Antes de escolher métricas ou construir dashboards, decida pelo que seu app de confiabilidade será responsável — e o que não será. Um escopo claro impede que a ferramenta vire um “portal de ops” catch‑all em que ninguém confia.
Defina o que você vai rastrear
Comece listando as ferramentas internas que o app cobrirá (por exemplo, ticketing, folha de pagamento, integrações de CRM, pipelines de dados) e os times que as possuem ou dependem delas. Seja explícito sobre limites: “site voltado ao cliente” pode ficar fora do escopo, enquanto “console administrativo interno” está dentro.
Combine o que significa “confiabilidade” aqui
Organizações usam essa palavra de formas diferentes. Escreva sua definição de trabalho em linguagem simples — tipicamente uma mistura de:
- Disponibilidade: as pessoas conseguem acessar quando precisam?
- Latência: é rápido o suficiente para ser utilizável?
- Erros: falha de formas que os usuários percebem (timeouts, falhas de jobs, respostas inválidas)?
Se as equipes discordarem, seu app vai acabar comparando maçãs com laranjas.
Decida os resultados que você quer
Escolha 1–3 resultados principais, como:
- Detecção de problemas mais rápida (menor “time to notice”)
- Relatórios mais claros para gerentes e stakeholders
- Menos incidentes repetidos por meio de follow‑up melhor
Esses resultados vão orientar o que medir e como apresentar.
Identifique usuários e papéis
Liste quem usará o app e que decisões cada um toma: engenheiros investigando incidentes, suporte escalando problemas, gestores revisando tendências, e stakeholders que precisam de atualizações de status. Isso vai moldar terminologia, permissões e o nível de detalhe que cada visão deve mostrar.
Escolha as métricas de confiabilidade que importam (SLIs/SLOs)
O rastreamento de confiabilidade só funciona se todos concordarem com o que significa “bom”. Comece separando três termos parecidos.
SLIs vs SLOs vs SLAs (em termos simples)
Um SLI (Service Level Indicator) é uma medição: “Qual porcentagem de requisições obteve sucesso?” ou “Quanto tempo as páginas demoraram para carregar?”.
Um SLO (Service Level Objective) é a meta para essa medição: “99,9% de sucesso em 30 dias.”
Um SLA (Service Level Agreement) é uma promessa com consequências, normalmente externa (créditos, penalidades). Para ferramentas internas, frequentemente você define SLOs sem SLAs formais — o suficiente para alinhar expectativas sem transformar confiabilidade em direito contratual.
Escolha um conjunto pequeno e consistente de SLIs por ferramenta
Mantenha comparável entre ferramentas e fácil de explicar. Um baseline prático é:
- Uptime/disponibilidade: a ferramenta estava alcançável?
- Tempo de resposta: quão rápido páginas ou endpoints chave responderam?
- Taxa de erro: qual parcela de checks ou requisições falhou (5xx, timeouts, estados de falha conhecidos)?
Evite adicionar mais métricas até poder responder: “Que decisão essa métrica vai orientar?”
Use janelas rolling para que scorecards atualizem continuamente:
- 7 dias: pega regressões rapidamente
- 30 dias: relatório e tendências mensais
- 90 dias: estabilidade por trimestre
Seu app deve transformar métricas em ação. Defina níveis de severidade (por exemplo, Sev1–Sev3) e gatilhos explícitos como:
- Sev1: ferramenta fora do ar ou fluxo crítico bloqueado por X minutos
- Sev2: degradação importante (ex.: taxa de erro acima de Y% por Z minutos)
- Sev3: problemas menores ou intermitentes
Essas definições tornam alertas, timelines de incidentes e rastreamento de budget de erro consistentes entre equipes.
Planeje suas fontes de dados e a ingestão
Um app de rastreamento de confiabilidade é tão confiável quanto os dados por trás dele. Antes de construir pipelines de ingestão, mapeie cada sinal que você vai tratar como “verdade” e escreva qual pergunta ele responde (disponibilidade, latência, erros, impacto de deploy, resposta a incidentes).
Mapeie as fontes de dados que você já tem
A maioria dos times consegue cobrir o básico com uma mistura de:
- Status checks / probes sintéticos (uptime e tempo de resposta básico)
- Métricas (percentis de latência, taxas de erro, saturação)
- Logs (contagem de erros, endpoints que mais falham)
- Traces (onde a latência é gasta entre dependências)
- Ferramentas de ticketing/incidentes (inicio/fim do incidente, severidade, dono, links para postmortem)
Seja explícito sobre quais sistemas são autoridades. Por exemplo, seu “SLI de uptime” pode vir apenas de probes sintéticos, não de logs de servidor.
