03 de abr. de 2025·8 min
Gerenciando Estado entre Frontend e Backend em Aplicações de IA
Aprenda como o estado de UI, sessão e dados se move entre frontend e backend em aplicações de IA, com padrões práticos para sincronização, persistência, cache e segurança.
O que “estado” significa em uma aplicação construída com IA
“Estado” é tudo o que sua aplicação precisa lembrar para se comportar corretamente de um momento para outro.
Se um usuário clica em Enviar numa interface de chat, a aplicação não deve esquecer o que ele digitou, o que o assistente já respondeu, se uma requisição ainda está em execução, ou quais configurações (tom, modelo, ferramentas) estão ativadas. Tudo isso é estado.
Estado, em termos simples
Uma forma útil de pensar em estado é: a verdade atual da aplicação — valores que afetam o que o usuário vê e o que o sistema fará a seguir. Isso inclui coisas óbvias como campos de formulários, mas também fatos “invisíveis” como:
- Em qual conversa o usuário está
- Se a última resposta está em streaming ou finalizada
- A lista de mensagens e sua ordem
- Chamadas de ferramentas e resultados de ferramentas (resultados de busca, consultas ao banco, extrações de arquivo)
- Erros, tentativas de repetição e backoff por limite de taxa
Por que apps de IA têm mais partes móveis
Aplicações tradicionais frequentemente leem dados, exibem e salvam atualizações. Apps de IA adicionam passos extras e saídas intermediárias:
- Uma única ação do usuário pode disparar múltiplas operações de backend (chamada ao LLM, chamada de ferramenta, outra chamada ao LLM).
- As respostas podem chegar incrementalmente (tokens em streaming), então a UI precisa gerenciar estado parcial.
- Contexto importa: o sistema pode precisar manter memória de conversa, resultados de ferramentas e configurações de modelo consistentes entre requisições.
Esse movimento extra é o motivo pelo qual o gerenciamento de estado costuma ser a complexidade oculta em aplicações de IA.
O que este guia cobrirá
Nas seções a seguir, vamos dividir o estado em categorias práticas (estado de UI, estado de sessão, dados persistidos e estado de modelo/runtime) e mostrar onde cada um deve viver (frontend vs. backend). Também cobriremos sincronização, cache, jobs de longa duração, atualizações em streaming e segurança — porque estado só é útil se for correto e protegido.
Exemplo rápido
Imagine um app de chat onde um usuário pede: “Resuma as faturas do mês passado e sinalize algo incomum.” O backend pode (1) buscar faturas, (2) rodar uma ferramenta de análise, (3) enviar um resumo em streaming para a UI e (4) salvar o relatório final.
Para que isso pareça contínuo, a aplicação deve acompanhar mensagens, resultados de ferramentas, progresso e o output salvo — sem confundir conversas ou vazar dados entre usuários.
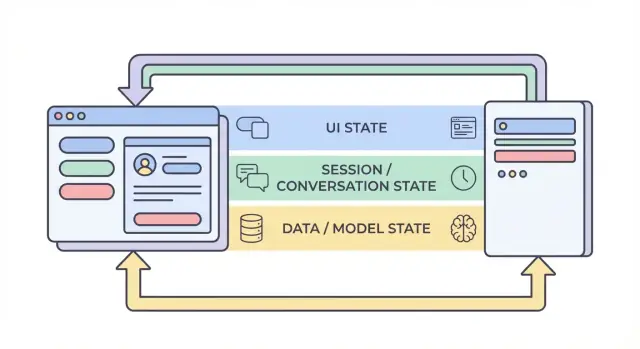
As quatro camadas de estado: UI, sessão, dados e modelo
Quando as pessoas dizem “estado” em um app de IA, frequentemente misturam coisas bem diferentes. Dividir o estado em quatro camadas — UI, sessão, dados e modelo/runtime — facilita decidir onde algo deve morar, quem pode mudá-lo e como deve ser armazenado.
