O que um Gerenciador de Experimentos de Preço Deve Fazer
Experimentos de preço são testes estruturados em que você mostra preços (ou pacotes) diferentes para grupos distintos de clientes e mede o que muda — conversão, upgrades, churn, receita por visitante e mais. É a versão de preços de um teste A/B, mas com risco extra: um erro pode confundir clientes, gerar tickets de suporte ou até violar políticas internas.
Um gerenciador de experimentos de preço é o sistema que mantém esses testes controlados, observáveis e reversíveis.
Os problemas que esse app deve resolver
Controle: Times precisam de um único lugar para definir o que está sendo testado, onde e para quem. “Alteramos o preço” não é um plano — um experimento precisa de uma hipótese clara, datas, regras de segmentação e um botão de matar (kill switch).
Rastreamento: Sem identificadores consistentes (chave do experimento, chave da variante, timestamp de atribuição), a análise vira palpite. O gerenciador deve garantir que toda exposição e compra possam ser atribuídas ao teste certo.
Consistência: Clientes não deveriam ver um preço na página de preços e outro no checkout. O gerenciador deve coordenar como variantes são aplicadas nas superfícies para que a experiência seja coerente.
Segurança: Erros de precificação são caros. Você precisa de guardrails como limites de tráfego, regras de elegibilidade (ex.: apenas novos clientes), etapas de aprovação e auditabilidade.
Quem usa
- Produto para planejar experimentos, definir métricas de sucesso e decidir o que será lançado.
- Crescimento/Marketing para iterar em ofertas e mensagens ligadas ao preço.
- Finanças para aplicar regras de receita, políticas de desconto e necessidades de reporte.
- Suporte para entender o que o cliente viu e resolver disputas rapidamente.
- Engenharia para integrar mudanças de preço de forma segura e previsível.
O que estamos construindo (e o que não estamos)
Este post foca em um app interno que gerencia experimentos: criação, atribuição de variantes, coleta de eventos e geração de relatórios.
Não é um motor completo de precificação (cálculo de impostos, faturamento, catálogos multicurrency, proration, etc.). Em vez disso, é o painel de controle e a camada de rastreamento que torna testes de preço seguros para executar regularmente.
Escopo, Requisitos e Não-Objetivos
Um gerenciador de experimentos de preço só é útil se ficar claro o que ele fará — e o que não fará. Escopo enxuto mantém o produto fácil de operar e mais seguro para lançar, especialmente quando há receita real em jogo.
Requisitos mínimos (capacidades obrigatórias)
No mínimo, seu app web deve permitir que um operador não técnico rode um experimento de ponta a ponta:
- Criar experimentos com nome, hipótese, produto(s) alvo, segmento(s) alvo e duração planejada.
- Definir variantes (ex.: “Controle: $29”, “Tratamento: $35”), incluindo moeda, período de cobrança e regras de elegibilidade.
- Iniciar / pausar / parar um experimento, com status claro e timestamps efetivos.
- Ver resultados em nível básico: conversão, receita por visitante, ticket médio, mais indicadores de confiança/incerteza.
Se não construir mais nada, construa bem isso — com defaults claros e guardrails.
Tipos de experimento suportados (seja intencional)
Decida cedo quais formatos de experimento serão suportados para que UI, modelo de dados e lógica de atribuição permaneçam consistentes:
- Testes A/B (um controle vs um tratamento) como caminho principal.
- Multivariados / multi-armed (vários pontos de preço) para times que precisam de mais de duas opções.
- Grupos de holdout (ex.: 5% vê preço baseline) para medir efeitos de longo prazo ou sistema amplo.
- Rollout gradual (ramp-up de tráfego ao longo do tempo) para reduzir risco enquanto aprende.
Não-objetivos (o que você explicitamente não está construindo)
Seja explícito para evitar “scope creep” que transforme a ferramenta de experimentos em um sistema frágil e crítico para o negócio:
- Não é um substituto de sistema de faturamento (faturas, impostos, proration, reembolsos).
- Não é uma plataforma BI completa (exploração livre de dados, SQL customizado, modelagem de data warehouse).
- Não é otimização complexa por ML (motores de precificação dinâmicos, reinforcement learning, auto-tuning).
