21 de set. de 2025·8 min
O fosso de fulfillment da JD.com: vencer com confiabilidade logística
Saiba como o modelo ‘logística em primeiro lugar’ da JD.com — armazéns controlados, última milha e SLAs claros — transforma entrega confiável em vantagem duradoura.
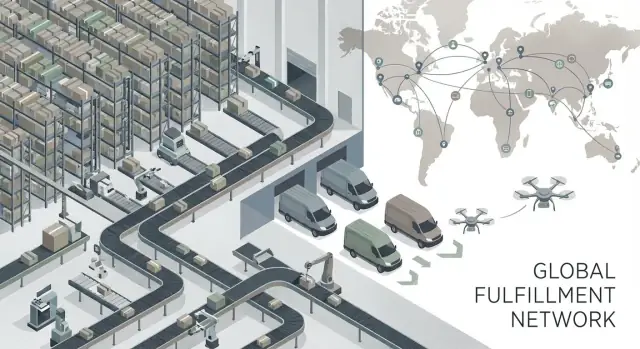
O que significa competir pela confiabilidade no atendimento
Alguns negócios de e-commerce crescem principalmente por marketing, variedade e um site atraente. O e‑commerce pesado em logística é diferente: a experiência do produto é inseparável da experiência de entrega. Quando clientes compram itens essenciais do dia a dia, eletrônicos ou presentes com prazo, o “produto” real inclui se chega no prazo, intacto e com devolução fácil.
A confiabilidade é o produto
Confiabilidade no atendimento significa que o cliente pode prever o que acontecerá após o checkout: disponibilidade de estoque precisa, promessas de entrega realistas, repasses consistentes, baixa taxa de avarias e recuperação de serviço quando algo dá errado. Velocidade ajuda, mas velocidade sem consistência condiciona o cliente a desconfiar das promessas — e essa desconfiança é cara.
Como é um fosso logístico
Um fosso competitivo em logística varejista não é um único armazém ou uma campanha pontual de “entrega no dia seguinte”. É um sistema que torna a entrega confiável mais fácil para você e mais difícil para concorrentes imitarem. Esse sistema cria vantagens que se acumulam:
- Conversão maior porque os clientes acreditam nas datas de entrega
- Mais recompra porque a entrega vira rotina
- Custos de suporte menores à medida que exceções diminuem
- Melhor economia por unidade quando a operação fica previsível em escala
A JD.com é um estudo útil porque trata atendimento como uma capacidade central, não como função de retaguarda. Seu fosso é construído ao tornar a confiabilidade um padrão operacional que os concorrentes têm dificuldade em reproduzir rapidamente.
O que este artigo fará (e o que não fará)
Esta é uma análise estratégica de como a confiabilidade pode ser projetada em um negócio de e-commerce. Não é uma previsão financeira, e não pressupõe que toda empresa deva copiar o nível de integração vertical da JD.com.
Blocos de construção que vamos destrinchar
A confiabilidade é criada por alavancas conectadas: uma rede de armazéns e hubs bem desenhada, posicionamento de estoque próximo à demanda, forte controle da última milha (ou gestão rigorosa de parceiros) e tecnologia + dados para manter desempenho consistente conforme o volume cresce.
Confiabilidade como promessa ao cliente (não apenas envio rápido)
Entrega rápida é fácil de divulgar, mas confiabilidade é o que o cliente vive todo dia. A vantagem da JD.com é menos sobre o ocasional “uau, chegou em horas” e mais sobre uma promessa consistente: seu pedido chegará quando dissemos, com os itens certos, em bom estado — e devolver não será um transtorno.
