O que você está construindo: o app web de IDP em termos diretos
Um app web de IDP é uma “porta de entrada” interna para o seu sistema de engenharia. É onde desenvolvedores vão descobrir o que já existe (serviços, bibliotecas, ambientes), seguir a maneira preferida de construir e executar software, e solicitar mudanças sem vasculhar uma dúzia de ferramentas.
Igualmente importante, não é outro substituto tudo-em-um para Git, CI, consoles de nuvem ou sistemas de tickets. O objetivo é reduzir atrito orquestrando o que você já usa — tornando o caminho certo o mais fácil.
Os problemas que ele deve resolver
A maioria das equipes constrói um app web de IDP porque o trabalho diário é desacelerado por:
- Espalhamento de ferramentas: o conhecimento de “onde clicar” vive na memória tribal.
- Onboarding lento: novos engenheiros passam semanas aprendendo processos em vez de entregar.
- Padrões inconsistentes: serviços são criados e operados de formas diferentes, dificultando confiabilidade e segurança.
O app web deve transformar isso em workflows repetíveis e informação clara e pesquisável.
Blocos principais
Um IDP prático geralmente tem três partes:
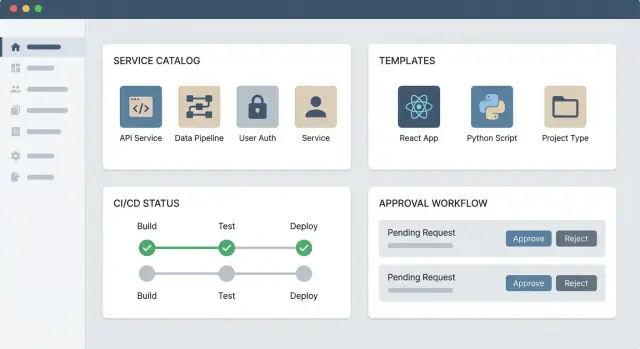
- UI do portal: um catálogo de serviços, pontos de entrada para documentação e formulários self-service (por exemplo, “criar um serviço”, “solicitar acesso”, “provisionar um banco de dados”).
- APIs de backend: a lógica de negócio que valida solicitações, aplica política e registra ações.
- Integrações: conectores para sua cadeia de ferramentas (hospedagem de Git, CI/CD, ferramentas de infraestrutura, gerenciadores de segredos, gestão de incidentes) para que ações ocorram nos sistemas de registro.
Quem é dono (e quem não é)
O time de plataforma normalmente é dono do produto do portal: a experiência, as APIs, os templates e as guardrails.
Os times de produto possuem seus serviços: manter metadados precisos, manter docs/runbooks e adotar os templates fornecidos. Um modelo saudável é responsabilidade compartilhada: o time de plataforma constrói a estrada pavimentada; os times de produto dirigem nela e ajudam a melhorá-la.
Usuários, casos de uso e métricas de sucesso
Um app web de IDP vence ou falha com base em servir as pessoas certas com os “caminhos felizes” certos. Antes de escolher ferramentas ou desenhar diagramas de arquitetura, fique claro sobre quem usará o portal, o que eles querem realizar e como você medirá progresso.
Usuários primários (e o que lhes interessa)
A maioria dos portais IDP tem quatro públicos principais:
- Desenvolvedores de aplicação: querem padrões rápidos e seguros para criar e rodar serviços sem esperar por tickets.
- SRE / ops: querem padronização, menos mudanças-surpresa e propriedade clara quando incidentes acontecem.
- Segurança / compliance: querem controles consistentes (revisões de acesso, tratamento de segredos, trilhas de auditoria) sem bloquear entrega.
- Gerentes de engenharia / líderes de produto: querem visibilidade — o que existe, quem é dono e se os times estão entregando com confiabilidade.
Se você não consegue descrever como cada grupo se beneficia em uma frase, provavelmente está construindo um portal que parecerá opcional.
Mapeie 5–10 jornadas-chave
Escolha jornadas que acontecem semanalmente (não anualmente) e torne-as realmente de ponta a ponta:
- Criar um novo serviço a partir de um template (repo + CI + ownership + tags).
- Solicitar um ambiente (dev/stage) com guardrails.
- Ver saúde do serviço (status de deploy, alertas, dependências).
- Rotacionar chaves / segredos com um workflow auditável.
