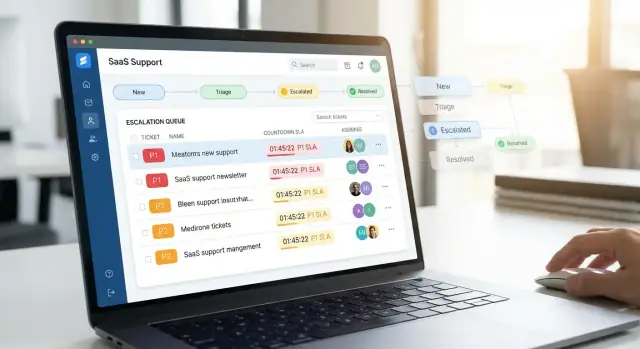
Esclareça o fluxo de escalamento e os objetivos
Antes de criar telas ou escrever código, decida para que seu app serve e qual comportamento ele deve impor. Escalamentos não são apenas “clientes irritados” — são tickets que exigem atendimento mais rápido, maior visibilidade e coordenação mais apertada.
O que conta como escalamento?
Defina critérios de escalamento em linguagem simples para que agentes e clientes não precisem adivinhar. Gatilhos comuns incluem:
- Uma queda ou degradação severa
- Um cliente VIP ou contratado como “suporte prioritário”
- Uma violação de SLA iminente (ou violações repetidas)
- Uma questão com impacto em segurança, faturamento ou jurídico
Também defina o que não é um escalamento (por exemplo, perguntas de uso, solicitações de funcionalidades, bugs menores) e como esses pedidos devem ser roteados em vez disso.
Papéis e responsabilidades
Liste os papéis que seu fluxo precisa e o que cada papel pode fazer:
- Agente: faz triagem e resolve, atualiza o ticket, segue playbooks
- Lead: revisa escalamentos, reatribui trabalho, aprova mudanças de prioridade
- Gerente: é responsável por relatórios, padrões de comunicação com clientes e política de escalamento
- On-call: recebe alertas urgentes e assume imediatamente fora do horário
- Administrador do cliente: submete e acompanha tickets, adiciona stakeholders internos
Anote quem é o dono do ticket em cada etapa (incluindo handoffs) e o que “ser dono” significa (requisito de resposta, próximo horário de atualização e autoridade para escalar).
Canais para suportar primeiro
Comece com um conjunto pequeno de entradas para poder lançar mais rápido e manter a triagem consistente. Muitas equipes começam com email + formulário web, depois adicionam chat quando SLAs e roteamento estiverem estáveis.
Escolha resultados mensuráveis que o app deve melhorar:
- Tempo até primeira resposta (geral e para escalamentos)
- Tempo de resolução ou tempo até mitigação de incidentes
- Taxa de reabertura e contagem de “pingados por atualização”
- Taxa de SLA perdidos e tempo gasto sem dono
Essas decisões viram requisitos de produto para o restante da construção.
Projete o modelo de dados para tickets, SLAs e escalamentos
Um app de suporte prioritário vive ou morre pelo seu modelo de dados. Se acertar as bases, roteamento, relatórios e aplicação de SLAs ficam mais simples — porque o sistema terá os fatos necessários.
No mínimo, cada ticket deve capturar: solicitante (um contato), empresa (conta do cliente), assunto, descrição e anexos. Trate a descrição como a declaração original do problema; atualizações posteriores pertencem a comentários para que você possa ver como a história evoluiu.
Adicione campos específicos de escalamento (o que torna isso “prioritário”)
Escalamentos precisam de mais estrutura que o suporte geral. Campos comuns incluem severidade (o quão grave), impacto (quantos usuários/qual receita) e prioridade (com que rapidez você responderá). Adicione um campo serviço afetado (ex.: Faturamento, API, App Mobile) para que a triagem possa rotear rapidamente.
Para prazos, armazene tempos de vencimento explícitos (como “primeira resposta devida” e “resolução/próxima atualização devida”), não apenas um “nome de SLA”. O sistema pode computar esses timestamps, mas os agentes devem ver os horários exatos.
Modele relacionamentos para trabalho real
Um modelo prático geralmente inclui:
- Clientes → muitos Contatos
- Clientes → muitos Tickets
- Tickets → muitos Comentários (internos + públicos)
- Tickets → muitas Tarefas (itens de checklist, follow-ups)
Isso mantém a colaboração limpa: conversas nos comentários, itens de ação nas tarefas e propriedade no ticket.
