Do que isto realmente trata: menos acompanhamentos de envio
Quando o volume de pedidos é pequeno, atualizações de envio podem ser resolvidas com checagens rápidas, uma planilha e algumas mensagens para a transportadora. À medida que os pedidos crescem, pequenas falhas se acumulam: etiquetas criadas fora do horário, pickups perdidos e rastreamento desatualizado.
O padrão é familiar: clientes perguntam “Onde está meu pedido?” Suporte pergunta para operações. Operações confere um portal. Alguém atualiza manualmente um status que deveria ter sido atualizado automaticamente.
Uma integração simplesmente significa que seu sistema pode enviar dados de envio (endereço, peso, COD, valor da nota) e puxar dados de envio de volta (número AWB, confirmação de pickup, scans de rastreamento, resultados de entrega) de forma confiável. “Confiável” importa porque deve funcionar todo dia, não apenas quando alguém lembra de fazer o upload de um arquivo.
Por isso essa comparação importa:
- Um fluxo de upload CSV é a linha de base. É fácil começar, mas depende de pessoas repetindo os mesmos passos no prazo.
- Uma integração completa via API de transportadora é a versão sempre ativa. Ela pode criar remessas, buscar scans de rastreamento e reagir a exceções sem esperar trabalho manual.
A maioria das equipes não quer “mais tecnologia.” Quer menos atrasos, menos edições manuais e rastreamento em que todos confiem. Reduza acompanhamentos (de clientes e times internos) e você normalmente reduz reembolsos, custos de reenvio e tickets de suporte também.
Onde o trabalho de envio dá errado nas operações reais
A maioria das equipes começa com uma rotina simples: agendar pickups, imprimir etiquetas, colar IDs de rastreamento numa planilha e responder quando os clientes pedem atualizações. Funciona em baixo volume, mas as rachaduras aparecem rápido na Índia, especialmente quando você lida com várias transportadoras, COD e qualidade de endereço inconsistente.
Os passos manuais não parecem grandes isoladamente. Alguém escolhe a transportadora, cria a remessa, baixa etiquetas e garante que o pacote certo receba o airway bill (AWB) correto. Então outra pessoa atualiza o status do pedido, compartilha o rastreamento e confere provas de entrega para COD.
Os pontos de falha mais comuns são:
- O AWB errado fica preso ao pacote errado, levando a perda ou devolução.
- Remessas duplicadas são criadas após uma reattempt ou por erro de cópia na planilha.
- O rastreamento não é atualizado a tempo, então o suporte não tem resposta clara e os clientes perdem confiança.
- O pickup não é confirmado, então pedidos ficam “prontos para envio” enquanto a transportadora acha que nada está agendado.
- Valores ou taxas de COD não batem, criando problemas de conciliação depois.
NDR significa Non‑Delivery Report. É o que acontece quando a entrega falha (endereço errado, cliente ausente, recusa, problema de pagamento). NDR gera trabalho extra porque força decisões: ligar para o cliente, atualizar o endereço, aprovar uma nova tentativa ou marcar para devolução.
Operações sente a pressão primeiro. Suporte recebe mensagens raivosas. Financeiro emperra na conciliação de COD. Clientes sentem o silêncio quando os status não mudam.
Opção A: o baseline de upload CSV (o que você ganha e o que não ganha)
Upload CSV é o ponto de partida padrão para muitos setups de envio na Índia. Você exporta um lote de pedidos pagos da sua loja ou ERP, formata num template da transportadora ou agregador e faz o upload no dashboard para gerar AWBs e etiquetas.
O que você ganha é simplicidade. Geralmente não há trabalho de engenharia e você pode rodar em um dia. Para baixo volume ou envio previsível (mesmo endereço de pickup, pequeno conjunto de SKUs, poucas exceções), um CSV diário pode ser “suficiente” e fácil de treinar.
Onde isso quebra é em tudo que vem depois do upload. A maioria das equipes acaba fazendo a mesma limpeza todo dia: corrigir linhas falhadas porque um pincode ou formato de telefone não bate com o template, re‑upar arquivos corrigidos, checar duplicados acidentais e copiar/colar números de rastreamento de volta para o admin da loja.
Aí vem a parte bagunçada: correr atrás de exceções (problemas de endereço, pagamento, risco de RTO) por e‑mail, telefone e portais de transportadora, e atualizar status em múltiplos lugares porque o dashboard da transportadora não é o seu sistema de registro.
O custo oculto é tempo e inconsistência. Transportadoras diferentes esperam colunas e regras distintas, então “um CSV” vira várias versões mais gambiarras de planilha. E porque as atualizações não são em tempo real, o suporte muitas vezes só descobre atrasos quando um cliente reclama.
