O que “ACID” significa para transações do dia a dia
Quando você paga por mantimentos, reserva um voo ou transfere dinheiro entre contas, espera um resultado sem ambiguidade: ou deu certo, ou não. Bancos de dados tentam oferecer essa mesma certeza — mesmo quando muitas pessoas usam o sistema ao mesmo tempo, servidores caem ou redes falham.
Uma transação, em termos simples
Uma transação é uma unidade de trabalho que o banco trata como um único “pacote”. Pode incluir vários passos — subtrair inventário, criar um registro de pedido, cobrar um cartão e escrever um recibo — mas deve se comportar como uma ação coerente.
Se qualquer etapa falha, o sistema deve rebobinar até um ponto seguro em vez de deixar um meio-acabado bagunçado.
Por que atualizações parciais causam problemas reais de negócio
Atualizações parciais não são apenas falhas técnicas; viram chamados de suporte e risco financeiro. Por exemplo:
- Um pagamento é capturado, mas o pedido não é criado — clientes são cobrados sem confirmação.
- Um pedido é criado, mas o inventário não é reduzido — seu site vende mais do que tem e depois cancela.
- Uma transferência bancária debita uma conta mas não credita a outra — saldos deixam de fazer sentido.
Essas falhas são difíceis de depurar porque tudo parece “mais ou menos correto”, mas os números não batem.
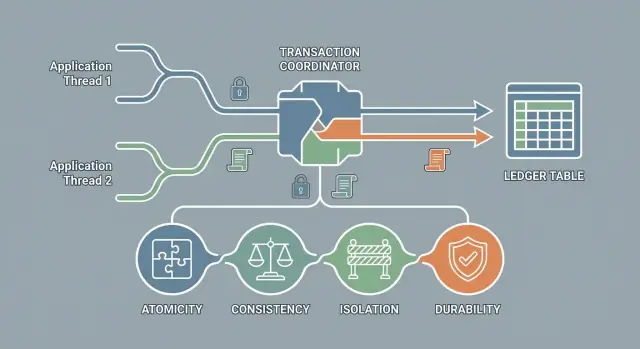
ACID é um conjunto de garantias (não um produto)
ACID é uma abreviação para quatro garantias que muitos bancos de dados podem fornecer para transações:
- Atomicidade: execução tudo-ou-nada
- Consistência: os dados permanecem dentro de regras válidas
- Isolamento: transações concorrentes não interferem de forma insegura
- Durabilidade: uma vez confirmado, a mudança persiste
Não é uma marca específica nem um único recurso que você liga; é uma promessa sobre o comportamento.
Benefícios — e os custos que você deve esperar
Garantias mais fortes geralmente significam que o banco precisa fazer mais trabalho: coordenação extra, aguardar locks, rastrear versões e escrever em logs. Isso pode reduzir throughput ou aumentar latência sob carga pesada. O objetivo não é “máxima ACID o tempo todo”, e sim escolher garantias que combinem com os riscos reais do seu negócio.
Atomicidade: atualizações tudo-ou-nada
Atomicidade significa que uma transação é tratada como uma única unidade de trabalho: ou ela termina completamente ou não tem efeito nenhum. Você nunca vê uma “meia atualização” no banco.
Um exemplo simples de transferência bancária
Imagine transferir $50 de Alice para Bob. Por trás dos panos, isso normalmente envolve pelo menos duas mudanças:
- Subtrair $50 do saldo da Alice
- Somar $50 ao saldo do Bob
Com atomicidade, essas duas mudanças acontecem junto ou falham junto. Se o sistema não puder fazer ambas com segurança, ele não faz nenhuma. Isso evita o pesadelo onde Alice é cobrada mas Bob não recebe o dinheiro (ou Bob recebe sem Alice ser cobrada).
Commit vs. rollback (em termos simples)
Bancos dão duas saídas a uma transação:
- Commit: “Todas as etapas sucederam; torne os resultados oficiais.”
- Rollback: “Algo deu errado; desfaça tudo desta transação.”
