Por que o gerenciamento de memória afeta desempenho e segurança
O gerenciamento de memória é o conjunto de regras e mecanismos que um programa usa para solicitar memória, usá-la e devolvê-la. Todo programa em execução precisa de memória para coisas como variáveis, dados do usuário, buffers de rede, imagens e resultados intermediários. Como a memória é limitada e compartilhada com o sistema operacional e outros aplicativos, as linguagens precisam decidir quem é responsável por liberá-la e quando isso ocorre.
Essas decisões moldam dois resultados que a maioria das pessoas valoriza: quão rápido o programa responde e quão confiável ele se comporta sob pressão.
O que “desempenho” significa aqui
Desempenho não é um único número. O gerenciamento de memória pode afetar:
- Throughput: quanto trabalho você consegue completar por segundo (requisições atendidas, frames renderizados, arquivos processados).
- Latência: quanto tempo uma operação individual leva, especialmente picos de latência de cauda causados por pausas ou alocações lentas.
- Pegada de memória: quanta RAM o programa mantém enquanto roda, o que influencia custo, bateria e com que frequência o SO começa a usar swap.
Uma linguagem que aloca rapidamente mas às vezes pausa para limpar pode se sair bem em benchmarks e parecer instável em apps interativos. Outro modelo que evita pausas pode exigir design mais cuidadoso para prevenir vazamentos e erros de tempo de vida.
O que “segurança” significa aqui
Segurança trata de prevenir falhas relacionadas à memória, como:
- Crashes (acessar memória inválida)
- Corrupção de dados (escrever onde não deveria)
- Vulnerabilidades de segurança (bugs que atacantes transformam em exploits)
Muitos problemas de segurança de alto perfil têm origem em erros de memória como use-after-free ou estouros de buffer.
Este guia é um passeio não técnico pelos principais modelos de memória usados por linguagens populares, o que cada um otimiza e as compensações ao escolher um.
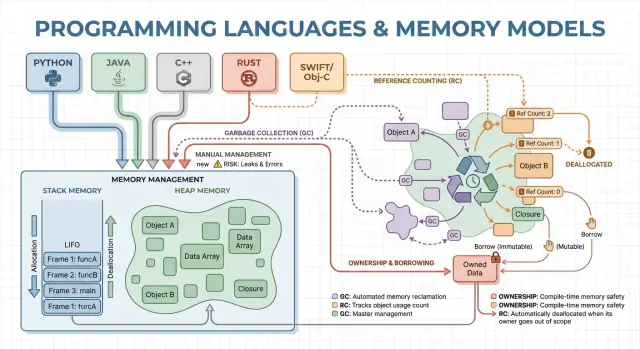
Conceitos centrais: pilha, heap e tempo de vida de objetos
Memória é onde seu programa guarda dados enquanto executa. A maioria das linguagens organiza isso em duas áreas principais: a pilha e o heap.
Pilha: armazenamento rápido e temporário
Pense na pilha como um monte organizado de anotações para a tarefa atual. Quando uma função começa, ela ganha um pequeno “frame” na pilha para suas variáveis locais. Quando a função termina, esse frame inteiro é removido de uma vez.
Isso é rápido e previsível — mas só funciona para valores cujo tamanho é conhecido e cujo tempo de vida termina com a chamada da função.
Heap: armazenamento flexível e de vida mais longa
O heap é como uma sala de armazenamento onde você pode manter objetos pelo tempo que precisar. É ótimo para listas redimensionáveis, strings ou objetos compartilhados entre partes do programa.
Como objetos no heap podem sobreviver a uma função, a pergunta-chave torna-se: quem é responsável por liberá-los e quando? Essa responsabilidade é o “modelo de gerenciamento de memória” de uma linguagem.
Tempo de vida e por que ponteiros/referências importam
Um ponteiro ou referência é uma forma de acessar um objeto indiretamente — como ter o número da prateleira de uma caixa no depósito. Se a caixa for descartada mas você ainda tiver o número, pode ler lixo ou travar (um clássico bug de use-after-free).
Um cenário simples
Imagine um loop que cria um registro de cliente, formata uma mensagem e o descarta:
- Na pilha: pequenas variáveis temporárias usadas apenas durante a formatação.
- No heap: o registro do cliente e o texto da mensagem (tamanhos variáveis).
Algumas linguagens escondem esses detalhes (limpeza automática), outras os expõem (você libera explicitamente a memória, ou precisa seguir regras de propriedade). O restante deste artigo explora como essas escolhas afetam velocidade, pausas e segurança.