- Pull funciona bem para APIs (Prometheus, monitoramento da nuvem, ticketing): seu app faz polls em um cronograma.
- Push é melhor para eventos de alto volume (deploys, incidentes, alertas): sistemas enviam webhooks/eventos para seu app.
Defina frequência de atualização por caso de uso: dashboards podem atualizar a cada 1–5 minutos, enquanto scorecards podem ser computados a cada hora/dia.
Normalize identificadores e propriedade
Crie IDs consistentes para tools/services, ambientes (prod/stage) e owners. Combine regras de nomenclatura cedo para que “Payments-API”, “payments_api” e “payments” não vire três entidades distintas.
Retenção e privacidade
Planeje o que manter e por quanto tempo (ex.: eventos brutos 30–90 dias, agregados diários 12–24 meses). Evite ingerir payloads sensíveis; armazene apenas metadados necessários para análise de confiabilidade (timestamps, códigos de status, buckets de latência, tags de incidente).
Desenhe o modelo de dados e o esquema do banco
Seu esquema deve facilitar duas coisas: responder perguntas do dia a dia (“esta ferramenta está saudável?”) e reconstruir o que aconteceu durante um incidente (“quando os sintomas começaram, quem mudou o quê, quais alertas dispararam?”). Comece com um pequeno conjunto de entidades core e torne relacionamentos explícitos.
Entidades core (comece mínimo)
- Tool/Service: a ferramenta interna rastreada (nome, descrição, ambiente, criticidade).
- Check: um check de uptime ou sintético ligado a uma ferramenta (tipo, URL alvo, schedule, enabled).
- Metric: datapoints de séries temporais (latência, taxa de sucesso, contagem de erros) associados a uma ferramenta ou check.
- SLO: a meta e a janela de avaliação (ex.: 99,9% em 30 dias) mais configurações de error budget.
- Incident: um evento que impactou confiabilidade (severidade, status, início/fim, resumo).
- Event: um registro de timeline para incidentes (mudanças de estado, notas, alerta recebido, mitigação aplicada).
- Owner: time ou indivíduo responsável pela ferramenta.
Relacionamentos que mantêm queries simples
Um baseline prático é:
- Tool tem muitos Checks (e pode ter muitos SLOs).
- Check tem muitas Metrics (ou streams de métricas).
- Incident pertence a Tool, e Incident tem muitos Events para a timeline.
- Tool pertence a Owner (ou many-to-many se a propriedade compartilhada for comum).
Essa estrutura suporta dashboards (“tool → status atual → incidentes recentes”) e drill‑down (“incident → events → checks e métricas relacionadas”).
Campos de auditoria e tagging
Adicione campos de auditoria onde precisar de responsabilidade e histórico:
created_by, created_at, updated_atstatus mais rastreamento de mudanças de status (ou na tabela Event ou numa tabela dedicada de histórico)
Finalmente, inclua tags flexíveis para filtragem e relatórios (ex.: team, criticidade, sistema, compliance). Uma tabela de join tool_tags (tool_id, key, value) mantém tagging consistente e facilita scorecards e rollups posteriormente.
Selecione stack tecnológico e modelo de deploy
Seu tracker de confiabilidade deve ser entediante no bom sentido: fácil de rodar, fácil de mudar e fácil de suportar. A “stack certa” costuma ser aquela que seu time consegue manter sem heroísmos.
Escolha um framework web mainstream que seu time conheça bem — Node/Express, Django ou Rails são opções sólidas. Priorize:
- Convenções claras (para que novos contribuintes não se percam)
- Boas bibliotecas para auth, jobs em background e gráficos
- Caminhos de upgrade previsíveis
Se você integra com sistemas internos (SSO, ticketing, chat), escolha o ecossistema onde essas integrações são mais fáceis.
Se quiser acelerar a primeira iteração, uma plataforma de desenvolvimento assistido como Koder.ai pode ser um ponto de partida prático: você descreve suas entidades (tools, checks, SLOs, incidents), fluxos (alerta → incidente → postmortem) e dashboards em chat, e gera um scaffold de app web rapidamente. Como Koder.ai costuma mirar React no frontend e Go + PostgreSQL no backend, mapeia bem para a stack “entediante e de manutenção” que muitos times preferem — e você pode exportar o código-fonte se depois migrar para um pipeline manual.
