Joe Armstrong e Erlang: Deixe Falhar para Plataformas Confiáveis
Explore como Joe Armstrong moldou a concorrência do Erlang, supervisão e a filosofia “deixe falhar” — ideias ainda usadas para construir serviços em tempo real confiáveis.
O que este post aborda (e por que ainda importa)
Joe Armstrong não só ajudou a criar o Erlang — ele se tornou seu explicador mais claro e persuasivo. Através de palestras, artigos e um ponto de vista pragmático, ele popularizou uma ideia simples: se você quer software que fique no ar, projete para a falha em vez de fingir que pode evitá-la.
Este post é um tour guiado pela mentalidade Erlang e por que ela ainda é relevante quando você está construindo plataformas em tempo real confiáveis — coisas como sistemas de chat, roteamento de chamadas, notificações ao vivo, coordenação multiplayer e infraestrutura que precisa responder rápido e de forma consistente mesmo quando partes se comportam mal.
“Tempo real” em termos simples
Tempo real nem sempre significa “microssegundos” ou “prazos rígidos”. Em muitos produtos quer dizer:
- respostas rápidas que o usuário percebe (sem pausas misteriosas)
- comportamento previsível sob carga (pode ficar mais lento, mas não deve entrar em espiral)
- serviço contínuo durante falhas parciais (um componente ruim não deve derrubar tudo)
O Erlang foi criado para sistemas de telecom onde essas expectativas eram inegociáveis — e essa pressão moldou suas ideias mais influentes.
Os três pilares em que vamos focar
Em vez de mergulhar na sintaxe, vamos focar nos conceitos que tornaram o Erlang famoso e que reaparecem no design de sistemas modernos:
- Concorrência por padrão: construa software a partir de muitos pequenos trabalhadores isolados em vez de poucos gigantes.
- Tolerância a falhas como objetivo de projeto: assuma que bugs, timeouts e crashes acontecerão — e planeje o que deve acontecer em seguida.
- “Deixe falhar”: não tente defender cada linha de código; falhe rápido e recupere de forma limpa usando estrutura (não heroísmo).
Ao longo do caminho, conectaremos essas ideias ao modelo de atores e passagem de mensagens, explicaremos árvores de supervisão e OTP em termos acessíveis, e mostraremos por que a BEAM torna toda a abordagem prática.
Mesmo que você não use Erlang (e nunca venha a usar), o ponto permanece: o enquadramento de Armstrong lhe dá uma checklist poderosa para construir sistemas que se mantêm responsivos e disponíveis quando a realidade fica bagunçada.
A motivação de Joe Armstrong: construir sistemas que ficam no ar
Comutadores de telecom e plataformas de roteamento de chamadas não podem “ficar fora do ar para manutenção” como muitos sites. Espera-se que continuem lidando com chamadas, eventos de faturamento e tráfego de sinalização 24/7 — frequentemente com requisitos rigorosos de disponibilidade e tempos de resposta previsíveis.
O Erlang começou dentro da Ericsson no final dos anos 1980 como uma tentativa de atender essas realidades com software, não apenas hardware especializado. Joe Armstrong e seus colegas não buscavam elegância por si só; tentavam construir sistemas nos quais operadores pudessem confiar sob carga constante, falhas parciais e condições do mundo real.
O que “confiável” significava na prática
Uma mudança chave de pensamento é que confiabilidade não é o mesmo que “nunca falhar”. Em sistemas grandes e de longa execução, algo vai falhar: um processo receberá uma entrada inesperada, um nó reiniciará, um link de rede oscilará, ou uma dependência travará.
Então o objetivo vira:
- continuar servindo usuários mesmo quando partes se comportam mal
- detectar falhas rapidamente
- recuperar automaticamente, com intervenção humana mínima
- isolar falhas para que um bug não derrube tudo
Essa mentalidade é a que faz ideias como árvores de supervisão e “deixe falhar” parecerem razoáveis: você projeta para a falha como evento normal, não como catástrofe excepcional.
Menos mito, mais solução de problemas
É tentador contar a história como a epifania de um visionário. A visão mais útil é mais simples: restrições de telecom forçaram um conjunto diferente de trade-offs. O Erlang priorizou concorrência, isolamento e recuperação porque essas eram as ferramentas práticas necessárias para manter serviços funcionando enquanto o mundo mudava ao redor.
