Uma ferramenta de observabilidade ajuda a responder perguntas específicas sobre um sistema — tipicamente mostrando gráficos, logs ou o resultado de uma query. É algo que você “usa” quando há um problema.
Uma plataforma de observabilidade é mais ampla: ela padroniza como a telemetria é coletada, como as equipes a exploram e como incidentes são tratados de ponta a ponta. Torna-se algo que sua organização “executa” todos os dias, em muitos serviços e equipes.
De gráficos para resultados
A maioria das equipes começa com dashboards: gráficos de CPU, taxas de erro, talvez algumas buscas de logs. Isso é útil, mas o objetivo real não são gráficos mais bonitos — é detecção mais rápida e resolução mais rápida.
Uma mudança para plataforma acontece quando você para de perguntar “Dá pra fazer um gráfico disso?” e começa a perguntar:
- O engenheiro on-call encontra a causa raiz em minutos, não horas?
- Podemos encaminhar o alerta certo automaticamente para a equipe certa?
- Conseguimos transformar padrões repetidos de incidentes em playbooks repetíveis?
Essas são perguntas focadas em resultado, e exigem mais do que visualização. Exigem padrões de dados compartilhados, integrações consistentes e workflows que conectem telemetria à ação.
Os três pilares que você realmente está comprando
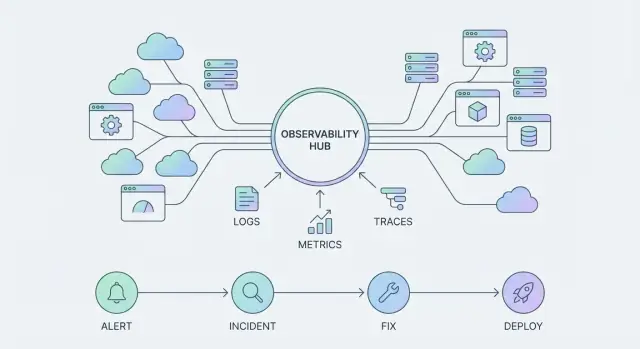
À medida que plataformas como a plataforma de observabilidade Datadog evoluem, a “superfície do produto” não são apenas dashboards. São três pilares interligados:
- Telemetria: logs, métricas e traces coletados de forma consistente e bem rotulados para serem confiáveis.
- Integrações: conexões pré-construídas que facilitam a adoção e ampliam a cobertura sem cola personalizada.
- Workflows: resposta a incidentes, roteamento de alertas, ownership e follow-up — para que o aprendizado se acumule.
Um único dashboard pode ajudar uma única equipe. Uma plataforma fica mais forte a cada serviço onboarded, a cada integração adicionada e a cada workflow padronizado. Com o tempo, isso se compõe em menos pontos cegos, menos ferramentas duplicadas e incidentes mais curtos — porque toda melhoria se torna reutilizável, não pontual.
Telemetria se Torna a Superfície do Produto
Quando a observabilidade muda de “uma ferramenta que consultamos” para “uma plataforma que construímos”, a telemetria deixa de ser mero resíduo e começa a agir como superfície do produto. O que você escolhe emitir — e com que consistência — determina o que suas equipes podem ver, automatizar e confiar.
Os tipos de telemetria core (e para que servem)
A maioria das equipes padroniza em um pequeno conjunto de sinais:
- Métricas: tendências numéricas ao longo do tempo (latência, taxa de erro, saturação).
- Logs: registros detalhados e legíveis por humanos para investigação e auditoria.
- Traces: caminhos de requisição entre serviços para encontrar onde o tempo e as falhas acontecem.
- Eventos: registros discretos de “algo mudou” (deploys, feature flags, incidentes).
- Profiles: comportamento de CPU/memória para apontar caminhos de código caros.
Individualmente, cada sinal é útil. Juntos, eles se tornam uma interface única para seus sistemas — o que você vê em dashboards, alertas, timelines de incidentes e postmortems.
Consistência vence volume
Um modo comum de falha é coletar “tudo” mas nomear de forma inconsistente. Se um serviço usa userId, outro usa uid e um terceiro não loga nada, você não consegue fatiar dados de forma confiável, juntar sinais ou construir monitores reutilizáveis.
