27 de set. de 2025·8 min
Implantações Blue/Green e Canário: Uma Estratégia Clara de Release
Saiba quando usar Blue/Green ou lançamento canário, como funciona o deslocamento de tráfego, o que monitorar e passos práticos de rollout e rollback para releases mais seguros.
O que significam Blue/Green e lançamento canário
Enviar código novo para produção é arriscado por um motivo simples: você só descobre realmente como ele se comporta quando usuários reais o acessam. Blue/Green e lançamento canário são duas formas comuns de reduzir esse risco mantendo o tempo de inatividade próximo de zero.
Blue/Green em termos simples
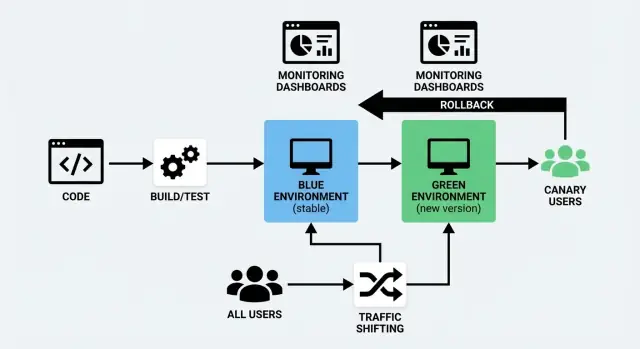
Uma implantação Blue/Green usa dois ambientes separados, porém semelhantes:
- Blue: a versão que está atendendo os usuários no momento (o ambiente “ativo").
- Green: um segundo ambiente pronto para ser usado, onde você faz o deploy da nova versão.
Você prepara o ambiente Green em segundo plano — faz o deploy, roda checagens, o aquece — e então troca o tráfego de Blue para Green quando estiver confiante. Se algo sair errado, você pode reverter rapidamente.
A ideia principal não é “duas cores”, e sim um corte limpo e reversível.
Lançamento canário em termos simples
Um lançamento canário é um rollout gradual. Em vez de trocar tudo de uma vez, você envia a nova versão para uma pequena fatia de usuários primeiro (por exemplo, 1–5%). Se tudo parecer saudável, você expande o rollout passo a passo até que 100% do tráfego esteja na nova versão.
A ideia central é aprender com tráfego real antes de se comprometer totalmente.
O objetivo compartilhado: releases mais seguros com menos downtime
Ambas as abordagens são estratégias de implantação que visam:
- reduzir o impacto para usuários quando algo quebra
- suportar uma implantação sem downtime (ou o mais próximo que o seu sistema permitir)
- tornar rollbacks menos estressantes e mais previsíveis
Elas fazem isso de maneiras diferentes: Blue/Green foca em uma troca rápida entre ambientes, enquanto o canário foca na exposição controlada através do deslocamento de tráfego.
Não existe uma opção “melhor” universal
Nenhuma das abordagens é automaticamente superior. A escolha certa depende de como seu produto é usado, do quanto você confia nos testes, da velocidade com que precisa de feedback e do tipo de falhas que quer evitar.
Muitas equipes também misturam as duas — usando Blue/Green pela simplicidade operacional e técnicas canárias para exposição gradual aos usuários.
Nas seções seguintes, vamos comparar diretamente e mostrar quando cada uma costuma funcionar melhor.
Blue/Green vs Canário: Comparação Rápida
Blue/Green e canário são maneiras de liberar mudanças sem interromper usuários — mas diferem em como o tráfego passa para a nova versão.
Como o tráfego é trocado
Blue/Green mantém dois ambientes completos: “Blue” (atual) e “Green” (novo). Você valida o Green e então troca todo o tráfego de uma vez — como acionar um único interruptor controlado.
Canário distribui a nova versão para uma pequena fatia de usuários primeiro (por exemplo, 1–5%) e então vai deslocando o tráfego gradualmente enquanto observa o comportamento em produção.