Critérios de sucesso
Defina sucesso em termos operacionais, não apenas estatísticos:
- Insights prontos para decisão: um PM pode decidir com confiança “lançar / reverter / iterar”.
- Baixo risco operacional: defaults seguros, rollback fácil e exposição controlada.
- Auditabilidade: quem mudou o quê, quando e por quê — adequado para revisão de finanças e compliance.
Modelo de Dados: Experimentos, Variantes e Atribuições
Um app de experimentos de preço vive ou morre pelo seu modelo de dados. Se você não consegue responder confiavelmente “qual preço esse cliente viu, e quando?”, suas métricas ficarão ruidosas e o time perderá confiança.
Entidades chave para modelar
Comece com um conjunto pequeno de objetos centrais que mapeiam como precificação funciona no seu produto:
- Produto: o que está sendo vendido (ex.: “Analytics Suite”).
- Plano: um nível de empacotamento (ex.: Starter, Pro, Enterprise).
- Preço: o valor real e regras de cobrança (moeda, intervalo, regras por país/VAT, datas efetivas).
- Cliente: unidade de análise (conta, usuário, workspace — escolha uma e mantenha).
- Segmento: definição reutilizável (ex.: “apenas EUA”, “self-serve”, “novos clientes”).
- Experimento: o contêiner com escopo, hipótese, start/end e targeting.
- Variante: cada tratamento (Variante A = preço atual, Variante B = novo preço).
- Atribuição: registro de que um cliente foi colocado em uma variante específica.
- Evento: ações rastreadas (page_view, checkout_started, subscription_created, upgrade).
- Métrica: definição computada (taxa de conversão, ARPA, receita por visitante, churn).
Identificadores e campos de tempo que você vai querer depois
Use identificadores estáveis entre sistemas (product_id, plan_id, customer_id). Evite “nomes bonitos” como chaves — eles mudam.
Campos de tempo são igualmente importantes:
- created_at para tudo.
- starts_at / ends_at em experimentos para janelas de relatório.
- decision_date (ou decided_at) para marcar quando o resultado do experimento foi aceito.
Considere também effective_from / effective_to em registros de Preço para que você possa reconstruir preços em qualquer ponto no tempo.
Relacionamentos que tornam a atribuição possível
Defina relacionamentos explicitamente:
- Experiment → Variants (um-para-muitos).
- Customer → Assignments (um-para-muitos, mas muitas vezes limitado a uma atribuição ativa por experimento).
- Event → Customer + Experiment + Variant.
Na prática, isso significa que um Evento deve carregar (ou ser unível via join) customer_id, experiment_id e variant_id. Se você armazenar apenas customer_id e “buscar a atribuição depois”, corre o risco de joins incorretos quando atribuições mudarem.
Imutabilidade: mantenha histórico, não sobrescreva
Experimentos de preço precisam de histórico auditável. Torne registros chave append-only:
- Preços devem ser versionados, não atualizados no lugar.
- Atribuições nunca devem ser editadas para “corrigir” dados; se precisar alterar exposição, crie um novo registro e feche o anterior.
- Decisões (vencedor, racional, decision_date) devem ser preservadas mesmo se você rodar um teste similar depois.
Essa abordagem mantém seus relatórios consistentes e facilita recursos de governança como logs de auditoria no futuro.
Workflow e Ciclo de Vida do Experimento
Um gerenciador de experimentos de preço precisa de um ciclo de vida claro para que todos entendam o que é editável, o que está bloqueado e o que acontece com clientes quando o experimento muda de estado.
Ciclo de vida recomendado
Rascunho → Agendado → Em execução → Parado → Analisado → Arquivado
- Rascunho: Crie o experimento, variantes, público e métricas. Nada é servido ao cliente.
- Agendado: Define-se uma hora de início (e opcionalmente fim). O sistema valida readiness e pode notificar stakeholders.
- Em execução: Atribuição e entrega de preço estão ativas. A maioria dos campos deve travar para evitar mudanças acidentais no meio do teste.
- Parado: O experimento não atribui novos usuários, e você escolhe como tratar usuários existentes.
- Analisado: Resultados são finalizados, documentados e compartilhados.
