O que um fluxo de onboarding multi‑etapa precisa fazer
Um onboarding multi‑etapa é uma sequência guiada de telas que ajuda um novo usuário a ir de “registrado” a “pronto para usar o produto”. Em vez de pedir tudo de uma vez, você divide a configuração em passos menores que podem ser concluídos em uma sessão ou ao longo do tempo.
Você precisa de um onboarding multi‑etapa quando a configuração é mais do que um único formulário—especialmente quando inclui escolhas, pré‑requisitos ou checagens de conformidade. Se seu produto exige contexto (setor, função, preferências), verificação (email/telefone/identidade) ou configuração inicial (workspaces, faturamento, integrações), um fluxo por etapas mantém tudo compreensível e reduz erros.
Fluxos de onboarding comuns que você já viu
Onboarding multi‑etapa está em todo lugar porque suporta tarefas que naturalmente acontecem em estágios, como:
- Configuração de conta: criar workspace, convidar colegas, escolher plano
- Completar perfil: nome, função, objetivos, preferências
- Verificação: confirmação de email/telefone, checagens KYC/ID, configuração de 2FA
- Tutoriais e guias de primeiro uso: tour do produto, criação de projeto de exemplo, checklist “faça isso primeiro”
Como deve ser o “sucesso”
Um bom fluxo de onboarding não é “telinhas concluídas”, é usuários alcançando valor rapidamente. Defina sucesso em termos que casem com seu produto:
- Ativação: o usuário completa a ação-chave que prediz retenção de longo prazo (por ex., cria o primeiro projeto, conecta uma fonte de dados)
- Taxa de conclusão: que porcentagem de usuários finaliza as etapas obrigatórias (e as opcionais, se relevante)
- Tempo‑até‑valor: quanto tempo leva para um novo usuário alcançar o primeiro resultado significativo
O fluxo também deve suportar retomada e continuidade: usuários podem sair e voltar sem perder progresso, e devem pousar na próxima etapa lógica.
Riscos típicos a evitar
Onboarding multi‑etapa falha de formas previsíveis:
- Abandono: muitas etapas, benefícios pouco claros ou pedir dados sensíveis cedo demais
- Etapas confusas: rótulos vagos (“Configuração”), requisitos ocultos ou navegação inconsistente
- Perda de dados: problemas com refresh/voltar, timeouts de sessão, salvamentos parciais não tratados
O objetivo é fazer o onboarding parecer um caminho guiado, não um teste: propósito claro por etapa, rastreamento de progresso confiável e maneira fácil de retomar onde o usuário parou.
Antes de desenhar telas ou escrever código, decida o que seu onboarding tenta alcançar—e para quem. Um fluxo multi‑etapa só é “bom” se levar as pessoas certas ao estado final correto com mínima confusão.
Identifique seus principais tipos de usuário
Diferentes usuários chegam com contexto, permissões e urgência diferentes. Comece nomeando as personas de entrada principais e o que já se sabe sobre elas:
- Novo usuário (cadastro self‑serve): tipicamente precisa criar conta, verificar email, completar perfil básico e executar ações de primeiro valor.
- Usuário convidado: frequentemente já pertence a uma organização e deve pular a criação de org; pode precisar aceitar termos, definir senha e confirmar função.
- Conta criada por admin: pode ter campos pré‑preenchidos e passos de segurança obrigatórios (MFA, reset de senha no primeiro login).
Para cada tipo, liste restrições (ex.: “não pode editar nome da empresa”), dados requeridos (ex.: “deve escolher um workspace”) e atalhos potenciais (ex.: “já verificado via SSO”).
Defina o que significa “pronto”
O estado final do onboarding deve ser explícito e mensurável. “Pronto” não é “finalizou todas as telas”; é um status pronto para o negócio, como:
- Perfil com completude mínima
- Organização/workspace configurado
- Faturamento definido (ou explicitamente adiado)
- Usuário alcançou a primeira ação significativa (ex.: cria um projeto)
Escreva os critérios de conclusão como um checklist que seu backend possa avaliar, não como um objetivo vago.