Prós e contras relevantes
| Fator | Blue/Green | Canário |
|---|---|---|
| Velocidade | Corte muito rápido após validação | Mais lento por projeto (rollout gradual) |
| Risco | Médio: se falhar, todos são afetados após a troca | Menor: problemas tendem a aparecer antes do rollout completo |
| Complexidade | Moderada (dois ambientes, troca limpa) | Maior (divisão de tráfego, análise, passos graduais) |
| Custo | Maior (duplica capacidade durante o rollout) | Frequentemente menor (pode aumentar usando capacidade existente) |
| Melhor para | Mudanças grandes e coordenadas | Melhorias pequenas e frequentes |
Um guia simples para decidir
Escolha Blue/Green quando quiser um momento de corte limpo e previsível — especialmente para mudanças grandes, migrações ou releases que exigem uma separação clara entre “antigo vs novo”.
Escolha Canário quando você entrega com frequência, quer aprender com o uso real de forma segura e prefere reduzir o blast radius deixando métricas guiar cada etapa.
Se estiver em dúvida, comece com Blue/Green por simplicidade operacional e adicione estratégias canárias para serviços de maior risco depois que monitoramento e hábitos de rollback estiverem consolidados.
Quando Blue/Green é a escolha certa
Blue/Green é uma escolha forte quando você quer que o release pareça um “switch”. Você mantém dois ambientes de produção: Blue (atual) e Green (novo). Quando o Green é verificado, você direciona os usuários para ele.
Você precisa de downtime quase zero
Se seu produto não tolera janelas de manutenção visíveis — fluxos de checkout, sistemas de reservas, dashboards autenticados — Blue/Green ajuda porque a nova versão é iniciada, aquecida e verificada antes que usuários reais sejam enviados. A maior parte do tempo de deploy acontece em paralelo, não na frente dos clientes.
Você quer o rollback mais simples possível
Rollback costuma ser apenas redirecionar o tráfego de volta para o Blue. Isso é valioso quando:
- é necessário reverter um release em minutos
- você quer evitar hotfixes emergenciais sob pressão
- precisa de uma resposta a falhas clara e repetível
O benefício chave é que o rollback não exige reconstruir ou redeployar — é uma troca de tráfego.
Suas mudanças no banco de dados podem ser compatíveis com versões anteriores
Blue/Green é mais simples quando migrações de banco são compatíveis com versões anteriores, porque por um curto período Blue e Green podem coexistir (e ambos podem ler/escrever, dependendo do roteamento e jobs).
Bom encaixe inclui:
- mudanças aditivas no esquema (novas colunas opcionais, novas tabelas)
- expansão de formatos de dados de forma que o código antigo ignore o novo campo
Encaixes arriscados incluem remoção de colunas, renomeação de campos ou mudanças de significado — essas ações podem quebrar a promessa de “voltar atrás” a menos que você planeje migrações em múltiplas etapas.
Você pode arcar com ambientes duplicados e controle de roteamento
Blue/Green exige capacidade extra (duas stacks) e um mecanismo para direcionar tráfego (load balancer, ingress ou roteamento da plataforma). Se você já tem automação para provisionar ambientes e um controle de roteamento limpo, Blue/Green se torna um padrão prático para releases de alta confiança e baixo drama.
Quando lançamentos canários fazem mais sentido
Um lançamento canário é uma estratégia em que você libera uma mudança para uma pequena fatia de usuários primeiro, aprende com o que acontece e só então expande. É a escolha certa quando você quer reduzir risco sem parar o mundo por um grande release de uma só vez.
Você tem muito tráfego — e sinais claros
Canário funciona melhor para apps de alto tráfego porque mesmo 1–5% do tráfego pode gerar dados significativos rapidamente. Se você já monitora métricas claras (taxa de erro, latência, conversão, conclusão de checkout, timeouts de API), é possível validar o release com padrões de uso reais em vez de confiar apenas em ambientes de teste.
Você se preocupa com desempenho e casos de borda
Alguns problemas só aparecem sob carga real: queries lentas no banco, misses em cache, latência regional, dispositivos incomuns ou fluxos raros de usuários. Com um canário, você confirma que a mudança não aumenta erros ou degrada performance antes de atingir todos.
