26 de dez. de 2025·8 min
Ferramentas internas para desenvolvedores com Claude Code: painéis CLI seguros
Construa ferramentas internas com Claude Code para resolver busca de logs, toggles de recursos e verificações de dados, aplicando o princípio do menor privilégio e limites claros.
Qual problema sua ferramenta interna realmente deve resolver
Ferramentas internas costumam começar como um atalho: um comando ou uma página que economiza 20 minutos da equipe durante um incidente. O risco é que o mesmo atalho se transforme silenciosamente em uma porta dos fundos privilegiada se você não definir o problema e os limites desde o início.
Times geralmente recorrem a uma ferramenta quando a mesma dor se repete todo dia, por exemplo:
- Busca de logs lenta, inconsistente ou espalhada por vários sistemas
- Feature toggles que exigem uma edição manual arriscada ou escrita direta no banco
- Verificações de dados que dependem de uma pessoa executando um script do laptop
- Tarefas de on-call simples, mas fáceis de errar às 2 da manhã
Esses problemas parecem pequenos até a ferramenta poder ler logs de produção, consultar dados de clientes ou virar uma flag. Aí você passa a lidar com controle de acesso, trilhas de auditoria e gravações acidentais. Uma ferramenta “só para engenheiros” ainda pode causar uma interrupção se executar uma consulta ampla, atingir o ambiente errado ou alterar estado sem uma etapa clara de confirmação.
Defina sucesso em termos estreitos e mensuráveis: operações mais rápidas sem ampliar permissões. Uma boa ferramenta interna remove passos, não salvaguardas. Em vez de dar acesso amplo ao banco de dados para todos verificarem um problema de cobrança suspeito, construa uma ferramenta que responda a uma pergunta: “Mostre os eventos de cobrança falhos de hoje para a conta X”, usando credenciais somente leitura e com escopo.
Antes de escolher uma interface, decida o que as pessoas precisam no momento. Um CLI é ótimo para tarefas repetíveis durante o on-call. Um painel web é melhor quando os resultados precisam de contexto e visibilidade compartilhada. Às vezes você entrega ambos, mas somente se forem visões finas sobre as mesmas operações protegidas. O objetivo é uma capacidade bem definida, não uma nova superfície de administração.
Escolha uma única dor e mantenha o escopo pequeno
A maneira mais rápida de tornar uma ferramenta interna útil (e segura) é escolher um trabalho claro e fazê-lo bem. Se ela tentar lidar com logs, feature flags, correções de dados e gerenciamento de usuários no primeiro dia, crescerá comportamentos ocultos e surpreenderá as pessoas.
Comece com uma única pergunta que um usuário faz durante o trabalho real. Por exemplo: “Dado um request ID, mostre o erro e as linhas ao redor entre serviços.” Isso é estreito, testável e fácil de explicar.
Seja explícito sobre para quem a ferramenta é. Um desenvolvedor depurando localmente precisa de opções diferentes de alguém em plantão, e ambos diferem de suporte ou um analista. Quando você mistura públicos, acaba adicionando comandos “poderosos” que a maioria nunca deveria tocar.
Escreva entradas e saídas como um pequeno contrato.
Entradas devem ser explícitas: request ID, intervalo de tempo, ambiente. Saídas devem ser previsíveis: linhas correspondentes, nome do serviço, timestamp, contagem. Evite efeitos colaterais ocultos como “também limpa cache” ou “também tenta novamente o job”. Essas são as funcionalidades que causam acidentes.
Padrão para somente leitura. Você ainda pode tornar a ferramenta valiosa com busca, diff, validação e relatórios. Adicione ações de escrita apenas quando puder nomear um cenário real que precise disso e puder restringi-la fortemente.
Uma declaração de escopo simples que mantém as equipes honestas:
- Uma tarefa principal, uma tela ou comando principal
- Uma fonte de dados (ou uma visão lógica), não “tudo”
- Flags explícitas para ambiente e intervalo de tempo
- Primeiro somente leitura, sem ações em background
- Se houver escritas, exigir confirmação e registrar cada alteração
Mapeie fontes de dados e operações sensíveis cedo
Antes do Claude Code escrever qualquer coisa, escreva o que a ferramenta vai tocar. A maioria dos problemas de segurança e confiabilidade aparece aqui, não na UI. Trate esse mapeamento como um contrato: ele diz aos revisores o que está no escopo e o que está fora.
