18 de ago. de 2025·8 min
LLVM de Chris Lattner: O motor silencioso por trás das cadeias de ferramentas modernas
Saiba como o LLVM de Chris Lattner se tornou a plataforma modular de compilador por trás de linguagens e ferramentas — impulsionando otimizações, melhores diagnósticos e builds rápidos.
O que é o LLVM, em linguagem simples
O LLVM pode ser pensado como a “sala das máquinas” que muitos compiladores e ferramentas de desenvolvimento compartilham.
Quando você escreve código em uma linguagem como C, Swift ou Rust, algo precisa traduzir esse código em instruções que a CPU consegue executar. Um compilador tradicional muitas vezes construía toda essa pipeline internamente. O LLVM adota uma abordagem diferente: fornece um núcleo reutilizável e de alta qualidade que cuida das partes difíceis e custosas — otimização, análise e geração de código para muitos tipos de processadores.
Uma base compartilhada para muitas linguagens
O LLVM raramente é um compilador único que você “usa diretamente”. É uma infraestrutura de compilador: blocos de construção que equipes de linguagem podem montar numa toolchain. Uma equipe pode concentrar-se em sintaxe, semântica e recursos voltados ao desenvolvedor, e então delegar o trabalho pesado ao LLVM.
Essa base compartilhada é uma grande razão pela qual linguagens modernas conseguem lançar toolchains seguros e rápidos sem reinventar décadas de trabalho em compiladores.
Por que importa mesmo se você não é da área de compiladores
O LLVM aparece na experiência quotidiana do desenvolvedor:
- Velocidade: converte código de alto nível em código de máquina eficiente em várias plataformas.
- Melhores erros e depuração: o ecossistema em torno do LLVM possibilita diagnósticos mais ricos e ferramentas melhores.
- Mais que “só compilação”: análise estática, sanitizadores, cobertura de código e outros auxílios ao desenvolvedor frequentemente usam a mesma representação e bibliotecas subjacentes.
O que este artigo será (e o que não será)
Esta é uma visita guiada pelas ideias que Chris Lattner colocou em movimento: como o LLVM é estruturado, por que a camada intermediária importa e como ela permite otimizações e suporte multiplataforma. Não é um livro-texto — vamos focar em intuição e impacto no mundo real, não em teoria formal.
A visão original de Chris Lattner
Chris Lattner é um cientista da computação e engenheiro que, ainda estudante de pós-graduação no início dos anos 2000, iniciou o LLVM a partir de uma frustração prática: a tecnologia de compiladores era poderosa, mas difícil de reutilizar. Se você queria uma nova linguagem, melhores otimizações ou suporte a um novo processador, muitas vezes tinha de mexer num compilador monolítico onde toda mudança causava efeitos colaterais.
O problema que ele quis resolver
Na época, muitos compiladores eram construídos como máquinas grandes e únicas: a parte que entendia a linguagem, a parte que otimizava e a parte que gerava código de máquina estavam profundamente entrelaçadas. Isso os tornava eficazes para seu propósito original, mas caros de adaptar.
O objetivo de Lattner não era “um compilador para uma linguagem só”. Era uma fundação compartilhada que pudesse alimentar muitas linguagens e ferramentas — sem que todo mundo reescrevesse as mesmas partes complexas repetidamente. A aposta era: se você padronizar o meio da pipeline, pode inovar mais rápido nas extremidades.
Por que “infraestrutura modular” foi uma ideia nova
A mudança chave foi tratar a compilação como um conjunto de blocos separáveis com limites claros. Em um mundo modular:
- uma equipe de linguagem pode focar em parsing e recursos para o desenvolvedor,
- uma equipe de otimização pode melhorar performance uma vez e compartilhar amplamente,
- suporte a hardware pode ser adicionado sem redesenhar tudo a montante.
Essa separação soa óbvia hoje, mas ia contra a forma como muitos compiladores de produção haviam evoluído.
Código aberto, feito para ser usado por outros
O LLVM foi lançado como código aberto cedo, o que importou porque uma infraestrutura só funciona se vários grupos puderem confiar nela, inspecioná-la e estendê-la. Ao longo do tempo, universidades, empresas e contribuintes independentes moldaram o projeto adicionando alvos, corrigindo casos de canto, melhorando desempenho e construindo novas ferramentas ao redor.
O aspecto comunitário não foi apenas boa vontade — fazia parte do desenho: torne o núcleo amplamente útil, e vale a pena mantê-lo em conjunto.