1) Estado de UI (o que o usuário está fazendo agora)
Estado de UI é o estado ao vivo, momento a momento no navegador ou app móvel: textos nos inputs, toggles, itens selecionados, qual aba está aberta e se um botão está desabilitado.
Apps de IA adicionam alguns detalhes específicos de UI:
- Indicadores de carregamento e estados de “pensando”
- Tokens em streaming (texto parcial aparecendo enquanto é gerado)
- Rascunhos locais de mensagens (antes de serem enviados)
O estado de UI deve ser fácil de resetar e seguro de perder. Se o usuário atualizar a página, você pode perder isso — e normalmente tudo bem.
2) Estado de sessão / conversa (contexto compartilhado para o fluxo do usuário)
Estado de sessão vincula um usuário a uma interação em andamento: identidade do usuário, um conversation_id e uma visão consistente do histórico de mensagens.
Em apps de IA, isso frequentemente inclui:
- Histórico de mensagens (ou referências a ele)
- Trilhas de ferramentas (quais funções/ferramentas foram chamadas e com quais resultados)
- Conjunto de trabalho como o projeto/documento atual, modelo selecionado ou workspace
Essa camada frequentemente abrange frontend e backend: o frontend guarda identificadores leves, enquanto o backend é a autoridade para continuidade de sessão e controle de acesso.
3) Estado de dados (registros duráveis em armazenamento)
Estado de dados é o que você armazena intencionalmente em um banco: projetos, documentos, embeddings, preferências, logs de auditoria, eventos de cobrança e transcrições de conversas salvas.
Ao contrário do estado de UI e sessão, o estado de dados deve ser:
- Durável (sobrevive reinícios)
- Consultável (você pode buscar/filtrar)
- Auditável (você pode entender o que aconteceu depois)
4) Estado de modelo / runtime (como a IA está configurada agora)
Estado de modelo/runtime é a configuração operacional usada para produzir uma resposta: prompts de sistema, ferramentas habilitadas, temperatura/tokens máximos, configurações de segurança, limites de taxa e caches temporários.
Alguns itens são configuração (padrões estáveis); outros são efêmeros (caches de curta duração ou orçamentos de tokens por requisição). A maior parte pertence ao backend para que possa ser controlada de forma consistente e não exposta desnecessariamente.
Por que a separação reduz bugs
Quando essas camadas se misturam, você tem falhas clássicas: a UI mostra texto que não foi salvo, o backend usa configurações de prompt diferentes das esperadas pelo frontend, ou a memória de conversa “vaza” entre usuários. Limites claros criam fontes de verdade mais nítidas — e tornam óbvio o que precisa persistir, o que pode ser recomputado e o que deve ser protegido.
O que vive no frontend vs. backend (e por quê)
Uma forma confiável de reduzir bugs em apps de IA é decidir, para cada pedaço de estado, onde ele deve morar: no navegador (frontend), no servidor (backend) ou em ambos. Essa escolha afeta confiabilidade, segurança e o quão “surpreendente” o app parece quando usuários atualizam, abrem nova aba ou perdem conexão.
Estado no frontend: rápido, temporário e orientado pelo usuário
Estado no frontend é melhor para coisas que mudam rapidamente e não precisam sobreviver a um refresh. Mantê-lo local torna a UI responsiva e evita chamadas de API desnecessárias.
Exemplos comuns somente no frontend:
- Texto de rascunho que o usuário está digitando
- Filtros locais e ordem de classificação em uma tabela
- Estado de modal aberto/fechado, aba selecionada, estados de hover
Se você perder esse estado no refresh, geralmente é aceitável (e muitas vezes esperado).
Estado no backend: autoritativo, sensível e compartilhado
O backend deve conter tudo que precisa ser confiável, auditável ou aplicado de forma consistente. Isso inclui estado que outros dispositivos/abas precisam ver, ou que deve permanecer correto mesmo se o cliente for modificado.
