Por que Patterson e o RISC ainda importam
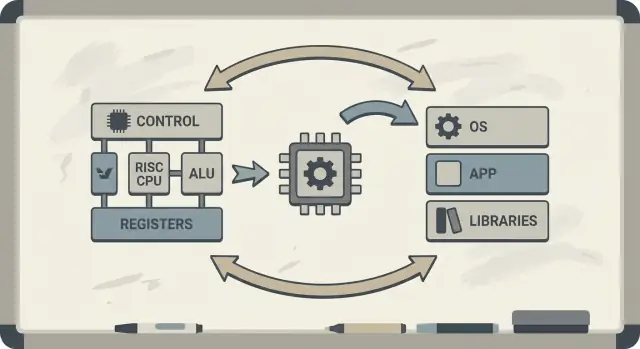
David Patterson é frequentemente introduzido como “um pioneiro do RISC”, mas sua influência duradoura é mais ampla do que qualquer projeto de CPU isolado. Ele ajudou a popularizar uma maneira prática de pensar sobre computadores: trate o desempenho como algo que você pode medir, simplificar e melhorar de ponta a ponta — desde as instruções que um chip entende até as ferramentas de software que geram essas instruções.
“Pensamento RISC” em termos simples
RISC (Reduced Instruction Set Computing) é a ideia de que um processador pode rodar mais rápido e de forma mais previsível quando foca em um conjunto menor de instruções simples. Em vez de construir um grande menu de operações complicadas em hardware, faz-se com que as operações comuns sejam rápidas, regulares e fáceis de pipelinear. O ganho não é “menos capacidade” — é que blocos simples, executados eficientemente, muitas vezes vencem em cargas de trabalho reais.
Co-design: chips e código melhorando um ao outro
Patterson também defendeu o co-design hardware–software: um ciclo de feedback onde arquitetos de chip, escritores de compilador e designers de sistema iteram juntos.
Se um processador é projetado para executar padrões simples bem, os compiladores podem produzir esses padrões de forma confiável. Se os compiladores revelam que programas reais gastam tempo em certas operações (como acesso à memória), o hardware pode ser ajustado para lidar melhor com esses casos. É por isso que discussões sobre uma arquitetura de conjunto de instruções (ISA) naturalmente se conectam a otimizações de compilador, cache e pipeline.
Você vai aprender por que ideias RISC se conectam ao desempenho por watt (não apenas à velocidade bruta), como a “previsibilidade” torna CPUs modernas e chips móveis mais eficientes, e como esses princípios aparecem nos dispositivos de hoje — de laptops a servidores em nuvem.
Se quiser um mapa dos conceitos-chave antes de se aprofundar, pule para /blog/key-takeaways-and-next-steps.
O problema ao qual o RISC respondeu
Os primeiros microprocessadores foram construídos sob restrições severas: chips tinham espaço limitado para circuitos, memória era cara e armazenamento era lento. Designers tentavam lançar computadores acessíveis e “rápidos o suficiente”, muitas vezes com caches pequenos (ou nenhum), velocidades de clock modestas e memória principal muito limitada em comparação com o que o software desejava.
A aposta antiga: instruções complexas = programas mais rápidos
Uma ideia popular na época era que, se a CPU oferecesse instruções de alto nível mais poderosas — capazes de fazer múltiplas etapas de uma vez — os programas rodariam mais rápido e seriam mais fáceis de escrever. Se uma instrução pudesse “fazer o trabalho de várias”, pensava-se, seriam necessárias menos instruções no total, economizando tempo e memória.
Essa é a intuição por trás de muitos designs CISC (Complex Instruction Set Computing): dar aos programadores e compiladores uma grande caixa de ferramentas com operações sofisticadas.
O descompasso: o que as CPUs ofereciam vs. o que era realmente usado
O problema era que programas reais (e os compiladores que os traduzem) não aproveitavam essa complexidade de forma consistente. Muitas das instruções mais elaboradas eram raramente usadas, enquanto um pequeno conjunto de operações simples — carregar dados, armazenar dados, somar, comparar, desviar — apareciam repetidas vezes.
Ao mesmo tempo, suportar um grande menu de instruções complexas tornava as CPUs mais difíceis de construir e mais lentas para otimizar. A complexidade consumia área do chip e esforço de projeto que poderiam ter sido usados para tornar as operações comuns rápidas e previsíveis.
RISC foi uma resposta a essa lacuna: foque a CPU no que o software realmente faz na maior parte do tempo, e faça esses caminhos rápidos — então deixe os compiladores fazerem mais do trabalho de “orquestração” de maneira sistemática.
