Defina o escopo e métricas de sucesso
Antes de desenhar um fluxo de moderação, decida exatamente o que você está moderando e o que significa “bom”. Um escopo claro evita que sua fila de moderação encha de casos de borda, duplicatas e solicitações fora do propósito.
O que conta como “conteúdo”
Anote todo tipo de conteúdo que pode gerar risco ou dano ao usuário. Exemplos comuns: texto gerado por usuários (comentários, posts, avaliações), imagens, vídeo, transmissões ao vivo, campos de perfil (nomes, biografias, avatares), mensagens diretas, grupos da comunidade e anúncios de marketplace (títulos, descrições, fotos, preços).
Também registre fontes: submissões de usuários, importações automáticas, edições em itens existentes e denúncias de outros usuários. Isso evita criar um sistema que funcione apenas para “posts novos” e ignore edições, reuploads ou abuso em DMs.
Seus objetivos (e trade-offs)
A maioria das equipes equilibra quatro objetivos:
- Velocidade: tempo curto até decisão para que conteúdo nocivo seja tratado rapidamente
- Consistência: casos similares recebem desfechos semelhantes entre revisores
- Conformidade de política e segurança: decisões alinhadas às regras e obrigações legais
- Controle de custos: tempo do revisor é finito; automação e priorização importam
Seja explícito sobre qual objetivo é primário em cada área. Por exemplo, abuso de alta gravidade pode priorizar velocidade em detrimento de consistência perfeita.
Ações que você precisa suportar
Liste o conjunto completo de desfechos que seu produto exige: aprovar, rejeitar/remover, editar/redigir, rotular/age-gate, restringir visibilidade, colocar sob revisão, escalar para um líder e ações a nível de conta como avisos, bloqueios temporários ou banimentos.
Métricas de sucesso para acompanhar
Defina metas mensuráveis: tempo mediano e percentil 95 de revisão, tamanho do backlog, taxa de reversão em apelações, precisão de política a partir de amostragem de QA e porcentagem de itens de alta gravidade tratados dentro de um SLA.
Stakeholders a envolver cedo
Inclua moderadores, líderes de equipe, política, suporte, engenharia e jurídico. Falta de alinhamento nessa etapa causa retrabalho depois—especialmente em torno do que “escalonamento” significa e quem detém a decisão final.
Modele o fluxo de moderação de ponta a ponta
Antes de construir telas e filas, esboce o ciclo de vida completo de um único conteúdo. Um workflow claro evita “estados misteriosos” que confundem revisores, quebram notificações e tornam auditorias penosas.
Mapeie o ciclo de vida como estados explícitos
Comece com um modelo de estados simples e de ponta a ponta que você possa colocar em um diagrama e no banco de dados:
Submitted → Queued → In review → Decided → Notified → Archived
Mantenha os estados mutuamente exclusivos e defina quais transições são permitidas (e por quem). Por exemplo: “Queued” só pode passar para “In review” quando atribuído, e “Decided” deve ser imutável exceto por um fluxo de apelação.
Separe sinais automatizados de decisões humanas
Classificadores automatizados, correspondências por palavra-chave, limites de taxa e denúncias de usuários devem ser tratados como sinais, não decisões. Um design com humano no loop mantém o sistema honesto:
- Sinais influenciam prioridade e ações recomendadas.
- A decisão do revisor é o resultado autoritativo.
Essa separação também facilita melhorar modelos mais tarde sem reescrever a lógica de política.
Planeje apelações e re-revisões
Decisões serão contestadas. Adicione fluxos de primeira classe para:
- Submissão de apelação do usuário (linkada ao caso original)
- Re-revisão por um revisor diferente ou uma equipe especializada
- Possíveis resultados: manter, reverter, modificar ou pedir mais informações
Modele apelações como novos eventos de revisão em vez de editar o histórico. Assim você conta a história completa do que aconteceu.
Decida o que deve ser rastreável
Para auditorias e disputas, defina quais passos devem ser registrados com timestamps e atores:
- Alterações de atribuição
- Evidência visualizada (quando apropriado)
- Decisão, motivo de política e ação de execução
- Notificações enviadas
Se você não conseguir explicar uma decisão depois, assuma que ela não aconteceu.