Você precisa de rollouts em etapas, não de um único corte
Se seu produto libera com frequência, tem múltiplas equipes contribuindo ou inclui mudanças que podem ser introduzidas gradualmente (ajustes de UI, experimentos de preço, lógica de recomendação), rollouts canários se encaixam naturalmente. Você pode expandir de 1% → 10% → 50% → 100% conforme o observado.
Feature flags fazem parte do seu kit
Canário combina especialmente bem com feature flags: você pode deployar o código em segurança e então habilitar a funcionalidade para um subconjunto de usuários, regiões ou contas. Isso torna rollbacks menos dramáticos — muitas vezes basta desligar a flag ao invés de redeployar.
Se você está caminhando para entrega progressiva, lançamentos canários costumam ser o ponto de partida mais flexível.
Veja também: /blog/feature-flags-and-progressive-delivery
Noções básicas de deslocamento de tráfego (sem jargões)
Deslocamento de tráfego significa simplesmente controlar quem recebe a nova versão da sua aplicação e quando. Em vez de mover todo mundo de uma vez, você transfere requisições gradualmente (ou seletivamente) da versão antiga para a nova. Isso é o coração prático tanto de uma implantação blue/green quanto de um lançamento canário — e é o que torna uma implantação sem downtime factível.
O “volante”: onde o tráfego é roteado
Você pode deslocar tráfego em alguns pontos comuns da sua stack. A escolha certa depende do que você já roda e do nível de controle necessário.
- Load balancer: divide requisições entre dois ambientes ou conjuntos de servidores.
- Ingress controller (Kubernetes): roteia tráfego para diferentes Services com base em regras.
- Service mesh: controla tráfego entre serviços com regras precisas e melhor visibilidade.
- CDN / roteamento na borda: útil quando quer decisões de roteamento próximas ao usuário, frequentemente para tráfego web.
Você não precisa de todas as camadas. Escolha uma fonte única de verdade para decisões de roteamento para que seu gerenciamento de releases não vire adivinhação.
Formas comuns de dividir o tráfego
A maioria das equipes usa uma (ou mistura) dessas abordagens para deslocamento de tráfego:
- Baseado em porcentagem: 1% → 5% → 25% → 50% → 100%. Padrão clássico do canário.
- Baseado em header: roteia requisições com um header específico (por exemplo, de ferramentas de QA ou testadores internos) para a nova versão.
- Coortes de usuário: libera para grupos específicos primeiro — funcionários, usuários beta, uma região ou um nível de cliente.
Porcentagem é mais fácil de explicar, mas coortes costumam ser mais seguras porque você controla quais usuários veem a mudança (e evita surpreender seus maiores clientes na primeira hora).
Sessões e caches: os dois “pegadinhas”
Duas coisas comumente quebram planos de implantação bem elaborados:
Sessões sticky (afinidade de sessão). Se o seu sistema prende um usuário a um servidor/versão, uma divisão de 10% talvez não se comporte como 10%. Também pode causar bugs confusos quando usuários pulam entre versões durante a sessão. Se possível, use armazenamento de sessão compartilhado ou garanta que o roteamento mantenha o usuário consistentemente em uma versão.
Aquecimento de cache. Versões novas frequentemente começam com caches frios (CDN, cache de aplicação, cache de query do banco). Isso pode parecer uma regressão de desempenho mesmo quando o código está correto. Planeje aquecer caches antes de aumentar o tráfego, especialmente para páginas de alto tráfego e endpoints caros.
Faça mudanças de tráfego uma operação controlada
Trate alterações de roteamento como mudanças de produção, não como um clique improvisado.
Documente:
- quem pode alterar divisões de tráfego
- como isso é aprovado (on-call? release manager? ticket de mudança?)
- onde é feito (config do load balancer, regras de ingress, política do mesh)
- o que significa “parar” (gatilho para pausar o rollout e seguir o plano de rollback)
Um pouco de governança evita que bem-intencionadas pessoas “só empurrem para 50%” enquanto você ainda avalia se o canário está saudável.