Gerenciamento manual significa que o programa (e portanto o desenvolvedor) pede memória explicitamente e depois a libera. Na prática, isso aparece como malloc/free em C ou new/delete em C++. Ainda é comum em programação de sistemas onde é necessário controle preciso sobre quando a memória é adquirida e devolvida.
Para que serve a alocação/remoção explícita
Você normalmente aloca memória quando um objeto precisa sobreviver à chamada de função atual, cresce dinamicamente (por exemplo, um buffer redimensionável) ou precisa de um layout específico para interoperabilidade com hardware, sistemas operacionais ou protocolos de rede.
Vantagem de desempenho: custos previsíveis (quando bem feito)
Sem um coletor de lixo rodando em segundo plano, há menos pausas-surpresa. Alocação e desalocação podem ser altamente previsíveis, especialmente quando combinadas com alocadores customizados, pools ou buffers de tamanho fixo.
O controle manual também pode reduzir overhead: não há fase de tracing, nem barreiras de escrita, e frequentemente menos metadata por objeto. Com código bem desenhado, é possível atingir metas de latência apertadas e manter o uso de memória dentro de limites rígidos.
Riscos de segurança: modos clássicos de falha
A compensação é que o programa pode cometer erros que o runtime não evita automaticamente:
- Vazamentos de memória (esquecer de liberar)
- Double-free (liberar duas vezes)
- Use-after-free (acessar depois de liberar)
Esses bugs podem causar crashes, corrupção de dados e vulnerabilidades de segurança.
Mitigações comuns
Equipes reduzem risco limitando onde a alocação crua é permitida e apoiando-se em padrões como:
- RAII em C++ (recursos liberados ao sair do escopo)
- Smart pointers (por exemplo,
std::unique_ptr) para codificar propriedade
- Padrões de codificação, checklists em code review, sanitizers e análise estática
Quando é uma boa escolha
Gerenciamento manual costuma ser indicado para software embarcado, sistemas em tempo real, componentes de SO e bibliotecas críticas de desempenho — onde controle rígido e latência previsível importam mais que conveniência do desenvolvedor.
Coleta de lixo: produtividade e segurança previsível
Coleta de lixo (GC) é limpeza automática de memória: em vez de exigir que você faça free, o runtime rastreia objetos e recupera os que não são mais alcançáveis. Na prática, isso permite focar em comportamento e fluxo de dados enquanto o sistema trata da alocação e desalocação.
Como o GC encontra objetos não usados
A maioria dos collectors identifica primeiro os objetos vivos e então recupera o resto.
Tracing GC começa nas “raízes” (variáveis da pilha, referências globais e registradores), segue referências para marcar tudo alcançável e depois varre o heap para liberar os não marcados. Se nada aponta para um objeto, ele fica elegível para coleta.
Estilos comuns de GC (em alto nível)
GC generacional baseia-se na observação de que muitos objetos morrem cedo. Separa o heap em gerações e coleta a área jovem com frequência, o que costuma ser mais barato e eficiente.
GC concorrente executa partes da coleta junto com as threads da aplicação, buscando reduzir pausas longas. Pode exigir mais bookkeeping para manter uma visão consistente da memória enquanto o programa continua rodando.
Compensações de desempenho
GC normalmente troca controle manual por trabalho em tempo de execução. Alguns sistemas priorizam alto throughput (muito trabalho por segundo) mas podem introduzir pausas stop-the-world. Outros minimizam pausas para apps sensíveis à latência, porém adicionam overhead durante a execução normal.
Por que desenvolvedores gostam
GC elimina uma classe inteira de bugs de tempo de vida (especialmente use-after-free) porque objetos não são recuperados enquanto ainda forem alcançáveis. Também reduz vazamentos causados por liberações esquecidas (embora você ainda possa “vazar” mantendo referências por mais tempo do que o pretendido). Em grandes bases de código onde ownership é difícil de rastrear manualmente, isso acelera a iteração.
Onde você vê GC
Runtimes com GC são comuns na JVM (Java, Kotlin), .NET (C#, F#), Go e motores JavaScript em navegadores e Node.js.
Contagem de referências é uma estratégia onde cada objeto rastreia quantos “donos” (referências) apontam para ele. Quando o contador chega a zero, o objeto é liberado imediatamente. Essa imediaticidade pode ser intuitiva: assim que nada alcança um objeto, sua memória é recuperada.