- Solicitar acesso a um sistema ou conjunto de dados com aprovações.
Escreva cada jornada como: gatilho → passos → sistemas tocados → resultado esperado → modos de falha. Isso vira seu backlog de produto e seus critérios de aceite.
Defina métricas de sucesso que você realmente pode rastrear
Boas métricas se ligam diretamente a tempo economizado e atrito removido:
- Tempo até o primeiro deploy para um novo serviço (mediana, p90).
- Volume de tickets manuais para solicitações comuns (e tempo de resolução).
- Taxa de adoção: % de serviços registrados, % de teams usando templates.
- Taxa de falha de mudança e tempo médio de restauração (se o portal padroniza a entrega).
Escreva uma declaração de escopo “versão 1”
Mantenha curta e visível:
Escopo V1: “Um portal que permite que desenvolvedores criem um serviço a partir de templates aprovados, o registre no catálogo de serviços com um dono, e mostre status de deploy + saúde. Inclui RBAC básico e logs de auditoria. Exclui dashboards personalizados, substituição completa de CMDB e workflows sob medida.”
Essa declaração é seu filtro contra scope creep — e a âncora do roadmap para o que vem depois.
Escopo do MVP e roadmap para um portal interno
Um portal interno é bem-sucedido quando resolve um problema doloroso de ponta a ponta, e então ganha o direito de expandir. O caminho mais rápido é um MVP estreito entregue a um time real em semanas — não trimestres.
Um MVP estreito que ainda pareça “completo”
Comece com três blocos:
- Catálogo de serviços: um lugar para descobrir o que existe, quem é o dono e onde ficam os links operacionais.
- Um workflow self-service: escolha uma solicitação de alta frequência (por exemplo, “criar um novo repositório de serviço” ou “provisionar um ambiente padrão”) e automatize-a.
- Hub de docs/links: não migre tudo — aponte para fontes de verdade existentes (CI/CD, ferramentas de incidente, runbooks) enquanto você aprende o que as pessoas realmente usam.
Esse MVP é pequeno, mas entrega um resultado claro: “Consigo encontrar meu serviço e realizar uma ação importante sem pedir no Slack.”
Se quiser validar a UX e o fluxo “caminho feliz” rapidamente, uma plataforma de prototipagem como Koder.ai pode ser útil para prototipar a UI do portal e telas de orquestração a partir de uma especificação escrita do workflow. Como o Koder.ai pode gerar um app web em React com backend Go + PostgreSQL e suporta exportação do código-fonte, times podem iterar rápido e ainda manter propriedade de longo prazo do código.
Estrutura de backlog: descobrir, criar, operar, governar
Para manter o roadmap organizado, agrupe trabalho em quatro blocos:
- Descobrir: busca, tags, propriedade, páginas de time, visualizações de dependências.
- Criar: templates, scaffolding, provisionamento de ambiente, configurações padrão.
- Operar: links para dashboards/runbooks, informações de on-call, resumos de SLO, ações comuns.
- Governar: RBAC, etapas de aprovação, logs de auditoria, checagens de política.
Essa estrutura evita um portal que é “só catálogo” ou “só automação” sem nada conectando os dois.
Automatizar agora vs. apontar para fora
Automatize apenas o que atende pelo menos um destes critérios: (1) repetido semanalmente, (2) sujeito a erros quando feito manualmente, (3) requer coordenação entre times. Todo o resto pode ser um link bem-curado para a ferramenta certa, com instruções claras e propriedade definida.
Aprimoramento progressivo sem redesenho
Desenhe o portal para que novos workflows se conectem como ações adicionais em uma página de serviço ou ambiente. Se cada novo workflow exigir repensar a navegação, a adoção vai travar. Trate workflows como módulos: entradas consistentes, status consistentes, histórico consistente — assim você adiciona mais sem mudar o modelo mental.
Arquitetura de referência: UI, APIs e integrações
Uma arquitetura prática mantém a experiência do usuário simples enquanto lida com o trabalho “bagunçado” de integrações por trás dos panos. O objetivo é dar aos desenvolvedores um único app web, mesmo que ações frequentemente atravessem Git, CI/CD, contas de nuvem, ticketing e Kubernetes.
Escolha um modelo de deployment
Há três padrões comuns, e a escolha certa depende de quão rápido você precisa entregar e quantos times vão estender o portal:
- Aplicação única (monólito): MVP mais rápido. UI, API e lógica de integração entregues juntas. Bom quando o time de plataforma possui a maioria dos recursos.
