O que é uma página de status SaaS (e por que importa)
Uma página de status SaaS é um site público (ou apenas para clientes) que mostra se seu produto está funcionando agora — e o que você está fazendo se não estiver. Ela se torna a fonte única da verdade durante incidentes, separada das redes sociais, tickets de suporte e boatos.
Ajuda mais pessoas do que você imagina:
- Clientes podem confirmar rapidamente “Sou só eu?” e decidir se devem esperar, tentar novamente ou usar um contorno.
- Times de suporte podem linkar para uma atualização canônica em vez de repetir explicações em dezenas de tickets.
- Times de vendas e Customer Success podem gerenciar proativamente renovações e contas chave com informações precisas e com timestamp.
Status em tempo real vs. histórico de incidentes vs. postmortems
Um bom site de status geralmente contém três camadas relacionadas (mas diferentes):
- Status em tempo real: o que está funcionando, fora ou degradado agora nos seus componentes (API, dashboard, cobrança, etc.).
- Página de histórico de incidentes: uma linha do tempo de incidentes e manutenções passadas, para que clientes entendam padrões e vejam que problemas foram tratados.
- Revisões pós-incidente (postmortems): relatos mais profundos explicando causa raiz, correções e passos de prevenção. Podem ser públicos ou compartilhados privadamente com clientes afetados.
O objetivo é clareza: o status em tempo real responde “Posso usar o produto?” enquanto o histórico responde “Com que frequência isso acontece?” e os postmortems respondem “Por que isso aconteceu e o que mudou?”.
Definindo expectativas: transparência, velocidade e clareza
Uma página de status funciona quando as atualizações são rápidas, em linguagem simples e honestas sobre o impacto. Você não precisa de um diagnóstico perfeito para comunicar. Você precisa de timestamps, escopo (quem é afetado) e horário da próxima atualização.
Momentos comuns para usá-la
Você a usará durante interrupções, desempenho degradado (logins lentos, webhooks atrasados) e manutenção planejada que possa causar breve interrupção ou risco.
Quando você trata a página de status como uma superfície de produto (não uma página operacional pontual), o restante da configuração fica muito mais fácil: você pode definir responsáveis, criar templates e conectar monitoramento sem reinventar o processo a cada incidente.
Antes de escolher uma ferramenta ou desenhar um layout, decida para que sua página de status deve servir. Uma meta clara e um responsável claro mantêm as páginas de status úteis durante um incidente — quando todos estão ocupados e a informação é confusa.
A maioria dos times SaaS cria uma página de status para três resultados práticos:
- Reduzir tickets de suporte respondendo “Está fora do ar?” em um lugar público
- Construir confiança compartilhando atualizações oportunas em linguagem simples
- Acelerar a comunicação entre Suporte, Engenharia, Vendas e Customer Success
Anote 2–3 sinais mensuráveis que você pode acompanhar após o lançamento: menos tickets duplicados durante outages, tempo até a primeira atualização mais rápido, ou mais clientes usando assinaturas.
Identifique a audiência e o nível de leitura
Seu leitor primário costuma ser um cliente não técnico que quer saber:
- O produto está funcionando agora?
- O que está impactado (login, API, cobrança, etc.)?
- O que devo fazer em seguida?
- Quando isso será consertado?
Isso significa minimizar jargões. Prefira “Alguns clientes não conseguem entrar” em vez de “Taxas elevadas de 5xx na autenticação.” Se precisar de detalhe técnico, mantenha-o como uma frase secundária curta.
Escolha o tom, regras e responsabilidade
Adote um tom que você consiga manter sob pressão: calmo, factual e transparente. Decida antecipadamente:
- Quem pode postar atualizações (um papel único ou uma rotação on-call)
- Quem aprova atualizações (se alguém) e quanto tempo essa aprovação pode levar
- Frequência mínima de atualização durante um incidente ativo (por exemplo, a cada 30 minutos)
Deixe a responsabilidade explícita: a página de status não deve ser “trabalho de todo mundo”, senão vira de ninguém.