Banco primeiro, depois peças de suporte
Para a maioria dos apps internos de confiabilidade, PostgreSQL é o default certo: ele lida bem com relatórios relacionais, consultas baseadas em tempo e auditoria.
Adicione componentes extras só quando resolverem um problema real:
- Cache (ex.: Redis) se dashboards estiverem lentos ou você for rate‑limited por APIs upstream
- Fila/jobs em background (Redis + worker, Sidekiq, Celery, BullMQ) para polling de uptime, envio de notificações e geração de relatórios
Modelo de hospedagem e deploy
Decida entre:
- Nuvem interna / Kubernetes quando precisar de acesso de rede mais fechado a serviços internos
- PaaS quando quiser ops mais simples e iteração rápida
Padronize dev/staging/prod e automatize deployments (CI/CD), para que mudanças não alterem silenciosamente números de confiabilidade. Se você usar uma plataforma (incluindo Koder.ai), procure por separação de ambientes, deploy/hosting e rollback rápido (snapshots) para iterar sem quebrar o tracker.
Gestão de configuração confiável
Documente configuração em um único lugar: variáveis de ambiente, segredos e feature flags. Mantenha um guia claro de “como rodar localmente” e um runbook mínimo (o que fazer se ingestão parar, fila encher ou banco atingir limites). Uma página curta em /docs costuma ser suficiente.
Desenhe a UX: dashboards, drill‑downs e fluxos
Inicie um piloto focado
Crie um rastreador leve para 2–3 ferramentas para validar SLIs, alertas e responsabilidades.
Um app de rastreamento de confiabilidade funciona quando as pessoas conseguem responder duas perguntas em segundos: “Estamos bem?” e “O que eu faço a seguir?” Desenhe telas em torno dessas decisões, com navegação clara de overview → ferramenta específica → incidente específico.
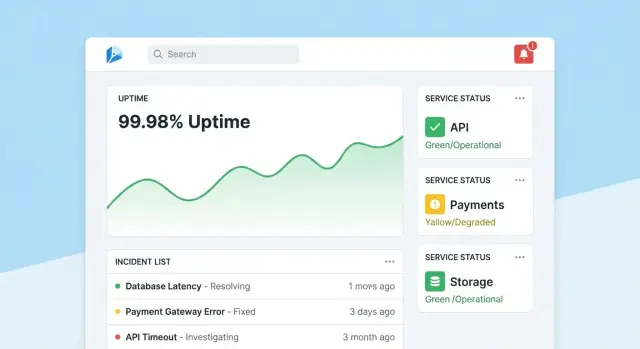
Página inicial: leitura rápida de saúde
Faça da homepage um centro de comando compacto. Comece com um resumo de saúde geral (por exemplo, número de ferramentas dentro dos SLOs, incidentes ativos, maiores riscos atuais), depois mostre incidentes e alertas recentes com badges de status.
Mantenha a visão padrão calma: destaque apenas o que precisa de atenção. Dê a cada tile um drill‑down direto para a ferramenta ou incidente afetado.
Página da ferramenta: do status à ação
Cada página de ferramenta deve responder “Esta ferramenta é confiável o suficiente?” e “Por que/por que não?” Inclua:
- Status atual do SLO com pass/fail simples e error budget restante
- Gráficos de uptime, latência ou taxa de erro em intervalos selecionáveis
- Mudanças recentes (deploys, edits de config, updates de checks) para tornar padrões óbvios
- Runbooks e owners: seção “O que fazer” em destaque com links e contatos
Projete gráficos para não‑especialistas: rotule unidades, marque thresholds de SLO e adicione explicações pequenas (tooltips) em vez de controles técnicos densos.
Página de incidente: contexto compartilhado e timeline
Uma página de incidente é um registro vivo. Inclua uma timeline (eventos capturados automaticamente como alerta disparado, acknowledge, mitigado), atualizações humanas, usuários impactados e ações tomadas.
Facilite publicar atualizações: uma caixa de texto, status predefinidos (Investigando/Identificado/Monitorando/Resolvido) e notas internas opcionais. Quando o incidente fechar, a ação “Iniciar postmortem” deve prefazer fatos da timeline.
Páginas de admin: propriedade e consistência
Admins precisam de telas simples para gerenciar tools, checks, metas de SLO e owners. Otimize para corretude: defaults sensíveis, validação e avisos quando mudanças afetam relatórios. Adicione uma trilha “última edição” visível para que as pessoas confiem nos números.