Como funciona (e por que agrada)
Cada vez que você copia ou armazena uma referência, o runtime incrementa o contador; quando uma referência some, ele decrementa. Chegar a zero dispara a limpeza naquele exato momento.
Isso torna o gerenciamento de recursos direto: objetos liberam memória perto do momento em que você para de usá-los, o que pode reduzir pico de memória e evitar recolha atrasada.
Características de desempenho
A contagem de referências tende a ter overhead constante e contínuo: operações de incremento/decremento ocorrem em muitas atribuições e chamadas de função. Esse overhead costuma ser pequeno, mas está presente em toda parte.
A vantagem é que normalmente não há grandes pausas stop-the-world típicas de alguns collectors de tracing. A latência costuma ser mais suave, embora rajadas de desalocação possam ocorrer quando grandes grafos de objetos perdem seu último dono.
O grande problema: ciclos
A contagem de referências não recupera objetos envolvidos em ciclos. Se A referencia B e B referencia A, ambos contadores permanecem acima de zero mesmo se nada os alcançar—criando um vazamento.
Os ecossistemas lidam com isso de algumas maneiras:
- Referências fracas (ponteiros não-donos) para quebrar ciclos em padrões comuns (delegates, links pai/filho).
- Detecção de ciclos sobreposta à contagem de referências (uma passagem de tracing que encontra ciclos inalcançáveis).
Onde você vê contagem de referências
- Swift / Objective-C usam ARC (Automatic Reference Counting), com referências “strong/weak/unowned” para gerenciar ciclos.
- Python usa contagem de referências para limpeza imediata, mais um detector de ciclos para coletar garbage cíclico.
Ownership e borrowing: segurança de memória em tempo de compilação
Tenha código que você pode controlar
Gere uma implementação base e exporte o código-fonte para otimizar localmente.
Ownership e borrowing é um modelo associado ao Rust. A ideia é simples: o compilador aplica regras que tornam difícil criar dangling pointers, double-frees e muitas condições de corrida—sem depender de um coletor em tempo de execução.
Ownership: um dono claro, limpeza determinística
Cada valor tem exatamente um “dono” por vez. Quando o dono sai de escopo, o valor é limpo de forma imediata e previsível. Isso dá gerenciamento determinístico de recursos (memória, descritores de arquivo, sockets), parecido com cleanup manual, mas com bem menos formas de errar.
A propriedade também pode se mover: atribuir um valor a uma nova variável ou passá-lo a uma função transfere responsabilidade. Após um move, a antiga ligação não pode mais ser usada, o que previne use-after-free por construção.
Borrowing: acesso temporário sem tomar posse
Borrowing permite usar um valor sem tornar-se seu dono.
Um borrow compartilhado permite acesso somente-leitura e pode ser copiado livremente.
Um borrow mutável permite atualizações, mas deve ser exclusivo: enquanto existir, ninguém mais pode ler ou escrever aquele mesmo valor. Essa regra de “um escritor ou muitos leitores” é verificada em tempo de compilação.
Benefícios de segurança — e custos
Porque os tempos de vida são rastreados, o compilador pode rejeitar código que viveria mais que os dados que referencia, eliminando muitos bugs de dangling-reference. As mesmas regras também previnem grande parte das condições de corrida em código concorrente.
A compensação é curva de aprendizado e algumas restrições de design. Pode ser necessário reestruturar fluxos de dados, introduzir limites de propriedade mais claros ou usar tipos especializados para estado compartilhado mutável.
Onde brilha
Esse modelo é ideal para código de sistemas — serviços, embarcados, rede e componentes sensíveis a desempenho — onde você quer limpeza previsível e baixa latência sem pausas de GC.
Arenas, regiões e pools: padrões de alocação rápida
Quando você cria muitos objetos de vida curta — nós de AST em um parser, entidades em um frame de jogo, dados temporários durante uma requisição web — o custo de alocar e liberar cada objeto pode dominar o tempo de execução. Arenas (ou regiões) e pools trocam liberação fina por gerenciamento em bloco rápido.
O que são arenas/regiões
Uma arena é uma “zona” de memória onde você aloca muitos objetos ao longo do tempo e depois libera todos de uma vez ao dropar ou resetar a arena.
Em vez de rastrear o tempo de vida de cada objeto individualmente, você atrelas a um limite claro: “tudo alocado para esta requisição” ou “tudo alocado enquanto compilamos esta função”.