Desenhe papéis, permissões e estrutura de equipe
Uma ferramenta de moderação vive ou morre pelo controle de acesso. Se todo mundo pode fazer tudo, você terá decisões inconsistentes, exposição acidental de dados e falta de responsabilização. Comece definindo papéis que correspondam à forma como sua equipe de confiança e segurança realmente trabalha, e então traduza-os para permissões que seu app possa aplicar.
Papéis principais a suportar
A maioria das equipes precisa de um pequeno conjunto claro de papéis:
- Moderador: revisa itens numa fila de moderação, aplica desfechos (aprovar/remover/rotular) e deixa notas internas.
- Revisor sênior: tudo que um moderador faz, mais sobrescritas, tratamento de escalonamentos e coaching (por exemplo, resolver disputas).
- Editor de política: atualiza textos de política, definições de regras e guias de decisão, mas não pode moderar itens diretamente.
- Admin: gerencia usuários, papéis, configurações de time, integrações e ações de alto risco.
- Somente leitura: pode ver dashboards, casos e entradas do log de auditoria, mas não pode alterar nada.
Essa separação ajuda a evitar “mudanças de política por acidente” e mantém a governança de política distinta da aplicação diária.
Permissões de menor privilégio (RBAC)
Implemente controle de acesso baseado em papéis para que cada papel receba apenas o que precisa:
- Limite quem pode ver dados sensíveis do usuário (PII, denúncias, sinais de dispositivo).
- Restrinja ações de alto impacto como decisões em lote, penalidades em nível de conta e deleção de casos.
- Separe permissões por capacidade (por exemplo,
can_apply_outcome, can_override, can_export_data) em vez de por página.
Se você adicionar novas funcionalidades (exports, automações, integrações de terceiros), poderá anexá-las a permissões sem redefinir toda a estrutura organizacional.
Estrutura multi-time (idioma, região, produto)
Planeje para múltiplas equipes cedo: pods por idioma, grupos por região ou linhas separadas para produtos diferentes. Modele equipes explicitamente e escopo filas, visibilidade de conteúdo e atribuições por time. Isso evita erros de revisão entre regiões e mantém cargas de trabalho mensuráveis por grupo.
Salvaguardas de impersonação e aprovações
Admins às vezes precisam se passar por usuários para depurar acessos ou reproduzir um problema de revisor. Trate a impersonação como uma ação sensível:
- Requeira uma permissão específica para impersonar.
- Registre quem impersonou quem, quando e por quê.
- Exiba um banner persistente de “impersonando” e desabilite ações arriscadas por padrão.
Para ações irreversíveis ou de alto risco, adicione aprovação administrativa (ou revisão por duas pessoas). Essa pequena fricção protege contra erros e abuso interno, mantendo a moderação rotineira rápida.
Construa filas, priorização e atribuição
Filas são onde o trabalho de moderação se torna gerenciável. Em vez de uma única lista sem fim, divida o trabalho em filas que reflitam risco, urgência e intenção—e faça com que seja difícil para itens caírem pelas frestas.
Defina os tipos de fila
Comece com um conjunto pequeno de filas que combinem com a operação da sua equipe:
- Novos itens: conteúdo novo aguardando primeira revisão.
- Alto risco: itens que provavelmente causam dano (ex.: menores, sinais de autoagressão, padrões conhecidos de golpe).
- Escalonamentos: qualquer coisa que um revisor não consiga decidir com confiança, ou que precise de um especialista.
- Apelações: pedidos dos usuários para reconsiderar ações.
- Backlog: itens mais antigos, menor urgência ou excesso durante picos.
Mantenha filas mutuamente exclusivas quando possível (um item deve ter uma “casa”) e use tags para atributos secundários.
