29 de nov. de 2025·8 min
Como construir uma app web para gerir ciclos de feedback de clientes
Aprenda a projetar e construir um app web que coleta, roteia, rastreia e fecha ciclos de feedback de clientes com workflows claros, papéis e métricas.
Aprenda a projetar e construir um app web que coleta, roteia, rastreia e fecha ciclos de feedback de clientes com workflows claros, papéis e métricas.
Um app de gestão de feedback não é “um lugar para armazenar mensagens”. É um sistema que ajuda sua equipe a passar de entrada para ação para retorno visível ao cliente, e então aprender com o que aconteceu.
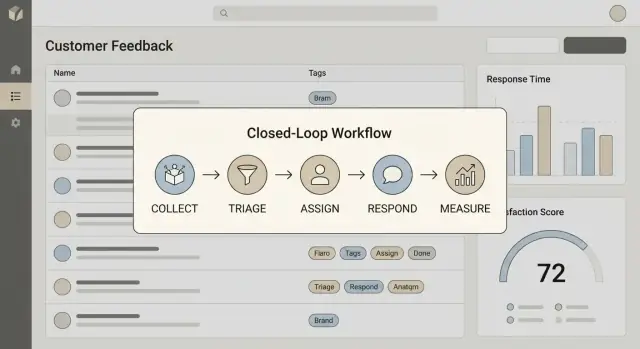
Escreva uma definição em uma frase que sua equipe possa repetir. Para a maioria das equipes, fechar o loop inclui quatro passos:
Se qualquer um desses passos estiver faltando, seu app se tornará um cemitério de backlog.
Sua primeira versão deve servir papéis do dia a dia:
Seja específico sobre as “decisões por clique”:
Escolha um pequeno conjunto de métricas que reflitam velocidade e qualidade, como tempo até a primeira resposta, taxa de resolução, e mudança no CSAT após o follow‑up. Elas serão sua estrela guia para escolhas de design posteriores.
Antes de desenhar telas ou escolher um banco, mapeie o que acontece com o feedback desde o momento em que é criado até a resposta. Um mapa simples mantém equipes alinhadas sobre o que “feito” significa e evita construir features que não se encaixam no trabalho real.
Liste suas fontes de feedback e observe quais dados cada uma fornece de forma confiável:
Mesmo que as entradas sejam diferentes, seu app deve normalizá‑las em um formato consistente de “item de feedback” para que a triagem ocorra em um só lugar.
Um modelo prático inicial costuma incluir:
Statuses para começar: New → Triaged → Planned → In Progress → Shipped → Closed. Mantenha o significado dos status documentado para que “Planned” não signifique “Talvez” para uma equipe e “Comprometido” para outra.
Duplicatas são inevitáveis. Defina regras cedo:
Uma abordagem comum é manter um item de feedback canônico e ligar outros como duplicatas, preservando a atribuição (quem solicitou) sem fragmentar o trabalho.
Um app de feedback vence ou perde no primeiro dia com base em se as pessoas conseguem processar feedback rapidamente. Mire em um fluxo que pareça: “escanear → decidir → seguir adiante”, enquanto preserva contexto para decisões posteriores.
Sua inbox é a fila compartilhada da equipe. Deve suportar triagem rápida por meio de um pequeno conjunto de filtros poderosos:
Adicione “views salvos” cedo (mesmo que básicos), pois equipes diferentes escaneiam diferente: Suporte quer “urgente + pagante”, Produto quer “pedidos de recurso + alto ARR”.
Quando um usuário abre um item, ele deve ver:
O objetivo é evitar trocar de aba só para responder: “Quem é este, o que quis dizer e já respondemos?”
Da visualização de detalhe, a triagem deve ser uma ação por decisão:
Você provavelmente precisará de dois modos:
Seja qual for a escolha, faça de “responder com contexto” o passo final—para que fechar o loop seja parte do workflow, não um pensamento posterior.
Um app de feedback rapidamente vira um sistema compartilhado de registro: produto quer temas, suporte quer respostas rápidas, liderança quer exports. Se você não definir quem pode fazer o quê (e provar o que aconteceu), a confiança se quebra.
Se você vai atender múltiplas empresas, trate cada workspace/org como um limite rígido desde o dia um. Todo registro central (item de feedback, cliente, conversa, tags, relatórios) deve incluir um workspace_id, e toda query deve ser escopada a ele.
Isso não é só detalhe de banco—afeta URLs, convites e analytics. Uma configuração segura: usuários pertencem a um ou mais workspaces, e permissões são avaliadas por workspace.