Defina a promessa em termos do cliente
Para a maioria dos compradores, “atendimento confiável” inclui vários pontos básicos funcionando juntos:
- Janelas de entrega previsíveis (o ETA é crível e as atualizações são precisas)
- Precisão do pedido (item certo, variante certa, quantidade certa)
- Baixas taxas de dano e perda (embalagem adequada e manuseio cuidadoso)
- Devoluções simples (passos claros, coleta/estorno rápidos, fricção mínima)
Por que previsibilidade frequentemente vence velocidade máxima
Muitos clientes não precisam do envio mais rápido; precisam de um envio com o qual possam planejar. Uma entrega em dois dias que chega em dois dias costuma ser melhor que uma “mesmo dia” que atrasa para amanhã à noite. Previsibilidade importa para presentes, itens para home office e compras sensíveis ao tempo — e reduz o risco percebido ao clicar em “Comprar”.
Como a confiança se transforma em fosso
Quando compradores aprendem que um varejista entrega com consistência, o comportamento muda:
- Mais recompras porque a escolha mais segura vira padrão
- Tamanho médio do pedido maior pois há menos preocupação com entregas parciais, itens errados ou dores para reembolso
- Menos cancelamentos porque ETAs confiáveis reduzem a incerteza
A confiabilidade também traz ganho operacional silencioso: menos contatos “onde está meu pedido?”, menos avaliações negativas por expectativas não atendidas e menos tempo gasto resolvendo exceções manualmente. Com o tempo, essas economias podem ser reinvestidas em serviço ainda mais consistente — apertando o ciclo que torna a JD.com difícil de igualar.
Construindo a rede física: armazéns e hubs regionais
A vantagem de confiabilidade da JD.com começa com uma escolha pouco glamourosa: possuir e controlar estritamente partes chave da rede física. Quando armazéns operam com um padrão único — em vez de serem um amontoado de terceiros — o serviço se torna mais previsível. O mesmo item é recebido, estocado, separado, embalado e despachado da mesma forma, independentemente da cidade.
Por que armazéns próprios/controlados melhoram a consistência
Controle é menos sobre imóvel e mais sobre execução. Um armazém que você opera pode aplicar um único playbook: níveis de pessoal por hora, regras de slotting para itens rápidos, checagens de qualidade e tratamento de exceções. Isso reduz a “aleatoriedade” que os clientes sentem — despachos atrasados, itens faltantes ou embalagens inconsistentes — porque menos etapas dependem de parceiros externos com incentivos diferentes.
Densidade da rede e janelas de corte
Confiabilidade não é apenas estar perto; é ter nós suficientes para oferecer horários de corte repetíveis.
Com cobertura densa — hubs nacionais alimentando hubs regionais que alimentam instalações locais — pedidos podem ser aceitos mais tarde no dia e ainda cumprir promessas de next‑day ou mesmo same‑day. Distâncias de transporte menores significam menos repasses e menor exposição a tráfego, clima e limitações de capacidade de transportadoras. Na prática, densidade converte velocidade em algo que o cliente pode contar, não só momentos excepcionais.
Padronização em cada repasse
Uma rede controlada pode padronizar pequenas ações que evitam grandes falhas:
- Regras de embalagem que combinam fragilidade do produto e manuseio do transportador
- Escaneamento ao receber, alocar, separar, embalar e despachar para criar rastreabilidade
- Treinamento que faz com que exceções (produto danificado, SKU errado, problemas de endereço) sejam tratadas da mesma forma sempre
Esses básicos apertam o loop de feedback: quando algo dá errado, você pode identificar onde e consertar o processo — não apenas culpar um parceiro.
Redundância mantém alta disponibilidade em picos
Picos e interrupções não testam só a capacidade; testam as opções de roteamento. Múltiplos hubs regionais, rotas line‑haul alternativas e capacidade de rebalancear estoque entre nós permitem que o sistema mantenha promessas quando uma instalação está sobrecarregada ou um corredor é bloqueado. Essa redundância é cara — mas transforma entrega “melhor esforço” em serviço que o cliente pode planejar.