Escolha regras de priorização que não sejam manipuláveis
Dentro de cada fila, defina regras de pontuação que determinam o que sobe ao topo:
- Severidade (categoria de política + confiança)
- Viralidade/alcance (visualizações, compartilhamentos, número de seguidores)
- Denúncias de usuários (contagem, reputação do denunciante, denunciantes únicos)
- Timers de SLA (idade, prazos de escalonamento, tempo desde a primeira denúncia)
Faça a priorização explicável na UI (“Por que estou vendo isto?”) para que revisores confiem na ordenação.
Use claiming/locking: quando um revisor abre um item, ele é atribuído a ele e escondido dos demais. Adicione um timeout (ex.: 10–20 minutos) para que itens abandonados retornem à fila. Sempre registre eventos de claim, release e conclusão.
Trate de justiça: evite viés por “casos fáceis”
Se o sistema recompensa velocidade, revisores podem escolher casos rápidos e pular os difíceis. Combata isso com:
- Auto-atribuição de parte do trabalho
- Mistura de níveis de dificuldade (batching inteligente)
- Rotação de filas de alto impacto entre a equipe
O objetivo é cobertura consistente, não apenas alto rendimento.
Uma política que existe apenas em PDF será interpretada de forma diferente por cada revisor. Para tornar decisões consistentes (e auditáveis), traduza o texto da política em dados estruturados e escolhas de UI que seu fluxo pode impor.
Crie uma taxonomia de política
Comece quebrando a política em um vocabulário compartilhado que os revisores possam selecionar. Uma taxonomia útil inclui:
- Categoria (ex.: Assédio, Conteúdo adulto, Misinformação)
- Tipo de violação (ex.: discurso de ódio vs insulto geral)
- Nível de severidade (ex.: Baixo/Médio/Alto/Crítico)
- Evidência requerida (o que deve estar presente para aplicar a política—frases específicas, contexto, denúncias, links, timestamps)
Essa taxonomia vira a base para filas, escalonamento e análises posteriormente.
Use templates de decisão para reduzir inconsistência
Em vez de pedir que revisores escrevam uma decisão do zero, forneça templates de decisão amarrados a itens da taxonomia. Um template pode preencher:
- A ação recomendada (remover, rotular, restringir, advertir, sem ação)
- A mensagem ao usuário (editável, mas guiada)
- A checklist interna (o que deve ser confirmado)
Templates aceleram o “caminho feliz” e ainda permitem exceções.
Suporte versionamento de política e datas de vigência
Políticas mudam. Armazene políticas como registros versionados com datas de vigência e registre qual versão foi aplicada em cada decisão. Isso evita confusão quando casos antigos são apelados e garante que você possa explicar desfechos meses depois.
Capture razões estruturadas (não só texto livre)
Texto livre é difícil de analisar e fácil de se perder. Exija que revisores escolham uma ou mais razões estruturadas (da taxonomia) e, opcionalmente, adicionem notas. Razões estruturadas melhoram o tratamento de apelações, amostragem de QA e relatórios—sem forçar longos textos dos revisores.
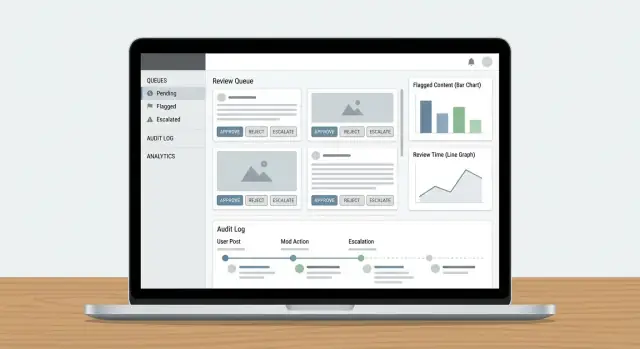
Desenhe o painel do revisor e a UX
Conecte decisões a resultados
Modele eventos de decisão para que notificações e ações de aplicação permaneçam consistentes.
Um painel de revisor funciona quando minimiza a “caça” por informações e maximiza decisões confiantes e repetíveis. Revisores devem entender o que aconteceu, por que importa e o que fazer a seguir—sem abrir cinco abas.
Mostre o conteúdo com o contexto certo
Não exiba um post isolado e espere decisões consistentes. Apresente um painel de contexto compacto que responda perguntas comuns de relance:
- Visão da conversa/thread: algumas mensagens antes e depois do item sinalizado, com destaque claro do conteúdo reportado.