- Serviços modulares: UI, API núcleo e alguns serviços de integração separados. Facilita escalar e clarificar propriedade conforme o portal cresce.
- Baseado em plugins: um “núcleo” estável mais plugins para fontes de catálogo, scaffolding, docs e workflows. Melhor quando muitos times contribuem com recursos.
Componentes centrais (o que roda onde)
No mínimo, espere estes blocos:
- Web UI (portal do desenvolvedor): navegação do catálogo, rotas recomendadas, formulários, páginas de status.
- API de backend (geralmente atrás de um API gateway): auth, checagens RBAC, validação, orquestração.
- Workers de integração: tarefas de longa duração (criação de repositório, provisionamento) executadas assincronamente.
- Banco de dados: configuração do portal, visualizações em cache do catálogo, histórico de workflows, eventos de auditoria.
Onde o estado deve viver
Decida cedo o que o portal “possui” versus o que apenas exibe:
- Mantenha fonte de verdade nos sistemas existentes (Git, IAM da nuvem, CI/CD, Kubernetes, ticketing).
- Armazene no DB do portal: solicitações de workflow, status, aprovações, logs de auditoria e índices em cache que deixam a UI rápida.
Confiabilidade para integrações
Integrações falham por razões normais (limites de taxa, falhas transitórias, sucesso parcial). Projete para:
- Retries com backoff e mensagens de erro claras
- Idempotência (re-executar uma solicitação não deve criar duplicatas)
- Timeouts e cancelamento
- Histórico durável de workflows para que usuários vejam o que aconteceu e possam recuperar com segurança
Modelo de dados: catálogo de serviços e propriedade
Seu catálogo de serviços é a fonte de verdade sobre o que existe, quem é o dono e como se encaixa no resto do sistema. Um modelo de dados claro evita “serviços misteriosos”, entradas duplicadas e automações quebradas.
Defina a entidade principal “Service”
Comece concordando sobre o que “serviço” significa na sua organização. Para a maioria, é uma unidade deployável (API, worker, website) com um ciclo de vida.
No mínimo, modele estes campos:
- Nome + descrição (legível)
- Donos: um time primário, mais contatos secundários opcionais (grupo de on-call, tech lead)
- Repositórios de origem: um ou vários links/IDs de repo
- Ambientes de execução: dev/stage/prod, ou variantes por região
- Dependências: serviços upstream/downstream e bibliotecas compartilhadas
Adicione metadados práticos que alimentam o portal:
- Lifecycle (experimental, ativo, obsoleto)
- Criticidade/tier (para expectativas de suporte e governança)
- Links (runbooks, dashboards, SLOs, canal de incidentes)
Modele relacionamentos explicitamente
Trate relacionamentos como primeira classe, não apenas campos de texto:
- Services ↔ teams: muitos serviços por time; às vezes propriedade compartilhada (use
primary_owner_team_id mais additional_owner_team_ids).
- Services ↔ resources: conecte a recursos de nuvem (namespaces de Kubernetes, filas, bancos) para que as pessoas respondam “o que este serviço usa?”.
- Service tiers: armazene o tier como enum estruturado e ligue a políticas (por exemplo, tier-0 exige on-call e logs de auditoria).
Essa estrutura relacional possibilita páginas como “tudo que o Time X possui” ou “todos os serviços que tocam este banco”.
Identificadores e regras de nomenclatura
Decida cedo o ID canônico para que duplicatas não apareçam após importações. Padrões comuns:
- Um slug estável (ex.:
payments-api) aplicado como único
- Um UUID imutável mais um slug legível
- Opcional: uma chave derivada do repo (
org_github/repo) se repos são 1:1 com serviços
Documente regras de nomeação (caracteres válidos, unicidade, política de renomeação) e valide na criação.
Planeje como os dados permanecem frescos
Um catálogo falha quando fica obsoleto. Escolha uma ou combine:
- Importações agendadas (sync noturno de Git, CI/CD, inventário de nuvem)
- Webhooks (atualiza em mudanças de repo, deploys, mudanças de propriedade)
- Streams de eventos (publique eventos como “service.created” ou “dependency.updated”)
Mantenha um last_seen_at e data_source por registro para mostrar frescor e depurar conflitos.