Posicionamento de estoque: coloque os itens certos perto dos clientes
Atribuem-se frequentemente a caminhões, motoboys ou opções “expressas” a razão da entrega rápida. Mas a alavanca real é mais simples: onde o estoque está antes do cliente clicar em comprar. Se seus itens mais vendidos já estão posicionados perto da demanda, o envio vira um repasse curto e previsível — não uma corrida pelo país.
Por que posicionamento vence velocidade pura
Um transportador só pode mover um pacote tão rápido. Posicionamento de estoque elimina distância da equação. A vantagem logística da JD.com está enraizada em estocar consistentemente os produtos certos nas regiões certas, para que o caminho “padrão” até o cliente seja curto e repetível.
Previsão de demanda, explicada de forma prática
Previsão não é mágica — é um palpite estruturado baseado em padrões:
- Histórico: o que vendeu na semana/mês em cada região
- Tendências: se a demanda está subindo ou caindo
- Eventos: pagamentos, feriados, clima, momentos locais
- Sinais: visualizações de busca, carrinhos e listas de desejos que indicam pedidos futuros
O objetivo não é prever perfeitamente. É reduzir surpresas o suficiente para que a operação se mantenha estável.
Segmentar SKUs: fast movers vs cauda longa
Nem todo produto merece espaço premium.
- Fast movers (alto volume): estocar em hubs regionais ou nós ainda mais próximos, porque cada hora economizada impacta muitos pedidos.
- Itens de cauda longa (baixo volume): manter centralizados. Você enviará mais longe ocasionalmente, mas evita imobilizar espaço e capital em todo lugar.
Estoque de segurança, sazonalidade e promoções
Confiabilidade é, em grande parte, prevenir ruptura de estoque. Isso exige:
- Estoque de segurança: um pequeno buffer para picos de demanda ou atrasos de fornecedor
- Planejamento sazonal: construir estoque antes de picos previsíveis (volta às aulas, feriados)
- Planejamento de promoções: tratar campanhas como uma curva de demanda diferente; alocar estoque para regiões onde a promoção converte de fato
Bem posicionado, o estoque transforma velocidade em promessa confiável, não em sorte.
Controle da última milha: a parte mais visível da marca
Para clientes, “confiabilidade” é julgada na porta. Uma operação de armazém perfeita não importa se o entregador chega atrasado, não toca a campainha ou marca entregue quando não foi. Por isso controlar a última milha pode melhorar substancialmente o desempenho no prazo: você define padrões, treina para eles, mede adesão e corrige rapidamente — em vez de esperar que uma rede terceirizada priorize seus pacotes.
Por que controle aumenta a pontualidade
Quando um varejista gerencia sua própria força de entrega (ou parceiros rigidamente gerenciados), pode coordenar despacho com janelas de corte do armazém, padrões de tráfego local e janelas de promessa. Esse alinhamento reduz falhas comuns: repasses perdidos, propriedade pouco clara e exceções do tipo “não é nosso problema”.
Planejamento de rotas, janelas e reentregas
A confiabilidade da última milha é, em grande parte, disciplina de planejamento.
- Planejamento de rotas: roteamento dinâmico que reflete tempo de direção real (não só distância) mantém paradas realistas e reduz cascatas de atraso.
- Janelas de entrega: janelas claras ajustam expectativas e reduzem falhas por ausência. Janelas mais estreitas custam mais, mas cortam retrabalho.
- Tratamento de reentregas: um playbook definido — tentativas no mesmo dia, opções de retirada e notificações — transforma exceções em resultados previsíveis em vez de churn.
Prova de entrega e responsabilização
O controle também melhora a “verdade” do que aconteceu. Prova de entrega não é só uma foto; é disciplina de escaneamento em cada etapa (coleta, triagem, a caminho, entregue) com timestamps e geodados. Quando os scans são consistentes, você localiza onde os atrasos começam, reduz reclamações por entregas falsas e orienta depósitos ou motoristas específicos.