Defina estados de status (e mantenha-os consistentes)
Use um conjunto pequeno e estável de status como: Novo, Triado, Em Progresso, Aguardando, Resolvido, Fechado. Evite status “quase iguais” — todo estado extra torna relatórios e automações menos confiáveis.
Decida o que deve ser imutável para auditorias
Para rastreamento de SLA e responsabilidade, alguns dados devem ser apenas-acréscimo: timestamps de criação/atualização, histórico de mudanças de status, eventos de início/parada de SLA, mudanças de escalamento e quem fez cada alteração. Prefira um log de auditoria (ou tabela de eventos) para que você possa reconstruir o que aconteceu sem adivinhações.
Defina níveis de prioridade e regras de SLA
Prioridade e regras de SLA são o “contrato” que seu app aplica: o que é tratado primeiro, quão rápido e quem é responsável. Mantenha o esquema simples, documente com clareza e torne difícil sobrescrever sem motivo.
Um esquema simples de prioridade (P1–P4)
Use quatro níveis para que agentes classifiquem rapidamente e gestores possam reportar de forma consistente:
- P1 — Crítico / outage severo: Produto indisponível, perda de dados ou suspeita de incidente de segurança. Vários usuários ou toda a conta bloqueada.
- P2 — Degradação importante: Funções centrais parcialmente quebradas, workarounds limitados e alto impacto no negócio, mas não total.
- P3 — Problema padrão: Usuário único ou funcionalidade não crítica afetada. Há workaround. Muitos tickets cairão aqui.
- P4 — Baixa urgência / solicitações: Perguntas de uso, bugs menores, pedidos de recurso, dúvidas de faturamento que não bloqueiam o uso.
Defina “impacto” (quantos usuários/clientes) e “urgência” (quão sensível ao tempo) na UI para reduzir rotulagem incorreta.
Defina SLAs por plano, tier do cliente e prioridade
Seu modelo de dados deve permitir que SLAs variem por plano/tier do cliente (ex.: Free/Pro/Enterprise) e prioridade. Tipicamente, você rastreia pelo menos dois timers:
- SLA de primeira resposta (tempo para reconhecer e começar a assumir)
- SLA de resolução ou SLA de próxima atualização (tempo para resolver ou fornecer uma atualização significativa)
Exemplo: Enterprise + P1 pode exigir primeira resposta em 15 minutos, enquanto Pro + P3 pode ser 8 horas úteis. Mantenha a tabela de regras visível para agentes e linke-a na página do ticket.
Horário comercial, 24/7 e calendários de feriados
SLAs de suporte frequentemente dependem se o plano inclui cobertura 24/7.
- Para SLAs em horário comercial, armazene uma agenda de trabalho (timezone, dias da semana, horário início/fim).
- Para SLAs 24/7, o relógio sempre corre.
- Adicione um calendário de feriados (por região se necessário) para que timers não “violem” em dias em que ninguém deve trabalhar.
Faça o ticket mostrar tanto “SLA restante” quanto a agenda que está sendo usada (para que agentes confiem no timer).
Pausas de SLA, “aguardando cliente” e tratamento de breaches
Fluxos reais precisam de pausas. Uma regra comum: pausar SLA quando o ticket está Aguardando cliente (ou Aguardando terceiro), e retomar quando o cliente responde.
Seja explícito sobre:
- Quais status pausam quais timers de SLA
- Se as pausas se aplicam ao SLA de resposta, ao de resolução ou a ambos
- O que acontece quando ocorre uma violação (ex.: auto-escalar prioridade, pager no on-call, notificar um gerente, marcar ticket “SLA Violado")
Evite breaches silenciosos. O tratamento de breaches deve criar um evento visível no histórico do ticket.
Quem é alertado antes e depois de um breach
Defina pelo menos dois thresholds de alerta:
- Aviso pré-breach (ex.: 50% e 80% do SLA consumido): notificar o dono do ticket e o canal da equipe responsável.
- Alerta de breach: notificar on-call (para P1/P2), lead da equipe e, opcionalmente, customer success para contas de alto nível.
