controls:
What observability do I need before scaling further?
Start with basics that match user pain:
- a request ID that shows up in logs end-to-end
- metrics for error rate, latency, queue depth, and slow queries
- alerts on “oldest message age” for queues (not just size)
Add tracing only where requests cross services; don’t instrument everything before you know what you’re looking for.
What should be on my “production ready” checklist before real users arrive?
“Production ready” means you can answer hard questions quickly:
- For each data type, where is the source of truth?
- Can every important write be retried safely (idempotency key or unique constraint)?
- Is async work bounded and monitored (lag/oldest message age)?
- Can you roll back releases quickly?
- Can you restore from backups because you’ve practiced?
If your platform supports snapshots and rollback (like Koder.ai), use them as a normal release habit, not only during incidents.