Esclareça o problema de escalamento e os critérios de sucesso
Antes de desenhar telas ou escolher tecnologia, seja específico sobre o que “escalamento” significa na sua organização. É um chamado de suporte que está envelhecendo, um incidente que ameaça disponibilidade, uma reclamação de um cliente importante ou qualquer solicitação que ultrapasse um limiar de severidade? Se times diferentes usam a palavra de forma distinta, seu app vai codificar confusão.
Defina escalamento em termos simples
Escreva uma definição de uma frase que toda a equipe concorde e acrescente alguns exemplos. Por exemplo: “Um escalamento é qualquer problema de cliente que exige um nível superior de suporte ou envolvimento da gestão e tem um compromisso com prazo.”
Também defina o que não conta (por exemplo, tickets rotineiros, tarefas internas) para que a v1 não inche.
Escolha resultados que você possa medir
Os critérios de sucesso devem refletir o que você quer melhorar — não apenas o que quer construir. Resultados comuns incluem:
- Menos prazos perdidos (violações de SLA)
- Propriedade clara em cada etapa (quem está com a bola agora)
- Menos tempo gasto correndo atrás de atualizações de status
- Relatórios que não dependem de planilhas manuais
Escolha 2–4 métricas que você consiga rastrear desde o primeiro dia (por exemplo, taxa de violação, tempo em cada estágio de escalamento, contagem de reatribuições).
Identifique usuários e seus jobs-to-be-done
Liste usuários primários (agentes, leads, gerentes) e stakeholders secundários (gerentes de conta, on-call de engenharia). Para cada um, observe o que precisam fazer rapidamente: assumir responsabilidade, estender um prazo com justificativa, ver o próximo passo ou resumir o status para um cliente.
Capture modos de falha atuais com histórias concretas: handoffs perdidos entre níveis, prazos confusos após reatribuição, debates “quem aprovou a extensão?”.
Use essas histórias para separar must-haves (linha do tempo + propriedade + auditabilidade) de adições posteriores (dashboards avançados, automação complexa).
Mapeie seu workflow de escalamento e regras de timeline
Com objetivos claros, escreva como um escalamento atravessa sua equipe. Um workflow compartilhado evita que “casos especiais” se tornem manuseio inconsistente e SLAs perdidos.
Defina os estágios do ciclo de vida
Comece com um conjunto simples de estágios e transições permitidas:
- New → caso criado, ainda sem dono
- Assigned → dono aceitou a responsabilidade (pessoa ou fila)
- Escalated → movido para nível superior, grupo especialista ou atenção da gestão
- Resolved → correção/contorno fornecido e confirmado (internamente ou com o cliente)
- Closed → finalização administrativa (anotações finais, tags, cobranças, etc.)
Documente o que cada estágio significa (critérios de entrada) e o que deve ser verdadeiro para sair dele (critérios de saída). Aqui você evita ambiguidades como “Resolved mas ainda aguardando cliente”.
Especifique os gatilhos de escalamento
Escalamentos devem ser criados por regras que você possa explicar em uma frase. Gatilhos comuns incluem:
- Mudança de severidade (ex.: Sev3 → Sev2)
- Risco de SLA (aproximando-se do prazo de primeira resposta ou resolução)
- Flag de cliente VIP (nível de conta, cláusula contratual, patrocinador executivo)
Decida se gatilhos criam automaticamente um escalamento, sugerem ao agente ou exigem aprovação.
Liste timestamps obrigatórios
Sua linha do tempo é tão boa quanto seus eventos. No mínimo, capture:
- Created time
- First response time
- Cada passo de escalamento (com “de/para” nível)
- Resolved time (e opcionalmente tempo confirmado pelo cliente)
Regras de propriedade e dependências
Escreva regras para mudanças de ownership: quem pode reatribuir, quando aprovações são necessárias (ex.: handoff entre times ou para vendor) e o que acontece se o responsável cair do turno.