Roteie alertas com base em prioridade e tier para que pessoas não sejam paginadas por ruído de P4. Se quiser mais detalhes, conecte esta seção às suas regras de on-call em /blog/notifications-and-on-call-alerting.
Construa lógica de triagem, roteamento e propriedade
Triagem e roteamento são onde um app de suporte prioritário ou economiza tempo — ou cria confusão. O objetivo é simples: cada novo pedido deve cair no lugar certo rapidamente, com um dono claro e um próximo passo óbvio.
Crie uma inbox de triagem em que agentes confiem
Comece com uma inbox dedicada à triagem para tickets não atribuídos ou precisando de revisão. Mantenha-a rápida e previsível:
- Ordenação padrão por sinais de urgência (prioridade, tempo até SLA, tier do cliente)
- Filtros por área do produto, região/timezone, canal (email/chat/web) e contas “VIP”
- Uma visão “Sem dono / Sem categoria” que destaque gaps de qualidade de dados
Uma boa inbox minimiza cliques: agentes devem conseguir reivindicar, re-rotear ou escalar a partir da lista sem abrir todo ticket.
Defina regras de roteamento (e mantenha-as explicáveis)
O roteamento deve ser baseado em regras, mas legível por não-engenheiros. Entradas comuns:
- Área do produto (selecionada pelo usuário, detectada pelo formulário ou inferida por tags)
- Palavras-chave no assunto/corpo (ex.: “queda”, “fatura”, “SSO”)
- Tier do cliente (padrão vs. prioritário)
- Região (rotear para times alinhados por timezone)
Armazene o “porquê” de cada decisão de roteamento (ex.: “Correspondência por palavra-chave: SSO → time de Auth”). Isso facilita resolver disputas e melhora treinamento.
Override manual e caminhos de escalamento
Mesmo as melhores regras precisam de uma rota de escape. Permita que usuários autorizados sobrescrevam o roteamento e disparem caminhos de escalamento como:
Agente → Lead da equipe → On-call
Overrides devem exigir um motivo curto e criar uma entrada de auditoria. Se você tiver paging on-call depois, linke ações de escalamento a ele (veja /blog/notifications-and-on-call-alerting).
Desduplicar e vincular trabalhos relacionados
Tickets duplicados desperdiçam tempo de SLA. Adicione ferramentas leves:
- Sugerir possíveis duplicatas com base em cliente + assunto similar + janela de tempo
- Permitir que agentes vinculem tickets a um incidente pai (“relacionado a INC-123”)
Tickets vinculados devem herdar atualizações de status e mensagens públicas do pai.
Regras de propriedade: um nome, uma fila
Defina estados de propriedade claros:
- Responsável único (uma pessoa accountable)
- Fila de equipe (não atribuído dentro de uma equipe; usar quando handoffs são frequentes)
- Transferência (handoff explícito com notas e um novo checkpoint de SLA se necessário)
Torne a propriedade visível em todos os lugares: lista, cabeçalho do ticket e log de atividade. Quando alguém perguntar “Quem tem isso?”, o app deve responder instantaneamente.
Crie um painel de suporte que agentes possam usar rápido
Um app de suporte prioritário vence ou perde nos primeiros 10 segundos que um agente passa nele. O dashboard deve responder três perguntas imediatamente: o que precisa de atenção agora, por quê, e o que eu posso fazer a seguir.
Visões-chave que agentes realmente usam
Comece com um pequeno conjunto de visões de alta utilidade em vez de um labirinto de abas:
- Fila (worklist): visão padrão com filtros por prioridade, status de SLA, canal, área do produto e responsável.
- Detalhe do ticket: abrir em um clique, com contexto e ações acima da dobra.
- Perfil do cliente: visão compacta do tier da conta, escalamentos recentes, incidentes ativos e contatos principais.
- Quadro de SLA: visão baseada em tempo que destaca o que vai vencer em breve, não apenas o que já está atrasado.
Sinais visuais que reduzem carga cognitiva
Use sinais claros e consistentes para que agentes não tenham que “ler” cada linha:
- Chips de prioridade (P1–P4) com cor acessível + texto (nunca só cor).
- Contagem regressiva do SLA (ex.: “45m para primeira resposta”) e um indicador de “risco de breach”.
