O que a pesquisa instantânea no servidor deve oferecer
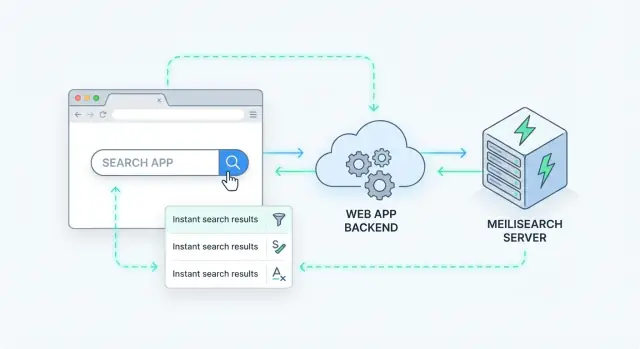
Pesquisa server-side significa que a consulta é processada no seu servidor (ou em um serviço de busca dedicado), não no navegador. Seu app envia uma requisição de busca, o servidor a executa contra um índice e retorna resultados ordenados.
Isso importa quando seu conjunto de dados é grande demais para enviar ao cliente, quando você precisa de relevância consistente entre plataformas, ou quando controle de acesso é inegociável (por exemplo, ferramentas internas onde usuários só devem ver o que lhes é permitido). Também é a escolha padrão quando você quer analytics, logs e desempenho previsível.
Pessoas não pensam em mecanismos de busca — elas avaliam a experiência. Um fluxo de busca “instantâneo” geralmente significa:
- Feedback rápido: resultados atualizam rapidamente enquanto o usuário digita, sem pausas desconfortáveis.
- Erros de digitação não atrapalham: grafias erradas, letras trocadas e palavras incompletas ainda encontram os itens certos.
- Controles úteis: filtragem (categoria, status, faixa de preço), ordenação (mais recentes, mais baratos) e facetas (contagens por filtro) parecem naturais.
- Ordenação relevante: os “melhores” resultados aparecem primeiro, não apenas os mais recentes ou os com mais palavras-chave.
Se algum desses estiver faltando, os usuários compensam tentando consultas diferentes, rolando mais, ou abandonando a busca completamente.
O que este guia ajudará você a fazer
Este artigo é um passo a passo prático para construir essa experiência com o Meilisearch. Cobriremos como configurá-lo com segurança, como estruturar e sincronizar seus dados indexados, como ajustar relevância e regras de ordenação, como adicionar filtros/ordenação/facetas e como pensar sobre segurança e escalabilidade para que a busca continue rápida conforme seu app cresce.
Onde a pesquisa server-side brilha
Meilisearch é uma boa opção para:
- Documentação e bases de conhecimento (encontre páginas rápido, tolere erros de digitação)
- Catálogos de produtos e marketplaces (filtros e ordenação são essenciais)
- Ferramentas internas (busca com permissões entre registros)
- Sites de conteúdo (buscar por artigos, guias, FAQs)
O objetivo ao longo do texto: resultados que pareçam imediatos, precisos e confiáveis — sem transformar a busca em um grande projeto de engenharia.
Visão geral do Meilisearch em linguagem simples
Meilisearch é um motor de busca que você roda ao lado do seu app. Você envia documentos (como produtos, artigos, usuários ou tickets de suporte) e ele constrói um índice otimizado para buscas rápidas. Seu backend (ou frontend) consulta o Meilisearch por uma API HTTP simples e recebe resultados ordenados em milissegundos.
O Meilisearch foca nas funcionalidades esperadas de buscas modernas:
- Tolerância a erros de digitação para que “iphnoe” ainda encontre “iPhone”.
- Controles de relevância (ranking rules) para que você decida o que significa “melhor correspondência” para seu negócio.
- Filtros, ordenação e facetas para que os usuários possam estreitar resultados por atributos como categoria, faixa de preço, disponibilidade ou tags.
É projetado para ser responsivo e tolerante, mesmo quando a consulta é curta, ligeiramente errada ou ambígua.
