Por que as escolhas iniciais de Joe Beda no Kubernetes ainda importam
Joe Beda foi uma das pessoas-chave por trás do design inicial do Kubernetes — ao lado de outros fundadores que trouxeram lições dos sistemas internos do Google para uma plataforma aberta. Sua influência não foi em perseguir recursos da moda; foi em escolher primitivas simples que sobrevivessem ao caos real de produção e ainda fossem compreensíveis por times comuns.
Essas decisões iniciais são o motivo de o Kubernetes ter se tornado mais do que “uma ferramenta de containers”. Ele virou um kernel reutilizável para plataformas modernas de aplicações.
Orquestração de containers, em termos simples
“Orquestração de containers” é o conjunto de regras e automação que mantém sua app funcionando quando máquinas falham, o tráfego aumenta ou você faz um novo deploy. Em vez de um humano ficar vigiando servidores, o sistema agenda containers em máquinas, reinicia-os quando caem, espalha-os para resiliência e conecta a rede para que usuários consigam alcançá-los.
A bagunça antes do Kubernetes
Antes do Kubernetes se popularizar, times frequentemente costuravam scripts e ferramentas customizadas para responder a perguntas básicas:
- Onde este container deve rodar agora?
- O que acontece se um nó morrer às 2 da manhã?
- Como fazemos um deploy seguro sem downtime?
- Como serviços se encontram quando os IPs mudam o tempo todo?
Esses sistemas DIY funcionavam — até não funcionarem. Cada nova app ou time acrescentava lógica pontual, e a consistência operacional era difícil de alcançar.
O que este post cobre
Este artigo percorre escolhas de design iniciais do Kubernetes (a “forma” do Kubernetes) e por que elas ainda influenciam plataformas modernas: o modelo declarativo, controladores, Pods, labels, Services, uma API forte, estado consistente do cluster, agendamento plugável e extensibilidade. Mesmo que você não rode Kubernetes diretamente, é provável que use uma plataforma construída sobre essas ideias — ou esteja enfrentando os mesmos problemas.
O problema que o Kubernetes veio resolver
Antes do Kubernetes, “rodar containers” geralmente significava rodar alguns containers. Times costuravam bash scripts, cron jobs, imagens base e um punhado de ferramentas ad-hoc para colocar coisas em produção. Quando algo quebrava, a correção frequentemente vivia na cabeça de alguém — ou em um README que ninguém confiava. Operações eram um fluxo de intervenções pontuais: reiniciar processos, reapontar balanceadores, limpar disco e adivinhar qual máquina era seguro tocar.
Containers em escala criaram novos modos de falha
Containers facilitaram empacotar aplicações, mas não removeram as partes confusas da produção. Em escala, o sistema falha de mais maneiras e com mais frequência: nós desaparecem, redes se partem, imagens são lançadas de forma inconsistente e workloads desviam do que você acha que está rodando. Um deploy “simples” pode virar uma cascata — algumas instâncias atualizadas, outras não, algumas presas, outras saudáveis mas inacessíveis.
A questão real não era iniciar containers. Era manter os containers certos rodando, na forma certa, apesar da constante mudança.
Um modelo consistente através da infraestrutura
Times também conciliavam ambientes diferentes: hardware on‑prem, VMs, provedores de nuvem iniciais e diversos setups de rede e armazenamento. Cada plataforma tinha seu vocabulário e padrões de falha. Sem um modelo compartilhado, toda migração significava reescrever ferramentas operacionais e re-treinar pessoas.
O Kubernetes propôs uma maneira única e consistente de descrever aplicações e suas necessidades operacionais, independentemente de onde as máquinas estivessem.
Desenvolvedores queriam self-service: deploy sem tickets, escalar sem pedir capacidade, e rollback sem drama. Times de ops queriam previsibilidade: health checks padronizados, deploys repetíveis e uma fonte clara de verdade do que deveria estar rodando.
O Kubernetes não tentou ser apenas um scheduler chique. O objetivo era ser a fundação para uma plataforma de aplicações confiável — que transforme a realidade bagunçada em um sistema que você consiga raciocinar.
Decisão 1: Modelo declarativo de estado desejado
Uma das escolhas mais influentes foi tornar o Kubernetes declarativo: você descreve o que quer e o sistema trabalha para fazer a realidade bater com essa descrição.
Estado desejado, explicado como um termostato
Um termostato é um exemplo útil do dia a dia. Você não liga e desliga o aquecedor a cada poucos minutos. Você define uma temperatura desejada — digamos 21°C — e o termostato fica checando a sala e ajustando o aquecedor para se manter perto desse alvo.