Decida onde ela fica
Você tem duas opções comuns:
- Site independente (por exemplo, status.yourcompany.com): separação mais clara e geralmente mais resistente a outages
- Subpath (por exemplo, /status): branding e analytics mais simples
Se seu app principal pode cair, um site independente costuma ser mais seguro. Você ainda pode linkar para ele de forma destacada no app e centro de ajuda (por exemplo, /help).
Mapeie seus serviços e modelo de status por componente
Uma página de status só é útil quanto o “mapa” por trás dela. Antes de escolher cores ou escrever textos, decida sobre o que você realmente vai reportar. O objetivo é refletir como os clientes vivenciam seu produto — não como seu organograma está organizado.
Liste as partes que um cliente poderia descrever quando diz “está quebrado”. Para muitos produtos SaaS, um conjunto prático inicial é:
- API
- Web app
- Dashboard / admin
- Autenticação (login, SSO)
- Cobrança
- Integrações (Slack, Salesforce, webhooks, etc.)
Se você oferece múltiplas regiões ou tiers, registre isso também (por exemplo, “API – US” e “API – EU”). Use nomes amigáveis ao cliente: “Login” é mais claro que “IdP Gateway”.
Decida como agrupar componentes
Escolha um agrupamento que corresponda à forma como os clientes pensam sobre seu serviço:
- Por produto: melhor se você tem ofertas distintas (Produto A vs Produto B)
- Por região: melhor se a disponibilidade variar significativamente por geografia
- Por funcionalidade/workflow: melhor se clientes dependem de trabalhos específicos (Relatórios, Importações, Notificações)
Tente evitar uma lista interminável. Se tiver dezenas de integrações, considere um componente pai (“Integrações”) mais algumas crianças de alto impacto (ex.: “Salesforce”, “Webhooks”).
Defina seus níveis de status (e o que significam)
Um modelo simples e consistente evita confusão durante incidentes. Níveis comuns incluem:
- Operational: funcionando como esperado
- Degraded Performance: mais lento que o normal ou com erros intermitentes
- Partial Outage: um subconjunto significativo de usuários/funcionalidades indisponível
- Major Outage: serviço amplamente indisponível
Escreva critérios internos para cada nível (mesmo que não publique). Por exemplo, “Partial Outage = uma região indisponível” ou “Degraded = p95 de latência acima de X por Y minutos.” Consistência constrói confiança.
Registre dependências — e escolha o que mostrar
A maioria dos outages envolve terceiros: hospedagem em cloud, entrega de email, processadores de pagamento ou provedores de identidade. Documente essas dependências para que suas atualizações de incidente sejam precisas.
Se exibi-las publicamente depende da sua audiência. Se clientes podem ser diretamente impactados (ex.: pagamentos), mostrar uma dependência pode ajudar. Se só gera ruído ou culpar terceiros, mantenha dependências internas, mas referencie-as nas atualizações quando relevantes (ex.: “Estamos investigando erros elevados no nosso provedor de pagamentos”).
Com esse modelo de componentes, o restante da configuração da sua página fica muito mais simples: todo incidente ganha um “onde” (componente) e “quão grave” (status) desde o início.
Projete uma página de status simples e voltada ao cliente
Uma página de status é mais útil quando responde às perguntas dos clientes em segundos. Pessoas normalmente chegam estressadas e querem clareza — não muita navegação.
Priorize o essencial no topo:
- Estado atual: Operacional, degradado ou fora do ar?
- Impacto: O que está afetado (quem/regiões/funcionalidades) e o que os usuários podem experienciar
- ETA (se houver): cuidado — compartilhe apenas estimativas que você consiga defender
- Próxima atualização: uma promessa específica como “Próxima atualização até 14:30 UTC” reduz tickets repetidos
Escreva em linguagem simples. “Taxas elevadas de erro em requisições da API” é mais claro que “Partial outage in upstream dependency.” Se precisar usar termos técnicos, acrescente uma tradução curta (“Algumas requisições podem falhar ou expirar”).