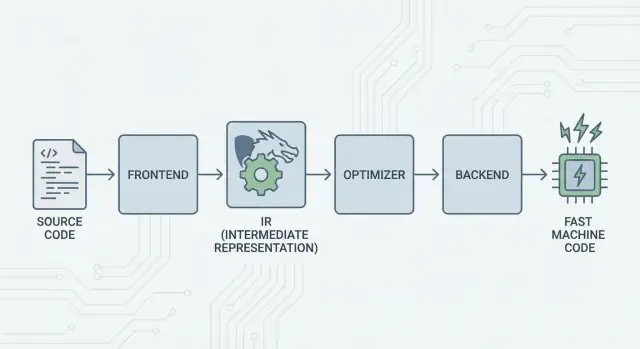
A grande ideia: frontends, um núcleo compartilhado e backends
A ideia central do LLVM é simples: dividir um compilador em três grandes peças para que muitas linguagens possam compartilhar o trabalho mais difícil.
1) Frontends: “O que o programador quis dizer?”
Um frontend entende uma linguagem específica. Ele lê seu código-fonte, verifica regras (sintaxe e tipos) e o transforma numa representação estruturada.
O ponto-chave: frontends não precisam conhecer todos os detalhes da CPU. A função deles é traduzir conceitos da linguagem — funções, laços, variáveis — para algo mais universal.
2) O meio compartilhado: um núcleo comum em vez de N×M trabalho
Tradicionalmente, construir um compilador significava repetir o mesmo trabalho:
- Com N linguagens e M alvos de processador, você acaba com N×M combinações a suportar.
O LLVM reduz isso para:
- N frontends que traduzem para uma forma compartilhada
- M backends que traduzem dessa forma compartilhada para código de máquina
Essa “forma compartilhada” é o centro do LLVM: um pipeline comum onde residem otimizações e análises. Isso simplifica muito. Melhorias no meio (como melhores otimizações ou informação de depuração) beneficiam muitas linguagens de uma vez, em vez de serem reimplementadas em cada compilador.
3) Backends: “Como fazemos isso rodar rápido nessa CPU?”
Um backend pega a representação compartilhada e produz saída específica da máquina: instruções para x86, ARM e assim por diante. É aqui que detalhes como registradores, convenções de chamada e seleção de instruções importam.
Uma imagem intuitiva da pipeline
Pense na compilação como uma rota de viagem:
- Código-fonte começa num país específico da linguagem (frontend).
- Ele cruza a fronteira para uma “linguagem do meio” padronizada (o núcleo do LLVM e suas passes).
- Depois usa um sistema local de trem até uma cidade de destino específica (backend para sua máquina alvo).
O resultado é uma toolchain modular: linguagens podem focar em expressar ideias claramente, enquanto o núcleo compartilhado do LLVM foca em fazer essas ideias rodarem eficientemente em muitas plataformas.
LLVM IR: a camada intermediária que permite reutilização
LLVM IR (Intermediate Representation) é a “língua comum” que fica entre uma linguagem de programação e o código de máquina que sua CPU executa.
Um frontend (como o Clang para C/C++) traduz seu código-fonte para essa forma compartilhada. Então os otimizadores e geradores de código do LLVM trabalham sobre o IR, e por fim um backend converte o IR em instruções para um alvo específico (x86, ARM etc.).
Uma linguagem comum entre ferramentas e CPUs
Pense no LLVM IR como uma ponte cuidadosamente desenhada:
- Acima dele: muitas linguagens de origem podem se conectar (C, C++, Rust, Swift, Julia etc.).
- Abaixo dele: muitos processadores podem ser alvo.
- No meio: as mesmas ferramentas de análise e otimização podem ser reutilizadas.
Por isso as pessoas costumam descrever LLVM como “infraestrutura de compilador” e não apenas “um compilador”. O IR é o contrato compartilhado que torna essa infraestrutura reutilizável.
Por que o IR permite reutilização (e economiza trabalho)
Uma vez que o código está em LLVM IR, a maior parte das passes de otimização não precisa saber se ele veio de templates C++, iteradores Rust ou genéricos Swift. Elas se importam principalmente com ideias universais como:
- “Esse valor é constante.”
- “Essa computação se repete; podemos reutilizar o resultado?”
- “Esse acesso à memória pode ser movido ou removido com segurança.”
