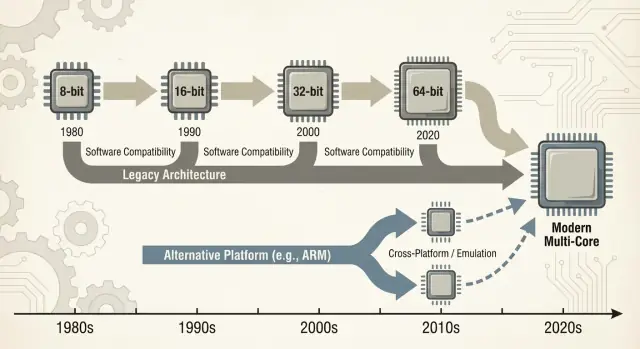
O que este post quer dizer com dominância x86
Quando as pessoas dizem “x86”, geralmente se referem a uma família de instruções de CPU que começou com o chip 8086 da Intel e evoluiu ao longo de décadas. Essas instruções são os verbos básicos que um processador entende—somar, comparar, mover dados, e assim por diante. Esse conjunto de instruções é chamado de ISA (instruction set architecture). Você pode pensar na ISA como a “língua” que o software precisa falar para rodar em um tipo específico de CPU.
Definições em linguagem simples
x86: A ISA mais comum usada em PCs durante a maior parte dos últimos 40 anos, implementada principalmente pela Intel e também pela AMD.
Compatibilidade retroativa: A capacidade de computadores mais novos continuarem a rodar software antigo (às vezes programas com décadas) sem exigir grandes reescritas. Não é perfeita em todos os casos, mas é uma promessa orientadora do mundo PC: “Suas coisas deveriam continuar funcionando.”
O que “dominância” significa neste post
“Dominância” aqui não é só sobre desempenho. É uma vantagem prática e composta em várias dimensões:
- Volume: Enormes quantidades de chips x86 enviados para desktops, laptops e servidores.
- Suporte de software: Um dos maiores catálogos de apps, jogos, software empresarial e ferramentas de desenvolvedor criados primeiro (ou melhor) para x86.
- Mindshare: A suposição padrão—por compradores, departamentos de TI e desenvolvedores—de que um “computador normal” é x86, a menos que se diga o contrário.
Essa combinação importa porque cada camada reforça as outras. Mais máquinas encorajam mais software; mais software encoraja mais máquinas.
Trocar uma ISA dominante não é como trocar um componente. Pode quebrar—ou pelo menos complicar—aplicações, drivers (para impressoras, GPUs, dispositivos de áudio, periféricos de nicho), cadeias de ferramentas de desenvolvedor e até hábitos do dia a dia (processos de imagem, scripts de TI, agentes de segurança, pipelines de implantação). Muitas dessas dependências ficam invisíveis até que algo falhe.
Escopo da discussão
Este post foca principalmente em PCs e servidores, onde o x86 tem sido o padrão por muito tempo. Também faremos referência a transições recentes—especialmente as transições para ARM—porque elas trazem lições modernas e fáceis de comparar sobre o que muda suavemente, o que não muda, e por que “só recompilar” raramente é toda a história.
Como a era do PC preparou o terreno para o x86
O mercado inicial de PCs não começou com um plano arquitetônico grandioso—começou com restrições práticas. Empresas queriam máquinas acessíveis, disponíveis em volume e fáceis de consertar. Isso empurrou fabricantes em direção a CPUs e peças que podiam ser obtidas de forma confiável, emparelhadas com periféricos padrão e montadas em sistemas sem engenharia customizada.
CPUs acessíveis + componentes padrão
O design original do PC da IBM apostou fortemente em componentes prontos e um processador Intel 8088 relativamente barato. Essa escolha importou porque fez o “PC” parecer menos um produto único e mais uma receita: uma família de CPU, um conjunto de slots de expansão, uma abordagem de teclado/monitor e um stack de software que podia ser reproduzido.
Clones, fontes alternativas e um mercado maior
Quando o PC da IBM provou que havia demanda, o mercado se expandiu via clonagem. Empresas como a Compaq mostraram que dava para construir máquinas compatíveis que rodavam o mesmo software—e vendê‑las em pontos de preço diferentes.
