07 de ago. de 2025·8 min
Da GPT-1 à GPT-4: A história dos modelos GPT da OpenAI
Explore a história dos modelos GPT da OpenAI, de GPT-1 a GPT-4o, e veja como cada geração avançou em compreensão de linguagem, usabilidade e segurança.
Por que a história dos modelos GPT importa
Os modelos GPT são uma família de grandes modelos de linguagem criados para prever a próxima palavra em uma sequência de texto. Eles leem enormes quantidades de texto, aprendem padrões de uso da linguagem e então usam esses padrões para gerar novo texto, responder perguntas, escrever código, resumir documentos e muito mais.
A própria sigla explica a ideia central:
- Generative (Generativo) – eles criam novo texto, não apenas classificam texto existente.
- Pre-trained (Pré-treinados) – são treinados primeiro em dados amplos e depois adaptados a tarefas específicas.
- Transformer – usam a arquitetura transformer, muito eficiente em modelar dependências de longo alcance na linguagem.
Compreender como esses modelos evoluíram ajuda a entender o que eles podem e não podem fazer, e por que cada geração parece um salto de capacidade. Cada versão reflete escolhas técnicas e trade-offs sobre tamanho do modelo, dados de treino, objetivos e trabalho em segurança.
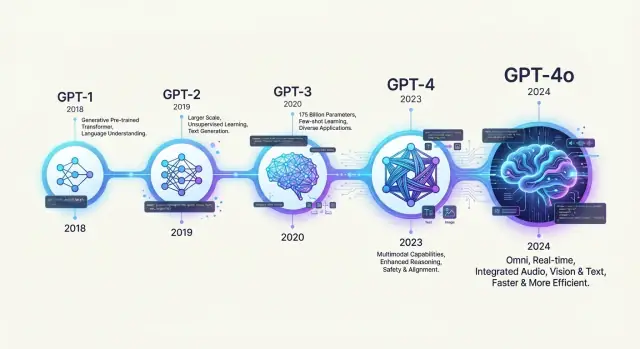
- GPT-1 introduziu a receita básica: pré-treinar em texto geral e depois fazer fine-tuning.\n- GPT-2 escalou essa receita e gerou os primeiros debates públicos sobre geradores de texto poderosos.\n- GPT-3 mostrou forte few-shot e in-context learning, disponibilizado principalmente via API.\n- GPT-3.5 transformou essa capacidade de pesquisa em algo que as pessoas usavam no dia a dia.\n- GPT-4 melhorou o raciocínio e adicionou capacidades multimodais (texto mais imagens).\n- GPT-4o e GPT-4o mini focaram em eficiência, custo e uso interativo em tempo real.
Este artigo segue uma visão cronológica e de alto nível: desde modelos de linguagem iniciais e GPT-1, passando por GPT-2 e GPT-3, até o tuning por instrução e o ChatGPT, e finalmente GPT-3.5, GPT-4 e a família GPT-4o. Ao longo do texto, veremos as principais tendências técnicas, como os padrões de uso mudaram e o que essas mudanças sugerem sobre o futuro dos grandes modelos de linguagem.
Fundamentos: dos primeiros modelos de linguagem ao GPT
Antes do GPT, modelos de linguagem já eram parte central da pesquisa em NLP. Sistemas iniciais foram os modelos n‑gram, que previam a próxima palavra a partir de uma janela fixa de palavras anteriores usando contagens simples. Eles alimentavam correção ortográfica e autocompletar básico, mas tinham dificuldades com contexto de longo alcance e escassez de dados.
O passo seguinte foram os modelos de linguagem neurais. Redes feed‑forward e, depois, redes neurais recorrentes (RNNs), especialmente LSTMs e GRUs, aprenderam representações distribuídas de palavras e podiam, em princípio, lidar com sequências mais longas. Na mesma época, modelos como word2vec e GloVe popularizaram embeddings de palavras, mostrando que aprendizado não supervisionado de texto cru podia capturar estrutura semântica rica.
No entanto, RNNs eram lentos para treinar, difíceis de paralelizar e ainda tinham problemas com contextos muito longos. O avanço veio com o artigo de 2017 "Attention Is All You Need", que introduziu a arquitetura transformer. Transformers substituíram recorrência por self‑attention, permitindo que o modelo conecte diretamente quaisquer duas posições em uma sequência e tornando o treino altamente paralelo.
Isso abriu a porta para escalar modelos de linguagem muito além do que os RNNs permitiam. Pesquisadores começaram a perceber que um único transformer grande treinado para prever o próximo token em corpora massivos poderia aprender sintaxe, semântica e até algumas habilidades de raciocínio sem supervisão específica por tarefa.
A ideia-chave da OpenAI foi formalizar isso como pré-treinamento generativo: primeiro treinar um grande transformer apenas de decoder em um corpus amplo em escala de internet para modelar texto, depois adaptar esse mesmo modelo a tarefas downstream com treino adicional mínimo. Essa abordagem prometia um modelo de propósito geral em vez de muitos modelos estreitos.