As equipes extraem mais valor concordando em algumas convenções — nomes de serviço, tags de ambiente, IDs de requisição e um conjunto padrão de atributos — do que dobrando o volume de ingestão.
O que alta cardinalidade realmente significa (e por que importa)
Campos de alta cardinalidade são atributos com muitos valores possíveis (como user_id, order_id ou session_id). Eles são poderosos para depurar problemas que “acontecem só com um cliente”, mas também podem aumentar custo e deixar queries mais lentas se usados em todo lugar.
A abordagem de plataforma é intencional: mantenha alta cardinalidade onde agrega valor investigativo claro e evite-a em lugares destinados a agregados globais.
Contexto unificado reduz trabalho de correlação
O ganho é velocidade. Quando métricas, logs, traces, eventos e profiles compartilham o mesmo contexto (service, version, region, request ID), os engenheiros gastam menos tempo costurando evidências e mais tempo consertando o problema real. Em vez de pular entre ferramentas e chutar hipóteses, você segue um fio único do sintoma até a causa raiz.
De Coleta de Dados para Estratégia de Telemetria
A maioria das equipes começa com “colocar dados pra dentro”. Isso é necessário, mas não é uma estratégia. Uma estratégia de telemetria é o que mantém o onboarding rápido e torna seus dados consistentes o suficiente para alimentar dashboards compartilhados, alertas confiáveis e SLOs significativos.
Caminhos comuns de ingestão (e para que servem)
Datadog normalmente recebe telemetria por algumas rotas práticas:
- Agentes em hosts/VMs: a forma mais rápida de coletar métricas de infraestrutura, logs e APM com mudanças mínimas de código.
- Collectors e gateways (ex.: OpenTelemetry Collector): útil quando você quer controle central, roteamento para múltiplos destinos, redaction ou processamento padrão.
- APIs e SDKs diretos: úteis para eventos customizados, métricas de negócio ou quando um agente não é viável.
- Integrações serverless: convenientes para runtimes gerenciados onde você não controla o host subjacente, mas é preciso deliberar sobre o que emitir.
Velocidade vs. padronização: decida o que otimizar
No começo, velocidade vence: equipes instalam um agente, ativam algumas integrações e veem valor imediato. O risco é que cada equipe invente suas próprias tags, nomes de serviço e formatos de log — tornando as visões cross-service bagunçadas e os alertas difíceis de confiar.
Uma regra simples: permita onboarding rápido, mas exija padronização em 30 dias. Isso dá impulso às equipes sem travar uma bagunça.
Uma convenção leve de naming e tagging
Você não precisa de uma taxonomia enorme. Comece com um conjunto pequeno que todo sinal (logs, métricas, traces) deve carregar:
service: curto, estável, em minúsculas (ex.: checkout-api)env: prod, staging, devteam: identificador da equipe responsável (ex.: payments)version: versão do deploy ou SHA do git
Se quiser um extra que paga rápido, adicione tier (frontend, backend, data) para simplificar filtros.
Amostragem, retenção e defaults conscientes de custo
Problemas de custo geralmente vêm de defaults generosos demais:
- Traces: comece com amostragem head-based para endpoints de alto volume; mantenha 100% para fluxos críticos.
- Logs: padrão para “erro + eventos de negócio importantes”, depois adicione info/debug seletivamente com retenção por tempo limitada.
- Retenção: mantenha dados de alta resolução por menos tempo (dias), agregue ou retenha agregados-chave por mais tempo (semanas/meses).
O objetivo não é coletar menos — é coletar os dados certos de forma consistente, para que você possa escalar uso sem surpresas.
Integrações como o Verdadeiro Canal de Distribuição
A maioria das pessoas pensa em ferramentas de observabilidade como “algo que você instala”. Na prática, elas se espalham numa organização do modo que bons conectores se espalham: uma integração de cada vez.
O que uma “integração” realmente significa
Uma integração não é só um cano de dados. Costuma ter três partes:
- Fontes de dados: puxando métricas, logs, traces, eventos e topologia dos sistemas que você já roda (serviços em nuvem, Kubernetes, bancos, CI/CD, SaaS).
