03 de out. de 2025·7 min
Fluxo de desenvolvimento snapshot-first para mudanças grandes mais seguras
Aprenda um fluxo snapshot-first para criar pontos de salvamento antes de mudanças em esquema, autenticação e UI, e reverter sem perder progresso.
Aprenda um fluxo snapshot-first para criar pontos de salvamento antes de mudanças em esquema, autenticação e UI, e reverter sem perder progresso.
Um fluxo snapshot-first significa que você cria um ponto de salvamento antes de fazer uma mudança que pode quebrar sua app. Um snapshot é uma cópia congelada do seu projeto em um momento no tempo. Se o próximo passo der errado, você pode voltar exatamente àquele estado em vez de tentar desfazer uma bagunça manualmente.
Grandes mudanças raramente falham de uma forma óbvia. Uma atualização de esquema pode quebrar um relatório três telas adiante. Um ajuste de autenticação pode te trancar fora. Uma reescrita de UI pode parecer bem com dados de exemplo e depois desmoronar com contas reais e casos de borda. Sem um ponto de salvamento claro, você acaba adivinhando qual mudança causou o problema, ou fica corrigindo uma versão quebrada até esquecer como era o estado “funcionando”.
Snapshots ajudam porque te dão uma base conhecida e boa, tornam mais barato tentar ideias arrojadas e facilitam testes. Quando algo quebra, você pode responder: “Estava OK logo depois do Snapshot X?”
Também é importante ser claro sobre o que um snapshot pode e não pode proteger. Um snapshot preserva seu código e configuração como estavam (e em plataformas como Koder.ai, ele pode preservar o estado completo do app com o qual você está trabalhando). Mas não vai consertar suposições ruins. Se sua nova feature espera uma coluna no banco que não existe em produção, reverter o código não desfará o fato de que uma migration já foi executada. Você ainda precisa de um plano para mudanças de dados, compatibilidade e ordem de deploy.
A mudança de mentalidade é tratar o snapshot como um hábito, não como um botão de resgate. Tire snapshots imediatamente antes de movimentos arriscados, não depois que algo quebrou. Você vai avançar mais rápido e com mais calma porque sempre terá um “último estado conhecido bom” para voltar.
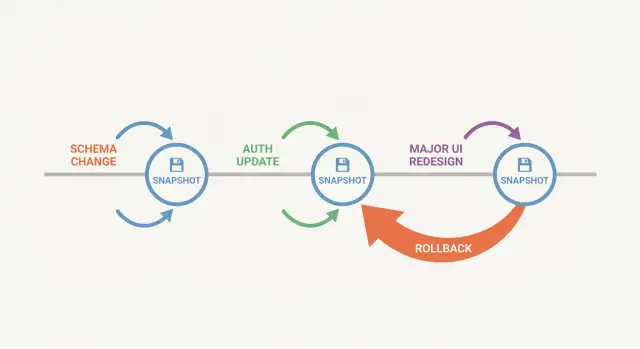
Um snapshot compensa mais quando uma mudança pode quebrar muitas coisas ao mesmo tempo.
Trabalho no esquema é o óbvio: renomear uma coluna pode silenciosamente quebrar APIs, jobs em background, exports e relatórios que ainda esperam o nome antigo. Autenticação é outro: uma mudança pequena de regra pode bloquear admins ou conceder acesso que você não queria. Reescritas de UI são sorrateiras porque frequentemente misturam mudanças visuais com mudanças de comportamento, e regressões se escondem em estados de borda.
Se quiser uma regra simples: faça snapshot antes de qualquer coisa que mude a forma dos dados, identidade e acesso, ou várias telas de uma vez.
Edições de baixo risco geralmente não precisam de um momento de parar e snapshot. Mudanças de texto, ajustes de espaçamento, uma pequena regra de validação ou limpeza de uma função auxiliar tendem a ter alcance pequeno. Você ainda pode tirar um snapshot se isso ajudar a focar, mas não precisa interromper cada edição menor.
Mudanças de alto risco são diferentes. Elas frequentemente funcionam nos seus testes “caminho feliz” mas falham em valores nulos em linhas antigas, usuários com combinações incomuns de papéis, ou estados de UI que você não testa manualmente.
Um snapshot só ajuda se você puder reconhecê-lo rapidamente sob pressão. O nome e as notas são o que transformam um rollback em uma decisão calma e rápida.