O Kubernetes funciona do mesmo jeito. Em vez de dizer ao cluster passo a passo “inicia este container naquela máquina, depois reinicie se falhar”, você declara o resultado: “quero 3 cópias desta app rodando.” O Kubernetes verifica continuamente o que está realmente rodando e corrige a deriva.
Menos passos manuais, menos surpresas
Configuração declarativa reduz a “checklist de ops” escondida que muitas vezes vive na cabeça de alguém ou em um runbook meio desatualizado. Você aplica a configuração e o Kubernetes cuida da mecânica — posicionamento, reinícios e reconciliações de mudança.
Também torna a revisão de mudanças mais fácil. Uma alteração aparece como um diff na configuração, não como uma série de comandos ad-hoc.
Repetibilidade entre ambientes
Como o estado desejado está escrito, você pode reaproveitar a mesma abordagem em dev, staging e produção. O ambiente pode diferir, mas a intenção permanece consistente, o que torna deploys mais previsíveis e mais fáceis de auditar.
Os trade-offs
Sistemas declarativos têm uma curva de aprendizado: você precisa pensar em “o que deve ser verdadeiro” em vez de “o que eu faço a seguir”. Eles também dependem muito de bons defaults e convenções claras — sem isso, times podem produzir configs que tecnicamente funcionam, mas são difíceis de entender e manter.
Decisão 2: Loops de controle (controladores) como motor
O Kubernetes não teve sucesso porque conseguiu rodar containers uma vez — teve porque conseguiu mantê-los rodando corretamente ao longo do tempo. O grande movimento de design foi tornar “control loops” (controladores) o motor central do sistema.
O que é um controlador
Um controlador é um loop simples:
- Olha o estado atual (o que está realmente rodando)
- Compara com o estado desejado (o que você pediu)
- Toma ações até que os dois coincidam
É menos como uma tarefa única e mais como piloto automático. Você não fica “babysitting” workloads; você declara o que quer e os controladores mantêm o cluster voltando para esse resultado.
Esse padrão é o motivo pelo qual o Kubernetes é resiliente quando coisas do mundo real dão errado:
- Crashes de container: o controlador nota menos instâncias rodando do que o desejado e inicia substituições.
- Perda de nó: quando um nó desaparece, os controladores reprogramam pods em outro lugar para restaurar a contagem desejada.
- Deriva de configuração: se alguém muda ou apaga recursos, os controladores reconciliam a diferença e corrigem.
Em vez de tratar falhas como casos especiais, controladores tratam como “descasamento de estado” rotineiro e corrigem do mesmo jeito toda vez.
Por que escala melhor que scripts
Scripts tradicionais frequentemente assumem um ambiente estável: execute o passo A, depois B, depois C. Em sistemas distribuídos, essas suposições quebram constantemente. Controladores escalam melhor porque são idempotentes (seguros para rodar repetidamente) e eventualmente consistentes (continuam tentando até o objetivo ser alcançado).
Exemplos do dia a dia: Deployments e ReplicaSets
Se você já usou um Deployment, você depende de control loops. Por baixo dos panos, o Kubernetes usa um controlador de ReplicaSet para garantir que o número requisitado de pods exista — e um controlador de Deployment para gerenciar atualizações contínuas e rollbacks previsíveis.
Decisão 3: Pods como unidade atômica de agendamento
O Kubernetes poderia ter agendado “apenas containers”, mas a equipe de Joe Beda introduziu Pods para representar a menor unidade implantável que o cluster coloca em uma máquina. A ideia chave: muitas aplicações reais não são um único processo. São um pequeno grupo de processos fortemente acoplados que devem viver juntos.
Por que Pods em vez de containers individuais?
Um Pod é um invólucro em torno de um ou mais containers que compartilham o mesmo destino: iniciam juntos, rodam no mesmo nó e escalam juntos. Isso torna padrões como sidecars naturais — pense em um roteador de logs, proxy, reloader de config ou agente de segurança que deve sempre acompanhar a app principal.
Em vez de ensinar cada app a integrar esses helpers, o Kubernetes permite empacotá-los como containers separados que ainda se comportam como uma unidade.
O que Pods habilitaram para rede e armazenamento
Pods tornaram práticas duas suposições importantes:
- Rede: containers em um Pod compartilham identidade de rede (um IP e espaço de portas). A app principal pode conversar com o sidecar via
localhost, simples e rápido.