Um modelo mental útil é “rascunho vs publicar”. Enquanto a transação está em execução, as mudanças são provisórias. Apenas um commit as publica.
O que pode dar errado no meio de uma transação?
Atomicidade importa porque falhas são normais:
- Crash da aplicação: seu serviço para depois de atualizar uma tabela, mas antes de atualizar a próxima.
- Queda de rede: o app não alcança o banco, ou o cliente nunca recebe a resposta de sucesso.
- Perda de energia: o servidor do banco para inesperadamente.
Se qualquer um desses acontecer antes do commit, a atomicidade garante que o banco pode fazer rollback para que trabalho parcial não vaze para saldos reais.
Atomicidade protege o estado do banco, mas sua aplicação ainda precisa lidar com incertezas — especialmente quando uma queda de rede deixa em dúvida se um commit aconteceu.
Dois complementos práticos:
- Retries: repetir uma requisição quando não se obtém resposta.
- Idempotência: tornar seguro repetir a mesma requisição (por exemplo, usando uma chave de idempotência para que “transferência #123” seja aplicada no máximo uma vez).
Juntas, transações atômicas e retries idempotentes ajudam a evitar tanto atualizações parciais quanto cobranças duplicadas acidentais.
Consistência: manter os dados dentro de regras válidas
Consistência em ACID não significa “os dados parecem razoáveis” ou “todas as réplicas batem”. Significa que toda transação deve levar o banco de dados de um estado válido para outro estado válido — conforme as regras que você definiu.
Consistência é definida por regras que você escolhe
Um banco de dados só pode manter consistência em relação a constraints explícitas, triggers e invariantes que descrevem o que “válido” significa para seu sistema. ACID não inventa essas regras; ele as aplica durante as transações.
Exemplos comuns incluem:
- Chaves estrangeiras: todo
order.customer_id deve apontar para um cliente existente.
- Constraints de unicidade: dois usuários não podem compartilhar o mesmo email.
- Check constraints / invariantes: um saldo não pode ficar abaixo de zero, ou a quantidade de um item não pode ser negativa.
Se essas regras existirem, o banco rejeitará qualquer transação que as viole — assim você não acaba com dados “meio válidos”.
Validação na aplicação vs. constraints no banco
Validação no app é importante, mas não é suficiente sozinha.
- Validação na aplicação melhora a experiência (mensagens claras, feedback precoce) e pode impor regras de negócio complexas.
- Constraints no banco atuam como a última barreira — especialmente quando múltiplos serviços, jobs em background, imports ou ferramentas administrativas escrevem nas mesmas tabelas.
Um modo clássico de falha é checar algo no app (“email disponível”) e então inserir a linha. Sob concorrência, duas requisições podem passar na checagem ao mesmo tempo. Uma unique constraint no banco é o que garante que apenas uma inserção terá sucesso.
Como a consistência se parece na prática
Se você codifica “saldo não negativo” como uma constraint (ou faz cumprir isso de forma confiável dentro de uma transação), então qualquer transferência que fosse deixar a conta negativa deve falhar como um todo. Se você não codificar essa regra em lugar nenhum, ACID não pode protegê-la — porque não há nada para aplicar.
Consistência é, em última análise, sobre ser explícito: defina as regras e deixe as transações garantir que elas nunca sejam quebradas.
Isolamento garante que transações não se atrapalhem. Enquanto uma transação está em andamento, outras não devem ver trabalho meio feito nem sobrescrever acidentalmente. O objetivo é simples: cada transação deve se comportar como se estivesse rodando sozinha, mesmo com muitos usuários ativos ao mesmo tempo.
Por que concorrência torna isso difícil
Sistemas reais são ocupados: clientes fazem pedidos, agentes de suporte atualizam perfis, jobs em background reconciliam pagamentos — tudo ao mesmo tempo. Essas ações se sobrepõem no tempo e frequentemente tocam as mesmas linhas (um saldo, contagem de inventário ou vaga de reserva).