- Enriquecimento: adicionando contexto para que a telemetria seja imediatamente utilizável — nomes de serviço, ambientes, tags de ownership, versões de deploy e metadados de nuvem.
- Ações: fazer algo com o que você aprendeu — criar tickets, paginar on-call, anotar deploys, escalar recursos ou disparar runbooks.
Essa última parte é o que transforma integrações em distribuição. Se a ferramenta só lê, é um destino de dashboard. Se ela também escreve, vira parte do trabalho diário.
Por que integrações aceleram a adoção
Boas integrações reduzem o tempo de setup porque vêm com defaults sensatos: dashboards pré-construídos, monitores recomendados, regras de parsing e tags comuns. Em vez de cada equipe inventar seu próprio “dashboard de CPU” ou “alertas do Postgres”, você obtém um ponto de partida padrão que segue boas práticas.
As equipes personalizam — mas partindo de uma base compartilhada. Essa padronização importa quando você consolida ferramentas: integrações criam padrões repetíveis que novos serviços podem copiar, mantendo o crescimento gerenciável.
Priorize integrações bidirecionais
Ao avaliar opções, pergunte: ela pode ingerir sinais e tomar ações? Exemplos incluem abrir incidentes no seu sistema de tickets, atualizar canais de incidente ou anexar link de trace de volta em um PR ou vista de deploy. Configurações bidirecionais são onde os workflows começam a parecer “nativos”.
Um método simples de shortlist
Comece pequeno e previsível:
- Infra crítica primeiro (provedor de nuvem, Kubernetes, balanceadores, bancos centrais).
- Depois pipeline de deploy (CI/CD, feature flags, rastreamento de releases) para alinhar telemetria com mudanças.
- Adicione SaaS por equipe (filas, caches, auth, pagamentos) depois que tagging e convenções de ownership estiverem estáveis.
Regra prática: priorize integrações que melhoram imediatamente a resposta a incidentes, não as que apenas adicionam mais gráficos.
Visões Padrão: Serviços, Dashboards e Monitores
Visões padrão são onde uma plataforma de observabilidade se torna usável no dia a dia. Quando equipes compartilham o mesmo modelo mental — o que é um “serviço”, o que significa “saudável” e onde clicar primeiro — o debug fica mais rápido e os handoffs mais limpos.
Escolha um pequeno conjunto de “golden signals” e mapeie cada um para um dashboard concreto e reutilizável. Para a maioria dos serviços, isso é:
- Latência (p95/p99 para endpoints chave)
- Tráfego (requisições por segundo, jobs processados)
- Erros (taxa e principais tipos de erro)
- Saturação (CPU, memória, profundidade de fila, conexões DB)
A chave é consistência: um layout de dashboard que funciona entre serviços vence dez dashboards criativos e pontuais.
Catálogos de serviço criam ownership compartilhado
Um catálogo de serviços (mesmo leve) transforma “alguém deveria olhar isso” em “essa equipe é dona”. Quando serviços têm tags com donos, ambientes e dependências, a plataforma pode responder perguntas básicas instantaneamente: quais monitores se aplicam a este serviço? Que dashboards devo abrir? Quem é notificado?
Essa clareza reduz o ping-pong no Slack durante incidentes e ajuda novos engenheiros a se autoatender.
Blocos de construção que escalam
Trate estes como artefatos padrão, não extras opcionais:
- Dashboards para golden signals e dependências chave
- Monitores atrelados a SLOs ou sintomas que impactam usuário
- Notebooks para investigações e timelines de post-incident
- Runbooks (linkados de monitores) para os primeiros 5–10 minutos de resposta
Anti-padrões a evitar
Dashboards de vaidade (gráficos bonitos sem decisões por trás), alertas one-off (criados às pressas e nunca ajustados) e queries não documentadas (só uma pessoa entende o filtro mágico) criam ruído na plataforma. Se uma query importa, salve-a, nomeie-a e anexe-a a uma vista de serviço que outros possam encontrar.
Workflows: Onde Observabilidade Entrega Valor ao Negócio
Projete Primeiro o Fluxo de Trabalho
Use o modo de planejamento para mapear alerta, responsável e runbook antes de gerar qualquer código.