- Badges de bloqueio (Aguardando cliente, Aguardando engenharia, Precisa de aprovação) para que trabalhos travados fiquem visíveis.
Mantenha tipografia simples: uma cor de destaque principal e hierarquia fechada (título → cliente → status/SLA → última atualização).
Ações rápidas e velocidade de triagem
Cada linha de ticket deve suportar ações rápidas sem abrir a página completa:
- Atribuir / reatribuir, escalar, mudar prioridade, pedir info, marcar bloqueio, adicionar nota interna.
Adicione ações em massa (atribuir, fechar, aplicar tag, marcar bloqueio) para limpar backlogs rapidamente.
Teclado, acessibilidade e “sem surpresas”
Suporte atalhos de teclado para usuários avançados: / para buscar, j/k para navegar, e para escalar, a para atribuir, g então q para voltar à fila.
Para acessibilidade, garanta contraste suficiente, estados de foco visíveis, controles rotulados e texto de status compatível com leitores de tela (ex.: “SLA: 12 minutos restantes”). Também torne a tabela responsiva para que o mesmo fluxo funcione em telas menores sem esconder campos críticos.
Notificações e paging on-call
Itere sem medo
Use snapshots e rollback enquanto ajusta regras de roteamento e limites de notificação.
Notificações são o “sistema nervoso” de um app de suporte prioritário: transformam mudanças de ticket em ação oportuna. O objetivo não é notificar mais — é notificar as pessoas certas, no canal certo, com contexto suficiente para responder.
Mapeie os tipos de notificação
Comece com um conjunto claro de eventos que disparam mensagens. Tipos comuns e de alto sinal incluem:
- Atribuição: ticket atribuído ou reatribuído a um agente ou time
- Menção: alguém @menciona um agente em nota interna
- Aviso de SLA: ticket se aproximando de metas de primeira resposta ou resolução
- Breach de SLA: meta perdida (com razão se conhecida)
- Escalamento: aumento de prioridade, executivo/cliente adicionado, ou incidente declarado
Cada mensagem deve incluir ID do ticket, nome do cliente, prioridade, dono atual, timers de SLA e um deep link para o ticket.
Escolha canais sem perder controle
Use notificações in-app para trabalho do dia a dia, e email para updates duráveis e handoffs. Para cenários realmente on-call, adicione SMS/push como canal opcional reservado para eventos urgentes (como escalamento P1 ou breach iminente).
Prevenção de fadiga de alerta
Fadiga de alertas reduz tempo de resposta. Adicione controles como agrupamento, horas de silêncio e deduplicação:
- Agrupe avisos de SLA repetidos em um único thread
- Deduza “mudança de atribuição” em flurries dentro de uma janela curta
- Respeite horas de silêncio com override para incidentes críticos
Templates + histórico de entrega
Forneça templates para updates voltados ao cliente e notas internas para que tom e completude permaneçam consistentes. Rastreie estado de entrega (enviado, entregue, falhou) e mantenha uma timeline de notificações por ticket para auditoria e follow-ups. Uma aba “Notificações” na página de detalhe do ticket facilita essa revisão.
Página de detalhe do ticket: colaboração e comunicação
A página de detalhe é onde o trabalho de escalamento acontece de fato. Deve ajudar agentes a entender o contexto em segundos, coordenar com colegas e comunicar-se com o cliente sem erros.
Separe o que o cliente vê do que permanece interno
Faça o compositor escolher explicitamente Resposta ao cliente ou Nota interna, com estilo diferente e pré-visualização clara. Notas internas devem suportar formatação rápida, links para runbooks e tags privadas (ex.: “precisa de engenharia”). Respostas ao cliente devem vir com template amigável por padrão e mostrar exatamente o que será enviado.
Conversa em thread + anexos seguros
Suporte um thread cronológico que inclua emails, transcrições de chat e eventos do sistema. Para anexos, priorize segurança:
- Scan de vírus e allowlists de tipos de arquivo
- Limites de tamanho e links de download expirantes
- Avisos de redaction para dados sensíveis (tokens, senhas)
Se exibir arquivos enviados pelo cliente, deixe claro quem fez upload e quando.
Macros, respostas rápidas e passos salvos
Adicione macros que inserem respostas pré-aprovadas mais checklists de solução (ex.: “coletar logs”, “passos de restart”, “texto para status page”). Permita bibliotecas compartilhadas de macros com histórico de versões para que escalamentos permaneçam consistentes e em conformidade.