RISC vs CISC: a ideia em linguagem simples
Uma maneira simples de pensar em CISC vs RISC é comparar kits de ferramentas.
CISC (Complex Instruction Set Computing) é como uma oficina cheia de muitas ferramentas especializadas e sofisticadas — cada uma pode fazer muito em um só movimento. Uma única “instrução” pode carregar dados da memória, fazer um cálculo e armazenar o resultado, tudo embalado junto.
RISC (Reduced Instruction Set Computing) é como carregar um conjunto menor de ferramentas confiáveis que você usa constantemente — martelo, chave de fenda, fita métrica — e construir tudo a partir de passos repetíveis. Cada instrução tende a fazer um trabalho pequeno e claro.
Por que “mais simples” pode ser mais rápido
Quando as instruções são mais simples e uniformes, a CPU pode executá-las com uma linha de montagem mais limpa (um pipeline). Essa linha de montagem é mais fácil de projetar, mais fácil de rodar em clocks mais altos e mais fácil de manter ocupada.
Com instruções estilo CISC “faça-muito”, a CPU frequentemente precisa decodificar e quebrar uma instrução complexa em passos internos menores de qualquer forma. Isso pode adicionar complexidade e dificultar manter o pipeline fluindo suavemente.
A previsibilidade importa
RISC busca tempo de instrução previsível — muitas instruções levam aproximadamente o mesmo tempo. A previsibilidade ajuda a CPU a agendar trabalho de forma eficiente e ajuda os compiladores a gerar código que mantenha o pipeline alimentado em vez de provocar stalls.
As concessões (e por que muitas vezes valem a pena)
RISC geralmente precisa de mais instruções para fazer a mesma tarefa. Isso pode significar:
- Tamanho de programa ligeiramente maior (mais bytes de código)
- Mais buscas de instrução na memória
Mas isso ainda pode ser um bom negócio se cada instrução for rápida, o pipeline permanecer suave e o design geral for mais simples.
Na prática, compiladores bem otimizados e bom caching podem compensar a desvantagem de “mais instruções” — e a CPU pode gastar mais tempo fazendo trabalho útil e menos tempo desembaraçando instruções complicadas.
Berkeley RISC e a mentalidade “meça, depois projete”
Berkeley RISC não foi apenas uma nova ISA. Foi uma atitude de pesquisa: não comece pelo que parece elegante no papel — comece pelo que os programas realmente fazem e então molde a CPU em torno dessa realidade.
Núcleo pequeno e rápido + compilador inteligente
Em nível conceitual, a equipe de Berkeley buscava um núcleo de CPU simples o bastante para rodar muito rápido e de forma previsível. Em vez de encher o hardware com muitas “truques” de instrução complicados, confiaram no compilador para fazer mais trabalho: escolher instruções diretas, escaloná-las bem e manter dados em registradores tanto quanto possível.
Essa divisão de responsabilidades importava. Um núcleo menor e mais limpo é mais fácil de pipelinear efetivamente, mais fácil de entender e frequentemente mais rápido por transistor. O compilador, vendo o programa inteiro, pode planejar com antecedência de maneiras que o hardware não consegue fazer facilmente em tempo de execução.
Meça workloads reais, não suposições
David Patterson enfatizou a medição porque o projeto de computadores está cheio de mitos tentadores — recursos que soam úteis, mas raramente aparecem em código real. Berkeley RISC promoveu o uso de benchmarks e traces de workload para encontrar os caminhos quentes: loops, chamadas de função e acessos à memória que dominam o tempo de execução.
Isso se liga diretamente ao princípio “faça o caso comum rápido”. Se a maioria das instruções são operações simples e loads/stores, então otimizar esses casos frequentes traz mais retorno do que acelerar instruções complexas e raras.
A lição duradoura é que RISC foi tanto uma arquitetura quanto uma mentalidade: simplifique o que é frequente, valide com dados e trate hardware e software como um único sistema que pode ser afinado conjuntamente.
O que significa co-design hardware–software
Co-design hardware–software é a ideia de que você não projeta uma CPU isoladamente. Você projeta o chip e o compilador (e às vezes o sistema operacional) com atenção mútua, de modo que programas reais rodem rápido e eficientemente — não apenas sequências sintéticas de instruções no “melhor caso”.
Um loop de feedback simples
Co-design funciona como um ciclo de engenharia:
-
Escolhas de ISA: a arquitetura decide o que a CPU pode expressar facilmente (por exemplo, acesso à memória por “load/store”, muitos registradores, modos de endereçamento simples).