O trade‑off
Possuir a última milha é caro: mão de obra, frota, treinamento e suporte ao cliente. Mas falhas de serviço também são caras — reenvios, suportes, compensações, perda de valor vitalício e dano reputacional. A aposta estratégica é que pagar pela consistência rende vantagem composta: menos exceções, menor custo por entrega bem‑sucedida e uma marca que os clientes confiam para cumprir promessas.
SLAs e padrões operacionais que tornam o serviço previsível
Mantenha o controle com exportação do código-fonte
Vá rápido agora e exporte o código-fonte completo quando precisar de customização mais profunda.
Acordos de Nível de Serviço (SLAs) são o “contrato” por trás da confiabilidade — mesmo quando os clientes nunca veem o documento. Eles traduzem a promessa da marca (“chega amanhã, intacto”) em compromissos mensuráveis que moldam dimensionamento de pessoal, janelas de corte, repasses a transportadoras e regras de escalonamento.
Como SLAs direcionam prioridades internas
Um SLA útil faz duas coisas ao mesmo tempo: define a expectativa do cliente e força trade‑offs dentro da operação. Se o SLA diz que 95% dos pedidos elegíveis saem no mesmo dia, então planejamento de mão de obra, liberação de ondas, estações de embalagem e partidas de linehaul devem alinhar-se a esse relógio. Equipes param de otimizar eficiência local (“minha estação é rápida”) e começam a otimizar resultados ponta a ponta (“o pedido sai do prédio no horário”).
Termos chave de confiabilidade (e por que importam)
Métricas comuns de SLA incluem:
- Taxa de pontualidade: parcela de pedidos entregues dentro da janela prometida.
- Fill rate: parcela de linhas de pedido atendidas completamente (sem itens faltantes ou substituições).
- Precisão de separação (pick accuracy): parcela de separações que conferem exatamente com o pedido.
- Taxa de avaria: parcela de pedidos chegando danificados (frequentemente por 1.000 envios).
Cada métrica aponta para um ponto de falha diferente: disponibilidade de estoque (fill rate), qualidade do processo de armazém (pick accuracy), embalagem e manuseio (taxa de avaria) e execução da rede (on‑time rate).
Tratamento de exceções: o que acontece quando algo dá errado
Confiabilidade não é “sem problemas” — é recuperação previsível. Padrões fortes definem o que fazer quando um pedido atrasa, estoque falta ou um pacote é danificado: quem é alertado, quão rápido se diagnostica, qual compensação é autorizada e como o cliente é atualizado. Playbooks claros evitam improviso e reduzem o tempo que uma exceção fica sem resolver.
Por que promessas claras reduzem churn
Prometer demais cria decepção mesmo quando o desempenho é razoável. Uma promessa de entrega precisa e uma janela consistente reduzem churn porque clientes conseguem planejar — especialmente para presentes, essenciais ou compras sensíveis ao tempo. Na prática, um SLA um pouco mais lento, mas confiável, costuma vencer um SLA rápido porém inconsistente.
Tecnologia e dados: como a confiabilidade escala além de processos manuais
A confiabilidade desmorona rapidamente quando depende de poucas pessoas experientes “lembrando” o que fazer. A vantagem da JD.com é tratar atendimento como um sistema instrumentado: cada passo gera dados, e esses dados retroalimentam o planejamento e a comunicação ao cliente.
Sistemas de armazém que evitam que pequenos erros virem grandes falhas
No centro está um sistema de gestão de armazém (WMS) que atribui locais, roteia tarefas e verifica cada toque.
Fluxos de código de barras/scan importam mais do que parecem: quando cartons de entrada são escaneados, itens ficam atrelados a um bin específico; quando separadores puxam unidades, scans confirmam SKU e quantidade; quando pedidos são embalados, scans finais validam o conteúdo do envio. Isso reduz erros de separação, acelera o tratamento de exceções e torna “previsível” um resultado repetível em vez de um objetivo aspiracional.