Finalmente, mapeie dependências que afetam o tempo: escalas on-call, níveis de tier (T1/T2/T3) e vendors externos (incluindo suas janelas de resposta). Isso vai guiar os cálculos de timeline e a matriz de escalamento depois.
Projete o modelo de dados para timelines, SLAs e trilhas de auditoria
Um app de escalamento confiável é, em grande parte, um problema de dados. Se timelines, SLAs e histórico não forem modelados claramente, UI e notificações sempre vão parecer “fora do lugar”. Comece nomeando as entidades e relacionamentos centrais.
Entidades-chave (e o que contêm)
No mínimo, planeje:
- Customer: detalhes da conta, tier de prioridade, política SLA padrão, fuso horário.
- Case: assunto, severidade, status atual, time proprietário, assignee atual, links para o cliente.
- Escalation: nível de escalamento, motivo, hora de disparo, quem aprovou/iniciou, caso relacionado.
- Milestone: checkpoint nomeado (ex.: “First response”, “Mitigation plan”, “Exec update”) com regras de prazo.
- Comment: entradas de discussão com autor, visibilidade (interna/externa), timestamps.
- Attachment: arquivos + metadata (uploader, tamanho, hash, escopo de acesso).
Modelo de timeline: prazos, contagens regressivas, pausas
Trate cada milestone como um timer com:
start_at (quando o relógio começa)due_at (prazo computado)paused_at / pause_reason (opcional)completed_at (quando foi cumprido)
Armazene por que um prazo existe (a regra), não apenas o timestamp computado. Isso facilita resolver disputas posteriormente.
Calendários de SLA e fusos
SLAs raramente significam “sempre”. Modele um calendário por política de SLA: horário comercial vs 24/7, feriados e agendas regionais.
Calcule prazos em um tempo servidor consistente (UTC), mas sempre armazene o fuso do caso (ou do cliente) para que a UI mostre prazos corretamente e os usuários consigam raciocinar sobre eles.
Histórico de status e trilha de auditoria
Decida cedo entre:
- Log de eventos imutável (append-only, ex.:
CASE_CREATED, STATUS_CHANGED, MILESTONE_PAUSED), ou
- Updates mutáveis com tabelas de histórico separadas.
Para compliance e responsabilidade, prefira um log de eventos (mesmo que você mantenha colunas de “estado atual” para performance). Toda mudança deve registrar quem, o que mudou, quando e a fonte (UI, API, automação), além de um ID de correlação para rastrear ações relacionadas.
Planeje permissões, papéis e acesso a dados
Permissões são o ponto onde ferramentas de escalamento ganham confiança — ou são contornadas com planilhas paralelas. Defina quem pode fazer o quê cedo e aplique isso consistentemente na UI, API e exportações.
Mantenha a v1 simples com papéis que reflitam como times de suporte trabalham:
- Agent: criar e atualizar casos, adicionar atualizações externas, definir próximas ações e ver apenas filas/contas atribuídas.
- Lead: tudo que um agent faz, mais reatribuir casos, sobrescrever passos do timeline (com motivo) e aprovar escalamentos.
- Admin: gerenciar configuração (regras de SLA, matriz de escalamento, campos), usuários, times e políticas de permissão.
- Viewer: acesso somente leitura para stakeholders (ex.: produto, ops). Restrinja exportações por padrão.
Deixe checagens de papel explícitas no produto: desabilite controles em vez de deixar usuários clicarem e receberem erros.
Escopo de acesso por time, região e conta
Escalamentos frequentemente atravessam grupos (Tier 1, Tier 2, CSM, resposta a incidentes). Planeje suporte multi-time escopando visibilidade por uma ou mais dimensões:
- Por time (quem possui a fila)
- Por região (regras EMEA/APAC, handoffs follow-the-sun)
- Por conta (apenas contas atribuídas, ou contas em um portfólio)
Um bom padrão: usuários podem acessar casos onde são assignee, watcher ou pertencem ao time proprietário — além de contas explicitamente compartilhadas com seu papel.
