Por que frameworks backend importam além de “escolher uma stack”
Um framework de backend é mais que um conjunto de bibliotecas. Bibliotecas ajudam em tarefas específicas (roteamento, validação, ORM, logging). Um framework adiciona um modo de trabalho opinativo: uma estrutura de projeto padrão, padrões comuns, ferramentas integradas e regras sobre como as peças se conectam.
Frameworks moldam decisões do dia a dia
Depois que um framework está em uso, ele orienta centenas de pequenas escolhas:
- Onde o novo código deve ficar (features, módulos, serviços)
- Como requisições atravessam a aplicação (controladores, middleware, handlers)
- Como lidar com preocupações transversais como auth, validação e erros
- Como as equipes nomeiam coisas, escrevem testes e revisam pull requests
É por isso que duas equipes construindo “a mesma API” podem acabar com codebases muito diferentes — mesmo usando a mesma linguagem e banco de dados. As convenções do framework viram a resposta padrão para “como fazemos isso aqui?”.
Velocidade e consistência vs. flexibilidade
Frameworks frequentemente trocam flexibilidade por estrutura previsível. O lado positivo é onboarding mais rápido, menos debates e padrões reutilizáveis que reduzem complexidade acidental. O lado negativo é que convenções do framework podem parecer restritivas quando o produto precisa de fluxos incomuns, otimizações de performance ou arquiteturas não padrão.
Uma boa decisão não é “usar framework ou não”, mas quanto de convenção você quer — e se sua equipe está disposta a pagar o custo da customização ao longo do tempo.
Quem deve se importar
- Engenheiros: menos tempo reinventando padrões, mais tempo entregando features
- Tech leads: padrões claros para arquitetura, testes e revisões de código
- Times de produto: entregas mais previsíveis e menos regressões de qualidade conforme a base cresce
Defaults do framework que definem sua estrutura de projeto
A maioria das equipes não começa com uma pasta vazia — começa com o layout “recomendado” do framework. Esses defaults decidem onde as pessoas colocam código, como nomeiam coisas e o que parece “normal” nas revisões.
As duas mentalidades padrão mais comuns
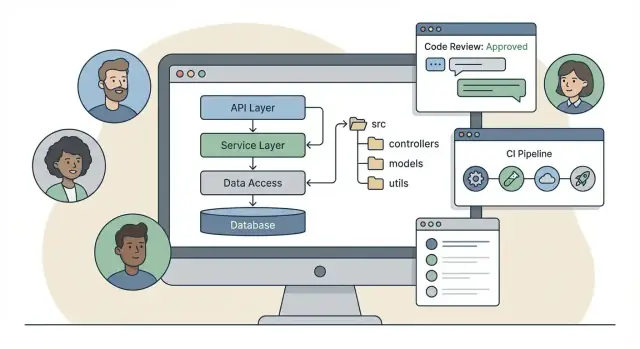
Alguns frameworks empurram uma estrutura clássica em camadas: controllers / services / models. É fácil de aprender e mapeia diretamente ao tratamento de requisições:
/src
/controllers
/services
/models
/repositories
Outros frameworks tendem a módulos por feature: agrupar tudo relativo a uma feature (handlers HTTP, regras de domínio, persistência). Isso incentiva raciocínio local — quando você trabalha em “Billing”, abre uma única pasta:
/src
/modules
/billing
/http
/domain
/data
Nenhuma das duas é automaticamente melhor, mas cada uma molda hábitos. Estruturas em camadas podem facilitar centralizar padrões transversais (logging, validação, tratamento de erro). Estruturas por módulos reduzem o “scroll horizontal” no código conforme ele cresce.
Ferramentas de scaffolding criam padrões duradouros
Geradores de CLI (scaffolding) são pegajosos. Se o gerador cria um par controller + service para cada endpoint, as pessoas continuarão fazendo isso — mesmo quando uma função simples bastaria. Se ele gera um módulo com limites claros, equipes têm mais probabilidade de respeitar essas fronteiras sob pressão de prazo.