Igualmente importante foi a fabricação de segunda fonte: múltiplos fornecedores podiam prover processadores ou componentes compatíveis. Para compradores, isso reduziu o risco de apostar em um único fornecedor. Para OEMs, aumentou oferta e competição, acelerando a adoção.
“Roda os mesmos programas” virou regra de compra
Nesse ambiente, compatibilidade virou a característica que as pessoas entendiam e valorizavam. Compradores não precisavam saber o que era uma ISA; só precisavam saber se o Lotus 1-2-3 (e depois os aplicativos do Windows) rodariam.
A disponibilidade de software rapidamente virou um heurístico simples de compra: se roda os mesmos programas que outros PCs, é uma escolha segura.
Convenções de hardware e firmware fizeram muito trabalho invisível. Barramentos comuns e abordagens de expansão—junto com expectativas de BIOS/firmware e comportamentos de sistema compartilhados—facilitaram que fabricantes de hardware e desenvolvedores de software mirassem “o PC” como uma plataforma estável.
Essa estabilidade ajudou a consolidar o x86 como a base padrão sob um ecossistema em crescimento.
O volante do ecossistema de software
x86 não venceu apenas por frequências ou chips engenhosos. Venceu porque o software seguiu os usuários, e os usuários seguiram o software—um efeito de rede econômico que se multiplica ao longo do tempo.
Efeito de rede: mais usuários → mais apps → mais usuários
Quando uma plataforma ganha vantagem inicial, desenvolvedores veem um público maior e um caminho mais claro para receita. Isso produz mais aplicações, melhor suporte e mais add‑ons de terceiros. Essas melhorias tornam a plataforma ainda mais atraente para a próxima leva de compradores.
Repita esse loop por anos e a plataforma “padrão” torna‑se difícil de desalojar—mesmo que alternativas sejam tecnicamente atraentes.
É por isso que transições de plataforma não se tratam só de construir uma CPU. Trata‑se de recriar um ecossistema inteiro: apps, instaladores, canais de atualização, periféricos, processos de TI e o conhecimento coletivo de milhões de usuários.
Empresas costumam manter aplicações críticas por muito tempo: bancos de dados customizados, ferramentas internas, add‑ons de ERP, software específico do setor e macros de fluxo de trabalho que ninguém quer mexer porque “simplesmente funcionam.” Um alvo x86 estável significava:
- Upgrades previsíveis (PCs novos ainda rodavam software antigo)
- Ciclos de vida de hardware mais longos
- Menos surpresas para help desks e orçamentos de treinamento
Mesmo que uma nova plataforma prometesse custos menores ou melhor desempenho, o risco de quebrar um fluxo de receita frequentemente superava o benefício.
Como prioridades de desenvolvedores seguem base instalada e custos de suporte
Desenvolvedores raramente otimizam para a “melhor” plataforma no vácuo. Eles otimizam para a plataforma que minimiza a carga de suporte e maximiza o alcance.
Se 90% dos seus clientes estão em Windows x86, é aí que você testa primeiro, lança primeiro e corrige bugs mais rápido. Suportar uma segunda arquitetura pode significar pipelines de build extras, mais matrizes de QA, mais debugging “funciona na minha máquina” e mais roteiros de suporte ao cliente.
O resultado é uma lacuna auto‑reforçadora: a plataforma líder tende a receber software melhor, mais rápido.
Um exemplo simples: software de contabilidade e drivers de impressora
Imagine uma pequena empresa. O pacote de contabilidade é só x86, integrado com uma década de templates e um plugin para folha de pagamento. Eles também dependem de uma impressora de etiquetas específica e um scanner com drivers temperamental.
Agora proponha uma mudança de plataforma. Mesmo se os apps centrais existirem, as pontas importam: o driver da impressora, o utilitário do scanner, o plugin de PDF, o módulo de importação bancária. Essas dependências “sem graça” se tornam imprescindíveis—e quando estão faltando ou são instáveis, toda migração empaca.
Esse é o volante em ação: a plataforma vencedora acumula a longa cauda de compatibilidade da qual todos dependem silenciosamente.