- Armazenamento: containers em um Pod podem compartilhar volumes. Um helper pode escrever arquivos que a app principal lê (ou vice-versa), sem saltos externos desajeitados.
Essas escolhas reduziram a necessidade de glue code customizado, mantendo containers isolados no nível de processo.
Onde Pods confundem iniciantes
Novos usuários frequentemente esperam “um container = uma app” e então se enroscam com conceitos de nível de Pod: reinícios, IPs e escala. Muitas plataformas suavizam isso fornecendo templates opinativos (por exemplo, “serviço web”, “worker” ou “job”) que geram Pods por baixo dos panos — assim os times colhem os benefícios de sidecars e recursos compartilhados sem pensar nos detalhes de Pod todo dia.
Decisão 4: Labels e Selectors para acoplamento frouxo
Da ideia à app a funcionar
Crie uma app real a partir do chat e veja como rapidamente consegue iterar com Koder.ai.
Uma escolha silenciosamente poderosa foi tratar labels como metadados de primeira classe e selectors como a forma primária de “encontrar” coisas. Em vez de relacionamentos hard-coded (como “estas três máquinas específicas rodam minha app”), o Kubernetes incentiva descrever grupos por atributos compartilhados.
Uma label é um par chave/valor simples que você anexa a recursos — Pods, Deployments, Nodes, Namespaces e mais. Elas funcionam como “tags” consistentes e pesquisáveis:
app=checkoutenv=prodtier=frontend
Como labels são leves e definidas pelo usuário, você pode modelar a realidade da sua organização: times, centros de custo, zonas de conformidade, canais de release ou o que for relevante para sua operação.
Selectors: relacionamentos sem dependências rígidas
Selectors são consultas sobre labels (por exemplo, “todos os Pods onde app=checkout e env=prod”). Isso vence listas fixas de hosts porque o sistema pode se adaptar conforme Pods são reprogramados, escalados ou substituídos durante rollouts. Sua configuração permanece estável mesmo quando as instâncias subjacentes mudam constantemente.
Agrupamento dinâmico em escala
Esse design escala operacionalmente: você não gerencia milhares de identidades de instância — você gerencia alguns conjuntos de labels significativos. Essa é a essência do acoplamento frouxo: componentes se conectam a grupos cuja filiação pode mudar com segurança.
Labels ativam mais do que agrupamento
Uma vez que labels existem, elas viram um vocabulário compartilhado por toda a plataforma. São usadas para roteamento de tráfego (Services), limites de política (NetworkPolicy), filtros de observabilidade (métricas/logs) e até rastreamento de custo e chargeback. Uma ideia simples — marcar coisas de forma consistente — desbloqueia todo um ecossistema de automação.
Decisão 5: Services para rede estável
Kubernetes precisava de uma forma de fazer a rede parecer previsível mesmo que containers não sejam nada disso. Pods são substituídos, reprogramados e escalados — então seus IPs e até as máquinas específicas onde rodam vão mudar. A ideia central de um Service é simples: fornecer uma “porta de entrada” estável para um conjunto mutável de Pods.
Acesso estável a Pods que mudam
Um Service dá a você um IP virtual consistente e um nome DNS (como payments). Por trás desse nome, o Kubernetes rastreia continuamente quais Pods casam com o selector do Service e encaminha o tráfego adequadamente. Se um Pod morre e outro aparece, o Service ainda aponta para o lugar certo sem você tocar nas configurações da aplicação.
Descoberta de serviços que simplificou configuração
Essa abordagem removeu muita fiação manual. Em vez de colocar IPs em configs, apps podem depender de nomes. Você deploya a app, deploya o Service e outros componentes a encontram via DNS — sem registry customizado, sem endpoints hard-coded.
Balanceamento de carga embutido para confiabilidade
Services também introduziram comportamento padrão de balanceamento entre endpoints saudáveis. Isso significa que times não precisaram construir (ou reconstruir) seus próprios balanceadores para cada microserviço interno. Espalhar tráfego reduz o raio de explosão de uma falha de Pod e torna updates contínuos menos arriscados.
Limites — e como Ingress/Gateway estendem isso
Um Service é ótimo para tráfego L4 (TCP/UDP), mas não modela regras de roteamento HTTP, terminação TLS ou políticas de borda. É aí que Ingress e, cada vez mais, a Gateway API entram: eles constroem sobre Services para lidar com hostnames, paths e pontos de entrada externos de forma mais limpa.
