O que evolução de API significa para backends gerados por IA
Evolução de API é o processo contínuo de alterar uma API depois que ela já está sendo usada por clientes reais. Isso pode significar adicionar campos, ajustar regras de validação, melhorar performance ou introduzir novos endpoints. Isso importa especialmente quando clientes estão em produção, porque até uma mudança “pequena” pode quebrar uma versão móvel, um script de integração ou um fluxo de trabalho de parceiro.
Uma mudança é compatível retroativamente se os clientes existentes continuarem funcionando sem atualizações.
Por exemplo, suponha que sua API retorne:
{ \"id\": \"123\", \"status\": \"processing\" }
Adicionar um novo campo opcional é tipicamente compatível:
{ \"id\": \"123\", \"status\": \"processing\", \"estimatedSeconds\": 12 }
Clientes antigos que ignoram campos desconhecidos continuarão funcionando. Por outro lado, renomear status para state, mudar o tipo de um campo (string → number) ou tornar um campo opcional em obrigatório são mudanças que geralmente quebram.
O que “backend gerado por IA” significa aqui
Um backend gerado por IA não é apenas um trecho de código. Na prática inclui:
- Código de API gerado (handlers, controllers, serializers)
- Configuração (rotas, regras de auth, limites de taxa)
- Cola de infraestrutura (migrações, templates de deploy, variáveis de ambiente)
Como a IA pode regenerar partes do sistema rapidamente, a API pode “derivar” a menos que você gerencie mudanças intencionalmente.
Isso é especialmente verdadeiro quando você gera apps inteiros a partir de um fluxo de trabalho orientado por chat. Por exemplo, ferramentas como Koder.ai podem criar aplicações web, servidor e mobile a partir de um chat — frequentemente com React no web, Go + PostgreSQL no backend e Flutter no mobile. Essa velocidade é ótima, mas torna disciplina de contrato (e diff/testes automatizados) ainda mais importante para que uma regeneração não mude acidentalmente o que os clientes dependem.
O que pode ser automatizado vs. o que precisa de revisão humana
A IA pode automatizar muito: produzir specs OpenAPI, atualizar código boilerplate, sugerir defaults seguros e até rascunhar passos de migração. Mas revisão humana continua essencial para decisões que afetam contratos de cliente — quais mudanças são permitidas, quais campos são estáveis e como lidar com regras de negócio e casos de borda. O objetivo é velocidade com comportamento previsível, não velocidade às custas de surpresas.
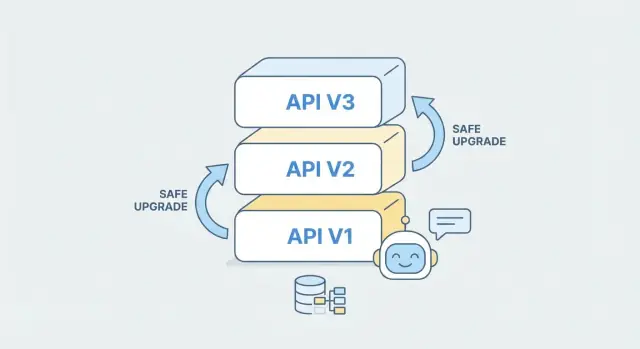
Por que compatibilidade retroativa é prioridade
APIs raramente têm um único “cliente”. Mesmo um produto pequeno pode ter múltiplos consumidores que dependem do mesmo endpoint se comportando do mesmo jeito:
- Uma web app com deploy contínuo
- Um app móvel que atualiza via lojas de apps em cadência mais lenta
- Integrações de parceiros (muitas vezes de times ou empresas diferentes)
- Serviços internos e automações (cobrança, analytics, ferramentas de suporte)
Quando uma API quebra, o custo não é só tempo de desenvolvedor. Usuários móveis podem ficar presos em versões antigas por semanas, então uma quebra pode virar uma cauda longa de erros e tickets de suporte. Parceiros podem ter downtime, perder dados ou interromper fluxos críticos — frequentemente com consequências contratuais ou reputacionais. Serviços internos podem falhar silenciosamente e criar filas bagunçadas (por exemplo, eventos perdidos ou registros incompletos).