Autenticação, autorização e auditabilidade
Experimente sem medo
Use instantâneos e reversão para iterar com segurança em alterações do portal e modelos.
Se o seu IDP for confiável, ele precisa de três coisas que funcionem juntas: autenticação (quem é você?), autorização (o que pode fazer?) e auditabilidade (o que aconteceu e quem fez?). Faça isso certo cedo e você evita retrabalho — especialmente quando o portal começa a lidar com mudanças em produção.
A maioria das empresas já tem infraestrutura de identidade. Use-a.
Faça SSO via OIDC ou SAML como caminho padrão de login, e puxe membros de grupo do seu IdP (Okta, Azure AD, Google Workspace, etc.). Então mapeie grupos para papéis do portal e participação em times.
Isso simplifica onboarding (“faça login e já está no time correto”), evita armazenamento de senhas e permite que TI aplique políticas globais como MFA e timeouts de sessão.
Defina papéis claros (e o que eles podem fazer)
Evite um modelo vago “admin vs todos”. Um conjunto prático de papéis para um portal interno é:
- Developer: navegar pelo portal, usar templates e workflows self-service dentro de escopos permitidos.
- Service Owner: gerenciar a entrada do catálogo de serviços (metadados, on-call, lifecycle), ver histórico específico do serviço.
- Approver: aprovar ou rejeitar solicitações sensíveis (acesso a prod, novos ambientes, recursos com impacto de custo).
- Platform Admin: gerenciar templates, integrações, configurações globais e padrões de política.
- Auditor: acesso somente leitura a logs de auditoria, aprovações e histórico de configuração.
Mantenha os papéis pequenos e compreensíveis. Você pode estender depois, mas um modelo confuso reduz a adoção.
RBAC mais permissões a nível de recurso
RBAC é necessário, mas não suficiente. O portal também precisa de permissões por recurso: acesso deve ser escopado a um time, um serviço ou um ambiente.
Exemplos:
- Um desenvolvedor pode disparar “criar ambiente sandbox” para serviços do seu time, mas não de outros.
- Um dono de serviço pode editar a entrada do catálogo de serviços para serviços que possui.
- Um aprovador pode aprovar solicitações apenas para centros de custo ou namespaces de produção específicos.
Implemente isso com um padrão de política simples: (principal) pode (ação) em (recurso) se (condição). Comece com escopo time/serviço e cresça a partir daí.
Trilhas de auditoria para ações sensíveis
Trate logs de auditoria como recurso de primeira classe, não detalhe de backend. O portal deve registrar:
- Quem iniciou um workflow self-service (e de onde)
- Valores de parâmetros submetidos (mascarar segredos)
- Quem aprovou/negou e comentários
- Mudanças resultantes (links para execuções de CI/CD, tickets ou mudanças de infraestrutura)
- Alterações em templates, permissões e integrações
Facilite o acesso às trilhas de auditoria nos locais onde as pessoas trabalham: uma página de serviço no portal, uma aba “Histórico” do workflow e uma visão administrativa para compliance. Isso também acelera revisões de incidentes quando algo quebra.
UX para desenvolvedores: torne o caminho certo o mais simples
Boa UX não é aparência — é reduzir atrito quando alguém tenta entregar. Desenvolvedores devem responder rapidamente: O que existe? O que posso criar? O que precisa de atenção agora?
Navegação baseada em tarefas reais
Ao invés de organizar menus por sistemas de backend (“Kubernetes”, “Jira”, “Terraform”), estruture o portal em torno do trabalho que desenvolvedores realmente fazem:
- Descobrir: encontrar serviços, APIs, docs, donos, runbooks
- Criar: iniciar um novo serviço, adicionar um endpoint, solicitar um banco
- Operar: ver saúde, incidentes, status de deploy, mudanças recentes
- Governar: permissões, checagens de compliance, exceções de política
Essa navegação por tarefas facilita onboarding: novos colegas não precisam conhecer sua cadeia de ferramentas para começar.
Torne a propriedade impossível de ignorar
Cada página de serviço deve mostrar claramente:
- Time dono e canal do time
- Rotação de on-call e caminho de escalonamento
- Repositório(s) primário(s) e alvo de deploy
Coloque esse painel “Quem é dono?” próximo ao topo, não escondido em uma aba. Em incidentes, segundos importam.