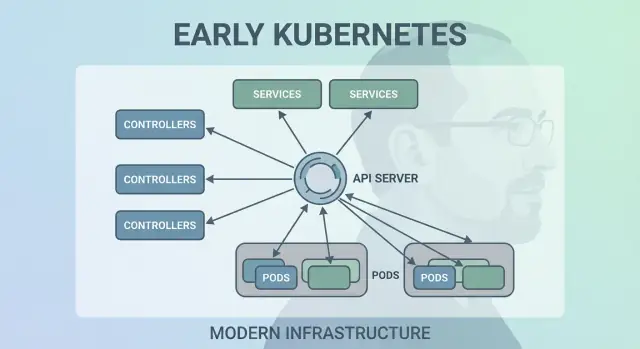
Decisão 6: Uma API como superfície do produto
Uma das escolhas iniciais mais radicalmente discretas foi tratar o Kubernetes como uma API para se construir — não um produto monolítico que você “usa”. Essa postura API-first fez o Kubernetes parecer menos um produto para clicar e mais uma plataforma que você pode estender, scriptar e governar.
Quando a API é a superfície, times de plataforma podem padronizar como aplicações são descritas e gerenciadas, independentemente de qual UI, pipeline ou portal interno exista por cima. “Deployar uma app” vira “submeter e atualizar objetos de API” (como Deployments, Services e ConfigMaps), que é um contrato muito mais limpo entre times de app e plataforma.
Ferramentas, UIs e automação sem acesso especial
Porque tudo passa pela mesma API, novas ferramentas não precisam de portas traseiras privilegiadas. Dashboards, controladores GitOps, engines de política e sistemas CI/CD podem operar como clientes normais da API com permissões bem escopadas.
Essa simetria importa: as mesmas regras, autenticação, auditoria e controles de admissão se aplicam se a requisição veio de uma pessoa, um script ou uma UI interna.
Versionamento e compatibilidade para clusters duradouros
Versionamento de API tornou possível evoluir o Kubernetes sem quebrar todo cluster ou toda ferramenta da noite para o dia. Deprecações podem ser escalonadas; compatibilidade pode ser testada; upgrades podem ser planejados. Para organizações que rodam clusters por anos, isso faz a diferença entre “conseguimos atualizar” e “estamos presos”.
O que kubectl realmente representa
kubectl não é o Kubernetes — é um cliente. Esse modelo mental empurra times a pensar em fluxos de trabalho baseados na API: você pode trocar kubectl por automação, uma UI web ou um portal customizado, e o sistema permanece consistente porque o contrato é a própria API.
Decisão 7: Estado centralizado do cluster (etcd) e consistência
Proteja o progresso enquanto itera
Guarde um estado estável antes de grandes mudanças para poder reverter rapidamente.
Kubernetes precisava de uma “fonte única de verdade” sobre como o cluster deveria estar agora: quais Pods existem, quais nós estão saudáveis, para onde Services apontam e quais objetos estão sendo atualizados. Isso é o que o etcd fornece.
O que o etcd faz (em termos simples)
etcd é o banco de dados do plano de controle. Quando você cria um Deployment, escala um ReplicaSet ou atualiza um Service, a configuração desejada é escrita no etcd. Controladores e outros componentes do plano de controle então observam esse estado armazenado e trabalham para fazer a realidade coincidir.
Por que consistência importa quando tudo age ao mesmo tempo
Um cluster Kubernetes é cheio de partes em movimento: scheduler, controllers, kubelets, autoscalers e checagens de admissão podem reagir simultaneamente. Se estiverem lendo versões diferentes da “verdade”, você tem condições de corrida — como dois componentes tomando decisões conflitantes sobre o mesmo Pod.
A forte consistência do etcd garante que quando o plano de controle diz “este é o estado atual”, todo mundo esteja alinhado. Esse alinhamento é o que torna os control loops previsíveis em vez de caóticos.
Como afeta backups, upgrades e recuperação de desastre
Como o etcd guarda a configuração do cluster e o histórico de mudanças, é também o que você protege durante:
- Backups: sem um snapshot do etcd, você não consegue restaurar objetos de cluster de forma confiável.
- Upgrades: saúde e snapshotagem cuidadosa do etcd reduzem riscos de upgrade.
- Recuperação de desastre: restaurar o etcd é frequentemente o caminho mais rápido para trazer o plano de controle de volta com a mesma intenção.