- Arquivado: Armazenamento somente leitura para compliance e referência futura.
Campos obrigatórios e validação por estado
Para reduzir lançamentos arriscados, force campos obrigatórios conforme o experimento progride:
- Antes de Agendado: owner, escopo (produtos/regiões/planos), variantes e pontos de preço, divisão/compartilhamento de exposição, start/end.
- Antes de Em execução: hipótese, métrica(s) primária(s), guardrails (ex.: churn, reembolsos, tickets de suporte), tamanho mínimo de amostra ou regra de run-time, plano de rollback e confirmação do esquema de tracking/eventos.
- Antes de Analisado: snapshot final de dados, notas de análise e decisão (ship/iterate/reject).
Portões de aprovação e overrides
Para precificação, adicione gates opcionais para Finanças e Jurídico/Compliance. Apenas aprovadores podem mover Agendado → Em execução. Se suportar overrides (ex.: rollback urgente), registre quem sobrepôs, por quê e quando no log de auditoria.
O que “Parar” significa operacionalmente
Quando um experimento está Parado, defina dois comportamentos explícitos:
- Congelar atribuições: parar de atribuir novos usuários; manter usuários existentes presos à última variante atribuída.
- Política de entrega: ou continuar servindo o último preço visto (estabilidade para clientes em jornada) ou reverter ao baseline (rollback rápido).
Faça dessa escolha um requisito na hora de parar para que a equipe não pare um experimento sem decidir o impacto ao cliente.
Atribuição de Variantes e Divisão de Tráfego
Acertar a atribuição é a diferença entre um teste de preço confiável e ruído confuso. Seu app deve facilitar a definição de quem recebe um preço e garantir que a pessoa continue vendo esse preço de modo consistente.
Atribuição consistente (regra “pegajosa”)
Um cliente deve ver a mesma variante entre sessões, dispositivos (quando possível) e atualizações. Isso significa que a atribuição precisa ser determinística: dado o mesmo assignment key e experimento, o resultado é sempre o mesmo.
Abordagens comuns:
- Atribuição baseada em hash: compute um hash de
(experiment_id + assignment_key) e mapeie para uma variante.
- Atribuição armazenada: grave a variante atribuída em uma tabela no banco para recuperação posterior (útil quando precisa de auditoria ou overrides complexos).
Muitas equipes usam hash por padrão e armazenam atribuições apenas quando necessário (casos de suporte ou governança).
Escolhendo uma chave de atribuição
Seu app deve suportar múltiplas chaves, porque precificação pode ser por usuário ou por conta:
- user_id: melhor quando precificação é individual e usuários fazem login com confiabilidade.
- account_id / org_id: melhor para B2B para que todos na mesma empresa vejam o mesmo preço.
- cookie/ID de dispositivo anônimo: útil antes do login, com um caminho de upgrade para mesclar com
user_id após cadastro/login.
Esse caminho de upgrade é importante: se alguém navega anonimamente e depois cria conta, você deve decidir manter a variante original (continuidade) ou reatribuir (regras de identidade mais limpas). Faça isso uma configuração clara e explícita.
Divisão de tráfego e ramp-ups
Suporte alocações flexíveis:
- 50/50 para testes A/B simples
- Divisões ponderadas (ex.: 90/10) para controle de risco
- Cronogramas de ramp-up (ex.: 1% → 5% → 25% → 50%) com datas/horários
Ao ramp-up, mantenha atribuições pegajosas: aumentar tráfego deve adicionar novos usuários ao experimento, não reorganizar os já existentes.
Casos de borda que você deve tratar
Testes concorrentes podem colidir. Construa guardrails para:
- Grupos mutuamente exclusivos (apenas um experimento de preço ativo por usuário/conta)
- Regras de prioridade (se dois experimentos miram o mesmo cliente, qual vence?)
- Exclusões (pessoal interno, contas de teste/suporte, regiões, planos, contratos existentes)
Uma tela clara de “Preview de Atribuição” (dada uma amostra de usuário/conta) ajuda times não técnicos a verificar regras antes do lançamento.
Lance um MVP em dias
Crie telas em React e um backend em Go com PostgreSQL sem montar uma pipeline completa.