Assim, equipes de linguagem não precisam construir (e manter) sua própria pilha completa de otimizações. Podem focar no frontend — parsing, verificação de tipos e regras específicas — e delegar o trabalho pesado ao LLVM.
Como é, conceitualmente
O LLVM IR é baixo nível o bastante para mapear bem ao código de máquina, mas ainda estruturado o suficiente para análise. Conceitualmente, é composto por instruções simples (add, compare, load/store), fluxo de controle explícito (branches) e valores fortemente tipados — mais parecido com uma assembly organizada para compiladores do que algo que humanos normalmente escrevem.
Como as otimizações funcionam (sem a matemática)
Quando se fala em “otimizações de compilador”, muitas pessoas imaginam truques misteriosos. No LLVM, a maior parte das otimizações é melhor entendida como reescritas mecânicas e seguras do programa — transformações que preservam o que o código faz, mas buscam fazê-lo mais rápido (ou menor).
Pense nisso como editar, não inventar
O LLVM pega seu código (em LLVM IR) e aplica repetidamente pequenas melhorias, muito parecido com polir um rascunho:
- Remover trabalho duplicado: se um valor é calculado duas vezes e nada mudou entre as duas, o LLVM pode calcular uma vez e reutilizar.
- Simplificar lógica óbvia: expressões constantes podem ser pré-calculadas (por exemplo, transformar
3 * 4em12), então a CPU faz menos no tempo de execução. - Racionalizar loops: passes relacionadas a loops podem reduzir verificações repetidas, mover trabalho invariante para fora do loop ou reconhecer padrões que podem ser executados de forma mais eficiente.
Essas mudanças são deliberadamente conservadoras. Uma pass só realiza uma reescrita quando consegue provar que não irá alterar o significado do programa.
Exemplos relacionáveis
Se seu programa faz, conceitualmente:
- Ler o mesmo valor de configuração a cada iteração de um laço
- Realizar o mesmo cálculo com as mesmas entradas em vários lugares
- Checar uma condição que é sempre verdadeira/falsa num dado contexto
…o LLVM tenta transformar isso em “faça a preparação uma vez”, “reutilize resultados” e “delete ramos mortos”. É menos mágica e mais organização.
O verdadeiro tradeoff: tempo de compilação vs. tempo de execução
Otimização não é grátis: mais análise e mais passes geralmente significam compilação mais lenta, mesmo se o programa final rodar mais rápido. Por isso toolchains oferecem níveis como “optimize um pouco” vs. “otimize agressivamente”.
Perfis ajudam aqui. Com otimização guiada por perfil (PGO), você executa o programa, coleta dados reais de uso e depois recompila para que o LLVM foque esforço nos caminhos que realmente importam — tornando o tradeoff mais previsível.
Backends: alcançar muitos CPUs sem reescrever tudo
Tenha o código-fonte
Mantenha controle total exportando o código-fonte quando estiver pronto para assumir o repositório.
Um compilador tem duas tarefas muito diferentes. Primeiro, entender seu código-fonte. Segundo, produzir código de máquina que um CPU específico possa executar. Os backends do LLVM concentram-se nessa segunda tarefa.
O que um backend realmente faz
Pense no LLVM IR como uma “receita universal” do que o programa deve fazer. Um backend transforma essa receita nas instruções exatas para uma família de processadores — x86-64 para a maioria de desktops e servidores, ARM64 para muitos telefones e laptops mais novos, ou alvos especializados como WebAssembly.
Concretamente, um backend é responsável por:
- Seleção de instruções: mapear operações do IR para instruções reais da CPU
- Alocação de registradores: escolher quais valores ficarão em registradores rápidos da CPU vs. memória
- Escalonamento: ordenar instruções para que a CPU possa executá-las eficientemente
- Saída de assembly/objeto: emitir código que o linker e o SO entendam
Por que infraestrutura compartilhada facilita suporte a hardware novo
Sem um núcleo compartilhado, cada linguagem precisaria reimplementar tudo isso para cada CPU que quisesse suportar — um trabalho enorme e uma manutenção constante.
O LLVM inverte isso: frontends (como o Clang) produzem LLVM IR uma vez, e backends cuidam da “média distância” por alvo. Adicionar suporte a um novo processador geralmente significa escrever um backend (ou estender um existente), não reescrever todo compilador no mundo.
Portabilidade para equipes que entregam em múltiplas plataformas
Para projetos que precisam rodar no Windows/macOS/Linux, em x86 e ARM, ou mesmo no navegador, o modelo de backend do LLVM é uma vantagem prática. Você pode manter uma base de código e em grande parte uma pipeline de build, então retargetar escolhendo um backend diferente (ou cross-compilar).
