13 de dez. de 2025·8 min
De startup de gráficos a titã da IA: a história da Nvidia
Explore a trajetória da Nvidia de uma startup de gráficos em 1993 a uma potência global em IA, acompanhando produtos‑chave, avanços, líderes e apostas estratégicas.
Explore a trajetória da Nvidia de uma startup de gráficos em 1993 a uma potência global em IA, acompanhando produtos‑chave, avanços, líderes e apostas estratégicas.
A Nvidia tornou‑se um nome conhecido por razões muito diferentes, dependendo de quem você pergunta. Jogadores de PC pensam em placas GeForce e taxas de quadros suaves. Pesquisadores de IA pensam em GPUs que treinam modelos de ponta em dias em vez de meses. Investidores veem uma das empresas de semicondutores mais valiosas da história, uma ação que virou um atalho para o boom da IA.
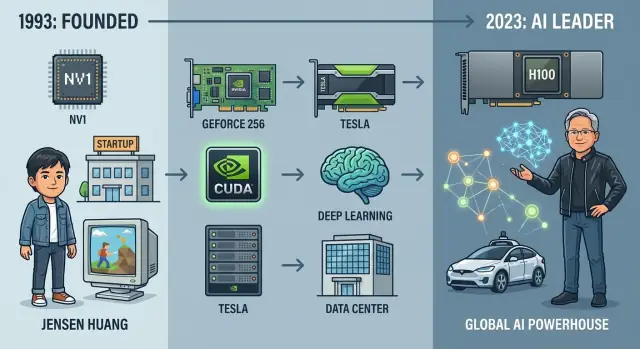
Ainda assim, isso não era inevitável. Quando a Nvidia foi fundada em 1993, era uma pequena startup apostando em uma ideia de nicho: que chips gráficos reconfigurariam a computação pessoal. Em três décadas, evoluiu de fabricante de placas gráficas brigando por espaço a fornecedor central de hardware e software para a IA moderna, alimentando desde sistemas de recomendação e protótipos de direção autônoma até grandes modelos de linguagem.
Entender a história da Nvidia é uma das maneiras mais claras de compreender o hardware de IA moderno e os modelos de negócio em formação. A empresa se situa na interseção de várias forças:
No caminho, a Nvidia fez repetidas apostas de alto risco: apoiar GPUs programáveis antes de haver um mercado claro, construir uma pilha de software completa para aprendizado profundo e gastar bilhões em aquisições como a Mellanox para controlar mais do centro de dados.
Este artigo traça a jornada da Nvidia de 1993 até hoje, com foco em:
O texto é voltado para leitores de tecnologia, negócios e investimentos que querem uma visão narrativa clara de como a Nvidia virou um titã da IA — e o que pode vir a seguir.
Em 1993, três engenheiros com personalidades distintas, mas a convicção compartilhada sobre gráficos 3D, fundaram a Nvidia ao redor de uma mesa do Denny’s no Vale do Silício. Jensen Huang, um engenheiro taiwanês‑americano e ex‑projetista de chips na LSI Logic, trouxe ambição e talento para contar histórias a clientes e investidores. Chris Malachowsky veio da Sun Microsystems com experiência em workstations de alto desempenho. Curtis Priem, ex‑IBM e Sun, era o arquiteto de sistemas obcecado por como hardware e software se encaixavam.
A região girava em torno de workstations, minicomputadores e fabricantes de PCs emergentes. Gráficos 3D eram poderosos, mas caros, majoritariamente atrelados à Silicon Graphics (SGI) e a fornecedores de estações de trabalho para CAD, cinema e visualização científica.
Huang e os cofundadores viram uma oportunidade: levar esse poder de computação visual a PCs acessíveis. Se milhões pudessem ter gráficos 3D de alta qualidade para jogos e multimídia, o mercado seria muito maior que o nicho das workstations.
A ideia fundadora da Nvidia não era semicondutores genéricos; era gráficos acelerados para o mercado de massa. Em vez de CPUs fazendo tudo, um processador gráfico especializado cuidaria da matemática pesada de renderização 3D.
A equipe acreditava que isso exigia:
Huang levantou capital inicial em firmas de venture como a Sequoia, mas dinheiro nunca foi abundante. O primeiro chip, NV1, foi ambicioso mas desalinhado com o padrão DirectX emergente e as APIs de jogos dominantes. Vendeu pouco e quase matou a empresa.