A mesma dinâmica aparece em fluxos de trabalho “vibe-coding”: se os defaults da sua plataforma produzem um layout previsível e divisões de módulo claras, as equipes tendem a manter a coerência do código à medida que ele cresce. Por exemplo, Koder.ai gera apps full-stack a partir de prompts de chat, e o benefício prático (além da velocidade) é que sua equipe pode padronizar estruturas e padrões cedo — e depois iterar sobre eles como qualquer outro código (incluindo exportar o código fonte quando quiser controle total).
Evitando “controladores gordos”
Frameworks que colocam controladores em destaque podem tentar empurrar regras de negócio para handlers de requisição. Uma regra prática útil: controladores traduzem HTTP → chamada de aplicação, e nada mais. Coloque lógica de negócio em uma camada de serviço/use-case (ou na camada de domínio do módulo), para que ela possa ser testada sem HTTP e reutilizada por jobs em background ou tarefas CLI.
Uma checagem rápida para sua estrutura
Se você não consegue responder “Onde fica a lógica de precificação?” em uma frase, os defaults do framework podem estar brigando com seu domínio. Ajuste cedo — pastas são fáceis de mudar; hábitos não são.
Fluxo de requisição: convenções de roteamento, controladores e middleware
Um framework de backend não é apenas um conjunto de bibliotecas — ele define como uma requisição deve viajar pelo código. Quando todos seguem o mesmo caminho de requisição, features são entregues mais rápido e revisões passam a tratar mais de correção do que de estilo.
Roteamento: o mapa público do seu sistema
Rotas devem ler como um sumário da sua API. Bons frameworks incentivam rotas que são:
- Declarativas (você consegue escanear e entender o que está exposto)
- Consistentes (mesmos padrões de URL e verbos HTTP em todo o código)
- Próximas da borda (config de roteamento não deve conter regras de negócio)
Uma convenção prática é manter arquivos de rota focados em mapear: GET /orders/:id -> OrdersController.getById, não “se o usuário for VIP, faça X”.
Controladores/handlers: tradutores leves de requisição
Controladores funcionam melhor como tradutores entre HTTP e sua lógica principal:
- Ler inputs (params, headers, body)
- Chamar um serviço/use-case
- Retornar uma resposta
Quando frameworks fornecem helpers para parsing, validação e formatação de resposta, equipes são tentadas a empilhar lógica nos controladores. O padrão mais saudável é “controladores leves, serviços grossos”: mantenha preocupações de request/response nos controladores e decisões de negócio em uma camada separada que não conhece HTTP.
Middleware/filters: um lugar para preocupações transversais
Middleware (ou filters/interceptors) define onde equipes colocam comportamentos repetidos como autenticação, logging, rate limiting e request IDs. A convenção chave: middleware deve enriquecer ou proteger a requisição, não implementar regras de produto.
Por exemplo, middleware de auth pode anexar req.user, e controladores podem passar essa identidade para a lógica central. Middleware de logging pode padronizar o que é logado sem que cada controlador reinvente a roda.
Convenções de nomes que reduzem atrito em reviews
Combine nomes previsíveis:
OrdersController, OrdersService, CreateOrder (use-case)authMiddleware, requestIdMiddlewarevalidateCreateOrder (schema/validator)
Quando os nomes codificam intenção, revisões de código focam comportamento, não em onde as coisas “deveriam ter ido”.
Camadas e fronteiras: onde mora a lógica de negócio
Um framework de backend não apenas ajuda a entregar endpoints — ele empurra sua equipe para uma determinada “forma” de código. Se você não definir fronteiras cedo, a gravidade padrão frequentemente é: controladores chamam o ORM, o ORM chama o banco, e regras de negócio ficam espalhadas.
Uma arquitetura em camadas prática
Uma separação simples e durável fica assim:
- Camada de apresentação: preocupações HTTP (roteamento, controladores, middleware de auth). Converte requisições em comandos da aplicação e retorna respostas.
- Camada de aplicação: use-cases (por exemplo,
CreateInvoice, CancelSubscription). Orquestram trabalho e transações, mas permanecem pouco dependentes do framework.