Backends gerados por IA adicionam um nuance: o código pode mudar rápida e frequentemente, às vezes em diffs grandes, porque a geração é otimizada para produzir código funcional — não necessariamente para preservar comportamento ao longo do tempo. Essa velocidade é valiosa, mas aumenta o risco de mudanças acidentais que quebram (campos renomeados, defaults diferentes, validações mais rígidas, novos requisitos de auth).
Por isso, compatibilidade retroativa precisa ser uma decisão de produto deliberada, não um hábito de boa vontade. A abordagem prática é definir um processo previsível de mudança onde a API é tratada como uma interface de produto: você pode adicionar capacidades, mas não surpreender clientes existentes.
Um modelo mental útil é tratar o contrato da API (por exemplo, uma spec OpenAPI) como a “fonte da verdade” sobre o que os clientes podem esperar. A geração então vira um detalhe de implementação: você pode regenerar o backend, mas o contrato — e as promessas que ele faz — permanece estável a menos que você versione e comunique mudanças intencionalmente.
O contrato de API como fonte da verdade
Quando um sistema de IA pode gerar ou modificar código backend rapidamente, a única âncora confiável é o contrato da API: a descrição escrita do que os clientes podem chamar, o que devem enviar e o que podem esperar em resposta.
O que “contrato” significa na prática
Um contrato é uma spec legível por máquina, tal como:
- OpenAPI para endpoints REST (paths, parâmetros, auth, formatos de resposta)
- JSON Schema para validar payloads de requisição/resposta (frequentemente embutido no OpenAPI)
- Schema GraphQL para tipos, queries, mutations e depreciações
Esse contrato é o que você promete aos consumidores externos — mesmo que a implementação por trás dele mude.
Contract-first vs. code-first (e onde os geradores se encaixam)
Num fluxo contract-first, você desenha ou atualiza o schema OpenAPI/GraphQL primeiro e depois gera stubs de servidor e implementa a lógica. Isso costuma ser mais seguro para compatibilidade porque mudanças são intencionais e revisáveis.
Num fluxo code-first, o contrato é produzido a partir de anotações no código ou introspecção em runtime. Backends gerados por IA frequentemente tendem ao code-first por padrão, o que é aceitável — desde que a spec gerada seja tratada como um artefato a ser revisado, não como detalhe secundário.
Um híbrido prático é: deixe a IA propor mudanças de código, mas exija que ela também atualize (ou regere) o contrato, e trate diffs do contrato como o principal sinal de mudança.
Coloque o contrato no versionamento
Armazene suas specs de API no mesmo repositório do backend e revise-as via pull requests. Uma regra simples: sem merge a menos que a mudança no contrato seja entendida e aprovada. Isso torna edições incompatíveis visíveis cedo, antes de chegar à produção.
Gere servidor e clientes a partir de uma única fonte
Para reduzir drift, gere stubs de servidor e SDKs de cliente a partir do mesmo contrato. Quando o contrato atualiza, ambos os lados se atualizam juntos — tornando mais difícil que um backend gerado invente comportamento que os clientes não foram construídos para lidar.
Estratégias de versionamento que funcionam na prática
Versionamento de API não é prever todo futuro — é dar aos clientes uma forma clara e estável de continuar funcionando enquanto você melhora o backend. Na prática, a “melhor” estratégia é aquela que seus consumidores entendem instantaneamente e que seu time aplica de forma consistente.
Estratégias comuns (e como elas parecem para clientes)
Versionamento por URL coloca a versão no path, como /v1/orders e /v2/orders. É visível em cada requisição, fácil de depurar e funciona bem com cache e roteamento.
Versionamento por header mantém as URLs limpas e coloca a versão num header (por exemplo, Accept: application/vnd.myapi.v2+json). Pode ser elegante, mas é menos óbvio no troubleshooting e pode ser esquecido em exemplos copiados.
Versionamento por query parameter usa algo tipo /orders?version=2. É direto, mas pode ficar confuso quando proxies ou clientes alteram strings de query, e é mais fácil misturar versões acidentalmente.