Mantenha a primeira versão simples:
Mapeie permissões para ações, não para telas: ver vs editar feedback, mesclar duplicatas, mudar status, exportar dados e enviar respostas. Isso facilita adicionar um papel “Somente leitura” depois sem reescrever tudo.
Um log de auditoria evita debates “quem mudou isso?”. Registre eventos chave com ator, timestamp e before/after quando útil:
Aplique uma política de senhas razoável, proteja endpoints com rate limiting (especialmente login e ingestão) e garanta tratamento seguro de sessões.
Projete com SSO em mente (SAML/OIDC) mesmo que seja entregue depois: armazene um ID do provedor de identidade e planeje linkagem de contas. Isso evita que pedidos enterprise forcem um refactor doloroso.
No início, o maior risco de arquitetura não é “vai escalar?”—é “vamos conseguir mudar rápido sem quebrar tudo?” Um app de feedback evolui rápido conforme você aprende como equipes realmente triam, roteiam e respondem.
Um monolito modular costuma ser a melhor primeira escolha. Você tem um serviço deployável, um conjunto de logs e debugging mais simples—enquanto mantém a base de código organizada.
Uma divisão prática de módulos parece com:
Pense em “pastas separadas e interfaces” antes de “serviços separados”. Se um limite ficar doloroso depois (ex.: volume de ingestão), você pode extraí‑lo com menos drama.
Prefira frameworks e bibliotecas que sua equipe consiga entregar com confiança. Um stack “sem novidades” normalmente vence porque:
Ferramentas exóticas podem esperar até ter restrições reais (alto volume de ingestão, latência estrita, permissões complexas). Até lá, otimize por clareza e entrega constante.
A maioria das entidades centrais—itens de feedback, clientes, contas, tags, atribuições—encaixa naturalmente num banco relacional. Você vai querer consultas boas, constraints e transações para mudanças de workflow.
Se busca full‑text e filtragem virarem críticas, adicione um índice de busca dedicado depois (ou use capacidades embutidas inicialmente). Evite ter duas fontes de verdade cedo demais.
Um sistema de feedback acumula rápido tarefas “faça isso depois”: enviar e‑mails, sync de integrações, processar anexos, gerar digests, disparar webhooks. Coloque isso em uma fila/worker desde o início.
Isso mantém a UI responsiva, reduz timeouts e torna falhas retryáveis—sem forçar microserviços no dia um.
Se seu objetivo é validar workflow e UI rápido (inbox → triage → respostas), considere usar uma plataforma de criação rápida como Koder.ai para gerar a primeira versão a partir de uma especificação estruturada. Ela pode ajudar a levantar um front React com backend Go + PostgreSQL, iterar em “modo planejamento” e ainda exportar o código‑fonte quando você estiver pronto para assumir um fluxo clássico de engenharia.
Sua camada de armazenamento decide se o ciclo de feedback parece rápido e confiável—ou lento e confuso. Mire num schema fácil de consultar para trabalho diário (triagem, atribuição, status), preservando detalhes brutos para auditoria.
Para um MVP, você cobre a maioria das necessidades com um pequeno conjunto de tabelas/coleções:
Uma regra útil: mantenha feedback enxuto (o que você consulta constantemente) e empurre o “todo o resto” para events e metadados específicos de canal.
Quando um ticket chega por e‑mail, chat ou webhook, armazene o payload de entrada bruto exatamente como recebido (ex.: headers + corpo do e‑mail, ou JSON do webhook). Isso ajuda a:
Padrão comum: uma tabela ingestions com source, received_at, raw_payload (JSON/text/blob) e link para o feedback_id criado/atualizado.
A maioria das telas se resume a alguns filtros previsíveis. Adicione índices cedo para:
(workspace_id, status) para views de inbox/kanban(workspace_id, assigned_to) para “meus itens”(workspace_id, created_at) para ordenação e filtros por data(tag_id, feedback_id) na tabela de junção ou um índice dedicado de lookup de tagsSe oferecer busca full‑text, considere um índice de busca separado (ou a busca embutida do banco) em vez de sobrecarregar produção com queries LIKE complexas.
Feedback frequentemente contém dados pessoais. Decida desde o início:
Implemente retenção como política por workspace (ex.: 90/180/365 dias) e aplique com job agendado que expire ingestions brutos primeiro, depois eventos/respostas antigas se necessário.
Ingestão é onde seu ciclo de feedback fica limpo e útil—ou vira bagunça. Mire em “fácil de enviar, consistente de processar.” Comece com alguns canais que seus clientes já usam e vá expandindo.