Exemplos comuns somente no backend:
- Permissões e papéis (o que o usuário pode fazer)
- Status de cobrança/assinatura e limites de uso
- Jobs de longa duração (indexação de documentos, grandes exportações, treinos) e seus estados
Uma boa mentalidade: se estado incorreto pode custar dinheiro, vazar dados ou quebrar controle de acesso, ele pertence ao backend.
Estado compartilhado: coordenado, mas com uma fonte de verdade
Alguns estados são naturalmente compartilhados:
- Título da conversa
- Fontes de conhecimento selecionadas para um chat
- Campos de perfil do usuário usados em vários dispositivos
Mesmo quando compartilhado, escolha uma “fonte de verdade”. Tipicamente, o backend é autoritativo e o frontend faz cache de uma cópia para velocidade.
Regra prática (e um anti-padrão comum)
Mantenha o estado o mais próximo possível de onde ele é necessário, mas persista o que precisa sobreviver a refresh, troca de dispositivo ou interrupções.
Evite o anti-padrão de armazenar estado sensível ou autoritativo apenas no navegador (por exemplo, tratar uma flag isAdmin no cliente, nível de plano, ou estado de conclusão de job como verdade). A UI pode exibir esses valores, mas o backend deve verificá-los.
Um ciclo típico de requisição de IA: do clique à conclusão
Uma função de IA parece uma “ação única”, mas é realmente uma cadeia de transições de estado compartilhada entre navegador e servidor. Entender o ciclo de vida facilita evitar UI desencontrada, contexto faltante e cobranças duplicadas.
1) Ação do usuário → frontend prepara a intenção
Um usuário clica Enviar. A UI atualiza imediatamente o estado local: pode adicionar um balão de mensagem “pendente”, desabilitar o botão de enviar e capturar os inputs atuais (texto, anexos, ferramentas selecionadas).
Nesse momento o frontend deve gerar ou anexar identificadores de correlação:
- conversation_id: qual thread isso pertence
- message_id: ID do cliente para a nova mensagem do usuário
- request_id: único por tentativa (útil para retries)
Esses IDs permitem que ambos os lados falem sobre o mesmo evento mesmo quando respostas chegam atrasadas ou em duplicidade.
2) Chamada de API → servidor valida e persiste
O frontend envia uma requisição de API com a mensagem do usuário mais os IDs. O servidor valida permissões, limites de taxa e o formato do payload, então persiste a mensagem do usuário (ou pelo menos um registro de log imutável) indexado por conversation_id e message_id.
Esse passo de persistência previne “histórico fantasma” quando o usuário atualiza no meio da requisição.
3) Servidor reconstrói o contexto
Para chamar o modelo, o servidor reconstrói o contexto a partir da sua fonte de verdade:
- Buscar mensagens recentes para o
conversation_id - Puxar registros relacionados (documentos, preferências, outputs de ferramentas)
- Aplicar políticas de conversa (prompts de sistema, regras de memória, truncamento)
A ideia chave: não confie no cliente para fornecer o histórico completo. O cliente pode estar defasado.
4) Execução do modelo/ferramentas → estado intermediário
O servidor pode chamar ferramentas (busca, consulta ao banco) antes ou durante a geração do modelo. Cada chamada de ferramenta produz estado intermediário que deve ser rastreado contra o request_id para que possa ser auditado e reexecutado com segurança.
5) Resposta (streaming ou não) → conclusão na UI
Com streaming, o servidor envia tokens/parciais. A UI atualiza incrementalmente a mensagem assistente pendente, mas ainda a trata como “em progresso” até que um evento final marque a conclusão.
6) Pontos de falha para planejar
Retries, envios duplos e respostas fora de ordem acontecem. Use request_id para deduplicar no servidor, e message_id para reconciliar na UI (ignore pedaços tardios que não correspondam à requisição ativa). Mostre sempre um estado claro de “falha” com uma opção de retry segura que não crie mensagens duplicadas.
Sessões e memória de conversa: manter contexto sem caos
Transforme arquitetura em código
Descreva seu modelo de estado e deixe o Koder.ai gerar a estrutura para React, Go e PostgreSQL.