Etapas obrigatórias vs opcionais, dependências e regras de pulo
Mapeie quais etapas são obrigatórias para o estado final e quais são opcionais. Documente dependências (“não pode convidar colegas antes de o workspace existir”).
Por fim, defina regras de pulo com precisão: quais etapas podem ser puladas, por qual tipo de usuário, em quais condições (ex.: “pular verificação de email se autenticado via SSO”) e se etapas puladas podem ser revistas depois nas configurações.
Desenhe o mapa do fluxo: etapas, ramificações e pontos de entrada
Antes de construir telas ou APIs, desenhe o onboarding como um mapa de fluxo: um diagrama que mostra cada etapa, para onde o usuário pode ir a seguir e como pode retornar depois.
Escreva as etapas com nomes curtos e focados em ações (verbos ajudam): “Criar senha”, “Confirmar email”, “Adicionar dados da empresa”, “Convidar colegas”, “Conectar faturamento”, “Finalizar.” Mantenha a primeira versão simples e depois acrescente detalhes como campos obrigatórios e dependências (ex.: faturamento não antes da escolha do plano).
Um teste útil: cada etapa deve responder a uma pergunta—ou “Quem é você?”, “Do que você precisa?” ou “Como o produto deve ser configurado?”. Se uma etapa tenta fazer as três, divida‑a.
2) Decida linear vs. ramificações condicionais
A maioria dos produtos se beneficia de uma espinha dorsal majoritariamente linear com ramificações condicionais apenas quando a experiência realmente difere. Regras comuns de ramificação:
- Função: admin vs. membro
- Plano: gratuito vs. pago
- Região: requisitos de IVA, consentimento de privacidade
- Caso de uso: pessoal vs. negócio
Documente isso como notas “if/then” no mapa (ex.: “If region = EU → show VAT step”). Isso mantém o fluxo compreensível e evita construir um labirinto.
3) Defina pontos de entrada (como o onboarding começa)
Liste todos os lugares onde um usuário pode entrar no fluxo:
- Primeiro login após o cadastro
- Aceitação de link de convite
- Lembrete “Complete a configuração” nas configurações (
/settings/onboarding)
Cada entrada deve levar o usuário à próxima etapa correta, não sempre à etapa um.
4) Planeje reentrada (comportamento de retomar)
Assuma que usuários vão sair no meio de uma etapa. Decida o que acontece quando retornam:
- Retomar na última etapa incompleta
- Preservar campos parciais (rascunho) vs. limpar ao sair
- Lidar com etapas “obsoletas” se o fluxo mudar depois
Seu mapa deve mostrar um caminho claro de “retomar” para que a experiência pareça confiável, não frágil.
Padrões de UX para um onboarding claro e de baixa fricção
Um bom onboarding parece um caminho guiado, não um teste. O objetivo é reduzir fadiga de decisão, tornar expectativas óbvias e ajudar o usuário a se recuperar rapidamente quando algo dá errado.
Um wizard funciona melhor quando etapas devem ser completadas em ordem (ex.: identidade → faturamento → permissões). Um checklist é apropriado quando o onboarding pode ser feito em qualquer ordem (ex.: “Adicionar logo”, “Convidar colegas”, “Conectar calendário”). Tarefas guiadas (dicas e callouts embutidos no produto) são ótimas quando o aprendizado acontece fazendo, não apenas preenchendo formulários.
Se estiver em dúvida, comece com um checklist + deep links para cada tarefa, e trave apenas as etapas realmente necessárias.
Mostre progresso sem pressão
O feedback de progresso deve responder: “Quanto falta?” Use uma das abordagens:
- Contagem de etapas (ex.: Etapa 2 de 5) para wizards lineares
- Marcos (ex.: Conta → Equipe → Integrações) para tarefas agrupadas
- Percentual apenas se for honesto e estável (evite saltos)
Também adicione um indicativo “Salvar e concluir depois”, especialmente para fluxos mais longos.
Rótulos, microcopy e padrões amigáveis
Use rótulos simples (“Nome da empresa”, não “Identificador de entidade”). Adicione microcopy que explique por que você está pedindo aquilo (“Usamos isso para personalizar faturas”). Quando possível, pré‑preencha com dados existentes e escolha padrões seguros.
