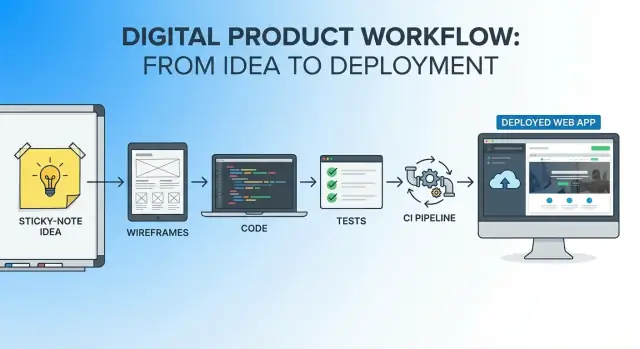
O objetivo: um caminho contínuo da ideia ao app ao vivo
Imagine uma ideia pequena e útil: um “Queue Buddy” que permite que um funcionário de café toque um botão para adicionar um cliente a uma lista de espera e envie automaticamente um SMS quando a mesa ficar pronta. A métrica de sucesso é simples e mensurável: reduzir as chamadas por dúvidas sobre o tempo de espera em 50% em duas semanas, mantendo o onboarding da equipe abaixo de 10 minutos.
Esse é o espírito deste artigo: escolha uma ideia clara e limitada, defina o que significa “bom” e depois vá do conceito ao deploy sem ficar trocando constantemente de ferramentas, documentos e modelos mentais.
O que significa “fluxo único”
Um fluxo único é um fio contínuo desde a primeira frase da ideia até a primeira release em produção:
- Um lugar onde decisões são registradas (o que estamos construindo e por quê)
- Um conjunto de artefatos que evolui (requisitos → telas → tarefas → código → testes → notas de deploy)
- Um loop de feedback (cada mudança pode ser rastreada até o objetivo e a métrica)
Você ainda usará múltiplas ferramentas (editor, repo, CI, hosting), mas não vai “reiniciar” o projeto em cada fase. A mesma narrativa e restrições seguem adiante.
O papel da IA: assistente, não piloto automático
A IA é mais valiosa quando ela:
- Rascunha opções rapidamente (texto de requisitos, fluxos de usuário, formatos de API)
- Gera código inicial e testes que você pode revisar em pequenos pedaços
- Aponta casos de borda que você poderia esquecer (validação, permissões, logging)
Mas ela não toma as decisões do produto. Você toma. O fluxo é desenhado para que você verifique sempre: essa mudança move a métrica? é seguro enviar?
O caminho ponta a ponta que seguiremos
Nas próximas seções, você seguirá passo a passo:
- Esclarecer o problema, os usuários e um “pequeno ganho” que você pode enviar.
- Transformar a ideia em um documento leve de requisitos.
- Esboçar a jornada do usuário e as telas-chave.
- Escolher uma arquitetura sensata para a versão 1.
- Bootstrapar um esqueleto de repo funcional.
- Construir funcionalidades centrais em fatias finas e revisáveis.
- Adicionar o básico de segurança: validação, permissões, logging.
- Incluir testes que protejam o caminho feliz e as partes de risco.
- Configurar builds, CI e gates de qualidade.
- Fazer o deploy com um processo claro e reversível.
- Monitorar, aprender e iterar—sem quebrar o fio.
Ao final, você terá uma maneira repetível de ir da “ideia” ao “app ao vivo” mantendo escopo, qualidade e aprendizado bem conectados.
Antes de pedir para a IA rascunhar telas, APIs ou tabelas de banco, você precisa de um alvo nítido. Um pouco de clareza aqui evita horas de saídas “quase certas” depois.
Declaração do problema em um parágrafo
Você está construindo um app porque um grupo específico de pessoas enfrenta repetidamente a mesma fricção: elas não conseguem completar uma tarefa importante de forma rápida, confiável ou com confiança usando as ferramentas que têm. O objetivo da versão 1 é remover um passo doloroso desse fluxo—sem tentar automatizar tudo—para que os usuários vão de “preciso fazer X” a “X está feito” em minutos, com um registro claro do que aconteceu.