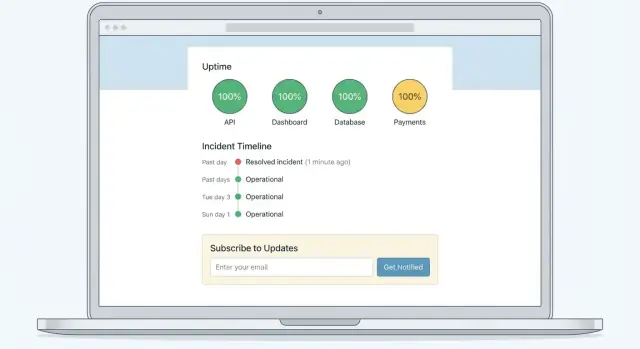
Use um layout simples e escaneável
Um padrão confiável é:
- Banner superior para o status geral (All Systems Operational / Degraded Performance / Major Outage)
- Lista de componentes com status claros (Web App, API, Billing, Integrations, etc.)
- Incidentes ativos e manutenções agendadas logo abaixo, ordenados por última atualização
Na lista de componentes, mantenha labels voltadas ao cliente. Se seu serviço interno for “k8s-cluster-2”, clientes provavelmente precisam ver “API” ou “Background Jobs”.
Acessibilidade e bases móveis
Deixe a página legível sob pressão:
- Forte contraste de cores e labels de texto (não dependa só da cor)
- Ícones claros com significado consistente (ex.: verde = operacional, amarelo = degradado, vermelho = outage)
- Espaçamento e elementos touch-friendly para mobile; muitos usuários checarão do telefone
Adicione links rápidos onde as pessoas esperam
Coloque um conjunto pequeno de links perto do topo (no cabeçalho ou logo abaixo do banner):
- Subscribe (para notificações por email/SMS/webhook)
- Incident History (para incidentes passados e timelines)
- Contact Support em /support
O objetivo é confiança: clientes devem entender imediatamente o que está acontecendo, o que é afetado e quando ouvirão de você novamente.
Crie templates de atualização para incidentes e manutenção
Quando um incidente acontecer, seu time está conciliando diagnóstico, mitigação e perguntas de clientes ao mesmo tempo. Templates removem incertezas para que as atualizações sejam consistentes, claras e rápidas — especialmente quando pessoas diferentes podem postar.
Defina os campos que você sempre publicará
Uma boa atualização começa com os mesmos fatos essenciais toda vez. No mínimo, padronize estes campos para que clientes entendam rapidamente o que está ocorrendo:
- Hora de início do incidente (com timezone)
- Componentes/serviços afetados (mapeados ao seu modelo de status)
- Impacto para o cliente (quem é afetado e como)
- Estado atual (Investigating, Identified, Monitoring, Resolved)
- Log de atualizações (entradas com timestamp)
- Hora de resolução (quando o serviço voltou ao normal)
Se publicar uma página de histórico, manter esses campos consistentes facilita escanear e comparar incidentes passados.
Use um template simples e repetível para atualizações
Mire em atualizações curtas que respondam às mesmas perguntas toda vez. Aqui está um template prático que você pode copiar para sua ferramenta de status:
Title: Resumo breve e específico (ex.: “Erros na API para a região EU”)
Start time: YYYY-MM-DD HH:MM (TZ)
Affected components: API, Dashboard, Payments
Impact: O que os usuários estão vendo (erros, timeouts, desempenho degradado) e quem é afetado
O que sabemos: Uma frase sobre a causa se confirmada (evite especulação)
O que estamos fazendo: Ações concretas (rollback, scale, escalonamento ao fornecedor)
Next update: Horário da próxima atualização
Updates:
- HH:MM (TZ) — Investigating: …
- HH:MM (TZ) — Identified: …
- HH:MM (TZ) — Monitoring: …
- HH:MM (TZ) — Resolved: …
Defina regras claras de cadência de atualização
Clientes não querem só informação — querem previsibilidade.
- Para incidentes grandes, comprometa-se com atualizações a cada 30–60 minutos, mesmo que a mensagem seja “Ainda investigando; sem ETA; próxima atualização em X.”
- Para problemas menores, publique com menos frequência, mas sempre informe a “próxima atualização”.
- Se não puder cumprir a cadência, publique uma nota rápida reconhecendo o atraso e redefinindo expectativas.
