O que “fora vs dentro” significa em linguagem simples
Quando você constrói um aplicativo, é fácil imaginar requisições chegando ordenadas, uma a uma. Redes reais não funcionam assim. Um usuário toca “Pagar” duas vezes porque a tela travou. A conexão móvel cai logo após o clique. Um webhook chega atrasado, ou chega duplicado. Às vezes ele nunca chega.
A ideia de Pat Helland sobre dados de fora vs de dentro é uma forma clara de pensar nessa bagunça.
Como é o “fora”
“Fora” é tudo que seu sistema não controla. É onde você conversa com outras pessoas e sistemas, e onde a entrega é incerta: requisições HTTP de navegadores e apps móveis, mensagens de filas, webhooks de terceiros (pagamentos, email, logística) e reenvios disparados por clientes, proxies ou jobs em background.
No lado de fora, assuma que mensagens podem ser atrasadas, duplicadas ou chegar fora de ordem. Mesmo que algo seja “normalmente confiável”, projete para o dia em que não for.
O que significa “dentro”
“Dentro” é o que seu sistema pode tornar confiável. É o estado durável que você armazena, as regras que aplica e os fatos que pode provar depois:
- Registros do banco de dados e seu histórico
- Regras de negócio (por exemplo: “um pedido só pode ser pago uma vez”)
- Uma fonte de verdade para status (pendente, pago, cancelado)
Dentro é onde você protege invariantes. Se você promete “um pagamento por pedido”, essa promessa precisa ser aplicada internamente, porque o lado de fora não é confiável.
A mudança de mentalidade é simples: não assuma entrega perfeita nem timing perfeito. Trate toda interação externa como uma sugestão não confiável que pode se repetir, e faça o interno reagir com segurança.
Isso importa mesmo para times pequenos e apps simples. Quando uma falha de rede cria uma cobrança duplicada ou um pedido travado, deixa de ser teoria e vira reembolso, chamado ao suporte e perda de confiança.
Um exemplo concreto: um usuário toca “Fazer pedido”, o app envia uma requisição e a conexão cai. O usuário tenta de novo. Se o seu interno não tem como reconhecer “essa é a mesma tentativa”, você pode criar dois pedidos, reservar estoque duas vezes ou enviar dois e-mails de confirmação.
A lição chave de Pat Helland
O ponto de Helland é direto: o mundo externo é incerto, mas o interior do seu sistema precisa permanecer consistente. Redes perdem pacotes, celulares perdem sinal, relógios derivam e usuários apertam atualizar. Seu app não controla isso. O que controla é o que aceita como “verdade” uma vez que os dados cruzam uma fronteira clara.
Tempo e incerteza em um momento cotidiano
Imagine alguém pedindo um café no celular enquanto caminha por um prédio com Wi‑Fi ruim. A pessoa toca “Pagar”. O spinner aparece. A rede cai. Ela toca de novo.
Talvez a primeira requisição tenha chegado ao seu servidor, mas a resposta não voltou. Ou talvez nenhuma das requisições tenha chegado. Para o usuário, as duas possibilidades parecem iguais.
Isso é tempo e incerteza: você ainda não sabe o que aconteceu e pode descobrir só depois. Seu sistema precisa se comportar de forma sensata enquanto espera.
Reenvios, duplicatas e reordenamento
Quando você aceita que o lado de fora é pouco confiável, alguns comportamentos “estranhos” se tornam normais:
- Reenvios criam duplicatas (duas requisições “Pagar”).
- Mensagens chegam fora de ordem (um “cancelar” chega antes de “pagar”).
- Uma requisição é processada, mas o cliente nunca vê a resposta.
Dados externos são uma afirmação, não um fato. “Eu paguei” é só uma declaração enviada por um canal pouco confiável. Só vira fato depois que você o registra internamente de forma durável e consistente.
Isso leva a três hábitos práticos: definir limites claros, tornar reenvios seguros com idempotência e planejar reconciliação quando a realidade divergir.