Essa mudança conceitual — de sistemas pequenos e específicos para tarefas a um grande transformador pré-treinado generativamente — preparou o terreno para o primeiro GPT e para toda a série de modelos GPT que se seguiram.
GPT-1: o primeiro transformer pré-treinado generativo
O GPT-1 marcou o primeiro passo da OpenAI rumo à série GPT que conhecemos hoje. Lançado em 2018, tinha 117 milhões de parâmetros e foi construído sobre a arquitetura Transformer apresentada por Vaswani et al. em 2017. Embora pequeno para padrões posteriores, cristalizou a receita central seguida por todos os GPTs posteriores.
A ideia de treinamento central
O GPT-1 foi treinado com uma ideia simples, porém poderosa:
- Pré-treinamento generativo em um grande corpus de texto de uso geral.\n2. Fine-tuning específico por tarefa em conjuntos de dados rotulados menores.
No pré-treinamento, o GPT-1 aprendeu a prever o próximo token em textos extraídos principalmente do BooksCorpus e de fontes no estilo Wikipedia. Esse objetivo — prever a próxima palavra — não exigia rótulos humanos, permitindo que o modelo absorvesse amplo conhecimento sobre linguagem, estilo e fatos.
Após o pré-treinamento, o mesmo modelo foi afinando (fine-tuned) com aprendizado supervisionado em benchmarks clássicos de NLP: análise de sentimento, perguntas e respostas, entailment textual e outros. Uma pequena cabeça classificadora era adicionada no topo, e o modelo inteiro (ou a maior parte dele) era treinado de ponta a ponta em cada conjunto rotulado.
O ponto metodológico chave foi que o mesmo modelo pré-treinado poderia ser levemente adaptado para muitas tarefas, em vez de treinar um modelo separado para cada tarefa do zero.
Insights de pesquisa a partir de um modelo de escala modesta
Apesar do tamanho relativamente pequeno, o GPT-1 trouxe vários insights influentes:
- Pré-treinamento como aprendizado geral de NLP: O artigo mostrou que um único modelo generativo, treinado em texto cru, podia igualar ou superar arquiteturas específicas de tarefa em múltiplos benchmarks após fine-tuning.\n- Transformers funcionam bem para linguagem: Modelos de estado-da-arte anteriores frequentemente usavam redes recorrentes ou convolucionais. O GPT-1 ajudou a validar decoders puros de Transformer como uma arquitetura forte para modelagem de linguagem.\n- Indícios de escala: Os resultados sugeriram que o desempenho continuaria melhorando à medida que o tamanho do modelo e dos dados crescessem, insinuando que modelos muito maiores poderiam desbloquear novas capacidades.\n- Arquitetura unificada, muitas tarefas: GPT-1 usou essencialmente uma arquitetura e um objetivo para muitos problemas downstream, antecipando a ideia de “modelo fundação”.
O GPT-1 já mostrou traços iniciais de generalização zero-shot e few-shot, embora isso ainda não fosse o tema central. A maior parte da avaliação ainda dependia de fine-tuning separado por tarefa.
Por que o GPT-1 permaneceu um protótipo de pesquisa
O GPT-1 nunca foi pensado para deployment ao consumidor ou uma API ampla. Vários fatores o mantiveram no âmbito de pesquisa:
- Limites de escala: 117M de parâmetros era pequeno o suficiente para que a qualidade de geração e a factualidade ficassem claramente limitadas.\n- Foco de avaliação estreito: O trabalho centrava-se em benchmarks de NLP, não em assistentes interativos ou casos de produção.\n- Segurança e confiabilidade não eram foco: Havia pouca discussão sobre uso indevido, alucinações ou alinhamento; essas preocupações cresceram com modelos posteriores.\n- Sem produto público: A OpenAI publicou artigo e código, mas não um serviço gerenciado ou interface.
Ainda assim, o GPT-1 estabeleceu o template: pré-treinamento generativo em grandes corpora de texto, seguido por fine-tuning simples específico por tarefa. Todo GPT posterior pode ser visto como um descendente escalado, refinado e cada vez mais capaz desse primeiro transformer pré-treinado generativo.
GPT-2: escalar e os primeiros debates públicos
O GPT-2, lançado em 2019, foi o primeiro modelo GPT a atrair atenção global de fato. Escalou a arquitetura do GPT-1 de 117 milhões para 1,5 bilhão de parâmetros, mostrando até onde a simples escala de um transformer de linguagem podia chegar.
Escala: 1,5B de parâmetros e o que mudou
Arquiteturalmente, o GPT-2 era muito semelhante ao GPT-1: um decoder-only transformer treinado com predição do próximo token em um grande corpus da web. A diferença chave foi a escala:
- Parâmetros: 117M → 1,5B\n- Dados: Texto da web muito maior e mais diverso
Esse salto em tamanho melhorou dramaticamente fluência, coerência em passagens mais longas e a capacidade de seguir prompts sem treino específico por tarefa.
Surpresas zero-shot e few-shot
O GPT-2 fez muitos pesquisadores repensarem o que “apenas” prever o próximo token podia fazer.