Estados de erro e recuperação
Projete erros como um caminho à frente: destaque o campo, explique o que fazer, mantenha a entrada do usuário e foque no primeiro campo inválido. Para falhas do servidor, mostre uma opção de retry e preserve o progresso para que o usuário não repita etapas concluídas.
Mobile e acessibilidade desde o início
Faça alvos de toque grandes, evite formulários multi‑coluna e mantenha ações primárias “sticky” visíveis. Garanta navegação por teclado completa, estados de foco visíveis, inputs rotulados e texto de progresso acessível a leitores de tela (não só uma barra visual).
Modelo de dados: usuários, etapas, progresso e versões
Um fluxo multi‑etapa suave depende de um modelo de dados que responda três perguntas com confiança: o que o usuário deve ver a seguir, o que ele já forneceu e qual definição do fluxo ele está seguindo.
Entidades principais (o que armazenar)
Comece com um conjunto pequeno de tabelas/coleções e cresça só quando necessário:
- User: seu registro de usuário existente.
- OnboardingFlow: um fluxo nomeado (ex.: “Onboarding padrão”, “Onboarding enterprise”).
- Step: definição de uma etapa (título, tipo, ordem, campos obrigatórios, texto de ajuda). Etapas devem pertencer a uma versão específica do fluxo.
- StepResponse: dados salvos do usuário para uma etapa (as respostas), mais status de validação.
- Completion (ou OnboardingProgress): um registro resumo que liga um usuário a uma versão do fluxo e rastreia o status geral.
Essa separação mantém a “configuração” (Flow/Step) claramente separada dos “dados do usuário” (StepResponse/Progress).
Versões: não quebre usuários em progresso
Decida cedo se os fluxos serão versionados. Na maioria dos produtos, a resposta é sim.
Quando você edita etapas (renomear, reordenar, acrescentar campos obrigatórios), você não quer que usuários no meio do processo comecem a falhar em validações ou percam o lugar. Uma abordagem simples é:
- Flow tem
id e version (ou flow_version_id imutável).
- Progress aponta para um
flow_version_id específico para sempre.
- Novos usuários recebem a versão mais recente; usuários existentes continuam na versão atribuída até serem migrados intencionalmente.
Progresso parcial e timestamps
Para salvar progresso, escolha entre autosave (salvar enquanto o usuário digita) e salvar explícito no “Próximo”. Muitas equipes combinam: salvam rascunhos automaticamente e só marcam a etapa “concluída” quando o usuário clica em Próximo.
Rastreie timestamps para relatórios e troubleshooting: started_at, completed_at e last_seen_at (além de saved_at por etapa). Esses campos alimentam análises de onboarding e ajudam o suporte a entender onde alguém travou.
Lógica de fluxo: estado e transições
Entregue a API de onboarding
Crie endpoints para rascunhos, envio, retomar e conclusão com respostas fáceis de validar.
Um onboarding multi‑etapa é mais fácil de raciocinar quando você o trata como uma máquina de estados: a sessão de onboarding do usuário está sempre em um “estado” (etapa atual + status), e você só permite transições específicas entre estados.
Modele o fluxo como transições permitidas
Em vez de permitir que o frontend navegue livremente, defina um pequeno conjunto de status por etapa (por exemplo: not_started → in_progress → completed) e um conjunto claro de transições (por exemplo: start_step, save_draft, submit_step, go_back, reset_step).
Isso fornece comportamento previsível:
- Usuários não pulam etapas obrigatórias a menos que as regras do fluxo permitam.
- “Retomar onboarding” é apenas carregar o último estado conhecido.
- Ramificações são explícitas: uma transição pode mover para etapas diferentes com base nas respostas armazenadas.
Regras de conclusão de etapa (validação + checagens servidoras)
Uma etapa só é “concluída” quando ambas as condições forem satisfeitas:
- Validação no cliente passa (campos obrigatórios, formatos etc.).
- Checagens no servidor passam (regras de negócio e verificações externas), como “este email não está em uso”, “CNPJ/ID confere com o país” ou “nome da empresa permitido”.