Uma sessão é o “fio” que prende as ações do usuário: em qual workspace ele está, o que buscou por último, qual rascunho estava editando e qual conversa uma resposta de IA deve continuar. Bom estado de sessão faz a aplicação parecer contínua entre páginas — e idealmente entre dispositivos — sem transformar seu backend num depósito de tudo o que o usuário já disse.
Objetivos do estado de sessão
Busque: (1) continuidade (o usuário pode sair e voltar), (2) correção (a IA usa o contexto certo para a conversa certa) e (3) contenção (uma sessão não pode vazar para outra). Se você suporta múltiplos dispositivos, trate sessões como escopo usuário + dispositivo: “mesma conta” nem sempre significa “mesma sessão aberta”.
Cookies vs. tokens vs. sessões no servidor
Você normalmente escolherá uma destas formas para identificar a sessão:
- Cookies: mais simples para apps web porque o navegador os envia automaticamente. Ótimo para sessões tradicionais, mas você deve configurar flags seguras (
HttpOnly,Secure,SameSite) e lidar com CSRF apropriadamente. - Tokens (ex.: JWT): bons para APIs e apps móveis porque o cliente os anexa explicitamente. Escalam bem, mas revogação e rotação exigem design extra (e você não deve colocar estado sensível dentro do token).
- Sessões no servidor: o servidor armazena dados de sessão (geralmente em Redis) e o cliente guarda apenas um ID opaco de sessão. Mais fácil de revogar e atualizar, mas é preciso rodar e escalar a store de sessão.
Estratégias de memória de conversa
“Memória” é apenas estado que você escolhe enviar de volta ao modelo.
- Histórico completo: mais preciso, mas fica caro e pode expor conteúdo sensível antigo.
- Histórico resumido: mantenha um resumo contínuo mais algumas voltas recentes; mais barato e geralmente suficiente.
- Contexto por janela: apenas as últimas N mensagens; mais simples, mas pode perder decisões importantes anteriores.
Um padrão prático é resumo + janela: previsível e ajuda a evitar comportamento surpreendente do modelo.
Chamadas de ferramenta: reprodutíveis e auditáveis
Se a IA usa ferramentas (busca, queries, leitura de arquivos), armazene cada chamada de ferramenta com: inputs, timestamps, versão da ferramenta e o output retornado (ou referência a ele). Isso permite explicar “por que a IA disse isso”, reproduzir execuções para debugging e detectar quando resultados mudaram porque a ferramenta ou dataset mudou.
Salvaguardas de privacidade
Não armazene memória de longa duração por padrão. Guarde apenas o necessário para continuidade (IDs de conversa, resumos e logs de ferramentas), defina limites de retenção e evite persistir texto bruto do usuário a menos que haja razão de produto e consentimento do usuário.
Sincronizando estado com segurança: fontes de verdade e tratamento de conflitos
O estado fica arriscado quando a mesma “coisa” pode ser editada em mais de um lugar — sua UI, uma segunda aba do navegador ou um job em background atualizando uma conversa. A correção é menos sobre código criativo e mais sobre propriedade clara.
Defina fontes de verdade
Decida qual sistema é autoritativo para cada pedaço de estado. Na maioria das aplicações de IA, o backend deve possuir o registro canônico para qualquer coisa que precise estar correta: configurações de conversa, permissões de ferramenta, histórico de mensagens, limites de cobrança e status de jobs. O frontend pode cachear e derivar estado para velocidade (aba selecionada, texto do rascunho, indicadores de “digitando”), mas deve assumir que o backend está certo em caso de divergência.
Uma regra prática: se você ficaria chateado em perder isso num refresh, provavelmente pertence ao backend.
Atualizações otimistas (use com cuidado)
Updates otimistas fazem o app parecer instantâneo: altere a UI imediatamente, depois confirme com o servidor. Funciona bem para ações de baixo risco e reversíveis (ex.: favoritar uma conversa).