Sem qualquer fine-tuning, o GPT-2 podia realizar tarefas zero-shot como:
- Responder perguntas factuais a partir de um prompt\n- Traduzir frases curtas entre línguas\n- Gerar resumos a partir de um parágrafo de entrada
Com alguns exemplos no prompt (few-shot), o desempenho muitas vezes melhorava ainda mais. Isso sugeriu que grandes modelos de linguagem podiam representar internamente uma ampla gama de tarefas, usando exemplos em contexto como uma interface de programação implícita.
Lançamento por etapas e receios de uso indevido
A qualidade impressionante de geração desencadeou alguns dos primeiros grandes debates públicos em torno de grandes modelos de linguagem. A OpenAI inicialmente reteve o modelo completo de 1,5B, citando preocupações sobre:
- Notícia falsa e desinformação em larga escala\n- Spam e conteúdo de baixa qualidade inundando plataformas online\n- Personificação e agentes de chat enganadores
Ao invés disso, a OpenAI adotou um lançamento por etapas:
- Liberação pública do modelo menor de 117M\n2. Liberação gradual das variantes de 345M e 774M\n3. Modelo completo de 1,5B liberado mais tarde em 2019
Essa abordagem incremental foi um dos primeiros exemplos explícitos de política de deployment de IA centrada em avaliação de risco e monitoramento.
Experimentação da comunidade e mudança de percepção
Mesmo os checkpoints menores do GPT-2 levaram a uma onda de projetos open-source. Desenvolvedores afinaram modelos para escrita criativa, autocompletar de código e chatbots experimentais. Pesquisadores sondaram viés, erros factuais e modos de falha.
Essas experiências mudaram a forma como muitos viam os grandes modelos de linguagem: de artefatos de pesquisa de nicho a motores de texto de propósito geral. O impacto do GPT-2 definiu expectativas — e gerou preocupações — que moldariam a recepção do GPT-3, ChatGPT e modelos de classe GPT-4 na evolução contínua da família GPT da OpenAI.
GPT-3: aprendizado in-context e a era da API
O GPT-3 chegou em 2020 com o número de manchete de 175 bilhões de parâmetros, mais de 100× maior que o GPT-2. Esse número sugeriu poder de memorização, mas, mais importante, desbloqueou comportamentos que não haviam sido vistos em escala antes.
Aprendizado in-context e a ascensão do prompt engineering
A descoberta definidora com o GPT-3 foi o aprendizado in-context. Em vez de afinar o modelo para novas tarefas, você podia colar alguns exemplos no prompt:
- Mostre alguns pares de sentença Inglês–Francês e ele traduzia.\n- Forneça alguns pares de P\u0026R e ele respondia novas perguntas.\n- Demonstre um estilo de escrita e ele imitava esse estilo.
O modelo não atualizava seus pesos; estava usando o próprio prompt como uma espécie de conjunto de treinamento temporário. Isso levou a termos como zero-shot, one-shot e few-shot prompting, e provocou a primeira onda de prompt engineering: criar instruções, exemplos e formatação para extrair melhor comportamento sem mexer no modelo subjacente.
De resultado de pesquisa para API comercial
Ao contrário do GPT-2, cujos pesos eram distribuíveis, o GPT-3 foi disponibilizado principalmente via API comercial. A OpenAI lançou um beta privado da OpenAI API em 2020, posicionando o GPT-3 como um motor de texto de propósito geral que desenvolvedores podiam chamar via HTTP.
Isso deslocou os grandes modelos de linguagem de artefatos de pesquisa de nicho para uma plataforma ampla. Em vez de treinar seus próprios modelos, startups e empresas podiam prototipar ideias com uma única chave de API, pagando por token.
Casos de uso iniciais
Os primeiros adotantes exploraram rapidamente padrões que mais tarde se tornaram padrão:
- Ajuda com código: gerar trechos de código, regexes ou sugestões de refatoração.\n- Auxílio à escrita: rascunho de e-mails, posts de blog, textos de marketing e resumos.\n- Prototipagem de produtos: construir chatbots, busca semântica e ferramentas no-code/low-code.
O GPT-3 provou que um único modelo geral — acessível via API — podia alimentar uma ampla gama de aplicações, preparando o terreno para o ChatGPT e para os sistemas GPT-3.5 e GPT-4 posteriores.
Tuning por instrução, alinhamento e a ascensão do ChatGPT
Do prompt ao full stack
Descreva sua ideia e gere um web app em React com backend em Go e PostgreSQL.
Por que o tuning por instrução era necessário
O GPT-3 base foi treinado apenas para prever o próximo token em texto em escala de internet. Esse objetivo o deixou bom em continuar padrões, mas nem sempre em fazer o que as pessoas pediam. Usuários frequentemente precisavam elaborar prompts com cuidado, e o modelo podia:
- Ignorar instruções ou mudar de tópico\n- Gerar conteúdo inseguro, tendencioso ou factualmente incorreto sem avisos\n- Afirmar nonsense com excesso de confiança
Pesquisadores chamaram essa lacuna entre o que os usuários querem e o que o modelo faz de problema de alinhamento: o comportamento do modelo não estava confiavelmente alinhado com intenções humanas, valores ou expectativas de segurança.