Orientação prática
Trate o estado do plano de controle como dados críticos. Faça snapshots do etcd regularmente, teste restaurações e armazene backups fora do cluster. Se você usa Kubernetes gerenciado, entenda o que seu provedor faz backup — e o que você ainda precisa proteger por conta própria (por exemplo, volumes persistentes e dados da aplicação).
Decisão 8: Agendamento plugável e consciência de recursos
O Kubernetes não tratou “onde um workload roda” como detalhe. Desde cedo, o scheduler foi um componente distinto com um trabalho claro: casar Pods a nós que realmente possam executá-los, usando o estado atual do cluster e os requisitos do Pod.
Como o scheduler casa workloads a nós
Em alto nível, o agendamento é uma decisão em duas etapas:
- Filtrar: remover nós que não atendem restrições rígidas (CPU/ memória insuficiente, labels ausentes, taints incompatíveis, portas ocupadas etc.).
- Pontuar: ranquear os nós restantes por preferências (espalhar entre zonas, empacotar para eficiência, evitar vizinhos barulhentos, honrar regras de afinidade).
Essa estrutura tornou possível evoluir o agendamento do Kubernetes sem reescrever tudo.
Separação de responsabilidades: scheduler vs runtime vs rede
Uma escolha chave foi manter responsabilidades claras:
- O scheduler decide onde colocar.
- O container runtime (e o kubelet) faz a execução no nó escolhido.
- A camada de rede fornece conectividade uma vez que as coisas estejam rodando.
Como essas preocupações são separadas, melhorias em uma área (por exemplo, um novo plugin CNI) não forçam um novo modelo de agendamento.
Restrições e prioridades cresceram naturalmente
Consciência de recursos começou com requests e limits, dando sinais significativos ao scheduler em vez de adivinhação. A partir daí, Kubernetes adicionou controles mais ricos — node affinity/anti-affinity, pod affinity, priorities and preemption, taints and tolerations e espalhamento sensível à topologia — todos construídos sobre a mesma base.
Impacto moderno: multi-tenant e colocação custo-eficiente
Essa abordagem permite clusters compartilhados de hoje: times podem isolar serviços críticos com prioridades e taints, enquanto todos se beneficiam de maior utilização. Com melhor bin-packing e controles de topologia, plataformas podem colocar workloads de forma mais custo-eficiente sem sacrificar confiabilidade.
Decisão 9: Extensibilidade sobre “uma maneira embutida”
Construa com mentalidade de estado desejado
Gere um serviço pequeno com APIs estáveis e refine-o como num ciclo de controlador.
O Kubernetes poderia ter saído com uma experiência PaaS completa e opinativa — buildpacks, regras de roteamento de apps, jobs em background, convenções de config e mais. Em vez disso, Joe Beda e a equipe mantiveram o núcleo focado em uma promessa menor: rodar e curar workloads de forma confiável, expô-los e fornecer uma API consistente para automatizar.
Por que o Kubernetes não tentou ser um PaaS completo
Um “PaaS completo” teria imposto um fluxo e um conjunto de trade-offs a todos. O Kubernetes mirou uma fundação mais ampla que pudesse suportar muitos estilos de plataforma — simplicidade tipo Heroku, governança empresarial, pipelines de batch/ML ou controle de infraestrutura — sem trancar uma filosofia de produto.
Os mecanismos de extensibilidade do Kubernetes criaram um jeito controlado de crescer capacidades:
- CRDs (CustomResourceDefinitions) permitem adicionar novos tipos de API (por exemplo,
Certificate ou Database) que parecem nativos.
- Controllers/operators reconciliam esses recursos novos usando o mesmo padrão desejado-estado que os componentes embutidos.
- Admission controllers/webhooks impõem políticas (segurança, nomes, quotas) e alteram defaults na borda da API.
Isso significa que times internos de plataforma e fornecedores podem entregar recursos como complementos, enquanto ainda usam primitivas do Kubernetes como RBAC, namespaces e logs de auditoria.
Benefícios — e o risco principal
Para fornecedores, isso viabiliza produtos diferenciados sem forkar o Kubernetes. Para times internos, isso permite uma “plataforma sobre Kubernetes” adaptada às necessidades da organização.
O trade-off é a proliferação do ecossistema: CRDs demais, ferramentas sobrepondo-se e convenções inconsistentes. Governança — padrões, propriedade, versionamento e regras de deprecação — vira parte do trabalho de plataforma.