Armazene a decisão do servidor junto com a etapa, incluindo códigos de erro. Isso evita casos em que a UI pensa que uma etapa está pronta, mas o backend discorda.
Lidando com invalidação quando respostas anteriores mudam
Um caso fácil de esquecer: usuário edita uma etapa anterior e torna etapas posteriores inválidas. Ex.: mudar “País” pode invalidar “Dados fiscais” ou “Planos disponíveis”.
Trate isso rastreando dependências e reavaliando etapas downstream após cada envio. Resultados comuns:
- Marcar etapas afetadas como
needs_review (ou reverter para in_progress).
- Limpar campos específicos que não são mais aplicáveis.
- Recalcular a próxima etapa com base na nova condição de ramificação.
Navegação para trás e revalidação
“Voltar” deve ser suportado, mas de forma segura:
- Permita navegar para etapas anteriores sem perder dados.
- Quando o usuário retorna a uma etapa posterior, reexecute a validação usando respostas atuais e regras do servidor.
Isso mantém a experiência flexível e garante que o estado da sessão permaneça consistente e aplicável.
Design da API backend para onboarding por etapas
Sua API backend é a “fonte da verdade” sobre onde um usuário está no onboarding, o que ele já preencheu e o que pode fazer a seguir. Uma boa API mantém o frontend simples: ele pode renderizar a etapa atual, submeter dados com segurança e recuperar após refreshs ou falhas de rede.
Endpoints principais que você provavelmente precisará
No mínimo, projete para estas ações:
- Obter etapa atual (e progresso)
GET /api/onboarding → retorna a chave da etapa atual, % de conclusão e quaisquer valores salvos necessários para renderizar a etapa.
- Salvar dados da etapa (rascunho ou final)
PUT /api/onboarding/steps/{stepKey} com { "data": {…}, "mode": "draft" | "submit" }
- Ir para próxima / anterior (opcional se você inferir o próximo a partir do estado salvo)
POST /api/onboarding/steps/{stepKey}/nextPOST /api/onboarding/steps/{stepKey}/previous
- Concluir onboarding
POST /api/onboarding/complete (o servidor verifica se todas as etapas obrigatórias foram satisfeitas)
Mantenha respostas consistentes. Por exemplo, depois de salvar, retorne o progresso atualizado mais a etapa seguinte decidida pelo servidor:
{ "currentStep": "profile", "nextStep": "team", "progress": 0.4 }
Idempotência: proteja o progresso de envios duplos
Usuários vão clicar duas vezes, dar retry em conexões ruins ou seu frontend pode reenviar requisições após timeout. Torne o “salvar” seguro:
- Aceite um header
Idempotency-Key para requisições PUT/POST e deduplique por (userId, endpoint, key).
- Trate
PUT /steps/{stepKey} como sobrescrita total do payload armazenado (ou documente claramente regras de mesclagem parcial).
- Opcionalmente adicione uma
version (ou etag) para evitar sobrescrever dados mais novos com retries antigos.
Erros claros e validação por campo
Retorne mensagens acionáveis que a UI possa exibir ao lado dos campos:
{
"error": "VALIDATION_ERROR",
"message": "Please fix the highlighted fields.",
"fields": {
"companyName": "Company name is required",
"teamSize": "Must be a number"
}
}
Também distinga 403 (não permitido) de 409 (conflito / etapa errada) e 422 (validação) para que o frontend reaja corretamente.
Autenticação e autorização
Separe capacidades de usuário e admin:
- Endpoints de usuário exigem sessão autenticada e só devem acessar o estado de onboarding do chamador.
- Endpoints de admin (ex.:
GET /api/admin/onboarding/users/{userId} ou sobrescritas) devem ser protegidos por papéis e auditáveis.
Essa fronteira evita vazamentos de privilégio acidentais enquanto ainda permite que suporte e operações ajudarem usuários travados.
Implementação frontend: roteamento, retomada e confiabilidade
O trabalho do frontend é fazer o onboarding parecer fluido mesmo quando a rede é ruim. Isso significa roteamento previsível, comportamento de retomada confiável e feedback claro quando dados estão sendo salvos.