Sem isolamento, o tempo vira parte da lógica de negócio. Uma atualização de “subtrair estoque” pode competir com outro checkout, ou um relatório pode ler dados no meio de uma mudança e mostrar números que nunca existiram em um estado estável.
Isolamento geralmente é configurável
O “agir como se você estivesse sozinho” completo pode ser caro. Pode reduzir throughput, aumentar esperas (locks) ou causar retries de transação. Ao mesmo tempo, muitos fluxos não precisam da proteção mais estrita — ler analytics de ontem, por exemplo, tolera pequenas inconsistências.
Por isso bancos oferecem níveis de isolamento configuráveis: você escolhe quanta risco de concorrência aceita em troca de melhor desempenho e menos conflitos.
Uma prévia rápida: anomalias que o isolamento previne (ou permite)
Quando o isolamento é fraco demais para sua carga, você encontrará anomalias clássicas:
- Dirty reads: ler mudanças que outra transação ainda não confirmou.
- Lost updates: duas transações sobrescrevem-se e um conjunto de mudanças some.
- Phantom reads: reexecutar uma consulta retorna um conjunto de linhas diferente porque outra transação inseriu ou removeu linhas que batem a condição.
Entender esses modos de falha facilita escolher um nível de isolamento que corresponda às promessas do seu produto.
Anomalias comuns que o isolamento previne (ou permite)
Implemente um fluxo de checkout mais seguro
Prototipe o checkout com reserva de estoque e intent de pagamento dentro da transação correta.
Isolamento determina o que outras transações podem “ver” enquanto a sua ainda roda. Quando o isolamento é fraco para uma carga, aparecem anomalias — comportamentos tecnicamente possíveis, mas surpreendentes para usuários.
Anomalias de leitura
Dirty read acontece quando você lê dados que outra transação escreveu mas não confirmou.
Cenário: Alex transfere $500 para fora de uma conta, o saldo fica temporariamente $200, e você lê $200 antes da transferência de Alex falhar e fazer rollback.
Resultado para o usuário: cliente vê saldo incorreto baixo, uma regra antifraude dispara incorretamente, ou um atendente dá a resposta errada.
Non-repeatable read significa que você lê a mesma linha duas vezes e obtém valores diferentes porque outra transação confirmou alterações entre as leituras.
Cenário: você carrega o total de um pedido ($49,00) e, ao atualizar, vê $54,00 porque uma linha de desconto foi removida.
Resultado para o usuário: “meu total mudou enquanto eu estava finalizando”, levando a desconfiança ou abandono do carrinho.
Phantom read é parecido com non-repeatable read, mas com um conjunto de linhas: uma segunda consulta retorna linhas extras (ou faltantes) porque outra transação inseriu/excluiu registros que batem a condição.
Cenário: busca de hotel mostra “3 quartos disponíveis”, então ao tentar reservar o sistema rechecaa e encontra nenhum porque novas reservas foram adicionadas.
Resultado para o usuário: tentativas de dupla reserva, telas de disponibilidade inconsistentes ou venda em excesso.
Anomalias de escrita (bugs comuns do mundo real)
Lost update ocorre quando duas transações leem o mesmo valor e ambas gravam atualizações, com a gravação posterior sobrescrevendo a anterior.
Cenário: dois admins editam o preço do mesmo produto. Ambos partem de $10; um salva $12, o outro salva $11 por último.
Resultado para o usuário: a mudança de alguém desaparece; totais e relatórios ficam errados.
Write skew acontece quando duas transações fazem mudanças que, individualmente, são válidas, mas juntas violam uma regra.
Cenário: Regra: “Pelo menos um médico de plantão deve estar escalado.” Dois médicos, independentemente, se desmarcam após verificar que o outro ainda está de plantão.
Resultado para o usuário: você fica sem cobertura, apesar de cada transação ter “passado” suas checagens.
Por que não usar sempre o isolamento mais estrito?