O que o Meilisearch não é
Meilisearch não substitui seu banco de dados primário. Seu banco continua sendo a fonte de verdade para gravações, transações e restrições. O Meilisearch armazena uma cópia dos campos que você escolhe tornar pesquisáveis, filtráveis ou exibíveis.
Um bom modelo mental é: banco de dados para armazenar e atualizar dados, Meilisearch para encontrá-los rapidamente.
Expectativas de desempenho (o que afeta a velocidade)
Meilisearch pode ser extremamente rápido, mas os resultados dependem de alguns fatores práticos:
- Tamanho e formato dos dados (número de documentos, número de campos e quanto texto você indexa)
- Hardware (CPU, RAM, disco)
- Configuração (quais atributos são pesquisáveis/filtráveis/ordenáveis e com que frequência você reindexa)
Para conjuntos pequenos a médios, muitas vezes é possível rodar em uma única máquina. À medida que o índice cresce, você precisará ser mais criterioso sobre o que indexar e como manter os dados atualizados — tópicos que cobriremos mais adiante.
Planejando seus índices e modelo de dados
Antes de instalar qualquer coisa, decida o que você realmente vai pesquisar. O Meilisearch será “instantâneo” somente se seus índices e documentos refletirem como as pessoas navegam no seu app.
Mapear entidades para índices
Comece listando suas entidades pesquisáveis — tipicamente produtos, artigos, usuários, docs de ajuda, locais, etc. Em muitos apps, a abordagem mais limpa é um índice por tipo de entidade (por exemplo, products, articles). Isso mantém regras de ordenação e filtros previsíveis.
Se sua UX faz busca entre vários tipos em uma caixa (“buscar tudo”), você ainda pode manter índices separados e mesclar resultados no backend, ou criar um índice “global” mais tarde. Não force tudo em um índice a menos que os campos e filtros realmente se alinhem.
Cada documento precisa de um identificador estável (chave primária). Escolha algo que:
- nunca mude (ou mude raramente)
- seja único dentro do índice
- já exista no seu banco (por exemplo,
id, sku, slug)
Para o formato do documento, prefira campos planos quando possível. Estruturas planas são mais fáceis de filtrar e ordenar. Campos aninhados são aceitáveis quando representam um conjunto coeso e estável (por exemplo, um objeto author), mas evite aninhamentos profundos que reflitam todo o seu esquema relacional — documentos de busca devem ser otimizados para leitura, não em formato de banco.
Classificar campos: pesquisável, filtrável, exibido
Uma maneira prática de projetar documentos é marcar cada campo com um papel:
- Searchable: texto que as pessoas digitam (title, name, description)
- Filterable: atributos usados como restrições (category, price range, status, tags)
- Displayed: o que você retorna para a UI (title, URL da thumbnail, snippet curto)
Isso evita um erro comum: indexar um campo “só por precaução” e depois se perguntar por que os resultados ficam ruidosos ou os filtros lentos.
Planejar conteúdo multilíngue
“Idioma” pode significar coisas diferentes nos seus dados:
- o idioma do documento (cada artigo tem
lang: "en")
- a localização do usuário (língua da UI)
- campos com múltiplos idiomas (nomes de produto em várias línguas)
Decida cedo se vai usar índices separados por idioma (simples e previsível) ou um único índice com campos de idioma (menos índices, mais lógica). A resposta certa depende se os usuários buscam em um idioma por vez e de como você armazena traduções.
Rodar o Meilisearch é direto, mas “seguros por padrão” exige algumas escolhas: onde você o deploya, como persistir dados e como lidar com a master key.
Opções de deployment (escolha o que você pode operar)
- Docker (mais comum): rápido para iniciar, fácil de atualizar, consistente entre ambientes. Combine com um volume persistente.
- VM ou bare metal: bom quando você já tem um pipeline Linux padrão (systemd, rotação de logs, backups).
- Hospedagem gerenciada: se sua equipe não quer manter servidores, procure um provedor gerenciado de Meilisearch ou uma plataforma que ofereça como add-on. Você troca flexibilidade por operações mais simples.