Usuários-alvo e seus 3 principais jobs-to-be-done
Escolha um usuário primário. Usuários secundários podem esperar.
- Usuário primário: operadores/proprietários ocupados que gerenciam o processo de ponta a ponta (não especialistas).
- Principais jobs-to-be-done:
- Capturar a solicitação (ou entrada) rápido, sem perder detalhes-chave.
- Rastrear status de relance e saber o próximo passo.
- Compartilhar um resultado (confirmação, resumo ou exportação) que outros possam confiar.
Suposições (o que precisa ser verdade)
Assunções são onde boas ideias silenciosamente fracassam—torne-as visíveis.
- Usuários vão aceitar um pequeno trabalho de configuração por um fluxo repetível.
- Os dados necessários existem (ou podem ser inseridos) com precisão razoável.
- Um rastro de auditoria leve é suficiente; requisitos de compliance completos não são necessários para o v1.
- A “ajuda da IA” melhora a velocidade, mas os usuários ainda querem controle final.
Definição de pronto para a primeira release
A versão 1 deve ser um pequeno ganho que você possa entregar.
- Um usuário pode completar o fluxo central em menos de 3 minutos.
- Dados são validados e armazenados, com permissões básicas e um log de atividade.
- Existe uma saída compartilhável (email, PDF ou link) consistente.
- Você pode fazer deploy, reverter e responder: “está funcionando?”
Um documento de requisitos leve (pense: uma página) é a ponte entre “ideia legal” e “plano construível.” Ele mantém o foco, dá contexto correto para sua assistente de IA e evita que a primeira versão vire um projeto de meses.
Rascunhe um PRD de uma página (as partes que importam)
Mantenha enxuto e fácil de ler. Um template simples:
- Problema: qual dor estamos resolvendo, em uma frase?
- Usuários-alvo: quem sente essa dor com mais frequência?
- Escopo (Versão 1): o que você vai construir agora.
- Non-goals: o que você explicitamente não vai construir ainda.
- Restrições: orçamento, cronograma, restrições técnicas, compliance, dispositivos, fontes de dados.
- Métrica de sucesso: como saber que “deu certo” (mesmo um proxy simples serve).
Defina e ranqueie 5–10 funcionalidades principais
Escreva no máximo 5–10 features, redigidas como resultados. Depois ranqueie:
- Must-have (o app falha sem isso)
- Should-have (alto valor, mas pode esperar)
- Nice-to-have (estacione)
Esse ranqueamento também guia planos e código gerados pela IA: “Implemente apenas os must-haves primeiro.”
Adicione critérios de aceitação para as principais features
Para as 3–5 principais, acrescente 2–4 critérios de aceitação cada. Use linguagem simples e declarações testáveis.
Exemplo:
- Feature: Criar conta
- Usuário pode se cadastrar com email e senha
- Senha deve ter no mínimo 12 caracteres
- Após o cadastro, o usuário cai no dashboard
- Email duplicado apresenta uma mensagem de erro clara
Capture perguntas em aberto para validação rápida
Finalize com uma curta lista “Perguntas em aberto”—coisas que você responde com um chat, uma ligação com um cliente ou uma busca rápida.
Exemplos: “Usuários precisam de login Google?” “Qual o mínimo de dados que devemos armazenar?” “Precisamos de aprovação de admin?”
Esse documento não é papelada; é uma fonte de verdade compartilhada que você continuará atualizando conforme o build progride.
Esboce a jornada do usuário e as telas-chave
Antes de pedir à IA que gere telas, alinhe a história do produto. Um esboço rápido de jornada mantém todos na mesma página: o que o usuário tenta fazer, o que é sucesso e onde as coisas podem dar errado.