A Nvidia sobreviveu ao pivotar rapidamente para o NV3 (RIVA 128), reposicionando a arquitetura em torno de padrões da indústria e aprendendo a trabalhar muito mais próximo de desenvolvedores de jogos e da Microsoft. A lição: tecnologia isolada não bastava; o alinhamento com o ecossistema determinaria a sobrevivência.
Desde o início, a Nvidia cultivou uma cultura onde engenheiros tinham influência desproporcional e o tempo‑para‑mercado era tratado como existencial. As equipes moviam‑se rápido, iteravam designs agressivamente e aceitavam que algumas apostas falhariam.
Restrições de caixa geraram frugalidade: móveis de escritório reaproveitados, longas jornadas e uma tendência a contratar poucos engenheiros altamente capazes em vez de formar grandes hierarquias. Essa cultura inicial — intensidade técnica, urgência e cuidado com gastos — moldaria como a Nvidia atacaria oportunidades muito maiores além dos gráficos de PC.
No começo e meados dos anos 1990, gráficos de PC eram básicos e fragmentados. Muitos jogos ainda dependiam de renderização por software, com a CPU fazendo a maior parte do trabalho. Aceleradores 2D dedicados existiam para Windows, e placas 3D iniciais como a Voodoo da 3dfx ajudavam, mas não havia um padrão de programação para hardware 3D. APIs como Direct3D e OpenGL ainda amadureciam, e desenvolvedores muitas vezes precisavam mirar em placas específicas.
Esse foi o ambiente que a Nvidia encontrou: dinâmico, confuso e repleto de oportunidades para quem conseguisse combinar desempenho com um modelo de programação limpo.
O primeiro produto importante da Nvidia, o NV1, lançado em 1995, tentou fazer tudo ao mesmo tempo: 2D, 3D, áudio e até suporte ao gamepad do Sega Saturn em uma única placa. Tecnicamente, focou em superfícies quadráticas em vez de triângulos, justamente quando a Microsoft e a indústria estavam padronizando APIs 3D em torno de polígonos triangulares.
O desalinhamento com o DirectX e o suporte de software limitado fizeram do NV1 um fracasso comercial. Mas ensinou duas lições cruciais: seguir a API dominante (DirectX) e concentrar‑se fortemente em desempenho 3D, em vez de recursos exóticos.
A Nvidia reagiu com o RIVA 128 em 1997. Abraçou triângulos e Direct3D, entregou forte desempenho 3D e integrou 2D e 3D em uma só placa. A imprensa notou, e OEMs começaram a ver a Nvidia como parceira séria.
RIVA TNT e TNT2 refinaram a fórmula: melhor qualidade de imagem, maiores resoluções e drivers aprimorados. Enquanto a 3dfx ainda dominava a mente dos consumidores, a Nvidia reduzia a distância ao lançar atualizações frequentes de driver e cortejando desenvolvedores de jogos.
Em 1999, a Nvidia lançou a GeForce 256 e a rotulou como a “primeira GPU do mundo” — uma Graphics Processing Unit. Foi mais que marketing. A GeForce 256 integrou transformações e iluminação por hardware (T&L), descarregando cálculos de geometria da CPU para o chip gráfico.
Essa mudança liberou CPUs para lógica de jogo e física enquanto a GPU lidava com cenas 3D cada vez mais complexas. Jogos passaram a desenhar mais polígonos, usar iluminação mais realista e rodar mais suaves em resoluções maiores.
Ao mesmo tempo, o mercado de jogos para PC explodia, impulsionado por títulos como Quake III Arena e Unreal Tournament, e pela adoção rápida do Windows e DirectX. A Nvidia alinhou‑se estreitamente com esse crescimento.
A empresa garantiu vitórias de design com grandes OEMs como Dell e Compaq, garantindo que milhões de PCs mainstream saíssem de fábrica com gráficos Nvidia. Programas de marketing conjunto com estúdios de jogo e o branding “The Way It’s Meant to Be Played” reforçaram a imagem da Nvidia como escolha padrão para jogadores sérios.
No início dos anos 2000, a Nvidia havia se transformado de uma startup em apuros com um produto desalinhado a uma força dominante em gráficos de PC, preparando o terreno para tudo o que viria depois em computação por GPU e, eventualmente, IA.