Uma boa etiqueta responde três perguntas:
Mantenha curto, mas específico. Evite nomes vagos como “antes da atualização” ou “tentar de novo”.
Escolha um padrão e mantenha-o. Por exemplo:
[WIP] Autenticação: adicionar magic link (próx: OAuth)[GOLD] DB: users table v2 (passa smoke tests)[WIP] UI: refatoração layout do dashboard (próx: gráficos)[GOLD] Release: correções de billing (deployed)Hotfix: loop de redirecionamento no login (causa raiz anotada)Status primeiro, depois área, depois a ação, e por fim um curto “próximo”. Essa última parte é surpreendentemente útil uma semana depois.
Nomes sozinhos não bastam. Use notas para capturar o que seu eu futuro vai esquecer: as suposições que fez, o que testou, o que ainda está quebrado e o que foi intencionalmente ignorado.
Boas notas costumam incluir suposições, 2–3 passos rápidos de teste, problemas conhecidos e quaisquer detalhes arriscados (ajustes de esquema, mudanças de permissão, alterações de roteamento).
Marque um snapshot como GOLD somente quando for seguro retornar a ele sem surpresas: fluxos básicos funcionam, erros são compreendidos e você poderia continuar dali. Todo o resto é WIP. Esse hábito pequeno evita reverter para um ponto que só parecia estável porque você esqueceu o grande bug que deixou para trás.
Um loop sólido é simples: só avance a partir de pontos conhecidos como bons.
Antes de tirar o snapshot, verifique que o app realmente roda e os fluxos-chave se comportam. Mantenha pequeno: você consegue abrir a tela principal, fazer login (se o app tiver) e completar uma ação central sem erros? Se algo já estiver instável, corrija isso primeiro. Caso contrário, seu snapshot preservará um problema.
Crie um snapshot, depois adicione uma nota de uma linha sobre por que ele existe. Descreva o risco futuro, não o estado atual.
Exemplo: “Antes de mudar a tabela users + adicionar organization_id” ou “Antes de refatorar o middleware de autenticação para suportar SSO”.
Evite empilhar várias mudanças grandes em uma iteração (esquema mais autenticação mais UI). Escolha uma fatia, termine-a e pare.
Uma boa “uma mudança” é “adicionar uma nova coluna e manter o código antigo funcionando” em vez de “substituir todo o modelo de dados e atualizar cada tela”.
Depois de cada passo, rode as mesmas checagens rápidas para que os resultados sejam comparáveis. Mantenha curto para que você realmente faça.
Quando a mudança estiver funcionando e você tiver uma nova baseline limpa, tire outro snapshot. Esse será seu novo ponto seguro para o próximo passo.
Mudanças de banco de dados parecem “pequenas” até o momento em que quebram signup, relatórios ou um job em background que você esqueceu que existia. Trate o trabalho de esquema como uma sequência de checkpoints seguros, não um grande salto.
Comece com um snapshot antes de tocar em qualquer coisa. Depois escreva uma baseline em linguagem simples: quais tabelas estão envolvidas, quais telas ou chamadas de API as leem, e como “correto” se parece (campos obrigatórios, regras de unicidade, contagens de linhas esperadas). Isso leva minutos e economiza horas quando você precisa comparar comportamentos.
Um conjunto prático de pontos de salvamento para a maioria do trabalho de esquema costuma ser:
Evite uma única migration enorme que renomeie tudo de uma vez. Divida em passos menores que você pode testar e reverter.
Depois de cada checkpoint, verifique mais do que o caminho feliz. Fluxos CRUD que dependem das tabelas alteradas importam, mas exports (downloads CSV, faturas, relatórios admin) também são importantes porque frequentemente usam queries antigas.
Planeje o caminho de rollback antes de começar. Se você adicionar uma nova coluna e começar a escrever nela, decida o que acontece se você reverter: o código antigo vai ignorar a coluna com segurança, ou você precisará de uma migration reversa? Se houver risco de dados parcialmente migrados, decida como detectar e completar a migração, ou como abandonar limpo.
Mudanças de auth são uma das formas mais rápidas de se trancar (e trancar seus usuários). Um ponto de salvamento ajuda porque você pode tentar uma mudança arriscada, testá-la e reverter rapidamente se necessário.
Tire um snapshot logo antes de mexer em auth. Depois escreva o que você tem hoje, mesmo que pareça óbvio. Isso evita surpresas do tipo “eu pensei que admins ainda conseguiriam logar”.