Por que pode ser rápido
Arenas costumam ser rápidas porque:
- reduzem chamadas ao alocador (frequentemente apenas incrementam um ponteiro)
- evitam custos de free por objeto
- melhoram localidade de cache mantendo objetos relacionados próximos
Isso pode melhorar throughput e reduzir picos de latência causados por frees frequentes ou contenção do alocador.
Casos de uso típicos
Arenas/pools aparecem em:
- parsers e compiladores (árvores sintáticas, tabelas de símbolos)
- dados com escopo de requisição em servidores (alocar durante a requisição, liberar ao final)
- jogos (alocações por frame resetadas a cada frame)
- simulações e processamento em lote
Considerações de segurança
A regra principal é simples: não deixe referências escaparem da região que detém a memória. Se algo alocado numa arena for guardado globalmente ou retornado além do tempo de vida da arena, você corre risco de use-after-free.
Linguagens e bibliotecas tratam isso de formas diferentes: algumas dependem de disciplina e APIs, outras conseguem codificar o limite da região nos tipos.
Como complementa outras abordagens
Arenas e pools não são alternativas exclusivas ao GC ou ownership — frequentemente são um suplemento. Linguagens com GC usam pools para caminhos quentes; linguagens baseadas em ownership podem usar arenas para agrupar alocações e tornar tempos de vida explícitos. Usadas com cuidado, entregam “rápido por padrão” sem perder clareza sobre quando a memória é liberada.
Otimizações do compilador e runtime que mudam a história
Modele custos de memória do backend
Crie uma API em Go que reflita sua escolha de linguagem e pressupostos sobre o modelo de memória.
O modelo de memória de uma linguagem é só parte da história de desempenho e segurança. Compiladores e runtimes modernos reescrevem seu programa para alocar menos, liberar mais cedo e evitar bookkeeping extra. Por isso ditos como “GC é lento” ou “memória manual é a mais rápida” frequentemente falham em aplicações reais.
Análise de escape: quando o heap não é necessário
Muitas alocações servem apenas para passar dados entre funções. Com escape analysis, o compilador prova que um objeto nunca vive além do escopo atual e o mantém na pilha em vez do heap.
Isso pode eliminar uma alocação no heap completamente, junto com custos associados (rastreamento do GC, atualizações de contagem de referências, locks do alocador). Em linguagens gerenciadas, essa é uma razão importante para objetos pequenos serem mais baratos do que parece.
Inlining e remoção de alocações
Quando um compilador inline uma função (substitui a chamada pelo corpo), ele pode “ver através” de camadas de abstração. Essa visibilidade permite otimizações como:
- eliminar objetos temporários
- substituição escalar (transformar um objeto em algumas variáveis locais)
- remover tráfego de contagem de referências quando tempos de vida ficam óbvios
APIs bem desenhadas podem se tornar “custo zero” após otimizações, mesmo que pareçam alocação-intensas no código-fonte.
JIT vs compilação ahead-of-time
Um JIT pode otimizar usando dados reais de produção: caminhos quentes, tamanhos típicos de objetos e padrões de alocação. Isso frequentemente melhora throughput, mas pode adicionar tempo de warm-up e pausas ocasionais para recompilação ou GC.
Compiladores AOT precisam adivinhar mais, mas entregam startup previsível e latência mais estável.
Ajustes do runtime (e quando mexer neles)
Runtimes baseados em GC expõem configurações como tamanho do heap, metas de tempo de pausa e limites de geração. Ajuste-as quando tiver evidências medidas (por exemplo, picos de latência ou pressão de memória), não como primeiro passo.
Por que o mesmo algoritmo se comporta diferente
Duas implementações do “mesmo” algoritmo podem diferir em contagens ocultas de alocações, objetos temporários e acessos por ponteiro. Essas diferenças interagem com otimizadores, o alocador e comportamento de cache — então comparações de desempenho exigem perfilagem, não suposições.
Compensações de desempenho: throughput, latência e uso de memória
As escolhas de gerenciamento de memória não só mudam como você escreve código — mudam quando o trabalho acontece, quanto de memória é preciso reservar e quão consistente o desempenho parece para os usuários.
Throughput vs latência (um exemplo concreto)
Throughput é “quanto trabalho por unidade de tempo”. Pense num job noturno que processa 10 milhões de registros: se GC ou contagem de referências adicionarem overhead pequeno mas aumentarem produtividade do time, você pode terminar mais rápido no total.
Latência é “quanto tempo uma operação leva ponta a ponta”. Para uma requisição web, uma resposta lenta prejudica a experiência mesmo que o throughput médio seja alto. Um runtime que pausa ocasionalmente para recuperar memória pode ser aceitável para processamento em lote, mas perceptível para apps interativos.