O que monitorar durante um rollout
Publique no seu domínio
Entre no ar no seu próprio domínio quando estiver pronto para promover uma nova versão.
Um rollout não é só “o deploy deu certo?” É “os usuários reais estão tendo uma experiência pior?” A forma mais simples de manter a calma durante Blue/Green ou canário é observar um pequeno conjunto de sinais que respondam: o sistema está saudável e a mudança está prejudicando clientes?
Os quatro sinais principais: erros, latência, saturação, impacto no usuário
Taxa de erro: monitore 5xx HTTP, falhas de requisição, timeouts e erros de dependência (banco, pagamentos, APIs de terceiros). Um canário que aumenta “pequenos” erros ainda pode gerar grande carga no suporte.
Latência: observe p50 e p95 (e p99, se tiver). Uma mudança que mantém a latência média estável pode criar caudas longas de lentidão que os usuários sentem.
Saturação: veja quão “cheio” seu sistema está — CPU, memória, disco IO, conexões DB, profundidade de filas, pools de threads. Problemas de saturação frequentemente se manifestam antes de quedas totais.
Sinais de impacto no usuário: meça o que os usuários realmente experimentam — falhas no checkout, taxa de sucesso de login, resultados de busca retornados, taxa de crash do app, tempos de carregamento de páginas-chave. Esses KPIs costumam ser mais significativos que estatísticas de infraestrutura isoladas.
Monte um “dashboard de release” que todo mundo entenda
Crie um dashboard pequeno, cabe em uma tela e é compartilhado no canal de release. Mantenha consistente em cada rollout para que ninguém perca tempo procurando gráficos.
Inclua:
- taxa de erro (geral + endpoints críticos)
- latência (p50/p95 para caminhos críticos)
- saturação (3 maiores restrições da sua stack, ex.: CPU do app, conexões DB, profundidade de fila)
- KPIs de impacto ao usuário (1–3 fluxos de negócio críticos)
Se for um lançamento canário, segmente métricas por versão/grupo de instâncias para comparar canário vs baseline diretamente. Para implantação blue/green, compare o novo ambiente com o antigo durante a janela de corte.
Defina limites claros para pausar/reverter
Decida as regras antes de começar a mover tráfego. Exemplos de gatilhos:
- taxa de erro aumenta X% sobre o baseline por Y minutos
- p95 excede um limite fixo (ou sobe X% sobre o baseline)
- um KPI de usuário cai abaixo de um mínimo aceitável
Os números exatos dependem do seu serviço, mas o importante é haver consenso. Se todo mundo sabe o plano de rollback e os gatilhos, evita-se debate enquanto clientes são afetados.
Alertas focados na janela de rollout
Adicione (ou ajuste temporariamente) alertas especificamente durante rollouts:
- picos inesperados de 5xx/timeouts
- regressão súbita de latência em rotas-chave
- crescimento rápido em sinais de saturação (pools de conexões, filas)
Mantenha alertas acionáveis: “o que mudou, onde e o que fazer em seguida.” Se seu sistema de alertas for barulhento, as pessoas perderão o sinal que realmente importa quando o deslocamento de tráfego estiver em andamento.
Checagens pré-release que pegam problemas cedo
A maioria das falhas em rollouts não vêm de “bugs enormes”. Vêm de pequenos desalinhamentos: um valor de configuração ausente, uma migration ruim, um certificado expirado ou uma integração que se comporta diferente no novo ambiente. Checagens pré-release são a chance de detectar essas questões enquanto o blast radius ainda é pequeno.
Comece por health checks e smoke tests
Antes de mover qualquer tráfego (seja Blue/Green ou um pequeno canário), confirme que a nova versão está viva e capaz de atender requisições.
- Garanta que endpoints de health reportem OK (não apenas “o processo está rodando”)
- Valide dependências: banco, cache, fila, armazenamento de objetos, provedores de e-mail/SMS
- Confirme que secrets e variáveis de ambiente estão presentes e corretamente escopadas
Rode testes rápidos end-to-end contra o novo ambiente
Testes unitários são ótimos, mas não provam que o sistema implantado funciona. Rode uma suíte end-to-end curta e automatizada contra o novo ambiente que termine em minutos, não horas.