Registre o básico:
Quando começar a mudar, altere uma regra por vez. Se você mudar checagens de papel, lógica de token e telas de login ao mesmo tempo, não saberá o que causou a falha.
Um bom ritmo: mude uma peça, rode as mesmas checagens pequenas, então snapshot novamente se estiver limpo. Por exemplo, ao adicionar a role “editor”, implemente criação e atribuição primeiro e confirme que logins ainda funcionam. Depois adicione uma regra de permissão e reteste.
Após a mudança, verifique o controle de acesso por três ângulos. Usuários normais não devem ver ações apenas de admin. Admins devem ainda acessar configurações e gerenciamento de usuários. Em seguida, teste os casos de borda: sessões expiradas, reset de senha, contas desativadas e usuários entrando com um método que você não usou no teste.
Um detalhe que as pessoas esquecem: segredos frequentemente vivem fora do código. Se você reverter o código mas manter novas chaves e configurações de callback, a autenticação pode quebrar de formas confusas. Deixe notas claras sobre quaisquer mudanças de ambiente que você fez ou precise reverter.
Reescritas de UI parecem arriscadas porque combinam trabalho visual com mudanças comportamentais. Crie um ponto de salvamento quando a UI estiver estável e previsível, mesmo que não seja bonita. Esse snapshot vira sua baseline de trabalho: a última versão que você enviaria se precisasse.
Reescritas de UI falham quando tratadas como um grande interruptor. Divida o trabalho em fatias que possam se sustentar sozinhas: uma tela, uma rota ou um componente.
Se estiver reescrevendo o checkout, divida em Cart, Endereço, Pagamento e Confirmação. Após cada fatia, primeiro iguale o comportamento antigo. Depois melhore layout, copy e interações pequenas. Quando essa fatia estiver “pronta o suficiente” para manter, tire um snapshot.
Após cada fatia, rode um reteste rápido focado no que costuma falhar durante reescritas:
Uma falha comum: a nova tela de Perfil está mais bonita, mas um campo não salva porque um componente mudou o formato do payload. Com um bom checkpoint, você pode reverter, comparar e reaplicar as melhorias visuais sem perder dias de trabalho.
Reverter deve parecer controlado, não pânico. Primeiro decida se precisa de um rollback completo para um ponto conhecido ou de um desfazer parcial de uma mudança.
Um rollback completo faz sentido quando o app está quebrado em muitos pontos (testes falham, servidor não inicia, login travado). Desfazer parcial serve quando só uma peça deu errado, como uma migration, um guard de rota ou um componente que causa crash.
Trate seu último snapshot estável como base:
Então passe cinco minutos nos básicos. É fácil reverter e ainda assim perder uma quebra silenciosa, como um job em background que não roda mais.
Verificações rápidas que pegam a maioria dos problemas:
Exemplo: você tentou uma grande refatoração de auth e bloqueou sua conta de admin. Volte para o snapshot de antes da mudança, verifique que consegue logar, então reaplique as edições em passos menores: roles primeiro, depois middleware, depois bloqueio na UI. Se quebrar de novo, você saberá exatamente qual passo causou.
Por fim, deixe uma nota curta: o que quebrou, como percebeu, o que resolveu e o que fará diferente na próxima vez. Isso transforma rollbacks em aprendizado em vez de tempo perdido.
A dor do rollback geralmente vem de pontos de salvamento pouco claros, mudanças misturadas e checagens puladas.
Salvar raramente demais é um erro clássico. Pessoas passam por um “pequeno” ajuste de esquema, uma mudança de regra de auth e um ajuste de UI, e então descobrem a app quebrada sem um ponto limpo para voltar.
O problema oposto é salvar constantemente sem notas. Dez snapshots chamados “teste” ou “wip” são basicamente um só snapshot porque você não consegue confiar em nenhum.
Misturar várias mudanças arriscadas em uma única iteração é outra armadilha. Se esquema, permissões e UI caírem juntos, um rollback vira jogo de adivinhação. Você também perde a opção de manter a parte boa (como melhora de UI) enquanto reverte a parte arriscada (como uma migration).
Mais uma questão: reverter sem checar suposições de dados e permissões. Depois de um rollback, o banco pode ainda conter colunas novas, nulos inesperados ou linhas parcialmente migradas. Ou você pode restaurar lógica antiga de auth enquanto roles foram criadas sob regras novas. Essa incompatibilidade pode parecer “o rollback não funcionou” quando na verdade ele funcionou.