Adicione templates para anúncios de manutenção
Manutenção planejada deve parecer calma e estruturada. Padronize posts de manutenção com:
- Janela de manutenção: início/fim (com timezone)
- Impacto esperado: none / degraded / intermittent / downtime
- Componentes afetados
- Ações do cliente (se houver): “Nenhuma ação necessária” ou passos claros
- Atualização lembrete: um post curto quando a manutenção começar e outro quando terminar
Mantenha a linguagem específica (o que muda, o que os usuários poderão notar) e evite prometer demais — clientes valorizam precisão sobre otimismo.
Construa um histórico de incidentes fácil de escanear
Uma página de histórico de incidentes é mais que um log — é uma forma para clientes (e seu próprio time) entenderem com que frequência problemas ocorrem, que tipos de problemas se repetem e como vocês respondem.
Por que o histórico vale a pena
Um histórico claro constrói confiança por transparência. Também cria visibilidade de tendências: se você vê incidentes recorrentes de “latência na API” a cada poucas semanas, isso é um sinal para investir em performance (e priorizar post-incident reviews). Ao longo do tempo, relatórios consistentes podem reduzir tickets porque clientes encontram respostas sozinhos.
Decida retenção: até quando manter histórico?
Escolha uma janela de retenção que combine com as expectativas dos clientes e a maturidade do produto.
- 90 dias: comum para SaaS em estágio inicial, mantém a página leve
- 6–12 meses: melhor para compradores enterprise avaliando confiabilidade
- Mais tempo: considere exportar registros antigos para uma página de arquivo separada se a timeline ficar poluída
Seja qual for a escolha, informe-a claramente (ex.: “O histórico de incidentes é mantido por 12 meses”).
Consistência facilita escaneamento. Use um formato previsível, por exemplo:
YYYY-MM-DD — Resumo curto (ex.: “2025-10-14 — Entrega de email atrasada”)
Para cada incidente, mostre pelo menos:
- componentes afetados
- hora de início/fim (com timezone)
- nível de impacto (minor/major)
- uma nota curta de resolução
Link para contexto mais profundo quando disponível
Se publicar postmortems, linke da página de incidente para o relato completo (por exemplo: “Leia o postmortem” apontando para /blog/postmortems/2025-10-14-email-delays). Isso mantém a timeline limpa e ainda oferece detalhe para quem quiser se aprofundar.
Adicione assinaturas e notificações
Uma página de status é útil quando clientes pensam em checá-la. Assinaturas invertem isso: clientes recebem atualizações automaticamente, sem atualizar a página ou abrir um ticket para confirmar.
Ofereça os canais que seus clientes já usam
A maioria dos times espera pelo menos algumas opções:
- Email (padrão para muitos clientes)
- SMS (melhor para alertas urgentes e de alto sinal)
- Slack ou Microsoft Teams (ideal para clientes empresariais e times de ops)
- RSS/Atom (ainda popular entre usuários técnicos e para tooling interno)
Se suportar múltiplos canais, mantenha o fluxo de configuração consistente para que clientes não sintam que se inscreveram quatro vezes de formas diferentes.
Torne opt-in e preferências cristalinas
Assinaturas devem ser sempre opt-in. Seja explícito sobre o que as pessoas receberão antes de confirmarem — especialmente para SMS.
Dê controle aos assinantes sobre:
- Escopo: todos os incidentes vs apenas componentes selecionados (ex.: “API” mas não “Marketing site”)
- Tipo: apenas incidentes, apenas manutenção, ou ambos
- Severidade (opcional): apenas “Major outage” vs “Todas as atualizações”
Essas preferências reduzem fadiga de alertas e mantêm suas notificações confiáveis. Se ainda não tiver assinaturas por componente, comece com “Todas as atualizações” e adicione filtros depois.
Não deixe notificações falharem no momento em que mais precisa delas
Durante um incidente, o volume de mensagens sobe e provedores terceiros podem limitar tráfego. Verifique:
- Entregabilidade: SPF/DKIM/DMARC para email; domínios de envio verificados; endereços “from” que os clientes reconheçam
- Limites de taxa e throttling: limites do provedor de email/SMS, limites de webhooks do Slack/Teams e comportamento de retry
- Fallbacks: se posts no Slack falharem, vocês ainda enviam email? Se SMS atrasar, há um banner claro na homepage do status?