-
Estratégias de compilador: o compilador se adapta — mantendo variáveis quentes em registradores, reordenando instruções para evitar stalls e escolhendo convenções de chamada que reduzem overhead.
-
Resultados de workload: você mede programas reais (compiladores, bancos de dados, gráficos, código de SO) e vê onde tempo e energia são gastos.
-
Próximo design: você ajusta a ISA e a microarquitetura (profundidade do pipeline, número de registradores, tamanhos de cache) com base nessas medições.
Aqui está um pequeno loop (C) que destaca a relação:
for (int i = 0; i < n; i++)
sum += a[i];
Em uma ISA estilo RISC, o compilador tipicamente mantém sum e i em registradores, usa instruções simples de load para a[i] e realiza instruction scheduling para que a CPU permaneça ocupada enquanto um load está em voo.
Por que ignorar o compilador desperdiça silício e energia
Se um chip adiciona instruções complexas ou hardware especial que compiladores raramente usam, essa área ainda consome energia e esforço de projeto. Enquanto isso, as coisas “chatas” nas quais os compiladores dependem — registradores suficientes, pipelines previsíveis, convenções de chamada eficientes — podem ficar subfinanciadas.
O pensamento RISC de Patterson enfatizou gastar silício onde o software real realmente pode se beneficiar.
Pipelines, previsibilidade e ajuda do compilador
Escolha o plano certo
Compare Free, Pro, Business e Enterprise para corresponder à sua forma de construir e entregar.
Uma ideia-chave do RISC foi tornar a “linha de montagem” da CPU mais fácil de manter ocupada. Essa linha é o pipeline: em vez de terminar uma instrução completamente antes de começar a próxima, o processador divide o trabalho em estágios (fetch, decode, execute, write-back) e os sobrepõe. Quando tudo flui, você conclui quase uma instrução por ciclo — como carros passando por várias estações de uma fábrica.
Por que instruções mais simples mantêm a linha em movimento
Pipelines funcionam melhor quando cada item na linha é semelhante. Instruções RISC foram projetadas para ser relativamente uniformes e previsíveis (frequentemente de comprimento fixo, com endereçamento simples). Isso reduz “casos especiais” onde uma instrução precisa de tempo extra ou recursos incomuns.
Quando o pipeline precisa pausar: hazards e stalls
Programas reais não são perfeitamente suaves. Às vezes uma instrução depende do resultado de uma anterior (você não pode usar um valor antes que ele seja calculado). Outras vezes, a CPU precisa esperar por dados da memória, ou ainda não sabe qual caminho um branch tomará.
Essas situações causam stalls — pausas breves onde parte do pipeline fica ociosa. A intuição é simples: stalls acontecem quando o próximo estágio não pode fazer trabalho útil porque algo que precisa ainda não chegou.
O compilador como controlador de tráfego
É aí que o co-design mostra claramente seu valor. Se o hardware é previsível, o compilador pode ajudar reordenando instruções (sem mudar o significado do programa) para preencher “lacunas”. Por exemplo, enquanto espera um valor ser produzido, o compilador pode agendar uma instrução independente que não dependa desse valor.
O ganho é uma responsabilidade compartilhada: a CPU fica mais simples e rápida no caso comum, enquanto o compilador faz mais planejamento. Juntos, reduzem stalls e aumentam a vazão — muitas vezes melhorando o desempenho real sem precisar de uma ISA mais complexa.
Caches e a memory wall: onde o co-design compensa
Uma CPU pode executar operações simples em poucos ciclos, mas buscar dados na memória principal (DRAM) pode levar centenas de ciclos. Essa lacuna existe porque a DRAM está fisicamente mais distante, otimizada para capacidade e custo, e limitada tanto pela latência (quanto tempo uma requisição demora) quanto pela banda (quantos bytes por segundo podem ser movidos).
Conforme as CPUs ficaram mais rápidas, a memória não acompanhou na mesma proporção — essa diferença crescente é frequentemente chamada de memory wall.
Caches e localidade
Caches são memórias pequenas e rápidas colocadas próximas à CPU para evitar pagar o custo da DRAM a cada acesso. Elas funcionam porque programas reais têm localidade:
- Localidade temporal: se você usou um valor ou instrução recentemente, é provável que o use novamente em breve.
- Localidade espacial: se você acessou um endereço, provavelmente acessará endereços próximos em seguida.