Mapeie os fluxos principais (caminho feliz + casos de borda importantes)
Comece pelo caminho feliz: a sequência mais simples que entrega o valor principal.
Exemplo de fluxo (genérico):
- Usuário se cadastra / faz login
- Usuário cria um novo Projeto
- Usuário adiciona Tarefas
- Usuário marca uma Tarefa como concluída
- Usuário vê progresso / confirmação
Depois adicione alguns casos de borda prováveis e custosos se mal tratados:
- Usuário abandona o cadastro pela metade (o que acontece com dados parciais?)
- Usuário perde acesso (sessão expirada, permissão revogada)
- Estado vazio (nenhum projeto ainda)
- Falha ao salvar (erro de rede) e comportamento de retry
Você não precisa de um grande diagrama. Uma lista numerada mais notas já basta para guiar prototipagem e geração de código.
Liste telas/páginas-chave e o que cada uma deve realizar
Escreva um pequeno “job to be done” para cada tela. Foque em resultados, não em UI.
- Login / Signup: fazer o usuário entrar; explicar erros claramente; permitir reset de senha
- Dashboard: mostrar itens atuais e a próxima ação; tratar estados vazios com cuidado
- Detalhe do Projeto: exibir info do projeto; permitir adicionar/editar tarefas; mostrar status
- Editor de Tarefa (modal/página): criar ou atualizar uma tarefa; validar campos obrigatórios
- Configurações / Conta: gerenciar perfil; desconectar; deletar conta se necessário
Se você trabalha com IA, essa lista vira excelente material de prompt: “Gere um Dashboard que suporte X, Y, Z e inclua estados empty/loading/error.”
Defina entidades de dados em alto nível
Mantenha no nível de “esquema de guardanapo”—o suficiente para suportar telas e fluxos.
- User: id, email, name, role
- Project: id, ownerId, title, createdAt
- Task: id, projectId, title, status, dueDate
Note relacionamentos (User → Projects → Tasks) e qualquer coisa que afete permissões.
Identifique onde confiança e segurança importam
Marque os pontos onde erros quebram confiança:
- Autenticação e gerenciamento de sessão
- Permissões (quem pode ver/editar um projeto?)
- Ações destrutivas (deletar projeto/tarefa) e confirmações
- Auditabilidade (logging básico de edições e deleções)
Não se trata de superengenharia—trata-se de prevenir surpresas que transformam um demo funcional em dor de cabeça no suporte após o lançamento.
Escolha uma arquitetura sensata para o v1
A arquitetura da versão 1 deve fazer uma coisa bem: permitir que você envie o menor produto útil sem se enredar. Uma boa regra é “um repo, um backend implantável, um frontend implantável, um banco”—e só adicione peças quando um requisito claro exigir.
Escolha a pilha mais simples que sirva
Se você vai construir um app web típico, um padrão sensato é:
- Frontend: React (ou Next.js se quiser roteamento + SSR básico)
- Backend: Node.js + framework mínimo (Express/Fastify) ou rotas API do Next.js se a API for pequena
- Banco: Postgres (confiável, flexível e amplamente suportado)
Mantenha o número de serviços baixo. Para v1, um “monolito modular” (código bem organizado, mas um backend) costuma ser mais fácil que microsserviços.
Se preferir um ambiente orientado à IA onde arquitetura, tarefas e código gerado fiquem conectados, plataformas como Koder.ai podem encaixar bem: você descreve o escopo do v1 em chat, itera em “modo planejamento” e gera um frontend React com backend Go + PostgreSQL—tudo mantendo revisão e controle nas suas mãos.
Esboce sua API como um contrato
Antes de gerar código, escreva uma pequena tabela de API para alinhar IA e equipe. Exemplo de formato:
GET /api/projects → { items: Project[] }POST /api/projects → { project: Project }GET /api/projects/:id → { project: Project, tasks: Task[] }POST /api/projects/:id/tasks → { task: Task }
Adicione notas para códigos de status, formato de erro (ex.: { error: { code, message } }) e paginação, se necessário.