Noções básicas de ambiente: armazenamento, memória, backups, monitoramento
Armazenamento: Meilisearch grava índices em disco. Coloque o diretório de dados em armazenamento confiável e persistente (não em storage efêmero de container). Planeje capacidade para crescimento: índices podem aumentar rapidamente com campos de texto grandes e muitos atributos.
Memória: aloque RAM suficiente para manter a busca responsiva sob carga. Se notar swapping, o desempenho irá degradar.
Backups: faça backup do diretório de dados do Meilisearch (ou use snapshots no nível de storage). Teste a restauração pelo menos uma vez; um backup que não pode ser restaurado é só um arquivo.
Monitoramento: monitore CPU, RAM, uso de disco e I/O de disco. Também monitore a saúde do processo e registre erros. No mínimo, alerte se o serviço cair ou o disco estiver ficando sem espaço.
Sempre rode o Meilisearch com uma master key em qualquer coisa além de desenvolvimento local. Armazene-a em um gerenciador de segredos ou em um cofre de variáveis de ambiente criptografadas (não no Git, não em um .env em texto puro no repositório).
Exemplo (Docker):
docker run -d --name meilisearch \
-p 7700:7700 \
-v meili_data:/meili_data \
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \
getmeili/meilisearch:latest
Considere também regras de rede: vincule a uma interface privada ou restrinja o acesso de entrada para que somente seu backend possa alcançar o Meilisearch.
Checklist para a primeira inicialização
curl -s http://localhost:7700/version
Indexando documentos e mantendo-os sincronizados
Mantenha controle total do código
Tenha propriedade da base de código — exporte o código-fonte quando estiver pronto para avançar.
O indexamento no Meilisearch é assíncrono: você envia documentos, o Meilisearch enfileira uma task e só após essa task ter sucesso é que os documentos ficam pesquisáveis. Trate o indexamento como um sistema de jobs, não como uma única requisição.
Um fluxo simples de indexação (adicionar → aguardar → verificar)
- Adicione documentos (garanta que cada um tenha um id único e estável, geralmente
id).
curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_WRITE_KEY' \
--data-binary @products.json
- Aguarde a task. A resposta da API inclui um
taskUid. Faça polling até que esteja succeeded (ou failed).
curl -X GET 'http://localhost:7700/tasks/123' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
- Verifique contagens e uma busca básica. Confirme que o índice tem o número esperado de documentos e que uma consulta simples retorna resultados.
curl -X GET 'http://localhost:7700/indexes/products/stats' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
Se as contagens não baterem, não faça suposições — verifique primeiro os detalhes de erro da task.
Batching que não surpreende depois
Batching é sobre manter tasks previsíveis e recuperáveis.
- Comece com 1.000–10.000 documentos por batch, ou limite pelo tamanho do payload (para muitos apps, 5–15 MB por requisição é confortável).
- Prefira muitos batches menores em vez de um envio gigantesco; é mais fácil reenviar e localizar dados ruins.
- Se tiver mudanças frequentes, indexe continuamente em batches (por exemplo, a cada minuto) em vez de reconstruir tudo.
Atualizações vs reindexação completa
addDocuments funciona como um upsert: documentos com a mesma chave primária são atualizados, novos são inseridos. Use isso para atualizações normais.
Faça uma reindexação completa quando:
- você mudou significativamente o formato dos documentos,
- precisar recalcular campos derivados,
- seu processo de sincronização saiu do alinhamento e você quer um reset limpo.
Para remoções, chame explicitamente deleteDocument(s); caso contrário registros antigos podem permanecer.
Idempotência: reenvios seguros quando jobs falham
Indexação deve ser reenviável. O pilar é ids de documento estáveis.
- Se um upload de batch expirar, você pode reenviar o mesmo lote: upsert + ids estáveis evita duplicatas.
- Persista o
taskUid retornado junto com o id do seu batch/job, e reenvie com base no status da task.