Essa portabilidade é por que o LLVM aparece em tantos lugares: não é só sobre velocidade — é também sobre evitar trabalho repetido específico por plataforma que atrasa equipes.
Clang: onde muitos desenvolvedores sentem o LLVM pela primeira vez
Clang é o frontend para C, C++ e Objective-C que se conecta ao LLVM. Se o LLVM é o motor compartilhado que pode otimizar e gerar código, o Clang é a parte que lê seus arquivos de origem, entende as regras da linguagem e converte o que você escreveu para uma forma que o LLVM consegue processar.
Por que o Clang chamou atenção
Muitos desenvolvedores não conheceram o LLVM lendo artigos acadêmicos — encontraram ele quando trocaram de compilador e o feedback melhorou significativamente.
Os diagnósticos do Clang são conhecidos por serem mais legíveis e específicos. Em vez de erros vagos, ele costuma apontar o token exato que causou o problema, mostrar a linha relevante e explicar o que esperava. Isso importa no dia a dia porque o ciclo “compilar, corrigir, repetir” fica menos frustrante.
O Clang também expõe interfaces limpas e bem documentadas (notadamente via libclang e o ecossistema de tooling do Clang). Isso facilitou a integração com editores, IDEs e outras ferramentas sem reinventar um parser C/C++.
Como aparece no fluxo diário
Quando uma ferramenta consegue analisar seu código de forma confiável, você começa a ter recursos que parecem menos edição de texto e mais trabalho com um programa estruturado:
- Navegação de código precisa (“ir para definição”, “encontrar referências”) mesmo em grandes projetos C++ com macros
- Suporte a refatoração que entende símbolos e escopos, não apenas busca-substitui
- Dicas inline e correções rápidas alimentadas por sintaxe e informação de tipos reais
Por isso o Clang frequentemente é o primeiro ponto de contato com LLVM: é onde melhorias práticas na experiência do desenvolvedor surgem. Mesmo sem pensar em LLVM IR ou backends, você se beneficia quando o autocomplete do seu editor fica mais inteligente, as checagens estáticas são mais precisas e os erros de build são mais fáceis de resolver.
Por que muitas linguagens modernas se baseiam no LLVM
O LLVM atrai equipes de linguagem por uma razão simples: permite que foquem na linguagem em vez de passar anos reinventando um compilador otimizado.
Tempo de lançamento mais rápido
Criar uma nova linguagem já envolve parsing, checagem de tipos, diagnósticos, ferramentas de pacote, documentação e suporte à comunidade. Se você também precisa criar um otimizador de produção, gerador de código e suporte de plataforma do zero, o lançamento atrasa — às vezes anos.
O LLVM fornece um núcleo de compilação pronto: alocação de registradores, seleção de instruções, passes de otimização maduras e alvos para CPUs comuns. Equipes podem plugar um frontend que reduza sua linguagem para LLVM IR e depois contar com a pipeline existente para produzir código nativo para macOS, Linux e Windows.
Alto desempenho (sem “heroísmos”)
O otimizador e os backends do LLVM são resultado de engenharia de longo prazo e testes constantes em cenários reais. Isso se traduz em uma boa base de desempenho para linguagens que o adotam — frequentemente suficiente desde o início e passível de melhoria conforme o LLVM evolui.
Por isso várias linguagens conhecidas se construíram sobre ele:
- Swift usa LLVM para gerar binários nativos otimizados nas plataformas Apple.
- Rust depende do LLVM para geração de código e muitos alvos de arquitetura.
- Julia usa LLVM para permitir código numérico rápido, inclusive compilação em tempo de execução para cargas especializadas.
Nem toda linguagem precisa de LLVM
Escolher LLVM é um tradeoff, não uma obrigação. Algumas linguagens priorizam binários mínimos, compilação ultra-rápida ou controle total sobre a toolchain. Outras já têm compiladores estabelecidos (como ecossistemas baseados em GCC) ou preferem backends mais simples.
O LLVM é popular porque é um bom padrão — não porque seja o único caminho válido.
JIT e compilação em tempo de execução: loops de feedback rápidos
Use seu domínio
Coloque seu app em um domínio personalizado quando for hora de compartilhar.