Implemente autenticação, permissões e trilhas de auditoria
Dados de confiabilidade só permanecem úteis se as pessoas confiarem neles. Isso significa amarrar cada mudança a uma identidade, limitar quem pode fazer edições de alto impacto e manter um histórico claro para revisões.
Autenticação: use o que sua empresa já usa
Para uma ferramenta interna, prefira SSO (SAML) ou OAuth/OIDC via seu provedor de identidade (Okta, Azure AD, Google Workspace). Isso reduz gestão de senhas e torna onboarding/offboarding automático.
Detalhes práticos:
- Aplique MFA via IdP (não reimplemente localmente).
- Mapeie grupos do IdP para papéis no app ao logar.
- Defina sessões curtas e suporte a logout manual.
Comece com papéis simples e adicione regras mais granulares só se necessário:
- Viewer: dashboards e scorecards somente leitura.
- Editor: criar/atualizar checks, incidentes e notas.
- Admin: gerenciar definições de SLO, thresholds, integrações e mapeamento de usuários/papéis.
Proteja ações que alteram outcomes ou narrativas:
- Apenas Admins podem mudar metas de SLO, thresholds de alerta ou mapeamentos de fontes de dados.
- Restrinja quem pode fechar incidentes ou marcá‑los como “resolvidos”, exigindo um resumo de resolução.
Trilhas de auditoria: histórico imutável de mudanças
Logue toda edição em SLOs, checks e campos de incidentes com:
- quem fez (usuário + papel)
- quando (timestamp)
- o que mudou (valores antes/depois)
- de onde veio (UI, API, automação)
Torne os logs pesquisáveis e visíveis nas páginas de detalhe relevantes (ex.: a página do incidente mostra todo o histórico de mudanças). Isso mantém revisões factuais e reduz discussões em postmortems.
Construa checks de monitoramento e coleta de uptime
Monitoramento é a “camada sensora” do seu app: transforma comportamento real em dados confiáveis. Para ferramentas internas, checks sintéticos geralmente são o caminho mais rápido porque você controla o que significa “saudável”.
Defina checks sintéticos por ferramenta
Comece com um conjunto pequeno de tipos de check que cobrem a maioria das apps internas:
- HTTP ping: confirma que o serviço responde (status code, TLS, headers básicos).
- Validação de endpoint: chama uma URL conhecida e valida algo significativo (shape JSON esperado, uma string-chave no HTML ou payload de health endpoint).
- Caminho “smoke” sem login: se possível, teste um fluxo de leitura que reflita a experiência do usuário (ex.: carregar a página do dashboard e verificar renderização).
Mantenha checks determinísticos. Se uma validação pode falhar por conteúdo mutável, você vai gerar ruído e minar a confiança.
Para cada execução de check, capture:
- Timestamp (start e end)
- Resultado: up/down/unknown
- Latência: duração total (e opcionalmente DNS/connect/TTFB se medir)
- Razão: código de erro, timeout, falha de validação ou mensagem de exceção
Armazene como eventos de séries temporais (uma linha por execução) ou como intervalos agregados (rollups por minuto com contagens e p95 de latência). Dados brutos são ótimos para debugging; rollups são ótimos para dashboards rápidos. Muitas equipes fazem ambos: mantêm eventos brutos por 7–30 dias e rollups para relatórios de longo prazo.
Trate outages vs. dados faltantes explicitamente
Um resultado de check ausente não deve automaticamente significar “down”. Adicione um estado unknown para casos como:
- worker de checagem parado
- partição de rede entre checker e alvo
- configuração removida no meio da execução
Isso evita inflar downtime e torna “gaps de monitoramento” visíveis como problema operacional.
Use workers em background (agendador estilo cron, filas) para executar checks em intervalos fixos (ex.: 30–60s para ferramentas críticas). Implemente timeouts, retries com backoff e limites de concorrência para que o checker não sobrecarregue serviços internos. Persista todo resultado de execução — inclusive falhas — para que o dashboard de uptime mostre status atual e histórico confiável.
Crie fluxos de alerta e notificação
Planeje o escopo antes de construir
Use o Modo de Planejamento para mapear ferramentas, papéis e limites, mantendo a primeira versão focada.
Alertas são onde rastreamento de confiabilidade vira ação. O objetivo é simples: notificar as pessoas certas, com o contexto certo, no momento certo — sem inundar todo mundo.