Quando a Nvidia começou, GPUs eram em sua maioria máquinas de função fixa: pipelines hard‑wired que recebiam vértices e texturas e devolviam pixels. Eram incrivelmente rápidas, mas quase totalmente inflexíveis.
No início dos anos 2000, shaders programáveis (Vertex e Pixel/Fragment Shaders no DirectX e OpenGL) mudaram essa equação. Com chips como a GeForce 3 e depois a GeForce FX e GeForce 6, a Nvidia passou a expor pequenas unidades programáveis que permitiam efeitos customizados em vez de depender de um pipeline rígido.
Esses shaders ainda eram voltados a gráficos, mas plantar a ideia de que uma GPU poderia ser programada para muitos efeitos diferentes levou a uma pergunta crucial: se uma GPU pode ser programada para efeitos visuais, por que não para cálculo em sentido mais amplo?
A computação de uso geral em GPUs (GPGPU) era uma aposta contrária. Internamente, muitos questionavam gastar orçamento de transistores, tempo de engenharia e esforço de software em cargas fora dos jogos. Externamente, céticos viam GPUs como brinquedos gráficos, e experimentos iniciais — forçando álgebra linear em fragment shaders — eram notoriamente penosos.
A resposta da Nvidia foi o CUDA, anunciado em 2006: um modelo de programação estilo C/C++, runtime e toolchain projetados para fazer a GPU parecer um coprocessador massivamente paralelo. Em vez de forçar cientistas a pensar em termos de triângulos e pixels, o CUDA expôs threads, blocos, grids e hierarquias de memória explícitas.
Foi um grande risco estratégico: a Nvidia teve que construir compiladores, depuradores, bibliotecas, documentação e programas de treinamento — investimentos de software mais típicos de uma empresa‑plataforma do que de um fornecedor de chips.
As primeiras vitórias vieram do computação científica de alto desempenho (HPC):
Pesquisadores puderam rodar simulações que levavam semanas em dias ou horas, muitas vezes em uma única GPU na estação de trabalho em vez de em um cluster inteiro de CPUs.
CUDA fez mais que acelerar código; criou um ecossistema de desenvolvedores ao redor do hardware Nvidia. A empresa investiu em SDKs, bibliotecas matemáticas (como cuBLAS e cuFFT), programas universitários e em sua própria conferência (GTC) para ensinar programação paralela em GPUs.
Cada aplicação e biblioteca em CUDA aprofundou o fosso: desenvolvedores otimizavam para GPUs Nvidia, toolchains amadureciam ao redor do CUDA, e novos projetos começavam assumindo Nvidia como acelerador padrão. Muito antes do treinamento de IA encher data centers com GPUs, esse ecossistema já havia transformado a programabilidade em um dos ativos estratégicos mais poderosos da Nvidia.
No meio dos anos 2000, o negócio de jogos da Nvidia prosperava, mas Jensen Huang e sua equipe viram um limite em depender apenas de GPUs de consumo. O mesmo poder de processamento paralelo que deixava jogos mais suaves também podia acelerar simulações científicas, finanças e, eventualmente, IA.
A Nvidia começou a posicionar GPUs como aceleradores de uso geral para workstations e servidores. Placas profissionais para designers e engenheiros (linha Quadro) foram um passo inicial, mas a maior aposta era entrar no núcleo do data center.
Em 2007, a Nvidia introduziu a linha Tesla, suas primeiras GPUs projetadas especificamente para HPC e workloads de servidor, não para exibição.
As placas Tesla enfatizavam desempenho em precisão dupla, memória com correção de erros e eficiência energética em racks densos — recursos que data centers e centros de supercomputação valorizavam muito mais do que taxas de quadros.
HPC e laboratórios nacionais tornaram‑se adotantes cruciais. Sistemas como o supercomputador “Titan” no Oak Ridge National Laboratory demonstraram que clusters de GPUs programáveis por CUDA podiam entregar ganhos enormes para física, modelagem climática e dinâmica molecular. Essa credibilidade em HPC depois ajudou a convencer empresas e provedores de nuvem de que GPUs eram infraestrutura séria, não apenas equipamento de jogos.
A Nvidia investiu pesadamente em relacionamento com universidades e institutos de pesquisa, semeando laboratórios com hardware e ferramentas CUDA. Muitos pesquisadores que experimentaram computação por GPU na academia depois impulsionaram a adoção em empresas e startups.