Busca, filtros e status do jeito que as pessoas pensam
Busca rápida é a característica poderosa do portal. Suporte filtros que desenvolvedores usam naturalmente: time, lifecycle (experimental/production), tier, linguagem, plataforma e “de minha propriedade”. Adicione indicadores de status nítidos (healthy/degraded, SLO em risco, bloqueado por aprovação) para que usuários escaneiem uma lista e decidam o que fazer.
Ao criar recursos, peça apenas o que é realmente necessário agora. Use templates (“rotas recomendadas”) e padrões para evitar erros evitáveis — convenções de nomeação, hooks de logging/metrics e configurações CI padrão devem vir pré-preenchidos. Se um campo for opcional, esconda-o em “Opções avançadas” para que o caminho feliz seja rápido.
Workflows self-service: templates, aprovações e histórico
Projete integrações com menos risco
Rascunhe telas de conectores e fluxos de orquestração antes de integrar cada API de fornecedor.
Self-service é onde um IDP ganha confiança: desenvolvedores devem completar tarefas comuns de ponta a ponta sem tickets, enquanto times de plataforma mantêm controle sobre segurança, conformidade e custo.
Escolha os tipos de workflow que importam primeiro
Comece com um pequeno conjunto de workflows que mapeiam para solicitações frequentes e de alto atrito. Os “quatro primeiros” típicos:
- Criar serviço: scaffolder um repo, registrar no catálogo, definir ownership e bootstrap do CI/CD.
- Provisionar ambiente: criar um ambiente dev/stage com networking, logging e budgets padrão.
- Solicitar acesso: conceder acesso com privilégio mínimo a um sistema (banco, fila, API de terceiros) com opção de expiração.
- Rotacionar segredos: disparar rotação, atualizar configurações downstream e validar que aplicações estão saudáveis.
Esses workflows devem ser opinionados e refletir sua rota recomendada, permitindo escolhas controladas (linguagem/runtime, região, tier, classificação de dados).
Defina um contrato de workflow (para manter templates previsíveis)
Trate cada workflow como uma API de produto. Um contrato claro torna workflows reutilizáveis, testáveis e fáceis de integrar.
Um contrato prático inclui:
- Inputs: campos tipados com defaults (ex.: nome do serviço, time dono, ambiente, sensibilidade de dados).
- Validação: regras de nomeação, regiões permitidas, checagens de quota e “já existe?”.
- Passos: sequência de ações (rodar template, chamar CI/CD, criar recursos na nuvem, atualizar catálogo de serviços).
- Outputs: artefatos e links que desenvolvedores precisam (URL do repo, URL de deploy, link do runbook, recursos criados).
Mantenha a UX focada: exponha só os inputs que o desenvolvedor realmente decide, e infira o resto do catálogo de serviços e das políticas.
Aprovações rápidas, claras e aplicáveis
Aprovações são inevitáveis para ações sensíveis (acesso a prod, dados sensíveis, aumento de custo). O portal deve tornar aprovações previsíveis:
- Quem aprova o quê: defina aprovadores por regra (dono do time, dono do sistema, segurança) em vez de pings ad-hoc.
- Limites de tempo: defina SLA para aprovação e expire automaticamente solicitações antigas.
- Escalonamento: se o aprovador primário estiver indisponível, direcione a um grupo backup ou rotação on-call.
Crucialmente, aprovações devem ser parte do motor de workflow, não um canal manual. O desenvolvedor precisa ver status, próximos passos e por que a aprovação é exigida.
Armazene histórico e resultados para que times se autodigam
Cada execução de workflow deve produzir um registro permanente:
- Inputs usados, resultados de validação e decisões de aprovadores
- Logs passo-a-passo (com segredos mascarados)
- Outputs finais, recursos criados e ações de rollback
Esse histórico vira seu “rastro em papel” e sistema de suporte: quando algo falha, desenvolvedores veem exatamente onde e por quê — muitas vezes resolvendo sem abrir ticket. Também dá aos times de plataforma dados para melhorar templates e detectar falhas recorrentes.
Integrações: conectar o portal à sua cadeia de ferramentas
Um portal só parece “real” quando consegue ler e agir sobre os sistemas que desenvolvedores já usam. Integrações transformam uma entrada de catálogo em algo que pode ser deployado, observado e suportado.