Limites claros: o que seu sistema possui e o que não possui
A ideia “fora vs dentro” começa com uma pergunta prática: onde começa e termina a verdade do seu sistema?
Dentro da fronteira, você pode dar garantias fortes porque controla os dados e as regras. Fora da fronteira, você faz tentativas com melhores esforços e assume que mensagens podem ser perdidas, duplicadas, atrasadas ou chegar fora de ordem.
Na prática, essa fronteira costuma aparecer em pontos como:
- Um endpoint de API que grava um registro no banco
- Um consumidor de fila que transforma um evento em mudança armazenada
- Um handler de callback que registra o que um provedor diz que aconteceu
- Um remetente que notifica outro sistema depois que você confirmou seu próprio estado
Depois de traçar essa linha, decida quais invariantes são inegociáveis dentro dela. Exemplos:
- Um ID de pedido é único no seu banco.
- Um saldo nunca fica negativo.
- Um estado só avança (created -> paid -> shipped).
- Toda requisição externa que você aceita tem uma trilha de auditoria armazenada.
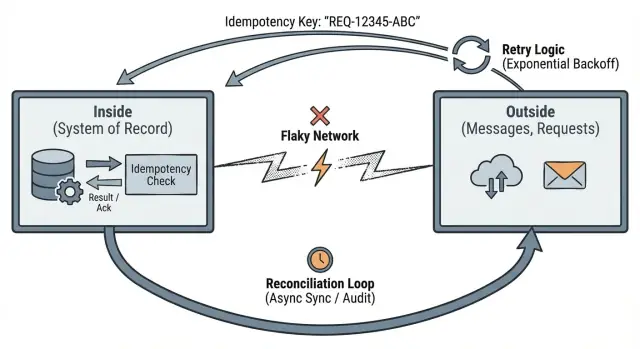
A fronteira também precisa de uma linguagem clara para “onde estamos”. Muitas falhas vivem no gap entre “ouvimos você” e “terminamos”. Um padrão útil é separar três significados:
- Recebido: a mensagem chegou na borda (não necessariamente salva ainda)
- Aceito: você salvou e pode reexecutar o trabalho com segurança depois
- Processado: o trabalho pretendido foi concluído e você registrou o resultado
Quando equipes pulam isso, acabam com bugs que só aparecem sob carga ou durante quedas parciais. Um sistema usa “pago” para significar dinheiro capturado; outro usa para significar tentativa de pagamento iniciada. Esse desalinhamento gera duplicatas, pedidos travados e chamados que ninguém consegue reproduzir.
Idempotência: tornando reenvios seguros
Idempotência significa: se a mesma requisição é enviada duas vezes, o sistema a trata como uma só e retorna o mesmo resultado.
Reenvios são normais. Timeouts acontecem. Clientes repetem requisições. Se o lado de fora pode repetir, seu interior precisa transformar isso em alterações de estado estáveis.
Um exemplo simples: um app móvel envia “pagar $20” e a conexão cai. O app reenvia. Sem idempotência, o cliente pode ser cobrado duas vezes. Com idempotência, a segunda requisição retorna o resultado da primeira cobrança.
A maioria dos times usa um dos padrões a seguir (às vezes misturados):
- Chave de idempotência: o cliente envia uma chave única por ação (por exemplo,
Idempotency-Key: ...). O servidor registra a chave e a resposta final.
- Tabela de deduplicação: armazene uma linha chaveada por (client_id, key) ou (order_id, operation) e recuse um segundo efeito colateral.
- Chaves naturais: use um identificador de negócio que já seja único, assim “criar pagamento” só existe uma vez.
Quando chega uma duplicata, o comportamento ideal geralmente não é responder “409 conflict” ou um erro genérico. É retornar o mesmo resultado que você retornou na primeira vez, incluindo o mesmo ID do recurso e status. Isso torna reenvios seguros para clientes e jobs em background.