Ao mesmo tempo, provedores de nuvem começaram a oferecer instâncias com Nvidia, transformando GPUs em um recurso on‑demand. Amazon Web Services, seguida por Microsoft Azure e Google Cloud, tornou GPUs de classe Tesla acessíveis a qualquer um com cartão de crédito — fator vital para o aprendizado profundo na prática.
Conforme os mercados de data center e profissional cresceram, a base de receita da Nvidia se ampliou. Jogos permaneceram um pilar, mas novos segmentos — HPC, IA empresarial e nuvem — viraram um segundo motor de crescimento, criando a fundação econômica para o posterior domínio em IA.
O ponto de inflexão ocorreu em 2012, quando uma rede neural chamada AlexNet impressionou a comunidade de visão computacional ao dominar o benchmark ImageNet. Crucialmente, ela rodou em um par de GPUs Nvidia. O que era uma ideia de nicho — treinar redes neurais gigantes com chips gráficos — passou a parecer o futuro da IA.
Redes neurais profundas são compostas de enormes números de operações idênticas: multiplicações de matrizes e convoluções aplicadas a milhões de pesos e ativações. GPUs foram projetadas para rodar milhares de threads simples em paralelo para sombreamento gráfico. Essa mesma paralelização encaixava‑se quase perfeitamente nas redes neurais.
Em vez de renderizar pixels, GPUs passaram a processar neurônios. Workloads massivamente paralelos que engasgavam em CPUs podiam agora ser acelerados por ordens de magnitude. Tempos de treinamento que levavam semanas cairam para dias ou horas, permitindo iterações rápidas e escalonamento de modelos.
A Nvidia agiu rápido para transformar a curiosidade de pesquisa em plataforma. O CUDA já dava aos desenvolvedores uma forma de programar GPUs, mas o aprendizado profundo precisava de ferramentas de nível mais alto.
A Nvidia construiu o cuDNN, uma biblioteca otimizada para GPUs com primitivas de redes neurais — convoluções, pooling, funções de ativação. Frameworks como Caffe, Theano, Torch e, mais tarde, TensorFlow e PyTorch integraram o cuDNN, permitindo que pesquisadores tivessem acelerações por GPU sem afinar kernels manualmente.
Ao mesmo tempo, a Nvidia ajustou seu hardware: adicionou suporte a precisão mista, memória de alta largura de banda e, depois, Tensor Cores nas arquiteturas Volta e posteriores, projetados especificamente para matemática matricial no aprendizado profundo.
A Nvidia cultivou relações próximas com laboratórios de IA e pesquisadores em lugares como University of Toronto, Stanford, Google, Facebook e startups iniciais como a DeepMind. A empresa ofereceu hardware precoce, ajuda de engenharia e drivers customizados, recebendo em troca feedback direto sobre as necessidades dos workloads de IA.
Para tornar supercomputação em IA mais acessível, a Nvidia lançou sistemas DGX — servidores de IA pré‑integrados recheados de GPUs de alto nível, interconexões rápidas e software ajustado. O DGX‑1 e seus sucessores tornaram‑se a referência para muitos laboratórios e empresas que construíam capacidades sérias de aprendizado profundo.
Com GPUs como Tesla K80, P100, V100 e, eventualmente, A100 e H100, a Nvidia deixou de ser uma “empresa de jogos que também fazia computação” e tornou‑se o motor padrão para treinar e servir modelos de ponta. O momento AlexNet abriu uma nova era, e a Nvidia posicionou‑se no seu centro.
A Nvidia não venceu em IA apenas vendendo chips mais rápidos. Construíu uma plataforma ponta a ponta que torna mais fácil construir, implantar e escalar IA em hardware Nvidia do que em qualquer outro lugar.
A base é o CUDA, o modelo de programação paralelo da Nvidia introduzido em 2006. CUDA permite que desenvolvedores tratem a GPU como um acelerador geral, com toolchains familiares em C/C++ e Python.
Sobre o CUDA, a Nvidia empilha bibliotecas e SDKs especializados:
Essa pilha faz com que um pesquisador ou engenheiro raramente escreva código GPU de baixo nível; chamam bibliotecas Nvidia otimizadas para cada geração de GPU.
Anos de investimento em tooling CUDA, documentação e treinamento criaram um fosso poderoso. Milhões de linhas de código em produção, projetos acadêmicos e frameworks open source estão otimizados para GPUs Nvidia.