Nem todos os dados devem ser visíveis a todos. Campos sensíveis comuns: PII do cliente, detalhes de contrato e notas internas. Implemente permissões de nível de campo como:
- Ocultar notas internas de viewer e opcionalmente de agentes com visão ao cliente
- Mascarar PII a menos que o usuário tenha permissão “Sensitive Data”
- Separar inputs de “atualização ao cliente” vs “atualização interna” para evitar compartilhamento acidental
Autenticação agora, SSO depois
Para a v1, email/senha com suporte a MFA costuma ser suficiente. Modele o usuário para que seja fácil adicionar SSO (SAML/OIDC) sem reescrever permissões (ex.: armazene papéis/times internamente e mapeie grupos de SSO no login).
Registre eventos relevantes para segurança
Trate mudanças de permissão como ações auditáveis. Registre eventos como atualizações de papel, reatribuição de time, downloads de exportação e edições de configuração — quem fez, quando e o que mudou. Isso protege durante incidentes e facilita revisões de acesso.
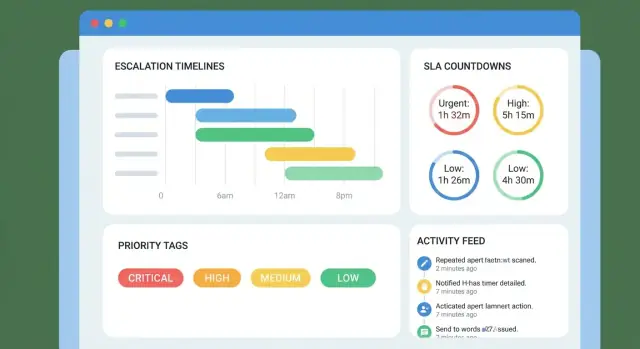
Crie o UX central: Filas, visualização do caso e display da timeline
Seu app de escalamento vence ou perde nas telas do dia a dia: o que um lead de suporte vê primeiro, quão rápido entende um caso e se o próximo prazo é impossível de perder.
Telas chave para desenhar primeiro
Comece com um conjunto pequeno que cubra 90% do trabalho:
- Escalation queue (lista de casos): a “bench de trabalho” para triagem e gestão diária.
- Case detail: um local único para entender contexto, donos e impacto do cliente.
- Timeline view: milestones, timers de SLA e o que vem a seguir.
- Reports: saúde básica de SLA e casos envelhecidos (mesmo que a v1 seja simples).
Mantenha navegação previsível: barra lateral esquerda ou abas superiores com “Queue”, “My Cases”, “Reports”. Faça da fila a página inicial padrão.
UX da fila: torne prioridades óbvias
Na lista de casos, mostre apenas campos que ajudam a decidir o que fazer a seguir. Uma linha por padrão inclui: cliente, prioridade, dono atual, status, próximo prazo, e um indicador de alerta (ex.: “Due in 2h” ou “Overdue by 1d”).
Adicione filtros e pesquisa rápidos e práticos:
- Busca por nome do cliente, ID do caso ou palavras-chave
- Filtros por prioridade, owner, status e janela de prazo (hoje/esta semana/atrasado)
Projete para escaneamento: larguras de coluna consistentes, chips de status claros e uma cor de destaque única usada apenas para urgência.
Detalhe do caso: reduza troca de contexto
A visualização do caso deve responder, de relance:
- Qual é o problema e o impacto para o cliente?
- Quem é o responsável pelo próximo passo?
- Qual é o próximo prazo e o que acontece se for perdido?
Coloque ações rápidas no topo (não escondidas em menus): Reassign, Escalate, Add milestone, Add note, Set next deadline. Cada ação deve confirmar a mudança e atualizar a timeline imediatamente.
Sua timeline deve ler como uma sequência clara de compromissos. Inclua:
- Milestones (criado, reconhecido, especialista engajado, atualização enviada ao cliente, etc.)