Esse enquadramento orientado ao problema também explica por que as lições do Erlang ainda se traduzem bem hoje — onde disponibilidade e recuperação rápida importam mais do que prevenção perfeita.
Concorrência como padrão: muitos pequenos trabalhadores
Uma ideia central no Erlang é que “fazer muitas coisas ao mesmo tempo” não é um recurso especial que você adiciona depois — é a forma normal de estruturar um sistema.
Processos leves, explicados de forma simples
No Erlang, o trabalho é dividido em muitos pequenos “processos”. Pense neles como pequenos trabalhadores, cada um responsável por uma tarefa: atender uma chamada, gerenciar uma sessão de chat, monitorar um dispositivo, reenviar um pagamento ou observar uma fila.
Eles são leves, o que significa que você pode ter enormes quantidades deles sem precisar de hardware enorme. Em vez de um trabalhador pesado tentando fazer tudo, você tem uma multidão de trabalhadores focados que podem iniciar rápido, parar rápido e ser substituídos rápido.
Por que “um grande programa” falha de forma diferente
Muitos sistemas são projetados como um único grande programa com muitas partes fortemente conectadas. Quando esse tipo de sistema encontra um bug sério, um problema de memória ou uma operação bloqueante, a falha pode se propagar — como desligar um disjuntor e apagar todo o prédio.
O Erlang empurra na direção oposta: isole responsabilidades. Se um pequeno trabalhador se comporta mal, você pode derrubá-lo e substituí‑lo sem tirar outros trabalhos do ar.
Passagem de mensagens como “trocar bilhetes”
Como esses trabalhadores coordenam? Eles não mexem no estado interno uns dos outros. Eles enviam mensagens — mais parecido com passar bilhetes do que compartilhar um quadro bagunçado.
Um trabalhador pode dizer: “Aqui está uma nova requisição”, “Este usuário desconectou” ou “Tente de novo em 5 segundos.” O trabalhador receptor lê o bilhete e decide o que fazer.
O benefício chave é contenção: como os trabalhadores são isolados e se comunicam por mensagens, falhas têm menos probabilidade de se espalhar pelo sistema inteiro.
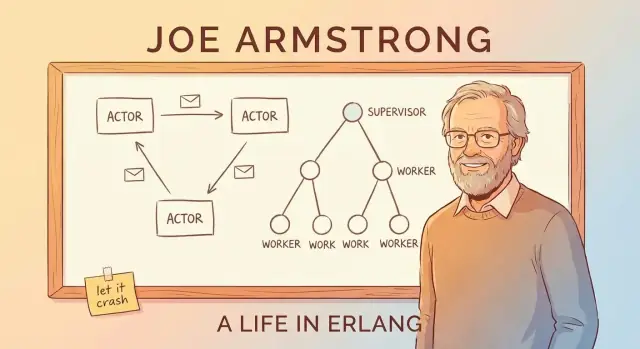
Passagem de mensagens e o modelo de atores (sem o jargão)
Uma forma simples de entender o “modelo de atores” do Erlang é imaginar um sistema feito de muitos pequenos trabalhadores independentes.
Atores: pequenos trabalhadores que só falam enviando mensagens
Um ator é uma unidade autocontida com estado privado e uma caixa postal. Ele faz três coisas básicas:
- recebe mensagens (uma por vez) da sua caixa postal
- atualiza seu próprio estado interno
- envia mensagens para outros atores
É isso. Sem variáveis compartilhadas ocultas, sem “ir na memória de outro trabalhador”. Se um ator precisa de algo de outro, ele pede enviando uma mensagem.
Por que evitar estado compartilhado remove categorias inteiras de bugs
Quando múltiplas threads compartilham os mesmos dados, surgem condições de corrida: duas coisas mudam o mesmo valor quase ao mesmo tempo e o resultado depende do tempo. É aí que bugs se tornam intermitentes e difíceis de reproduzir.
Com passagem de mensagens, cada ator é dono dos seus dados. Outros atores não podem mutá‑los diretamente. Isso não elimina todo bug, mas reduz dramaticamente problemas causados por acesso simultâneo ao mesmo pedaço de estado.
