30 de ago. de 2025·8 min
Nginx vs HAProxy: Escolhendo o Proxy Reverso Adequado
Compare Nginx e HAProxy como proxies reversos: desempenho, balanceamento de carga, TLS, observabilidade, segurança e topologias comuns para escolher o ajuste ideal.
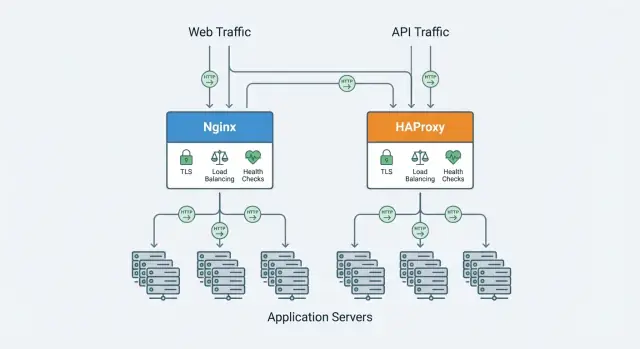
O que um Proxy Reverso Faz pelas Suas Aplicações
Um proxy reverso é um servidor que fica à frente de suas aplicações e recebe as requisições dos clientes primeiro. Ele encaminha cada requisição para o serviço de backend correto (seus servidores de aplicação) e devolve a resposta ao cliente. Usuários falam com o proxy; o proxy fala com suas aplicações.
Um proxy direto (forward proxy) funciona ao contrário: fica na frente dos clientes (por exemplo, dentro de uma rede corporativa) e encaminha suas requisições de saída para a internet. Ele serve principalmente para controlar, filtrar ou ocultar o tráfego dos clientes.
Um balanceador de carga muitas vezes é implementado como um proxy reverso, mas com foco específico: distribuir tráfego por múltiplas instâncias de backend. Muitos produtos (incluindo Nginx e HAProxy) fazem tanto proxy reverso quanto balanceamento, então os termos às vezes são usados de forma intercambiável.
Objetivos típicos para usar um proxy reverso
A maioria das implantações começa por um ou mais destes motivos:
- Terminação TLS/SSL: tratar HTTPS em um lugar só, gerenciar certificados centralmente, e encaminhar HTTP simples para serviços internos quando apropriado.
- Roteamento: enviar tráfego para serviços diferentes com base em hostname, caminho, headers ou outras regras (por exemplo,
/apipara um serviço de API,/para um app web). - Buffering e gerenciamento de conexões: suavizar clientes lentos ou upstreams lentos, reduzir overhead por conexão nos servidores de aplicação e melhorar a confiabilidade percebida.
- Controles de proteção: impor limites de requisição, filtragem básica e padrões mais seguros antes que as requisições cheguem à sua aplicação.
Onde ele se posiciona na frente das suas aplicações
Proxies reversos normalmente ficam na frente de sites, APIs e microserviços — seja na borda (internet pública) ou internamente entre serviços. Em stacks modernos, também são usados como blocos de construção para gateways de ingresso, deploys blue/green e configurações de alta disponibilidade.
O que este guia vai te ajudar a decidir
Nginx e HAProxy se sobrepõem, mas diferem na ênfase. Nas seções seguintes, vamos comparar fatores de decisão como desempenho sob muitas conexões, balanceamento de carga e health checks, suporte a protocolos (HTTP/2, TCP), recursos TLS, observabilidade e configuração/operação no dia a dia.
Visão Geral do Nginx: Pontos Fortes e Casos de Uso Típicos
Nginx é amplamente usado tanto como servidor web quanto como proxy reverso. Muitas equipes começam com ele para servir um site público e depois expandem seu papel para ficar na frente de servidores de aplicação — tratando TLS, roteando tráfego e suavizando picos.
Por que as pessoas gostam do Nginx na borda
Nginx brilha quando seu tráfego é principalmente HTTP(S) e você quer uma única “porta de entrada” que faça um pouco de tudo. Ele é especialmente forte em:
- Servir assets estáticos (imagens, CSS/JS) de forma eficiente
- Agir como proxy reverso HTTP com roteamento por caminho e host simples
- Cachear respostas para reduzir carga nos apps upstream
- Adicionar ou normalizar headers (ex.:
X-Forwarded-For, headers de segurança)
Como pode servir conteúdo e fazer proxy para apps, Nginx é uma escolha comum para setups pequenos a médios onde você quer menos peças em movimento.
Módulos e recursos que equipes costumam usar
Capacidades populares incluem:
- Terminação TLS e fluxos de trabalho para gerenciamento de certificados (frequentemente com automação em torno de reloads)
- Compressão (gzip/brotli dependendo do build) para reduzir largura de banda
- Rate limiting e controles básicos de requisição para atenuar clientes barulhentos
- Rewrites e redirects para limpeza de URLs e migrações legadas
- Recursos opcionais como proxy de WebSocket para apps em tempo real
Cenários típicos de “porta de entrada”
Nginx costuma ser escolhido quando você precisa de um ponto de entrada para:
- Um site institucional mais uma API (estático + proxy)
- Balanceamento simples entre algumas instâncias de app
- Cache na frente de backends mais lentos (ex.: CMS ou serviços REST)
- Agir como gateway para múltiplos serviços sob hostnames diferentes
Se sua prioridade é um manuseio HTTP rico e você gosta da ideia de combinar servidor web e proxy reverso, Nginx frequentemente é o ponto de partida padrão.
Visão Geral do HAProxy: Pontos Fortes e Casos de Uso Típicos
HAProxy (High Availability Proxy) é mais comumente usado como um proxy reverso e balanceador de carga que fica na frente de um ou mais servidores de aplicação. Ele aceita tráfego, aplica regras de roteamento e encaminha requisições para backends saudáveis — frequentemente mantendo tempos de resposta estáveis sob alta concorrência.