InstructGPT: aprender a seguir direções
O InstructGPT (2021–2022) da OpenAI foi um ponto de inflexão. Em vez de treinar apenas em texto cru, adicionaram duas etapas chave sobre o GPT-3:
- Supervised fine-tuning (SFT): Avaliadores humanos escreveram respostas ideais a muitos prompts (ex.: “Explique computação quântica em termos simples”). O modelo foi afinado para imitar esses exemplos.\n2. Reinforcement learning from human feedback (RLHF): Avaliadores ranquearam múltiplas saídas do modelo para o mesmo prompt. Um “modelo de recompensa” aprendeu essas preferências, e o modelo base foi otimizado (via gradientes de política) para produzir respostas com ranking mais alto.
Isso produziu modelos que:
- Seguiam instruções de forma mais confiável\n- Recusavam pedidos mais perigosos\n- Eram geralmente mais úteis e polidos por padrão
Em estudos com usuários, modelos menores InstructGPT foram preferidos a modelos base GPT-3 muito maiores, mostrando que alinhamento e qualidade de interface podem importar mais que escala bruta.
Do InstructGPT ao ChatGPT
O ChatGPT (final de 2022) estendeu a abordagem InstructGPT para diálogo de múltiplas rodadas. Era essencialmente um modelo da classe GPT-3.5, afinado com SFT e RLHF em dados conversacionais em vez de apenas instruções de disparo único.
Em vez de uma API ou playground direcionado a desenvolvedores, a OpenAI lançou uma interface de chat simples:
- Usuários podiam conversar com o modelo como em um app de mensagens\n- Contexto entre rodadas tornou a interação conversacional e persistente\n- As pessoas podiam corrigir o modelo, refinar perguntas e explorar ideias iterativamente
Isso reduziu a barreira para usuários não técnicos. Sem necessidade de engenharia de prompts, sem código, sem configuração — só digitar e obter respostas.
O resultado foi uma ruptura mainstream: tecnologia construída sobre anos de pesquisa em transformers e trabalho de alinhamento de repente ficou acessível a qualquer pessoa com navegador. O tuning por instrução e o RLHF fizeram o sistema parecer cooperativo e seguro o suficiente para liberação ampla, enquanto a interface de chat transformou um modelo de pesquisa em um produto global e ferramenta cotidiana.
GPT-3.5: de sistema de pesquisa a ferramenta cotidiana
O GPT-3.5 marcou o momento em que grandes modelos de linguagem deixaram de ser principalmente curiosidade de pesquisa e passaram a parecer utilitários cotidianos. Ficou entre o GPT-3 e o GPT-4 em capacidade, mas sua real importância foi quão acessível e prático se tornou.
Uma ponte entre GPT-3 e GPT-4
Tecnicamente, o GPT-3.5 refinou a arquitetura central do GPT-3 com dados de treino melhores, otimização atualizada e amplo tuning por instrução. Modelos da série — incluindo text-davinci-003 e depois gpt-3.5-turbo — foram treinados para seguir instruções em linguagem natural de modo mais confiável que o GPT-3, responder com mais segurança e manter conversas multi-turno coerentes.
Isso fez do GPT-3.5 um degrau natural rumo ao GPT-4. Anunciou padrões que definiriam a próxima geração: raciocínio mais forte em tarefas cotidianas, melhor manuseio de prompts longos e comportamento de diálogo mais estável, tudo isso sem o salto completo em complexidade e custo associado ao GPT-4.
ChatGPT e a ascensão da IA conversacional
A primeira liberação pública do ChatGPT no fim de 2022 foi alimentada por um modelo da classe GPT-3.5 afinado com RLHF. Isso melhorou dramaticamente como o modelo:
- Mantinha o foco ao longo de várias rodadas\n- Pedia esclarecimentos em vez de chutar respostas\n- Seguia instruções formuladas em linguagem casual
Para muitas pessoas, o ChatGPT foi a primeira experiência prática com um grande modelo de linguagem e definiu expectativas sobre como um “chat de IA” deveria se comportar.
gpt-3.5-turbo e por que virou padrão
Quando a OpenAI liberou gpt-3.5-turbo via API, ofereceu uma combinação atraente de preço, velocidade e capacidade. Era mais barato e rápido que modelos GPT-3 anteriores, mas fornecia melhor seguimento de instruções e qualidade de diálogo.
Esse equilíbrio fez do gpt-3.5-turbo a escolha padrão para muitas aplicações:
- Startups o usaram para bots de suporte, geração de conteúdo e ferramentas internas.\n- Desenvolvedores adotaram para explicar código, documentação inline e síntese simples de código.\n- Equipes de produto integraram em apps de produtividade, transformando autocompletar, sumarização e rascunho em expectativas padrão.
O GPT-3.5, portanto, desempenhou um papel de transição: potente o suficiente para desbloquear produtos reais em escala, econômico o bastante para ser amplamente implantado e alinhado o bastante com instruções humanas para ser realmente útil em fluxos de trabalho diários.