Back-pressure, explicado como fila numa cafeteria
Mensagens não chegam “de graça”. Se um ator recebe mensagens mais rápido do que processa, sua caixa postal (fila) cresce. Isso é back‑pressure: o sistema está dizendo, indiretamente, “essa parte está sobrecarregada.”
Na prática, você monitora tamanhos de mailbox e aplica limites: descarte carga, faça batch, amostre ou distribua trabalho para mais atores em vez de deixar filas crescerem indefinidamente.
Um exemplo concreto: notificações de chat
Imagine um app de chat. Cada usuário poderia ter um ator responsável por entregar notificações. Quando um usuário fica offline, mensagens continuam chegando — então a caixa postal cresce. Um sistema bem projetado pode limitar a fila, descartar notificações não críticas ou mudar para modo digest, em vez de deixar um usuário lento degradar todo o serviço.
“Deixe falhar” explicado: falhe rápido, recupere mais rápido
“Deixe falhar” não é um slogan para engenharia preguiçosa. É uma estratégia de confiabilidade: quando um componente entra num estado ruim ou inesperado, ele deve parar rápido e de forma visível em vez de arrastar-se.
O que isso realmente significa
Em vez de escrever código que tenta lidar com todo caso de borda dentro de um processo, o Erlang incentiva manter cada trabalhador pequeno e focado. Se esse trabalhador encontra algo que realmente não sabe lidar (estado corrompido, suposições violadas, entrada inesperada), ele sai. Outra parte do sistema é responsável por trazê‑lo de volta.
Isso muda a pergunta principal de “Como prevenimos a falha?” para “Como recuperamos de forma limpa quando a falha acontece?”
O tradeoff: menos checagens defensivas, lógica mais clara
Programação defensiva em toda parte pode transformar fluxos simples em um labirinto de condicionais, retries e estados parciais. “Deixe falhar” troca parte dessa complexidade interna por:
- caminhos de código mais simples e legíveis
- detecção mais rápida de suposições quebradas
- recuperação consistente (porque é centralizada)
A grande ideia é que a recuperação deve ser previsível e repetível, não improvisada dentro de cada função.
Quando isso se encaixa — e quando não se encaixa
Funciona melhor quando falhas são recuperáveis e isoladas: um problema temporário de rede, uma requisição malformada, um trabalhador travado, um timeout de terceiros.
É inadequado quando um crash pode causar dano irreversível, como:
- perda de dados sem uma fonte durável de verdade
- operações de segurança crítica onde “tentar de novo” não é aceitável
Reinícios rápidos e estado conhecido
Crash só ajuda se o retorno for rápido e seguro. Na prática, isso significa reiniciar trabalhadores em um estado conhecido — muitas vezes recarregando configuração, reconstruindo caches em memória a partir de armazenamento durável e retomando o trabalho sem fingir que o estado quebrado nunca existiu.
Árvores de supervisão: projetando para a falha de propósito
A ideia de “deixe falhar” do Erlang só funciona porque crashes não ficam ao acaso. O padrão chave é a árvore de supervisão: uma hierarquia onde supervisores são gerentes e trabalhadores fazem o trabalho real (lidar com uma chamada, gerenciar uma sessão, consumir uma fila, etc.). Quando um trabalhador se comporta mal, o gerente nota e o reinicia.
Gerentes que reiniciam trabalhadores
Um supervisor não tenta “consertar” o trabalhador quebrado in‑place. Em vez disso, aplica uma regra simples e consistente: se o trabalhador morre, inicie um novo. Isso torna o caminho de recuperação previsível e reduz a necessidade de manejo de erros espalhado pelo código.
Igualmente importante, os supervisores também decidem quando não reiniciar — se algo está crashando frequentemente, pode indicar um problema mais profundo, e reiniciar repetidamente pode piorar a situação.
Estratégias de reinício (alto nível)
Supervisão não é única para todos. Estratégias comuns incluem:
- One-for-one: só o trabalhador que falhou é reiniciado. Serve para tarefas independentes onde uma falha não deve perturbar outras.
- Reinício em grupo: se um trabalhador falha, um conjunto relacionado é reiniciado junto. Serve para componentes fortemente acoplados que precisam permanecer sincronizados.
Dependências: a parte que você precisa pensar
Bom design de supervisão começa com um mapa de dependências: quais componentes dependem de quais outros, e o que significa realmente um “arranque limpo” para eles.