Observabilidade só vira “real” para o negócio quando encurta o tempo entre um problema e uma correção confiante. Isso acontece através de workflows — caminhos repetíveis que levam do sinal à ação, e da ação ao aprendizado.
A jornada do incidente: alerta → triagem → comunicar → mitigar → aprender
Um workflow escalável é mais que paginar alguém.
Um alerta deve abrir um loop de triagem focado: confirmar impacto, identificar o serviço afetado e puxar o contexto mais relevante (deploys recentes, saúde de dependências, picos de erro, sinais de saturação). A partir daí, a comunicação transforma um evento técnico em resposta coordenada — quem está com o incidente, o que os usuários estão vendo e quando será a próxima atualização.
Mitigação é onde você quer “ações seguras” à mão: feature flags, shift de tráfego, rollback, rate limits ou uma workaround conhecida. Finalmente, o aprendizado fecha o ciclo com uma revisão leve que captura o que mudou, o que funcionou e o que deve ser automatizado a seguir.
Ferramentas de incidente + ChatOps = colaboração, não heroísmos
Plataformas como a plataforma de observabilidade Datadog agregam valor quando suportam trabalho compartilhado: canais de incidente, atualizações de status, handoffs e timelines consistentes. Integrações ChatOps podem transformar alertas em conversas estruturadas — criando um incidente, atribuindo papéis e postando gráficos e queries chave direto no thread para que todos vejam a mesma evidência.
O que um bom runbook realmente contém
Um runbook útil é curto, opinativo e seguro. Deve incluir: o objetivo (restaurar o serviço), donos/rotações de on-call claras, checagens passo a passo, links para dashboards/monitores certos e “ações seguras” que reduzem risco (com passos de rollback). Se não é seguro executar às 3 da manhã, ele não está pronto.
Vincule incidentes a deploys e mudanças
A causa raiz aparece mais rápido quando incidentes são correlacionados automaticamente com deploys, mudanças de configuração e flips de feature flag. Faça “o que mudou?” uma vista de primeira classe para que a triagem comece com evidências, não com suposições.
SLOs e Error Budgets como Sistema Operacional da Equipe
O que é um SLO (e por que ele vence “dashboards verdes”)
Um SLO (Service Level Objective) é uma promessa simples sobre a experiência do usuário em uma janela de tempo — como “99.9% das requisições bem-sucedidas em 30 dias” ou “p95 dos carregamentos abaixo de 2s”.
Isso vence um “dashboard verde” porque dashboards frequentemente mostram saúde do sistema (CPU, memória, filas) em vez de impacto no cliente. Um serviço pode parecer verde e ainda falhar para usuários (por exemplo, uma dependência está com timeout, ou erros concentrados em uma região). SLOs forçam a equipe a medir o que o usuário realmente sente.
Um error budget é a quantidade permitida de indisponibilidade implícita no seu SLO. Se você promete 99.9% de sucesso em 30 dias, está “permitido” cerca de 43 minutos de erros nesse período.
Isso cria um sistema operacional prático para decisões:
- Budget saudável: entregue features, rode experimentos, aceite risco razoável.
- Budget queimando: desacelere releases, foque em trabalho de confiabilidade, reduza mudanças.
- Budget esgotado: pause deploys arriscados e corrija as principais fontes de falha.
Em vez de debater opiniões numa reunião de release, você debate um número que todos podem ver.
Alertar por burn rate, não por cada pico
Alertas de SLO funcionam melhor quando você alerta pelo burn rate (o quão rápido você está consumindo o budget), não por contagens brutas de erro. Isso reduz ruído:
- Um pico breve que se auto-recupera pode não pagar ninguém.
- Um problema sustentado que consumiria o budget em breve dispara um alerta claro e acionável.
Muitas equipes usam duas janelas: um fast burn (pagina rápido) e um slow burn (ticket/notificação).
Conjunto inicial leve de SLOs para um serviço web típico
Comece pequeno — dois a quatro SLOs que você vai realmente usar:
- Disponibilidade: % de requisições bem-sucedidas (ex.: HTTP 2xx/3xx) em 30 dias.