Isolamento mais forte reduz anomalias, mas pode aumentar esperas, retries e custos sob alta concorrência. Muitos sistemas escolhem isolamento mais fraco para leituras analíticas, enquanto usam configurações mais rígidas para movimentação de dinheiro, reservas e outros fluxos críticos para corretude.
Níveis de Isolamento: escolhendo a configuração certa
Isolamento trata do que sua transação pode “ver” enquanto outras ocorrem. Bancos expõem isso como níveis de isolamento: níveis mais altos reduzem comportamentos surpreendentes, mas podem custar throughput ou aumentar esperas.
Níveis comuns de isolamento
- Read Uncommitted: você pode ler mudanças que outra transação ainda não confirmou (“dirty reads”). Quase nada é prevenido.
- Read Committed: você lê apenas dados confirmados, então dirty reads são prevenidos. Mas se você rodar a mesma consulta duas vezes, pode ver resultados diferentes porque alguém confirmou algo entre as leituras (“non-repeatable reads”).
- Repeatable Read: leituras que você já fez permanecem estáveis durante a transação, então non-repeatable reads são geralmente prevenidos. Dependendo do mecanismo, você ainda pode ver “phantoms” (linhas novas que batem a busca) ou não.
- Serializable: transações se comportam como se fossem executadas uma a uma. É a configuração mais forte, prevenindo geralmente dirty reads, non-repeatable reads e phantoms, e reduzindo muitas anomalias sutis de escrita.
Escolhendo um nível: throughput vs. corretude
Times frequentemente escolhem Read Committed como padrão para apps de usuário: bom desempenho, e “sem dirty reads” corresponde à maioria das expectativas.
Use Repeatable Read quando precisar de resultados estáveis dentro de uma transação (por exemplo, gerar uma fatura a partir de linhas de item) e puder tolerar alguma sobrecarga.
Use Serializable quando a corretude for mais importante que a concorrência (por exemplo, fazer cumprir invariantes complexas como “nunca vender mais do que o estoque”), ou quando você não consegue raciocinar facilmente sobre condições de corrida no código da aplicação.
Read Uncommitted é raro em sistemas OLTP; às vezes é usado para monitoramento ou relatórios aproximados onde leituras erradas ocasionais são aceitáveis.
Aviso importante: o comportamento varia
Os nomes são padronizados, mas garantias exatas diferem por motor de banco de dados (e às vezes por configuração). Confirme na documentação do seu banco e teste as anomalias que importam para o seu negócio.
Durabilidade: fazer commits permanecerem
Durabilidade significa que, uma vez que uma transação é confirmada, seus resultados devem sobreviver a um crash — perda de energia, reinício de processo ou reboot de máquina. Se sua aplicação diz a um cliente “pagamento bem-sucedido”, durabilidade é a promessa de que o banco não vai “esquecer” esse fato após a próxima falha.
Como bancos tornam commits sobreviventes a crashes
A maioria dos bancos relacionais alcança durabilidade com write-ahead logging (WAL). Em alto nível, o banco grava um “recibo” sequencial de mudanças no log no disco antes de considerar a transação como confirmada. Se ocorrer um crash, ele pode reproduzir o log na inicialização para restaurar as mudanças confirmadas.
Para manter o tempo de recuperação razoável, os bancos também criam checkpoints. Um checkpoint é um momento em que o banco garante que mudanças recentes suficientes foram gravadas nos arquivos de dados principais, para que a recuperação não precise reproduzir um histórico de log ilimitado.
Durabilidade depende de armazenamento e configuração
Durabilidade não é um interruptor único; depende de quão agressivamente o banco força dados a armazenamento estável.
- Com configurações síncronas, o banco aguarda o log ser persistido (frequentemente via
fsync) antes de confirmar o commit. Isso é mais seguro, mas pode aumentar latência.
- Com configurações assíncronas, o banco pode reconhecer o commit antes do log estar totalmente em storage durável. O desempenho melhora, mas um crash pode perder transações “confirmadas” mais recentes.