Linha do tempo de eventos chave
Ao lado das mensagens, mostre uma linha do tempo compacta de eventos: mudanças de status, atualizações de prioridade, pausas/resumos de SLA, transferências de responsável e shifts de nível de escalamento. Isso evita “o que mudou?” e ajuda na revisão pós-incidente.
Ferramentas de colaboração que não geram ruído
Habilite @menções, seguidores e tarefas vinculadas (ticket de engenharia, documento de incidente). Menções devem notificar apenas as pessoas certas, e seguidores devem receber resumos quando o ticket mudar materialmente — não a cada edição.
Segurança, privacidade e permissões
Colabore no fluxo de trabalho
Convide líderes e colegas de plantão para revisar juntos caminhos de escalonamento e permissões.
Segurança não é recurso “futuro” para um app de escalamento: escalamentos frequentemente contêm emails de clientes, screenshots, logs e notas internas. Construa guardrails cedo para que agentes possam mover-se rápido sem compartilhar demais dados ou perder confiança.
Controle de acesso baseado em funções (RBAC) que reflita o trabalho real de suporte
Comece com um conjunto pequeno de papéis que possa explicar em uma frase cada (por exemplo: Agente, Lead, Engenheiro On-Call, Admin). Depois defina o que cada papel pode ver, editar, comentar, reatribuir e exportar.
Uma abordagem prática é “negação por padrão” nas permissões:
- Visibilidade de escalamento: restrinja por time, fila e conta cliente (ex.: apenas agentes da fila Enterprise podem abrir escalamentos Enterprise)
- Direitos de edição: permita que agentes atualizem status e adicionem notas, mas limite mudanças de SLA, overrides de prioridade e cancelamentos de escalamento a leads/admins
- Campos sensíveis: trate PII do cliente (email, telefone), logs de segurança e anexos como permissões separadas
Privacidade by design: padrões de menor privilégio
Colete apenas o que o fluxo precisa. Se você não precisa de corpos completos de mensagem ou IPs completos, não os armazene. Quando armazenar dados do cliente, deixe claro quais campos são obrigatórios vs. opcionais e evite copiar dados de outros sistemas sem motivo.
Para padrões de acesso, assuma “agentes devem ver o mínimo necessário para resolver o ticket”. Use escopo por conta e por fila antes de adicionar regras complexas.
Proteja o básico: autenticação, sessões e CSRF
Use autenticação comprovada (SSO/OIDC se possível), exija senhas fortes quando usadas e suporte MFA para papéis elevados.
Endureça sessões:
- Cookies Secure e HttpOnly; tempos de sessão curtos para ações administrativas
- Rotação em login e mudanças de privilégio
- Proteção CSRF para requisições que mudam estado
Segredos, logs de auditoria e acesso sensível
Armazene segredos em um cofre gerenciado (não no source control). Logue acessos a dados sensíveis (quem visualizou um escalamento, baixou um anexo, exportou um ticket) e torne logs de auditoria resistentes a adulteração e pesquisáveis.
Retenção e exports (sem prometer demais)
Defina regras de retenção para tickets, anexos e logs de auditoria (ex.: deletar anexos após N dias, reter logs de auditoria por mais tempo). Forneça exports para clientes ou relatórios internos, mas evite afirmar certificações de conformidade específicas sem verificar. Um fluxo simples de “exportar dados” mais um workflow administrativo de “pedido de exclusão” é um bom começo.
Escolha de stack tecnológico e arquitetura
Seu app de escalamento só será efetivo se for fácil de mudar. Regras de escalamento, SLAs e integrações evoluem constantemente, então priorize uma stack que seu time consiga manter e contratar para.
Escolha uma stack que caiba no time
Prefira ferramentas familiares a “perfeitas”. Combinações comuns e testadas:
- React + Node.js (Express/NestJS): bom para dashboard altamente interativo e muito UI em tempo real.
- Django (Python): fortes ferramentas de admin, desenvolvimento CRUD rápido, ótimo para apps com workflows pesados.
- Rails (Ruby): convenções excelentes para construir produtos estilo ticketing rapidamente.
Se você já roda um monólito em outro lugar, combinar ecossistemas costuma reduzir tempo de onboarding e complexidade operacional.