Causa confusão quando o servidor pode rejeitar ou transformar a mudança (cheque de permissões, limites, validação ou defaults do servidor). Nesses casos, mostre um estado “salvando…” e atualize a UI só após confirmação.
Lidando com conflitos (duas abas, uma conversa)
Conflitos acontecem quando dois clientes atualizam o mesmo registro a partir de versões diferentes. Exemplo comum: Aba A e Aba B mudam a temperatura do modelo.
Use versionamento leve para que o backend detecte gravações obsoletas:
updated_attimestamps (simples, fácil de depurar)- ETags / cabeçalhos
If-Match(nativo HTTP) - Números de revisão incrementais (detecção explícita de conflito)
Se a versão não bater, retorne uma resposta de conflito (frequentemente HTTP 409) e envie o objeto servidor mais recente.
Projetar APIs para reduzir divergências
Após qualquer escrita, faça a API retornar o objeto salvo como persistido (incluindo defaults gerados no servidor, campos normalizados e a nova versão). Isso permite que o frontend substitua seu cache imediatamente — uma atualização da fonte de verdade em vez de adivinhação do que mudou.
Cache e performance: acelerar sem estado obsoleto
Cache é uma das maneiras mais rápidas de deixar um app de IA instantâneo, mas também cria uma segunda cópia do estado. Se você cachear a coisa errada — ou no lugar errado — entregará uma UI rápida e ao mesmo tempo confusa.
O que cachear no cliente
Caches no cliente devem focar na experiência, não na autoridade. Bons candidatos incluem pré-visualizações recentes de conversas (títulos, trecho da última mensagem), preferências de UI (tema, modelo selecionado, estado da barra lateral) e estado otimista da UI (mensagens “enviando”).
Mantenha o cache do cliente pequeno e descartável: se ele for limpo, o app deve continuar funcionando ao refazer a busca do servidor.
O que cachear no servidor
Caches no servidor devem focar em trabalho caro ou frequentemente repetido:
- Resultados de ferramentas que são seguros de reutilizar (ex.: previsão do tempo para a mesma cidade em 5 minutos)
- Lookups de embeddings e resultados de busca vetorial para queries repetidas (frequentemente com TTL curto)
- Estado de rate-limit e contadores de throttling (para proteger sua API e custos)
Também é aqui que você pode cachear estado derivado como contagens de tokens, decisões de moderação ou saídas de parsing de documentos — qualquer coisa determinística e custosa.
Noções básicas de invalidação de cache (sem complicar)
Três regras práticas:
- Use chaves de cache claras que codifiquem inputs (
user_id, modelo, parâmetros de ferramenta, versão do documento). - Defina TTLs baseados em quão rápido os dados mudam. TTL curto vence lógica complicada.
- Ignore o cache quando correção importa mais que velocidade: após um usuário atualizar um documento, mudar permissões ou solicitar refresh.
Se você não consegue explicar quando uma entrada de cache fica errada, não a cacheie.
Não cacheie segredos ou dados pessoais em caches compartilhados
Evite colocar chaves de API, tokens de autenticação, prompts brutos com texto sensível ou conteúdo específico de usuário em camadas compartilhadas como CDNs. Se precisar cachear dados de usuário, isole por usuário e cifre em repouso — ou mantenha-os no banco principal.
Meça o impacto: velocidade vs. UI obsoleta
Cache deve ser provado, não assumido. Acompanhe latência p95 antes/depois, taxa de acerto de cache e erros visíveis ao usuário como “mensagem atualizada após renderização”. Uma resposta rápida que depois contradiz a UI é muitas vezes pior que uma resposta um pouco mais lenta e consistente.
Persistência e trabalhos de longa duração: jobs, filas e estado de status
Adicione tarefas em segundo plano com clareza
Modele fluxos enfileirado→em execução→concluído e exiba progresso confiável na UI.
Algumas funcionalidades de IA terminam em um segundo. Outras demoram minutos: fazer upload e parsing de PDF, embedding e indexação de uma base de conhecimento, ou rodar um workflow multi-step de ferramentas. Para esses, “estado” não é só o que está na tela — é o que sobrevive a refreshes, retries e tempo.