Compatibilidade retroativa como estratégia de produto
Compatibilidade retroativa não foi só um recurso do x86—virou estratégia deliberada de produto. A Intel manteve a ISA x86 estável o suficiente para que software escrito anos antes ainda pudesse rodar, enquanto mudava quase tudo por baixo.
Microarquitetura evolui; ISA fica em grande parte
A distinção chave é o que permaneceu compatível. A ISA define as instruções da máquina das quais os programas dependem; microarquitetura é como um chip as executa.
A Intel pôde passar de pipelines simples para execução fora de ordem, adicionar caches maiores, melhorar predição de branches ou introduzir novos processos de fabricação—sem pedir aos desenvolvedores que reescrevessem seus apps.
Essa estabilidade criou uma expectativa poderosa: novos PCs deveriam rodar software antigo no primeiro dia.
Adicionando poder sem quebrar código antigo
x86 acumulou novas capacidades em camadas. Extensões de conjunto de instruções como MMX, SSE, AVX e recursos posteriores foram aditivas: binários antigos ainda funcionavam, e apps mais novos podiam detectar e usar instruções quando disponíveis.
Mesmo transições maiores foram suavizadas por mecanismos de compatibilidade:
- Modos legados que preservam ambientes de execução antigos (por exemplo, compatibilidade 16‑bit e 32‑bit em processadores mais recentes).
- Protected e long mode que permitem que sistemas operacionais modernos usem mais memória e recursos de segurança enquanto ainda suportam apps antigos.
- Extensões de virtualização (como Intel VT‑x) que facilitaram rodar SOs antigos ou cargas isoladas de forma eficiente.
O trade‑off: legado vira restrição
O lado negativo é a complexidade. Suportar décadas de comportamento significa mais modos de CPU, mais casos de borda e uma carga de validação maior. Cada nova geração precisa provar que ainda roda o app de negócios, driver ou instalador de ontem.
Com o tempo, “não quebrar apps existentes” deixa de ser uma diretriz e vira uma restrição estratégica: protege a base instalada, mas também torna mudanças radicais de plataforma—novas ISAs, novos designs de sistema, novas suposições—muito mais difíceis de justificar.
O ciclo Wintel: SO, hardware e incentivos dos OEMs
“Wintel” não foi só um rótulo para Windows e chips Intel. Descreveu um ciclo auto‑reforçador onde cada parte da indústria de PCs se beneficiava de manter o mesmo alvo padrão: Windows em x86.
Por que Windows + x86 virou alvo padrão para apps
Para a maioria dos vendedores de software de consumo e empresarial, a questão prática não era “qual a melhor arquitetura?” mas “onde estão os clientes e como serão as chamadas de suporte?”
Os PCs com Windows estavam amplamente implantados em lares, escritórios e escolas, e eram majoritariamente x86. Enviar para essa combinação maximizava alcance enquanto minimizava surpresas.
Quando uma massa crítica de apps assumiu Windows + x86, novos compradores tiveram outro motivo para escolher: seus softwares essenciais já funcionavam ali. Isso, por sua vez, tornou a plataforma ainda mais atraente para a próxima leva de desenvolvedores.
OEMs, periféricos e o volante dos drivers
Fabricantes de PCs (OEMs) têm sucesso quando conseguem construir muitos modelos rápido, obter componentes de múltiplos fornecedores e enviar máquinas que “simplesmente funcionam.” Uma base comum Windows + x86 simplificou isso.
Empresas de periféricos seguiram o volume. Se a maioria dos compradores usava PCs Windows, então impressoras, scanners, interfaces de áudio, chips Wi‑Fi e outros dispositivos priorizariam drivers para Windows primeiro. Melhor disponibilidade de drivers melhorou a experiência do PC Windows, ajudou OEMs a vender mais unidades e manteve o volume alto.
Realidade de compras: menor risco costuma vencer
Compras corporativas e governamentais tendem a recompensar previsibilidade: compatibilidade com apps existentes, custos de suporte gerenciáveis, garantias de fornecedores e ferramentas de implantação comprovadas.
Mesmo quando alternativas eram atraentes, a escolha de menor risco frequentemente vencia porque reduzia treinamento, evitava falhas de casos de borda e cabia em processos de TI estabelecidos.
O resultado foi menos conspiração do que um conjunto de incentivos alinhados—cada participante escolhendo o caminho que reduz fricção—criando um momentum que tornou a mudança de plataforma incomumente difícil.