Se quiser ir mais rápido sem grande investimento inicial, também é possível prototipar o fluxo em uma plataforma low-code como Koder.ai — especialmente para peças padrão como dashboard React, backend Go/PostgreSQL e lógica de SLA/notificações baseada em jobs.
Armazenamento de dados: relacional primeiro, busca onde ajuda
Para registros centrais — tickets, clientes, SLAs, eventos de escalamento, atribuições — use um banco relacional (Postgres é uma escolha comum). Ele dá transações, constraints e queries amigáveis para relatórios.
Para busca rápida em assuntos, textos de conversa e nomes, considere um índice de busca depois (ex.: Elasticsearch/OpenSearch). Mantenha opcional no começo: use full-text search do Postgres e só evolua se necessário.
Jobs em background são obrigatórios
Apps de escalamento dependem de trabalho baseado em tempo e integrações que não devem rodar em uma requisição web:
- Timers de SLA e checagens de breach
- Notificações (email/SMS/push)
- Paging on-call
- Sincronização de mensagens de email/chat/CRM
Use uma fila de jobs (ex.: Celery, Sidekiq, BullMQ) e torne jobs idempotentes para que retries não criem alertas duplicados.
Defina APIs cedo e mantenha consistência
Quer você escolha REST ou GraphQL, defina limites de recurso desde o início: tickets, comentários, eventos, clientes e usuários. Uma API consistente acelera integrações e o UI. Planeje também endpoints de webhook (assinatura, retries e limites de taxa) desde o começo.
Hospedagem e ambientes
Execute pelo menos dev/staging/prod. Staging deve espelhar configurações de prod (provedores de email, filas, webhooks) com credenciais de teste seguras. Documente deploy e rollback, e mantenha configuração em variáveis de ambiente — não no código.
Integrações: Email, Chat, CRM e Webhooks
Integrações transformam seu app de escalamento de “outro lugar para checar” no sistema onde sua equipe realmente trabalha. Comece com os canais que seus clientes já usam e adicione ganchos de automação para que outras ferramentas reajam a eventos de escalamento.
Email: parsing inbound, envio outbound, threading
Email é geralmente a integração de maior impacto. Suporte encaminhamento inbound (ex.: support@) e parseie:
- From/To/Cc, assunto, corpo (prefira fallback em plain-text) e anexos
- Message-ID e In-Reply-To para threading
- Domínio do cliente e pistas de assinatura para descoberta de contato
No envio outbound, responda a partir do ticket e preserve headers de threading para que respostas retornem ao mesmo ticket. Armazene uma timeline de conversa limpa: mostre o que o cliente viu, não notas internas.
Ferramentas de chat (opcional): converter mensagens em tickets
Para chat (Slack/Teams/widgets estilo intercom), mantenha simples: converta uma conversa em ticket com transcrição clara e participantes. Evite sincronizar cada mensagem por padrão — ofereça botão “Anexar últimas 20 mensagens” para que agentes controlem o ruído.
A sync com CRM é como você automatiza suporte prioritário. Puxe empresa, plano/tier, dono da conta e contatos-chave. Mapeie contas do CRM para seus tenants para que novos tickets herdem regras de prioridade imediatamente.
Webhooks para eventos-chave
Forneça webhooks para eventos como ticket.escalated, ticket.resolved e sla.breached. Inclua payload estável (ID do ticket, timestamps, severidade, ID do cliente) e assine requisições para que receptores verifiquem autenticidade.
Documente e simplifique a configuração
Adicione um pequeno fluxo administrativo com botões de teste (“Enviar email de teste”, “Verificar webhook”). Mantenha docs em um lugar (ex.: /docs/integrations) e mostre passos de troubleshooting comuns como problemas SPF/DKIM, headers de threading ausentes e mapeamento de campos do CRM.
Testes, monitoramento e confiabilidade
Compense seu tempo de desenvolvimento
Ganhe créditos criando conteúdo sobre construir apps com Koder.ai.
Um app de suporte prioritário se torna “fonte da verdade” em momentos tensos. Se timers de SLA divergem, roteamento falha ou permissões vazam dados, a confiança evapora. Trate confiabilidade como recurso: teste o que importa, meça o que acontece e planeje pelo fracasso.