Chips modernos empilham caches (L1, L2, L3), tentando manter o “working set” de código e dados perto do núcleo.
Onde a ISA e os compiladores influenciam o comportamento do cache
Aqui é onde o co-design hardware–software mostra seu valor. A ISA e o compilador juntos moldam quanta pressão de cache um programa cria.
- Tamanho do código importa. Binaries maiores e sequências de instruções mais pesadas podem estourar o cache de instrução, causando stalls. Escolhas de ISA que melhoram a densidade de código (por exemplo, instruções comprimidas opcionais) podem aumentar a taxa de acerto do cache de instrução.
- Padrões de acesso importam. O design load/store ao estilo RISC torna acessos à memória explícitos. Compiladores podem então agendar loads mais cedo, manter valores quentes em registradores por mais tempo e reduzir tráfego de memória desnecessário.
- Layout e blocking. Otimizações de compilador como loop tiling (blocking), reordenação de estruturas de dados e dicas de prefetch visam transformar “viagens aleatórias à DRAM” em acertos previsíveis de cache.
A memory wall no desempenho real
Em termos cotidianos, a memory wall explica por que uma CPU com clock alto pode ainda parecer lenta: abrir um app grande, rodar uma query de banco de dados, rolar um feed ou processar um grande conjunto de dados frequentemente fica limitado por faltas de cache e largura de banda de memória — não pela velocidade aritmética bruta.
Eficiência: desempenho por watt, não apenas velocidade bruta
Prototipe o ciclo de co-design
Transforme ideias de co-design num protótipo funcional construindo sua app via chat no Koder.ai.
Por muito tempo, discussões sobre CPUs soavam como uma corrida: o chip que termina uma tarefa mais rápido “vence”. Mas computadores reais vivem dentro de limites físicos — capacidade de bateria, calor, ruído e contas de eletricidade.
É por isso que desempenho por watt virou uma métrica central: quanto trabalho útil você obtém pela energia que gasta.
O que “desempenho por watt” realmente significa
Pense nisso como eficiência, não força máxima. Dois processadores podem parecer igualmente rápidos no uso diário, mas um pode fazer isso consumindo menos energia, ficando mais frio e rodando mais tempo na mesma bateria.
Em laptops e celulares, isso afeta diretamente vida útil da bateria e conforto. Em datacenters, afeta o custo para energizar e resfriar milhares de máquinas, além de quão densamente você pode empilhar servidores sem superaquecimento.
Por que núcleos mais simples frequentemente desperdiçam menos energia
O pensamento RISC empurrou o projeto de CPUs a fazer menos em hardware e mais de forma previsível. Um núcleo mais simples pode reduzir consumo por vários motivos:
- Lógica de controle menos complicada significa menos “peças” internas alternando a cada ciclo.
- Execução mais previsível facilita manter o pipeline ocupado sem trabalho caro de recuperação.
- Designs amigáveis ao compilador permitem que o software agende trabalho eficientemente, evitando que o hardware faça adivinhações custosas.
A ideia não é que “simples é sempre melhor”. É que a complexidade tem um custo energético, e uma ISA e microarquitetura bem escolhidas podem trocar um pouco de esperteza por muita eficiência.
Mobile e servidores convergem no mesmo objetivo
Telefonês se preocupam com bateria e calor; servidores se preocupam com entrega de energia e resfriamento. Ambientes diferentes, mesma lição: o chip mais rápido nem sempre é o melhor computador. Os vencedores frequentemente são designs que entregam vazão constante enquanto mantêm o consumo de energia sob controle.
O que o RISC acertou — e o que foi mais complexo
RISC é frequentemente resumido como “instruções mais simples vencem”, mas a lição mais duradoura é mais sutil: a ISA importa, porém muitos ganhos do mundo real vieram de como os chips eram implementados, não apenas do que a ISA mostrava no papel.
O debate “a ISA importa”
Argumentos iniciais do RISC sugeriam que uma ISA mais limpa e pequena automaticamente tornaria computadores mais rápidos. Na prática, os maiores ganhos frequentemente vieram de escolhas de implementação que o RISC facilitou: decodificação mais simples, pipelining mais profundo, clocks mais altos e compiladores que podiam escalonar trabalho de forma mais previsível.
É por isso que duas CPUs com ISAs diferentes podem acabar surpreendentemente próximas em desempenho se microarquitetura, tamanhos de cache, predição de desvios e processo de fabricação diferirem. A ISA define as regras; a microarquitetura joga o jogo.