Comece com um inventário concreto de fontes de dados e donos. Por exemplo: logs (app, gateway, auth) e onde ficam; as tabelas ou views exatas do banco que a ferramenta pode consultar; sua loja de feature flags e regras de nomeação; métricas e traces e quais labels são seguros para filtrar; e se você planeja escrever notas em sistemas de ticket ou incidente.
Depois nomeie as operações que a ferramenta tem permissão para executar. Evite “admin” como permissão. Em vez disso, defina verbos auditáveis. Exemplos comuns incluem: busca e exportação somente leitura (com limites), anotar (adicionar nota sem editar histórico), alternar flags específicas com TTL, backfills limitados (intervalo de data e contagem de registros) e modos dry-run que mostram impacto sem mudar dados.
Campos sensíveis precisam de tratamento explícito. Decida o que deve ser mascarado (e-mails, tokens, IDs de sessão, chaves de API, identificadores de clientes) e o que pode ser mostrado apenas de forma truncada. Por exemplo: mostrar os últimos 4 caracteres de um ID, ou hasheá-lo consistentemente para que as pessoas possam correlacionar eventos sem ver o valor bruto.
Por fim, entenda regras de retenção e auditoria. Se um usuário executa uma consulta ou alterna uma flag, registre quem fez, quando, quais filtros foram usados e a contagem de resultados. Mantenha logs de auditoria mais tempo que logs de app. Mesmo uma regra simples como “consultas retidas 30 dias, registros de auditoria 1 ano” evita debates dolorosos durante um incidente.
Modelo de acesso de menor privilégio que permanece simples
Menor privilégio é mais fácil quando você mantém o modelo sem frescuras. Comece listando o que a ferramenta pode fazer, depois rotule cada ação como somente leitura ou escrita. A maioria das ferramentas internas precisa de leitura para a maioria das pessoas.
Para um painel web, use seu sistema de identidade existente (SSO com OAuth). Evite senhas locais. Para um CLI, prefira tokens de curta duração que expiram rápido e escopem apenas as ações que o usuário precisa. Tokens compartilhados de longa duração tendem a ser colados em tickets, salvos no histórico do shell ou copiados para máquinas pessoais.
Mantenha o RBAC pequeno. Se você precisa de mais de alguns papéis, a ferramenta provavelmente está fazendo demais. Muitas equipes vão bem com três:
- Viewer: somente leitura, padrões seguros
- Operator: leitura mais um pequeno conjunto de ações de baixo risco
- Admin: ações de alto risco, usado raramente
Separe ambientes cedo, mesmo que a UI pareça a mesma. Torne difícil “acidentalmente fazer em prod.” Use credenciais diferentes por ambiente, arquivos de configuração diferentes e endpoints API distintos. Se um usuário só dá suporte ao staging, ele não deveria nem conseguir autenticar em produção.
Ações de alto risco merecem uma etapa de aprovação. Pense em deletar dados, mudar feature flags, reiniciar serviços ou rodar queries pesadas. Adicione uma checagem por segunda pessoa quando o blast radius for grande. Padrões práticos incluem confirmações digitadas que incluam o alvo (nome do serviço e ambiente), registrar quem pediu e quem aprovou, e adicionar um pequeno atraso ou janela agendada para as operações mais perigosas.
Se você gera a ferramenta com Claude Code, faça uma regra: cada endpoint e comando declara seu papel requerido desde o início. Esse hábito mantém as permissões revisáveis conforme a ferramenta cresce.
Guardrails que previnem acidentes e consultas ruins
Planeje antes de construir
Mapeie entradas, saídas e permissões antes do código ser gerado.
O modo de falha mais comum para ferramentas internas não é um atacante. É um colega cansado executando o “comando certo” com os inputs errados. Trate guardrails como funcionalidades de produto, não como acabamento.
Padrões de segurança
Comece com uma postura segura: somente leitura por padrão. Mesmo que o usuário seja admin, a ferramenta deve abrir em um modo que só busque dados. Faça ações de escrita opt-in e óbvias.
Para qualquer operação que mude estado (alternar uma flag, backfill, deletar um registro), exija type-to-confirm explícito. “Tem certeza? y/N” é fácil demais de cair em muscle-memory. Peça ao usuário para redigitar algo específico, como o nome do ambiente mais o ID alvo.
Validação de entrada rígida previne a maioria dos desastres. Aceite apenas as formas que você realmente suporta (IDs, datas, ambientes) e rejeite o resto cedo. Para buscas, limite poder: imponha limites de resultados, faixas de data sensatas e use uma abordagem de allow-list em vez de deixar padrões arbitrários atingirem seu armazenamento de logs.