Experimentos de preço falham mais frequentemente na camada de integração — não porque a lógica esteja errada, mas porque o produto mostra um preço e cobra outro. Seu app web deve tornar muito explícito “qual é o preço” e “como o produto o usa”.
Separe definição de preço da entrega
Trate a definição de preço como fonte da verdade (regras de preço da variante, datas efetivas, moeda, tratamento de impostos, etc.). Trate a entrega de preço como um mecanismo simples para buscar o preço escolhido via endpoint de API ou SDK.
Essa separação mantém a ferramenta de experimentos limpa: times não técnicos editam definições, enquanto engenheiros integram um contrato de entrega estável como GET /pricing?sku=....
Decida onde o preço é calculado
Existem dois padrões comuns:
- Server-side no checkout (recomendado para cobrança): compute o montante final pagável no servidor para evitar inconsistências e manipulação.
- Client-side para exibição: aceitável para mostrar preços estimados, mas deve ser confirmado por cálculos server-side no momento da compra.
Uma abordagem prática é “exibir no cliente, verificar e computar no servidor”, usando a mesma atribuição do experimento.
Seja rigoroso com moedas, impostos e arredondamento
Variantes devem seguir as mesmas regras para:
- seleção de moeda (locale do usuário vs país de faturamento)
- inclusão de impostos (VAT incluído vs adicionado)
- arredondamento (por item vs por fatura)
Armazene essas regras junto ao preço para que cada variante seja comparável e compatível com finanças.
Planeje fallbacks seguros
Se o serviço de experimentos estiver lento ou fora, seu produto deve retornar um preço padrão seguro (normalmente o baseline). Defina timeouts, cache e uma política clara de “fail closed” para que o checkout não quebre — e registre os fallbacks para quantificar o impacto.
Métricas, Eventos e Noções Básicas de Atribuição
Experimentos de preço vivem ou morrem pela medição. Seu app deve dificultar o “lançar e torcer” ao exigir métricas primárias claras, eventos limpos e abordagem de atribuição consistente antes do lançamento.
Escolha métricas primárias (as “métricas de decisão”)
Comece com uma ou duas métricas que serão usadas para decidir o vencedor. Escolhas comuns para precificação:
- Taxa de conversão (ex.: visitante → checkout, trial → pago)
- Receita por visitante (RPV) (captura preço e conversão juntos)
- ARPA/ARPU (útil para tiers de assinatura)
- Churn / retenção (somente se puder medir em janela razoável)
Uma regra útil: se times discutem o resultado depois do teste, provavelmente a métrica de decisão não foi definida com clareza.
Adicione guardrails (métricas de “não quebrar o negócio”)
Guardrails pegam danos que um preço maior pode causar mesmo que receita de curto prazo pareça boa:
- Taxa de reembolso e chargebacks
- Tickets de suporte (cobrança, confusão, reclamações)
- Falhas de pagamento (cartão recusado, 3DS)
- Queda trial→pago (mudanças de preço podem afetar intenção)
Seu app pode impor guardrails exigindo thresholds (ex.: “taxa de reembolso não deve aumentar mais que 0,3%”) e destacando violações na página do experimento.
Defina um esquema de evento confiável para o seu app
No mínimo, seu tracking deve incluir identificadores estáveis do experimento e variante em todo evento relevante.
{
"event": "purchase_completed",
"timestamp": "2025-01-15T12:34:56Z",
"user_id": "u_123",
"experiment_id": "exp_earlybird_2025_01",
"variant_id": "v_price_29",
"currency": "USD",
"amount": 29.00
}
Torne essas propriedades obrigatórias no momento da ingestão, não “melhor esforço”. Se um evento chegar sem experiment_id/variant_id, direcione-o para um bucket “não atribuído” e sinalize problemas de qualidade de dados.
Escolha janelas de atribuição (e trate resultados atrasados)
Resultados de preço muitas vezes são atrasados (renovações, upgrades, churn). Defina:
- Janela de atribuição: ex.: “contar compras dentro de 7 dias da primeira exposição”
- Regra de exposição: primeira exposição vs última exposição (primeira costuma ser mais segura para preço)
- Métricas atrasadas: mostre uma “leitura preliminar” rapidamente, mas mantenha um estado “final” que atualiza quando a janela fecha
Isso alinha times sobre quando um resultado é confiável — e evita decisões prematuras.