- Se você usa fila, torne o worker seguro em “at-least-once”: duplicatas não devem causar problemas.
Dados seed para um teste rápido em pré-produção
Antes dos dados de produção, indexe um pequeno conjunto (200–500 itens) que reflita seus campos reais. Exemplo: um conjunto products com id, name, description, category, brand, price, inStock, createdAt. Isso é suficiente para validar o fluxo de tasks, contagens e comportamento de update/delete — sem esperar por uma importação massiva.
Relevância e regras de ordenação que você pode controlar
“Relevância” de busca é simplesmente: o que aparece primeiro e por quê. O Meilisearch torna isso ajustável sem que você precise construir seu próprio sistema de pontuação.
Duas configurações determinam o que o Meilisearch pode fazer com seu conteúdo:
searchableAttributes: os campos em que o Meilisearch procura quando um usuário digita uma consulta (por exemplo: title, summary, tags). A ordem importa: campos anteriores são tratados como mais importantes.displayedAttributes: os campos retornados na resposta. Isso importa para privacidade e tamanho do payload — se um campo não é exibido, ele não será enviado.
Uma base prática é tornar pesquisáveis alguns campos de alto sinal (title, texto-chave) e manter os campos exibidos apenas ao que a UI precisa.
Como as regras de ordenação afetam a ordem dos resultados
O Meilisearch ordena documentos correspondentes usando ranking rules — um pipeline de “desempates”. Conceitualmente, ele prefere:
- resultados que combinem bem com a consulta (incluindo tolerância a erros), então
- resultados onde as correspondências são mais fortes (palavras mais próximas, match em atributos mais importantes), então
- resultados que se encaixem na lógica do seu negócio (ordenação personalizada como recência ou popularidade).
Você não precisa memorizar os detalhes internos para ajustar efetivamente; você escolhe principalmente quais campos importam e quando aplicar ordenação customizada.
Objetivo: “Matches no título devem ganhar.” Coloque title primeiro:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
Objetivo: “Conteúdo mais novo deve aparecer primeiro.” Adicione um atributo ordenável e ordene na query (ou configure um ranking customizado):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
Então solicite:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
Objetivo: “Promover itens populares.” Torne popularity ordenável e ordene por ele quando apropriado.
Escolha 5–10 consultas reais dos usuários. Salve os resultados principais antes das alterações e compare depois.
Exemplo:
- Antes: consulta
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case
- Depois (título-primeiro + exatidão): consulta
"apple" → Apple iPhone case, Apple Watch band, Pineapple slicer
Se a lista “depois” refletir melhor a intenção do usuário, mantenha as configurações. Se prejudicar casos de borda, ajuste uma coisa por vez (ordem de atributos, depois regras de ordenação) para saber o que causou a mudança.
Filtros, ordenação e facetas para busca do mundo real
Uma boa caixa de busca não é só “digite palavras, obtenha correspondências.” Pessoas também querem estreitar resultados (“apenas itens disponíveis”) e ordená-los (“mais barato primeiro”). No Meilisearch, isso é feito com filters, sort e facets.
Filtros e facetas (mesma ideia, UI diferente)
Um filtro é uma regra aplicada ao conjunto de resultados. Uma faceta é o que você mostra na UI para ajudar os usuários a construir essas regras (geralmente como checkboxes ou contagens).
Exemplos práticos:
- Categoria: “Shoes”, “Jackets”, “Accessories”
- Preço: “Under $50”, “$50–$100”
- Status: “In stock”, “Backorder”, “Archived”
Assim, um usuário pode buscar “running” e depois filtrar para category = Shoes e status = in_stock. Facetas podem mostrar contagens como “Shoes (128)” e “Jackets (42)” para que os usuários entendam o que há disponível.
O Meilisearch exige que você permita explicitamente campos usados para filtragem e ordenação.
- Marque campos como filterable quando serão usados em filtros:
category, status, brand, price, created_at (se filtrar por tempo), tenant_id (se isolar clientes).