O que persistir (e por quê)
Persista somente o que desbloqueia valor real de produto.
Histórico de conversa é o óbvio: mensagens, timestamps, identidade do usuário e (freq.) qual modelo/ferramentas foram usadas. Isso permite “retomar depois”, trilhas de auditoria e suporte.
Configurações de usuário e workspace devem ficar no banco: modelo preferido, defaults de temperatura, toggles de recurso, prompts de sistema e preferências de UI que acompanham o usuário entre dispositivos.
Arquivos e artefatos (uploads, texto extraído, relatórios gerados) geralmente ficam em object storage com registros no banco apontando para eles. O banco guarda metadados (proprietário, tamanho, tipo de conteúdo, estado de processamento), enquanto o blob store guarda os bytes.
Jobs em background para tarefas longas
Se uma requisição não termina confiavelmente dentro do timeout HTTP normal, mova o trabalho para uma fila.
Padrão típico:
- Frontend chama uma API como
POST /jobscom inputs (file id, conversation id, parâmetros). - Backend enfileira um job (extração, indexação, execuções batch de ferramentas) e retorna imediatamente um
job_id. - Workers processam jobs assincronamente e escrevem resultados de volta no armazenamento persistente.
Isso mantém a UI responsiva e torna retries mais seguros.
Estado de status que a UI pode confiar
Deixe o estado do job explícito e consultável: queued → running → succeeded/failed (opcionalmente canceled). Armazene essas transições no servidor com timestamps e detalhes de erro.
No frontend, reflita o status claramente:
- Queued/running: mostre um spinner e desabilite ações duplicadas.
- Failed: mostre um erro conciso e um botão Retry.
- Succeeded: carregue o artefato resultante ou atualize a conversa.
Exponha GET /jobs/{id} (polling) ou streaming de atualizações (SSE/WebSocket) para que a UI nunca precise adivinhar.
Chaves de idempotência: retries sem gravações duplicadas
Timeouts de rede acontecem. Se o frontend reexecutar POST /jobs, você não quer dois jobs idênticos (e duas cobranças).
Exija uma Idempotency-Key por ação lógica. O backend armazena a chave com o job_id/resposta resultante e retorna o mesmo resultado para requisições repetidas.
Políticas de limpeza e expiração
Apps de IA de longa duração acumulam dados rapidamente. Defina regras de retenção cedo:
- Expire conversas antigas após N dias (ou deixe o usuário configurar).
- Delete artefatos derivados quando a fonte for removida.
- Purge periodicamente jobs falhados e arquivos intermediários.
Trate limpeza como parte do gerenciamento de estado: reduz risco, custo e confusão.
Respostas em streaming e atualizações em tempo real: gerenciando estado parcial
Streaming torna o estado mais complicado porque a “resposta” não é mais um único blob. Você lida com tokens parciais (texto chegando palavra a palavra) e, às vezes, trabalho parcial de ferramenta (uma busca começa e termina depois). Isso significa que sua UI e backend devem concordar sobre o que conta como estado temporário vs. final.
Backend: faça streaming de eventos tipados, não só texto
Um padrão limpo é fazer streaming de uma sequência de pequenos eventos, cada um com um tipo e um payload. Por exemplo:
token: texto incremental (ou um pequeno chunk)tool_start: uma chamada de ferramenta começou (ex.: “Buscando…”, com um id)tool_result: saída da ferramenta pronta (mesmo id)done: a mensagem do assistente está completaerror: algo falhou (incluir mensagem segura ao usuário e um debug id)
Esse stream de eventos é mais fácil de versionar e debugar do que streaming de texto cru, porque o frontend pode renderizar progresso com precisão (e mostrar status de ferramentas) sem adivinhar.