Converta progresso em créditos
Crie conteúdo sobre sua build e ganhe créditos para continuar experimentando.
Uma “transição de plataforma” não é só trocar uma CPU por outra. É uma mudança de pacote: o ISA da CPU, o sistema operacional, o compilador/toolchain que constrói apps e a pilha de drivers que faz o hardware funcionar. Mude qualquer um desses e você frequentemente perturba os outros.
Dependências ocultas que você só vê quando falham
A maior parte das quebras não é um dramático “o app não abre”. É morte por mil cortes:
- Instaladores e atualizadores que assumem uma certa versão do Windows, layout do registro ou runtime x86.
- Proteções de cópia e gerenciadores de licença ligados a IDs de hardware específicos, drivers de kernel ou suposições de temporização.
- Plugins, add‑ins e extensões compilados para uma só arquitetura (pense em plugins CAD, VSTs de áudio, helpers de navegador).
- Macros e automações dentro de documentos do Office, telas de ERP ou scripts caseiros que dependem de caminhos exatos, objetos COM ou APIs obsoletas.
Mesmo que o app central tenha uma nova build, sua “cola” ao redor pode não ter.
Periféricos: o bloqueador de upgrade que ninguém orça
Impressoras, scanners, cortadores de etiquetas, placas PCIe/USB especializadas, dispositivos médicos, equipamentos de ponto de venda e dongles USB vivem e morrem por drivers. Se o fornecedor sumiu—ou simplesmente não se interessou—pode não haver driver para o novo SO ou arquitetura.
Em muitas empresas, um dispositivo de $200 pode congelar uma frota de PCs de $2.000.
O problema da cauda longa de software
O maior bloqueador costuma ser ferramentas internas “pequenas”: um banco de dados Access customizado, uma planilha Excel com macros, um app VB de 2009, uma utilidade de manufatura usada por três pessoas.
Esses itens não estão no roadmap de produto de ninguém, mas são críticos. Transições fracassam quando a cauda longa não é migrada, testada e assumida por alguém.
A economia real da troca
Uma mudança de plataforma não é julgada só por benchmarks. É julgada se a conta total—dinheiro, tempo, risco e perda de momentum—fica abaixo do benefício percebido. Para a maioria das pessoas e organizações, essa conta é maior do que parece por fora.
A conta do usuário: tempo, hábitos e quebras “pequenas”
Para usuários, os custos começam no óbvio (hardware novo, periféricos novos, novas garantias) e rapidamente entram no bagunçado: reeducar memória muscular, reconfigurar workflows e revalidar ferramentas diárias.
Mesmo quando um app “roda”, os detalhes podem mudar: um plugin não carrega, um driver de impressora falta, uma macro se comporta diferente, um anti‑cheat de jogo dispara ou um acessório de nicho para de funcionar. Cada um é pequeno; juntos podem apagar o valor do upgrade.
A conta do fornecedor: espalhamento de QA e carga de suporte
Fornecedores pagam pela mudança com uma matriz de testes que explode. Não é só “abre?”. É:
- diferentes versões de SO e canais de atualização
- diferentes gerações de CPU e conjuntos de recursos
- drivers, firmware e ferramentas de segurança
- políticas empresariais e modos de lockdown
Cada combinação extra aumenta tempo de QA, mais documentação para manter e mais tíquetes de suporte. Uma transição pode transformar um trem de releases previsível em um ciclo permanente de resposta a incidentes.
A conta do desenvolvedor: portas, desempenho e confiança
Desenvolvedores absorvem o custo de portar bibliotecas, reescrever código crítico de desempenho (muitas vezes otimizado à mão para uma ISA) e reconstruir testes automatizados. A parte mais difícil é restaurar confiança: provar que a nova build está correta, rápida o suficiente e estável sob cargas reais.
O assassino oculto: custo de oportunidade
Trabalho de migração compete diretamente com novas funcionalidades. Se uma equipe passa dois trimestres fazendo as coisas apenas “voltarem a funcionar”, são dois trimestres em que não melhoraram o produto.
Muitas organizações só mudam quando a plataforma antiga as bloqueia—ou quando a nova é tão atraente que justifica a troca.