Roteamento: uma URL por etapa vs. página única
Uma URL por etapa (ex.: /onboarding/profile, /onboarding/billing) geralmente é mais fácil de raciocinar. Suporta back/forward do navegador, deep linking de emails e facilita refresh sem perder contexto.
Uma página única com estado interno pode funcionar para fluxos muito curtos, mas eleva o risco em refreshes, crashes e cenários de “copiar link para continuar”. Se usar essa abordagem, terá de ter persistência forte (veja abaixo) e gerenciamento cuidadoso do histórico.
Persistência de progresso: o servidor é a fonte da verdade
Armazene conclusão de etapa e os dados mais recentes no servidor, não só em localStorage. No carregamento da página, busque o estado atual de onboarding (etapa atual, etapas concluídas e quaisquer valores de rascunho) e renderize a partir disso.
Isso permite:
- Segurança em refresh
- Continuação entre dispositivos
- Visão consistente após admins mudarem o fluxo
UI otimista sem confundir usuários
UI otimista reduz fricção, mas precisa de limites:
- Mostre um status claro Salvando… / Salvo / Erro perto do botão primário.
- Desative o botão de envio enquanto a requisição está em andamento para evitar envios duplicados.
- Se fizer autosave, debouncing e revele falhas (“Não foi possível salvar. Tentar novamente”).
Quando um usuário retorna, não o jogue na etapa um. Apresente algo como: “Você está 60% concluído—continuar de onde parou?” com duas ações:
- Continuar (linka para a próxima etapa obrigatória)
- Terminar depois (leva ao app, com um banner persistente linkando de volta para
/onboarding)
Esse pequeno toque reduz abandono e respeita usuários que não querem completar tudo na hora.
Estratégia de validação e tratamento de dados parciais
Torne o comportamento de retomada confiável
Persista os dados das etapas no servidor para que os usuários possam atualizar, trocar de dispositivo e continuar sem problemas.
Validação é onde fluxos de onboarding ou parecem suaves ou frustrantes. O objetivo é capturar erros cedo, manter o usuário em movimento e ainda proteger seu sistema quando dados estiverem incompletos ou suspeitos.
Validar no navegador (feedback rápido)
Use validação no cliente para evitar erros óbvios antes de uma requisição de rede. Isso reduz churn e torna cada etapa responsiva.
Checagens típicas incluem campos obrigatórios, limites de tamanho, formatação básica (email/telefone) e regras simples entre campos (confirmação de senha). Mantenha mensagens específicas (“Digite um email de trabalho válido”) e posicione‑as ao lado do campo.
Validar no servidor (correção e segurança)
Trate a validação no servidor como fonte da verdade. Mesmo que a UI valide perfeitamente, usuários podem contornar. A validação no servidor deve impor:
- Autorização (o usuário pode editar só seu onboarding)
- Valores permitidos (enums, códigos de país, tipos de documento)
- Integridade de dados (constraints únicas, foreign keys)
- Controles de segurança (rate limits, sanitização de input)
Retorne erros estruturados por campo para que o frontend destaque exatamente o que precisa ser corrigido.
Suporte a checagens assíncronas
Algumas validações dependem de sinais externos ou demorados: unicidade de email, códigos de convite, sinais de fraude ou verificação de documentos. Trate isso com status explícitos (ex.: pending, verified, rejected) e um estado de UI claro. Se uma checagem estiver pendente, permita que o usuário continue quando possível e informe quando ele será notificado ou qual etapa será liberada depois.
Decida como tratar falhas parciais
Onboarding multi‑etapa frequentemente tem dados parciais como algo normal. Decide por etapa se deve:
- Salvar rascunho: armazenar inputs parciais e permitir navegar embora; marque a etapa como “em progresso”.
- Bloquear progresso: exigir um conjunto mínimo de campos antes de avançar.
Uma abordagem prática: “salvar rascunho sempre, bloquear só na conclusão da etapa.” Isso suporta retomar sessões sem reduzir o padrão de qualidade dos dados.