Migrar para uma arquitetura rival muitas vezes implica reescrever kernels, revalidar modelos e treinar engenheiros — custos de troca que mantêm desenvolvedores, startups e grandes empresas ancorados na Nvidia.
A Nvidia trabalha muito próxima dos hyperscalers, fornecendo plataformas de referência HGX e DGX, drivers e stacks de software ajustados para que clientes aluguem GPUs com mínima fricção.
A suíte Nvidia AI Enterprise, o catálogo NGC e modelos pré‑treinados dão às empresas um caminho suportado do piloto à produção, seja on‑premises ou na nuvem.
A Nvidia estende sua plataforma em soluções verticais completas:
Esses stacks verticais unem GPUs, SDKs, aplicações de referência e integrações com parceiros, oferecendo aos clientes algo próximo de uma solução pronta.
Ao nutrir ISVs, parceiros de nuvem, laboratórios de pesquisa e integradores em torno de sua pilha, a Nvidia transformou GPUs no hardware padrão para IA.
Cada novo framework otimizado para CUDA, cada startup que entrega em Nvidia e cada serviço de nuvem ajustado às suas GPUs fortalece um ciclo de retroalimentação: mais software na Nvidia atrai mais usuários, justificando mais investimento e ampliando a vantagem sobre competidores.
A ascensão da Nvidia ao domínio da IA deve‑se tanto a apostas estratégicas além da GPU quanto aos próprios chips.
A aquisição da Mellanox em 2019 foi um divisor de águas. A Mellanox trouxe InfiniBand e Ethernet de alta‑performance, além de expertise em interconexões de baixa latência e alta largura de banda.
Treinar grandes modelos depende de costurar milhares de GPUs em um único computador lógico. Sem rede rápida, as GPUs ficam ociosas esperando dados ou a sincronização de gradientes. Tecnologias como InfiniBand, RDMA, NVLink e NVSwitch reduzem overhead de comunicação e fazem clusters massivos escalarem de forma eficiente. Por isso os sistemas de IA mais valiosos da Nvidia — DGX, HGX e designs completos de data center — combinam GPUs, CPUs, NICs, switches e software num único kit otimizado.
Em 2020, a Nvidia anunciou a intenção de comprar a Arm, buscando combinar sua experiência em aceleração de IA com uma arquitetura de CPU amplamente licenciada usada em celulares, dispositivos embarcados e, cada vez mais, servidores.
Reguladores nos EUA, Reino Unido, UE e China levantaram fortes preocupações antitruste: a Arm é um fornecedor de IP neutro para muitos rivais da Nvidia, e a consolidação ameaçava essa neutralidade. Após escrutínio prolongado e resistência da indústria, a Nvidia abandonou o negócio em 2022.
Mesmo sem a Arm, a Nvidia avançou com seu próprio CPU Grace, mostrando que ainda pretende moldar o nó completo de data center, não apenas o cartão acelerador.
O Omniverse estende a Nvidia para simulação, gêmeos digitais e colaboração 3D. Baseado em OpenUSD, conecta ferramentas e dados para que empresas simulem fábricas, cidades e robôs antes de implantar no mundo físico. O Omniverse é tanto uma carga pesada para GPUs quanto uma plataforma de software que prende desenvolvedores.
No setor automotivo, a plataforma DRIVE mira computação centralizada no carro, direção autônoma e ADAS. Ao fornecer hardware, SDKs e ferramentas de validação a montadoras e fornecedores de nível 1, a Nvidia se encaixa em ciclos de produto longos e receitas recorrentes de software.
Na borda, módulos Jetson e stacks de software associados alimentam robótica, câmeras inteligentes e IA industrial. Esses produtos levam a plataforma Nvidia a varejo, logística, saúde e cidades, capturando workloads que não podem viver apenas na nuvem.
Com Mellanox e rede, jogadas instrutivas como a Arm, e expansões em Omniverse, automotivo e borda, a Nvidia deliberadamente deixou de ser apenas um “vendedor de GPUs”.
Hoje vende:
Essas apostas tornam a Nvidia mais difícil de deslocar: concorrentes precisam igualar não só o chip, mas uma pilha integrada que abrange computação, rede, software e soluções específicas de domínio.
A ascensão da Nvidia atraiu rivais poderosos, reguladores mais atentos e novos riscos geopolíticos que moldam cada movimento estratégico da empresa.