Teste as regras que dirigem urgência
Foque testes automatizados na lógica que altera resultados:
- Cálculos de SLA: condições de início/parada, horário comercial, pausas, limiares de breach e timestamps de “próximo devido”.
- Roteamento e propriedade: regras de triagem, round-robin/atribuição por skill e gatilhos de escalamento.
- Permissões: RBAC para filas, detalhes de ticket, notas internas e mensagens visíveis ao cliente.
Adicione uma suíte pequena de testes end-to-end que imitem fluxo do agente (criar ticket → triar → escalar → resolver) para capturar suposições quebradas entre UI e backend.
Dados de seed e cenários realistas
Crie seed data útil além de demos: alguns clientes, múltiplos tiers (padrão vs. prioritário), prioridades variadas e tickets em estados diferentes. Inclua casos difíceis como tickets reabertos, “aguardando cliente” e múltiplos responsáveis. Isso torna prática de triagem significativa e ajuda QA a reproduzir edge cases rapidamente.
Observabilidade: saber antes de o cliente dizer
Instrume o app para responder: “O que falhou, para quem e por quê?”
- Tracking de erros para exceções em jobs de SLA/roteamento.
- Logs estruturados com IDs de ticket, IDs de regra e correlation IDs.
- Monitoramento de performance em páginas críticas e workers em background.
Teste de carga e recuperação segura
Rode testes de carga em visões de alto tráfego como filas, busca e dashboards — especialmente em trocas de turno.
Por fim, prepare seu próprio playbook de incidentes: feature flags para regras novas, passos de rollback de migrations e procedimento claro para desativar automações mantendo agentes produtivos.
Plano de lançamento, relatórios e iteração
Um app de suporte prioritário só está “pronto” quando agentes confiam nele sob pressão. A melhor forma é lançar pequeno, medir o que realmente acontece e iterar em ciclos curtos.
Resista à vontade de lançar todo recurso. Seu primeiro release deve cobrir o caminho mais curto de “novo escalamento” a “resolvido com responsabilidade”:
- Uma fila de triagem com ordenação clara (prioridade, SLA devida, tier do cliente)
- Página de detalhe do ticket que suporte atualizações rápidas e notas internas
- Timers de SLA visíveis (primeira resposta e resolução/próxima atualização, se aplicável)
- Alertas básicos para breaches iminentes e mudanças de status
Se usar Koder.ai, esse formato de MVP mapeia bem para defaults comuns (UI React, serviços Go, PostgreSQL) e a habilidade de snapshot/rollback pode ser útil enquanto você afina matemática de SLA, regras de roteamento e limites de permissão.
Rode um piloto com um grupo reduzido (uma região, uma linha de produto ou uma rotação on-call) e faça revisão semanal de feedback. Mantenha estruturado: o que atrasou agentes, que dados faltaram, que alertas foram ruidosos e onde a gestão de escalamento falhou (handoffs, propriedade confusa ou tickets mal roteados).
Uma tática prática: mantenha um changelog leve dentro do app para que agentes vejam melhorias e sintam-se ouvidos.
Adicione relatórios que gerem ação, não vaidade
Quando houver uso consistente, introduza relatórios que respondam perguntas operacionais:
- Conformidade de SLA: taxa de breaches por prioridade, tier e canal
- Volume de escalamentos: tendências ao longo do tempo e picos após releases
- Principais drivers: tags/motivos correlacionados com escalamentos
- Carga de agentes: tickets abertos por agente e tempo até primeiro toque
Esses relatórios devem ser fáceis de exportar e simples de explicar a stakeholders não técnicos.
Itere em regras e macros usando resultados reais
Regras de roteamento e triagem estarão erradas no começo — e isso é normal. Ajuste regras com base em misroutes, tempos de resolução e feedback do on-call. Faça o mesmo com macros e respostas prontas: remova as que não reduzem tempo e refine as que melhoram comunicação e clareza em incidentes.
Publique um roadmap simples e recursos de ajuda
Mantenha seu roadmap curto e visível dentro do produto (“Próximos 30 dias”). Linke para conteúdo de ajuda e FAQs para que treinamento não vire conhecimento tribal. Se mantiver info pública, deixe-a descoberta por links internos como /pricing ou /blog para que times possam se autoatender com atualizações e melhores práticas.