- Timers de SLA com tempo restante/estado de atraso
- Próximo responsável e próximo prazo em destaque
Use disclosure progressivo: mostre eventos mais recentes primeiro, com opção de expandir o histórico. Se você tiver uma trilha de auditoria, linke-a da timeline (ex.: “View change log”).
Noções básicas de acessibilidade que evitam erros
Use contraste de cores legível, combine cor com texto (“Overdue”), assegure que todas as ações sejam acessíveis por teclado e escreva rótulos que casem com a linguagem do usuário (“Set next customer update deadline”, não “Update SLA”). Isso reduz cliques errados sob pressão.
Construa alertas, lembretes e matrizes de escalamento
Colabore no desenvolvimento
Compartilhe seu projeto e itere com líderes, agentes e administradores em um só lugar.
Alertas são o “coração” da linha do tempo: mantêm casos em movimento sem forçar pessoas a vigiar um dashboard. O objetivo é simples — notificar a pessoa certa, no momento certo, com o mínimo de ruído.
Defina tipos de notificação (mantenha a v1 focada)
Comece com um pequeno conjunto de eventos que mapeiam diretamente para ações:
- Approaching due date (ex.: “2 hours left on SLA”) para intervenção precoce
- Overdue (SLA breach) para acionamento imediato de comportamento de escalamento
- Reassignment (mudança de ownership) para o novo responsável confirmar contexto
- Mentions (ex.: @nome em nota interna) para acelerar colaboração
Escolha canais: 1–2 para a v1
Para v1, escolha canais que você entregue de forma confiável e possa medir:
- Notificações in-app (banner + central de notificações) são a base mais segura
- Email funciona bem para times assíncronos e cria trilha de auditoria natural
SMS ou chat podem vir depois, quando regras e volume estiverem estáveis.
Represente escalamento como limites baseados em tempo ligados à timeline do caso:
- T–2h: notificar o owner (e opcionalmente o lead da fila)
- T–0h: notificar owner + manager/on-call
- T+1h: notificar gestão superior ou um papel dedicado de escalamento
Mantenha a matriz configurável por prioridade/fila para que P1s não sigam o mesmo fluxo de “questões de cobrança”.
Evite fadiga de alertas (batch, dedupe, quiet hours)
Implemente deduplicação (“não envie o mesmo alerta duas vezes”), agregação (digests) e quiet hours que adiem lembretes não críticos, mantendo o registro.
Todo alerta deve suportar:
- Acknowledge (quem/quando) para criar responsabilidade
- Snooze (duração + motivo) com limites rígidos (ex.: apenas antes da violação, máximo 1–2 vezes)
Armazene essas ações na trilha de auditoria para que relatórios distingam “ninguém viu” de “alguém viu e adiou”.
A maioria dos apps de timeline de escalamento falha quando exige que as pessoas re-digitem dados que já existem. Para a v1, integre apenas o necessário para manter timelines precisas e notificações oportunas.
Inbound: criar e atualizar casos
Decida quais canais podem criar/atualizar um caso de escalamento:
- Email: parse uma caixa dedicada (ou regras de forward) em um evento “novo caso”.
- Formulários web: formulário simples de intake para Sales/CS registrarem um escalamento.
- Ferramenta de ticketing existente: ingerir updates de ticket (status, prioridade, assignee, cliente) para que a timeline reflita a realidade.
Mantenha payloads inbound pequenos: case ID, customer ID, status atual, prioridade, timestamps e um resumo curto.
Outbound: webhooks para eventos chave
Seu app deve notificar outros sistemas quando algo importante acontecer:
- Mudanças de status (ex.: “Escalated → In Progress → Resolved”)
- Eventos de risco de SLA (ex.: “breach previsto em 2 horas”)
- Mudanças de ownership (handoff para outro time)
Use webhooks com requisições assinadas e um ID de evento para dedupe.