Opção B: integração completa por API da transportadora (o que desbloqueia e o que custa)
Uma configuração completa de API significa que seu sistema e os sistemas da transportadora conversam diretamente. Em vez de subir arquivos, você envia detalhes do pedido e endereço automaticamente, recebe uma etiqueta e fica puxando updates de rastreamento sem que ninguém precise checar vários portais. Normalmente é o ponto em que o envio para de ser uma tarefa diária de operações e começa a se comportar como infraestrutura confiável.
O que isso desbloqueia
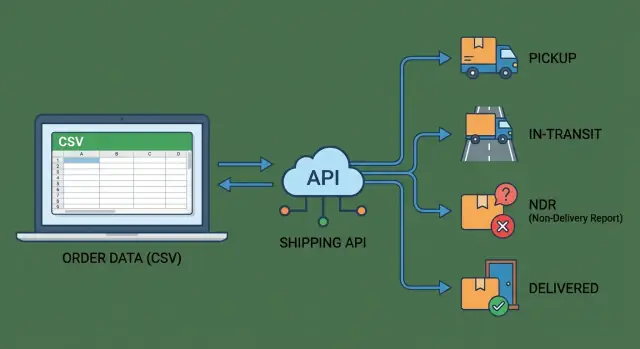
A maioria das equipes começa uma integração de API para três ações centrais: booking, etiquetas e rastreamento. Capacidades típicas incluem criar uma remessa e obter um AWB instantaneamente, gerar a etiqueta e dados da nota fiscal, solicitar pickup (onde suportado) e puxar scans de rastreamento quase em tempo real.
Uma vez com o básico, você também pode tratar exceções de forma mais limpa, como problemas de endereço e atualizações de status NDR.
O retorno é direto: despacho mais rápido, menos erros de copiar/colar e atualizações ao cliente mais claras. Se um pedido é pago às 14h, seu sistema pode auto‑agendar a remessa, imprimir a etiqueta e enviar o número de rastreamento em minutos, sem esperar exportar e re‑upar um CSV.
O que custa
Integrações por API não são “configure e esqueça”. Planeje tempo para setup, testes e manutenção contínua.
As fontes usuais de esforço:
- Regras específicas de transportadora (pincode atendido, faixas de peso, limites de COD)
- Desalinhamento de códigos de status (o “RTO iniciado” de uma pode ser “return in transit” de outra)
- Confiabilidade de webhooks e lógica de retry para eventos perdidos
- Formatos de etiqueta e requisitos de documento que mudam com o tempo
- Sandboxes que não batem 100% com produção
Se você planejar essas particularidades desde cedo, o setup escala bem. Se não, pode acabar com remessas agendadas mas não coletadas, ou clientes vendo status confusos porque eventos de rastreamento não foram mapeados corretamente.
O que automatizar vs manter manual (uma divisão prática)
Uma regra simples funciona bem: automatize tarefas que acontecem muitas vezes ao dia e que geram mais retrabalho quando alguém erra.
Na Índia, isso normalmente significa booking, etiquetas e atualizações de rastreamento. Um erro de digitação ou um scan perdido pode desencadear uma cadeia de acompanhamentos.
Passos manuais ainda têm lugar. Mantenha algo manual quando o volume é baixo, exceções são frequentes ou processos da transportadora não são consistentes o suficiente para confiar na automação.
Uma divisão prática por fluxo:
- Automatizar primeiro: agendamento de remessa a partir do sistema de pedidos, geração e impressão de etiquetas, pulls de status de rastreamento ou webhooks, alertas de NDR com fila interna e mensagens de confirmação de entrega para o time de suporte.
- Manter manual (até ter volume): escolher uma transportadora para casos de borda, negociar mudanças de pickup por telefone, aprovar reattempts de COD arriscados e correções pontuais de endereço que exigem julgamento.
Uma tabela rápida de decisão antes de construir qualquer coisa:
| Fator | Quando manual é aceitável | Quando a automação compensa |
|---|
| Volume diário de pedidos | Abaixo de ~20/dia | 50+/dia ou picos frequentes |
| Número de transportadoras | 1 transportadora | 2+ transportadoras ou trocas frequentes |
| Pressão de SLA | Entrega em 3–5 dias é aceitável | Promessas same/next‑day, penalidades altas |
| Tamanho do time | Pessoa de operações dedicada | Papéis compartilhados ops/suporte |
Um checkpoint simples: se seu time toca os mesmos dados duas vezes (copiar/colar do pedido para o portal da transportadora, depois de volta para uma planilha), esse passo é um forte candidato à automação.