Recomendação padrão
Para a maioria dos times — especialmente quando você quer que clientes entendam com facilidade — padronize no versionamento por URL. É a abordagem menos surpreendente, simples de documentar e deixa claro qual versão um SDK, app móvel ou integração está chamando.
Como backends gerados por IA podem ajudar
Ao usar IA para gerar ou estender um backend, trate cada versão como uma unidade separada de “contrato + implementação”. Você pode scaffoldar um novo /v2 a partir de uma spec OpenAPI atualizada enquanto mantém /v1 intacto, e compartilhar lógica de negócio por baixo quando possível. Isso reduz risco: clientes existentes continuam funcionando, enquanto novos clientes adotam v2 intencionalmente.
Documentação e comunicação de mudanças
Versionamento só funciona se a documentação acompanhar. Mantenha docs de API versionadas, exemplos consistentes por versão e publique um changelog que declare claramente o que mudou, o que está deprecated e notas de migração (de preferência com exemplos lado a lado de request/response).
Mudanças compatíveis vs. quebradoras: checklist prático
Quando um backend gerado por IA atualiza, a forma mais segura de pensar em compatibilidade é: “Um cliente existente ainda funciona sem alterações?” Use o checklist abaixo para classificar mudanças antes de liberar.
Geralmente compatíveis (aditivas)
Essas mudanças tipicamente não quebram clientes porque não invalidam o que já é enviado ou esperado:
- Novos campos opcionais na resposta (ex.:
middleName ou metadata). Clientes antigos continuam funcionando desde que não exijam um conjunto exato de campos.
- Novos endpoints (ou novos métodos em um caminho diferente). Nada existente muda.
- Novos campos opcionais na requisição que o servidor pode ignorar ou tratar com defaults.
- Enums expandidas nas respostas (clientes devem tratar valores desconhecidos de forma defensiva).
Geralmente quebradoras (arriscadas)
Trate essas mudanças como breaking, a menos que tenha forte evidência em contrário:
- Remover campos ou endpoints, ou parar de suportar um campo de requisição que clientes enviam atualmente.
- Renomear campos (mesmo mantendo o significado). Muitos clientes mapeiam por nome.
- Mudanças de tipo (string → number, object → array,
nullable → não-nullable).
- Mudanças de comportamento: defaults diferentes, alterações na ordenação, semântica de paginação, regras de validação alteradas.
- Apertar constraints: tornar um campo opcional em obrigatório, reduzir comprimentos máximos, mudar formatos aceitos.
“Leitores tolerantes” como baseline de compatibilidade
Incentive clientes a serem leitores tolerantes: ignorem campos desconhecidos e tratem valores de enum inesperados com robustez. Isso permite que o backend evolua adicionando campos sem forçar atualizações de cliente.
Como geradores de IA devem aplicar as regras
Um gerador pode prevenir mudanças acidentais por política:
- Bloquear merges se diffs OpenAPI incluírem remoção de campos, renomes ou mudanças de tipo sem bump de versão.
- Exigir que qualquer breaking change seja introduzida primeiro como novos campos/endpoints, com avisos de depreciação nos antigos.
- Emitir avisos ao adicionar enums de resposta ou mudar defaults, pedindo revisão de compatibilidade.
Migrações de banco de dados sem quebrar clientes
Mantenha erros consistentes
Defina formatos de erro e códigos de status estáveis, e regenere sem surpreender integrações.
Mudanças na API são o que clientes veem: formatos de request/response, nomes de campos, regras de validação e comportamento de erro. Mudanças de banco de dados são o que seu backend armazena: tabelas, colunas, índices, constraints e formatos de dados. Elas estão relacionadas, mas não são idênticas.
Um erro comum é tratar uma migração de banco como “só interno”. Em backends gerados por IA, a camada de API frequentemente é gerada a partir do esquema (ou fortemente acoplada a ele), então uma mudança de esquema pode se tornar silenciosamente uma mudança de API. É assim que clientes antigos quebram mesmo quando você não pensou em tocar na API.
Padrão seguro de migração (expand → migrate → contract)
Use uma abordagem em passos que mantenha caminhos antigos e novos funcionando durante rollouts:
- Add (Adicionar): introduza novas colunas/tabelas sem remover ou renomear as existentes.