O hardware subjacente também importa: SSDs, controladoras RAID com cache de escrita e volumes de nuvem podem se comportar diferente sob falha.
Backups e replicação são relacionados — mas diferentes
Backups e replicação ajudam a recuperar ou reduzir tempo de inatividade, mas não são o mesmo que durabilidade. Uma transação pode ser durável no primário mesmo que não tenha chegado a uma réplica ainda, e backups são tipicamente snapshots no tempo, não garantias commit-a-commit.
Como bancos aplicam ACID por baixo dos panos
Evite bugs de concorrência comuns
Monte um sistema de reservas ou inventário que evita vendas em excesso e atualizações perdidas.
Quando você BEGIN uma transação e depois COMMIT, o banco coordena muitas peças móveis: quem pode ler quais linhas, quem pode atualizá-las e o que acontece se duas pessoas tentarem mudar o mesmo registro ao mesmo tempo.
Controle de concorrência pessimista vs otimista
Uma escolha “por baixo” importante é como lidar com conflitos:
- Bloqueio pessimista assume que conflitos são prováveis. Quando uma transação atualiza uma linha, o banco a bloqueia para que outras transações tenham de esperar. Isso previne muitas anomalias, mas pode causar bloqueios.
- Abordagens otimistas assumem que conflitos são raros. Transações seguem adiante com menos bloqueio, e o banco detecta conflitos no commit (ou via verificações) e pode rejeitar uma transação para que ela seja reexecutada.
Muitos sistemas misturam as duas ideias dependendo da carga e do nível de isolamento.
MVCC: leitores não bloqueiam escritores
Bancos modernos frequentemente usam MVCC (Multi-Version Concurrency Control): em vez de manter apenas uma cópia de uma linha, o banco mantém múltiplas versões.
- Leitores podem ver um snapshot consistente (uma versão antiga) sem esperar.
- Escritores podem criar uma nova versão enquanto leituras continuam.
Isso é uma grande razão pela qual alguns bancos lidam com muitas leituras e escritas concorrentes com menos bloqueio — embora conflitos de escrita ainda precisem ser resolvidos.
Locks podem levar a deadlocks: Transação A espera por um lock de B, enquanto B espera por um lock de A.
Bancos normalmente resolvem isso detectando o ciclo e abortando uma transação (uma “vítima de deadlock”), retornando um erro para que a aplicação possa tentar novamente.
Sinais práticos de que algo está errado
Se a aplicação de ACID estiver criando atrito, você frequentemente verá:
- Aumentos em lock waits durante picos
- Timeouts (consultas falhando após esperar demais)
- Pontos quentes de contenção (poucas linhas/tabelas atualizadas constantemente, como contadores ou campos “última visualização”)
Esses sintomas geralmente significam que é hora de revisar o tamanho das transações, indexação ou qual estratégia de isolamento/bloqueio se ajusta à carga.
Como ACID molda decisões de design de aplicação
Garantias ACID não são só teoria de banco; influenciam como você projeta APIs, jobs em background e até fluxos de UI. A ideia central é simples: decida quais passos precisam suceder juntos e então envolva apenas esses passos numa transação.
Projetando APIs em torno de “uma mudança de negócio”
Uma API transacional boa geralmente mapeia para uma única ação de negócio, mesmo que toque várias tabelas. Por exemplo, uma operação /checkout pode: criar um pedido, reservar inventário e registrar uma intenção de pagamento. Essas gravações no banco normalmente devem viver numa única transação para que confirmem juntas (ou revertam juntas) se alguma validação falhar.
Um padrão comum é:
- Fazer validação de entrada antes de abrir a transação.
- Abrir a transação.
- Realizar as leituras/gravações mínimas necessárias.
- Commit.
Isso mantém atomicidade e consistência enquanto evita transações lentas e frágeis.
Limites de transação em requisições, serviços e jobs
Onde você coloca os limites de transação depende do que “uma unidade de trabalho” significa:
- Requisições de usuário: mantenha transações curtas — idealmente algumas queries. Não segure locks enquanto renderiza views ou espera por respostas externas.