UX e Telas para Times Não Técnicos
Planeje experimentos com clareza
Mapeie estados do ciclo de vida, regras de validação e diretrizes antes de gerar o app.
Uma ferramenta de experimentos de preço só funciona se PMs, marketing e finanças puderem usá-la sem pedir um engenheiro a cada clique. A UI deve responder três perguntas rapidamente: O que está rodando? O que mudará para clientes? O que aconteceu e por quê?
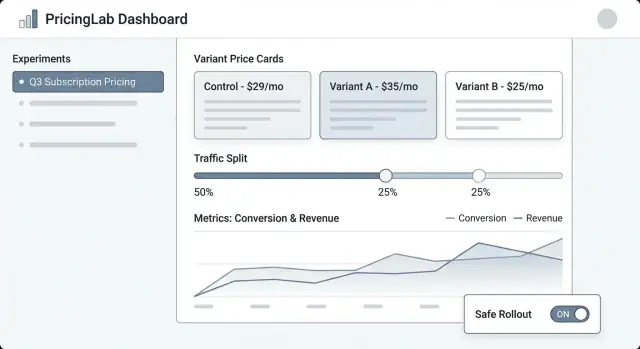
Telas principais a incluir
Lista de experimentos deve parecer um painel operacional. Mostre: nome, status (Rascunho/Agendado/Em execução/Pausado/Encerrado), datas de início/fim, divisão de tráfego, métrica primária e owner. Adicione “última atualização por” e timestamp visíveis para aumentar a confiança.
Detalhe do experimento é a base. Coloque um resumo compacto no topo (status, datas, público, divisão, métrica primária). Abaixo, use abas como Variantes, Segmentação, Métricas, Log de mudanças e Resultados.
Editor de variante precisa ser simples e opinativo. Cada linha de variante deve incluir preço (ou regra de preço), moeda, período de cobrança e uma descrição em linguagem simples (“Anual: $120 → $108”). Torne difícil editar acidentalmente uma variante ativa, exigindo confirmação.
Visão de resultados deve liderar com a decisão, não apenas gráficos: “Variante B aumentou a conversão no checkout em 2,1% (IC 95% …).” Depois, forneça drill-downs e filtros de apoio.
Design para clareza (e confiança)
Use badges de status consistentes e mostre uma timeline de datas-chave. Exiba a divisão de tráfego como percentagem e uma barra pequena. Inclua um painel “Quem mudou o quê” que lista edições em variantes, segmentação e métricas.
Guardrails e validação
Antes de permitir Start, exija: ao menos uma métrica primária selecionada, pelo menos duas variantes com preços válidos, plano de ramp-up (opcional mas recomendado) e plano de rollback ou preço fallback. Se faltar algo, mostre erros acionáveis (“Adicione uma métrica primária para habilitar resultados”).
Ações rápidas que economizam tempo
Forneça ações seguras e visíveis: Pausar, Parar, Rampa (ex.: 10% → 25% → 50%) e Duplicar (copiar configurações para novo Rascunho). Para ações arriscadas, use confirmações que resumem impacto (“Pausar congela atribuições e para exposição”).
Prototipando a ferramenta interna rapidamente
Se quiser validar fluxos (Rascunho → Agendado → Em execução) antes de investir em build completo, uma plataforma vibe-coding como Koder.ai pode ajudar a levantar um app interno a partir de uma especificação por chat — e iterar rápido com telas baseadas em papéis, logs de auditoria e dashboards simples. É útil para protótipos iniciais onde você quer uma UI React funcional e um backend Go/PostgreSQL que possa exportar e endurecer depois.
Dashboards e Relatórios que Orientam Decisões
Um dashboard de experimento de preço deve responder rapidamente: “Devemos manter esse preço, reverter ou continuar testando?” O melhor reporting não é o mais sofisticado — é o mais confiável e fácil de explicar.