- Backfill: populize novos campos para linhas existentes (em batches, se necessário).
- Dual-write: faça o backend gravar tanto no local antigo quanto no novo.
- Switch reads: comece a ler da nova fonte enquanto ainda faz dual-write.
- Clean up: somente depois de todos os clientes estarem atualizados e o código legado removido, elimine os campos antigos.
Esse padrão evita releases “big bang” e dá opções de rollback.
Defaults, nulls e campos “ausentes”
Clientes antigos frequentemente assumem que um campo é opcional ou tem um significado estável. Ao adicionar uma nova coluna non-null, escolha entre:
- um default no servidor que preserve o comportamento, ou
- permitir NULL temporariamente e tratá-lo explicitamente na camada de API.
Cuidado: um default no DB nem sempre ajuda se seu serializer da API ainda emitir null ou mudar regras de validação.
Migrações geradas por IA: úteis, não automáticas
Ferramentas de IA podem rascunhar scripts de migração e sugerir backfills, mas você ainda precisa de validação humana: confirmar constraints, checar performance (locks, builds de índice) e rodar migrações contra dados de staging para garantir que clientes antigos sigam funcionando.
Feature flags e rollouts graduais para atualizações mais seguras
Feature flags permitem mudar comportamento sem alterar a forma do endpoint. Isso é especialmente útil em backends gerados por IA, onde lógica interna pode ser regenerada ou otimizada frequentemente, mas clientes dependem de requisições e respostas consistentes.
Ao invés de liberar um “grande interruptor”, entregue o novo caminho de código desativado por padrão e ligue-o gradualmente. Se algo der errado, desligue sem precisar de um redeploy de emergência.
Como rollout gradual funciona
Um plano prático geralmente combina três técnicas:
- Canary release: habilite o novo comportamento para uma fatia pequena do tráfego (ou um tenant pequeno) primeiro.
- Rollout por porcentagem: aumente exposição 1% → 10% → 50% → 100%, observando taxas de erro e impacto em clientes.
- Plano de rollback rápido: defina métricas que disparem rollback (ex.: taxa de 5xx, falhas de validação, tickets de suporte) e torne a flag reversível em minutos.
Para APIs, o importante é manter respostas estáveis enquanto experimenta internamente. Você pode trocar implementações (novo modelo, nova lógica de roteamento, novo plano de query) retornando os mesmos status codes, nomes de campos e formatos de erro que o contrato promete. Se precisar adicionar novos dados, prefira campos aditivos que clientes possam ignorar.
Exemplo simples: adotando validação mais rígida gradualmente
Imagine um endpoint POST /orders que atualmente aceita phone em muitos formatos. Você quer aplicar E.164, mas apertar a validação pode quebrar clientes.
Uma abordagem mais segura:
- Publique o validador mais rígido atrás de uma flag (ex.:
strict_phone_validation).
- Comece em modo “report-only”: aceite a requisição, mas logue o que teria falhado. As respostas permanecem inalteradas.
- Canary: habilite a aplicação da validação para usuários internos ou 1% do tráfego.
- Ramping: aumente a porcentagem enquanto monitora picos de erro, tentativas de retry e churn.
- Rollback: reverta imediatamente se as falhas ultrapassarem thresholds.
Esse padrão permite melhorar a qualidade dos dados sem transformar uma API compatível num breaking change acidental.
Depreciação e encerramento: como aposentar versões antigas
Implemente com segurança usando snapshots
Teste alterações na API e reverta rapidamente se uma regeneração alterar o comportamento.
Deprecação é a “saída educada” para comportamentos antigos: você para de incentivar o uso, avisa clientes cedo e dá um caminho previsível para migração. Sunsetting é o passo final: uma versão antiga é desligada numa data publicada. Para backends gerados por IA — onde endpoints e schemas podem evoluir rapidamente — ter um processo rígido de aposentadoria é o que mantém a evolução segura e a confiança intacta.
Defina o que é “major” (Versionamento Semântico)
Use versionamento semântico no nível do contrato de API, não apenas no repositório.
- MAJOR: qualquer breaking change (remoção de campos/endpoints, mudança de significado de um campo, apertar validação, mudança de requisitos de auth, mudança de comportamento padrão que clientes dependem).