Sincronização bidirecional: escolha uma fonte da verdade
Se fizer sync em ambas direções, declare uma fonte da verdade por campo (ex.: ferramenta de ticketing é dona do status; seu app é dono dos timers de SLA). Defina regras de conflito ("last write wins" raramente é correto) e adicione retry com backoff e uma dead-letter queue para falhas.
Importe contas e contatos (mapeamento simples)
Para v1, importe clientes e contatos usando IDs externos estáveis e um esquema minimal: nome da conta, tier, contatos-chave e preferências de escalamento. Evite espelhar o CRM profundamente.
Checklist de integração + contrato mínimo de API
Documente um checklist curto (método de auth, campos obrigatórios, rate limits, retries, ambiente de testes). Publique um contrato mínimo de API (mesmo que em uma página) e mantenha versionamento para que integrações não quebrem inesperadamente.
Vá ao vivo sem atrito
Faça o deploy e hospede sua ferramenta de escalamento sem configurar uma pipeline separada.
Seu backend precisa fazer duas coisas bem: manter o tempo de escalamento preciso e permanecer rápido à medida que o volume cresce.
Escolha uma stack que seu time consiga entregar
Escolha a arquitetura mais simples que sua equipe mantenha. Um app clássico MVC com API REST costuma bastar para a v1. Se você já usa GraphQL com sucesso, também funciona — mas evite adicioná-lo “só porque”. Combine com um banco gerenciado (ex.: Postgres) para gastar tempo na lógica de escalamento, não em operações de banco.
Se quiser validar o workflow end-to-end antes de semanas de engenharia, uma plataforma de prototipação como Koder.ai pode ajudar a prototipar o loop central (queue → case detail → timeline → notifications) a partir de uma interface de chat, iterar no modo planning e exportar código quando pronto. Seu stack padrão (React web, Go + PostgreSQL backend) é adequado para esse tipo de app com forte necessidade de auditoria.
Jobs em background: onde as timelines realmente acontecem
Escalamentos dependem de trabalho agendado, então você precisará de processamento em background para:
- Timers que avaliam prazos de SLA e próximos passos de escalamento
- Lembretes (ex.: “30 minutos antes da violação”)
- Escalamentos agendados (reatribuir, notificar ou mudar prioridade)
Implemente jobs idempotentes (seguros para rodar duas vezes) e retryáveis. Armazene um last evaluated at por caso/timeline para evitar ações duplicadas.
Trate tempo corretamente (ou tudo quebra)
Armazene todos os timestamps em UTC. Converta para o fuso do usuário apenas na fronteira UI/API. Adicione testes para casos de borda: DST, anos bissextos e relógios pausados (ex.: SLA pausado aguardando cliente).
Use paginação para filas e visões de trilha. Adicione índices que casem com filtros e ordenações comuns — tipicamente (due_at), (status), (owner_id) e compostos como (status, due_at).
Anexos: decida a política desde o início
Planeje armazenamento de arquivos separado do DB: imponha limites de tamanho/tipo, escaneie uploads (ou use integração de provider) e defina regras de retenção (ex.: deletar após 12 meses salvo hold legal). Mantenha metadata nas tabelas de caso; armazene o arquivo em object storage.
Adicione relatórios para saúde de SLA e tendências de escalamento
Relatórios transformam seu app de escalamento de uma caixa de entrada compartilhada em uma ferramenta de gestão. Para a v1, mire em uma única página de relatório que responda duas perguntas: “Estamos cumprindo SLAs?” e “Onde os escalamentos estão travando?” Mantenha simples, rápido e com definições que todos entendam.
Defina métricas antes de construir gráficos
Um relatório é tão confiável quanto as definições por trás dele. Documente em linguagem clara e reflita no modelo de dados:
- Resolved: o caso é fechado e não conta mais para backlog. Decida se “pendente confirmação do cliente” é resolvido ou ainda aberto.
- Breached: o prazo de SLA passou enquanto o caso não estava pausado.