Medição vence listas de recursos
Uma mudança chave da era Patterson foi projetar a partir de dados, não de suposições. Em vez de adicionar instruções porque pareciam úteis, as equipes mediram o que programas realmente faziam e então otimizaram o caso comum.
Essa mentalidade frequentemente superou designs “guiados por recursos”, onde a complexidade cresce mais rápido que os benefícios. Também torna trade-offs mais claros: uma instrução que economiza algumas linhas de código pode custar ciclos extras, energia ou área do chip — e esses custos aparecem em todo lugar.
Não é uma história de vencedor leva tudo
O pensamento RISC não moldou apenas “chips RISC”. Com o tempo, muitas CPUs CISC adotaram técnicas internas parecidas (por exemplo, quebrar instruções complexas em operações internas mais simples) mantendo suas ISAs compatíveis.
Portanto o resultado não foi “RISC venceu CISC”. Foi uma evolução em direção a designs que valorizam medição, previsibilidade e coordenação apertada hardware–software — independentemente do logo na ISA.
De MIPS ao RISC-V: um fio condutor contínuo
RISC não ficou só no laboratório. Uma das linhas mais claras do trabalho de pesquisa para a prática moderna vai de MIPS ao RISC-V — duas ISAs que fizeram da simplicidade e clareza uma característica, não uma restrição.
MIPS: a ISA limpa que as pessoas podiam construir (e aprender)
MIPS é frequentemente lembrada como uma ISA didática, e por boas razões: as regras são fáceis de explicar, os formatos de instrução são consistentes e o modelo básico load/store fica fora do caminho do compilador.
Essa limpeza não foi apenas acadêmica. Processadores MIPS foram vendidos em produtos reais por anos (de workstations a sistemas embarcados), em parte porque uma ISA direta facilita construir pipelines rápidos, compiladores previsíveis e toolchains eficientes. Quando o comportamento do hardware é regular, o software pode planejar em torno disso.
RISC-V: aberto, prático e favorável ao co-design
RISC-V renovou o interesse pelo pensamento RISC ao dar um passo chave que o MIPS nunca deu: é uma ISA aberta. Isso muda incentivos. Universidades, startups e grandes empresas podem experimentar, lançar silício e compartilhar ferramentas sem negociar acesso à própria ISA.
Para o co-design, essa abertura importa porque o lado “software” (compiladores, sistemas operacionais, runtimes) pode evoluir publicamente junto com o lado “hardware”, com menos barreiras artificiais.
Extensões modulares: adicione o que precisa — só quando precisar
Outra razão pela qual RISC-V se conecta bem ao co-design é sua abordagem modular. Você começa com uma ISA base pequena e depois adiciona extensões para necessidades específicas — como matemática vetorial, restrições embarcadas ou recursos de segurança.
Isso incentiva um trade-off mais saudável: em vez de enfiar todo recurso possível em um design monolítico, equipes podem alinhar recursos de hardware com o software que realmente rodará.
Se quiser um primer mais profundo, veja /blog/what-is-risc-v.
Como o co-design aparece na computação moderna
Leve o pensamento RISC para mobile
Crie uma app Flutter via chat e itere em velocidade, bateria e UX.
Co-design não é uma nota histórica do período RISC — é como a computação moderna continua ficando mais rápida e eficiente. A ideia-chave ainda é no estilo Patterson: você não “vence” só com hardware ou só com software. Você vence quando os dois se encaixam nas forças e limitações um do outro.
Pensamento RISC nos dispositivos que você usa todo dia
Smartphones e muitos dispositivos embarcados se apoiam fortemente em princípios RISC (frequentemente baseados em ARM): instruções mais simples, execução previsível e forte ênfase no uso de energia.
Essa previsibilidade ajuda compiladores a gerar código eficiente e ajuda designers a construir núcleos que economizam energia enquanto você rola a tela, mas que conseguem picos de desempenho para pipeline de câmera ou jogos.
Laptops e servidores buscam cada vez mais os mesmos objetivos — especialmente desempenho por watt. Mesmo quando a ISA não é tradicionalmente “RISC”, muitas escolhas internas de projeto miram eficiência estilo RISC: pipelining profundo, execução ampla e gestão de energia agressiva ajustada ao comportamento real do software.
Aceleradores são co-design em ação
GPUs, aceleradores de IA (TPUs/NPUs) e engines de mídia são uma forma prática de co-design: em vez de forçar todo trabalho através de uma CPU de uso geral, a plataforma oferece hardware que combina com padrões comuns de computação.