Se um manipulador de sessão depende de um processo de cache, reiniciar só o manipulador pode deixá‑lo conectado a um estado ruim. Agrupar os componentes sob o supervisor certo (ou reiniciá‑los juntos) transforma modos de falha confusos em comportamento de recuperação consistente e repetível.
OTP: blocos reutilizáveis para serviços confiáveis
Se Erlang é a linguagem, OTP (Open Telecom Platform) é o kit de peças que transforma “deixe falhar” em algo que você pode rodar em produção por anos.
OTP como uma caixa de ferramentas de padrões testados
OTP não é uma única biblioteca — é um conjunto de convenções e componentes prontos (chamados de behaviours) que resolvem as partes chatas, mas críticas, de construir serviços:
gen_serverpara um trabalhador de longa duração que mantém estado e lida com requisições uma por vezsupervisorpara reiniciar automaticamente trabalhadores falhos segundo regras clarasapplicationpara definir como um serviço inteiro sobe, desce e entra numa release
Não é “mágica”. São templates com callbacks bem definidos, de modo que seu código se encaixa numa forma conhecida em vez de inventar uma nova a cada projeto.
Por que padrões padrão vencem frameworks customizados
Times costumam construir workers ad‑hoc, hooks de monitoramento caseiros e lógica de reinício única. Isso funciona — até não funcionar. O OTP reduz esse risco empurrando todos para o mesmo vocabulário e ciclo de vida. Quando um novo engenheiro entra, não precisa aprender seu framework customizado primeiro; pode confiar em padrões compartilhados e amplamente conhecidos no ecossistema Erlang.
Como o OTP orienta a arquitetura no dia a dia
OTP o incentiva a pensar em termos de papéis de processo e responsabilidades: o que é um trabalhador, o que é um coordenador, o que deve reiniciar o que, e o que nunca deve reiniciar automaticamente.
Também estimula boa higiene: nomeação clara, ordem de inicialização explícita, desligamento previsível e sinais de monitoramento embutidos. O resultado é software pensado para rodar continuamente — serviços que se recuperam de falhas, evoluem com o tempo e continuam fazendo seu trabalho sem babá humana constante.
BEAM VM: o runtime que torna o modelo prático
As grandes ideias do Erlang — processos minúsculos, passagem de mensagens e “deixe falhar” — seriam muito mais difíceis de usar em produção sem a máquina virtual BEAM. A BEAM é o runtime que torna esses padrões naturais, não frágeis.
Escalonamento: justiça em vez de “uma grande thread”
A BEAM foi construída para rodar um enorme número de processos leves. Em vez de depender de poucas threads do SO e torcer para que a aplicação se comporte, a BEAM escala os processos Erlang por conta própria.
O benefício prático é responsividade sob carga: o trabalho é fatiado em pedaços pequenos e rotacionado de forma justa, para que nenhum trabalhador ocupado domine o sistema por muito tempo. Isso se encaixa perfeitamente com um serviço composto por muitas tarefas independentes — cada uma faz um pouco de trabalho e então cede o lugar.
Isolamento e coleta de lixo por processo
Cada processo Erlang tem seu próprio heap e coleta de lixo própria. Esse é um detalhe chave: limpar memória em um processo não exige pausar o programa inteiro.
Igualmente importante, processos são isolados. Se um morre, não corrompe a memória dos outros, e a VM continua viva. Esse isolamento é a base que torna as árvores de supervisão realistas: a falha é contida e então tratada reiniciando a parte que falhou em vez de derrubar tudo.
Distribuição: vários nós, um sistema
A BEAM também suporta distribuição de forma direta: você pode rodar vários nós Erlang (instâncias separadas da VM) e fazer com que eles se comuniquem enviando mensagens. Se você entendeu “processos se comunicam por mensagens”, distribuição é uma extensão da mesma ideia — alguns processos simplesmente vivem em outro nó.
A BEAM não promete desempenho bruto máximo. Promove, sim, tornar concorrência, contenção de falhas e recuperação padrão, para que a história de confiabilidade seja prática em vez de teórica.
Atualizações sem parar (código a quente, com cuidado)
Um dos truques mais comentados do Erlang é a troca de código a quente: atualizar partes de um sistema em execução com downtime mínimo (quando o runtime e as ferramentas suportam). A promessa prática não é “nunca mais reiniciar”, mas “entregar correções sem transformar um bug breve em uma longa interrupção”.