- Marque campos como sortable quando você ordenar por eles:
price, rating, created_at, popularity.
Mantenha essa lista enxuta. Tornar tudo filtrável/ordenável pode aumentar o tamanho do índice e tornar atualizações mais lentas.
Paginação e limites para manter buscas rápidas
Mesmo que você tenha 50.000 resultados, os usuários veem apenas a primeira página. Use páginas pequenas (frequentemente 20–50 resultados), defina limit sensato e pagine com offset (ou recursos de paginação mais novos, se preferir). Também limite a profundidade máxima de página no app para evitar requisições caras como “página 400”.
- Sinônimos ajudam quando palavras diferentes significam a mesma coisa (por exemplo, “hoodie” ↔ “sweatshirt”). Adicione gradualmente e revise analytics — excesso de sinônimos pode criar correspondências surpreendentes.
- Stop words removem palavras comuns (“o”, “e”). Podem reduzir ruído, mas também atrapalhar buscas exatas como nomes de banda (“The Who”, “A Team”). Customize stop words só se houver um problema claro a corrigir.
Integrando o Meilisearch no backend da sua aplicação
Leve a busca para mobile
Gere um cliente Flutter que chame seu endpoint de busca no backend de forma consistente.
Uma maneira limpa de adicionar busca server-side é tratar o Meilisearch como um serviço de dados especializado atrás da sua API. Seu app recebe uma requisição de busca, chama o Meilisearch e retorna uma resposta curada ao cliente.
Um padrão simples de backend
A maioria das equipes acaba com um fluxo assim:
- Cliente chama seu endpoint (por exemplo,
GET /api/search?q=wireless+headphones&limit=20).
- Seu backend valida entradas, aplica regras de negócio e decide qual índice consultar.
- Backend chama a Search API do Meilisearch com a query do usuário mais filtros/ordenação.
- Backend pós-processa resultados (oculta campos privados, mescla com dados do BD, aplica permissões).
- Backend retorna uma resposta com esquema estável ao cliente.
Esse padrão mantém o Meilisearch substituível e impede que o código frontend dependa de detalhes internos do índice.
Se você estiver construindo um app novo (ou reescrevendo uma ferramenta interna) e quiser esse padrão implementado rapidamente, uma plataforma de scaffolding como Koder.ai pode ajudar a gerar o fluxo completo — UI em React, backend em Go e PostgreSQL — e integrar o Meilisearch atrás de um único endpoint /api/search para que o cliente permaneça simples e suas permissões fiquem no servidor.
Consultas no frontend vs backend (e por que backend é mais seguro)
O Meilisearch suporta consultas no cliente, mas consultar via backend costuma ser mais seguro porque:
- Segredos ficam privados: você não corre risco de vazar chaves privilegiadas.
- Autorização é consistente: seu backend pode aplicar “o que este usuário pode ver” antes de retornar hits.
- Você controla a complexidade da query: limite filtros, opções de ordenação e paginação para proteger o desempenho.
Consultas no frontend ainda funcionam para dados públicos com chaves restritas, mas se houver regras de visibilidade por usuário, encaminhe a busca via servidor.
Cache de consultas populares sem quebrar a relevância
Tráfego de busca costuma ter repetições (“iphone case”, “return policy”). Adicione cache na camada da API:
- Faça cache da resposta completa por curtos períodos (por exemplo, 10–60 segundos) para tráfego anônimo.
- Normalize chaves de cache (remova espaços, lowercase, inclua filtros/ordenação).
- Invalide com cuidado: para índices que mudam rápido, mantenha TTLs curtos em vez de tentar purgar agressivamente.
Rate limiting e controles contra abuso
Trate a busca como um endpoint público:
- Aplique limites por IP ou por usuário.
- Defina
limit máximo e tamanho máximo de query.
- Considere bloqueios suaves para bots óbvios, mantendo acesso para usuários reais.
Noções básicas de segurança: chaves, controle de acesso e multi-tenancy
Meilisearch frequentemente fica “atrás” do seu app porque pode retornar dados sensíveis rapidamente. Trate-o como um banco: proteja, e exponha somente o que cada chamador deve ver.