- Camada de domínio: regras e conceitos centrais do negócio (entidades, políticas, domain services). Deve ler como negócio, não como SQL.
- Camada de dados: repositórios, modelos/mappers do ORM, queries, migrations.
Frameworks que geram “controllers + services + repositories” podem ajudar — se você tratar isso como fluxo direcional, não como requisito de que toda feature precise de cada camada.
Como ORMs e repositórios influenciam fronteiras
Um ORM facilita a tentação de passar modelos do DB por todo lado porque são convenientes e já validados em certa medida. Repositórios ajudam oferecendo uma interface mais estreita (“pega cliente por id”, “salva invoice”), de modo que aplicação e domínio não dependam dos detalhes do ORM.
Para evitar designs onde “tudo depende do banco”:
- Não retorne entidades do ORM diretamente dos controladores.
- Mantenha formatos de query na camada de dados; mantenha regras no domínio.
- Prefira inputs/outputs amigáveis ao domínio para use-cases.
Quando introduzir uma camada de serviço (e quando não)
Adicione uma camada de serviço/use-case quando a lógica for reutilizada entre endpoints, exigir transações ou precisar aplicar regras de forma consistente. Pule essa camada para CRUD simples que realmente não tem comportamento de negócio — adicionar camadas ali vira cerimônia sem clareza.
Injeção de dependências e hábitos de design modular
Dependency Injection (DI) é um desses defaults do framework que treina toda a equipe. Quando vem integrado ao framework, você para de “new” serviços em lugares aleatórios e passa a tratar dependências como algo a declarar, conectar e trocar intencionalmente.
O que DI incentiva (e o que pode complicar)
DI empurra equipes a componentes pequenos e focados: um controlador depende de um serviço, um serviço depende de um repositório, e cada parte tem um papel claro. Isso tende a melhorar testabilidade e torna alterações de implementação (por exemplo, gateway de pagamento real vs mock) mais simples.
O lado negativo é que DI pode esconder complexidade. Se cada classe depende de cinco outras, fica difícil entender o que realmente roda numa requisição. Containers mal configurados também podem causar erros que parecem distantes do código que você editou.
Injeção por construtor e design guiado por interfaces
A maioria dos frameworks favorece injeção por construtor porque torna dependências explícitas e evita padrões de “service locator”.
Um hábito útil é combinar injeção por construtor com design orientado a contratos: o código depende de um contrato estável (como EmailSender) em vez de um cliente de fornecedor específico. Isso mantém mudanças localizadas ao trocar provedores ou refatorar.
Módulos coesos sem dependências circulares
DI funciona melhor quando seus módulos são coesos: um módulo possui uma fatia de funcionalidade (orders, billing, auth) e expõe uma superfície pública pequena.
Dependências circulares são uma falha comum. Frequentemente indicam que fronteiras estão pouco claras — dois módulos compartilham conceitos que merecem um módulo próprio, ou um módulo está fazendo demais.
Concordando onde o wiring acontece
Times devem concordar onde as dependências são registradas: uma composition root única (startup/bootstrap), mais wiring no nível de módulo para internações. Manter o wiring centralizado facilita revisões: revisores podem ver novas dependências, confirmar justificativa e evitar “container sprawl” que transforma DI em mistério.
Construa e ganhe créditos
Ganhe créditos compartilhando o que você constrói no Koder.ai ou convidando outros para experimentar.
Um framework influencia o que significa “uma boa API” na sua equipe. Se validação é uma feature de primeira classe (decorators, schemas, pipes, guards), as pessoas projetam endpoints em torno de inputs claros e outputs previsíveis — porque é mais fácil fazer a coisa certa do que ignorá-la.
Quando validação vive na fronteira (antes da lógica de negócio), equipes começam a tratar payloads como contratos, não como “o que o cliente mandar”. Isso tende a gerar:
- Campos explicitamente obrigatórios vs opcionais (e menos discussões sobre “null significa desconhecido”)
- Regras claras de formato (datas, IDs, enums) e restrições (min/max, length)
- Rejeição precoce de requests inválidos, mantendo código de serviço focado em regras de negócio
É também aqui que frameworks incentivam convenções compartilhadas: onde definir validação, como expor erros e se campos desconhecidos são permitidos.