A AMD continua sendo o par mais próximo da Nvidia em GPUs, competindo olho no olho em jogos e aceleradores de data center. A série MI da AMD mira os mesmos clientes de nuvem e hyperscale que a Nvidia atende com H100 e peças sucessoras.
A Intel ataca por várias frentes: CPUs x86 que ainda dominam servidores, suas próprias GPUs discretas e aceleradores de IA dedicados. Ao mesmo tempo, hyperscalers como Google (TPU), Amazon (Trainium/Inferentia) e uma onda de startups (ex.: Graphcore, Cerebras) desenvolvem chips próprios para reduzir dependência da Nvidia.
A defesa chave da Nvidia continua sendo uma combinação de liderança de desempenho e software. CUDA, cuDNN, TensorRT e um stack profundo de SDKs prendem desenvolvedores e empresas. Hardware sozinho não basta; portar modelos e ferramentas para fora do ecossistema Nvidia implica custos reais.
Governos hoje tratam GPUs avançadas como ativos estratégicos. Controles de exportação dos EUA têm repetidamente restringido o envio de chips de IA de ponta para a China e outros mercados sensíveis, forçando a Nvidia a projetar variantes “compatíveis com exportação” com desempenho limitado. Esses controles protegem a segurança nacional, mas restringem o acesso a uma grande região de crescimento.
Reguladores também observam o poder de mercado da Nvidia. O negócio da Arm bloqueado evidenciou preocupações sobre permitir que a Nvidia controlasse IP chip fundamental. À medida que a participação da Nvidia em aceleradores de IA cresce, reguladores nos EUA, UE e outros ficam mais inclinados a examinar exclusividade, empacotamento e discriminação no acesso a hardware e software.
A Nvidia é fabless, dependente da TSMC para fabricação de ponta. Qualquer interrupção em Taiwan — por desastres naturais, tensão política ou conflito — afetaria diretamente a capacidade da Nvidia de fornecer GPUs de alto nível.
Escassez global de capacidade de empacotamento avançado (CoWoS, integração de HBM) já cria gargalos de oferta, diminuindo a flexibilidade da Nvidia para responder a picos de demanda. A empresa precisa negociar capacidade, navegar nas fricções tecnológicas EUA–China e cobrir riscos de controles de exportação que mudam mais rápido que roteiros de semicondutores.
Conciliar essas pressões enquanto mantém a liderança tecnológica é tão tarefa geopolítica e regulatória quanto de engenharia.
Jensen Huang é um CEO fundador que ainda age como engenheiro prático. Envolve‑se profundamente em estratégia de produto, participando de revisões técnicas e sessões em quadro branco, não só nas calls de resultados.
Sua persona pública mistura showmanship e clareza. As apresentações de jaqueta de couro são deliberadas: ele usa metáforas simples para explicar arquiteturas complexas, posicionando a Nvidia como uma empresa que entende física e negócios. Internamente, é conhecido pelo feedback direto, grandes expectativas e disposição para tomar decisões desconfortáveis quando tecnologia ou mercado mudam.
A cultura da Nvidia gira em torno de temas recorrentes:
Essa mistura cria uma cultura onde loops longos (design de chips) coexistem com loops rápidos (software e pesquisa), e onde hardware, software e pesquisa colaboram de forma estreita.
A Nvidia investe rotineiramente em plataformas plurianuais — novas arquiteturas de GPU, interconexões, frameworks — enquanto gerencia expectativas trimestrais.
Organizacionalmente, isso significa:
Huang frequentemente enquadra discussões de resultados em tendências de longo prazo (IA, computação acelerada) para manter investidores alinhados ao horizonte da empresa, mesmo quando a demanda de curto prazo oscila.
A Nvidia trata desenvolvedores como cliente de primeira classe. CUDA, cuDNN, TensorRT e dezenas de SDKs verticais contam com:
Ecossistemas de parceiros — OEMs, provedores de nuvem, integradores de sistema — são cultivados com designs de referência, marketing conjunto e acesso antecipado a roadmaps. Esse ecossistema fechado torna a plataforma Nvidia pegajosa e difícil de substituir.
Ao crescer de fornecedor de placas gráficas a plataforma global de IA, a cultura da Nvidia evoluiu:
Apesar da escala, a Nvidia procurou preservar a mentalidade de fundador e prioridade à engenharia, onde apostas técnicas ambiciosas são encorajadas e equipes se movem rápido em busca de avanços.