Frontend: atualizações append-only, depois um commit final
No cliente, trate streaming como append-only: crie uma mensagem assistente “rascunho” e vá estendendo-a conforme eventos token chegam. Ao receber done, faça um commit: marque a mensagem como final, persista se você armazenar localmente e habilite ações como copiar, avaliar ou regenerar.
Isso evita reescrever histórico no meio do stream e mantém sua UI previsível.
Lidando com interrupções (cancelar, quedas, timeouts)
Streaming aumenta a chance de trabalho pela metade:
- Usuário cancela: envie um sinal de cancelamento; pare de renderizar tokens; mantenha o rascunho visivelmente cancelado.
- Queda de rede: pare o stream; mostre “reconectando…” e não assuma conclusão.
- Timeouts/erros do servidor: finalize o rascunho como falhado e ofereça retry que inicia uma nova requisição (não tente costurar streams silenciosamente).
Reidratação: recarregar e reconstruir estado estável
Se a página recarregar no meio de um stream, reconstrua a partir do último estado estável: as últimas mensagens confirmadas mais quaisquer metadados de rascunho armazenados (message id, texto acumulado até então, status de ferramentas). Se não for possível retomar o stream, mostre o rascunho como interrompido e permita que o usuário tente novamente, em vez de fingir que concluiu.
Segurança e privacidade: proteger o estado de ponta a ponta
Prototipe para web e mobile
Crie clientes Flutter (mobile) e React (web) que compartilham o mesmo estado de backend.
Estado não é só “dados que você armazena” — é prompts do usuário, uploads, preferências, outputs gerados e metadados que conectam tudo. Em apps de IA, esse estado pode ser incomumente sensível (info pessoal, documentos proprietários, decisões internas), então segurança precisa ser projetada em cada camada.
Mantenha segredos no servidor
Tudo que permitiria ao cliente se passar pelo seu app deve permanecer no backend: chaves de API, conectores privados (Slack/Drive/credenciais de BD) e prompts de sistema ou lógica de roteamento interna. O frontend pode solicitar uma ação (“resumir este arquivo”), mas o backend deve decidir como executá-la e com quais credenciais.
Autorize toda escrita (e a maioria das leituras)
Trate cada mutação de estado como operação privilegiada. Quando o cliente tenta criar uma mensagem, renomear uma conversa ou anexar um arquivo, o backend deve verificar:
- O usuário está autenticado.
- O usuário é proprietário do recurso (conversa, workspace, projeto).
- O usuário tem permissão para executar a ação (papel, limites do plano, política da organização).
Isso evita ataques de “adivinhação de ID” onde alguém troca um conversation_id e acessa o histórico de outro usuário.
Nunca confie no navegador: valide e sanitize
Assuma que qualquer estado fornecido pelo cliente é input não confiável. Valide esquema e restrições (tipos, tamanhos, enums permitidos) e sanitize para o destino (SQL/NoSQL, logs, renderização HTML). Se aceitar “atualizações de estado” (ex.: configurações, parâmetros de ferramenta), whitelist os campos permitidos em vez de mesclar JSON arbitrário.
Trilhas de auditoria para ações críticas
Para ações que alteram estado durável — compartilhar, exportar, apagar, acessar conectores — registre quem fez o quê e quando. Um log de auditoria leve ajuda em resposta a incidentes, suporte ao cliente e conformidade.
Minimização de dados e criptografia
Armazene apenas o que você precisa para entregar a funcionalidade. Se não precisa manter prompts completos para sempre, considere janelas de retenção ou redação. Cifre estado sensível em repouso onde apropriado (tokens, credenciais de conectores, documentos upados) e use TLS em trânsito. Separe metadados operacionais do conteúdo para que você possa restringir acesso mais fortemente.
Arquitetura de referência prática e checklist de build
Um padrão útil para apps de IA é simples: o backend é a fonte de verdade, e o frontend é um cache otimista e rápido. A UI pode parecer instantânea, mas qualquer coisa que você ficaria triste em perder (mensagens, status de jobs, outputs de ferramentas, eventos cobrados) deve ser confirmada e armazenada server-side.