Erros centralizados criam expectativas consistentes para clientes
Frameworks que suportam filtros/handlers globais de exceção tornam consistência alcançável. Em vez de cada controlador inventar respostas, você padroniza:
- Envelope de erro (ex.:
code, message, details, traceId)
- Mapeamento de status HTTP (validação → 400, auth → 401/403, not found → 404)
- Logging e IDs de correlação para que suporte debuge uma única requisição falhando
Um formato de erro consistente reduz lógica condicional no front-end e torna docs de API mais confiáveis.
DTOs e view models protegem seu interno
Muitos frameworks incentivam DTOs (input) e view models (output). Essa separação é saudável: evita expor campos internos acidentalmente, evita acoplamento de clientes a schemas de banco e torna refactors mais seguros. Regra prática: controladores falam em DTOs; serviços falam em modelos de domínio.
Versionamento e princípios de compatibilidade
Mesmo APIs pequenas evoluem. Convenções de roteamento frequentemente determinam se o versionamento é por URL (/v1/...) ou por header. Qualquer que seja a escolha, defina o básico cedo: nunca remova campos sem janela de depreciação, adicione campos de forma compatível e documente mudanças em um lugar só (por exemplo, /docs ou /changelog).
Estratégia de testes influenciada pelas ferramentas do framework
Um framework não só ajuda a entregar features; ele dita como você as testa. O test runner integrado, utilitários de boot e o container DI frequentemente determinam o que é fácil — e isso vira o que sua equipe realmente faz.
Helpers do framework: unit vs integração vs end-to-end
Muitos frameworks fornecem um “test app” que sobe o container, registra rotas e roda requisições em memória. Isso puxa equipes para testes de integração cedo — porque costumam ser poucas linhas a mais do que um unit test.
Uma divisão prática:
- Unit tests para lógica pura de negócio (sem boot do framework, sem DB).
- Integration tests para módulos/serviços conectados via container do framework.
- End-to-end tests para comportamento HTTP real (roteamento, middleware, auth, mapeamento de erros).
Pirâmide de testes que cabe em serviços backend
Para a maioria dos serviços, velocidade importa mais do que pureza da pirâmide. Uma boa regra: mantenha muitos testes unitários pequenos, um conjunto focado de testes de integração nas fronteiras (DB, filas) e uma camada fina de E2E que prove o contrato.
Se seu framework torna simulação de requisição barata, você pode tender um pouco mais para testes de integração — mantendo a lógica de domínio isolada para que os unit tests continuem estáveis.
Mocking alinhado ao DI e runtime
Estratégia de mocks deve seguir como o framework resolve dependências:
- Prefira sobrescrever bindings do DI (trocar um cliente de email real por um fake) em vez de monkey-patching imports.
- Use adaptadores em memória quando possível (ex.: repositórios em memória) para evitar mocks frágeis.
- Mock no limite do módulo, não dentro da lógica de negócio, assim refactors não quebram testes.
Testes rápidos e confiáveis para CI
Tempo de boot do framework pode dominar o CI. Mantenha testes rápidos cacheando setups caros, rodando migrations uma vez por suíte e usando paralelização só onde o isolamento estiver garantido. Facilite diagnóstico de falhas: seed consistente, relógios determinísticos e hooks de cleanup rigorosos vencem “retry on fail”.
Escalando a codebase: módulos, pacotes e código compartilhado
Padronize hábitos da equipe
Alinhe engenheiros em nomes, regras de pastas e hábitos de revisão começando de uma base compartilhada.
Frameworks não só ajudam a entregar a primeira API — eles moldam como seu código cresce quando um “serviço” vira dezenas de features, times e integrações. Os mecanismos de módulo/pacote que o framework facilita normalmente viram sua arquitetura de longo prazo.
Padrões de modularidade que frameworks incentivam
A maioria dos frameworks empurra para modularidade por design: apps, plugins, blueprints, módulos, feature folders ou packages. Quando isso é padrão, equipes tendem a adicionar capacidades como “mais um módulo” em vez de espalhar arquivos pela base.