Vale a pena rodar testes agendados (até trimestrais) para garantir que as assinaturas continuam funcionais.
Coloque “Subscribe to updates” onde ninguém deixe de ver
Adicione um callout claro na homepage do status — acima da dobra, se possível — para que clientes possam se inscrever antes do próximo incidente. Torne visível no mobile e inclua em locais onde clientes buscam ajuda (como um link do portal de suporte ou /help).
Escolha um método de construção: ferramenta hospedada vs DIY
Escolher como construir sua página é menos sobre “podemos construir?” e mais sobre o que você quer otimizar: velocidade de lançamento, confiabilidade durante incidentes e esforço de manutenção.
Opção 1: usar uma ferramenta hospedada
Uma ferramenta hospedada é geralmente o caminho mais rápido. Você tem uma página pronta, assinaturas, timelines de incidentes e frequentemente integrações com sistemas de monitoramento.
O que buscar em uma ferramenta hospedada:
- Confiabilidade e independência: a página deve ficar acessível mesmo se seu app principal cair
- API e automação: criar incidentes, atualizar componentes e postar progresso via API ou webhooks
- Controle de acesso: papéis para quem pode publicar vs rascunhos; SSO é um bônus
- Branding e domínio customizado: logo/cores e domínio como status.yourcompany.com
- Analytics: número de assinantes, visualizações de atualização e métricas de entrega de email
- Necessidades de compliance: logs de auditoria e retenção se você opera em ambientes regulados
Opção 2: construir você mesmo (DIY)
DIY pode ser ótimo se você quer controle total sobre design, retenção de dados e como o histórico é apresentado. A troca é que você assume confiabilidade e operação.
Uma arquitetura prática de DIY é:
- Site estático (rápido, amigável a cache) para UI de status e páginas de histórico
- Fonte de dados via API (ou um CMS leve) que armazene incidentes, componentes e atualizações
- Caching agressivo + CDN para que a página permaneça rápida sob picos de tráfego
Se autohospedar, planeje modos de falha: o que acontece se seu banco de dados principal ficar indisponível ou seu pipeline de deploy cair? Muitos times mantêm a página de status em infraestrutura separada (ou até outro provedor) do produto principal.
Se quiser o controle do DIY sem reconstruir tudo, uma plataforma de vibe-coding como Koder.ai pode ajudar a levantar um site de status customizado (UI web + uma API de incidentes) rapidamente a partir de uma especificação por chat. Isso é útil para times que querem modelos de componente sob medida, UX de histórico customizado ou fluxos administrativos internos — e ainda poder exportar código, deployar e iterar rápido.
Planejamento de custos
Ferramentas hospedadas têm preço mensal previsível; DIY tem custo em tempo de engenharia, hospedagem/CDN e manutenção contínua. Ao comparar opções, esboce o gasto mensal esperado e o tempo interno necessário — então confronte com seu orçamento (veja /pricing).
Conecte monitoramento e fluxo de incidentes
Uma página de status só é útil se refletir a realidade rapidamente. A forma mais fácil de fazer isso é conectar os sistemas que detectam problemas (monitoramento) com os que coordenam a resposta (fluxo de incidentes), para que as atualizações sejam consistentes e oportunas.
De onde devem vir as atualizações de status
A maioria dos times combina três fontes de dados:
- Alertas de monitoramento (health checks, testes sintéticos, taxas de erro, latência, profundidade de fila). São ótimos para detecção, mas nem sempre descrevem o impacto ao cliente.
- Atualizações manuais do on-call ou do time de suporte. Humanos adicionam contexto: quem é afetado, qual workaround, o que mudou.
- Ferramentas de gestão de incidentes (PagerDuty, Opsgenie, Jira Service Management, etc.). Fornecem timeline, papéis e notas de resolução que sua página pode resumir.
Uma regra prática: o monitoramento detecta; o fluxo de incidentes coordena; a página de status comunica.