Decida sobre autenticação (ou evite-a)
Se o v1 pode ser público ou single-user, pule auth e envie mais rápido. Se precisar de contas, use um provedor gerenciado (magic link por email ou OAuth) e mantenha permissões simples: “usuário é dono dos seus registros.” Evite papéis complexos até que o uso real exija.
Documente algumas restrições práticas:
- Tráfego esperado (mesmo número aproximado)
- Objetivo de tempo de resposta (ex.: “a maioria das requisições abaixo de 300ms”)
- Logging mínimo (requisições, erros e eventos de negócio chave)
- Backups e plano de rollback
Essas notas guiam a geração assistida por IA para algo implantável, não apenas funcional.
Bootstrap do repo: de pasta vazia a esqueleto funcional
Vá ao vivo no seu domínio
Adicione um domínio personalizado para que seu v1 pareça real no momento do lançamento.
A forma mais rápida de matar o impulso é debater ferramentas por uma semana e não ter código executável. O objetivo aqui é simples: chegar a um “hello app” que inicia localmente, tem uma tela visível e aceita uma requisição—mantendo o repositório pequeno o bastante para revisão rápida.
Peça à IA um esqueleto prático (não um produto acabado)
Dê à IA um prompt apertado: escolha de framework, páginas básicas, uma API stub e os arquivos esperados. Você quer convenções previsíveis, não genialidade.
Um primeiro passe pode ter estrutura como:
/README.md
/.env.example
/apps/web/
/apps/api/
/package.json
Se usar um repositório único, peça rotas básicas (ex.: / e /settings) e um endpoint de API (ex.: GET /health ou GET /api/status). Isso já prova que o encanamento funciona.
Se usar Koder.ai, este é um bom lugar para começar: peça um esqueleto mínimo “web + api + pronto para banco”, depois exporte o código quando estiver satisfeito com estrutura e convenções.
Gere uma UI mínima ligada a um backend stub
Mantenha a UI propositalmente simples: uma página, um botão, uma chamada.
Exemplo de comportamento:
- A homepage renderiza “App is running.”
- Um botão chama o endpoint do backend.
- A resposta é exibida na página.
Isso te dá um ciclo de feedback imediato: se a UI carrega mas a chamada falha, você sabe onde olhar (CORS, porta, roteamento, rede). Resista a adicionar auth, banco ou estado complexo aqui—faça isso após o esqueleto estar estável.
Adicione variáveis de ambiente e instruções de dev local
Crie um .env.example no dia um. Evita problemas de “funciona na minha máquina” e facilita onboarding.
Exemplo:
WEB_PORT=3000
API_PORT=4000
API_URL=http://localhost:4000
Depois torne o README executável em menos de um minuto:
- instalar dependências
- copiar
.env.example para .env
- iniciar web + api
- abrir a URL no navegador
Mantenha mudanças pequenas e comite cedo
Trate essa fase como alinhar fundações limpas. Comite após cada pequeno avanço: “init repo”, “add web shell”, “add api health endpoint”, “wire web to api.” Commits pequenos tornam a iteração assistida por IA mais segura: se uma mudança gerada der errado, você reverte sem perder um dia de trabalho.
Construa as features centrais em fatias finas e revisáveis
Com o esqueleto rodando end-to-end, resista ao impulso de “terminar tudo”. Em vez disso, construa uma fatia vertical estreita que toque banco, API e UI (se aplicável), e repita. Fatias finas mantêm revisões rápidas, bugs pequenos e a ajuda da IA fácil de verificar.
Comece pelo modelo de dados principal (e migrations)
Escolha o modelo sem o qual seu app não funciona—geralmente a “coisa” que usuários criam ou gerenciam. Defina-o claramente (campos, obrigatório vs opcional, defaults) e adicione migrations se usar um relacional. Mantenha o primeiro versionamento sem frescura: evite normalização criativa e flexibilidade prematura.