Uma regra prática: trate cada módulo como um mini-produto com sua própria superfície pública (rotas/handlers, interfaces de serviço), internos privados e testes. Se o framework suporta auto-discovery (ex.: module scanning), use com cuidado — imports explícitos frequentemente tornam dependências mais fáceis de raciocinar.
Módulos de domínio core vs módulos de infraestrutura
Conforme a codebase cresce, misturar regras de negócio com adaptadores fica caro. Uma separação útil é:
- Módulos de domínio core: regras de negócio, políticas, domain services e modelos de domínio (componentes que devem sobreviver a uma troca de banco)
- Módulos de infraestrutura: clientes de banco, modelos ORM, brokers de mensagens, clients HTTP, caches, provedores de auth
Convenções do framework influenciam isso: se o framework incentiva “classes de serviço”, coloque domain services em módulos core e mantenha wiring específico do framework (controllers, middleware, providers) nas bordas.
Bibliotecas compartilhadas vs copiar-colar: regras de decisão
Times costumam compartilhar cedo demais. Prefira copiar código pequeno até que esteja estável, depois extraia quando:
- duas ou mais equipes mantêm a mesma lógica
- um bug precisa ser corrigido em múltiplos lugares
- você pode definir uma API clara e versioná-la
Ao extrair, publique pacotes internos (ou libs em workspace) com ownership estrito e disciplina de changelog.
Preparando-se para modular monolith → microservices (no futuro)
Um monolito modular é muitas vezes o melhor “meio termo”. Se módulos têm fronteiras claras e poucos imports cruzados, você pode depois levantar um módulo para serviço com menos churn. Modele módulos em torno de capacidades de negócio, não camadas técnicas. Para uma estratégia mais profunda, veja /blog/modular-monolith.
Configuração, ambientes e prontidão operacional
O modelo de configuração do framework molda quão consistentes (ou caóticos) seus deploys são. Quando config está espalhada entre arquivos ad-hoc, variáveis de ambiente e “só essa constante aqui”, equipes gastam tempo debugando diferenças em vez de construir features.
Estilo de configuração = consistência
A maioria dos frameworks orienta para uma fonte primária de verdade: arquivos de config, variáveis de ambiente ou configuração baseada em código (módulos/plugins). Qualquer caminho que escolher, padronize cedo:
- Arquivos funcionam bem para desenvolvimento local e defaults claros (ex.:
config/default.yml).
- Variáveis de ambiente são ótimas para diferenças em tempo de deploy e plataformas conteinerizadas.
- Config baseada em código pode ser poderosa, mas é fácil esconder configurações importantes atrás de lógica.
Uma convenção útil: defaults vivem em arquivos versionados, variáveis de ambiente sobrescrevem por ambiente, e o código lê de um objeto de config tipado. Isso mantém óbvio “onde mudar um valor” durante incidentes.
Segredos: trate como categoria separada
Frameworks frequentemente oferecem helpers para ler env vars, integrar secret stores ou validar config no boot. Use essas ferramentas para tornar segredos difíceis de manusear errado:
- Nunca comite segredos no repositório (nem chaves “temporárias”).
- Mantenha segredos fora de logs e páginas de erro.
- Prefira injeção em runtime (CI/CD, orquestrador de containers ou secret manager) ao invés de
.env local espalhado.
O hábito operacional desejado é simples: desenvolvedores rodam localmente com placeholders seguros, enquanto credenciais reais existem apenas no ambiente que precisa delas.
Paridade de ambiente: dev, staging, production
Defaults do framework podem incentivar paridade (mesmo processo de boot em qualquer ambiente) ou criar casos especiais (“production usa um entrypoint diferente”). Mire no mesmo comando de startup e no mesmo schema de config entre ambientes, mudando só valores.
Staging deve ser um ensaio: mesmos feature flags, mesmas migrations, mesmos background jobs — só em escala menor.