Pontes: emulação, tradução e virtualização
Prototipe o app substituto
Crie uma ferramenta interna rápida no chat e veja como é rápido iterar.
Quando uma nova arquitetura de CPU chega, usuários não perguntam sobre conjuntos de instruções—perguntam se seus apps ainda abrem. Por isso as “pontes” importam: deixam máquinas novas rodarem software antigo tempo suficiente para o ecossistema se adaptar.
Emulação vs tradução: mantendo apps antigos vivos
Emulação imita uma CPU inteira em software. É a opção mais compatível, mas geralmente a mais lenta porque cada instrução é “encenada” em vez de executada diretamente.
Tradução binária (frequentemente dinâmica) reescreve pedaços de código x86 para as instruções nativas da nova CPU enquanto o programa roda. É assim que muitas transições modernas entregam uma história de dia‑um: instale seus apps existentes, e uma camada de compatibilidade traduz na surdina.
O valor é simples: você pode comprar hardware novo sem esperar que todo fornecedor recompile.
Por que nunca é perfeito
Camadas de compatibilidade funcionam melhor para apps mainstream bem comportados—e têm dificuldades nas bordas:
- Penhascos de desempenho: uma carga pode ir bem até atingir SIMD pesado, compiladores JIT ou loops apertados que traduzem mal.
- Casos de borda: proteção de cópia, suposições de temporização de baixo nível ou código auto‑modificante podem quebrar.
- Drivers e componentes de kernel: você pode traduzir um app, mas não dá para “traduzir” um driver de impressora ausente ou uma extensão de kernel legada.
Suporte de hardware costuma ser o bloqueador real.
Virtualização: ponte parcial para software empresarial
Virtualização ajuda quando você precisa de um ambiente legado inteiro (uma versão específica do Windows, um stack Java antigo, um app de negócios). É operacionalmente limpa—snapshots, isolamento, rollback fácil—mas depende do que você virtualiza.
VMs de mesma arquitetura podem ser quase nativas; VMs entre arquiteturas geralmente recorrem à emulação e ficam lentas.
Quando “bom o suficiente” é realmente suficiente?
Uma ponte costuma bastar para apps de escritório, navegadores e produtividade diária—onde “rápido o suficiente” vence. É mais arriscada para:
- periféricos especializados e drivers
- pipelines de áudio/vídeo de baixa latência
- computação de alto desempenho ou gráficos pesados
Na prática, pontes compram tempo—mas raramente eliminam o trabalho de migração.
Desempenho, energia e mistura de workloads
Argumentos sobre CPUs costumam soar como um placar único: “mais rápido vence”. Na realidade, plataformas vencem quando combinam com as restrições dos dispositivos e dos workloads que as pessoas realmente rodam.
x86 tornou‑se padrão em PCs em parte porque entregava alto pico de desempenho com energia na tomada, e porque a indústria construiu todo o resto em torno dessa expectativa.
Pico de desempenho vs eficiência energética
Compradores de desktop e laptop historicamente valorizam performance responsiva: abrir apps, compilar código, jogar, planilhas pesadas. Isso empurra vendedores a perseguirem clocks altos, núcleos largos e comportamento turbo agressivo—ótimo quando você pode gastar watts livremente.
Eficiência de energia é outro jogo. Se seu produto é limitado por bateria, calor, ruído de ventoinha ou um chassi fino, a melhor CPU é a que faz “trabalho suficiente por watt”, consistentemente, sem throttling.
Eficiência não é só economizar energia; é manter-se dentro de limites térmicos para que o desempenho não desabe após um minuto.
Por que mobile favoreceu outras arquiteturas
Phones e tablets vivem em envelopes de potência apertados e sempre foram sensíveis a custo em volumes massivos. Esse ambiente recompensou designs otimizados para eficiência, componentes integrados e comportamento térmico previsível.
Também criou um ecossistema onde SO, apps e silício evoluíram juntos sob suposições mobile‑first.
Servidores: maturidade e confiabilidade vencem velocidade bruta
Em datacenters, a escolha de CPU raramente é só decisão por benchmark. Operadores se importam com recursos de confiabilidade, janelas de suporte longas, firmware maduro, monitoramento e um ecossistema maduro de drivers, hypervisors e ferramentas de gestão.
