23 de out. de 2025·6 min
Filtragem no servidor vs no cliente: checklist de decisão
Checklist para decidir entre filtragem no servidor ou no cliente com base em tamanho dos dados, latência, permissões e cache — sem vazamentos de UI ou lentidão.
Checklist para decidir entre filtragem no servidor ou no cliente com base em tamanho dos dados, latência, permissões e cache — sem vazamentos de UI ou lentidão.
Filtrar em uma UI é mais que uma caixa de busca única. Normalmente inclui algumas ações relacionadas que mudam o que o usuário vê: busca de texto (nome, email, ID do pedido), facetas (status, responsável, intervalo de datas, tags) e ordenação (mais recentes, maior valor, última atividade).
A questão chave não é qual técnica é “melhor”. É onde o conjunto completo de dados vive e quem tem permissão para acessá‑lo. Se o navegador recebe registros que o usuário não deveria ver, a UI pode expor dados sensíveis mesmo que você osculte visualmente.
A maioria dos debates sobre filtragem no servidor vs no cliente são, na prática, reações a duas falhas que os usuários percebem imediatamente:
Há um terceiro problema que gera muitos relatórios de bug: resultados inconsistentes. Se alguns filtros rodam no cliente e outros no servidor, usuários veem contagens, páginas e totais que não batem. Isso quebra a confiança rápido, especialmente em listas paginadas.
Um padrão prático é simples: se o usuário não pode acessar o conjunto completo, filtre no servidor. Se pode e o conjunto é pequeno o bastante para carregar rápido, a filtragem no cliente pode funcionar bem.
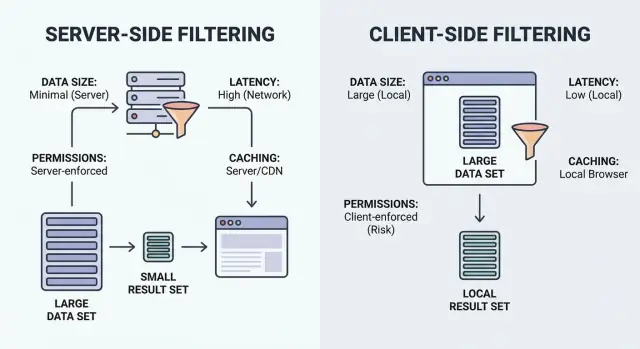
Filtrar é só “mostre os itens que combinam”. A pergunta é onde a comparação acontece: no navegador do usuário (cliente) ou no seu backend (servidor).
Filtragem no cliente roda no navegador. O app baixa um conjunto de registros (frequentemente JSON) e aplica filtros localmente. Pode parecer instantâneo depois que os dados são carregados, mas só funciona quando o conjunto é pequeno o suficiente para enviar e seguro o suficiente para expor.
Filtragem no servidor roda no backend. O navegador envia entradas de filtro (como status=open, owner=me, createdAfter=Jan 1) e o servidor retorna apenas os resultados correspondentes. Na prática, geralmente é um endpoint de API que aceita filtros, monta uma query no banco e retorna uma lista paginada mais totais.
Um modelo mental simples:
Configurações híbridas são comuns. Um bom padrão é forçar filtros “grandes” no servidor (permissões, propriedade, intervalo de datas, busca) e usar toggles pequenos apenas na UI (ocultar arquivados, chips rápidos de tags, visibilidade de colunas) sem outra requisição.
Ordenação, paginação e busca geralmente pertencem à mesma decisão. Eles afetam o tamanho do payload, a sensação do usuário e quais dados você está expondo.
Comece com a pergunta prática: quanto você enviaria ao navegador se filtrar no cliente? Se a resposta honesta for “mais do que algumas telas”, você pagará isso em tempo de download, uso de memória e interações mais lentas.
Você não precisa de estimativas precisas. Pegue a ordem de grandeza: quantas linhas o usuário pode ver e qual o tamanho médio de uma linha? Uma lista de 500 itens com alguns campos curtos é muito diferente de 50.000 itens onde cada linha inclui notas longas, rich text ou objetos aninhados.
Registros “largos” são os assassinos silenciosos do payload. Uma tabela pode parecer pequena em contagem de linhas, mas pesada se cada linha contém muitos campos, strings longas ou dados juntados (contato + empresa + última atividade + endereço completo + tags). Mesmo mostrando só três colunas, times frequentemente enviam “tudo, por precaução”, e o payload infla.
Pense também no crescimento. Um dataset que está bom hoje pode ficar pesado em poucos meses. Se os dados crescem rápido, trate a filtragem no cliente como um atalho temporário, não como padrão.