O que torna isso co-design (e não apenas “hardware extra”) é a pilha de software ao redor:
- GPUs obtêm velocidade de modelos de programação como CUDA e APIs como Vulkan/Metal.
- Aceleradores de IA dependem de compiladores e otimizadores de grafo que transformam um modelo nas operações preferidas do chip.
- Codificadores/decodificadores de vídeo valem a pena porque SOs, navegadores e apps são escritos para usá-los.
Se o software não mirar o acelerador, a velocidade teórica permanece teórica.
Pilhas de software fazem parte do desempenho
Duas plataformas com especificações semelhantes podem parecer muito diferentes porque o “produto real” inclui compiladores, bibliotecas e frameworks. Uma biblioteca matemática bem otimizada (BLAS), um bom JIT ou um compilador mais inteligente podem gerar ganhos grandes sem mudar o chip.
É por isso que o projeto moderno de CPU é muitas vezes orientado por benchmarks: equipes de hardware observam o que compiladores e workloads realmente fazem e então ajustam recursos (caches, predição de desvios, instruções vetoriais, prefetching) para tornar o caso comum mais rápido.
Um checklist rápido: o que observar
Ao avaliar uma plataforma (celular, laptop, servidor ou placa embarcada), procure sinais de co-design:
- Compatibilidade com workload: Seus apps são CPU-bound, GPU-bound, dependentes de memória ou amigáveis a aceleradores?
- Disponibilidade de aceleradores: Há NPU/GPU/engine de mídia — e suas ferramentas realmente os usam?
- Maturidade do compilador/toolchain: Existem builds otimizados, boas ferramentas de profiling e suporte ativo?
- Ecossistema de bibliotecas: Bibliotecas essenciais (math, visão, crypto) estão ajustadas para aquele hardware?
- Comportamento de energia: Você obtém desempenho sustentado dentro dos limites térmicos/energéticos?
O progresso da computação moderna é menos sobre uma única “CPU mais rápida” e mais sobre um sistema inteiro hardware+software que foi moldado — medido, depois projetado — em torno de workloads reais.
Principais conclusões e próximos passos práticos
O pensamento RISC e a mensagem mais ampla de Patterson podem ser resumidos em algumas lições duradouras: simplifique o que deve ser rápido, meça o que realmente acontece e trate hardware e software como um único sistema — porque o usuário experimenta o todo, não os componentes.
Lições que valem a pena manter
Primeiro, simplicidade é estratégia, não estética. Uma ISA limpa e execução previsível tornam mais fácil para compiladores gerar código bom e para CPUs rodá-lo eficientemente.
Segundo, medição vence intuição. Faça benchmarks com workloads representativos, colete dados de profiling e deixe gargalos reais guiem decisões de projeto — seja ao afinar otimizações de compilador, escolher uma SKU de CPU ou redesenhar um hot path crítico.
Terceiro, co-design é onde os ganhos se acumulam. Código amigável a pipeline, estruturas de dados conscientes de cache e metas realistas de desempenho por watt frequentemente entregam velocidade prática maior do que perseguir vazão teórica máxima.
Próximos passos práticos para equipes de produto
Se você está selecionando uma plataforma (sistemas baseados em x86, ARM ou RISC-V), avalie-a do jeito que seus usuários vão:
- Meça cenários ponta a ponta (tempo de inicialização, vazão em estado estável, latência de cauda), não apenas microbenchmarks.
- Acompanhe métricas de eficiência (watts, térmica, impacto na bateria) junto com desempenho.
- Itere: profile → mude uma coisa → meça de novo. Passos pequenos e validados se acumulam.
Se parte do seu trabalho é transformar essas medições em software entregue, pode ajudar encurtar o ciclo build–measure. Por exemplo, equipes usam Koder.ai para prototipar e evoluir apps reais por meio de um fluxo de trabalho guiado por chat (web, backend e mobile), e então reexecutam os mesmos benchmarks ponta a ponta após cada mudança. Recursos como modo de planejamento, snapshots e rollback suportam a mesma disciplina “meça, depois projete” que Patterson defendia — aplicada ao desenvolvimento de produto moderno.
Para um primer mais aprofundado sobre eficiência, veja /blog/performance-per-watt-basics. Se estiver comparando ambientes e precisar de uma forma simples de estimar trade-offs custo/desempenho, /pricing pode ajudar.
A lição duradoura: as ideias — simplicidade, medição e co-design — continuam compensando, mesmo quando implementações evoluem de pipelines da era MIPS para núcleos heterogêneos modernos e novas ISAs como RISC-V.