Se quiser uma forma simples de evitar a maior parte disso:
Snapshots funcionam melhor quando emparelhados com checagens rápidas. Essas checagens não são um plano de testes completo. São um conjunto pequeno de ações que dizem, rápido, se você pode continuar ou deve reverter.
Rode estas imediatamente antes de tirar o snapshot. Você está provando que a versão atual vale a pena salvar.
Se algo já estiver quebrado, conserte primeiro. Não tire snapshot de um problema a menos que esteja preservando-o intencionalmente para depuração.
Mire em um caminho feliz, um caminho de erro e uma checagem de permissões.
Imagine que você está adicionando uma nova role chamada “Manager” e redesenhando a tela de Configurações.
Comece de uma build estável. Rode as checagens pré-mudança, então tire um snapshot com nome claro, por exemplo: “pre-manager-role + pre-settings-redesign”.
Faça primeiro o trabalho backend de roles (tabelas, permissões, API). Quando roles e regras de acesso se comportarem corretamente, tire outro snapshot: “roles-working”.
Depois comece a reescrita da UI de Settings. Antes de um grande rewrite de layout, tire um snapshot: “pre-settings-ui-rewrite”. Se a UI ficar bagunçada, volte a esse ponto e tente uma abordagem mais limpa sem perder o trabalho bom de roles.
Quando a nova UI de Settings estiver utilizável, tire um snapshot: “settings-ui-clean”. Só então passe para o polimento.
Experimente isso em uma feature pequena esta semana. Escolha uma mudança arriscada, coloque dois snapshots ao redor dela (antes e depois) e pratique um rollback de propósito.
Se você está construindo no Koder.ai (koder.ai), os snapshots e rollback embutidos facilitam manter esse fluxo enquanto itera. O objetivo é simples: tornar grandes mudanças reversíveis, para que você possa avançar rápido sem apostar na sua melhor versão de trabalho.
Um snapshot é um ponto de salvamento congelado do seu projeto em um momento específico. O hábito padrão é: crie um snapshot logo antes de uma mudança arriscada, assim você pode voltar a um estado conhecido e bom se algo quebrar.
É mais útil quando falhas são indiretas (uma mudança de esquema quebrando um relatório, um ajuste de autenticação travando o acesso, uma reescrita de UI falhando com dados reais).
Faça snapshot antes de mudanças com grande raio de impacto:
Para edições pequenas (ajustes de texto, espaçamento, refactors minúsculos) geralmente não é necessário interromper tudo para tirar um snapshot.
Use um padrão consistente que responda:
Um formato prático é: STATUS + Área + Ação (+ próximo passo).
Exemplos:
Marque um snapshot como GOLD apenas quando você ficaria confortável em voltar a ele e continuar o trabalho sem surpresas.
Um snapshot GOLD geralmente significa:
Todo o resto é . Isso evita voltar para um ponto que estável, mas tinha um bug grande não resolvido.
Mantenha as verificações curtas e repetíveis para que você realmente as faça:
O objetivo não é testar tudo—é só garantir que você ainda tem uma base segura.
Uma sequência prática de pontos de salvamento é:
Tire um snapshot antes de mexer na autenticação e escreva o que existe hoje:
Mude uma regra por vez, reteste e snapshot novamente se estiver limpo. Também documente quaisquer mudanças de ambiente—reverter o código não reverterá automaticamente segredos ou configurações externas.
Divida a reescrita em fatias que possam ser mantidas independentemente:
Após cada fatia, reteste o que costuma quebrar: caminhos de navegação, envio/validação de formulários, estados de carregamento/vazio/erro e comportamento em mobile. Tire um snapshot quando uma fatia estiver “pronta o suficiente”.
Use uma sequência de rollback controlada:
stable-after-rollback.Isso transforma um rollback em um retorno à “base” em vez de um desfazer em pânico.
Erros comuns:
Padrão recomendado: snapshot em pontos de decisão (antes/depois de uma mudança arriscada), escreva uma frase de nota, e separe por tipo de trabalho.
[WIP] Autenticação: adicionar magic link (próx: OAuth)[GOLD] DB: users v2 (passa smoke tests)Evite nomes como “teste” ou “antes da atualização”—eles são difíceis de confiar sob pressão.
Regra padrão: evite uma migration gigante que renomeie tudo de uma vez. Divida para testar e reverter com segurança.