- Histórico do usuário: avisos recentes, suspensões, remoções anteriores e resultados de apelações (com limite de tempo para manter relevância).
- Ações anteriores: quem mexeu no item antes, qual decisão foi tomada e quaisquer notas.
Mantenha a visão padrão concisa, com opções de expandir para mergulhos mais profundos. Revisores raramente devem precisar sair do painel para decidir.
Ações rápidas que mapeiam decisões reais
Sua barra de ações deve corresponder aos resultados da política, não a botões CRUD genéricos. Padrões comuns:
- Aprovar / Rejeitar com um clique
- Rotular (ex.: spam, assédio, autoagressão, desinformação) para suportar relatórios e treinamento
- Editar ou redigir (quando a política permite remoção parcial)
- Escalar para especialistas ou revisão de segundo nível
- Pedir mais informações (para casos ambíguos) com prompts template
Deixe ações visíveis e torne passos irreversíveis explícitos (confirmação apenas quando necessário). Capture um código de razão curto mais notas opcionais para auditorias futuras.
Recursos de velocidade: atalhos de teclado e ações em lote
Trabalho em alto volume demanda baixo atrito. Adicione atalhos de teclado para as ações principais (aprovar, rejeitar, próximo item, adicionar rótulo). Exiba um atalho dentro da UI.
Para filas de trabalho repetitivo (ex.: spam óbvio), suporte seleção em lote com salvaguardas: mostre uma contagem de pré-visualização, exija um código de razão e registre a ação em lote.
Projetar para segurança do revisor
A moderação pode expor pessoas a material nocivo. Adote padrões de segurança:
- Desfoque mídia sensível por padrão com clique-para-revelar
- Banners de aviso para provável autoagressão, conteúdo sexual ou violência gráfica
- Um rápido ocultar conteúdo que preserva a habilidade de decidir sem exposição prolongada
Essas escolhas protegem revisores e mantêm decisões precisas e consistentes.
Adicione logs de auditoria e rastreabilidade
Logs de auditoria são sua “fonte da verdade” quando alguém pergunta: Por que esse post foi removido? Quem aprovou a apelação? O modelo ou um humano tomou a decisão final? Sem rastreabilidade, investigações viram suposições, e a confiança dos revisores cai rápido.
Capture cada decisão (e a evidência)
Para cada ação de moderação, registre quem fez, o que mudou, quando aconteceu e por que (código de política + notas). Igualmente importante: armazene snapshots antes/depois dos objetos relevantes—texto do conteúdo, hashes de mídia, sinais detectados, rótulos e o desfecho final. Se o item pode mudar (edições, deleções), snapshots evitam que “o registro” se desvie.
Um padrão prático é um registro de eventos append-only:
{
"event": "DECISION_APPLIED",
"actor_id": "u_4821",
"subject_id": "post_99102",
"queue": "hate_speech",
"decision": "remove",
"policy_code": "HS.2",
"reason": "slur used as insult",
"before": {"status": "pending"},
"after": {"status": "removed"},
"created_at": "2025-12-26T10:14:22Z"
}
Registre eventos de fila para clareza operacional
Além das decisões, registre a mecânica do fluxo: claimed, released, timed out, reassigned, escalated e auto-routed. Esses eventos explicam “por que demorou 6 horas” ou “por que esse item pulou entre times” e são essenciais para detectar abuso (ex.: revisores selecionando apenas casos fáceis).
Torne trilhas de auditoria pesquisáveis para investigações
Dê aos investigadores filtros por usuário, ID de conteúdo, código de política, intervalo de tempo, fila e tipo de ação. Inclua exportação para um arquivo de caso, com timestamps imutáveis e referências a itens relacionados (duplicatas, re-uploads, apelações).
Defina regras de retenção que atendam compliance
Estabeleça janelas de retenção claras para eventos de auditoria, snapshots e notas de revisores. Documente a política (ex.: 90 dias para logs rotineiros, mais longo para retenções legais) e como solicitações de redação ou exclusão afetam evidências armazenadas.