Mesmo quando uma nova arquitetura parece atraente em perf/watt, o risco de surpresas operacionais pode superar o benefício.
Workloads modernos são diversos: servir web favorece alto throughput e escalonamento eficiente; bancos de dados recompensam largura de banda de memória e consistência de latência; AI desloca valor para aceleradores e stacks de software.
À medida que a mistura muda, a plataforma vencedora pode mudar também—mas só se o ecossistema ao redor conseguir acompanhar.
Ferramentas e distribuição: os gatekeepers silenciosos
Uma nova arquitetura de CPU pode ser tecnicamente excelente e ainda falhar se as ferramentas do dia a dia não facilitarem construir, distribuir e suportar software. Para a maioria das equipes, “plataforma” não é só conjunto de instruções—é todo o pipeline de entrega.
Compiladores, depuradores, profilers e bibliotecas centrais moldam comportamentos de desenvolvedores. Se os melhores compiladores, traces de pilha, sanitizadores ou ferramentas de performance chegam tarde (ou se comportam diferente), equipes hesitam em apostar releases neles.
Mesmo pequenas lacunas importam: uma biblioteca ausente, um plugin de depurador instável ou um build de CI mais lento pode transformar “podemos portar” em “não vamos este trimestre”. Quando o toolchain x86 é o padrão em IDEs, sistemas de build e templates de CI, o caminho de menor resistência puxa desenvolvedores de volta.
Distribuição é fricção, não teoria
Software chega aos usuários por convenções de empacotamento: instaladores, atualizadores, repositórios, app stores, containers e binários assinados. Uma mudança de plataforma força perguntas desconfortáveis:
- Publicamos builds separadas (x86 e ARM), um pacote “universal” ou dependemos de tradução?
- Plugins/drivers existentes ainda instalam limpos?
- Assinatura de código, notarização e atualizações automáticas são consistentes entre arquiteturas?
Se a distribuição fica confusa, custos de suporte disparam—e muitos fornecedores evitam isso.
Gestão empresarial é um portão difícil
Empresas compram plataformas que conseguem gerenciar em escala: imaging, enrollment de dispositivos, políticas, segurança de endpoint, agentes EDR, clientes VPN e relatórios de compliance. Se alguma dessas ferramentas fica atrás numa nova arquitetura, pilotos empacam.
“Funciona na minha máquina” é irrelevante se o TI não consegue implantar e proteger.
A métrica real: velocidade de envio
Desenvolvedores e TI convergem numa pergunta prática: quão rápido conseguimos enviar e suportar? Ferramentas e distribuição costumam responder isso de forma mais decisiva do que benchmarks brutos.
Uma forma prática de reduzir atrito de migração é encurtar o tempo entre ideia e build testável—especialmente ao validar o mesmo app em ambientes diferentes (x86 vs ARM, imagens de SO diferentes ou alvos de implantação distintos).
Plataformas como Koder.ai entram nesse fluxo permitindo que equipes gerem e iterem aplicações reais via interface de chat—comummente produzindo front‑ends web em React, backends em Go e bancos PostgreSQL (além de Flutter para mobile). Para trabalho de transição de plataforma, duas capacidades são especialmente relevantes:
- Prototipação rápida e rebuilds quando é preciso recriar ferramentas internas, painéis administrativos ou utilitários da “cauda longa” que não têm dono claro.
- Snapshots e rollback para testar mudanças com segurança enquanto se gerencia múltiplas arquiteturas, toolchains e ambientes de implantação.
Porque o Koder.ai suporta exportação de código‑fonte, ele também pode servir de ponte entre experimentação e um pipeline de engenharia convencional—útil quando é preciso agir rápido, mas ainda assim manter código manutenível sob seu controle.
Lições recentes das transições ARM
Veja se Koder.ai serve para você
Use o plano gratuito para avaliar Koder.ai no seu próximo protótipo ou piloto.
A entrada do ARM em laptops e desktops é um check real sobre o quão difíceis são mudanças de plataforma. No papel, a proposta é simples: melhor desempenho por watt, máquinas mais silenciosas, maior autonomia.