Dados que melhoram previsão, reposição e planejamento de mão de obra
Confiabilidade depende de ter o estoque certo e as pessoas certas prontas antes da demanda chegar.
Sinais de demanda (pedidos passados, sazonalidade, promoções, eventos locais) melhoram previsão e tempo de reposição, reduzindo rupturas. Os mesmos dados apoiam o planejamento de mão de obra: dimensionamento e alocação de turnos podem ser ajustados ao volume esperado, reduzindo gargalos que causam despachos tardios.
Automação como consistência, não espetáculo
Automação ajuda mais quando remove variabilidade. Exemplos relevantes: triagem automática para reduzir erros de roteamento, correias e túneis de scan para acelerar verificação, e auxiliares de separação (como picking guiado por luz) para cortar taxas de erro — sem pressupor um armazém totalmente “lights‑out”.
Rastreamento em tempo real que reduz carga de suporte
Quando scans e repasses atualizam em tempo real, clientes veem status e ETAs precisos. Essa transparência reduz contatos “onde está meu pedido?” e, quando ocorre um problema (scan perdido, atraso em um hub), o sistema pode gerar alertas e atualizações proativas — preservando a confiança mesmo quando a entrega não é perfeita.
Construir ferramentas de confiabilidade rápido (sem ciclo de desenvolvimento longo)
Um ponto prático: muitas vitórias de confiabilidade vêm de ferramentas internas leves — captura de códigos de motivo de exceção, dashboards de performance de transportadoras, monitoramento de janelas de corte ou uma visão simples de envelhecimento de backlog. Plataformas como Koder.ai podem ajudar equipes a prototipar e lançar esses tipos de apps web rapidamente via fluxo de construção orientado por chat, e depois iterar conforme operações aprendem quais métricas realmente predizem falhas. Isso é útil quando você precisa de um dashboard funcional agora, não após um replatforming de WMS de vários trimestres.
O trade‑off custo–serviço: pagar pela consistência
Planeje antes de construir
Defina KPIs e fluxos no modo de planejamento e gere o app a partir desse plano.
Confiabilidade não é de graça. A questão é se você quer pagar por ela diretamente (possuindo mais da cadeia logística) ou pagá‑la indiretamente (por reembolsos, perda de recompras e confiança de marca quando entregas falham).
Economia por unidade, explicada de forma simples
Pense em dois mostradores:
- Custo por pedido: quanto custa separar, embalar e entregar um envio.
- Nível de serviço: quão consistentemente você cumpre a promessa (item certo, no prazo, sem avaria).
Aumentar o nível de serviço geralmente implica gastar mais — mais armazéns, mais entregadores, embalagens melhores, mais estoque de buffer. Mas falhas de serviço também custam caro: reenvios, tempo de suporte, compensações e o custo de longo prazo do churn. A aposta da JD.com é que entrega previsível reduz custos “ocultos” e aumenta recompras, o que pode compensar o gasto operacional mais alto.
Possuir logística vs parceiros: quando cada um faz sentido
Possuir logística (armazéns + última milha) é mais justificável quando:
- O volume de pedidos é alto e denso em regiões chave.
- Confiabilidade é central para a promessa da marca.
- Você vende categorias onde confiança importa (eletrônicos, eletrodomésticos, itens de alto valor).
Parcerias fazem mais sentido quando:
- Volumes ainda são incertos.
- Você está entrando em áreas de baixa densidade.
- Velocidade e confiabilidade são “desejáveis”, não a razão principal da escolha do cliente.
Muitos negócios começam híbridos: mantêm rotas críticas internamente e terceirizam geografias de cauda longa.
Utilização é a alavanca de custo oculta
Um armazém ou frota sai mais barato por pedido quando está ocupado. Alta utilização dilui custos fixos (aluguel, sistemas, treinamento) em mais envios.
Picos são o desafio. Para não sobreconstruir, operadores usam trabalho temporário, parceiros de overflow, posicionamento antecipado de estoque antes de grandes promos e definem cortes realistas para que a promessa permaneça consistente.