Conecte denúncias, notificações e ações do usuário
Uma ferramenta de moderação só é útil se fechar o ciclo: denúncias viram tarefas de revisão, decisões chegam às pessoas certas e ações em nível de usuário são executadas consistentemente. É aqui que muitos sistemas quebram—alguém resolve a fila, mas nada mais muda.
Intake: unifique todo tipo de denúncia
Trate denúncias de usuários, flags automatizadas (spam/CSAM/hash matches/sinais de toxicidade) e escalonamentos internos (suporte, community managers, jurídico) como o mesmo objeto central: um relatório que pode gerar uma ou mais tarefas de revisão.
Use um roteador de relatórios único que:
- Deduplica (mesmo conteúdo denunciado várias vezes)
- Vincula itens relacionados (mesmo autor, mesma thread)
- Aplica triagem básica (severidade, categoria, jurisdição)
- Cria/atualiza itens na fila de moderação
Se escalonamentos de suporte fazem parte do fluxo, vincule-os diretamente (ex.: /support/tickets/1234) para que revisores não precisem trocar de contexto.
Desfechos: notifique usuários sem criar novos riscos
Decisões de moderação devem gerar notificações templateadas: conteúdo removido, advertência emitida, sem ação ou ação de conta aplicada. Mantenha mensagens consistentes e mínimas—explique o desfecho, referencie a política relevante e forneça instruções de apelação.
Operacionalmente, emita notificações via um evento como moderation.decision.finalized, para que e-mail/in-app/push possam subscrever sem atrasar o revisor.
Ações do usuário: conecte a controles de conta
Decisões frequentemente requerem ações além de um único conteúdo:
- Suspensões (temporárias/permanentes)
- Restrições (limites de postagem, limites de DM, shadow bans onde permitido)
- Atualizações de scores de confiança / níveis de risco
Torne essas ações explícitas e reversíveis, com durações e motivos claros. Vincule cada ação à decisão e ao relatório subjacente para rastreabilidade e forneça um caminho rápido para Apelações para que decisões possam ser revistas sem investigação manual extensa.
Escolha modelos de dados e estratégia de armazenamento
Torne as políticas aplicáveis
Transforme códigos de política em motivos estruturados e modelos de decisão para revisões consistentes.
Seu modelo de dados é a “fonte da verdade” sobre o que aconteceu a cada item: o que foi revisado, por quem, sob qual política e qual foi o resultado. Se você acertar essa camada, todo o resto—filas, dashboards, auditorias e análises—fica mais simples.
Separe conteúdo, decisões e códigos de política
Evite armazenar tudo em um único registro. Um padrão prático é manter:
- Referências de conteúdo (o que está sendo revisado): um ID estável, tipo de conteúdo (post/comentário/imagem/vídeo), ID do autor, hora de criação e um ponteiro para a localização do conteúdo bruto.
- Decisões de moderação (o que os revisores fizeram): ID da decisão, ID do revisor, resultado, timestamps, notas livres e campos estruturados (ex.: confiança, severidade).
- Códigos de política (por que foi decidido): identificadores canônicos como
HARASSMENT.H1 ou NUDITY.N3, armazenados como referências para que políticas possam evoluir sem reescrever o histórico.
Isso mantém a aplicação de política consistente e facilita relatórios (ex.: “principais códigos de violação esta semana”).
Não coloque grandes imagens/vídeos diretamente no banco de dados. Use object storage e guarde apenas chaves de objeto + metadados na tabela de conteúdo.
Para revisores, gere URLs assinadas de curta duração para que a mídia seja acessível sem tornar pública. URLs assinadas permitem controlar expiração e revogar acesso quando necessário.
Indexe para velocidade onde importa
Filas e investigações dependem de consultas rápidas. Adicione índices para:
- Filtros de fila (status, prioridade, revisor atribuído, tempo de criação)
- Busca textual (motivo reportado, texto do conteúdo quando permitido)
- Consultas do log de auditoria (ator, tipo de ação, intervalo de tempo, ID do conteúdo)
Acompanhe transições de estado para evitar itens “presos”
Modele a moderação como estados explícitos (ex.: NEW → TRIAGED → IN_REVIEW → DECIDED → APPEALED). Armazene eventos de transição de estado (com timestamps e ator) para detectar itens que não avançaram.