- Jobs em background: trate cada tentativa do job como uma unidade de trabalho. Se um job processa 10.000 registros, faça commits em lotes para poder reiniciar com segurança.
- Fronteiras de serviço: prefira manter uma transação dentro do banco de um serviço. Cruzar serviços normalmente precisa de outra abordagem (como outbox), porque uma transação ACID não cobre facilmente múltiplos bancos.
Tratamento de erro: rollback, retries e replays seguros
ACID ajuda, mas sua aplicação ainda deve lidar com falhas corretamente:
- Rollback ao erro: se qualquer passo falhar, aborte a transação para que atualizações parciais não vazem.
- Retry em erros transitórios: falhas de serialização e deadlocks são normais sob concorrência. Retentar a transação inteira costuma ser o conserto certo.
- Tornar operações idempotentes: se uma requisição for reexecutada (pelo cliente ou pelo runner de jobs), você deve conseguir “reproduzi-la com segurança” sem cobranças/envios duplicados — use chaves de idempotência e constraints únicas.
Anti-padrões comuns
Evite transações longas, chamar APIs externas dentro de uma transação e tempo de pensamento do usuário dentro de uma transação (por exemplo, “bloquear a linha do carrinho e pedir usuário confirmar”). Isso aumenta contenção e torna conflitos de isolamento muito mais prováveis.
Onde ferramentas podem ajudar (sem mudar os fundamentos)
Se você está construindo um sistema transacional rapidamente, o maior risco raramente é “não conhecer ACID” — é espalhar inadvertidamente uma ação de negócio por múltiplos endpoints, jobs ou tabelas sem uma fronteira transacional clara.
Plataformas como Koder.ai podem ajudar a acelerar sem perder o desenho: você descreve um fluxo (por exemplo, “checkout com reserva de inventário e intenção de pagamento”) em um chat de planejamento, gera uma UI React mais backend em Go + PostgreSQL e itera com snapshots/rollback se um schema ou borda de transação precisar mudar. O banco ainda aplica as garantias; o valor está em acelerar o caminho de um design correto para uma implementação funcionando.
ACID em sistemas distribuídos e multi-serviços
Experimente sem medo
Itere esquemas e opções de isolamento, tire snapshots e reverta quando necessário.
Um único banco normalmente entrega garantias ACID dentro de uma fronteira transacional. Quando você espalha trabalho por múltiplos serviços (e frequentemente múltiplos bancos), manter essas mesmas garantias fica mais difícil — e mais caro quando tentam implementá-las.
Consistência vs. disponibilidade: a troca que você sente em produção
Consistência estrita significa que toda leitura vê a “verdade última” confirmada. Alta disponibilidade significa que o sistema continua respondendo mesmo quando partes estão lentas ou inacessíveis.
Num setup multi-serviço, um problema de rede temporário pode forçar uma escolha: bloquear ou falhar requisições até que todos os participantes concordem (mais consistente, menos disponível), ou aceitar que serviços possam ficar brevemente dessincronizados (mais disponível, menos consistente). Nenhuma opção é “sempre certa” — depende dos erros que seu negócio tolera.
Por que transações distribuídas são difíceis
Transações distribuídas exigem coordenação entre fronteiras que você não controla totalmente: atrasos de rede, retries, timeouts, crashes de serviço e falhas parciais.
Mesmo que cada serviço esteja correto, a rede pode criar ambiguidade: o serviço de pagamento confirmou mas o de pedidos nunca recebeu a confirmação. Para resolver isso com segurança, sistemas usam protocolos de coordenação (como two-phase commit), que podem ser lentos, reduzir disponibilidade em falhas e aumentar complexidade operacional.
Padrões práticos que substituem “uma grande transação”
Sagas quebram um fluxo em passos, cada um confirmado localmente. Se um passo posterior falha, passos anteriores são “desfeitos” por ações compensatórias (por exemplo, reembolsar uma cobrança).