Checklist de eventos de rastreamento: pickup, em‑trânsito, NDR, entregue
Se você quer menos mensagens “onde está meu pedido?”, trate o rastreamento como uma linha do tempo de eventos, não um único status. Isso importa na Índia, onde a mesma remessa pode passar por vários hubs, tentativas e devoluções.
Capture estas etapas para que seu time e os clientes vejam a mesma história:
- Pickup: quando o pickup foi agendado, se foi tentado e o resultado final (coletado ou falhou). Quando falha, armazene o motivo de falha da transportadora para agir sem ligar para o entregador.
- Em‑trânsito: o primeiro scan (muitas vezes o verdadeiro começo), scans em hubs importantes, flags de exceção ou atraso e “out for delivery”. Esses são os pontos que geram a maioria das perguntas ao suporte.
- NDR (Non‑Delivery Report): quando um NDR é levantado, o código do motivo, se o cliente foi contatado e o que acontece a seguir (reattempt planejado ou devolução iniciada). O relógio costuma estar correndo aqui.
- Entregue (ou não): horário de entrega e detalhes da prova de entrega quando disponíveis (nome, assinatura, referência de foto). Separe também “entrega falhada” de “devolvido”, porque clientes entendem esses resultados de formas muito diferentes.
Para cada evento, guarde os mesmos campos principais: timestamp, localização (cidade e hub se disponível), texto cru do status, status normalizado, código de motivo e referência da transportadora/AWB. Manter valores crus e normalizados facilita auditorias e disputas com transportadoras.
Dados que você precisa antes de integrar (para que nada quebre depois)
Muitas integrações de envio falham por motivos banais: telefones faltando, pesos inconsistentes ou ausência de definição clara de qual sistema “possui” a verdade. Antes de tocar uma API, trave os dados mínimos que sempre estarão presentes para cada pedido.
Comece com uma linha de base que também funcione com CSV. Se você não consegue exportar esses campos de forma confiável, uma API só fará os erros acontecerem mais rápido:
- Order ID (único e nunca reutilizado)
- Endereço de entrega completo (nome, pincode, cidade, estado, ponto de referência se coletado)
- Número de telefone (formato validado) e e‑mail (opcional)
- Itens e informações da remessa (SKU, quantidade, peso bruto, dimensões se tiver)
- Detalhes de pagamento (valor COD, flag de pré‑pago)
Depois, defina o que espera receber de volta da transportadora, porque isso vira seus “ganchos” para todo o resto. No mínimo, armazene shipment ID, número AWB, nome ou código da transportadora, referência da etiqueta e data/janela de pickup.
Uma decisão evita semanas de confusão: escolha sua única fonte da verdade para o status da remessa. Se seu time continua checando o portal da transportadora e sobrescrevendo seu sistema, clientes verão uma coisa enquanto o suporte diz outra.
Um plano simples de mapeamento que mantém todos alinhados:
- Escolha os status internos que vai usar (por exemplo: Created, Picked Up, In Transit, Out for Delivery, Delivered, NDR).
- Mapeie cada status da transportadora para um status interno (mesmo que pareça menos detalhado).
- Salve o texto cru do status da transportadora separadamente para auditorias.
- Decida quais eventos podem alterar status automaticamente vs somente por um humano.
Se estiver construindo isso dentro de uma ferramenta como Koder.ai, trate esses campos e mapeamentos como modelos de primeira classe cedo, para que exports, rastreamento e rollback não quebrem quando você adicionar uma segunda transportadora.
Passo a passo: migrar de CSV para API sem caos
O caminho de upgrade mais seguro é uma série de pequenas trocas, não um corte único. Operações deve continuar enviando enquanto a integração fica mais apertada.
1) Trave o escopo antes de escrever código
Escolha as transportadoras que você realmente vai usar, então confirme quais ações você precisa agora vs depois: booking, rastreamento, tratamento de NDR e devoluções (RTO). Isso importa porque cada transportadora nomeia status de forma diferente e expõe campos distintos.
2) Integre rastreamento primeiro (somente leitura)
Antes de automatizar booking ou criação de etiquetas, puxe eventos de rastreamento para seu sistema e mostre‑os ao lado do pedido. Isso é baixo risco porque não altera como os pacotes são criados.
Assegure que você consegue buscar eventos por AWB e trate casos onde o AWB está faltando ou está errado.