Analytics: medir conclusão e encontrar pontos de abandono
Analytics para onboarding multi‑etapa deve responder duas perguntas: “Onde as pessoas travam?” e “Que mudança melhoraria a conclusão?”. A chave é rastrear um pequeno conjunto de eventos consistentes em cada etapa, e torná‑los comparáveis mesmo quando o fluxo muda ao longo do tempo.
Eventos confiáveis para rastrear
Rastreie os mesmos eventos base para cada etapa:
step_viewed (usuário visualizou a etapa)step_completed (usuário submeteu e passou validação)step_failed (usuário tentou submeter mas falhou em validação ou checagens servidoras)flow_completed (usuário alcançou o estado de sucesso final)
Inclua um payload de contexto mínimo e estável em cada evento: user_id, flow_id, flow_version, step_id, step_index e um session_id (para separar “na mesma sessão” de “em dias diferentes”). Se suportar retomada, também inclua resume=true/false em step_viewed.
Abandono e tempo por etapa
Para medir abandono por etapa, compare contagens de step_viewed vs. step_completed para a mesma flow_version. Para medir tempo gasto, capture timestamps e compute:
- tempo de
step_viewed → step_completed
- tempo de
step_viewed → próximo step_viewed (útil quando usuários pulam)
Mantenha métricas de tempo agrupadas por versão; caso contrário, melhorias podem ser ofuscadas por mistura de versões antigas e novas.
Ganchos de experimentação sem quebrar métricas
Se fizer A/B test de copy ou reordenar etapas, trate isso como parte da identidade analítica:
- adicione
experiment_id e variant_id a cada evento
- mantenha
step_id estável mesmo se o texto de exibição mudar
- ao reordenar, mantenha o mesmo
step_id e use step_index para posição
Dashboards e exportações para stakeholders
Construa um dashboard simples que mostre taxa de conclusão, abandono por etapa, tempo mediano por etapa e “campos com mais falhas” (a partir do metadata de step_failed). Adicione exportações CSV para que times revisem progresso em planilhas e compartilhem sem precisar de acesso direto à ferramenta de analytics.
Ferramentas de admin: construtor de fluxos, rollouts e sobrescritas
Planeje antes de codificar
Defina etapas, ramificações e critérios de conclusão primeiro, depois gere a implementação com menos retrabalhos.
Um sistema de onboarding multi‑etapa vai precisar, com o tempo, de controle operacional: mudanças de produto, exceções de suporte e experimentação segura. Construir uma área admin interna evita que engenharia vire gargalo.
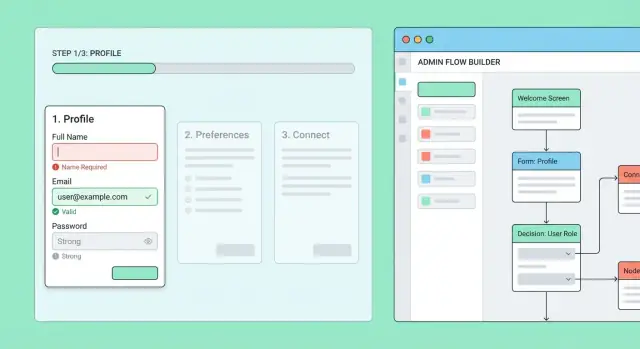
Construtor de fluxos: criar e editar etapas sem deploys
Comece com um simples “flow builder” que permita a funcionários autorizados criar e editar fluxos de onboarding e suas etapas.
Cada etapa deve ser editável com:
- Título e texto curto de ajuda
- Tipo de etapa (formulário, checklist, upload de documento, agendamento etc.)
- Campos obrigatórios e regras de validação
- Regras de ramificação opcionais (ex.: “Se usuário selecionar Empresa, mostrar etapa de IVA”)
Adicione um modo de preview que renderize a etapa como o usuário final veria. Isso pega copy confusa, campos faltando e ramificações quebradas antes de irem a usuários reais.