Onde guardar o registro (e por quanto tempo)
O registro de idempotência precisa viver dentro da sua fronteira em armazenamento durável, não em memória. Se sua API reiniciar e esquecer, a garantia de segurança desaparece.
Mantenha registros tempo suficiente para cobrir reenvios realistas e entregas atrasadas. A janela depende do risco de negócio: minutos a horas para criações de baixo risco, dias para pagamentos/emails/envios onde duplicatas são custosas, e mais tempo se parceiros puderem reenviar por períodos longos.
Como evitar armadilhas de “transação distribuída”
Transações distribuídas soam confortantes: um grande commit através de serviços, filas e bancos. Na prática, muitas vezes não estão disponíveis, são lentas ou frágeis demais. Quando existe um salto de rede, você não pode assumir que tudo será comitado junto.
Uma armadilha comum é construir um fluxo que funciona só se cada passo der certo agora: salvar pedido, cobrar cartão, reservar estoque, enviar confirmação. Se a etapa 3 der timeout, ela falhou ou teve sucesso? Se você reexecutar, vai cobrar ou reservar duas vezes?
Duas abordagens práticas evitam isso:
- Outbox/inbox: grave uma intenção durável no seu banco (uma linha outbox) na mesma transação da mudança de estado, depois um worker envia a mensagem. No lado receptor, mantenha uma inbox chaveada por ID de mensagem para que o processamento seja seguro caso a mesma mensagem chegue de novo.
- Estilo saga com compensações: quebre o workflow em passos menores que completam independentemente. Se um passo posterior falhar, rode uma compensação (por exemplo, libere estoque ou cancele um pedido não pago) em vez de tentar desfazer o histórico.
Escolha um estilo por workflow e mantenha-o. Misturar “às vezes usamos outbox” com “às vezes assumimos sucesso síncrono” cria casos de borda difíceis de testar.
Uma regra simples ajuda: se você não consegue commitar de forma atômica através das fronteiras, projete para reenvios, duplicatas e atrasos.
Reconciliação: como sistemas reais se recuperam de divergências
Reconciliação é admitir uma verdade básica: quando seu app conversa com outros sistemas pela rede, vocês às vezes discordarão sobre o que aconteceu. Requisições dão timeout, callbacks chegam tarde e pessoas reenviam ações. Reconciliação é como detectar divergências e consertá‑las ao longo do tempo.
Trate sistemas externos como fontes de verdade independentes. Seu app mantém seu próprio registro interno, mas precisa comparar esse registro com o que parceiros, provedores e usuários realmente fizeram.
Mecanismos comuns de reconciliação
A maioria dos times usa um conjunto pequeno de ferramentas monótonas (monótono é bom): um worker que reexecuta ações pendentes e reconsulta status externo, uma varredura agendada por inconsistências e uma pequena ação administrativa para o suporte reenviar, cancelar ou marcar como revisado.
O que comparar e o que registrar
Reconciliação só funciona se você souber o que comparar: razão interna vs razão do provedor (pagamentos), estado do pedido vs estado do envio (fulfillment), estado da assinatura vs estado de cobrança.
Torne estados reparáveis. Em vez de pular direto de “created” para “completed”, use estados de espera como pending, on hold ou needs review. Isso permite dizer com segurança “não temos certeza ainda” e dá um lugar claro para a reconciliação pousar.
Capture uma trilha de auditoria pequena nas mudanças importantes:
- Quando você enviou uma requisição e quando ouviu algo por último
- IDs de correlação que ligam seu registro a um evento/referência externa
- O último status externo conhecido (e de onde veio)
- Um campo de motivo para overrides manuais (quem, o quê, por quê)
Exemplo: se seu app solicita uma etiqueta de envio e a rede cai, você pode ficar com “sem etiqueta” internamente enquanto a transportadora realmente criou uma. Um worker de reconciliação pode buscar pelo ID de correlação, descobrir que a etiqueta existe e mover o pedido adiante (ou marcar para revisão se os detalhes não baterem).