Pegada de memória: custo e velocidade
Uma maior pegada de memória aumenta custos na nuvem e pode tornar programas mais lentos. Quando seu working set não cabe bem nos caches da CPU, o processador espera mais por dados da RAM. Algumas estratégias usam mais memória para ganhar velocidade (por exemplo, manter objetos liberados em pools), enquanto outras reduzem memória à custa de bookkeeping extra.
Fragmentação e localidade de cache (em termos simples)
Fragmentação ocorre quando a memória livre fica dividida em muitos buracos — como tentar estacionar uma van num terreno com muitos espaços pequenos. Alocadores podem gastar mais tempo procurando espaço e a memória pode crescer apesar de haver “espaço suficiente”.
Localidade de cache significa que dados relacionados ficam próximos. Alocação por pool/arena costuma melhorar localidade (objetos alocados juntos ficam próximos), enquanto heaps de longa vida com tamanhos mistos podem degradar a localidade.
Requisitos de tempo previsível
Se você precisa de tempos de resposta consistentes — jogos, áudio, trading, controles embarcados ou tempo real — “majoritariamente rápido, mas às vezes lento” pode ser pior que “um pouco mais lento mas consistente”. É aí que padrões de desalocação previsíveis e controle rigoroso sobre alocações importam.
Checklist de medição
- Meça throughput (jobs/sec) e latência de cauda (p95/p99)
- Profile alocações: taxa de alocação, tempo de pausa e tempo gasto em alloc/free
- Use cargas representativas (formas de tráfego reais, tamanhos de dados, concorrência)
- Monitore memória: pico de RSS, tamanho do heap ao longo do tempo, métricas de fragmentação (se disponíveis)
- Repita execuções para capturar variabilidade (efeitos de warm-up, ciclos de GC em background)
Segurança: como modelos de memória previnem bugs comuns
Erros de memória não são apenas “enganos de programador”. Em muitos sistemas reais, eles viram problemas de segurança: quedas (denial of service), exposição acidental de dados (ler memória liberada ou não inicializada) ou condições que permitam a um atacante redirecionar a execução.
Como bugs mapeiam para modelos de memória
Diferentes estratégias tendem a falhar de formas distintas:
- Gerenciamento manual (C/C++) arrisca use-after-free, double free e buffer overflows — problemas que corrompem memória e podem ser exploráveis.
- GC elimina a maioria de erros do tipo UAF porque objetos não são liberados enquanto alcançáveis, mas ainda permite vazamentos (referências mantidas indefinidamente) e riscos em interoperabilidade nativa insegura.
- Contagem de referências oferece limpeza imediata, ajudando liberação previsível de recursos, mas pode sofrer com ciclos (vazamentos) e sutilezas de tempo de vida em presença de estado mutável compartilhado.
- Ownership/borrowing (ex.: Rust) previne muitas classes de UAF e data races em tempo de compilação, tornando difícil ter referências pendentes ou mutações não sincronizadas.
Segurança em concorrência
Concorrência muda o modelo de ameaças: memória “segura” numa thread pode virar perigosa quando outra thread a libera ou modifica. Modelos que impõem regras sobre compartilhamento (ou requerem sincronização explícita) reduzem a chance de condições de corrida que levam a corrupção, vazamentos e crashes intermitentes.
Defesa em profundidade ainda importa
Nenhum modelo remove todos os riscos — bugs de lógica (falhas de autenticação, defaults inseguros, validação inadequada) continuam ocorrendo. Boas equipes empilham proteções: sanitizers em testes, bibliotecas padrão seguras, code review rigoroso, fuzzing e fronteiras estritas em código inseguro/FFI. Segurança de memória reduz muito a superfície de ataque, mas não garante completa invulnerabilidade.
Ferramentas e técnicas para achar problemas de memória cedo
Planeje ciclos de vida desde o início
Mapeie ciclos de vida de objetos e limites de propriedade antes de gerar qualquer código.
Problemas de memória são mais fáceis de consertar quando pegos logo após a mudança que os introduziu. A chave é medir primeiro, depois estreitar com a ferramenta certa.
Noções básicas de profiling: o que medir (e quando)
Comece decidindo se persegue desempenho ou crescimento de memória.