Foque em fluxos que cruzem limites de serviço (web → API → banco → terceiros) e inclua ao menos uma requisição “real” por integração crítica.
Verifique jornadas críticas de usuário (as que pagam as contas)
Automatizados falham às vezes em pegar o óbvio. Faça uma verificação humana direcionada dos fluxos centrais:
- login e recuperação de senha
- fluxo de checkout ou pagamento (incluindo caminhos de falha)
- ações básicas de CRUD usadas diariamente
Se houver múltiplos papéis (admin vs cliente), teste ao menos uma jornada por papel.
Mantenha um checklist de prontidão pré-release
Um checklist transforma conhecimento tribal em uma estratégia repetível. Mantenha-o curto e acionável:
- migrations aplicadas e reversíveis (ou claramente seguras)
- observabilidade pronta: logs, dashboards, alerts para métricas-chave
- plano de rollback revisado (quem, como e o que significa “parar”)
Quando essas checagens se tornam rotina, o deslocamento de tráfego vira um passo controlado — não um salto de fé.
Rollout Blue/Green: um playbook prático
Aprenda e seja recompensado
Ganhe créditos ao compartilhar o que você constrói e aprende com Koder.ai.
Um rollout Blue/Green é mais fácil de executar quando tratado como um checklist: preparar, deployar, validar, trocar, observar e então limpar.
1) Deploy no Green (sem tocar nos usuários)
Faça o deploy da nova versão no Green enquanto Blue continua atendendo o tráfego real. Mantenha configs e secrets alinhados para que o Green seja um espelho fiel.
2) Valide o Green antes de qualquer troca de tráfego
Execute checagens rápidas e de alto sinal: app sobe limpo, páginas-chave carregam, pagamentos/login funcionam, e logs parecem normais. Se tiver smoke tests automatizados, rode-os agora. Esse é também o momento de verificar dashboards e alerts para o Green.
3) Planeje migrações de banco de forma segura (expand/contract)
Blue/Green fica complicado quando o banco muda. Use a abordagem expand/contract:
- Expandir: adicione colunas/tabelas novas de forma compatível com versões antigas.
- Deploy no Green para que ele funcione com o esquema antigo e com o novo.
- Contrair: remova campos antigos apenas depois que o Blue for aposentado e você estiver confiante na estabilidade.
Isso evita o cenário “Green funciona, Blue quebra” durante a troca.
4) Aqueça caches e trate jobs em background
Antes de trocar o tráfego, aqueça caches críticos (home, queries comuns) para que os usuários não sofram o custo de cold start.
Para jobs/background/cron, decida quem os executa:
- rode jobs em apenas um ambiente durante o corte para evitar processamento em duplicidade
5) Troque o tráfego e observe
Altere o roteamento de Blue para Green (load balancer/DNS/ingress). Observe taxa de erro, latência e métricas de negócio por uma janela curta.
6) Verificação pós-troca e limpeza
Faça verificações no estilo “usuário real” e mantenha Blue disponível brevemente como fallback. Uma vez estável, desative jobs do Blue, arquive logs e desprovisione o Blue para reduzir custo e confusão.
Rollout Canário: um playbook prático
Um rollout canário é sobre aprender com segurança. Em vez de enviar todo o tráfego para a nova versão de uma vez, você expõe uma pequena parte do tráfego real, observa de perto e só então expande. O objetivo não é “ir devagar” — é “comprovar segurança” com evidências a cada passo.
Um plano de ramp simples (1–5% → 25% → 50% → 100%)
- Prepare o canário
Deploy a nova versão ao lado da versão estável atual. Garanta que você possa rotear uma porcentagem definida de tráfego para cada uma e que ambas apareçam no monitoramento (dashboards separados ou tags ajudam).
- Estágio 1: 1–5%
Comece pequeno. É aqui que problemas óbvios surgem rápido: endpoints quebrados, configs ausentes, surpresas em migrations ou picos inesperados de latência.