Documente config como uma API
Quando configuração não é documentada, colegas chutam — e chutes viram outages. Mantenha um resumo curto e atualizado no repo (por exemplo, /docs/configuration) listando:
- cada chave de config e o que controla
- tipo/formatos esperados (string, URL, inteiro)
- valor default e exemplos seguros
- quais ambientes devem setar cada chave
Muitos frameworks podem validar config no boot. Combine isso com documentação e você transforma “funciona na minha máquina” em uma exceção rara.
Padrões de observabilidade definidos pelo framework
Um framework estabelece a base de como você entende o sistema em produção. Quando observabilidade é integrada (ou fortemente encorajada), equipes deixam de tratar logs e métricas como “trabalho posterior” e começam a projetá-los como parte da API.
Logging, tracing e métricas: o que você ganha “de graça”
Muitos frameworks integram com ferramentas comuns de logging estruturado, tracing distribuído e coleta de métricas. Essa integração influencia organização de código: você tende a centralizar preocupações transversais (middleware de logging, interceptors de tracing, coletores de métricas) em vez de espalhar print statements.
Um padrão útil é definir um pequeno conjunto de campos obrigatórios que cada linha de log relacionada a requisição inclui:
correlation_id (ou request_id) para conectar logs entre serviçosroute e method para entender qual endpoint está envolvidouser_id ou account_id (quando disponível) para investigações de suporteduration_ms e status_code para performance e confiabilidade
Convenções do framework (como contextos de requisição ou pipelines de middleware) facilitam gerar e propagar correlation IDs consistentemente, evitando que desenvolvedores reinventem o padrão a cada feature.
Health checks e endpoints de readiness
Defaults de framework frequentemente determinam se health checks são cidadãos de primeira classe ou pensamento posterior. Endpoints padrão como /health (liveness) e /ready (readiness) viram parte da definição de “pronto”, e empurram requisitos operacionais para fora do código de feature:
- liveness: “o processo está rodando?”
- readiness: “pode servir tráfego?” (ex.: conexão DB, migrations aplicadas)
Quando esses endpoints são padronizados cedo, requisitos operacionais deixam de vazar para código de feature.
Usar observabilidade para guiar refactors
Dados de observabilidade também são ferramenta para decidir refactors. Se traces mostram que um endpoint gasta tempo repetido na mesma dependência, é um sinal claro para extrair um módulo, adicionar caching ou redesenhar uma query. Se logs mostram formatos de erro inconsistentes, é um prompt para centralizar tratamento de erros. Em outras palavras: hooks de observabilidade do framework não apenas ajudam a debugar — ajudam você a reorganizar a codebase com confiança.
Incorpore operabilidade
Configure logs e padrões operacionais desde cedo gerando uma app que você possa evoluir.
Um framework não só organiza código — ele define as “regras da casa” para como a equipe trabalha. Quando todos seguem as mesmas convenções (local de arquivo, nomes, como dependências são wired), revisões aceleram e onboarding fica mais fácil.
Geração de código e scaffolds: use, não adore
Ferramentas de scaffolding padronizam endpoints, módulos e testes em minutos. A armadilha é deixar geradores ditarem seu modelo de domínio.
Use scaffolds para criar conchas consistentes (rotas/controladores, DTOs, stubs de teste), e então edite o output para bater com suas regras arquiteturais. Uma boa política: geradores são permitidos, mas o código final deve parecer um design pensado — não um despejo de template.
Se estiver usando fluxo assistido por IA, aplique a mesma disciplina: trate código gerado como scaffolding. Em plataformas como Koder.ai, você pode iterar rápido via chat enquanto ainda aplica convenções de time (fronteiras de módulo, padrões de DI, formatos de erro) pelas revisões — porque velocidade só ajuda se a estrutura permanecer previsível.
Guias de estilo alinhados a idioms do framework
Frameworks muitas vezes implicam uma estrutura idiomática: onde fica validação, como erros são lançados, como serviços são nomeados. Capture essas expectativas num guia de estilo curto que inclua:
- Convenções de nomes que casem com primitivos do framework (ex.: Controller, Service, Module)
- Limites de pasta (o que é permitido em controller vs camada de domínio/serviço)
- Exemplos de um endpoint “bom"
Mantenha leve e acionável; linke do /contributing.