O essencial acima da dobra
Comece com um conjunto pequeno de gráficos de tendência que atualizam automaticamente:
- Taxa de conversão ao longo do tempo (com marcador claro de “experimento iniciado”)
- Receita por visitante (ou ticket médio, dependendo do negócio)
- Reembolsos/cancelamentos se preço afetar retenção
Abaixo dos gráficos, inclua uma tabela de comparação de variantes: nome da variante, share de tráfego, visitantes, compras, taxa de conversão, receita por visitante e o delta vs controle.
Para indicadores de confiança, evite jargão acadêmico. Use rótulos claros como:
- “Leitura inicial” (dados insuficientes)
- “Tendência melhor/pior” (direcional)
- “Alta confiança” (pronto para decisão)
Uma tooltip curta pode explicar que confiança aumenta com amostra e tempo.
Quebras por segmento que evitam rollouts ruins
Preço frequentemente “vence” no agregado mas falha em grupos chave. Facilite abas de segmento:
- Novos vs recorrentes
- Região (país/estado)
- Dispositivo (mobile/desktop)
- Tier de plano (ou categoria de produto)
Mantenha as mesmas métricas em todos os segmentos para comparações consistentes.
Alertas de anomalia acionáveis
Adicione alertas leves no dashboard:
- Queda súbita na conversão após mudança de preço
- Pico de receita que pode ser causado por bugs de tracking ou eventos pontuais
- Lacunas de dados (eventos pararam, tráfego muito baixo, ingestão atrasada)
Ao aparecer um alerta, mostre a janela suspeita e um link para o status bruto de eventos.
Exportações e compartilhamento para alinhamento rápido
Torne o reporting portátil: download CSV da vista atual (incluindo segmentos) e link interno compartilhável para o relatório do experimento. Se útil, linke um explicador curto como /blog/metric-guide para que stakeholders entendam sem marcar reunião.
Permissões, Logs de Auditoria e Governança
Experimentos de preço tocam receita, confiança do cliente e frequentemente relatórios regulatórios. Um modelo simples de permissões e um trilho de auditoria claro reduzem lançamentos acidentais, discussões “quem mudou isso?” e ajudam a acelerar deploys com menos reversões.
Papéis que refletem como times trabalham
Mantenha papéis fáceis de explicar e difíceis de usar de forma indevida:
- Viewer: acesso somente leitura a setups, status e relatórios.
- Editor: pode criar rascunhos (variantes, copy, regras de elegibilidade) mas não iniciar/parar nem mudar splits em produção.
- Approver: revisa e aprova rascunhos, e pode executar ações em produção (start, stop, ramp) dentro dos guardrails.
- Admin: gerencia papéis, configurações globais e controles de emergência.
Se tiver múltiplos produtos ou regiões, faça papéis com escopo por workspace (ex.: “Precificação UE”) para que um editor numa área não impacte outra.
Logs de auditoria que você possa confiar
Seu app deve logar cada mudança com quem, o quê, quando, idealmente com diffs “antes/depois”. Eventos mínimos a capturar:
- Definições de variante (preço, moeda, período), divisões de tráfego, start/stop e regras de segmentação.
- Ações de aprovação (solicitado, aprovado, rejeitado) e rollbacks.
- Mudanças em fontes de dados (qual stream de receita ou evento está sendo usado).
Torne logs pesquisáveis e exportáveis (CSV/JSON), e linke-os diretamente da página do experimento para que revisores não precisem procurar. Uma view dedicada /audit-log ajuda times de compliance.
Trate identificadores de clientes e receita como sensíveis por padrão:
- Masque identificadores brutos (hashing, tokenização) e limite acesso a breakdowns de receita.
- Restrinja regras de segmentação que possam revelar atributos protegidos.
- Armazene segredos (chaves de API, credenciais de warehouse) fora do banco principal.
Comentários e notas de decisão
Adicione notas leves em cada experimento: hipótese, impacto esperado, racional de aprovação e um “por que paramos” ao encerrar. Seis meses depois, essas notas evitam reexecuções de ideias falhas — e tornam o reporting muito mais crível.
Testes e Checagens de Qualidade Antes do Lançamento
Faça seu orçamento render mais
Publique o que você construiu com Koder.ai ou indique colegas e ganhe créditos de uso.