Automação que ajuda (sem prometer demais)
Automação pode economizar minutos quando importa:
- Crie um incidente a partir de um alerta quando um monitor de alta severidade disparar (ex.: "taxa de erro da API > 5% por 5 minutos"). Pré-preencha título, componentes afetados e severidade inicial.
- Atualize componentes a partir de health checks para sinais objetivos (ex.: “Web app: Degraded Performance” quando limiares de latência são ultrapassados).
- Sincronize mudanças de status ao canal de incidentes (Slack/Teams) para que quem responde veja o que os clientes estão vendo.
Mantenha a primeira mensagem pública conservadora. “Investigando erros elevados” é mais seguro que “Outage confirmado” ao validar dados.
Não automatize tudo sem revisão humana
Mensagens totalmente automáticas podem sair pela culatra:
- Um alerta ruidoso pode publicar incidentes falsos.
- Uma falha parcial pode parecer “down” para um monitor, mas estar ok para clientes.
- Atualizações auto-resolvidas podem fechar um incidente enquanto usuários ainda são impactados.
Use automação para rascunhar e sugerir atualizações, mas exija revisão humana para a linguagem voltada ao cliente — especialmente para estados Identified, Mitigated e Resolved.
Mantenha trilha de auditoria
Trate a página de status como um registro público. Garanta que você possa responder:
- Quem alterou o status do incidente?
- O que foi alterado (texto, componentes, timestamps)?
- Quando foi alterado?
Esse histórico ajuda no post-incident review, reduz confusão em handoffs e constrói confiança quando clientes pedem esclarecimentos.
Torne-a confiável: hospedagem, DNS e proteção contra outages
Uma página de status só ajuda se for alcançável quando seu produto não estiver. O modo de falha mais comum é hospedar a página de status na mesma infraestrutura do app — então quando o app cai, a página some também, deixando clientes sem fonte de verdade.
Isole-a do seu stack principal
Quando possível, hospede a página de status em um provedor diferente do app (ou pelo menos em uma conta/região diferente). O objetivo é reduzir raio de impacto: um outage na plataforma do app não deve derrubar também suas comunicações.
Considere também separar o DNS. Se o DNS do seu domínio principal for gerenciado no mesmo lugar que a borda/CDN do app, um problema de DNS ou certificado pode bloquear ambos. Muitos times usam um subdomínio dedicado (ex.: status.yourcompany.com) com DNS hospedado independentemente.
Faça a página rápida e resiliente
Mantenha ativos leves: JavaScript mínimo, CSS comprimido e sem dependências que exijam as APIs do app para renderizar. Coloque um CDN na frente da página e habilite cache para recursos estáticos para que carregue mesmo sob tráfego alto durante um incidente.
Uma rede de segurança prática é um modo estático de fallback:
- pré-renderize o último status conhecido e banner de incidente
- sirva isso a partir de object storage ou hospedagem estática
- atualize dinamicamente quando sistemas estiverem saudáveis, mas degrade graciosamente quando não estiverem
Clientes não deveriam precisar logar para ver a saúde do serviço. Mantenha a página pública, mas coloque ferramentas de admin/editor atrás de autenticação (SSO se possível), com controles de acesso fortes e logs de auditoria.
Por fim, teste cenários de falha: bloqueie temporariamente a origem do app em um ambiente de staging e confirme que a página de status ainda resolve, carrega rápido e pode ser atualizada quando mais precisar.
Processo operacional: quem atualiza e quando
Uma página de status só constrói confiança se for atualizada consistentemente em incidentes reais. Essa consistência não acontece por acaso — você precisa de propriedade clara, regras simples e cadência previsível.
Defina papéis (antes de tudo quebrar)
Mantenha o time central pequeno e explícito:
- Incident Commander (IC): conduz a resposta, decide prioridades e confirma quando está estável
- Communications Lead: publica atualizações na página de status e mantém a linguagem voltada ao cliente
- Engenheiros on call: investigam, mitigam e alimentam fatos confirmados ao IC
Se você for um time pequeno, uma pessoa pode acumular dois papéis — só decida isso com antecedência. Documente handoffs e caminhos de escalonamento no seu manual on-call (veja /docs/on-call).