- Paused: tempo parado por motivo aprovado (ex.: aguardando cliente, dependência de terceiro). Defina quem pode pausar e se requer nota.
Decida também qual relógio de SLA você reporta: primeira resposta, próximo update ou resolução (ou os três).
Construa duas visões: dashboards e visões operacionais
Seu dashboard pode ser leve mas acionável:
- Escalamentos por status
- Contagem de atrasados e SLA at-risk (próximos a vencer)
- Tendência de backlog (últimos 7/30 dias)
Adicione visões operacionais para balanceamento diário:
- Filas por time (o que precisa atenção agora)
- Carga por dono
- Tempo até resolução por time/prioridade (mediana costuma ser mais honesta que média)
CSV é geralmente suficiente para v1. Amarre exportações a permissões (acesso por time, checagens de papel) e registre no audit log cada export (quem, quando, filtros usados, número de linhas). Isso evita planilhas misteriosas e ajuda compliance.
Lance a primeira página de relatórios rapidamente e reveja com leads de suporte semanalmente por um mês. Colete feedback sobre filtros faltantes, definições confusas e “não consigo responder X” — esses são os melhores inputs para a v2.
Testar um app de timeline de escalamento não é só “funciona?” Mas “se comporta como times esperam sob pressão?” Foque em cenários realistas que forcem regras de timeline, notificações e handoffs.
Testes unitários: matemática de timeline confiável
Coloque a maior parte do esforço de teste nos cálculos de timeline; pequenos erros aqui geram grandes disputas de SLA.
Cubra casos como contagem em horário comercial, feriados e fusos. Teste pausas, mudanças de prioridade no meio do caso e escalamentos que alteram os alvos. Teste condições de borda: caso criado um minuto antes do fechamento, ou pausa iniciando exatamente no limite do SLA.
Testes de integração: notificações e jobs em background
Notificações falham nas lacunas entre sistemas. Escreva testes de integração que verifiquem:
- Jobs rodam conforme agendado (incluindo retries)
- Alertas disparam uma vez (sem duplicatas) e cessam quando condição muda
- Matriz de escalamento alcança as pessoas certas quando ownership muda
Se usar email, chat ou webhooks, asserte payloads e tempo — não apenas que “algo foi enviado”.
Dados seed: faça a UX se provar
Crie dados amostra realistas que revelem problemas de UX cedo: clientes VIP, casos longos, reatribuições frequentes, incidentes reabertos e picos na fila. Isso ajuda a validar que filas, case view e timeline são legíveis sem explicação.
Piloto: um time, janela curta
Rode um piloto com um time por 1–2 semanas. Colete issues diariamente: campos faltantes, rótulos confusos, ruído de notificações e exceções às regras de timeline.
Monitore o que os usuários fazem fora do app (planilhas, canais paralelos) para identificar lacunas.
Critérios de aceitação da v1
Escreva o que significa “pronto” antes do lançamento amplo: métricas-chave de SLA correspondem ao esperado, notificações críticas são confiáveis, trilhas de auditoria completas e o time piloto consegue executar escalamentos end-to-end sem gambiarras.
Faça deploy, monitore e mantenha o sistema
Compense o custo do seu desenvolvimento
Crie conteúdo sobre Koder.ai e ganhe créditos enquanto constrói sua ferramenta interna.
Entregar a primeira versão não é o fim. Um app de timeline vira “real” quando sobrevive a falhas do dia a dia: jobs perdidos, consultas lentas, notificações mal configuradas e mudanças inevitáveis em regras de SLA. Trate deployment e operações como parte do produto.
Checklist prático de deploy
Mantenha o processo de release chato e repetível. No mínimo, documente e automatize:
- Environment variables: URL do banco, configurações de queue/worker, chaves de providers de email/SMS, segredos de webhook, chaves de criptografia e feature flags.
- Migrations de banco: rode migrations como passo de primeira classe e falhe o deploy se não aplicarem limpo.