A trajetória financeira da Nvidia é uma das mais dramáticas da tecnologia: de fornecedor de gráficos para PC a empresa de vários trilhões de dólares no centro do boom da IA.
Após o IPO em 1999, a Nvidia passou anos avaliada em bilhões singelos, ligada a mercados cíclicos de PC e jogos. Nos anos 2000, a receita cresceu de forma constante para alguns bilhões, mas a empresa ainda era vista como fornecedora de chips especializada, não uma líder de plataforma.
A inflexão veio meados dos anos 2010, quando receita de data center e IA começou a se acumular. Por volta de 2017, o market cap ultrapassou US$100 bilhões; em 2021 tornou‑se uma das empresas de semicondutores mais valiosas do mundo. Em 2023 entrou brevemente no clube do trilhão e, em 2024, frequentemente negociava acima dessa marca, refletindo a convicção dos investidores de que a Nvidia é infraestrutura fundamental para IA.
Por grande parte de sua história, GPUs para jogos foram o núcleo do negócio. Gráficos de consumo, além de visualização profissional e placas para workstations, geravam a maior parte da receita e do lucro.
Esse mix virou com a explosão da IA e computação acelerada na nuvem:
A economia do hardware de IA transformou o perfil financeiro da Nvidia. Plataformas de alto nível, rede e software têm preços premium e margens elevadas. Com o aumento da receita do data center, margens gerais se expandiram, tornando a Nvidia uma máquina de geração de caixa com alavancagem operacional extraordinária.
A demanda por IA não apenas adicionou uma linha de produto; redefiniu como investidores valorizam a Nvidia. A empresa deixou de ser modelada como um nome cíclico de semicondutores e passou a ser tratada mais como infraestrutura crítica e plataforma de software.
Margens brutas, sustentadas por aceleradores de IA e software de plataforma, subiram para níveis elevados. Com custos fixos crescendo mais devagar que a receita, as margens incrementais do crescimento em IA têm sido extremamente altas, impulsionando ganhos por ação e revisões alcistas de analistas. Isso levou a múltiplos ciclos de reavaliação e a um valuation premium comparável a grandes plataformas de nuvem e software.
A história do preço das ações da Nvidia é pontuada por rallies espetaculares e quedas acentuadas.
A empresa realizou desdobramentos para manter o preço por ação acessível: várias divisões 2‑por‑1 nos anos 2000, 4‑por‑1 em 2021 e 10‑por‑1 em 2024. Acionistas de longo prazo que mantiveram posições viram retornos compostos extraordinários.
A volatilidade também se destacou. Quedas profundas ocorreram durante:
Cada vez, preocupações sobre ciclicidade ou correções de demanda afetaram as ações. Ainda assim, o boom da IA repetidamente levou a Nvidia a patamares inéditos conforme as expectativas se ajustavam.
Apesar do sucesso, a Nvidia não é vista como isenta de risco. Investidores debatem questões-chave:
Por outro lado, o caso bullish é que computação acelerada e IA vírtem‑se padrão em data centers, empresas e borda por décadas. Nesse cenário, a combinação da Nvidia de GPUs, rede, software e bloqueio do ecossistema poderia sustentar muitos anos de crescimento e margens fortes, justificando sua transição de fabricante de nicho a gigante duradoura.
O próximo capítulo da Nvidia é transformar GPUs de ferramenta de treinamento em tecido subjacente de sistemas inteligentes: IA generativa, máquinas autônomas e mundos simulados.
IA generativa é o foco imediato. A Nvidia quer que cada grande modelo — texto, imagem, vídeo, código — seja treinado, afinado e servido em sua plataforma. Isso significa GPUs de data center mais potentes, redes mais rápidas e stacks de software que facilitem a empresas construir copilotos personalizados e modelos de domínio.
Além da nuvem, a Nvidia empurra sistemas autônomos: carros autônomos, robôs de entrega, braços de fábrica e drones. O objetivo é reutilizar o mesmo stack CUDA, IA e de simulação entre automotivo (Drive), robótica (Isaac) e plataformas embarcadas (Jetson).
Gêmeos digitais conectam tudo isso. Com Omniverse e ferramentas relacionadas, a Nvidia aposta que empresas vão simular fábricas, cidades e redes 5G antes de construir ou reconfigurar — criando receita de software e serviços de longo prazo sobre o hardware.