GPT-4: modelos multimodais e raciocínio mais forte
Construa com chat, não com boilerplate
Transforme o que você aprendeu sobre GPT em um app funcional criado por chat no Koder.ai.
O GPT-4, lançado pela OpenAI em 2023, marcou uma mudança de “grande modelo de texto” para assistente de propósito geral com habilidades de raciocínio mais fortes e entrada multimodal.
Do GPT-3 ao GPT-4: o que realmente mudou
Em comparação com GPT-3 e GPT-3.5, o GPT-4 focou menos em contagem de parâmetros e mais em:
- Raciocínio e confiabilidade: Melhor desempenho em exames e benchmarks (ex.: provas da ordem dos advogados, problemas estilo olimpíada, desafios de programação) e menos erros lógicos óbvios.\n- Controlabilidade: Mensagens de sistema permitem que desenvolvedores especifiquem estilo, papel e restrições de forma mais direta.\n- Contexto mais longo: Certas variantes lidam com prompts muito mais extensos, possibilitando análise de documentos e fluxos de trabalho multi‑etapa.
A família principal incluiu gpt-4 e depois gpt-4-turbo, que buscavam oferecer qualidade similar ou melhor a custo e latência menores.
Multimodalidade: entender mais que texto
Uma característica de destaque do GPT-4 foi sua habilidade multimodal: além de entrada textual, podia aceitar imagens. Usuários podiam:
- Fazer perguntas sobre diagramas, gráficos ou notas manuscritas\n- Obter descrições de screenshots de interfaces\n- Usar imagens para guiar código, design ou extração de dados
Isso fez o GPT-4 parecer menos um modelo apenas de texto e mais um motor de raciocínio geral que se comunica via linguagem.
Segurança, alinhamento e controle
O GPT-4 também foi treinado e ajustado com ênfase maior em segurança e alinhamento:
- Expansão do RLHF para reduzir saídas nocivas ou enganosas\n- Políticas de conteúdo e comportamentos de recusa mais refinados\n- Ferramentas melhores para controlar tom, verbosidade e persona via prompts de sistema e configurações de API
Modelos como gpt-4 e gpt-4-turbo tornaram-se escolhas padrão para usos de produção sérios: automação de suporte ao cliente, assistentes de programação, ferramentas educacionais e busca por conhecimento. O GPT-4 preparou o terreno para variantes posteriores como GPT-4o e GPT-4o mini, que avançaram em eficiência e interação em tempo real herdando muitos avanços de raciocínio e segurança do GPT-4.
GPT-4o e GPT-4o mini: eficiência e uso em tempo real
O GPT-4o ("omni") marca uma mudança de “o mais capaz a qualquer custo” para “rápido, acessível e sempre disponível”. Foi projetado para entregar qualidade do nível GPT-4 com custo muito menor e rapidez suficiente para experiências interativas ao vivo.
Para que o GPT-4o é otimizado
O GPT-4o unifica texto, visão e áudio em um único modelo. Em vez de integrar componentes separados, ele lida nativamente com:
- Chat de texto e programação\n- Compreensão de imagens (screenshots, fotos, diagramas)\n- Entrada e saída de áudio em tempo real
Essa integração reduz latência e complexidade. O GPT-4o pode responder em tempo quase real, transmitir respostas em streaming enquanto "pensa" e alternar entre modalidades dentro de uma mesma conversa.
Velocidade, custo e acesso diário
Um objetivo central do GPT-4o foi eficiência: melhor desempenho por dólar e menor latência por requisição. Isso permite que a OpenAI e desenvolvedores:
- Ofereçam camadas mais baratas ou até gratuitas mantendo qualidade elevada\n- Potencializem produtos de alto volume (chat, suporte, educação) sem custos proibitivos\n- Ativem recursos interativos como respostas em streaming e correções ao vivo
O resultado é que capacidades antes restritas a APIs de alto custo ficam agora acessíveis a estudantes, entusiastas, pequenas startups e equipes experimentais.
GPT-4o mini: pequeno, rápido e onipresente
O GPT-4o mini estende a acessibilidade ao trocar parte da capacidade máxima por velocidade e custo ultra‑baixo. É bem adequado para:
- Assistentes sempre ativos e agentes em segundo plano\n- Chatbots simples, roteamento e sumarização\n- Ferramentas leves que precisam de respostas rápidas e baratas
Como o 4o mini é econômico, desenvolvedores podem embuti‑lo em muitos lugares — dentro de apps, portais de clientes, ferramentas internas ou serviços de baixo orçamento — sem se preocupar tanto com a fatura de uso.
Juntos, GPT-4o e GPT-4o mini estendem recursos avançados do GPT a casos de uso multimodais, conversacionais e em tempo real, ampliando quem pode construir com — e se beneficiar de — modelos de ponta.
Tendências técnicas que moldaram a evolução do GPT
Diversas correntes técnicas percorrem cada geração de modelos GPT: escala, feedback, segurança e especialização. Juntas, explicam por que cada nova versão parece qualitativamente diferente, não apenas maior.