Clientes notam a confiabilidade, não sua estrutura de custos
A maioria dos compradores não quer saber por que o frete custa o que custa; quer que a promessa de entrega valha. Por isso preços funcionam melhor quando refletem resultados — níveis claros, ETAs honestos e menos atrasos surpresa — em vez de tentar explicar a matemática logística.
Efeitos no ecossistema: por que logística atrai mais vendedores
Um sistema de atendimento confiável não só deixa clientes satisfeitos — ele muda quem quer vender na sua plataforma.
Quando marcas e sellers veem entrega consistente, baixas taxas de avaria e devoluções previsíveis, ficam mais dispostos a listar seus melhores produtos e lançar novos SKUs. Confiabilidade reduz custos ocultos do e‑commerce (clientes irritados, reembolsos, carga de suporte), então lojistas podem focar em marketing e sortimento em vez de apagar incêndio.
Confiabilidade como ímã para marcas e vendedores
Para marcas estabelecidas, performance logística é proxy de segurança de marca. Se a entrega é bagunçada, o cliente culpa o logo na embalagem — não o transportador. Uma plataforma conhecida por fulfillment confiável pode conquistar lançamentos exclusivos, categorias de maior margem e compromissos de catálogo maiores porque protege reputação da marca.
Para vendedores menores, logística forte é atalho para credibilidade: eles competem com players maiores ao se conectar a um sistema que os clientes já confiam.
Padrões para sellers: regras de entrada que protegem a promessa
Para manter a rede previsível em escala, marketplaces costumam impor requisitos de inbound e fulfillment — rotulagem, dimensões de caixa, precisão de códigos de barras, padrões de embalagem e recebimento por agendamento. Essas regras parecem rígidas, mas reduzem exceções no armazém que causam atrasos e erros de separação.
Plataformas também definem cortes claros (quando pedidos devem ser confirmados/entregues) e exigem feeds de estoque precisos para que clientes não comprem itens indisponíveis.
Controle de qualidade: penalidades, auditorias e níveis de performance
A confiabilidade torna‑se autorreforçadora quando ligada a resultados dos sellers. Mecanismos comuns incluem:
- Auditorias (checagens aleatórias sobre embalagem, autenticidade e precisão de pedidos)
- Penalidades por despacho tardio, pedidos cancelados e altas taxas de devolução
- Níveis de performance que desbloqueiam benefícios (melhor posicionamento nas buscas, acesso a capacidade na alta temporada, taxas menores ou elegibilidade a programas premium)
O objetivo não é punir — é tornar qualidade de serviço mensurável e economicamente relevante.
Habilitar serviços premium que elevam o patamar
Com o básico confiável, a plataforma pode vender “upgrades de confiabilidade” que clientes valorizam: janelas de entrega agendadas, entregas à noite/fim de semana, instalação, retirada do item antigo ou serviço white‑glove para eletrodomésticos. Esses serviços atraem mais sellers em categorias volumosas ou de consideração elevada, ampliando o mix do marketplace sem quebrar a promessa ao cliente.
Métricas que provam que você é confiável (e mostram onde não é)
Confiabilidade só vira fosso quando você a mede com consistência, detecta derrapagens cedo e corrige causas de base — não apenas pede desculpas mais rápido. O objetivo é um conjunto pequeno de métricas que todos confiem, revisadas com frequência.
Um conjunto simples de KPIs (comece por aqui)
Mantenha o placar curto e alinhado a resultados do cliente:
- % de entrega no prazo (por região, transportadora e nível de promessa)
- % de precisão do pedido (pedidos perfeitos: item, quantidade e embalagem corretos)
- Tempo do ciclo de devolução (dias desde a devolução do cliente até reembolso/estoque revendável)
- NPS ou CSAT (pós‑entrega, segmentado pela experiência de entrega)
Se só puder rastrear dois, escolha % de entrega no prazo e % de precisão do pedido — eles capturam a maioria das falhas de confiabilidade que o cliente percebe.