Para evitar queries fora de controle, adicione timeouts e limites de taxa. Uma ferramenta segura falha rápido e explica o motivo, em vez de ficar pendurada e martelando seu banco.
Um conjunto de guardrails que funciona bem na prática:
- Padrão só leitura, com um botão claro de “modo de escrita”
- Type-to-confirm para escritas (incluir env + alvo)
- Validação estrita para IDs, datas, limites e padrões permitidos
- Timeouts de query mais limites por usuário
- Mascaramento de segredos na saída e nos próprios logs da ferramenta
Higiene da saída
Presuma que a saída da ferramenta será copiada para tickets e chat. Mascarar segredos por padrão (tokens, cookies, chaves de API e e-mails quando necessário). Também limpe o que você armazena: logs de auditoria devem registrar o que foi tentado, não os dados brutos retornados.
Para um dashboard de busca de logs, retorne uma prévia curta e uma contagem, não payloads completos. Se alguém realmente precisar do evento completo, faça disso uma ação separada e claramente protegida com sua própria confirmação.
Como trabalhar com Claude Code sem perder o controle
Trate o Claude Code como um colega júnior rápido: útil, mas não um leitor da sua mente. Seu trabalho é manter o trabalho limitado, revisável e fácil de desfazer. Essa é a diferença entre ferramentas que parecem seguras e ferramentas que te surpreendem às 2 da manhã.
Comece com uma especificação que o modelo possa seguir
Antes de pedir código, escreva uma pequena especificação que nomeie a ação do usuário e o resultado esperado. Mantenha sobre comportamento, não detalhes de framework. Uma boa especificação geralmente cabe meia página e cobre:
- Comandos ou telas (nomes exatos)
- Entradas (flags, campos, formatos, limites)
- Saídas (o que aparece, o que é salvo)
- Casos de erro (entrada inválida, timeouts, resultados vazios)
- Checagens de permissão (o que acontece quando o acesso é negado)
Por exemplo, se você está construindo um CLI de busca de logs, defina um comando completo: logs search --service api --since 30m --text \"timeout\", com um limite rígido de resultados e uma mensagem clara de “sem acesso”.
Peça pequenos incrementos que você possa verificar
Solicite primeiro um esqueleto: wiring do CLI, carregamento de config e uma chamada de dados stubada. Depois peça exatamente uma funcionalidade completa (incluindo validação e erros). Diffs pequenos tornam reviews reais.
Após cada mudança, peça uma explicação em linguagem simples do que mudou e por quê. Se a explicação não bater com o diff, pare e reescreva o comportamento e as restrições de segurança.
Gere testes cedo, antes de adicionar mais funcionalidades. No mínimo, cubra o caminho feliz, entradas inválidas (datas ruins, flags faltando), permissão negada, resultados vazios e timeouts ou limites do backend.
CLI vs painel web: escolher a interface certa
Um CLI e um painel web interno podem resolver o mesmo problema, mas falham de maneiras diferentes. Escolha a interface que torna o caminho seguro o caminho mais fácil.
Um CLI é geralmente melhor quando velocidade importa e o usuário já sabe o que quer. Também se encaixa bem em fluxos somente leitura, porque você pode manter permissões estreitas e evitar botões que acionem escritas acidentais.
Um CLI é uma escolha forte para consultas rápidas de on-call, scripts e automação, trilhas de auditoria explícitas (cada comando fica escrito) e rollout de baixo overhead (um binário, uma config).
Um painel web é melhor quando você precisa de visibilidade compartilhada ou passos guiados. Ele pode reduzir erros induzindo padrões seguros como intervalos de tempo, ambientes e ações pré-aprovadas. Dashboards também funcionam bem para visões de status do time, ações protegidas que exigem confirmação e explicações embutidas do que um botão faz.
Quando possível, use o mesmo backend API para ambos. Coloque auth, limites de taxa, limites de query e logs de auditoria nessa API, não na UI. Assim o CLI e o painel se tornam clientes diferentes com ergonomias distintas.
Também decida onde ele roda, porque isso muda seu risco. Um CLI no laptop pode vazar tokens. Executá-lo em um bastion host ou em um cluster interno pode reduzir exposição e facilitar logs e aplicação de políticas.