Leis de escala e o padrão “mais dados, mais compute, melhores modelos”
Uma descoberta chave por trás do progresso do GPT são as leis de escala: ao aumentar parâmetros, tamanho do dataset e compute de forma balanceada, o desempenho tende a melhorar de modo suave e previsível em muitas tarefas.
Modelos iniciais mostraram que:
- Transformers maiores treinados em texto mais diverso e de maior qualidade generalizam melhor.\n- Muitas habilidades (tradução, programação, comportamento similar a raciocínio) emergem quando a escala ultrapassa certos limiares, mesmo sem treino específico por tarefa.
Isso levou a uma abordagem sistemática:
- Planejar tamanho do modelo e do dataset juntos, com base em curvas empíricas de escala.\n- Usar corpora cada vez maiores, deduplicados e filtrados misturando dados da web, livros, código e dados proprietários.\n- Otimizar eficiência de treino (paralelismo melhor, kernels, uso de hardware) para viabilizar cada passo de escala economicamente.
Reinforcement learning from human feedback (RLHF)
Modelos GPT brutos são poderosos, mas indiferentes às expectativas dos usuários. O RLHF os transforma em assistentes úteis:
- Coletar respostas escritas ou avaliadas por humanos a prompts.\n2. Treinar um modelo de recompensa que prevê quais respostas usuários preferem.\n3. Usar aprendizado por reforço (frequentemente Proximal Policy Optimization) para que o modelo base gere respostas de alto valor.
Com o tempo, isso evoluiu para tuning por instrução + RLHF: primeiro afinamento em muitos pares instrução–resposta, depois aplicação de RLHF para refinar o comportamento. Essa combinação sustenta interações no estilo ChatGPT.
Avaliações de segurança e filtros de conteúdo
À medida que as capacidades cresciam, também cresceu a necessidade de avaliações sistemáticas de segurança e aplicação de políticas.
Padrões técnicos incluem:
- Red‑teaming dedicado e testes automatizados para cenários de uso indevido (ex.: conselhos perigosos, conteúdo proibido).\n- Variantes do modelo ajustadas para segurança, otimizadas para recusar ou redirecionar pedidos arriscados.\n- Filtros de conteúdo que operam em paralelo ao modelo: classificadores e heurísticas checando prompts e saídas contra políticas antes da entrega.
Esses mecanismos são iterados repetidamente: novas avaliações descobrem modos de falha, que retroalimentam dados de treino, modelos de recompensa e filtros.
De um grande modelo monolítico para famílias de modelos
Lançamentos iniciais focavam em um modelo “flagship” com poucas variantes menores. Com o tempo, a tendência mudou para famílias de modelos otimizadas para diferentes restrições e casos de uso:
- Modelos de ponta para raciocínio complexo e tarefas multimodais.\n- Modelos mais leves e baratos (variantes “mini”) voltados para interação em tempo real, implantação em larga escala ou uso na borda.\n- Modelos especializados para programação, moderação ou fluxos enterprise.
Por baixo, isso reflete uma pilha madura: arquiteturas base e pipelines de treino compartilhados, seguidos por afinamentos direcionados e camadas de segurança para produzir um portfólio em vez de um monólito. Essa estratégia multi‑modelo é hoje uma tendência técnica e de produto definidora na evolução do GPT.
Como os modelos GPT mudaram uso e aplicações de IA
Planeje antes, construa melhor
Use o Planning Mode para mapear telas, dados e fluxos antes de gerar o código.
Os GPTs transformaram IA baseada em linguagem de ferramenta de pesquisa de nicho em infraestrutura sobre a qual muitas pessoas e organizações constroem.
Novos blocos de construção para desenvolvedores
Para desenvolvedores, modelos GPT funcionam como um “motor de linguagem” flexível. Em vez de codificar regras à mão, enviam prompts em linguagem natural e recebem texto, código ou saídas estruturadas.
Isso mudou como software é projetado:
- Protótipos podem ser construídos em horas usando chamadas simples à API.\n- Apps delegam tarefas complexas como sumarização, tradução e geração de código ao modelo.\n- Surgiram padrões como agentes, uso de ferramentas (function calling) e geração com recuperação (RAG).
Como resultado, muitos produtos agora dependem do GPT como componente central, não apenas como recurso adicional.
Como empresas integram GPT
Companhias usam modelos GPT tanto internamente quanto em produtos para clientes.
Internamente, equipes automatizam triagem de suporte, redigem e-mails e relatórios, assistem programação e QA, e analisam documentos e logs. Externamente, GPT alimenta chatbots, copilotos em suítes de produtividade, assistentes de programação, ferramentas de conteúdo e copilotos especializados para finanças, direito, saúde e mais.
APIs e produtos hospedados possibilitam adicionar recursos avançados de linguagem sem gerenciar infraestrutura ou treinar modelos do zero, reduzindo a barreira para pequenas e médias organizações.
Impacto em pesquisa, educação e trabalho criativo
Pesquisadores usam GPT para brainstorm, gerar código para experimentos, rascunhar artigos e explorar ideias em linguagem natural. Educadores e estudantes recorrem ao GPT para explicações, questões de prática, tutoria e apoio linguístico.