Indicadores antecedentes vs. defasados
Indicadores defasados (NPS, reembolsos, entregas atrasadas) dizem que você já falhou. Combine‑os com indicadores antecedentes que avisam antes:
- Conformidade de scan (os scans obrigatórios foram feitos em pick/pack/dispatch?)
- Backlog (pedidos não despachados e envelhecimento por janela de corte)
- Taxa de missort (associações erradas de hub/rota)
- % de sucesso na primeira tentativa (qualidade do endereço, planejamento de rota, comunicação ao cliente)
Regra prática: se uma métrica pode ser “consertada” trabalhando horas extras hoje, geralmente é defasada. Se aponta um passo quebrado (treinamento, layout, regra do sistema), é antecedente.
Revisões operacionais semanais e disciplina de causa raiz
Faça uma revisão semanal de confiabilidade com uma página por nó (armazém/hub/última milha). Comece pelas exceções: maiores quedas na pontualidade, SKUs que mais geram erros e piores rotas.
Use tags simples de causa raiz (estoque indisponível, falta de capacidade, missort, problema de endereço, avaria) e exija um responsável + uma próxima ação por cada problema importante. Acompanhe se as ações reduziram o problema na semana seguinte.
Um dashboard leve para times não técnicos
Estruture como:
- Resultados ao cliente (pontualidade, precisão, NPS/CSAT)
- Saúde do processo (conformidade de scan, backlog, missort)
- Visão de capacidade (pedidos vs. plano de pessoal/veículos)
O dashboard deve responder duas perguntas em menos de cinco minutos: Onde estamos falhando a promessa? e Qual passo do processo está causando?
Se não tiver capacidade de analytics engineering, considere construir primeiro um “dashboard mínimo viável de confiabilidade” (mesmo imperfeito) e iterar semanalmente. Ferramentas como Koder.ai podem ser uma forma prática de criar um app interno rapidamente — e evoluir conforme sua definição de SLA e taxonomia de exceções amadurecem.
Riscos e modos de falha: o que pode quebrar o fosso
Acompanhe o tempo do ciclo de devoluções
Crie um rastreador do tempo do recolhimento até o reembolso para que as devoluções deixem de ser um ponto cego.
Confiabilidade é um fosso só enquanto os clientes a vivenciam como “previsível”. No momento em que as entregas ficam incertas, a vantagem pode virar centro de custo — porque você ainda paga pela rede, mas não ganha confiança.
Onde a confiabilidade costuma falhar
Os maiores pontos de falha raramente são misteriosos; são os mesmos estressores que atingem qualquer operador logístico:
- Clima e interrupções locais (tempestades, inundações, fechamentos de vias) que cascata em rotas perdidas.
- Escassez de mão de obra em armazéns ou última milha, especialmente em feriados e promoções grandes.
- Atrasos de fornecedores e variabilidade de entrada que causam rupturas mesmo com previsão correta.
- Picos de demanda (campanhas, produtos virais) que sobrecarregam capacidade de separação, embalagem e linehaul.
Táticas de resiliência que realmente ajudam
Fossos não vêm de evitar problemas — vêm de absorvê‑los sem quebrar a promessa ao cliente.
Algumas táticas consistentemente eficazes:
- Estoque buffer em SKUs de alta velocidade, colocado regionalmente para proteger ETAs quando entradas atrasam.
- Transportadoras e rotas alternativas para que um gargalo não congele uma região inteira.
- Modelos flexíveis de mão de obra (pessoal multiqualificado, contratação para picos, playbooks de turnos estendidos) para lidar com semanas de pico sem caos.
O detalhe importante é orquestração: essas opções devem estar pré‑negociadas, ensaiadas e acionadas por limiares claros — não improvisadas na crise.