Se usar IA para rascunhar o modelo, peça que justifique cada campo e default. Tudo que não conseguir explicar em uma frase provavelmente não pertence ao v1.
Crie apenas os endpoints necessários para a primeira jornada do usuário: tipicamente criar, ler e uma atualização mínima. Coloque validação perto da fronteira (DTO/schema) e torne regras explícitas:
- campos obrigatórios, formatos e intervalos permitidos
- checagens de propriedade/permissão (“esse usuário pode acessar este registro?”)
- formatos de resposta consistentes (sucesso e falha)
Validação faz parte da feature, não é acabamento—evita dados bagunçados que atrasam depois.
Tratamento de erro que ajuda humanos
Trate mensagens de erro como UX para debugging e suporte. Retorne mensagens claras e acionáveis (o que falhou e como consertar) mantendo detalhes sensíveis fora das respostas ao cliente. Logue contexto técnico no servidor com um request ID para traçar incidentes sem adivinhação.
Use sugestões da IA—e revise cada mudança
Peça à IA mudanças incrementais do tamanho de um PR: uma migration + um endpoint + um teste por vez. Revise diffs como faria com o código de um colega: checar nomes, casos de borda, suposições de segurança e se a mudança realmente suporta o “pequeno ganho” do usuário. Se acrescentar features extras, corte e siga adiante.
Deixe “seguro o suficiente”: validação, permissões e logs
Converta aprendizado em créditos
Ganhe créditos criando conteúdo sobre Koder.ai ou compartilhando seu link de indicação.
O v1 não precisa de segurança de nível enterprise—mas precisa evitar falhas previsíveis que transformam um app promissor em pesadelo de suporte. O objetivo aqui é “seguro o suficiente”: impedir entrada ruim, restringir acesso por padrão e deixar um rastro útil quando algo der errado.
Validação de entrada + proteção básica contra abuso
Trate toda fronteira como não confiável: formulários, payloads de API, query params e até webhooks internos. Valide tipo, tamanho e valores permitidos, e normalize dados (trim em strings, converter case) antes de armazenar.
Alguns padrões práticos:
- Validação server-side (sempre), mesmo que haja validação na UI.
- Rate limits para login, reset de senha e endpoints caros.
- Checks de upload de arquivo: limite de tamanho, MIME types permitidos e scan antiviral se aceitar uploads públicos.
- Mensagens de erro seguras: diga ao usuário o que consertar, sem vazar stack traces ou identificadores internos.
Se usar IA para gerar handlers, peça que inclua regras de validação explicitamente (ex.: “máx 140 chars” ou “deve ser um de: …”) em vez de só “valide input.”
Permissões: comece pequeno, negue por padrão
Um modelo simples costuma bastar para o v1:
- Anônimo: apenas páginas públicas
- Usuário autenticado: pode criar e ver seus próprios dados
- Owner/editor (opcional): pode editar registros compartilhados
Centralize checagens de propriedade em middleware/funções de policy reutilizáveis para não espalhar if userId == … pelo código.
Logs que ajudam a debugar rápido
Bons logs respondem: o que aconteceu, para quem e onde? Inclua:
- Request ID (propague entre serviços)
- User ID (quando autenticado)
- Ação + recurso (ex.:
update_project, project_id)
- Tempo (duração para requests lentos)
Logue eventos, não segredos: nunca escreva senhas, tokens ou dados de pagamento completos.
Checklist rápido de “erros comuns”
Antes de chamar o app de “seguro o suficiente”, verifique:
- Auth requerida em todas rotas não públicas
- Checagens de autorização (não só autenticação)
- Rate limits em endpoints de auth e escrita
- Validação server-side para todas entradas
- Segredos em env/secret manager (nunca no repo)
- Logging consistente e não sensível com request IDs
Adicione testes que protejam o caminho feliz e os riscos
Testes não são perseguição a uma nota perfeita—são evitar falhas que prejudicam usuários, quebram confiança ou geram incêndios caros. Em um fluxo assistido por IA, testes também são um “contrato” que mantém o código gerado alinhado ao que você quis dizer.