- MINOR: adições compatíveis retroativamente (novos campos opcionais, novos endpoints, valores aditivos de enum quando clientes podem ignorar desconhecidos, novos parâmetros de filtro).
- PATCH: correções de bug e melhorias não-funcionais (performance, refactors internos) que não mudam o contrato ou comportamento observável.
Coloque essa definição na documentação e aplique-a consistentemente. Isso evita “majors silenciosos” onde uma mudança auxiliada por IA parece pequena mas quebra um cliente real.
Timeline prática de depreciação
Escolha uma política padrão e mantenha-a para que usuários possam planejar. Uma abordagem comum:
- Anuncie a depreciação: no momento em que a nova versão é lançada.
- Janela de depreciação: mantenha a versão antiga por 90–180 dias (mais tempo para clientes enterprise).
- Data de sunset: publique uma data firme desde o primeiro dia.
Se estiver em dúvida, escolha um período um pouco maior; o custo de manter uma versão por mais tempo geralmente é menor que o custo de migrações emergenciais.
Sinais de depreciação (faça difícil de ignorar)
Use múltiplos canais porque nem todo mundo lê release notes.
- Headers de resposta: ex.:
Deprecation: true e Sunset: Wed, 31 Jul 2026 00:00:00 GMT, além de um Link para docs de migração.
- Notas na docs: banner claro na documentação da versão antiga com data de sunset e checklist de migração (link para /docs/api/v2/migration).
- Warnings em SDKs: avisos em runtime nos SDKs oficiais (+ anotações de depreciação em tempo de compilação quando possível).
Inclua também avisos em changelogs e updates de status para que times de procurement e ops vejam a informação.
Mantenha versões antigas rodando até a data de sunset e então desabilite-as deliberadamente — não via quebra acidental.
No sunset:
- Retorne um erro claro para a versão retirada (ex.:
410 Gone) com uma mensagem apontando para a versão mais nova e a página de migração.
- Mantenha uma página explicativa estável por um tempo (ex.: /docs/deprecations/v1).
O mais importante é tratar o sunset como uma mudança agendada com responsáveis, monitoramento e plano de rollback. Essa disciplina torna possível evoluir frequentemente sem surpreender clientes.
Testes que previnem mudanças acidentais
Código gerado por IA pode mudar rapidamente — e às vezes em lugares inesperados. A forma mais segura de manter clientes funcionando é testar o contrato (o que você promete externamente), não apenas a implementação.
Testes de contrato: comparações spec-a-spec
Uma linha de base prática é um teste de contrato que compara a spec OpenAPI anterior com a nova gerada. Trate isso como um check “antes vs depois”:
- Detecte endpoints removidos, campos renomeados, regras de validação mais rígidas ou mudanças de auth
- Alerte sobre mudanças de códigos de resposta (ex.: 200 → 204, ou mudança no comportamento de 404)
- Capture alterações sutis como tornar um campo opcional em obrigatório
Muitas equipes automatizam um diff do OpenAPI no CI para que nenhuma mudança gerada seja deployada sem revisão. Isso é especialmente útil quando prompts, templates ou versões de modelo mudam.
Testes orientados pelo consumidor (consumer-driven contract testing)
Testes dirigidos pelo consumidor invertem a perspectiva: ao invés do time backend adivinhar como clientes usam a API, cada cliente compartilha um conjunto pequeno de expectativas (as requisições que envia e as respostas das quais depende). O backend deve provar que ainda satisfaz essas expectativas antes do release.
Isso funciona bem quando você tem múltiplos consumidores (web, mobile, parceiros) e quer atualizações sem coordenar cada deploy.
Testes de regressão para formatos de resposta e erros
Adicione testes de regressão que travem:
- Formato JSON de resposta (nomes de campos, tipos, aninhamento)
- Defaults e nullability (ausente vs. null)
- Semântica de paginação e ordenação
- Formato de erros: códigos estáveis, estrutura de mensagem e campos de erro de validação
Se você publica um schema de erro, teste-o explicitamente — clientes frequentemente fazem parse de erros mais do que gostaríamos.