Um conjunto prático inicial costuma incluir:
Você não precisa de filtragem pesada no dia um, mas precisa de proteções básicas:
Normalize cada evento em um formato interno com campos consistentes:
Mantenha tanto o payload bruto quanto o registro normalizado para poder melhorar o parser depois sem perder dados.
Envie uma confirmação imediata (para e‑mail/API/widget quando possível): agradeça, explique o que acontece a seguir e evite promessas. Exemplo: “Revisamos todas as mensagens. Se precisarmos de mais detalhes, responderemos. Não podemos responder individualmente todas as solicitações, mas seu feedback está registrado.”
Uma inbox de feedback só permanece útil se as equipes conseguirem responder rapidamente a três perguntas: O que é isto? Quem é o dono? Quão urgente é? Triagem é a parte do app que transforma mensagens brutas em trabalho organizado.
Tags livres parecem flexíveis, mas fragmentam rápido (“login”, “log‑in”, “signin”). Comece com uma taxonomia pequena que espelhe como suas equipes de produto já pensam:
Permita que usuários sugiram novas tags, mas exija um dono (ex.: PM/Líder de Suporte) para aprová‑las. Isso mantém relatórios significativos depois.
Construa um motor de regras simples que possa rotear feedback automaticamente com base em sinais previsíveis:
Mantenha as regras transparentes: mostre “Roteado porque: plano Enterprise + palavra‑chave ‘SSO’.” Equipes confiam em automação quando podem auditá‑la.
Adicione timers de SLA em cada item e cada fila:
Exiba o status de SLA na lista (“2h restantes”) e na página de detalhe, para que a urgência seja compartilhada na equipe—não presa na cabeça de alguém.
Crie um caminho claro quando itens travarem: uma fila de atrasados, digests diários para donos e uma escada de escalonamento leve (Suporte → Líder de equipe → On‑call/Manager). O objetivo não é pressão—é evitar que feedback importante expire silenciosamente.
Fechar o loop é onde um sistema de gestão de feedback deixa de ser uma “caixa de coleta” e vira uma ferramenta de construção de confiança. O objetivo é simples: cada feedback pode ser conectado a trabalho real, e clientes que pediram algo podem ser informados do que aconteceu—sem planilhas manuais.
Comece permitindo que um item de feedback aponte para um ou mais objetos de trabalho internos (bug, tarefa, pedido de recurso). Não tente espelhar todo o seu issue tracker—armazene referências leves:
work_type (ex.: issue/task/feature)external_system (ex.: jira, linear, github)external_id e opcionalmente external_urlIsso mantém seu modelo de dados estável mesmo se você mudar de ferramenta depois. Também permite ver “todos os feedbacks de clientes ligados a esta release” sem raspar outro sistema.
Quando o trabalho vinculado chega em Shipped (ou Done/Released), seu app deveria poder notificar todos os clientes ligados aos itens de feedback relacionados.
Use uma mensagem templateada com placeholders seguros (nome, área do produto, resumo, link das notas de release). Mantenha editável no momento do envio para evitar linguagem estranha. Se você tiver notas públicas, linke‑as usando um caminho relativo como /releases.
Faça suporte a respostas pelos canais que você pode enviar de forma confiável:
Independente da escolha, registre respostas por item de feedback com uma timeline auditável: sent_at, channel, author, template_id e status de entrega. Se um cliente responder, armazene mensagens inbound com timestamps também, para provar que o loop foi realmente fechado—não apenas “marcado como shipped.”
Relatórios só são úteis se mudarem o que as equipes fazem em seguida. Mire em algumas views que as pessoas chequem diariamente, e expanda quando tiver confiança de que os dados de workflow (status, tags, donos, timestamps) são consistentes.
Comece com dashboards operacionais que apoiem roteamento e follow‑up:
Mantenha gráficos simples e clicáveis para que um gestor consiga aprofundar nos itens que compõem um pico.
Adicione uma página “customer 360” que ajude suporte e success a responder com contexto:
Essa view reduz perguntas duplicadas e faz follow‑ups parecerem intencionais.
As equipes vão pedir exports cedo. Forneça:
Mantenha filtragem consistente em todos os lugares (mesmos nomes de tags, intervalos de datas, definições de status). Essa consistência evita “duas versões da verdade.”
Pule dashboards que medem só atividade (tickets criados, tags adicionadas). Prefira métricas de resultado ligadas a ação e resposta: tempo até primeira resposta, % de itens que chegaram a uma decisão e problemas recorrentes que foram realmente resolvidos.
Um ciclo de feedback só funciona se viver onde as pessoas já passam tempo. Integrações reduzem copiar/colar, mantêm contexto próximo ao trabalho e fazem de “fechar o loop” um hábito em vez de um projeto especial.