O que ‘código a quente’ realmente significa
No Erlang/OTP, o runtime pode manter duas versões de um módulo carregadas ao mesmo tempo. Processos existentes podem terminar usando a versão antiga enquanto novas chamadas passam a usar a nova. Isso dá espaço para patchar um bug, liberar uma feature ou ajustar comportamento sem expulsar todos do sistema.
Feito bem, isso suporta objetivos de confiabilidade diretamente: menos reinícios totais, janelas de manutenção mais curtas e recuperação mais rápida quando algo escapa para produção.
Restrições que ninguém deve ignorar
Nem toda mudança é segura para trocar ao vivo. Exemplos de mudanças que exigem cuidado extra (ou reinício) incluem:
- mudanças na forma do estado (um processo espera dados em um formato, mas o novo código espera outro)
- alterações de protocolo ou formato de mensagem que precisam coincidir entre serviços
- migrações de esquema que levam tempo ou exigem coordenação
O Erlang fornece mecanismos para transições controladas, mas você ainda tem que projetar o caminho de upgrade.
A mentalidade: upgrades e rollbacks são normais
Atualizações a quente funcionam melhor quando upgrades e rollbacks são operações rotineiras, não emergências raras. Isso significa planejar versionamento, compatibilidade e um caminho claro de “desfazer” desde o início. Na prática, times combinam técnicas de upgrade ao vivo com rollouts graduais, health checks e recuperação baseada em supervisão.
Mesmo que você nunca use Erlang, a lição se transfere: projete sistemas de modo que mudar eles com segurança seja um requisito de primeira classe, não um pensamento posterior.
Onde as ideias do Erlang brilham em plataformas em tempo real
Plataformas em tempo real têm menos a ver com tempo perfeito e mais com manter responsividade enquanto coisas constantemente dão errado: redes oscilam, dependências desaceleram e picos de tráfego aparecem. O design do Erlang — defendido por Joe Armstrong — se encaixa nessa realidade porque assume falha e trata concorrência como normal, não excepcional.
Casos comuns de uso “em tempo real”
Você vê o pensamento ao estilo Erlang brilhar em lugares com muitas atividades independentes acontecendo ao mesmo tempo:
- Mensageria e chat: milhões de pequenas conversas, cada uma com seu estado e retries.
- Comunicação em tempo real: sinalização de voz/vídeo, updates de presença e coordenação de sessões.
- Coordenação de IoT: frotas de dispositivos checando, caindo e reaparecendo de forma imprevisível.
- Fluxos de pagamento: processos em múltiplas etapas onde alguns passos são lentos, indisponíveis ou precisam de ações compensatórias.
O que ‘tempo real suave’ geralmente significa
A maioria dos produtos não precisa de garantias rígidas como “toda ação completa em 10 ms”. Precisam de tempo real suave: latência consistentemente baixa para requisições típicas, recuperação rápida quando partes falham e alta disponibilidade para que usuários raramente percebam incidentes.
Falha é normal: projete para isso
Sistemas reais enfrentam problemas como:
- Conexões caídas (redes móveis, handoffs de Wi‑Fi)
- Timeouts quando um serviço downstream está lento
- Falhas parciais onde uma região ou dependência degrada
O modelo do Erlang incentiva isolar cada atividade (uma sessão de usuário, um dispositivo, uma tentativa de pagamento) para que uma falha não se espalhe. Em vez de construir um grande componente que tenta lidar com tudo, equipes podem raciocinar em unidades menores: cada trabalhador faz um trabalho, fala por mensagens e, se quebrar, é reiniciado limpo.
Essa mudança — de “prevenir toda falha” para “conter e recuperar rápido” — é muitas vezes o que faz plataformas em tempo real parecerem estáveis sob pressão.
Mal-entendidos comuns e limites reais
A reputação do Erlang pode soar como uma promessa: sistemas que nunca caem porque simplesmente reiniciam. A realidade é mais prática — e mais útil. “Deixe falhar” é uma ferramenta para construir serviços confiáveis, não licença para ignorar problemas difíceis.