Gates de CI antes do rollout
Combine checks de diff OpenAPI, contratos consumidores e testes de regressão de formato/erro em um gate de CI. Se uma mudança gerada falhar, a correção normalmente é ajustar o prompt, regras de geração ou adicionar uma camada de compatibilidade — antes que usuários notem.
Tratamento de erros e estabilidade de comportamento entre versões
Quando clientes integram com sua API, eles normalmente não “leem” mensagens de erro — reagem a formas e códigos de erro. Um erro de digitação numa mensagem humana é incômodo, mas sobrevivível; mudar um status code, remover um campo ou renomear um identificador de erro pode transformar uma situação recuperável em um checkout quebrado, sync falho ou loop infinito de retry.
Erros estáveis: priorize legibilidade por máquina
Mire em manter um envelope de erro consistente (a estrutura JSON) e um conjunto estável de identificadores que clientes possam usar. Por exemplo, se você retorna { code, message, details, request_id }, não remova ou renomeie esses campos em uma nova versão. Você pode melhorar a redação de message livremente, mas mantenha a semântica de code estável e documentada.
Se você já tem múltiplos formatos em uso, resista à vontade de “limpar” tudo no lugar. Em vez disso, adicione um novo formato atrás de um boundary de versão ou mecanismo de negociação (ex.: header Accept), enquanto continua a suportar o antigo.
Adicionar novos códigos de erro sem quebrar clientes antigos
Novos códigos às vezes são necessários (novas regras de validação, checagens de autorização), mas adicione-os de forma que não surpreendam integrações existentes:
- Mantenha os códigos antigos válidos: se clientes já lidam com
VALIDATION_ERROR, não substitua de repente por INVALID_FIELD.
- Introduza códigos novos como variantes mais específicas: retorne o novo
code, mas inclua dicas compatíveis em details (ou mantenha mapeamento para o código generalizado antigo para versões antigas).
- Documente uma regra de fallback: instrua clientes a tratar códigos desconhecidos como uma classe genérica baseada no status HTTP (400/401/403/404/409/429/500) e ainda exibir
message.
Nunca altere o significado de um código existente. Se NOT_FOUND significava “recurso não existe”, não comece a usá-lo para “acesso negado” (isso seria 403).
Estabilidade de comportamento: defaults não devem mudar silenciosamente
Compatibilidade retroativa também significa “mesma requisição, mesmo resultado”. Mudanças sutis de defaults podem quebrar clientes que nunca definiram explicitamente parâmetros.
Paginação: não mude limit, page_size ou comportamento de cursor padrão sem versionamento. Trocar paginação baseada em página por cursor é breaking a menos que mantenha ambos caminhos.
Ordenação: a ordenação padrão deve ser estável. Mudar de created_at desc para relevance desc pode reordenar listas e quebrar suposições de UI ou sync incremental.
Filtragem: evite alterar filtros implícitos (ex.: excluir “inativos” por padrão). Se precisar de novo comportamento, adicione uma flag explícita como include_inactive=true ou status=all.
Alguns problemas de compatibilidade não são sobre endpoints — são sobre interpretação.
- Fusos horários: especifique se timestamps estão em UTC, inclua offsets e mantenha consistência. Mudar de horário local para UTC sem aviso pode causar eventos duplicados ou faltantes.
- Formatos numéricos: números JSON são unívocos, mas strings que parecem números (moeda, decimais) podem variar. Não mude
"9.99" para 9.99 (ou vice-versa) no lugar.
- Defaults booleanos: defaults como
include_deleted=false ou send_email=true não devem inverter. Se precisar mudar um default, exija que o cliente opte por ele via novo parâmetro.
Para backends gerados por IA em particular, trave esses comportamentos com contratos explícitos e testes: o modelo pode “melhorar” respostas a menos que você imponha estabilidade como requisito de primeira classe.
Observabilidade: monitorando compatibilidade no mundo real
Atualize clientes com o backend
Gere apps web, server e mobile juntos para que clientes e backend evoluam em sincronia.
Compatibilidade retroativa não é algo que você verifica uma vez e esquece. Com backends gerados por IA, o comportamento pode mudar mais rápido do que em sistemas feitos à mão, então você precisa de loops de feedback que mostrem quem está usando o quê e se uma atualização está prejudicando clientes.