- Latência: p95 de requisição abaixo de um limiar (separe read vs write se necessário).
- Checkout / endpoint crítico: taxa de sucesso para o caminho único que mais importa ao negócio.
- Freshness (se aplicável): jobs em background completam dentro de X minutos.
Uma vez estáveis, expanda — caso contrário você só vai construir mais uma parede de dashboards. Para mais, veja /blog/slo-monitoring-basics.
Alertas que Escalam Sem Queimar Pessoas
Destaque os SLOs
Prototipe um painel de SLO que destaque a taxa de queima e mantenha os alertas vinculados ao impacto no usuário.
Alertas é onde muitos programas de observabilidade emperram: os dados estão lá, os dashboards ficam ótimos, mas a experiência de on-call vira barulhenta e não confiável. Se as pessoas aprendem a ignorar alertas, sua plataforma perde capacidade de proteger o negócio.
Por que fadiga de alertas acontece (e por que sinais se duplicam)
As causas mais comuns são surpreendentemente consistentes:
- Muitos alertas “FYI” que não exigem ação.
- Thresholds copiados entre serviços sem contexto (mesma regra de CPU para workloads muito diferentes).
- Múltiplas ferramentas ou equipes alertando sobre o mesmo sintoma — por exemplo, um monitor APM de taxa de erro e um monitor baseado em logs ambos paginando pelo mesmo incidente.
- Métricas barulhentas (percentis de latência muito oscilantes, efeitos de autoscaling) que disparam flutuações em vez de problemas reais.
Em termos práticos, sinais duplicados aparecem quando monitores são criados a partir de diferentes “superfícies” (métricas, logs, traces) sem decidir qual é o canônico para paginação.
Roteamento: ownership, severidade e horários silenciosos
Escalar alertas começa com regras de roteamento que façam sentido para humanos:
- Ownership: todo monitor deve ter um dono claro (serviço/equipe) e um caminho de escalonamento.
- Severidade: reserve paginação para problemas urgentes que afetam usuários; use tickets ou notificações em chat para menor severidade.
- Janelas de manutenção: deploys planejados, migrações e testes de carga não devem gerar páginas.
Regras simples que mantêm alertas acionáveis
Um default útil é: alerte em sintomas, não em cada variação de métrica. Page em coisas que usuários sentem (taxa de erro, checkouts falhos, latência sustentada, consumo de SLO), não em “entradas” (CPU, contagem de pods) a menos que prevejam impacto.
Cadência de revisão que realmente funciona
Torne higiene de alertas parte da operação: poda mensal e ajuste de monitores. Remova monitores que nunca disparam, ajuste thresholds que disparam demais e una duplicatas para que cada incidente tenha uma página primária e contexto de suporte.
Feito direito, alertas viram um workflow confiável — não um gerador de ruído de fundo.
Chamar observabilidade de “plataforma” não é só ter logs, métricas, traces e muitas integrações num mesmo lugar. Implica também governança: consistência e guardrails que mantêm o sistema usável quando o número de equipes, serviços, dashboards e alertas se multiplica.
Sem governança, Datadog (ou qualquer plataforma) pode derivar para um scrapbook barulhento — centenas de dashboards ligeiramente diferentes, tags inconsistentes, ownership pouco claro e alertas que ninguém confia.
Governança é problema de pessoas e processos
Boa governança esclarece quem decide o quê e quem é responsável quando a plataforma fica bagunçada:
- Time de plataforma: define padrões (tagging, naming, templates), fornece componentes compartilhados e mantém integrações.
- Donos de serviço: são responsáveis pela qualidade da telemetria de seus serviços e por manter monitores relevantes.
- Segurança e conformidade: define regras de tratamento de dados (PII, retenção, limites de acesso) e revisa integrações de alto risco.
- Liderança: alinha governança com prioridades do negócio (metas de confiabilidade, expectativas de resposta) e financia o trabalho.
Controles práticos que impedem o “sprawl” de observabilidade
Alguns controles leves valem mais que longos manuais:
- Templates por padrão: dashboards e packs de monitor para cada tipo de serviço (API, worker, banco) para começar consistente.