Passo a passo: projetando um fluxo que sobrevive a falhas de rede
Quando você assume que a rede vai falhar, o objetivo muda. Você não tenta fazer cada passo vencer de primeira. Você tenta fazer cada passo seguro para repetir e fácil de reparar.
Um fluxo prático
-
Escreva uma sentença que descreva a fronteira. Seja explícito sobre o que seu sistema possui (a fonte da verdade), o que ele espelha e o que apenas solicita a outros.
-
Liste modos de falha antes do caminho feliz. Ao mínimo: timeouts (você não sabe se funcionou), requisições duplicadas, sucesso parcial (um passo aconteceu, o próximo não) e eventos fora de ordem.
-
Escolha uma estratégia de idempotência para cada entrada. Para APIs síncronas, muitas vezes é uma chave de idempotência mais um resultado armazenado. Para mensagens/eventos, é geralmente um ID de mensagem único e um registro “já processei isso?”.
-
Persista a intenção, depois aja. Primeiro armazene algo durável como PaymentAttempt: pending ou ShipmentRequest: queued, então faça a chamada externa e depois grave o resultado. Retorne um ID de referência estável para que reenvios apontem para a mesma intenção em vez de criar outra.
-
Construa reconciliação e um caminho de reparo, e torne-os visíveis. Reconciliação pode ser um job que escaneia registros “pendentes há muito tempo” e re-verifica status. O caminho de reparo pode ser uma ação administrativa segura como “retry”, “cancel” ou “mark resolved”, com nota de auditoria. Adicione observabilidade básica: IDs de correlação, campos de status claros e algumas contagens (pendentes, reenvios, falhas).
Exemplo: se o checkout der timeout logo após chamar um provedor de pagamento, não adivinhe. Armazene a tentativa, retorne o ID da tentativa e permita que o usuário reenvie com a mesma chave de idempotência. Depois, a reconciliação pode confirmar se o provedor cobrou ou não e atualizar a tentativa sem cobrar em dobro.
Um cliente toca “Fazer pedido”. Seu serviço envia uma requisição de pagamento para um provedor, mas a rede é instável. O provedor tem sua própria verdade, e seu banco de dados tem a sua. Eles divergem a menos que você projete para isso.
O que acontece no lado de fora (eventos que você não controla)
Do seu ponto de vista, o exterior é um fluxo de mensagens que podem estar atrasadas, repetidas ou ausentes:
- “Enviar pedido” atinge sua API.
- Sua requisição de pagamento vai para o provedor.
- O provedor envia um webhook dizendo “authorized”.
- O provedor reenviar o webhook e manda o mesmo callback de novo.
- Seu cliente dá timeout e reenvia “Fazer pedido”.
Nenhuma dessas etapas garante “uma vez exatamente”. Elas só garantem “talvez”.
O que você guarda no lado de dentro (registros que você controla)
Dentro da sua fronteira, armazene fatos duráveis e o mínimo necessário para conectar eventos externos a esses fatos.
Quando o cliente cria o pedido, crie um registro order em um estado claro como pending_payment. Também crie um registro payment_attempt com uma referência única do provedor e um idempotency_key ligado à ação do cliente.
Se o cliente der timeout e reencaminhar, sua API não deve criar um segundo pedido. Deve procurar o idempotency_key e retornar o mesmo order_id e estado atual. Essa escolha única evita duplicatas quando a rede falha.
Agora o webhook chega duas vezes. O primeiro callback atualiza payment_attempt para authorized e move o pedido para paid. O segundo callback aciona o mesmo handler, mas você detecta que já processou aquele evento do provedor (armazenando o ID do evento do provedor, ou checando o estado atual) e não faz nada. Você ainda pode responder 200 OK, porque o resultado já é verdadeiro.