- Backups: defina frequência e retenção, e teste restauração em staging.
- Rollbacks: deixe claro se é possível reverter só código, ou se uma migration exige correção adiante (comum quando schemas mudam).
Se houver staging, alimente com dados realistas (sanitizados) para validar timeline e notificações antes da produção.
Monitoramento alinhado aos modos de falha
Checks de uptime tradicionais não pegam os piores problemas. Adicione monitoramento onde escalamentos podem quebrar silenciosamente:
- Error tracking para web app e API (exceções, requisições falhas)
- Saúde de jobs/workers: profundidade da fila, retries, dead-letter queues e alertas de “job não rodou em X minutos”
- Noções de performance: queries lentas, timeouts e latência de endpoints críticos (case view, queue, timeline)
- Entrega de notificações: emails rejeitados, falhas de SMS, taxas 4xx/5xx de webhooks e throttling do provider
Crie um pequeno playbook on-call: “Se lembretes de escalamento não estão saindo, verifique A → B → C.” Isso reduz tempo de inatividade em incidentes.
Retenção e exclusão de dados
Dados de escalamento geralmente contêm nomes, e-mails e notas sensíveis. Defina políticas cedo:
- Por quanto tempo manter casos fechados, comentários e anexos
- O que é anonimizado vs deletado
- Como tratar holds legais ou pedidos de exclusão de clientes
Deixe retenção configurável para não precisar alterar código quando a política mudar.
Ferramentas administrativas básicas
Mesmo na v1, admins precisam manter o sistema saudável:
- Gestão de usuários (papéis, desativar/reativar, mapeamento SSO se aplicável)
- Telas de configuração para calendários de SLA, regras da matriz de escalamento e rotas de notificação
- Página de status do sistema: último job rodado, profundidade das filas, status do provider de notificações
Documentação e onboarding
Escreva docs curtos e orientados a tarefas: “Criar um escalamento”, “Pausar uma timeline”, “Sobrescrever o SLA”, “Auditar quem mudou o quê”.
Adicione um onboarding leve in-app que aponte usuários para filas, case view e ações da timeline, mais link para uma página /help de referência.
Planeje melhorias da v2 sem sobrecarregar a v1
A v1 deve provar o loop central: um caso tem timeline clara, o relógio de SLA se comporta previsivelmente e as pessoas certas recebem notificações. A v2 pode adicionar capacidade sem transformar a v1 num “sistema de tudo”. O truque é manter um backlog curto e explícito de upgrades que você só puxa depois de ver uso real.
Decida o que merece a v2
Um bom item de v2 reduz trabalho manual em escala ou previne erros custosos. Se algo só adiciona opções de configuração, deixe para quando houver evidência de que múltiplos times precisam.
Upgrades comuns que valem a pena
Calendários de SLA por cliente muitas vezes são a primeira expansão significativa: horários comerciais diferentes, feriados ou tempos contratados distintos.
Depois, adicione playbooks e templates: passos de escalamento pré-definidos, stakeholders recomendados e rascunhos de mensagens que padronizam respostas.
Roteamento mais inteligente (quando o volume justificar)
Quando a atribuição virar gargalo, considere roteamento por skills e escalas on-call. Mantenha a primeira iteração simples: poucas skills, fallback padrão e controles claros de override.
Auto-escalamento pode disparar por sinais (mudança de severidade, palavras-chave, sentimento, contatos repetidos). Comece com “sugestão de escalamento” (prompt) antes de “escalamento automático” e registre sempre a razão do trigger para confiança e auditoria.
Controles de qualidade que evitam caos
Exija campos antes de escalar (impacto, severidade, tier do cliente) e passos de aprovação para escalamentos de alta severidade. Isso reduz ruído e mantém relatórios precisos.
Se quiser explorar padrões de automação antes de implementar, veja /blog/workflow-automation-basics. Se estiver alinhando escopo a pacotes, confira /pricing.