- Política de tagging: conjunto pequeno obrigatório (ex.:
service, env, team, tier) e regras claras para tags opcionais. Aplique em CI quando possível.
- Acesso e ownership: use RBAC para dados sensíveis e exija um dono para dashboards e monitores.
- Fluxos de aprovação para mudanças de alto impacto: monitores que paginam, pipelines de logs que afetam custo e integrações que puxam dados sensíveis devem ter revisão.
Reuso vence reinvenção
A forma mais rápida de escalar qualidade é compartilhar o que funciona:
- Bibliotecas compartilhadas: pacotes internos ou snippets que padronizam campos de log, atributos de trace e métricas comuns.
- Dashboards e monitores reutilizáveis: um catálogo central de dashboards “golden” e templates que as equipes podem clonar e adaptar.
- Padrões versionados: trate ativos chave como código — documente mudanças, depreque padrões antigos e anuncie atualizações num único lugar.
Se quiser que isso pegue, torne o caminho governado o caminho fácil — menos cliques, setup mais rápido e ownership claro.
Quando observabilidade se comporta como plataforma, ela tende a seguir economia de plataformas: quanto mais equipes adotam, mais telemetria é produzida e mais útil ela fica.
Isso cria um flywheel:
- Mais serviços onboarded → melhor visibilidade cross-service e correlação
- Melhor visibilidade → diagnóstico mais rápido, menos incidentes repetidos, mais confiança na ferramenta
- Mais confiança → mais equipes instrumentam e integram → ainda mais dados
O porém é que o mesmo loop também aumenta custo. Mais hosts, containers, logs, traces, synthetics e métricas customizadas podem crescer mais rápido que seu orçamento se você não gerenciar deliberadamente.
Alavancas práticas de custo (sem matar sinal)
Você não precisa “desligar tudo”. Comece modelando os dados:
- Amostragem: mantenha traces de alta fidelidade para endpoints críticos, amostre mais agressivamente no resto.
- Camadas de retenção: retenção curta para logs brutos de alto volume; retenção longa para streams de segurança/auditoria curados.
- Filtragem e parsing de logs: descarte ruído óbvio cedo (health checks, requisições a assets) e padronize parsing para roteamento por atributos.
- Agregação de métricas: prefira percentis, taxas e rollups ao invés de cardinalidade ilimitada (ex.: por ID de usuário).
KPIs que conectam custo a resultados
Acompanhe um conjunto pequeno de métricas que mostrem se a plataforma está pagando de volta:
- MTTD (mean time to detect)
- MTTR (mean time to resolve)
- Contagem de incidentes e incidentes repetidos (mesma causa raiz)
- Frequência de deploy (e taxa de falha de mudanças, se você rastrear)
Rodando uma revisão trimestral “valor vs custo” (sem culpa)
Faça disso uma revisão de produto, não uma auditoria. Traga donos de plataforma, algumas equipes de serviço e finanças. Reveja:
- Principais drivers de custo por tipo de dado (logs/métricas/traces) e por equipe
- Principais ganhos: incidentes encurtados, outages evitados, toil removido
- 2–3 ações acordadas (ex.: ajustar regras de amostragem, adicionar camadas de retenção, consertar integração barulhenta)
O objetivo é ownership compartilhado: custo vira insumo para decisões de instrumentação melhores, não razão para parar de observar.
O que Isso Significa para Sua Pilha de Ferramentas de Observabilidade
Padronize Tags Sem Atrito
Crie uma interface de verificação de regras de tags para ajudar as equipes a padronizar serviço, ambiente, time e versão.
Se observabilidade está virando uma plataforma, sua “pilha de ferramentas” deixa de ser um conjunto de soluções pontuais e passa a agir como infraestrutura compartilhada. Essa mudança faz com que o sprawl de ferramentas seja mais que um incômodo: cria instrumentação duplicada, definições inconsistentes (o que conta como erro?) e mais carga de on-call porque sinais não se alinham entre logs, métricas, traces e incidentes.
Consolidar não significa por padrão “um vendor para tudo”. Significa menos sistemas de registro para telemetria e resposta, ownership mais claro e um número menor de lugares que as pessoas precisam olhar durante um outage.