3) Mapeie status, mas armazene a verdade crua
Crie um pequeno modelo de status interno (pickup, em‑trânsito, NDR, entregue), então mapeie os status da transportadora para ele. Também salve cada payload de evento cru exatamente como recebido.
Quando um cliente diz “mostra entregue mas eu não recebi”, eventos crus ajudam o suporte a responder rápido.
Automatize as partes fáceis primeiro: detectar NDR, atribuir a uma fila, notificar o cliente e definir timers para janelas de reattempt.
Mantenha um override manual para mudanças de endereço e casos especiais.
5) Só então adicione booking, etiquetas e agendamento de pickup
Quando o rastreamento estiver estável, adicione booking por API, geração de etiquetas e solicitações de pickup. Faça rollout transportadora por transportadora, mantendo a via CSV como fallback por algumas semanas.
Teste com cenários reais:
- Mudança de endereço após NDR
- Reattempt solicitado mas não realizado
- RTO acionado e depois cancelado
- Entrega parcial ou remessa dividida
- Scan de entregue sem OTP ou detalhes de POD
Erros comuns que causam atrasos e tickets de suporte
A maioria dos tickets de envio não é só “onde está meu pedido?” São expectativas desencontradas: seu sistema diz uma coisa, a transportadora outra e o cliente vê uma terceira.
Uma armadilha comum é assumir que o texto do status é uniforme. O mesmo marco pode aparecer com frases diferentes entre zonas, tipos de serviço ou hubs. Se você mapear por texto exato em vez de normalizar em seu pequeno conjunto de estados, seu dashboard e mensagens ao cliente divergem.
Erros que geram atrasos e acompanhamentos extras:
- Salvar apenas o último status: sobrescrever eventos perde a linha do tempo que explica o que aconteceu. Mantenha o histórico completo com timestamps e localização.
- Tratar NDR como um único status: NDR é um processo. Você precisa do motivo, da ação tomada e da data da próxima tentativa.
- Sem tratamento para eventos tardios ou fora de ordem: transportadoras podem enviar eventos em lotes ou em ordem estranha. Sem reconciliação e atualizações seguras, seu sistema pode ficar alternando status.
- Falta de lógica de retry e tratamento de rate‑limit: chamadas de API falham. Se você não fizer retries com segurança, perde updates. Se retryar agressivamente, recebe rate‑limit.
- Sem plano operacional de fallback: decida o que acontece quando a API cai. Dá para trocar para CSV por um dia, pausar notificações ou sinalizar pedidos para revisão manual?
Um exemplo simples: um cliente liga dizendo que o pacote foi “devolvido”. Seu sistema só mostra “NDR”. Se você tivesse armazenado o motivo do NDR e histórico de reattempts, o agente poderia responder numa única mensagem em vez de escalar para operações.
Checagens rápidas antes de considerar a integração “pronta”
Antes de declarar sucesso, teste a integração do jeito que ops e suporte vão usar num dia ocupado. Uma atualização de status da transportadora que chega atrasada, ou que chega sem os detalhes certos, cria o mesmo problema que nenhuma atualização.
Execute um drill “uma remessa, de ponta a ponta” em pelo menos 10 pedidos reais através de pincodes e tipos de pagamento (prepaid e COD). Escolha um pedido e cronometre quanto tempo leva para responder:
- Onde está agora?
- O que aconteceu antes?
- O que fazemos a seguir?
Uma lista rápida que pega a maioria das lacunas:
- Prova de pickup visível rapidamente: você vê pickup confirmado dentro da janela esperada, e consegue diferenciar “etiqueta criada” de “fisicamente coletado”.
- NDR é acionável, não só um status: você armazena o código de motivo do NDR mais o próximo passo (reattempt, ligar, ou RTO) e pode alterar essa decisão.
- Linha do tempo fácil de achar: um agente pode puxar o histórico completo de eventos de um AWB em menos de 30 segundos, incluindo timestamps e scans de localização.
- Entregue bate com dinheiro e devoluções: remessas entregues conciliam com relatórios de remessa COD e dados de devolução/RTO, para que financeiro não corra atrás no fim de semana.
- Existe um override manual seguro: dá para corrigir um endereço, reagendar uma entrega ou reatribuir para outra transportadora quando necessário, e toda mudança manual é logada.
Se estiver construindo telas internas, mantenha a primeira versão sem frescuras: uma caixa de busca por remessa, uma linha do tempo limpa e dois botões (nota manual e override).
Ferramentas como Koder.ai podem ajudar a prototipar esse dashboard de operações rapidamente e exportar o código‑fonte quando você estiver pronto para assumir. Se quiser explorar depois, procure por Koder.ai.