Automatize padrões. Configure formatadores e linters para refletir convenções do framework (imports, decorators/annotations, padrões async). Aplique via pre-commit hooks e CI para que revisões foquem design em vez de whitespace e nomes.
Templates de PR e checklists de revisão ligados à arquitetura
Um checklist baseado em framework evita deriva lenta para inconsistência. Adicione um template de PR que peça ao revisor confirmar coisas como:
- Novos endpoints seguem convenções de roteamento/controller
- Validação e respostas de erro batem com o padrão do time
- Limites de dependência são respeitados (sem chamadas diretas ao DB em controllers, etc.)
- Testes seguem padrões recomendados pelo framework
Com o tempo, esses guardrails de workflow são o que mantém a codebase manutenível à medida que o time cresce.
Escolhendo e evoluindo um framework sem rewrites dolorosos
Escolhas de framework tendem a travar padrões — layout de diretório, estilo de controller, DI, até como as pessoas escrevem testes. O objetivo não é escolher o framework perfeito; é escolher um que combine com a forma como sua equipe entrega software, e manter a possibilidade de mudança quando requisitos mudarem.
Avaliando ajuste ao tamanho e objetivos do time
Comece pelas suas restrições de entrega, não por checagens de feature. Um time pequeno geralmente se beneficia de convenções fortes, tooling “batteries-included” e onboarding rápido. Times maiores precisam de fronteiras de módulo mais claras, pontos de extensão estáveis e padrões que dificultem acoplamento oculto.
Faça perguntas práticas:
- Você consegue fazer cumprir estrutura consistente com mínima fiscalização nas revisões?
- O framework facilita a coisa certa (validação, tratamento de erro, logging), ou cada time inventa sua própria solução?
- Upgrades são previsíveis (changelogs claros, caminhos de deprecação), e o ecossistema é maduro o suficiente?
Sinais de alerta que prevêem rewrites
Um rewrite costuma ser o resultado de dores pequenas ignoradas por muito tempo. Fique de olho:
- Fronteiras pouco claras: lógica de negócio escorrendo para controllers, middleware ou modelos ORM
- Testes lentos: integração que leva minutos, empurrando equipes a pular testes
- Upgrades frágeis: mudanças breaking frequentes, dependência em APIs internas ou workarounds da comunidade virando norma
Padrões de refactor incremental que mantêm entrega
Você pode evoluir sem parar o trabalho de features introduzindo seams:
- Abordagem strangler: direcione um conjunto pequeno de endpoints para um novo módulo mantendo o sistema antigo rodando
- Camadas adapter: envolva primitivos específicos do framework por suas próprias interfaces (request context, logger, repositories)
- Fronteiras “ports and adapters”: mova lógica de domínio para módulos plain com importações mínimas do framework e faça o wiring nas bordas
Checklist de adoção e próximos passos
Antes de assumir (ou antes do próximo grande upgrade), faça um pequeno trial:
- Construa um endpoint real end-to-end: auth, validação, respostas de erro e logging.
- Escreva dois testes: um unitário rápido para lógica de domínio e um de integração para a camada HTTP.
- Simule uma mudança: adicione um campo, version a resposta e refatore um módulo.
- Revise notas de upgrade da última versão major — isso teria te afetado?
Se quiser uma forma estruturada de avaliar opções, crie um RFC leve e guarde no repositório (ex.: /docs/decisions) para que times futuros entendam por que escolheram e como mudar com segurança.
Uma lente extra a considerar: se seu time está experimentando ciclos de build mais rápidos (incluindo desenvolvimento guiado por chat), avalie se o fluxo ainda produz os mesmos artefatos arquiteturais — módulos claros, contratos aplicáveis e defaults operáveis. Os melhores ganhos de velocidade (sejam via CLI do framework ou por uma plataforma como Koder.ai) são os que reduzem o tempo por ciclo sem corroer as convenções que mantêm um backend manutenível.