Reinícios não são um band‑aid
Um erro comum é tratar supervisão como forma de esconder bugs profundos. Se um processo cai imediatamente após iniciar, um supervisor pode reiniciá‑lo sem parar até você acabar com um loop de crash — queimando CPU, enchendo logs e potencialmente causando um incidente maior que o bug original.
Sistemas bons adicionam backoff, limites de intensidade de reinício e comportamento claro de “desistir e escalar”. Reinícios devem restaurar operação saudável, não mascarar uma invariante quebrada.
Estado é a parte difícil
Reiniciar um processo é muitas vezes fácil; recuperar estado correto não é. Se o estado vive só em memória, você deve decidir o que significa “correto” depois de um crash:
- Deve reconstruir a partir de uma loja durável?
- Você pode reproduzir eventos com segurança (idempotência)?
- O que acontece com trabalho em voo ou atualizações parcialmente aplicadas?
Tolerância a falhas não substitui bom design de dados. Ela força você a ser explícito sobre isso.
Você ainda precisa de observabilidade
Crashes só são úteis se você puder vê‑los cedo e entendê‑los. Isso significa investir em logs, métricas e tracing — não apenas “reiniciou, então está tudo bem.” Você quer notar taxas de reinício crescentes, filas crescendo e dependências lentas antes que usuários sintam.
Limites operacionais reais existem
Mesmo com as forças da BEAM, sistemas falham de maneiras muito ordinárias:
- Crescimento de memória por leaks, caches ou heaps grandes
- Backlog de mailbox quando produtores superam consumidores (picos de latência e timeouts)
- Falhas de dependência (bancos, APIs de terceiros, DNS) onde reiniciar seu código não resolve a causa raiz
O modelo do Erlang ajuda a conter e recuperar falhas — mas não pode eliminá‑las.
Como aplicar as lições hoje (mesmo sem usar Erlang)
O maior legado do Erlang não é sintaxe — são hábitos para construir serviços que seguem no ar quando partes inevitavelmente falham. Você pode aplicar esses hábitos em quase qualquer stack.
Traduza ideias em ações concretas
Comece tornando limites de falha explícitos. Quebre seu sistema em componentes que possam falhar de forma independente e garanta que cada um tenha um contrato claro (entradas, saídas e o que é “ruim”).
Então automatize a recuperação em vez de tentar prevenir todo erro:
- Isole componentes: rode trabalho arriscado em processos/containers/threads separados para que um crash não envenene tudo.
- Defina limites: timeouts, retries com backoff, circuit breakers e bulkheads para parar falhas em cascata.
- Torne recuperação rotineira: health checks, reinícios automáticos e defaults seguros para que o sistema volte a um estado conhecido rapidamente.
Uma forma prática de tornar esses hábitos reais é incorporá‑los nas ferramentas e no ciclo de vida, não só no código. Por exemplo, quando times usam Koder.ai para vibe‑codar web, backend ou apps móveis via chat, o fluxo naturalmente incentiva planejamento explícito (Planning Mode), deploys repetíveis e iteração segura com snapshots e rollback — conceitos alinhados com a mesma mentalidade operacional que o Erlang popularizou: assuma que mudança e falha vão acontecer e torne recuperação algo entediante.
Pontos de partida fora do Erlang
Você pode aproximar padrões de “supervisão” com ferramentas que já usa:
- Supervisores: systemd, Deployments do Kubernetes ou um process manager (restart-on-failure, readiness probes).
- Isolamento de processo: serviços trabalhadores separados para tarefas pesadas em CPU ou não confiáveis.
- Passagem de mensagens: filas/streams (RabbitMQ, SQS, Kafka) para desacoplar produtores e consumidores e amortecer picos.
Checklist rápido de decisão
Antes de copiar padrões, decida o que você realmente precisa:
- Modos de falha esperados: sobrecarga, falhas parciais, dependências lentas, inputs ruins, memory leaks.
- Necessidades de latência: você exige respostas em tempo real ou processamento eventual é suficiente?
- Objetivo de recuperação: reinício rápido, degradação graciosa ou intervenção manual?
- Habilidades e ferramentas do time: quem vai ser on‑call, cuidar de observabilidade e resposta a incidentes?
Se quiser próximos passos práticos, veja mais guias em /blog, ou navegue por detalhes de implementação em /docs (e planos em /pricing se estiver avaliando ferramentas).