Escritores, designers e criadores usam o GPT para esboçar, ideação, construção de mundos e polimento de rascunhos. O modelo atua menos como substituto e mais como colaborador que acelera a exploração.
Preocupações e trade-offs
A difusão dos GPTs também levanta preocupações sérias. A automação pode deslocar alguns empregos enquanto aumenta demanda por outros, empurrando trabalhadores para novas habilidades.
Como o GPT é treinado em dados humanos, pode refletir e amplificar vieses sociais se não for cuidadosamente contido. Pode também gerar informações plausíveis, porém incorretas, ou ser usado para spam, propaganda e conteúdo enganoso em escala.
Esses riscos impulsionaram trabalho em técnicas de alinhamento, políticas de uso, monitoramento e ferramentas para detecção e procedência. Equilibrar aplicações poderosas com segurança, justiça e confiança continua sendo um desafio aberto à medida que os modelos GPT avançam.
Direções futuras e perguntas abertas para modelos GPT
À medida que os modelos GPT se tornam mais capazes, as questões centrais mudam de podemos construí‑los? para como devemos construí‑los, implantar e governar?
Fronteiras técnicas
Eficiência e acessibilidade. GPT-4o e GPT-4o mini sugerem um futuro onde modelos de alta qualidade rodam barato, em servidores menores e, eventualmente, em dispositivos pessoais. Perguntas-chave:
- Até onde podemos reduzir modelos sem perder qualidade de raciocínio?\n- Treino e inferência podem ficar energeticamente eficientes o bastante para escalar de forma sustentável?
Personalização sem sobreajuste. Usuários querem modelos que lembrem preferências, estilo e fluxos de trabalho sem vazar dados ou se polarizar nas visões de uma pessoa. Questões abertas incluem:
- Como separar conhecimento de base do modelo de adaptações específicas do usuário?\n- Como personalizar com segurança em muitos dispositivos e apps?
Confiabilidade e raciocínio. Mesmo os melhores modelos ainda alucinam, falham silenciosamente ou se comportam de modo imprevisível sob mudança de distribuição. A pesquisa investiga:
- Métodos para raciocínio verificável e checagens assistidas por ferramentas\n- Maneiras de representar incerteza e dizer “não sei” de forma apropriada
Desafios societais e de governança
Segurança e alinhamento em escala. À medida que modelos ganham agência por meio de ferramentas e automação, alinhá‑los com valores humanos — e mantê‑los alinhados durante atualizações contínuas — permanece um desafio. Isso inclui pluralismo cultural: quais valores e normas são codificados e como lidar com desacordos?
Regulação e padrões. Governos e grupos da indústria estão redigindo regras para transparência, uso de dados, watermarking e relato de incidentes. As perguntas:
- O que deve ser mandatório (auditorias, red‑teaming, avaliações de segurança)?\n- Como harmonizar regras entre jurisdições para beneficiar inovação e segurança?
Uma perspectiva equilibrada
Sistemas GPT futuros provavelmente serão mais eficientes, mais personalizados e mais integrados em ferramentas e organizações. Junto com novas capacidades, espere práticas de segurança mais formais, avaliação independente e controles de usuário mais claros. A história de GPT-1 ao GPT-4 sugere progresso contínuo, mas também que avanços técnicos devem andar lado a lado com governança, participação social e medição cuidadosa do impacto no mundo real.
Perguntas frequentes
O que é um modelo GPT em termos simples?
GPT (Generative Pre-trained Transformer) são grandes redes neurais treinadas para prever a próxima palavra em uma sequência. Fazendo isso em larga escala com enormes corpora de texto, elas aprendem gramática, estilo, fatos e padrões de raciocínio. Depois de treinadas, podem:
- Gerar novo texto (histórias, e-mails, código)
- Responder perguntas e explicar conceitos
- Resumir e traduzir documentos
- Agir como assistentes conversacionais ou copilotos em apps
Por que a história dos modelos GPT importa para os usuários de hoje?
Saber a história ajuda a esclarecer:
- Por que as capacidades pulavam entre versões (por exemplo, GPT-2 → GPT-3 → GPT-4)
- No que cada modelo é bom e ruim (raciocínio, comprimento de contexto, multimodalidade)
- Como segurança e alinhamento evoluíram (de geração bruta de texto a assistentes no estilo ChatGPT)
- Por que as ferramentas atuais têm a forma que têm, de APIs a interfaces de chat e modelos “mini”
Também ajuda a estabelecer expectativas realistas: os GPTs são poderosos aprendizes de padrões, não oráculos infalíveis.
Quais são os principais marcos de GPT-1 até GPT-4o?
Marcos principais incluem:
- GPT-1 (2018): Provou que um transformador generativo, pré-treinado em texto e depois afinado, podia lidar com várias tarefas de NLP.\n- GPT-2 (2019): Escalou para 1,5B de parâmetros, mostrando fortes capacidades zero-shot e few-shot e gerando debates públicos sobre uso indevido.\n- 175B de parâmetros e forte aprendizado in‑context, disponibilizado principalmente via API.\n- Tuning por instrução e RLHF transformaram o GPT em um assistente conversacional prático.\n- Melhor raciocínio, contexto mais longo e entrada multimodal (texto + imagens).\n- Foco em eficiência, baixo custo e interação multimodal em tempo real.