Chaves de API: master vs scoped (privilégio mínimo)
Meilisearch tem uma master key que pode tudo: criar/excluir índices, atualizar settings e ler/gravar documentos. Mantenha-a apenas no servidor.
Para aplicações, gere chaves de API com ações limitadas e índices limitados. Um padrão comum:
- Jobs de backend: uma chave que escreve documentos e atualiza settings, mas apenas em índices específicos.
- Servidor de aplicação: uma chave read-only para buscas.
- Cliente (se necessário): uma chave muito restrita só para search com filtros rígidos.
Princípio do menor privilégio significa que uma chave vazada não pode apagar dados ou ler índices não relacionados.
Multi-tenancy: índices separados ou filtro por tenantId
Se você atende múltiplos clientes (tenants), tem duas opções principais:
1) Um índice por tenant.
Simples de raciocinar e reduz risco de acesso cruzado. Desvantagens: mais índices para gerenciar e atualizações de settings devem ser aplicadas de forma consistente.
2) Índice compartilhado + filtro por tenant.
Armazene um campo tenantId em cada documento e exija um filtro como tenantId = "t_123" em todas as buscas. Pode escalar bem, mas apenas se você garantir que toda requisição aplica o filtro (idealmente via chave scoped para que chamadores não possam removê-lo).
Evitando vazamento de dados: controle o que pode ser retornado
Mesmo que a busca esteja correta, resultados podem vazar campos que você não pretende mostrar (emails, notas internas, preços de custo). Configure o que pode ser retornado:
- Limite displayed/retrievable attributes para uma allowlist segura.
- Mantenha campos sensíveis indexados só se for absolutamente necessário — e evite retorná-los nos resultados.
Faça um teste rápido de “pior cenário”: pesquise por um termo comum e confirme que nenhum campo privado aparece.
Segurança operacional básica
- Restrinja acesso de rede: vincule ao localhost ou a uma rede privada e permita acesso somente dos seus servidores de app.
- Coloque o Meilisearch atrás de um reverse proxy se precisar de TLS e rate limiting.
- Armazene chaves em um gerenciador de segredos (não em controle de versão nem em bundles frontend) e rode rotações periódicas.
Se tiver dúvida se uma chave deve ficar no cliente, assuma “não” e mantenha a busca do lado do servidor.
Desempenho e escalabilidade sem achismos
Ajuste a relevância com confiança
Teste ajustes de ranking e reverta rapidamente com snapshots e rollback.
Meilisearch é rápido quando você observa duas cargas: indexação (escrita) e consultas (leitura). A maior parte da lentidão misteriosa é resultado de competições por CPU, RAM ou disco entre essas cargas.
Onde o desempenho geralmente engasga
Carga de indexação pode subir quando você importa grandes batches, executa atualizações frequentes ou adiciona muitos campos pesquisáveis. Indexação é background, mas consome CPU e banda de disco. Se a fila de tasks crescer, buscas podem ficar lentas mesmo sem aumento de QPS.
Carga de consulta cresce com o tráfego, mas também com recursos: mais filtros, mais facetas, conjuntos de resultados maiores e maior tolerância a erros aumentam o trabalho por requisição.
I/O de disco é o culpado silencioso. Discos lentos (ou vizinhos barulhentos em volumes compartilhados) podem transformar “instantâneo” em “eventual”. NVMe/SSD costuma ser a base em produção.
Passos práticos para escalar
Comece com um sizing simples: dê ao Meilisearch RAM suficiente para manter índices “quentes” e CPU suficiente para o QPS de pico. Depois separe preocupações:
- Se indexação atrapalha leituras, agende imports pesados fora do pico e prefira batches maiores a muitos updates pequenos.
- Adicione réplicas para alta disponibilidade e capacidade de leitura (seu app pode balancear requisições entre réplicas).