Perguntas frequentes
Por que a mentalidade de Joe Armstrong sobre Erlang ainda é relevante hoje?
O Erlang popularizou uma mentalidade prática de confiabilidade: assuma que partes vão falhar e projete o que acontece em seguida.
Em vez de tentar prevenir toda queda, enfatiza isolamento de falhas, detecção rápida e recuperação automática, o que se aplica bem a plataformas em tempo real como chat, roteamento de chamadas, notificações e serviços de coordenação.
O que ‘tempo real’ significa, nas palavras simples do post?
Neste contexto, “tempo real” geralmente significa tempo real suave:
- respostas que parecem rápidas e consistentes
- comportamento previsível sob carga
- o sistema continua funcionando durante falhas parciais
É menos sobre prazos de microssegundos e mais sobre evitar travamentos, espirais e falhas em cascata.
O que significa 'concorrência por padrão' no design ao estilo Erlang?
Concorrência por padrão significa estruturar o sistema como muitos pequenos trabalhadores isolados em vez de alguns componentes grandes e fortemente acoplados.
Cada trabalhador trata uma responsabilidade estreita (uma sessão, dispositivo, chamada, loop de retry), o que facilita escalabilidade e contenção de falhas.
O que são 'processos leves' do Erlang e por que eles importam?
Processos leves são pequenos trabalhadores independentes que você pode criar em grande número.
Na prática, ajudam porque:
- você pode modelar um processo por 'coisa' (usuário/sessão/dispositivo)
- falhas ficam locais a um único trabalhador
- reiniciar trabalho é barato comparado a reiniciar um monólito
Por que o Erlang prefere passagem de mensagens em vez de estado compartilhado?
Passagem de mensagens é coordenação por enviar mensagens em vez de compartilhar estado mutável.
Isso reduz classes inteiras de bugs de concorrência (como condições de corrida), porque cada trabalhador é dono do seu estado interno; outros só podem pedir mudanças indiretamente via mensagens.
O que é back-pressure num sistema de atores/mensagens e como lidar com isso?
Back-pressure ocorre quando um trabalhador recebe mensagens mais rápido do que consegue processar, fazendo sua caixa postal (mailbox) crescer.
Maneiras práticas de lidar com isso incluem:
- monitorar tamanhos de mailbox/filas
- aplicar limites (descartar, amostrar ou limitar)
- espalhar carga entre mais trabalhadores
- degradar de forma graciosa (por exemplo, trocar por digests para notificações não críticas)
O que ‘deixe falhar’ realmente significa (e o que não significa)?
“Deixe falhar” quer dizer: se um trabalhador chega a um estado inválido ou inesperado, ele deve falhar rápido em vez de se arrastar.
A recuperação é tratada estruturalmente (via supervisão), o que gera rotas de código mais simples e recuperação mais previsível—desde que os reinícios sejam seguros e rápidos.
O que são árvores de supervisão e por que são centrais para a tolerância a falhas?
Uma árvore de supervisão é uma hierarquia onde supervisores monitoram trabalhadores e os reiniciam segundo regras definidas.
Em vez de espalhar recuperação ad-hoc, você centraliza:
- decidir o que reinicia quando algo falha
- prevenir loops de crash sem fim com limites/backoff
- reiniciar grupos juntos quando componentes precisam permanecer sincronizados
O que é OTP e como ajuda a construir serviços confiáveis?
OTP é o conjunto de padrões (behaviours) e convenções que tornam sistemas Erlang operáveis a longo prazo.
Blocos comuns incluem:
gen_serverpara trabalhadores de longa duração com estadosupervisorpara políticas de reinícioapplicationpara definir como um serviço sobe, desce e entra numa release
A vantagem é ciclos de vida compartilhados e bem compreendidos em vez de frameworks ad-hoc.
Como posso aplicar as lições do Erlang se não estiver usando Erlang?
Você pode aplicar os mesmos princípios em outras stacks tornando falha e recuperação prioridades:
- isole trabalho arriscado (processos/serviços/containers separados)
- adote timeouts, retries com backoff, circuit breakers e bulkheads
- automatize recuperação (health checks + restart-on-failure)
- use filas/streams para desacoplar produtores e consumidores
Para mais, o post aponta para guias em /blog e detalhes de implementação em /docs.