Para desempenho, meça tempo de parede, tempo de CPU, taxa de alocação (bytes/s) e tempo gasto em GC ou alocador. Para memória, acompanhe pico de RSS, RSS em estado estável e contagens de objetos ao longo do tempo. Rode a mesma carga com entradas consistentes; pequenas variações podem esconder churn de alocação.
Categorias de ferramentas (o que cada uma acha)
- Perfis de CPU + alocação: mostram onde o tempo é gasto e quais caminhos alocam mais. Ótimo para encontrar “morte por mil alocações pequenas”.
- Detectores de vazamento: reportam memória alocada e nunca liberada (ou nunca tornada inalcançável para GC).
- Sanitizers: capturam use-after-free, estouros de buffer, data races e comportamento indefinido cedo nos testes.
- Fuzzing: fornece entradas inesperadas para acionar crashes e corrupção que testes normais não pegam.
Identificar hotspots de alocação e reduzir churn
Sinais comuns: uma requisição aloca muito mais que o esperado, ou memória sobe com o tráfego mesmo com throughput estável. Correções frequentes incluem reaproveitar buffers, usar arena/pool para objetos de vida curta e simplificar grafos de objetos para que menos objetos sobrevivam a ciclos.
Fluxo prático para vazamentos e crashes
Reproduza com uma entrada mínima, ative as verificações mais rigorosas de runtime (sanitizers/verificação do GC) e capture:
- um perfil (CPU + alocações), 2) um snapshot de heap ou relatório de vazamento, 3) uma stack trace no momento da falha.
Trate a primeira correção como experimento; rode as medições novamente para confirmar que a mudança reduziu alocações ou estabilizou a memória — sem deslocar o problema.
Para mais sobre interpretar trade-offs, veja /blog/performance-trade-offs-throughput-latency-memory-use.
Escolhendo uma linguagem: alinhe o modelo de memória aos seus objetivos
Escolher uma linguagem não é só sintaxe ou ecossistema — seu modelo de memória molda velocidade de desenvolvimento, risco operacional e quão previsível será o desempenho em tráfego real.
Comece pelos requisitos (não pelas preferências)
Mapeie as necessidades do produto a uma estratégia de memória respondendo algumas perguntas práticas:
- Habilidades da equipe e tolerância à complexidade: a maioria dos contribuidores vai se sentir confortável raciocinando sobre tempos de vida e ownership, ou você prefere que o runtime cuide disso?
- Latência vs throughput: você precisa de latência de cauda consistente (ex.: trading, áudio, controle em tempo real) ou throughput médio é prioridade (ex.: backends web, jobs em lote)?
- Restrições de deploy: você roda com envelope de memória apertado (embarcado, mobile) ou tem espaço para um runtime com heaps maiores?
“Boas escolhas” comuns
- GC: costuma ser bom para serviços backend e apps de produto onde velocidade de desenvolvimento e segurança importam mais que micro-segundos de pausa.
- Ownership/borrowing (ex.: Rust): adequado para software de sistemas, componentes críticos de desempenho e código sensível à segurança onde bugs de memória são inaceitáveis.
- Contagem de referências: funciona bem para apps desktop/mobile e interfaces gráficas que tiram proveito de limpeza incremental previsível, aceitando overhead por atribuição e tratamento de ciclos.
Migração e interoperabilidade
Ao trocar de modelo, planeje atritos: chamadas a bibliotecas existentes (FFI), convenções de memória mistas, tooling e mercado de contratação. Protótipos ajudam a descobrir custos escondidos (pausas, crescimento de memória, overhead de CPU) mais cedo.
Uma abordagem prática é prototipar a mesma feature nos ambientes que você considera e comparar taxa de alocação, latência de cauda e pico de memória sob carga representativa. Times às vezes fazem essa avaliação “maçã-para-maçã” em Koder.ai: você pode rapidamente montar um front React + backend Go + PostgreSQL, iterar nas formas de requisição e estruturas de dados para ver como um serviço baseado em GC se comporta em tráfego real (e exportar o código-fonte quando quiser avançar).
Um framework leve de decisão
Defina as 3–5 restrições principais, construa um protótipo fino e meça uso de memória, latência de cauda e modos de falha.
| Modelo | Segurança por padrão | Previsibilidade de latência | Velocidade de desenvolvimento | Armadilhas típicas |
|---|
| Manual | Baixa–Média | Alta | Média | vazamentos, use-after-free |
| GC | Alta | Média | Alta | pausas, crescimento do heap |
| RC | Média–Alta | Alta | Média | ciclos, overhead |
| Ownership | Alta | Alta | Média | curva de aprendizado |