Versionamento e rollout seguro
Evite editar um fluxo ativo no lugar. Em vez disso, publique versões:
- Draft: editável, previsualizável
- Published: definição imutável usada por usuários
- Archived: mantida para suporte e auditoria
Rollouts devem ser configuráveis por versão:
- Apenas novos usuários: usuários existentes mantêm sua versão atual
- Porcentagem gradual: comece em 5–10% e aumente conforme as métricas estiverem saudáveis
- Targeting (opcional): por plano, região, parceiro ou campanha de convite
Isso reduz risco e dá comparações limpas ao medir conclusão e abandono.
Sobrescritas para suporte e operações
Times de suporte precisam de ferramentas para desbloquear usuários sem editar manualmente o banco:
- Marcar uma etapa como concluída (com motivo)
- Resetar o fluxo de um usuário para o início ou para uma etapa específica
- Mover um usuário uma etapa para trás após um erro
- Reenviar convite / magic link / email de verificação ligado ao onboarding
Logs de auditoria e permissões
Toda ação admin deve ser logada: quem mudou o quê, quando e os valores antes/depois. Restrinja acesso por papéis (somente visualização, editor, publicador, sobrescrita de suporte) para que ações sensíveis—como resetar progresso—sejam controladas e rastreáveis.
Testes, segurança e monitoramento antes do lançamento
Antes de entregar um fluxo de onboarding multi‑etapa, assuma duas coisas: usuários vão tomar caminhos inesperados, e algo vai falhar no meio (rede, validação, permissões). Uma boa checklist de lançamento prova que o fluxo está correto, protege dados de usuários e dá sinais de alerta cedo quando a realidade diverge do plano.
Teste o mapa do fluxo, não só a UI
Comece com testes unitários para sua lógica de workflow (estados e transições). Esses testes devem verificar que cada etapa:
- só pode ser entrada a partir de etapas permitidas
- produz a próxima etapa esperada dado uma resposta/role/plano
- lida com edge cases (pulagens, navegação pra trás, sessões expiradas)
Depois adicione testes de integração que exercitem sua API: salvar payloads de passo, retomar progresso e rejeitar transições inválidas. Testes de integração pegam problemas “funciona localmente” como índices faltando, bugs de serialização ou mismatches de versão entre frontend e backend.
Testes end‑to‑end para caminhos críticos
E2E devem cobrir pelo menos:
- caminho feliz de início → conclusão
- falhas comuns: erros de validação, 500 do servidor, timeout/retry e retomar após fechar o navegador
Mantenha cenários E2E pequenos mas significativos—foco nos poucos caminhos que representam a maioria dos usuários e o maior impacto em receita/ativação.
Proteja dados sensíveis por padrão
Aplique privilégio mínimo: admins de onboarding não devem automaticamente ter acesso total a registros de usuário, e contas de serviço só devem tocar nas tabelas/endpoints necessários.
Criptografe onde for relevante (tokens, identificadores sensíveis, campos regulados) e trate logs como risco de vazamento. Evite logar payloads brutos de formulários; logue IDs de etapa, códigos de erro e tempos. Se precisar logar trechos de payload para debug, redija campos consistentemente.
Monitoramento que detecta problemas cedo
Instrumente onboarding como funil de produto e API.
Monitore erros por etapa, latência de salvamento (p95/p99) e falhas de retomada. Configure alertas para quedas súbitas na taxa de conclusão, picos de falhas de validação em uma etapa ou aumento de erro de API após um release. Isso permite consertar a etapa quebrada antes que tickets de suporte se acumulem.
Onde o Koder.ai se encaixa (se quiser construir isso mais rápido)
Se você está implementando um sistema de onboarding por etapas do zero, a maior parte do tempo vai para os mesmos blocos descritos acima: roteamento de passos, persistência, validações, lógica de estado/progresso e uma interface admin para versionamento e rollouts. Koder.ai pode ajudar a prototipar e entregar essas peças mais rápido, gerando apps full‑stack a partir de uma especificação via chat—tipicamente com frontend React, backend em Go e modelo de dados PostgreSQL que mapeia claramente para fluxos, etapas e respostas de etapa.
Como o Koder.ai suporta exportação de código-fonte, hosting/deploy e snapshots com rollback, ele também é útil quando você quer iterar em versões de onboarding com segurança (e recuperar rápido se um rollout prejudicar a conclusão).