Mantenha notas para a etapa:
- o que mudou nesse release (incluindo mudanças pequenas de config)
- o que você esperava que acontecesse
- o que observou (erros, latência, impacto ao usuário)
- Estágio 2: 25%
Se o estágio inicial estiver limpo, suba para cerca de um quarto do tráfego. Agora você verá mais variedade do mundo real: comportamentos diferentes, dispositivos de cauda longa, casos de borda e maior concorrência.
- Estágio 3: 50%
Meia carga é onde questões de capacidade e performance ficam mais claras. Se vai atingir um limite de escala, sinais iniciais normalmente aparecem aqui.
- Estágio 4: 100% (promoção)
Quando métricas estiverem estáveis e o impacto aceito, mova todo o tráfego para a nova versão e declare-a promovida.
Escolhendo intervalos de ramp (quanto esperar em cada etapa)
O timing depende de risco e volume de tráfego:
- Mudança de alto risco ou baixo tráfego: espere mais em cada estágio para coletar sinal suficiente (ex.: 30–60 minutos ou mais). Serviços de baixo tráfego podem precisar de horas para padrões significativos.
- Mudança de baixo risco com alto tráfego: estágios mais curtos funcionam (ex.: 5–15 minutos), porque os dados chegam rápido.
Considere também ciclos de negócio. Se seu produto tem picos (almoço, finais de semana, janelas de faturamento), rode o canário tempo suficiente para cobrir condições que costumam causar problemas.
Automação de promoção e rollback
Rollouts manuais causam hesitação e inconsistência. Automatize quando possível:
- promova quando métricas chave permanecerem dentro de limites por uma janela definida
- rollback quando limites forem violados (ex.: taxa de erro ou latência ultrapassa o limite)
Automação não substitui julgamento humano — remove atraso.
Trate cada estágio como um experimento
Para cada passo de ramp, registre:
- resumo da mudança (o que exatamente é diferente)
- critérios de sucesso (quais métricas devem permanecer estáveis)
- resultados observados (o que foi visto, inclusive “nada incomum”)
- decisão (promover, manter ou reverter) e por quê
Essas notas transformam o histórico de rollouts em um playbook e facilitam diagnosticar incidentes futuros.
Planos de rollback e tratamento de falhas
Rollbacks ficam fáceis quando você decide antes o que é “ruim” e quem pode apertar o botão. Um plano de rollback não é pessimismo — é como evitar que pequenos problemas virem quedas prolongadas.
Defina gatilhos claros de rollback
Escolha sinais curtos e límites explícitos para evitar debates em incidentes. Gatilhos comuns:
- taxa de erro: picos em 5xx, checkouts falhando, falhas de login ou timeouts de API
- latência: p95/p99 acima de um limite acordado por uma janela sustentada (ex.: 5–10 minutos)
- KPIs de negócio: quedas súbitas em conversão, sucesso de pagamento, cadastros ou aumento de cancelamentos
Faça o gatilho mensurável (“p95 > 800ms por 10 minutos”) e atribua um responsável (on-call, release manager) com permissão para agir imediatamente.
Mantenha o rollback rápido (e sem drama)
Velocidade é mais importante que elegância. Seu rollback deve ser uma destas opções:
- reverter o deslocamento de tráfego (típico para blue/green e canário): mova o tráfego de volta para a versão conhecida como boa
- redeploy da versão anterior: se a infra mudou, faça push do último build estável e rode health checks
Evite “consertar manualmente e continuar o rollout” como primeira medida. Estabilize primeiro, investigue depois.
Planeje rollbacks parciais
Com um canário, alguns usuários podem ter criado dados na nova versão. Decida antecipadamente:
- Usuários do canário voltam imediatamente ou ficam no canário enquanto avalia?
- Se formatos de dados mudaram, o banco é compatível com versões antigas? Se não, rollback pode exigir mitigação separada.
Post-mortem que melhora o próximo release
Uma vez estável, escreva um resumo curto: o que acionou o rollback, quais sinais faltaram e o que será alterado no checklist. Trate isso como ciclo de melhoria do processo de release, não como caça a culpados.