Como o tuning por instrução e o RLHF mudam o comportamento do GPT?
O tuning por instrução e o RLHF tornam os modelos mais alinhados com o que as pessoas realmente querem.
- Tuning por instrução (SFT): Afina o modelo com muitos pares instrução–resposta escritos por humanos, para que aprenda a seguir instruções claramente.\n- RLHF: Treina um modelo de recompensa a partir de rankings humanos de saídas e otimiza o GPT para gerar respostas mais bem avaliadas.
Juntos, eles:
O que realmente mudou do GPT-3.5 para o GPT-4?
O GPT-4 difere dos modelos anteriores em vários aspectos:
- Raciocínio: Melhor desempenho em exames, tarefas de programação e instruções complexas.\n- Controlabilidade: Mensagens de sistema permitem que desenvolvedores definam tom, persona e restrições.\n- Comprimento de contexto: Algumas variantes aceitam entradas bem mais longas para tarefas em nível de documento.\n- Multimodalidade: Aceita imagens como entrada, possibilitando tarefas como análise de diagramas ou entendimento de interfaces.
Essas mudanças empurram o GPT-4 de gerador de texto para assistente de propósito geral.
Para que são mais indicados o GPT-4o e o GPT-4o mini?
GPT-4o e GPT-4o mini são otimizados para velocidade, custo e uso em tempo real, em vez de apenas máxima capacidade.
- GPT-4o: Modelo único que lida com texto, imagens e áudio, com baixa latência adequado para chat ao vivo, assistentes de voz e ferramentas interativas.\n- GPT-4o mini: Menor e mais barato, ideal para:\n - Chatbots de alto volume e fluxos de suporte\n - Resumos leves, roteamento e rascunhos rápidos\n - Agentes sempre ativos embutidos em muitos apps
Eles tornam recursos avançados do GPT economicamente viáveis para uso mais amplo e cotidiano.
Como desenvolvedores e empresas estão integrando modelos GPT em produtos?
Desenvolvedores usam modelos GPT para:
- Construir chatbots e copilotos (suporte, vendas, ferramentas internas)
- Redigir e resumir e-mails, relatórios, tickets e documentação
- Gerar e explicar código, testes e transformações de dados
- Implementar tradução, análise de sentimento e classificação sem ML sob medida
- Prototipar fluxos complexos via uso de ferramentas e geração com recuperação (RAG)
Como o acesso é via API, equipes podem integrar essas capacidades sem treinar ou hospedar seus próprios modelos grandes.
Quais são as principais limitações e riscos dos modelos GPT atuais?
As principais limitações dos GPTs atuais incluem:
- Alucinações: Podem produzir informações confiantes, mas incorretas ou fabricadas.\n- Vieses: Dados de treinamento podem codificar vieses sociais e culturais que aparecem nas saídas.\n- Sensibilidade ao contexto: Desempenho pode piorar com entradas muito longas, desordenadas ou fora da distribuição.\n- Falta de entendimento real: Modelam padrões em texto, não conhecimento ancorado no mundo.
Para usos críticos, as saídas devem ser verificadas, restringidas com ferramentas (ex.: recuperação, validadores) e acompanhadas por supervisão humana.
Quais direções futuras para os modelos GPT o artigo destaca?
Várias tendências provavelmente moldarão futuros sistemas GPT:
- Eficiência: Modelos menores e mais baratos com qualidade próxima à do GPT-4, possivelmente rodando em servidores menores ou dispositivos pessoais.\n- Personalização: Formas seguras de adaptar preferências e estilos de usuários sem vazar ou sobreajustar dados privados.\n- Confiabilidade: Melhor tratamento de incerteza, raciocínio verificável e comportamento de “não sei” apropriado.\n- Governança: Padrões mais fortes para avaliações de segurança, transparência e relato de incidentes à medida que modelos ganham capacidades e autonomia.
A tendência é por sistemas mais capazes, porém mais controlados e responsabilizados.
Como as equipes devem pensar em usar modelos GPT de forma segura e eficaz?
O artigo sugere orientações práticas:
- Escolha o nível certo: Use modelos de ponta (classe GPT‑4) para raciocínio complexo; use modelos tipo 4o mini para tarefas simples e alto volume.\n- Camadas de segurança: Combine modelos alinhados com filtros de conteúdo, políticas de uso e revisão humana quando os riscos forem altos.\n- Projete para verificação: Trate as saídas como rascunhos ou sugestões, não como verdades absolutas; acrescente recuperação e checagens para informações críticas.\n- Itere prompts e UX: Pequenas mudanças em instruções, contexto e interface podem afetar muito a confiabilidade e a confiança do usuário.
Usar GPTs com eficácia significa parear seus pontos fortes com salvaguardas e bom design de produto.