Acompanhe métricas por versão de API (e por endpoint)
Comece marcando cada requisição com uma versão de API explícita (path como /v1/..., header X-Api-Version, ou schema negociado). Depois colete métricas segmentadas por versão:
- Uso: requisições por minuto por versão/rota
- Latência: p50/p95 por versão (uma mudança compatível pode ainda ser lenta)
- Taxas de erro: 4xx vs 5xx por versão (picos revelam quebras ocultas)
Isso te permite notar, por exemplo, que /v1/orders é 5% do tráfego mas 70% dos erros após um rollout.
Detecte clientes que ainda usam campos/endpoints antigos
Instrua seu gateway/API a logar o que os clientes realmente enviam e quais rotas estão chamando:
- Requisições batendo em endpoints depreciados (ex.:
/v1/legacy-search)
- Payloads contendo campos depreciados
- Requisições sem novos campos opcionais que algum código gerado pode assumir presentes
Se você controla SDKs, adicione um identificador leve do cliente + versão do SDK no header para identificar integrações desatualizadas.
Use logs e tracing para localizar a mudança
Quando erros sobem, queira responder: “Qual deploy mudou o comportamento?” Correlacione picos com:
- identificadores de release (commit hash/build id)
- logs estruturados que incluam versão, rota e falhas de validação
- traces distribuídos mostrando onde a latência/exceção apareceu (gateway → handler → BD)
Rollback adequado para deploys gerados
Mantenha rollbacks simples: sempre consiga redeployar o artefato gerado anterior (container/image) e reverter tráfego via roteador. Evite rollbacks que requerem reversão de dados; se houver mudanças de esquema, prefira migrações aditivas para que versões antigas sigam funcionando enquanto você reverte a camada de API.
Se sua plataforma suportar snapshots de ambiente e rollback rápido, use-os. Por exemplo, algumas ferramentas incluem snapshots e rollback como parte do fluxo, o que se encaixa naturalmente com o padrão “expand → migrate → contract” e rollouts graduais de API.
Um workflow repetível para evoluir APIs geradas por IA
Backends gerados por IA podem mudar rapidamente — novos endpoints aparecem, modelos mudam e validações apertam. A forma mais segura de manter clientes estáveis é tratar mudanças de API como um pequeno processo de release repetível, não como edições pontuais.
O workflow (proposta → sunset)
- Propor a mudança
Escreva o “porquê”, o comportamento pretendido e o impacto exato no contrato (campos, tipos, obrigatório/opcional, códigos de erro).
- Classificar
Marque como compatível (seguro) ou breaking (requer mudanças de cliente). Se tiver dúvida, assuma breaking e desenhe um caminho de compatibilidade.
- Desenhar o plano de compatibilidade
Decida como suportará clientes antigos: aliases, dual-write/dual-read, valores padrão, parsing tolerante ou uma nova versão.
- Implementar atrás de guardrails
Adicione a mudança com feature flags ou configuração para poder fazer rollout gradual e rollback rápido.
- Testar o contrato
Rode checks automatizados de contrato (ex.: diff OpenAPI) mais testes “golden” com requests/responses de clientes conhecidos para capturar drift.
- Liberar com documentação
Cada release deve incluir: docs atualizadas em /docs, nota curta de migração quando relevante e uma entrada no changelog declarando o que mudou e se é compatível.
- Depreciar e remover conforme cronograma
Anuncie depreciações com datas, adicione headers/warnings, meça uso restante e remova após a janela de sunset.
Mini-exemplo: renomeando um campo sem quebrar clientes
Para renomear last_name para family_name:
- Requisições: aceite ambos os campos; se ambos vierem, prefira
family_name.
- Respostas: retorne ambos durante um período de transição (ou retorne
family_name e mantenha last_name como alias).
- Armazenamento: mapeie os dois para a mesma coluna interna.
- Docs + changelog: documente o novo nome, marque
last_name como deprecated e publique uma data de remoção.
Se sua oferta inclui suporte por plano ou garantia de suporte de versões longas, destaque isso em /pricing.