Vincule alertas aos SLOs (não só thresholds)
Comece definindo regras de alerta que mapeiem diretamente para seus SLIs/SLOs. Dois padrões práticos:
- Burn‑rate alerts: chamar quando o error budget está sendo consumido rápido o suficiente para perder o SLO se nada mudar.
- Quebras por threshold: avisar quando uma métrica ultrapassa um limite claro (ex.: disponibilidade abaixo de 99,5% por 15 minutos).
Para cada regra, armazene o “porquê” junto com o “o quê”: qual SLO é impactado, a janela de avaliação e a severidade pretendida.
Faça notificações acionáveis
Envie notificações pelos canais onde times já vivem (email, Slack, Microsoft Teams). Cada mensagem deve incluir:
- Um resumo curto (serviço + sintoma + severidade)
- Um link direto para a visualização relevante do dashboard (ex.: /services/payments?window=1h)
- Um link para a página do incidente, se criado (ex.: /incidents/123)
Evite despejar métricas brutas. Forneça um “próximo passo” curto como “Ver deployments recentes” ou “Abrir logs”.
Implemente:
- Deduplicação (mesmo fingerprint de alerta → atualizar thread existente)
- Agrupamento (um incidente pode coletar múltiplos alertas relacionados)
- Horários silenciosos e regras de roteamento para que alertas de baixa severidade não acordem on‑call
Suporte escalonamento e roteamento on‑call
Mesmo em ferramenta interna, as pessoas precisam de controle. Adicione escalonamento manual (botão na página do alerta/incidente) e integre com tooling de on‑call se houver (PagerDuty/Opsgenie), ou ao menos uma lista de rotação configurável armazenada no app.
Adicione gestão de incidentes e recursos de postmortem
Gestão de incidentes transforma “vimos um alerta” em resposta compartilhada e rastreável. Construa isso no app para que as pessoas movam sinal → coordenação sem pular entre ferramentas.
Permita criar um incidente diretamente de um alerta, página de serviço ou gráfico de uptime. Prefaça campos chave (serviço, ambiente, origem do alerta, primeiro timestamp) e atribua um ID único.
Um conjunto padrão de campos mantém leve: severidade, impacto no cliente (times internos afetados), owner atual e links para o alerta que disparou.
Ciclo de vida de status e colaboração
Use um ciclo simples que reflita como times realmente trabalham:
- Open → Investigating → Mitigated → Resolved
Cada mudança de status deve registrar quem fez e quando. Adicione updates de timeline (notas curtas com timestamp), suporte a anexos e links para runbooks e tickets (ex.: /runbooks/payments-retries ou /tickets/INC-1234). Isso vira o fio único para “o que aconteceu e o que fizemos”.
Postmortems com itens de ação
Postmortems devem ser rápidos de iniciar e consistentes para revisão. Forneça templates com:
- Resumo, impacto, detecção e causa raiz
- Fatores contribuintes (incluindo gaps de processo)
- O que funcionou / o que não funcionou
- Follow‑ups com donos e datas de vencimento
Vincule itens de ação ao incidente, rastreie conclusão e destaque itens vencidos em dashboards de time. Se suportar “learning reviews”, permita um modo sem culpa que foque em mudanças de sistema/processo em vez de erros individuais.
Relatórios e scorecards de confiabilidade
Comece com Go e Postgres
Gere um backend manutenível com schemas PostgreSQL alinhados a ferramentas, checks, SLOs e incidentes.
Relatórios é onde rastreamento vira tomada de decisão. Dashboards ajudam operadores; scorecards ajudam líderes a entender se ferramentas internas estão melhorando, onde investir e o que significa “bom”.
O que incluir num scorecard
Construa uma visão consistente por ferramenta (e opcionalmente por time) que responda rapidamente:
- Conformidade com SLO ao longo do tempo: período atual (semana/mês/trimestre) e linha de tendência contra a meta.
- Ferramentas mais instáveis: rank por SLO perdido, minutos de downtime ou maior burn de error budget.
- MTTR: mediana e p90 de tempo para restaurar, para que um incidente longo não esconda padrões.
- Contagem de incidentes: total e por severidade (Sev1–Sev3), com comparação ao período anterior.
Quando possível, adicione contexto leve: “SLO perdido devido a 2 deploys” ou “Maior downtime por dependência X”, sem transformar o relatório em revisão completa de incidente.