Regras práticas:
Esse último ponto importa além do desempenho. “Podemos enviar o conjunto completo ao navegador?” também é uma questão de segurança. Se a resposta não for um sim confiante, não envie.
Escolhas de filtragem frequentemente falham na sensação, não na correção. Usuários não medem milissegundos. Eles notam pausas, flicker e resultados que pulam enquanto digitam.
O tempo pode desaparecer em lugares distintos:
Defina o que “rápido o suficiente” significa para esta tela. Uma view de lista pode precisar de digitação responsiva e scroll suave, enquanto uma página de relatório tolera uma espera curta desde que o primeiro resultado apareça rápido.
Não julgue só pela Wi‑Fi do escritório. Em conexões lentas, filtragem no cliente pode parecer ótima depois do primeiro carregamento, mas esse primeiro carregamento pode ser demorado. Filtragem no servidor mantém payloads pequenos, mas pode parecer lenta se você disparar uma requisição a cada tecla.
Projete pensando na entrada humana. Use debounce ao digitar. Para grandes conjuntos, use carregamento progressivo para que a página mostre algo rapidamente e permaneça suave enquanto o usuário rola.
Permissões devem decidir sua abordagem de filtragem mais do que a velocidade. Se o navegador alguma vez receber dados que um usuário não pode ver, você já tem um problema, mesmo que os esconda atrás de um botão desabilitado ou de uma coluna colapsada.
Comece nomeando o que é sensível nessa tela. Alguns campos são óbvios (emails, telefones, endereços). Outros são fáceis de esquecer: notas internas, custo ou margem, regras de precificação especiais, scores de risco, flags de moderação.
A grande armadilha é “filtramos no cliente, mas só mostramos as linhas permitidas”. Ainda assim o dataset completo foi baixado. Qualquer um pode inspecionar a resposta de rede, abrir as dev tools ou salvar o payload. Esconder colunas na UI não é controle de acesso.
Filtragem no servidor é o padrão mais seguro quando a autorização varia por usuário, especialmente quando usuários diferentes podem ver linhas ou campos diferentes.
Checklist rápido:
Se qualquer resposta for sim, mantenha filtragem e seleção de campos no servidor. Envie apenas o que o usuário pode ver e aplique as mesmas regras em busca, ordenação, paginação e exportação.
Exemplo: em uma lista de contatos CRM, representantes veem apenas suas contas enquanto gerentes veem tudo. Se o navegador baixar todos os contatos e filtrar localmente, um representante ainda pode recuperar contas ocultas na resposta. Filtragem no servidor evita isso nunca enviando essas linhas.
Cache pode fazer uma tela parecer instantânea. Também pode mostrar a verdade errada. A chave é decidir o que você pode reusar, por quanto tempo, e quais eventos devem invalidar.
Comece escolhendo a unidade de cache. Fazer cache de uma lista inteira é simples, mas geralmente desperdiça banda e fica obsoleta rápido. Fazer cache de páginas funciona bem para scroll infinito. Fazer cache de resultados de query (filtro + ordenação + busca) é preciso, mas pode crescer rápido se usuários tentarem muitas combinações.
A atualidade importa mais em alguns domínios que em outros. Se os dados mudam rápido (níveis de estoque, saldos, status de entrega), até um cache de 30 segundos pode confundir usuários. Se os dados mudam lentamente (arquivos, dados de referência), cache mais longo geralmente é aceitável.
Planeje invalidação antes de codar. Além do tempo, decida o que deve forçar um refresh: criações/edições/exclusões, mudança de permissões, imports ou merges em massa, transições de status, desfazer/rollback e jobs em background que atualizam campos usados em filtros.
Decida também onde o cache vive. Memória do navegador deixa navegação back/forward rápida, mas pode vazar dados entre contas se não for indexada por usuário e organização. Cache no backend é mais seguro para permissões e consistência, mas deve incluir a assinatura completa do filtro e a identidade do chamador para não misturar resultados.
Trate o objetivo como inegociável: a tela deve parecer rápida sem vazar dados.
A maioria dos times tropeça nos mesmos padrões: uma UI que fica bonita na demo e, com dados reais, permissões reais e redes reais, revela as falhas.
A falha mais séria é tratar filtragem como apresentação. Se o navegador recebe registros que não deveria, você já perdeu.
Duas causas comuns:
Exemplo: estagiários devem ver apenas leads da sua região. Se a API retorna todas as regiões e o dropdown filtra em React, estagiários ainda podem extrair a lista completa.
A lentidão frequentemente vem de suposições:
Um problema sutil e doloroso é regras desencontradas. Se o servidor trata “começa com” diferente da UI, usuários veem contagens que não batem, ou itens que somem após refresh.