As escolhas iniciais do Kubernetes não criaram apenas um scheduler de containers — criaram um kernel de plataforma reutilizável. Por isso muitas plataformas internas de desenvolvedor (IDPs) são, no núcleo, “Kubernetes mais fluxos opinativos”. O modelo declarativo, os controladores e a API consistente tornaram possível construir produtos de nível mais alto — sem reinventar deploy, reconciliação e descoberta de serviços a cada vez.
Kubernetes como um plano de controle compartilhado
Porque a API é a superfície do produto, fornecedores e times de plataforma podem padronizar em um plano de controle e construir experiências diferentes por cima: GitOps, gestão multi-cluster, políticas, catálogos de serviço e automação de deploy. Essa é uma grande razão pela qual o Kubernetes virou o denominador comum para plataformas cloud native: integrações miram a API, não uma UI específica.
O que continuou difícil (realidade do Day-2)
Mesmo com abstrações limpas, o trabalho mais duro ainda é operacional:
- Segurança: identidade, network policy, secrets e confiança na supply chain
- Upgrades: versões do Kubernetes, CRDs e add-ons movendo-se em ritmos diferentes
- Confiabilidade: debugar controladores, más configurações e vizinhos barulhentos
Faça perguntas que revelem maturidade operacional:
- Como são tratados upgrades e qual a história de rollback?
- Quais partes são Kubernetes padrão vs extensões proprietárias?
- Que guardrails existem (política, defaults, templates) para evitar armadilhas?
- Quão observável é o sistema (eventos, logs, trilhas de auditoria) e quem assume incidentes?
Uma boa plataforma reduz carga cognitiva sem esconder o plano de controle subjacente ou tornar saídas (escape hatches) dolorosas.
Uma lente prática: a plataforma ajuda times a ir de “ideia → serviço rodando” sem forçar todo mundo a virar especialista em Kubernetes no dia um? Ferramentas na categoria “vibe-coding” — como Koder.ai — investem nisso, permitindo gerar aplicações reais a partir de chat (web em React, backends em Go com PostgreSQL, mobile em Flutter) e iterar rápido com recursos como modo de planejamento, snapshots e rollback. Seja adotando algo assim ou construindo seu próprio portal, o objetivo é o mesmo: preservar as primitivas fortes do Kubernetes enquanto reduz o overhead de workflow ao redor delas.
Principais conclusões e lições práticas
O Kubernetes pode parecer complicado, mas a maior parte dessa “estranheza” é intencional: é um conjunto de pequenas primitivas desenhadas para se compor em muitos tipos de plataforma.
Esclareça dois equívocos comuns
Primeiro: “Kubernetes é só orquestração do Docker.” Kubernetes não é primariamente sobre iniciar containers. É sobre reconciliar continuamente estado desejado (o que você quer rodando) com estado atual (o que realmente está acontecendo), através de falhas, rollouts e demanda variável.
Segundo: “Se usarmos Kubernetes, tudo vira microservices.” Kubernetes suporta microservices, mas também suporta monólitos, jobs em batch e plataformas internas. As unidades (Pods, Services, labels, controladores e a API) são neutras; suas escolhas arquiteturais não são ditadas pela ferramenta.
De onde vem a complexidade de verdade
As partes difíceis geralmente não são YAML ou Pods — são rede, segurança e uso por múltiplos times: identidade e acesso, gestão de secrets, políticas, ingress, observabilidade, controles da supply chain e criar guardrails para que times publiquem com segurança sem pisar um no outro.
Decisões de nível estratégico que você pode aplicar
Ao planejar, pense nos mesmos bets de design originais:
- Prefira fluxos declarativos e automação que reconcilie deriva.
- Use labels/selectors para manter baixo o acoplamento entre times e componentes.
- Trate a API como um produto: versionamento, convenções e propriedade clara importam.
Um próximo passo prático
Mapeie seus requisitos reais para as primitivas e camadas de plataforma do Kubernetes:
-
Workloads → Pods/Deployments/Jobs
-
Conectividade → Services/Ingress
-
Operações → controladores, políticas e observabilidade
Se estiver avaliando ou padronizando, escreva esse mapeamento e revise com stakeholders — depois construa sua plataforma incrementalmente em torno das lacunas, não em volta de tendências.
Se também busca acelerar o lado “build” (não só o “run”), pense em como seu fluxo de entrega transforma intenção em serviços deployáveis. Para alguns times isso é um conjunto curado de templates; para outros é um fluxo assistido por IA como o Koder.ai que pode produzir um serviço funcional inicial rapidamente e então exportar código-fonte para customização mais profunda — enquanto sua plataforma continua se beneficiando das decisões de design fundamentais do Kubernetes por baixo.