Exemplo: para busca de logs, um CLI é ótimo para um engenheiro em on-call puxar os últimos 10 minutos de um serviço. Um painel é melhor para uma sala de incidente compartilhada onde todos precisam da mesma visão filtrada, mais uma ação guiada “exportar para postmortem” que é checada por permissão.
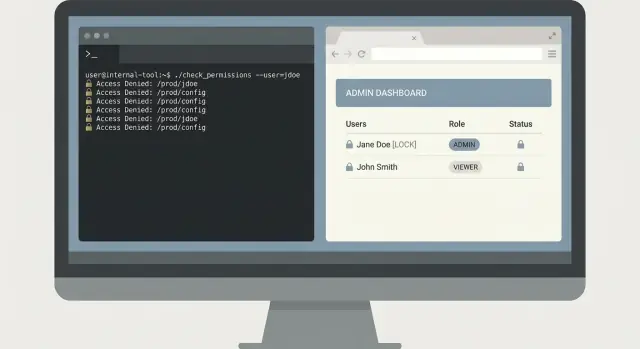
Um exemplo realista: ferramenta de busca de logs para on-call
Recupere-se de deploys ruins
Restaure rapidamente se uma versão nova se comportar diferente do esperado.
São 02:10 e o on-call recebe um relato: “Clicar em Pagar às vezes falha para um cliente.” O suporte tem uma captura de tela com um request ID, mas ninguém quer colar consultas aleatórias no sistema de logs com permissões de admin.
Um CLI pequeno pode resolver isso com segurança. A chave é manter estreito: achar o erro rápido, mostrar só o necessário e não modificar dados de produção.
Um fluxo mínimo de CLI
Comece com um comando que force limites de tempo e um identificador específico. Exija um request ID e uma janela de tempo, e padronize para uma janela curta.
oncall-logs search --request-id req_123 --since 30m --until now
Retorne um resumo primeiro: nome do serviço, classe do erro, contagem e as 3 mensagens mais relevantes. Depois permita um passo explícito de expandir que imprime linhas completas de log somente quando o usuário solicitar.
oncall-logs show --request-id req_123 --limit 20
Esse design em dois passos evita despejos acidentais de dados. Também facilita revisões porque a ferramenta tem um caminho claro e seguro por padrão.
Ação opcional de acompanhamento (sem escritas)
On-call frequentemente precisa deixar um rastro para a próxima pessoa. Em vez de escrever no banco, adicione uma ação opcional que gere o payload de nota do ticket ou aplique uma tag no sistema de incidentes, mas nunca toque nos registros de clientes.
Para manter menor privilégio, o CLI deve usar um token de logs somente leitura e um token separado e escopado para a ação de ticket/tag.
Armazene um registro de auditoria para cada execução: quem executou, qual request ID, quais limites de tempo foram usados e se os detalhes foram expandidos. Esse log de auditoria é sua rede de segurança quando algo der errado ou quando o acesso precisar ser revisado.
Erros comuns que criam riscos de segurança e confiabilidade
Pequenas ferramentas internas muitas vezes começam como “apenas um ajudante rápido.” É exatamente por isso que acabam com padrões arriscados. A maneira mais rápida de perder confiança é um incidente ruim, como uma ferramenta que deleta dados quando deveria ser só leitura.
Os erros que aparecem com mais frequência:
- Dar à ferramenta permissão de escrita no banco de produção quando ela só precisa ler, e depois assumir “vamos ter cuidado”
- Pular trilha de auditoria, de modo que depois você não consegue responder quem executou um comando, quais inputs usou e o que mudou
- Permitir SQL livre, regex ou filtros ad-hoc que acidentalmente varrem tabelas grandes ou logs e derrubam sistemas
- Misturar ambientes de forma que ações em staging atinjam produção porque configs, tokens ou URLs base são compartilhados
- Imprimir segredos em um terminal, console do navegador ou logs, e depois esquecer que essas saídas são copiadas para tickets e chat
Uma falha realista se parece com isto: um engenheiro em on-call usa um CLI de busca de logs durante um incidente. A ferramenta aceita qualquer regex e manda para o backend de logs. Um padrão caro roda por horas de logs de alto volume, gera custos e deixa as buscas lentas para todos. Na mesma sessão, o CLI imprime um token de API em saída de debug, e ele é colado num documento público do incidente.
Padrões seguros que previnem a maioria dos incidentes
Trate só leitura como uma fronteira real de segurança, não um hábito. Use credenciais separadas por ambiente e contas de serviço separadas por ferramenta.