Comece pela lógica de maior risco
Antes de aumentar cobertura, identifique onde erros seriam custosos. Áreas típicas de alto risco incluem dinheiro/créditos, permissões, transformações de dados e validação de casos de borda. Escreva testes unitários primeiro para essas partes. Mantenha pequenos e específicos: dado X, espero Y (ou erro). Se uma função tem muitos ramos, é sinal que deve ser simplificada.
Adicione 1–2 testes de integração para o fluxo principal
Testes unit pegam bugs de lógica; integração pega bugs de “fiação”—rotas, chamadas de banco, checagens de auth e o fluxo UI funcionando junto.
Escolha a jornada central (caminho feliz) e automatize-a end-to-end:
- Criar conta / login
- Completar a ação principal do app
- Confirmar que o resultado aparece onde o usuário espera (tela, email, dashboard)
Alguns testes de integração sólidos frequentemente evitam mais incidentes do que dezenas de testes minúsculos.
Use a IA para rascunhar testes—e torne-os significativos
A IA é ótima para gerar scaffolding de testes e enumerar casos de borda que você pode perder. Peça:
- casos de limite (valores vazios, tamanhos máximos, fusos horários)
- casos negativos (acesso não autorizado, estados inválidos)
- exemplos de dados realistas (não só “foo/bar”)
Depois revise cada asserção. Testes devem verificar comportamento, não detalhes de implementação. Se um teste passa mesmo com um bug, não está fazendo seu trabalho.
Escolha um alvo modesto (por exemplo, 60–70% nos módulos centrais) e use como limitador, não troféu. Foque em testes estáveis e rápidos que rodem no CI e falhem por bons motivos. Testes flakey corroem confiança—e quando a suíte deixa de ser confiável, ela pára de proteger você.
Prepare para automação: builds, CI e gates de qualidade
Automação é onde um fluxo assistido por IA deixa de ser “funciona na minha máquina” e vira algo que você pode enviar com confiança. O objetivo não é ferramenta chique—é repetibilidade.
Escolha um comando que produza o mesmo resultado local e no CI. Em Node, npm run build; em Python, um make build; em mobile, um passo Gradle/Xcode específico.
Separe configuração de dev e produção cedo. Regra simples: defaults dev são convenientes; defaults prod são seguros.
{
"scripts": {
"lint": "eslint .",
"format": "prettier -w .",
"test": "vitest run",
"build": "vite build"
}
}
Um linter pega padrões arriscados (variáveis não usadas, async inseguro). Um formatter evita debates de estilo aparecendo como diffs ruidosos. Mantenha regras modestas para o v1, mas aplique consistentemente.
Ordem prática de gates:
- formatar → 2) lint → 3) testes → 4) build
Seu primeiro workflow de CI pode ser pequeno: instalar dependências, rodar gates e falhar rápido. Isso já previne que código quebrado entre silenciosamente.
name: ci
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npm run format -- --check
- run: npm run lint
- run: npm test
- run: npm run build
Defina o manuseio de segredos (e torne difícil errar)
Decida onde segredos vivem: store de segredos do CI, gerenciador de senhas ou variáveis do seu provedor de deploy. Nunca comite segredos no git—adicione .env ao .gitignore e inclua .env.example com placeholders seguros.
Se quiser um próximo passo limpo, conecte esses gates ao seu processo de deploy, para que “CI verde” seja o caminho único para produção.
Planeje o v1 sem trocar de ferramentas
Transforme seu PRD do v1 em tarefas e arquitetura no modo de planejamento do Koder.ai.
Enviar não é um clique—é uma rotina repetível. O objetivo para v1 é simples: escolha um alvo de deploy compatível com sua stack, faça deploy em pequenos incrementos e tenha sempre um caminho de volta.