Filtros que tornam o relatório útil para liderança
Líderes raramente querem “tudo”. Adicione filtros por time, criticidade da ferramenta (ex.: Tier 0–3) e janela de tempo. Garanta que a mesma ferramenta possa aparecer em múltiplos rollups (time da plataforma é dono, finanças depende).
Resumos e exports
Forneça resumos semanais e mensais compartilháveis fora do app:
- Export CSV com um clique para planilhas
- Export PDF limpo para reuniões de status
Mantenha narrativa consistente (“O que mudou desde o período anterior?” “Onde estamos acima do budget?”). Se precisar de um guia para stakeholders, linke um curto guia como /blog/sli-slo-basics.
Segurança, qualidade de dados e hardening operacional
Um tracker de confiabilidade rapidamente vira fonte da verdade. Trate-o como sistema de produção: seguro por padrão, resistente a dados ruins e fácil de recuperar quando algo dá errado.
Proteja a superfície do app
Bloqueie todos os endpoints — mesmo os “internal‑only”.
- Valide inputs na borda (tipos, ranges, enums permitidos, tamanho máximo de payload) e rejeite campos desconhecidos.
- Adicione rate limiting por usuário/token de serviço para evitar clientes barulhentos saturarem ingestão ou dashboards.
- Use queries parametrizadas e padrões de ORM seguros para evitar injeção.
Segredos e controle de acesso
Mantenha credenciais fora do código e fora de logs.
Armazene segredos num secret manager e rotacione‑os. Dê ao app acesso de mínimo privilégio ao banco: papéis separados de leitura/gravação, restrinja acesso às tabelas necessárias e use credenciais de curta duração quando possível. Criptografe trânsito (TLS) entre browser↔app e app↔database.
Guardrails de qualidade de dados
Métricas de confiabilidade valem pouco sem eventos confiáveis.
Adicione checagens server‑side para timestamps (timezone/clock skew), campos obrigatórios e keys de idempotência para desduplicar retries. Rastreie erros de ingestão numa dead‑letter queue ou tabela de “quarentena” para que eventos ruins não envenenem dashboards.
Básicos operacionais (não pule)
Automatize migrações de banco e testes de rollback. Agende backups, restaure‑os regularmente em testes e documente um plano mínimo de recuperação de desastre (quem, o quê, quanto tempo). Finalmente, torne o app de confiabilidade ele mesmo confiável: adicione health checks, monitoramento básico de lag de filas e latência do DB, e alerta quando ingestão cai silenciosamente a zero.
Plano de rollout e roadmap de iteração
Um app de rastreamento de confiabilidade vence quando as pessoas confiam e o usam. Trate o primeiro release como um loop de aprendizado, não como um lançamento “big bang”.
Escolha 2–3 ferramentas internas amplamente usadas e com donos claros. Implemente um conjunto pequeno de checks (por exemplo: disponibilidade da homepage, sucesso de login e um endpoint de API chave) e publique um dashboard que responda: “Está no ar? Se não, o que mudou e quem é o dono?”
Mantenha o piloto visível mas contido: um time ou um pequeno grupo de power users é suficiente para validar o fluxo.
Colete feedback onde dói
Nas primeiras 1–2 semanas, recolha ativamente feedback sobre:
- O que é confuso (nomes de métricas, gráficos, filtros, definições)
- O que é ruidoso (alertas que não refletem impacto usuário)
- O que falta (propriedade, runbooks, links para incidentes)
Transforme feedback em backlog concreto. Um simples botão “Reportar um problema com esta métrica” em cada gráfico frequentemente revela as melhores percepções.
Adicione valor em camadas: conecte ao seu chat para notificações, depois à ferramenta de incidentes para criação automática de tickets, depois ao CI/CD para marcadores de deploy. Cada integração deve reduzir trabalho manual ou encurtar tempo de diagnóstico — caso contrário é só complexidade.
Se estiver prototipando rápido, considere usar o modo de planejamento do Koder.ai para mapear escopo inicial (entidades, papéis e fluxos) antes de gerar a primeira build. É uma forma simples de manter o MVP enxuto — e como você pode snapshotar e reverter, itera dashboards e ingestão com segurança enquanto times refinam definições.
Defina métricas de sucesso e expanda
Antes de expandir para mais times, defina métricas de sucesso como usuários ativos semanais do dashboard, redução do time‑to‑detect, menos alertas duplicados ou reviews de SLO consistentes. Publique um roadmap leve em /blog/reliability-tracking-roadmap e expanda ferramenta a ferramenta com donos claros e sessões de treinamento.