Experimentos de preço falham de forma sutil: uma divisão 50/50 deriva para 62/38, um cohort vê moeda errada ou eventos nunca chegam aos relatórios. Antes de deixar clientes reais verem um novo preço, trate o sistema de experimentos como uma feature de pagamento — valide comportamento, dados e modos de falha.
Consistência de atribuição e precisão da divisão
Comece com casos de teste determinísticos para provar que a lógica de atribuição é estável entre serviços e releases. Use entradas fixas (IDs, chaves de experimento, salt) e assegure que a mesma variante é retornada sempre.
customer_id=123, experiment=pro_annual_price_v2 -> variant=B
customer_id=124, experiment=pro_annual_price_v2 -> variant=A
Depois, teste a distribuição em escala: gere 1M de IDs sintéticos e verifique que a divisão observada esteja dentro da tolerância (ex.: 50% ± 0.5%). Verifique também casos de borda como limites de tráfego (apenas 10% inscritos) e grupos de holdout.
Valide coleta de eventos ponta a ponta
Não pare em “o evento foi disparado”. Adicione um fluxo automatizado que cria uma atribuição de teste, dispara um evento de compra/checkout e verifica:
- o evento foi aceito pelo coletor
- foi armazenado com os campos experiment/variant corretos
- aparece na query de relatório com timestamps corretos e deduplicação
Execute isso em staging e em produção com um experimento de teste limitado a usuários internos.
Ferramentas de QA para checagens não técnicas
Dê a QA e PMs uma ferramenta simples de “preview”: insira um customer ID (ou session ID) e veja a variante atribuída e o preço exato que seria exibido. Isso captura problemas de arredondamento, moeda, impostos e “plano errado” antes do lançamento.
Considere uma rota interna segura como /experiments/preview que nunca altera atribuições reais.
Simule falhas e configurações ruins
Pratique cenários feios:
- Pipeline de eventos down: UI continua funcionando; métricas mostram banner de aviso e badge “dados incompletos”.
- Serviço de experimentos indisponível: produto cai para preço de controle (e loga o fallback).
- Configuração inválida (experimentos sobrepostos, preço inválido): bloqueie publicação com erros de validação claros.
Se você não consegue responder com confiança “o que acontece quando X quebra?”, ainda não está pronto para lançar.
Plano de Lançamento, Monitoramento e Iteração
Lançar um gerenciador de experimentos de preço é menos sobre “entregar uma tela” e mais sobre garantir controle do blast radius, observar comportamento rapidamente e recuperar com segurança.
Abordagem de deploy: reduza risco no dia um
Comece com um caminho de lançamento que case com sua confiança e restrições de produto:
- Rollout gradual: habilite experimentos para pequena porcentagem do tráfego elegível, depois expanda em passos (ex.: 1% → 10% → 50%).
- Feature flag: coloque o sistema de experimentos inteiro atrás de uma flag para poder desligar sem redeploy. Útil enquanto integrações se estabilizam.
- Beta interno: restrinja experimentos a funcionários ou contas de teste para validar atribuição, renderização de preço e integridade do checkout antes de expor clientes reais.
Monitoramento: o que vigiar nas primeiras horas
Trate monitoramento como requisito de release, não um “nice to have”. Configure alertas para:
- Taxas de erro: falhas de API, erros no checkout e exceções do serviço de preços.
- Latência: p95/p99 para fetch de preço, atribuição e páginas de checkout.
- Volume de eventos: quedas ou picos súbitos em eventos chave (view price, add to cart, purchase).
- Atribuição faltante: compras sem experiment/variant IDs, ou variant IDs que não batem com o log de atribuição.
Runbooks: pausar e reverter rápido
Crie um runbook escrito para operações e on-call:
- Um kill switch global para pausar todos os experimentos.
- Um caminho de reverter para preços baseline (preços baseline em cache, defaults seguros).
- Donos claros: quem aprova pausar, quem comunica impacto e como registrar o incidente.
Iteração após o MVP
Depois que o workflow core estiver estável, priorize upgrades que melhorem decisões: regras de segmentação (geo, plano, tipo de cliente), estatísticas e guardrails mais fortes, e integrações (data warehouse, billing, CRM). Se você oferece tiers ou pacotes, considere expor capacidades de experimentos em /pricing para que times entendam o que é suportado.