Uma salvaguarda simples: um campo last_state_change_at mais alertas para itens que excedem um SLA, e um job de reparo que reencaminha itens que ficaram IN_REVIEW além do timeout.
Segurança, privacidade e resistência a abuso
Ferramentas de Trust & Safety frequentemente lidam com os dados mais sensíveis do seu produto: conteúdo gerado por usuários, denúncias, identificadores de conta e por vezes solicitações legais. Trate o app de moderação como um sistema de alto risco e projete segurança e privacidade desde o começo.
Acesso seguro para revisores e admins
Comece com autenticação forte e controles de sessão apertados. Para a maioria das equipes, isso significa:
- SSO (SAML/OIDC) para que o acesso siga políticas de identidade da empresa
- MFA para papéis privilegiados (admins, editores de política, exports)
- Timeouts curtos de sessão e reautenticação para ações arriscadas (ações em lote, exports, mudanças de papel)
- Allowlists de IP para ferramentas internas, quando fizer sentido (ex.: workstations de contratados ou ranges de escritório)
Combine isso com RBAC para que revisores vejam só o que precisam (por exemplo: uma fila, uma região ou um tipo de conteúdo).
Proteja conteúdo sensível e dados de usuários
Criptografe dados em trânsito (HTTPS em toda parte) e em repouso (criptografia gerenciada). Foque em minimizar exposição:
- Mostre prévias redigidas por padrão (desfoque mídia, mascarar telefone/email) com uma ação de reveal que é logada
- Separe permissões de visualização das permissões de exportação
- Limite acesso a campos de alto risco (endereços exatos, dados de pagamento) a um conjunto pequeno de papéis
Se você lida com consentimento ou categorias especiais de dados, torne essas flags visíveis aos revisores e as imponha na UI (ex.: visualização restrita ou regras de retenção).
Resistência a abuso em denúncias e apelações
Endpoints de denúncia e apelação são alvos frequentes de spam e assédio. Adote:
- Rate limits por usuário/IP/dispositivo
- Proteções contra bots (desafio em picos, detecção de anomalias)
- Controles de custo (caps por dia, fricção crescente para abuso repetido)
Por fim, torne cada ação sensível rastreável com um log de auditoria (veja /blog/audit-logs) para investigar erros de revisores, contas comprometidas ou abuso coordenado.
Análises, QA e melhoria contínua
Gere um painel de moderação
Crie filas, visualizações para revisores e ações principais a partir de uma especificação de chat no Koder.ai.
Um fluxo de moderação só melhora se você puder medi-lo. Análises devem dizer se seu design de fila, regras de escalonamento e aplicação de política estão produzindo decisões consistentes—sem esgotar revisores ou deixar conteúdo nocivo esperando.
Métricas que mapeiam para operações reais
Comece com um pequeno conjunto de métricas vinculadas a outcomes:
- Throughput: itens revisados por hora/dia, divididos por fila, tipo de conteúdo e time.
- Tempos de resposta: time-to-first-review e time-to-resolution (por fila e por banda de prioridade).
- Sinais de acurácia (proxies): taxa de reversão em apelação, correções administrativas e taxa de “violação confirmada” após escalonamento.
Coloque isso em um dashboard de SLA para que líderes de ops vejam quais filas estão atrasando e se o gargalo é equipe, regras pouco claras ou um pico de denúncias.
Discordância e amostragem: seu sistema de alerta precoce
Discordâncias nem sempre são ruins—podem indicar casos de borda. Acompanhe:
- Taxas de discordância entre revisores no mesmo item (ex.: amostras double-reviewed).
- Resultados de amostragem de auditoria: taxas de aprovação/reprovação de QA e motivos mais comuns.
Use o log de auditoria para conectar cada decisão amostrada ao revisor, regra aplicada e evidência. Isso dá capacidade de explicação ao treinar revisores e avaliar se a UI de revisão está induzindo inconsistências.