Priorize sistemas que sua equipe usa para comunicação, construção e gestão de clientes:
Mantenha a primeira versão simples: notificações one‑way + deep links de volta ao seu app, depois adicione ações de escrita (ex.: “Atribuir dono” do Slack) mais tarde.
Mesmo que lance poucas integrações nativas, webhooks permitem que clientes e times internos conectem qualquer outra coisa.
Ofereça um pequeno e estável conjunto de eventos:
feedback.createdfeedback.updatedfeedback.closedInclua uma chave de idempotência, timestamps, tenant/workspace id e um payload mínimo mais uma URL para buscar detalhes completos. Isso evita quebrar consumidores quando seu modelo de dados evoluir.
Integrações falham por motivos normais: tokens revogados, limites de taxa, problemas de rede, mismatches de schema.
Projete para isso desde o início:
Se você estiver empacotando isto como produto, integrações também são gatilho de compra. Adicione passos claros do seu app (e site de marketing) para /pricing e /contact para times que queiram demo ou ajuda para conectar a stack.
Um app de feedback eficaz não é “finalizado” após o lançamento—ele é moldado por como equipes realmente triagem, agem e respondem. O objetivo do primeiro release é simples: provar o workflow, reduzir esforço manual e capturar dados limpos em que se possa confiar.
Mantenha escopo enxuto para entregar rápido e aprender. Um MVP prático normalmente inclui:
Se uma feature não ajuda a equipe a processar feedback ponta a ponta, pode esperar.
Usuários iniciais perdoam falta de features, mas não feedback perdido ou roteamento incorreto. Foque testes onde erros são caros:
Busque confiança no workflow, não cobertura perfeita.
Mesmo um MVP precisa de alguns essenciais “entediosos”:
Comece com um piloto: uma equipe, um conjunto limitado de canais e uma métrica de sucesso clara (ex.: “responder 90% do feedback de alta prioridade em até 2 dias”). Colete pontos de fricção semanalmente e itere no workflow antes de convidar mais equipes.
Trate dados de uso como seu roadmap: onde as pessoas clicam, onde abandonam, quais tags não são usadas e quais “workarounds” revelam requisitos reais.
"Fechar o loop" significa que você consegue mover de forma confiável de Coletar → Agir → Responder → Aprender. Na prática, todo item de feedback deve terminar com um resultado visível (implementado, recusado, explicado ou encaixado na fila) e — quando aplicável — uma resposta ao cliente com prazo.
Comece com métricas que reflitam velocidade e qualidade:
Escolha um conjunto pequeno para que as equipes não otimizem por métricas de vaidade.
Normalize tudo em uma única estrutura interna "item de feedback", mantendo os dados originais.
Uma abordagem prática:
Isso mantém a triagem consistente e permite reprocessar mensagens antigas quando seu parser melhorar.
Mantenha o modelo central simples e amigável para consultas:
Documente definições curtas e compartilhadas de status e comece com uma sequência linear:
Assegure que cada status responda “o que acontece a seguir?” e “quem é o responsável pelo próximo passo?” Se “Planned” às vezes significar “talvez”, divida ou renomeie para manter os relatórios confiáveis.
Defina duplicatas como “mesmo problema/solicitação subjacente”, não apenas texto semelhante.
Um fluxo comum:
Isso evita trabalho fragmentado mantendo um registro completo da demanda.
Mantenha a automação simples e auditável:
Mostre sempre “Roteado porque…” para que humanos possam confiar e corrigir. Comece com sugestões antes de impor roteamento automático rígido.
Trate cada workspace como um limite rígido:
workspace_id em todo registro centralworkspace_idDepois defina papéis por ações (ver/editar/mesclar/exportar/enviar respostas), não por telas. Adicione um cedo para mudanças de status, merges, atribuições e respostas.
Comece com um monolito modular e limites claros (auth/orgs, feedback, workflow, messaging, analytics). Use um banco relacional para dados transacionais do workflow.
Adicione jobs em background cedo para:
Isso mantém a UI rápida e as falhas retryáveis sem assumir microserviços cedo demais.
Armazene referências leves em vez de espelhar todo o seu rastreador de issues:
external_system (jira/linear/github)work_type (bug/task/feature)external_id (e opcionalmente external_url)Quando o trabalho vinculado estiver , dispare um fluxo para notificar todos os clientes ligados usando templates e rastreando o status de entrega. Se você tiver notas públicas, linke-as relativamente (ex.: ).
Use a timeline de eventos para auditoria e para não sobrecarregar o registro principal de feedback.
/releases