Risco oculto: sobredimensionar a rede
Uma grande rede vira passivo se a utilização cair. Excesso de capacidade aparece como custos fixos, automação subutilizada e pressão para “encher a máquina” com volume de baixa margem.
Estageie investimentos: expanda hub a hub, automatize onde volumes são estáveis e use capacidade temporária (sortação pop‑up, contratos de curto prazo) em períodos de crescimento incerto.
Quando ETAs falham, comunicação é parte do serviço
Clientes toleram atraso mais do que incerteza. O plano básico deve incluir notificações proativas, ETAs atualizados, janelas de corte claras e caminhos fáceis de cancelamento/reembolso. Se você publica promessas, mantenha‑as simples — e vincule regras de escalonamento — para que equipes de linha de frente possam agir com consistência.
Lições práticas: como aplicar o playbook da JD.com
A vantagem da JD.com não é só “enviar rápido”. É tornar resultados de entrega previsíveis — para que clientes confiem na promessa e o negócio escale sem incêndios constantes. Você pode pegar a lógica emprestada mesmo sem ter uma frota gigante.
Princípios repetíveis
1) Lógica de rede (onde você alcança com consistência): defina a área de serviço que você consegue cumprir consistentemente e só expanda quando o desempenho se mantiver estável.
2) Posicionamento de estoque (o que manter perto): coloque SKUs mais comuns e sensíveis ao tempo mais próximos da demanda. A confiabilidade melhora mais com “item certo, lugar certo” do que com remessas heroicas de última hora.
3) Padrões (como o trabalho é feito sempre): cortes claros, regras de embalagem, etapas de repasse ao transportador, tratamento de exceções e mensagens ao cliente reduzem surpresas.
4) Loops de feedback (como melhorar semanalmente): registre falhas, tagueie causas raiz e corrija o passo a montante — não apenas reembolse e siga em frente.
Plano inicial para varejistas menores (passo a passo)
-
Escolha uma promessa que possa cumprir. Exemplo: “Envia no mesmo dia para pedidos até 14h; entrega em 2–4 dias.” Publique e alinhe operações.
-
Separe SKUs por velocidade e dor. Identifique o top 20% de SKUs que geram 80% dos pedidos, mais itens que frequentemente causam atraso (frágeis, volumosos, perigosos, com lead time longo do fornecedor).
-
Crie um “pacote de confiabilidade.” Para esses SKUs: mais estoque de segurança, embalagens pré‑etiquetadas, locais de separação dedicados e opção de transportadora primária + backup.
-
Padronize repasses. Uma checklist de embalagem, um fluxo de rótulo, uma rotina de despacho ao fim do dia. Pequena consistência vence velocidade ocasional.
-
Instrumente exceções. Cada envio atrasado recebe um código de motivo (ruptura, erro de separação, falha da transportadora, problema de endereço). Revise semanalmente e corrija o maior motor.
Se quiser acelerar a etapa de instrumentação, não precisa reescrever toda sua stack. Muitas equipes começam lançando um app interno pequeno para captura de exceções e relatórios semanais, e depois ampliam. Uma plataforma de desenvolvimento rápido como Koder.ai pode ajudar a produzir essa “primeira versão funcional” e iterar sem grandes handoffs.
Próximos 90 dias: checklist “faça a seguir”
- Semana 1–2: Defina promessa de entrega + horário de corte; audite principais causas de atraso.
- Semana 3–4: Realoque os fast movers; defina pontos de reordem; crie SOP de embalagem.
- Mês 2: Adicione transportadora backup; implemente códigos de exceção; ajuste notificações ao cliente.
- Mês 3: Defina SLAs internos (tempo de separação, precisão de embalagem, taxa de despacho); rode uma revisão semanal de confiabilidade.
Para comparações de custo e planos, vincule seu trabalho operacional a pressupostos claros de preço (/pricing). Para mais templates de processo e playbooks, mantenha uma lista interna de leitura (/blog).