Checklist simples de atualização para seguir sempre
Quando um alerta vira um incidente com impacto ao cliente, siga um fluxo repetível:
- Reconhecer: publicar uma atualização “Investigating” rapidamente (mesmo com detalhes limitados)
- Avaliar impacto: confirmar componentes, regiões ou segmentos de clientes afetados
- Postar atualização: dizer o que os usuários podem notar, workarounds (se houver) e quando atualizarão novamente
- Resolver: confirmar que o serviço foi restaurado e o que está sendo monitorado
- Recapitular: adicionar um resumo curto e linkar a revisão completa quando disponível
Regra prática: publique a primeira atualização dentro de 10–15 minutos, depois a cada 30–60 minutos enquanto houver impacto — mesmo que seja “Sem mudança, ainda investigando.”
Após a resolução: revisar e melhorar
Dentro de 1–3 dias úteis, faça um post-incident review leve:
- Timeline: eventos-chave da detecção à recuperação
- Causa raiz (melhor explicação conhecida): explique em linguagem simples
- Ações: correções específicas, responsáveis e prazos
Depois, atualize a entrada do incidente com o resumo final para que o histórico não fique só como um log de “resolvido”.
Checklist de lançamento e melhorias contínuas
Uma página de status só é útil se for fácil de encontrar, confiável e atualizada consistentemente. Antes de anunciá-la, faça uma checagem “pronta para produção” — e depois configure uma cadência leve para melhorar com o tempo.
Checklist de lançamento (a versão prática)
Texto e estrutura
- Confirme que os nomes dos componentes batem com o que clientes reconhecem (ex.: “Dashboard” vs nomes internos).
- Adicione uma breve introdução “O que esta página mostra” e um link claro para suporte (ex.: /support) para questões específicas de conta.
- Garanta que atualizações de incidentes expliquem impacto ao cliente (“pagamentos falhando”) e forneçam próximos passos (“tente novamente após 10 minutos”).
Branding e confiança
- Adicione logo, favicon e um sistema de cores simples para status (evite tons excessivamente sutis).
- Inclua formato de timestamp claro e fuso horário.
Acesso e permissões
- Verifique quem pode publicar incidentes, agendar manutenção e editar configurações da página.
- Configure um “backup on-call” para que atualizações não fiquem bloqueadas por uma única pessoa.
Teste do fluxo completo
- Rode um incidente de teste (marque como resolvido e rotule claramente como teste).
- Inscreva-se por email/SMS e confirme que as notificações chegam com links corretos.
Anuncie
- Adicione o link da página de status no rodapé do app, centro de ajuda e respostas automáticas de suporte.
- Envie um anúncio curto aos clientes explicando o que esperar e como assinar.
Se estiver construindo seu próprio site de status, considere rodar esse mesmo checklist em staging primeiro. Ferramentas como Koder.ai podem acelerar esse loop de iteração gerando UI web, telas admin e endpoints backend a partir de uma única especificação — então permitir que você exporte o código e deploye onde precisar.
Meça o que significa “melhorar”
Acompanhe alguns resultados simples e revise mensalmente:
- Tickets reduzidos: compare volume de tickets relacionados a incidentes antes/depois do lançamento
- Primeira atualização mais rápida: meça tempo entre detecção e primeira atualização pública
- Crescimento de assinantes: acompanhe assinantes por canal e componentes seguidos
Mantenha uma taxonomia básica para que o histórico vire ação:
- Marque incidentes por categoria (performance, partial outage, terceiro, manutenção, segurança)
- Note componentes recorrentes e repetidores
- Use isso para priorizar correções e alimentar o processo de revisão pós-incidente
Noções básicas de SEO (para clientes encontrarem a página)
- Use títulos de página claros como “Service Status” e “Incident History.”
- Mantenha headings estruturados (H2/H3) para que páginas de histórico sejam fáceis de escanear.
- Prefira páginas de histórico indexáveis (a menos que haja motivo de segurança/privacidade) e garanta links entre a página principal de status e cada incidente sejam rastreáveis.
Com o tempo, pequenas melhorias — textos mais claros, atualizações mais rápidas, categorização melhor — se acumulam em menos interrupções, menos tickets e mais confiança dos clientes.