Escolha o alvo de deploy certo (não compre além do necessário)
Escolha uma plataforma que combine com como seu app roda:
- Site estático + API serverless: Vercel / Netlify
- App web Docker: Render / Fly.io
- VM tradicional: um VPS pequeno (só se realmente precisar)
O que facilita “reimplantar” costuma vencer “máximo controle” nesse estágio.
Se prioridade é minimizar troca de ferramentas, considere plataformas que agrupem build + hosting + rollback. Por exemplo, Koder.ai oferece deployment e hosting com snapshots e rollback, assim você trata releases como passos reversíveis.
Use um checklist de deploy toda vez
Escreva o checklist uma vez e reutilize em cada release. Mantenha curto o suficiente para que as pessoas realmente sigam:
- Confirmar variáveis de ambiente e segredos estão setados
- Rodar migrations do banco (ou confirmar que não há)
- Buildar e iniciar app em configuração de produção
- Rodar um smoke test do fluxo principal
- Verificar se logs estão fluindo e erros visíveis
Se guardar no repositório (por ex. /docs/deploy.md), ele fica próximo ao código.
Adicione pontos de saúde e um endpoint de status
Crie um endpoint leve que responda: “O app está up e alcança dependências?” Padrões comuns:
GET /health para load balancers e monitorsGET /status retornando versão do app + checagens de dependências
Mantenha respostas rápidas, sem cache e seguras (sem segredos).
Planeje rollback antes de precisar
Um plano de rollback deve ser explícito:
- como re-deployar a versão anterior (tag, release ou imagem)
- o que fazer sobre migrations (compatibilidade regressiva; reverter só quando necessário)
- quem decide rollback e quais sinais o disparam (taxa de erro, checks de saúde)
Quando deploy é reversível, liberar vira rotina—e você envia mais seguido com menos estresse.
Feche o ciclo: monitore, aprenda e itere no mesmo fluxo
Lançamento é o começo da fase mais útil: aprender o que usuários reais fazem, onde o app quebra e quais pequenas mudanças movem sua métrica de sucesso. O objetivo é manter o mesmo fluxo assistido por IA que você usou para construir—agora apontado para evidência em vez de suposição.
Comece com um stack mínimo que responda três perguntas: está up? está falhando? está lento?
Uptime checks podem ser simples (hit periódico ao endpoint de health). Error tracking deve capturar stack traces e contexto de requisição (sem coletar dados sensíveis). Performance pode começar com tempos de resposta para endpoints-chave e métricas de carregamento front-end.
Peça à IA para gerar:
- um formato de logging e IDs de correlação para traçar uma ação de usuário end-to-end
- thresholds de alerta (inicialmente conservadores) e um checklist de on-call do que fazer primeiro
Adicione analytics de produto ligado à métrica de sucesso
Não rastreie tudo—rastreie o que prova que o app está funcionando. Defina uma métrica primária (por ex.: “checkout completo”, “criou primeiro projeto”, “convidou colega”). Então instrumente um pequeno funil: entrada → ação chave → sucesso.
Peça à IA nomes e propriedades de eventos, então revise por privacidade e clareza. Mantenha eventos estáveis; trocar nomes toda semana torna tendências inúteis.
Crie uma entrada simples: botão de feedback in-app, um alias de email curto e um template de bug leve. Faça triagem semanal: agrupe feedback por tema, conecte temas à analytics e decida 1–2 melhorias seguintes.
Mantenha o fluxo contínuo pós-lançamento
Trate alertas de monitoramento, quedas em analytics e temas de feedback como novos “requisitos.” Injete-os no mesmo processo: atualize o doc, gere uma proposta de mudança pequena, implemente em fatias finas, adicione um teste direcionado e faça o deploy via o mesmo processo reversível. Para times, uma página “Learning Log” compartilhada mantém decisões visíveis e repetíveis.