Automotivo, automação industrial e computação de borda são grandes prêmios. Carros viram data centers móveis, fábricas se tornam sistemas dirigidos por IA e hospitais/lojas viram ambientes ricos em sensores. Cada caso exige inferência de baixa latência, software crítico para segurança e ecossistemas de desenvolvedores — áreas onde a Nvidia investe pesado.
Mas os riscos são reais:
Para fundadores e engenheiros, a história da Nvidia mostra o poder de possuir a pilha completa: silício, sistema e ferramentas para desenvolvedores, além de apostar no próximo gargalo de computação antes que ele seja óbvio.
Para formuladores, é um estudo de caso de como plataformas de computação se tornam infraestrutura estratégica. Decisões sobre controles de exportação, política de concorrência e financiamento de alternativas abertas vão influenciar se a Nvidia permanece a porta de entrada dominante para IA ou apenas um ator importante em um ecossistema mais diversificado.
A Nvidia foi fundada com uma aposta muito específica: que gráficos 3D sairiam de estações de trabalho caras e entrariam em PCs de consumo, e que essa transição exigiria um processador gráfico dedicado estreitamente integrado com software.
Em vez de tentar ser uma empresa de semicondutores genérica, a Nvidia:
Esse foco estreito, porém profundo, em computação gráfica em tempo real criou a base técnica e cultural que mais tarde se traduziu em computação por GPU e aceleração de IA.
CUDA transformou as GPUs da Nvidia de hardware gráfico de função fixa em uma plataforma de computação paralela de uso geral.
Principais formas pelas quais CUDA ajudou na liderança em IA:
A Mellanox deu à Nvidia controle sobre a malha de rede que conecta milhares de GPUs em supercomputadores de IA.
Para modelos muito grandes, o desempenho depende não só de chips rápidos, mas de quão rapidamente eles trocam dados e gradientes. A Mellanox trouxe:
A receita da Nvidia mudou de um foco majoritário em jogos para uma predominância de data center.
De forma resumida:
A Nvidia enfrenta concorrência de rivais tradicionais e de aceleradores personalizados:
GPUs avançadas são tratadas hoje como tecnologia estratégica, especialmente para IA.
Impactos diretos:
A pilha de software de IA da Nvidia é uma camada de ferramentas que abstrai a complexidade da GPU da maioria dos desenvolvedores:
Autônomos e robótica estendem a plataforma central de IA e simulação da Nvidia para sistemas físicos.
Do ponto de vista estratégico:
Algumas lições principais para fundadores e engenheiros:
Se cargas futuras deixarem de favorecer o padrão GPU, a Nvidia precisará adaptar hardware e software rapidamente.
Mudanças possíveis:
A provável reação da Nvidia seria:
Quando o aprendizado profundo explodiu, as ferramentas, a documentação e os hábitos em torno de CUDA já estavam maduros, dando à Nvidia uma grande vantagem inicial.
Isso permitiu que a Nvidia vendesse plataformas integradas (DGX, HGX e designs completos de data center) onde GPUs, rede e software são co‑otimizados, em vez de apenas vender placas aceleradoras isoladas.
Plataformas de IA de ponta e soluções de rede têm preços e margens premium, por isso o crescimento do data center transformou a rentabilidade geral da Nvidia.
As defesas da Nvidia são liderança em desempenho, o bloqueio de software (CUDA/cuDNN/TensorRT) e sistemas integrados. Mas se alternativas ficarem “boas o suficiente” e mais fáceis de programar, a participação e o poder de precificação da Nvidia podem ser pressionados.
Assim, a estratégia da Nvidia deve considerar políticas, regras comerciais e planos industriais regionais além de decisões puramente técnicas e de mercado.
A maioria das equipes chama essas bibliotecas por meio de frameworks como PyTorch ou TensorFlow, então raramente escrevem código GPU de baixo nível diretamente.
Esses mercados podem ser menores hoje do que a nuvem, mas oferecem receita duradoura e margens elevadas, além de aprofundar o ecossistema da Nvidia em setores industriais.
Para quem constrói produtos, o aprendizado é combinar visão técnica profunda com pensamento de ecossistema, não apenas desempenho bruto.
A história da empresa sugere capacidade de pivô, mas mudanças profundas testariam sua adaptabilidade.