- Sharding: o Meilisearch não faz sharding distribuído automaticamente. Se você ultrapassar um nó, particione dados na aplicação (por tenant, região ou faixa temporal) em múltiplos índices ou clusters.
O que monitorar (para não chutar)
Monitore um conjunto pequeno de sinais:
- Latência de busca (p50/p95) e throughput
- Tamanho da fila de tasks / tempo de processamento de tasks (fila crescente indica indexação incapaz de acompanhar)
- CPU, RAM, uso de disco e espera de I/O
- Taxas de erro (timeouts, 4xx/5xx, tasks falhas)
Backups e planejamento de upgrades
Backups devem ser rotina, não heroicos. Use o recurso de snapshot do Meilisearch em uma agenda, armazene snapshots fora da máquina e teste restaurações periodicamente. Para upgrades, leia as release notes, faça stage em um ambiente não-prod e planeje tempo de reindexação se mudanças de versão afetarem comportamento de indexação.
Se você já utiliza snapshots/rollback da sua plataforma (por exemplo, via workflow de snapshots/rollback do Koder.ai), alinhe o rollout da busca à mesma disciplina: snapshot antes de mudanças, verifique health checks e mantenha um caminho rápido para um estado conhecido bom.
Troubleshooting e checklist prático de rollout
Mesmo com uma integração limpa, problemas de busca tendem a cair em alguns grupos repetíveis. A boa notícia: o Meilisearch oferece visibilidade suficiente (tasks, logs, settings determinísticos) para depurar rapidamente — se você seguir um método.
Problemas frequentes (e o que geralmente significam)
- “Meus filtros não funcionam”: o campo não foi adicionado a
filterableAttributes, ou os documentos armazenam o campo em forma inesperada (string vs array vs objeto aninhado).
- “Resultados estão estranhamente ordenados”: regras de ordenação, sinônimos, stop words ou falta de
sortableAttributes/rankingRules podem estar elevando itens “errados”.
- “A busca mostra dados antigos”: tasks de indexação ainda estão processando, você escreve em um índice diferente do que lê, ou seu pipeline de sync perdeu updates/deletes.
Fluxo de depuração que se mantém sensato
Comece verificando se o Meilisearch aplicou com sucesso sua última mudança.
- Inspecione o status da task: cada mudança de settings e atualização de documentos cria uma task assíncrona. Se uma task falhou, corrija isso primeiro (payloads inválidos, tipos de campo errados, documentos muito grandes).
- Use os logs com uma única pergunta em mente: “O servidor aceitou minha requisição?” depois “Ele terminou o processamento?” Evite vasculhar tudo de uma vez.
- Crie uma query minimamente reproduzível:
- Escolha um índice.
- Use uma consulta que retorne um conjunto pequeno e estável.
- Adicione restrições uma a uma:
filter, depois sort, depois facets.
Se você não consegue explicar um resultado, reduza temporariamente sua configuração: remova sinônimos, reduza ajustes de ranking e teste com um pequeno dataset. Problemas complexos de relevância são muito mais fáceis de detectar em 50 documentos do que em 5 milhões.
Estratégia de rollout: reduzir o raio de impacto
- Índice de teste primeiro: construa
your_index_v2 em paralelo, aplique settings e reproduza uma amostra de queries de produção.
- Canary rollout: roteie uma pequena porcentagem do tráfego de busca para o novo índice ou novas configurações, compare taxas de clique e “sem resultados”.
- Comportamento de fallback: decida o que os usuários veem se a busca estiver lenta ou indisponível — resultados em cache, uma query simplificada ou uma mensagem amigável de “tente novamente”. Não deixe falhas na busca quebrarem toda a página.
Checklist de próximos passos
- Verifique
filterableAttributes e sortableAttributes para que correspondam aos requisitos da UI.
- Confirme que tasks de indexação terminam com sucesso após cada deploy.
- Adicione um pequeno monitor de “saúde da busca” (latência + tasks falhas).
- Pratique um rollback: troque o tráfego de volta para o índice anterior.
Related guides: /blog (search reliability, indexing patterns, and production rollout tips).