Faça uma última revisão com duas mentalidades: um usuário curioso e um dia de rede ruim.
Um teste simples: crie um registro restrito e confirme que ele nunca aparece no payload, nas contagens ou no cache, mesmo quando você filtra amplamente ou limpa filtros.
Imagine um CRM com 200.000 contatos. Representantes de vendas só veem suas contas, gerentes veem o time e admins veem tudo. A tela tem busca, filtros (status, responsável, última atividade) e ordenação.
Filtragem no cliente falha rápido aqui. O payload é pesado, o primeiro carregamento fica lento e o risco de vazamento é alto. Mesmo que a UI esconda linhas, o navegador recebeu os dados. Você também pressiona o dispositivo: arrays grandes, ordenação pesada, execuções repetidas de filtros, alto uso de memória e crashes em celulares antigos.
Uma abordagem mais segura é filtragem no servidor com paginação. O cliente envia escolhas de filtro e texto de busca, e o servidor retorna apenas linhas que o usuário pode ver, já filtradas e ordenadas.
Padrão prático:
Uma pequena exceção onde filtragem no cliente funciona: dados minúsculos e estáticos. Um dropdown de “Status do Contato” com 8 valores pode ser carregado uma vez e filtrado localmente com pouco custo e risco.
Times geralmente não se queimam por escolher a opção “errada” uma vez. Se queimam por fazer escolhas diferentes em cada tela e depois tentar consertar vazamentos e páginas lentas sob pressão.
Escreva uma nota curta por tela com filtros: tamanho do dataset, custo de envio, o que é “rápido o suficiente”, quais campos são sensíveis e como os resultados devem ser cacheados (ou não). Mantenha servidor e UI alinhados para não acabar com “duas verdades” sobre filtragem.
Se você está construindo telas rapidamente no Koder.ai (koder.ai), vale decidir desde o início quais filtros devem ser aplicados no backend (permissões e acesso a nível de linha) e quais toggles pequenos podem ficar na camada React. Essa escolha costuma evitar as reescritas mais caras depois.
Por padrão, use filtragem no servidor quando usuários tiverem permissões diferentes, o conjunto de dados for grande ou quando você precisar de paginação e totais consistentes. Use filtragem no cliente apenas quando o conjunto completo for pequeno, seguro para expor e rápido de baixar.
Tudo o que o navegador recebe pode ser inspecionado. Mesmo que a UI esconda linhas ou colunas, um usuário ainda pode ver dados nas respostas de rede, em payloads em cache ou em objetos na memória.
Geralmente acontece quando você envia dados demais e então filtra/ordena grandes arrays a cada tecla, ou quando dispara uma requisição ao servidor em cada pressionar de tecla sem debounce. Mantenha payloads pequenos e evite trabalho pesado a cada mudança de input.
Mantenha uma única fonte de verdade para os filtros “reais”: permissões, busca, ordenação e paginação devem ser aplicadas no servidor em conjunto. Limite a lógica no cliente a pequenos toggles de UI que não alterem o conjunto de dados subjacente.
O cache no cliente pode mostrar dados desatualizados ou vazar informações entre contas se não for indexado corretamente. O cache no servidor é mais seguro para permissões, mas deve incluir a assinatura completa do filtro e a identidade do chamador para não misturar resultados.
Pergunte duas coisas: quantas linhas um usuário pode ter realisticamente, e qual o tamanho em bytes de cada linha. Se você não carregaria aquilo confortavelmente em uma conexão móvel típica ou em um dispositivo mais antigo, mova a filtragem para o servidor e pagine.
Servidor. Se papéis, equipes, regiões ou regras de propriedade mudam o que alguém pode ver, o servidor deve aplicar acesso a linhas e campos. O cliente deve receber apenas os registros e campos que o usuário tem permissão para ver.
Defina primeiro o contrato de filtros e ordenação: campos aceitos, ordenação padrão, regras de paginação e como a busca corresponde (case, acentos, correspondências parciais). Depois implemente a mesma lógica no backend e teste se totais e páginas batem.
Debounce na digitação para não requisitar a cada tecla e mantenha os resultados antigos visíveis até os novos chegarem para reduzir flicker. Use paginação ou carregamento progressivo para que o usuário veja algo rápido sem depender de uma resposta enorme.
Aplique permissões primeiro, depois filtros e ordenação, e retorne apenas uma página mais o total. Evite enviar “campos extras só por precaução” e garanta que as chaves de cache incluam usuário/org/papel para que um vendedor nunca receba dados destinados a um gerente.