A maioria dos portais precisa de um conjunto básico de conexões:
- Git (repositórios, branches padrão, CODEOWNERS, pull requests)
- CI/CD (pipelines, status de build, artifacts, promoções)
- Kubernetes (clusters, namespaces, workloads, rollouts)
- Nuvem (contas/projetos, networking, serviços gerenciados)
- IAM (times, grupos, SSO, mapeamentos de papéis)
- Segredos (vaults, referências a segredos, status de rotação)
Seja explícito sobre o que é somente leitura (ex.: status de pipeline) vs escrita (ex.: disparar um deploy).
Prefira API-first; use webhooks ou sync quando necessário
Integrações API-first são mais fáceis de raciocinar e testar: você pode validar auth, esquemas e tratamento de erros.
Use webhooks para eventos em tempo quase real (PR mergeado, pipeline finalizado). Use sync agendado para sistemas que não conseguem empurrar eventos ou onde consistência eventual é aceitável (ex.: importação noturna de contas de nuvem).
Construa uma camada de conectores (não incorpore provedores no core)
Crie um conector fino que normalize detalhes vendor-specific em um contrato interno estável (ex.: Repository, PipelineRun, Cluster). Isso isola mudanças quando você migrar de ferramenta e mantém a UI/API do portal limpa.
Um padrão prático é:
- Portal chama seu conector
- Conector lida com auth, rate limits, retries, mapping
- Conector retorna dados normalizados + links acionáveis (ex.:
/deployments/123)
Documente modos de falha e o que usuários devem fazer
Cada integração deve ter um pequeno runbook: como “degradado” aparece, como é mostrado na UI e o que fazer.
Exemplos:
- Git API rate-limited: portal mostra dados em cache; usuário pode navegar no catálogo, mas “Criar a partir do template” fica desabilitado.
- CI/CD indisponível: portal oferece fallback manual (link para UI do pipeline) e explica intervalo de nova tentativa.
- Gerenciador de segredos indisponível: bloqueie mudanças que exijam novos segredos; permita acesso somente leitura a metadados do serviço.
Mantenha esses docs perto do produto (ex.: /docs/integrations) para que desenvolvedores não adivinhem.
Observabilidade: monitorando o portal e suas automações
Seu portal não é só UI — é uma camada de orquestração que dispara CI/CD, cria recursos na nuvem, atualiza catálogo e aplica aprovações. Observabilidade permite responder, rápido e com confiança: “O que aconteceu?”, “Onde falhou?” e “Quem precisa agir a seguir?”
Trace cada solicitação através dos passos
Instrumente cada execução de workflow com um correlation ID que siga a requisição desde a UI do portal por APIs backend, checagens de aprovação e ferramentas externas (Git, CI, nuvem, ticketing). Adicione tracing de requests para uma visão única com caminho e tempo de cada passo.
Complete traces com logs estruturados (JSON) que incluam: nome do workflow, run ID, nome do passo, serviço alvo, ambiente, ator e resultado. Isso facilita filtrar por “todos os runs failed do template-deploy” ou “tudo que afetou o Serviço X”.
Métricas que refletem dor do desenvolvedor
Métricas infra básicas não bastam. Adicione métricas de workflow que mapeiem para resultados reais:
- Contagem de execuções, taxa de sucesso e duração por workflow e passo
- Tempo de espera por aprovação vs tempo de execução (identifica gargalos)
- Retries, timeouts e limites de taxa dos conectores
Visões operacionais dentro do portal
Dê aos times de plataforma páginas “de relance”:
- Fila de workflows: em execução, enfileirados, falhados, aguardando aprovação
- Saúde dos conectores: validade de token, última chamada bem-sucedida, taxa de erro
- Status de sync: última sincronização do catálogo, drift detectado, tamanho do backlog
Ligue cada status a detalhes e logs/traces exatos daquela execução.
Alertas, retenção e auditoria
Configure alertas para integrações quebradas (ex.: 401/403 repetidos), aprovações travadas (sem ação por N horas) e falhas de sync. Planeje retenção de dados: mantenha logs de alto volume por menos tempo, mas retenha eventos de auditoria por mais tempo para compliance e investigações, com controles de acesso e opções de exportação.
Segurança e governança sem desacelerar times
Adicione histórico e auditoria de fluxos
Crie uma API em Go com PostgreSQL para armazenar requisições, aprovações e eventos de auditoria.