Outbox/inbox tornam a publicação e consumo de eventos confiáveis. Um serviço grava dados de negócio e um registro de “evento a publicar” na mesma transação local (outbox). Consumidores registram IDs de mensagem processados (inbox) para lidar com retries sem duplicar efeitos.
Consistência eventual aceita janelas curtas onde dados diferem entre serviços, com um plano claro de reconciliação.
Quando relaxar garantias — e como controlar o risco
Relaxe garantias quando:
- Você tolera divergências temporárias (status de envio atrasado em relação ao pedido).
- Você pode corrigir erros com compensações (reembolsos, cancelamentos).
- Latência e disponibilidade importam mais que corretude global imediata.
Controle risco definindo invariantes (o que nunca pode ser violado), projetando operações idempotentes, usando timeouts e retries com backoff, e monitorando deriva (sagas presas, compensações repetidas, tabelas outbox crescendo). Para invariantes verdadeiramente críticas (por exemplo, “nunca gastar além do saldo”), mantenha-as dentro de um único serviço e uma única transação de banco quando possível.
Checklist prático: projetando, testando e monitorando sistemas ACID
Uma transação pode ser “correta” num teste unitário e ainda falhar sob tráfego real, reinícios e concorrência. Use este checklist para manter garantias ACID alinhadas com o comportamento em produção.
1) Design: defina invariantes e fronteira transacional
Comece escrevendo o que deve sempre ser verdade (suas invariantes de dados). Exemplos: “saldo nunca fica negativo”, “total do pedido é igual à soma dos itens”, “inventário não pode ficar abaixo de zero”, “um pagamento está vinculado a exatamente um pedido.” Trate isso como regras de produto, não apenas trivia de banco.
Depois decida o que precisa estar dentro de uma transação versus o que pode ser adiado.
- Invariantes de dados: liste tabelas/linhas envolvidas e a regra exata.
- Cenários de falha: crash de processo no meio da requisição, timeout de rede após o commit, retry causando duplicados, failover de réplica, disco cheio.
- Perfil de concorrência: quais operações rodam em paralelo (picos de checkout, updates em lote, jobs agendados), pontos esperados de contenção e se leituras precisam ser “agora” ou podem ser um pouco stale.
Mantenha transações pequenas: toque menos linhas, faça menos trabalho (sem chamadas externas) e comite rápido.
2) Teste: prove o comportamento sob corridas e falhas
Faça concorrência uma dimensão de teste de primeira classe.
- Testes de condição de corrida: rode a mesma operação crítica concorrentemente (por exemplo, dois checkouts do último item) e afirme que as invariantes nunca se quebram.
- Injeção de falhas: mate o processo da aplicação no meio da transação; injete timeouts; simule retries; force um reinício do banco; verifique que os resultados ou foram confirmados uma vez ou revertidos com segurança.
- Testes de carga com checagens de corretude: sob pico de throughput, valide não só latência mas também totais, contagens e constraints de “sem duplicados”.
Se você suporta retries, adicione uma chave de idempotência explícita e teste “requisição repetida após sucesso”.
3) Monitoramento: detecte dores ACID antes dos usuários
Monitore indicadores de que suas garantias estão ficando caras ou frágeis:
- Lock waits e tempos de fila (contenção crescente)
- Deadlocks (frequência, queries vítimas)
- Transações de longa execução (frequentemente a raiz)
- Lag de replicação (leituras stale e failover atrasado)
- Tempos de commit/fsync (pressão de armazenamento; custo da durabilidade)
Alarme em tendências, não só picos, e vincule métricas aos endpoints ou jobs que as causam.
Regras práticas: isolamento e escopo de transação
Use o isolamento mais fraco que ainda proteja suas invariantes; não “aumente ao máximo” por padrão. Quando precisar de corretude estrita para uma pequena seção crítica (movimentação de dinheiro, decremento de inventário), estreite a transação para só essa seção e mantenha todo o resto fora.