Feature flags e entrega progressiva
Implemente com confiança
Implemente e hospede seu app com uma forma fácil de criar instantâneos e reverter.
Feature flags permitem separar “deploy” (colocar código em produção) de “release” (ligar para as pessoas). Isso é importante porque você pode usar o mesmo pipeline de deploy — blue/green ou canário — enquanto controla a exposição com um simples interruptor.
Deploy sem pressão, release com intenção
Com flags, você pode mergear e deployar com segurança mesmo que uma feature não esteja pronta para todos. O código está presente, mas dormindo. Quando estiver confiante, habilita a flag gradualmente — frequentemente mais rápido que enviar um novo build — e, se algo der errado, desliga a flag igualmente rápido.
Habilitação direcionada (não tudo-ou-nada)
Entrega progressiva é sobre aumentar acesso em passos deliberados. Uma flag pode ser ativada para:
- um grupo específico de usuários (staff interno, beta users, cliente pago)
- uma região (comece por um país ou data center)
- uma porcentagem de usuários (1% → 10% → 50% → 100%)
Isso é útil quando um rollout canário indica que a nova versão está saudável, mas você ainda quer gerenciar o risco da feature separadamente.
Guardrails que evitam “dívida de flags”
Feature flags são poderosas, mas só se governadas. Alguns guardrails mantêm tudo organizado e seguro:
- propriedade: cada flag tem um time ou pessoa responsável
- expiração: defina data de remoção (ou revisão) para que flags antigas não se acumulem
- documentação: descreva o que a flag faz, quem ela afeta e como reverter
Regra prática: se alguém não consegue responder “o que acontece quando desligamos isso?”, a flag não está pronta.
Para orientação mais profunda sobre flags como parte da estratégia de releases, veja /blog/feature-flags-release-strategy.
Como escolher sua estratégia e começar
Escolher entre blue/green e canário não é “qual é melhor”. É sobre qual risco você quer controlar e com que capacidade sua equipe e ferramentas conseguem operar.
Uma forma rápida de decidir
Se sua prioridade é um corte limpo, previsível e um botão fácil para voltar à versão antiga, blue/green costuma ser a opção mais simples.
Se sua prioridade é reduzir blast radius e aprender com tráfego real antes de generalizar, canário é a opção mais segura — especialmente quando mudanças são frequentes ou difíceis de testar totalmente antes.
Uma regra prática: escolha a abordagem que sua equipe consegue rodar consistentemente às 2 da manhã quando algo der errado.
Comece pequeno: pilote uma coisa
Escolha um serviço (ou um fluxo de usuário) e execute um piloto por alguns releases. Pegue algo importante, mas não tão crítico que todo mundo congele. O objetivo é criar músculo para deslocamento de tráfego, monitoramento e rollback.
Escreva um runbook simples (e atribua dono)
Mantenha curto — uma página serve:
- o que é “bom” (métricas-chave e thresholds)
- quem está responsável durante o rollout
- como pausar, reverter e comunicar
Garanta propriedade. Uma estratégia sem dono vira sugestão.
Use o que você já tem primeiro
Antes de adicionar novas plataformas, olhe para as ferramentas que já usa: configurações do load balancer, scripts de deploy, monitoramento existente e seu processo de incidentes. Adicione ferramentas novas apenas quando elas removerem fricção real sentida no piloto.
Se você está criando e entregando serviços rapidamente, plataformas que integram geração de app com controles de deploy também reduzem atrito operacional. Por exemplo, Koder.ai é uma plataforma vibe-coding que permite criar apps web, backend e mobile a partir de uma interface de chat — e então deployar e hospedar com recursos de segurança como snapshots e rollback, além de suporte a domínios customizados e exportação de código fonte. Essas capacidades mapeiam bem para o objetivo central deste artigo: tornar releases repetíveis, observáveis e reversíveis.
Próximos passos sugeridos
Se quiser ver opções de implementação e workflows suportados, revise /pricing e /docs/deployments. Depois, agende seu primeiro release piloto, documente o que funcionou e itere o runbook após cada rollout.