Encontrando lacunas de política e necessidades de treinamento
Análises de moderação devem responder: “O que estamos vendo que nossa política não cobre bem?” Procure padrões como:
- Alta discordância numa categoria de política específica
- Uso frequente de motivos “outro/incerto”
- Escalonamentos que saltam entre equipes
Transforme esses sinais em ações concretas: reescrever exemplos de política, adicionar árvores de decisão ao painel do revisor ou atualizar presets de aplicação (ex.: timeouts padrão vs advertências).
Feche o ciclo sem quebrar confiança
Trate análises como parte de um sistema humano-no-loop. Compartilhe desempenho por fila publicamente dentro do time, mas trate métricas individuais com cuidado para não incentivar velocidade em detrimento da qualidade. Combine KPIs quantitativos com sessões regulares de calibração e pequenas atualizações de política frequentes—para que a ferramenta e as pessoas melhorem juntas.
Testes, rollout e operações contínuas
Uma ferramenta de moderação falha mais frequentemente nas bordas: posts estranhos, caminhos raros de escalonamento e momentos em que várias pessoas tocam o mesmo caso. Trate testes e rollout como parte do produto, não um checklist final.
Construa um pequeno “pacote de cenários” que reflita trabalho real. Inclua:
- Casos de borda (mídia mista, contas deletadas, conteúdo editado, ambiguidade de idioma)
- Apelações e reversões (uma decisão é contestada, re-revistada e anulada)
- Escalonamentos (handoffs para especialistas, jurídico ou política) e SLAs baseados em tempo
- Concorrência (dois revisores abrindo o mesmo item, condições de corrida em ações, denúncias duplicadas)
Use volumes próximos ao de produção em um ambiente de staging para detectar lentidões de fila e problemas de paginação/busca cedo.
Faça rollout em estágios para proteger throughput
Um padrão de rollout mais seguro:
- Time piloto: uma fila, ações limitadas, loop diário de feedback
- Modo shadow: rode o novo sistema ao lado do antigo (grave decisões sem executar enforcement visível ao usuário)
- Migração completa: troque para execução, mantenha caminhos de rollback e monitore métricas chave por hora na primeira semana
O modo shadow é especialmente útil para validar regras de aplicação e automação sem arriscar falsos positivos.
Documente playbooks e treine para consistência
Escreva playbooks curtos e orientados a tarefas: “Como processar uma denúncia”, “Quando escalar”, “Como lidar com apelações” e “O que fazer quando o sistema está incerto”. Treine com o mesmo pacote de cenários para que revisores pratiquem os fluxos que usarão.
Operações contínuas: políticas mudam, filas crescem
Planeje manutenção como trabalho contínuo: novos tipos de conteúdo, regras de escalonamento atualizadas, amostragem periódica para QA e planejamento de capacidade quando filas disparam. Mantenha um processo claro de release para atualizações de política para que revisores vejam o que mudou e quando—e para correlacionar mudanças com análises de moderação.
Se você está implementando isso como uma aplicação web, grande parte do esforço é infraestrutura repetitiva: RBAC, filas, transições de estado, logs de auditoria, dashboards e a cola baseada em eventos entre decisões e notificações. Koder.ai pode acelerar essa construção permitindo descrever o workflow de moderação em uma interface de chat e gerar uma base funcional que você pode iterar—normalmente com frontend em React e backend em Go + PostgreSQL.
Duas formas práticas de usar isso para tooling de Trust & Safety:
- Modo planejamento primeiro: descreva suas entidades (Content, Report, ReviewTask, Decision, PolicyCode, AuditEvent), transições do state machine e SLAs antes de gerar código.
- Snapshots e rollback: útil quando você está afinando regras de escalonamento, pontuação de filas ou guardrails de ações em lote e quer iteração rápida e segura.
Uma vez que a base esteja pronta, exporte o código-fonte, conecte seus sinais de modelo existentes como “inputs” e mantenha a decisão do revisor como autoridade final—casando com a arquitetura humano-no-loop descrita acima.