Por fim, a reconciliação lida com os casos bagunçados. Se o pedido continua pending_payment após um certo tempo, um job background consulta o provedor usando a referência armazenada. Se o provedor disser “authorized” mas você perdeu o webhook, atualize seus registros. Se o provedor disser “failed” mas você marcou como pago, sinalize para revisão ou dispare uma ação compensatória como reembolso.
Erros comuns que causam duplicatas e estados travados
A maioria dos registros duplicados e workflows “travados” vem de confundir o que aconteceu fora do seu sistema (uma requisição chegou, uma mensagem foi recebida) com o que você cometeu com segurança dentro do seu sistema.
Uma falha clássica: um cliente envia “fazer pedido”, seu servidor começa a trabalhar, a rede cai e o cliente reenvia. Se você tratar cada reenvio como uma verdade nova, terá cobranças duplicadas, pedidos duplicados ou múltiplos e-mails.
Causas usuais:
- Confiar na requisição recebida cedo demais: enviar emails ou registrar “pedido criado” antes do commit durável no banco.
- Reenvios que criam novas linhas: gerar um novo order ID a cada tentativa em vez de mapear reenvios para um mesmo resultado.
- Assumir entrega “uma vez”: filas e callbacks não prometem isso. Duplicatas, atrasos e reordenações acontecem.
- Sem identificadores estáveis: se você não consegue responder “já vi essa intenção antes?”, não evita duplicatas.
- Apenas sucesso/falha, sem estado intermediário: sem estados pendentes, timeouts viram mistério e usuários clicam de novo.
Um problema que piora tudo: sem trilha de auditoria. Se você sobrescrever campos e manter só o estado mais recente, perde as evidências necessárias para reconciliar depois.
Um bom teste de sanidade é: “Se eu rodar esse handler duas vezes, eu obtenho o mesmo resultado?” Se a resposta for não, duplicatas não são um caso raro. Elas são garantidas.
Checklist rápido e próximos passos práticos
Se lembrar de uma coisa: seu app deve permanecer correto mesmo quando mensagens chegam atrasadas, chegam duas vezes ou nunca chegam.
Use este checklist para identificar pontos fracos antes que virem registros duplicados, atualizações perdidas ou fluxos travados:
- Fonte da verdade explícita: para cada workflow, você aponta um lugar que é “a verdade” (geralmente seu banco).
- Cada escrita pode ser reexecutada com segurança: cada comando/chamada API tem uma chave de idempotência (ou uma chave natural única).
- IDs estáveis e IDs de correlação fim a fim: você consegue traçar uma ação de negócio através de logs, tabelas e callbacks.
- Reconciliação roda automaticamente: você regularmente compara “o que acreditamos” vs “o que aconteceu” e repara ou dispara um alerta claro.
- Rollback não corrompe estado: mudanças de estado são auditáveis e compatíveis entre versões.
Se você não consegue responder uma dessas rapidamente, isso é útil. Geralmente significa que uma fronteira está nebulosa ou uma transição de estado falta.
Próximos passos práticos:
-
Esboce fronteiras e estados primeiro. Defina um pequeno conjunto de estados por workflow (por exemplo: Created, PaymentPending, Paid, FulfillmentPending, Completed, Failed).
-
Adicione idempotência onde mais importa. Comece pelas escritas de maior risco: criar pedido, capturar pagamento, emitir reembolso. Armazene chaves de idempotência no PostgreSQL com uma constraint única para que duplicatas sejam rejeitadas com segurança.
-
Trate reconciliação como um recurso normal. Agende um job que procure por registros “pendentes há muito tempo”, cheque sistemas externos novamente e repare o estado local.
-
Itere com segurança. Ajuste transições e regras de reenvio, então teste re-enviando deliberadamente a mesma requisição e re-processando o mesmo evento.
Se você está construindo rápido numa plataforma orientada por chat como Koder.ai (koder.ai), vale a pena incorporar essas regras desde cedo: a velocidade vem da automação, mas a confiabilidade vem de limites claros, handlers idempotentes e reconciliação.