Na prática, o sucesso depende menos do núcleo da CPU e mais de tudo que a envolve—apps, drivers, distribuição e quem tem poder para alinhar incentivos.
Apple: controle reduz as “incógnitas”
A migração da Apple de Intel para Apple Silicon funcionou em grande parte porque a Apple controla a pilha completa: design de hardware, firmware, sistema operacional, ferramentas de desenvolvedor e canais primários de distribuição de apps.
Esse controle permitiu à empresa fazer uma quebra limpa sem esperar que dezenas de parceiros se movessem em sincronia.
Também possibilitou um período de ponte coordenado: desenvolvedores tiveram alvos claros, usuários tiveram caminhos de compatibilidade e a Apple pôde pressionar fornecedores-chave a lançar builds nativas. Mesmo quando alguns apps não eram nativos, a experiência do usuário frequentemente permaneceu aceitável porque o plano de transição foi desenhado como produto, não apenas como troca de processador.
Windows on ARM: parceiros, timing e lacunas
Windows on ARM mostra o outro lado. A Microsoft não controla totalmente o ecossistema de hardware, e PCs Windows dependem fortemente de escolhas de OEMs e de uma longa cauda de drivers.
Isso cria pontos comuns de falha:
- Drivers: impressoras, interfaces de áudio, periféricos empresariais e dispositivos “pontuais” podem bloquear a adoção.
- Lacunas de apps: algumas ferramentas profissionais chegam tarde (ou nunca), e plugins/add‑ons podem ser o bloqueador oculto.
- Timing de incentivos: OEMs não apostam forte sem demanda, mas usuários não demandam dispositivos até que a compatibilidade pareça segura.
Conclusão: vencer transições é organizacional, não só técnico
O progresso recente do ARM reforça uma lição central: controlar mais da pilha torna transições mais rápidas e menos fragmentadas.
Quando você depende de parceiros, precisa de coordenação muito forte, caminhos de upgrade claros e uma razão para que cada participante—fornecedor de chip, OEM, desenvolvedor e comprador de TI—priorize a migração ao mesmo tempo.
Transições falham por razões mundanas: a plataforma antiga ainda funciona, todo mundo já pagou por ela (em dinheiro e hábitos) e os “casos de borda” é onde os negócios reais vivem.
Sinais de que uma transição pode realmente vingar
Uma nova plataforma tende a vencer só quando três coisas se alinham:
Primeiro, o benefício é óbvio para compradores normais—não apenas engenheiros: melhor autonomia, custos materialmente menores, novos formatos ou um salto de desempenho para tarefas comuns.
Segundo, há um plano de compatibilidade crível: ótima emulação/tradução, builds “universais” fáceis e caminhos claros para drivers, periféricos e ferramentas empresariais.
Terceiro, incentivos se alinham na cadeia: fornecedor do SO, do chip, OEMs e desenvolvedores veem vantagem e têm motivo para priorizar a migração.
Como empresas reduzem o risco
Transições bem‑sucedidas parecem menos um interruptor e mais sobreposição controlada. Rollouts em fases (grupos piloto primeiro), builds duais (antigo + novo) e telemetria (taxas de crash, desempenho, uso de recursos) permitem pegar problemas cedo.
Igualmente importante: janela de suporte publicada para a plataforma antiga, prazos internos claros e um plano para usuários que “não podem se mover ainda”.
Checklist prático antes de trocar
- Teste seus apps críticos (incluindo plugins e macros), não apenas o software principal.
- Valide periféricos e drivers: docks, impressoras, scanners, interfaces de áudio, chaves de segurança.
- Confirme segurança e gestão: criptografia de disco, EDR, VPN, gerenciamento de dispositivos e políticas de compliance.
- Faça testes de desempenho que reflitam seu workload (tempos de build, exportações de vídeo, análise de dados), além de bateria e térmicos.
Visão equilibrada
x86 ainda tem um ímpeto massivo: décadas de compatibilidade, fluxos de trabalho empresariais entrincheirados e uma ampla variedade de hardware.
Mas a pressão aumenta por novas necessidades—eficiência energética, integração mais estreita, computação focada em AI e frotas de dispositivos mais simples. As batalhas mais difíceis não são sobre velocidade bruta; são sobre fazer a troca parecer segura, previsível e que valha a pena.