Alguns guardrails fazem a maior parte do trabalho:
- Use consultas allow-listed (ou templates) em vez de SQL cru, e limite intervalos de tempo e contagens de linhas
- Logue cada ação com um request ID, identidade do usuário, ambiente alvo e parâmetros exatos
- Exija seleção explícita do ambiente, com uma confirmação alta para produção
- Reduza segredos por padrão e desative saída de debug a menos que uma flag privilegiada seja usada
Se a ferramenta não puder fazer algo perigoso por projeto, sua equipe não precisará confiar na atenção perfeita durante um incidente às 3 da manhã.
Checklist rápido antes de liberar a ferramenta
Vá do desenvolvimento ao deploy
Implemente e hospede sua ferramenta interna quando estiver pronto para compartilhá-la com a equipe.
Antes de sua ferramenta interna chegar a usuários reais (especialmente on-call), trate-a como um sistema de produção. Confirme que acesso, permissões e limites de segurança são reais, não implícitos.
Comece por acesso e permissões. Muitos acidentes acontecem porque acesso “temporário” vira permanente, ou porque uma ferramenta ganha silenciosamente poder de escrita ao longo do tempo.
- Auth e offboarding: confirme quem pode entrar, como o acesso é concedido e como é revogado no mesmo dia que alguém muda de time
- Papéis permanecem pequenos: mantenha 2-3 papéis no máximo (viewer, operator, admin) e escreva o que cada um pode fazer
- Somente leitura por padrão: torne a visualização o caminho padrão e exija um papel explícito para qualquer alteração de dados
- Tratamento de segredos: armazene tokens e chaves fora do repositório e verifique que a ferramenta nunca os imprime em logs ou mensagens de erro
- Fluxo de quebra-glass: se precisar de acesso de emergência, torne-o com tempo limitado e registrado
Depois valide os guardrails que previnem erros comuns:
- Confirmações para ações arriscadas: exija confirmações digitadas para deletes, backfills ou mudanças de configuração
- Limites e timeouts: limite tamanho de resultados, imponha janelas de tempo e timeouts para que uma requisição ruim não rode para sempre
- Validação de entrada: valide IDs, datas e nomes de ambientes; rejeite qualquer coisa que pareça “rodar em todos os lugares”
- Logs de auditoria: registre quem fez o quê, quando e de onde; facilite a busca desses logs durante incidentes
- Métricas básicas e erros: monitore taxa de sucesso, latência e principais tipos de erro para perceber falhas cedo
Faça controle de mudanças como faria para qualquer serviço: revisão por pares, alguns testes focados nos caminhos perigosos e um plano de rollback (incluindo um jeito de desabilitar a ferramenta rapidamente se comportar mal).
Próximos passos: liberar com segurança e melhorar continuamente
Trate o primeiro release como um experimento controlado. Comece com um time, um fluxo de trabalho e um pequeno conjunto de tarefas reais. Uma ferramenta de busca de logs para on-call é um piloto sólido porque você pode medir tempo economizado e identificar queries arriscadas rapidamente.
Mantenha o rollout previsível: pilote com 3 a 10 usuários, comece em staging, gateie acesso com papéis de menor privilégio (não tokens compartilhados), estabeleça limites de uso e registre logs de auditoria para cada comando ou clique de botão. Verifique que você pode reverter configurações e mudanças de permissão rapidamente.
Escreva o contrato da ferramenta em linguagem simples. Liste cada comando (ou ação do painel), os parâmetros permitidos, o que significa sucesso e o que os erros significam. Pessoas deixam de confiar em ferramentas internas quando as saídas parecem ambíguas, mesmo que o código esteja correto.
Adicione um ciclo de feedback que você realmente verifique. Monitore quais queries são lentas, quais filtros são comuns e quais opções confundem as pessoas. Quando você vê gambiarras frequentes, geralmente é sinal de que a interface está faltando um padrão seguro.
Manutenção precisa de um dono e de um cronograma. Decida quem atualiza dependências, quem rotaciona credenciais e quem é acionado se a ferramenta quebrar durante um incidente. Reveja mudanças geradas por IA como revisaria um serviço de produção: diffs de permissões, segurança de queries e logging.
Se sua equipe prefere iteração via chat, Koder.ai (koder.ai) pode ser uma maneira prática de gerar um pequeno CLI ou painel a partir de uma conversa, manter snapshots de estados conhecidos e reverter rapidamente quando uma mudança introduzir risco.