Segurança em um portal IDP funciona melhor quando parece “guardrails”, não portões. O objetivo é reduzir escolhas arriscadas fazendo o caminho seguro ser o mais fácil — mantendo autonomia para os times entregarem.
Governança pode acontecer no momento em que um desenvolvedor solicita algo (novo serviço, repositório, ambiente ou recurso na nuvem). Trate cada formulário e chamada de API como input não confiável.
Aplique padrões em código, não só em docs:
- Exija propriedade (time, on-call e contato de escalonamento) e bloqueie criação quando faltar.
- Valide convenções de nomeação (service names, repo names, ambientes) para evitar colisões.
- Exija tags/metadados usados para alocação de custo, compliance e descoberta.
- Rejeite solicitações que não atendam política mínima (por exemplo, “exposição pública” precisa de revisão extra).
Isso mantém o catálogo limpo e facilita auditorias depois.
Proteja segredos por design
Um portal frequentemente toca credenciais (tokens de CI, acesso à nuvem, chaves de API). Trate segredos como radioativos:
- Nunca logue segredos ou os inclua em mensagens de erro.
- Prefira tokens de curta duração (OIDC, acesso federado, credenciais temporárias) a chaves longas.
- Armazene segredos apenas em um gerenciador dedicado; o portal deve referenciá-los, não copiá-los.
Assegure que logs de auditoria capturem quem fez o quê e quando — sem capturar valores de segredo.
Modele ameaças para falhas “normais”
Concentre-se em riscos realistas:
- Escalada de privilégios por RBAC mal configurado e permissões amplas
- Webhooks ou callbacks falsificados que disparem ações sem verificação
- Vazamento de dados via endpoints de debug, logs verbosos ou busca permissiva
Mitigue com verificação assinada de webhooks, princípio do menor privilégio e separação rígida entre operações de leitura e mudança.
Execute checagens de segurança em CI para o código do portal e para templates gerados (linting, checagens de política, análise de dependências). Agende revisões periódicas de:
- Papéis RBAC e mapeamentos de grupos
- Permissões de templates (quem pode criar o quê)
- Acesso emergencial “break-glass” e procedimentos de rotação
Governança é sustentável quando é rotineira, automatizada e visível — não um projeto pontual.
Rollout, adoção e manutenção a longo prazo
Um portal entrega valor apenas se times o usarem. Trate rollout como um lançamento de produto: comece pequeno, aprenda rápido e então escale com base em evidências.
Pilote com 1–3 times motivados e representativos (um time “greenfield”, um com legado pesado, um com requisitos de compliance mais rígidos). Observe como completam tarefas reais — registrar um serviço, solicitar infra, disparar um deploy — e corrija atrito imediatamente. O objetivo não é completude de features; é provar que o portal economiza tempo e reduz erros.
Torne a migração entediante e previsível
Forneça passos de migração que caibam em uma sprint normal. Por exemplo:
- registrar um serviço existente no catálogo de serviços,
- anexar propriedade e info de on-call,
- conectar CI/CD,
- adotar um template (repo, pipeline ou infra) no próximo componente novo.
Mantenha upgrades do “day 2” simples: permita que times adicionem metadados gradualmente e substituam scripts bespoke por workflows do portal.
Docs e ajuda in-product que as pessoas leem
Escreva docs concisos para workflows importantes: “Registrar um serviço”, “Solicitar um banco de dados”, “Rollback de um deploy”. Adicione ajuda in-product ao lado de campos de formulário e links para /docs/portal e /support para contexto mais profundo. Trate docs como código: versionamento, revisão e poda.
Propriedade é compromisso de longo prazo
Planeje propriedade contínua desde o começo: alguém precisa triagem do backlog, manter conectores atualizados e suportar usuários quando automações falham. Defina SLAs para incidentes do portal, cadência regular para atualização de conectores e revise logs de auditoria para identificar pontos de dor recorrentes e lacunas de política.
À medida que o portal amadurece, você provavelmente vai querer recursos como snapshots/rollback de configuração do portal, deploys previsíveis e promoção de ambientes entre regiões. Se estiver construindo ou experimentando rapidamente, o Koder.ai também pode ajudar times a levantar apps internos com modo de planejamento, deployment/hosting e exportação de código — útil para pilotar features antes de torná-las componentes de plataforma de longo prazo.