“Just-in-time” (JIT) é mais fácil de entender como compilar enquanto você roda. Em vez de traduzir tudo antecipadamente para um executável final, um motor JIT espera até que um pedaço de código seja realmente necessário e então compila essa parte na hora — frequentemente usando informação de tempo de execução (como tipos e tamanhos exatos) para fazer escolhas melhores.
Por que o JIT pode parecer tão rápido
Porque você não precisa compilar tudo antes, sistemas JIT podem entregar feedback rápido para trabalho interativo. Você escreve ou gera um trecho de código, executa imediatamente e o sistema compila só o que é necessário agora. Se esse mesmo código rodar repetidamente, o JIT pode armazenar em cache o resultado compilado ou recompilar trechos “quentes” de forma mais agressiva.
Onde compilação em tempo de execução ajuda na prática
JIT brilha quando cargas de trabalho são dinâmicas ou interativas:
- REPLs e notebooks: avalie trechos instantaneamente e ainda obtenha execução em velocidade nativa para loops pesados.
- Plugins e extensões: aplicações podem carregar código do usuário em runtime e compilá-lo para combinar com a CPU hospedeira.
- Cargas dinâmicas: quando entradas variam muito, profile em tempo de execução pode guiar quais caminhos merecem otimização.
- Computação científica: kernels gerados (para um tamanho de matriz específico, formato de modelo ou recurso de hardware) podem ser compilados sob demanda.
O papel do LLVM (sem hype)
O LLVM não faz todo programa ficar mais rápido automaticamente, nem é um JIT completo por si só. O que fornece é um kit de ferramentas: um IR bem definido, um conjunto grande de passes de otimização e geração de código para muitas CPUs. Projetos podem construir motores JIT sobre esses blocos, escolhendo o tradeoff certo entre tempo de inicialização, desempenho máximo e complexidade.
Desempenho, previsibilidade e tradeoffs no mundo real
Toolchains baseados em LLVM podem produzir código extremamente rápido — mas “rápido” não é uma propriedade única e estável. Depende da versão do compilador, do CPU alvo, das configurações de otimização e até do que você pede ao compilador para assumir sobre o programa.
Por que “mesma origem, resultados diferentes” acontece
Dois compiladores podem ler o mesmo código-fonte e ainda assim gerar código de máquina visivelmente diferente. Parte disso é intencional: cada compilador tem seu conjunto de passes de otimização, heurísticas e configurações padrão. Mesmo dentro do LLVM, Clang 15 e Clang 18 podem tomar decisões diferentes de inline, vetorizar laços distintos ou escalonar instruções de forma diferente.
Também pode ser causado por comportamento indefinido e comportamento não especificado na linguagem. Se seu programa acidentalmente depende de algo que o padrão não garante (como overflow de inteiro com sinal em C), compiladores diferentes — ou flags diferentes — podem “otimizar” de formas que alteram resultados.
Determinismo, builds de depuração e builds de release
Pessoas costumam esperar determinismo na compilação: mesmas entradas, mesmas saídas. Na prática, você chega perto, mas nem sempre obtém binários idênticos entre ambientes. Caminhos de build, timestamps, ordem de link, dados de PGO e opções de LTO podem afetar o artefato final.
A distinção prática maior é depurar vs release. Builds de depuração tipicamente desabilitam muitas otimizações para preservar depuração passo-a-passo e rastros de pilha legíveis. Builds de release habilitam transformações agressivas que podem reordenar código, inline funções e remover variáveis — ótimo para performance, mas às vezes mais difícil de depurar.
Conselho prático: meça, não chute
Trate desempenho como um problema de medição:
- Faça benchmark em hardware representativo e com datasets realistas.
- Aqueça caches e execute múltiplas iterações.
- Compare builds com flags explícitas (por exemplo, mudar
-O2vs-O3, ativar/desativar LTO ou selecionar um alvo com-march).
Pequenas mudanças de flag podem deslocar desempenho em qualquer direção. O fluxo de trabalho mais seguro é: formule uma hipótese, meça e mantenha benchmarks próximos do que seus usuários realmente rodam.
Ferramentas além da compilação: análise, depuração e segurança
Construa pelo chat
Transforme uma ideia em um app funcional com um chat simples, sem precisar configurar ferramentas.
O LLVM costuma ser descrito como um kit de compilador, mas muitos desenvolvedores sentem seu impacto por meio de ferramentas que ficam ao redor da compilação: analisadores, depuradores e checagens de segurança que você ativa durante builds e testes.