O que a consolidação pode realmente resolver
O sprawl de ferramentas costuma esconder custos em três lugares: tempo gasto pulando entre UIs, integrações frágeis que você precisa manter e governança fragmentada (naming, tags, retenção, acesso).
Uma abordagem mais consolidada pode reduzir troca de contexto, padronizar vistas de serviço e tornar workflows de incidente repetíveis.
Checklist de decisão (rápido, mas prático)
Ao avaliar sua pilha (incluindo Datadog ou alternativas), pressione nestes pontos:
- Integrações obrigatórias: provedor de nuvem, Kubernetes, CI/CD, gerenciamento de incidentes, paginação e stores de dados essenciais — mais quaisquer sistemas do negócio sem os quais você não pode entregar.
- Workflows: dá para ir de alert → owner → runbook → timeline → postmortem sem copiar/colar?
- Governança: padrões de tagging, controles de acesso, retenção e guardrails contra sprawl de dashboards/monitores.
- Modelo de preço: o que impulsiona custo (hosts, containers, logs ingeridos, traces indexados)? Dá para prever crescimento sem surpresas?
Escolha um ou dois serviços com tráfego real. Defina uma métrica de sucesso única como “tempo para identificar causa raiz caiu de 30 minutos para 10” ou “reduzir alertas ruidosos em 40%.” Instrumente apenas o necessário e revise os resultados após duas semanas.
Centralize docs internas para que o aprendizado se some — linke o runbook do piloto, regras de tagging e dashboards em um lugar (por exemplo, /blog/observability-basics como ponto de partida interno).
Um Plano de Adoção Prático que Você Pode Copiar
Você não “rola Datadog” de uma vez. Comece pequeno, defina padrões cedo e então escale o que funciona.
Implantação 30/60/90 dias
Dias 0–30: Onboard (provar valor rápido)
Escolha 1–2 serviços críticos e uma jornada customer-facing. Instrumente logs, métricas e traces de forma consistente e conecte as integrações que vocês já usam (nuvem, Kubernetes, CI/CD, on-call).
Dias 31–60: Padronizar (tornar repetível)
Transforme o que aprendeu em defaults: nomeação de serviço, tagging, templates de dashboard, nomes de monitores e ownership. Crie vistas dos “golden signals” (latência, tráfego, erros, saturação) e um conjunto mínimo de SLOs para os endpoints mais importantes.
Dias 61–90: Escalar (expandir sem caos)
Onboard de times adicionais usando os mesmos templates. Introduza governança (regras de tags, metadata obrigatória, processo de revisão para novos monitores) e comece a rastrear custo vs uso para manter a plataforma saudável.
Onde o Koder.ai se encaixa (pragmaticamente)
Quando você trata observabilidade como plataforma, normalmente acaba querendo pequenos apps "cola": uma UI de catálogo de serviços, um hub de runbooks, página de timeline de incidentes ou um portal interno que ligue donos → dashboards → SLOs → playbooks.
Isso é o tipo de tooling interno leve que dá para construir rápido com Koder.ai — uma plataforma de vibe-coding que gera apps via chat (comum: React frontend, Go + PostgreSQL backend), com exportação de código e suporte a deploy/hosting. Na prática, times usam para prototipar e entregar superfícies operacionais que facilitam governança e workflows sem puxar um time de produto inteiro do roadmap.
Vitórias rápidas para entregar na primeira semana
- Top 10 monitores para disponibilidade, taxa de erro, latência, saturação e dependências chave
- Marcadores de deploy (do CI/CD) em dashboards e traces para correlação imediata com mudanças
- Template de incidente: o que aconteceu, impacto, timeline, donos, links para dashboards/queries, próximas ações
Treinamento que realmente fica
Faça duas sessões de 45 minutos: (1) “Como consultamos aqui” com padrões de query compartilhados (por serviço, env, região, versão), e (2) “Playbook de troubleshooting” com fluxo simples: confirmar impacto → checar marcadores de deploy → estreitar para o serviço → inspecionar traces → conferir saúde de dependências → decidir rollback/mitigação.
Checklist copy/paste