Se você está construindo com um fluxo “vibe-coding” — onde muita superfície de produto é gerada rapidamente — o modelo de estado se torna ainda mais importante. Plataformas como Koder.ai podem ajudar times a entregar web, backend e mobile a partir de chat, mas a mesma regra vale: iterar rápido é mais seguro quando suas fontes de verdade, IDs e transições de status são projetadas desde o início.
Arquitetura de referência (uma que você pode entregar)
Frontend (browser/móvel)
- Estado de UI: painéis abertos, texto de rascunho, modelo selecionado, indicadores temporários de “digitando”.
- Cache do estado do servidor: conversas recentes, último status de job conhecido, buffer parcial de streaming.
- Um único pipeline de requisição que sempre anexa:
session_id,conversation_ide um novorequest_id.
Backend (API + workers)
- Serviço de API: valida entrada, cria registros, emite respostas em streaming.
- Armazenamento durável (SQL/NoSQL): conversas, mensagens, chamadas de ferramenta, status de jobs.
- Fila + workers: tarefas longas (indexação RAG, parsing de arquivos, geração de imagens).
- Cache (opcional): leituras quentes (resumos de conversas, metadados de embeddings), sempre com chaves contendo versões/timestamps.
Nota: uma forma prática de manter isso consistente é padronizar sua stack de backend cedo. Por exemplo, backends gerados por Koder.ai comumente usam Go com PostgreSQL (e React no frontend), o que facilita centralizar o estado “autoritativo” em SQL enquanto mantém o cache do cliente descartável.
Modele seu estado primeiro
Antes de construir telas, defina os campos dos quais você dependerá em cada camada:
- IDs e propriedade:
user_id,org_id,conversation_id,message_id,request_id. - Timestamps e ordenação:
created_at,updated_ate umsequenceexplícito para mensagens. - Campos de status:
queued | running | streaming | succeeded | failed | canceled(para jobs e chamadas de ferramenta). - Versionamento:
etagouversionpara atualizações seguras contra conflito.
Isso previne o bug clássico onde a UI “parece correta” mas não consegue reconciliar retries, refreshes ou edições concorrentes.
Use formatos de API consistentes
Mantenha endpoints previsíveis entre features:
GET /conversations(lista)GET /conversations/{id}(obter)POST /conversations(criar)POST /conversations/{id}/messages(acrescentar)PATCH /jobs/{id}(atualizar status)GET /streams/{request_id}ouPOST .../stream(stream)
Retorne o mesmo envelope em todo lugar (incluindo erros) para que o frontend possa atualizar estado de forma uniforme.
Adicione observabilidade onde o estado pode quebrar
Logue e retorne um request_id para cada chamada de IA. Grave inputs/outputs de chamadas de ferramenta (com redação), latência, retries e status final. Facilite responder: “O que o modelo viu, quais ferramentas rodaram e que estado persistimos?”
Checklist de build (para evitar bugs comuns de estado)
- Backend é a fonte de verdade; cache do frontend é claramente rotulado e descartável.
- Toda escrita é idempotente (segura para retry) usando
request_id(e/ou uma Idempotency-Key). - Transições de status são explícitas e validadas (sem saltos silenciosos de
queuedparasucceeded). - Atualizações de streaming mesclam por IDs/sequence, não por “último a vencer”.
- Conflitos são tratados via
version/etagou regras de merge server-side. - PII e segredos nunca são armazenados no estado do cliente; logs são redigidos por padrão.
- Existe uma visão de dashboard para debugging: requisições, chamadas de ferramenta, status de jobs e erros.
Ao adotar ciclos de entrega mais rápidos (incluindo geração assistida por IA), considere adicionar guardrails que imponham automaticamente esses itens do checklist — validação de esquema, idempotência e streaming por eventos — para que “mover-se rápido” não vire deriva de estado. Na prática, é aí que uma plataforma de ponta a ponta como Koder.ai pode ser útil: acelera entrega, mantendo padrões de manipulação de estado consistentes entre web, backend e mobile.