Análise e instrumentação como “add-ons”
Como o LLVM expõe uma representação intermediária bem definida (IR) e uma pipeline de passes, é natural construir etapas extras que inspecionam ou reescrevem código com propósito que não seja só velocidade. Uma pass pode inserir contadores para profiling, marcar operações de memória suspeitas ou coletar dados de cobertura.
O ponto-chave é que esses recursos podem ser integrados sem que cada equipe de linguagem reescreva o mesmo encanamento.
Sanitizadores: capturando bugs perto da fonte
Clang e LLVM popularizaram uma família de runtime “sanitizadores” que instrumentam programas para detectar classes comuns de bugs durante os testes — pense acesso fora dos limites, use-after-free, condições de corrida e padrões de comportamento indefinido. Não são escudos mágicos e normalmente tornam o programa mais lento, então são usados principalmente em CI e testes pre-release. Mas quando disparam, frequentemente apontam uma localização de fonte precisa e uma explicação legível — exatamente o que equipes precisam ao caçar falhas intermitentes.
Melhores diagnósticos = onboarding mais rápido
Qualidade de tooling também é sobre comunicação. Avisos claros, mensagens de erro acionáveis e informação de depuração consistente reduzem o “fator mistério” para quem chega novo. Quando a toolchain explica o que aconteceu e como consertar, desenvolvedores gastam menos tempo decorando peculiaridades do compilador e mais tempo aprendendo a base de código.
O LLVM não garante diagnósticos perfeitos ou segurança por si só, mas fornece uma fundação comum que torna essas ferramentas voltadas ao desenvolvedor práticas de construir, manter e compartilhar.
Quando usar LLVM (e quando não usar)
Pense no LLVM como um “monte-seu-próprio kit de compilador e ferramentas”. Essa flexibilidade é justamente por que alimenta tantas toolchains modernas — mas também por que nem sempre é a resposta certa.
Quando o LLVM é uma ótima opção
O LLVM brilha quando você quer reutilizar engenharia séria de compiladores sem reinventar a roda.
Se você está construindo uma nova linguagem de programação, o LLVM pode oferecer uma pipeline de otimização comprovada, geração de código madura para muitos CPUs e um caminho para bom suporte de depuração.
Se você entrega aplicações multiplataforma, o ecossistema de backends do LLVM reduz o trabalho necessário para mirar diferentes arquiteturas. Você foca na linguagem ou lógica do produto, em vez de escrever geradores de código separados.
Se seu objetivo é ferramentas de desenvolvedor — linters, análise estática, navegação de código, refatoração — o LLVM (e o ecossistema ao redor) é uma base forte, porque o compilador já “entende” estrutura e tipos do código.
Quando pode ser exagero
O LLVM pode ser pesado se você trabalha com sistemas embarcados diminutos onde tamanho de build, memória e tempo de compilação são extremamente restritos.
Também pode ser inadequado para pipelines muito especializados onde você não quer otimizações generalistas, ou onde sua “linguagem” é mais um DSL fixo com mapeamento direto para código de máquina.
Um checklist simples
Faça três perguntas:
- Precisamos mirar múltiplas plataformas/CPUs agora ou em breve?
- Nos beneficiamos de otimizações e info de depuração já existentes, em vez de construir as nossas?
- Queremos um caminho de ecossistema (ferramentas, integrações, contratação) mais do que um compilador mínimo e customizado?
Se respondeu “sim” para a maioria, o LLVM costuma ser uma aposta prática. Se quer basicamente o compilador mais simples que resolva um problema estreito, uma abordagem mais leve pode vencer.
Uma nota prática para times de produto: benefícios do LLVM sem virar especialista em compiladores
A maioria das equipes não quer “adotar LLVM” como projeto separado. Elas querem resultados: builds multiplataforma, binários rápidos, bons diagnósticos e tooling confiável.
Por isso plataformas como Koder.ai são interessantes nesse contexto. Se seu fluxo de trabalho é cada vez mais guiado por automação de alto nível (planejamento, geração de scaffolding, iteração em loops fechados), você continua se beneficiando do LLVM indiretamente via toolchains subjacentes — seja construindo um app React, um backend Go com PostgreSQL ou um cliente móvel Flutter. A abordagem de "vibe-coding" direcionada por chat da Koder.ai foca em entregar produto mais rápido, enquanto a infraestrutura moderna de compilação (LLVM/Clang e afins, quando aplicável) continua fazendo o trabalho pouco glamouroso de otimização, diagnóstico e portabilidade nos bastidores.