Para que o HAProxy é comumente usado
Equipes tipicamente implantam HAProxy para gerenciamento de tráfego: distribuir requisições entre servidores, manter serviços disponíveis durante falhas e suavizar picos de tráfego. É escolha frequente na “borda” de um serviço (tráfego norte–sul) e também entre serviços internos (leste–oeste), especialmente quando você precisa de comportamento previsível e forte controle sobre o gerenciamento de conexões.
Forças centrais: conexões, balanceamento e health checks
HAProxy é conhecido por manipular eficientemente um grande número de conexões concorrentes. Isso importa quando você tem muitos clientes conectados ao mesmo tempo (APIs ocupadas, conexões longas, microserviços chatos) e quer que o proxy mantenha responsividade.
Suas capacidades de balanceamento são uma grande razão para escolhê-lo. Além do round-robin simples, ele suporta vários algoritmos e estratégias que ajudam a:
- Evitar que servidores “quentes” sejam sobrecarregados
- Mover tráfego gradualmente durante rollouts
- Preferir instâncias mais rápidas ou menos carregadas quando necessário
Health checks são outro ponto forte. HAProxy pode verificar ativamente a saúde dos backends e remover automaticamente instâncias não saudáveis da rotação, readicionando-as quando se recuperam. Na prática, isso reduz downtime e evita que deploys “meio quebrados” afetem todos os usuários.
Camada 4 vs Camada 7: o que significa na prática
HAProxy pode operar em Camada 4 (TCP) e Camada 7 (HTTP).
- Camada 4 (TCP) foca no encaminhamento bruto de conexões. É ideal para protocolos onde não é necessário inspecionar detalhes HTTP — pense em serviços TCP genéricos, proxies de banco de dados, ou quando se quer overhead mínimo.
- Camada 7 (HTTP) entende a semântica HTTP, permitindo recursos como roteamento por header, regras por path e controles de tráfego mais detalhados.
A diferença prática: L4 é geralmente mais simples e muito rápido para forwarding de TCP, enquanto L7 oferece roteamento mais rico e lógica por requisição quando necessário.
Quando escolher o HAProxy
HAProxy costuma ser a escolha quando o objetivo principal é balanceamento de carga confiável e de alto desempenho com health checks robustos — por exemplo, distribuir tráfego de API entre múltiplos servidores, gerenciar failover entre zonas de disponibilidade ou frontalizar serviços onde o volume de conexões e comportamento previsível importam mais que recursos avançados de servidor web.
Fundamentos de Desempenho: Latência, Throughput e Conexões
Comparações de desempenho frequentemente falham porque as pessoas observam um único número (como “RPS máximo”) e ignoram o que os usuários realmente sentem.
Throughput vs latência vs latência nas caudas
- Throughput é quanto trabalho você consegue processar (requisições/segundo ou bytes/segundo).
- Latência é quanto tempo uma requisição leva.
- Latência nas caudas (p95/p99) é onde o problema real aparece: mesmo que a média esteja ok, os 1–5% mais lentos podem causar timeouts, retries e má experiência de usuário.
Um proxy pode aumentar o throughput enquanto ainda piora a latência nas caudas se enfileirar trabalho demais sob carga.
Padrões de conexão importam
Pense no “formato” da sua aplicação:
- Muitas requisições curtas (tráfego web típico): eficiência em aceitar conexões, handshakes TLS e parsing de requisição importa.
- Poucas conexões longas (WebSockets, streaming, gRPC, TCP parecido com banco de dados): estabilidade e uso previsível de recursos por conexão importam mais que RPS bruto.
Se você benchmarka com um padrão e implanta outro, os resultados não se transferirão.
Buffering: amigo e inimigo
O buffering pode ajudar quando clientes são lentos ou trafegos são em rajadas, porque o proxy pode ler a requisição (ou resposta) inteira e alimentar seu app de forma mais constante.
O buffering pode prejudicar quando seu app se beneficia de streaming (server-sent events, downloads grandes, APIs em tempo real). Buffer extra adiciona pressão de memória e pode aumentar latência nas caudas.
Dicas práticas para benchmark
Meça mais do que “RPS máximo”:
- RPS/throughput, p50/p95/p99 de latência e taxa de erros (timeouts, 502/503).
- Teste carga estável e picos (rajadas curtas geralmente revelam comportamento de enfileiramento).
- Use configurações realistas de keep-alive/TLS e registre CPU, memória e conexões abertas.
Se o p95 sobe muito antes de aparecerem erros, você está vendo sinais iniciais de saturação — não “headroom” livre.
Balanceamento de Carga e Health Checks Comparados
Tanto Nginx quanto HAProxy podem ficar na frente de múltiplas instâncias de aplicação e distribuir tráfego, mas diferem na profundidade do conjunto de recursos de load-balancing prontos para uso.
Algoritmos de balanceamento
Round-robin é a escolha padrão “boa o suficiente” quando seus backends são semelhantes (mesma CPU/memória, mesmo custo por requisição). É simples, previsível e funciona bem para apps stateless.
Least connections é útil quando as requisições variam em duração (downloads, chamadas longas de API, chat/WebSocket). Tende a manter servidores mais lentos menos sobrecarregados, pois favorece o backend com menos requisições ativas.
Balanceamento ponderado (round-robin com pesos, ou least connections ponderado) é a opção prática quando servidores não são idênticos — misturando nós antigos e novos, tamanhos de instância diferentes ou mudando tráfego durante uma migração.
Em geral, HAProxy oferece mais opções de algoritmo e controle fino em Camada 4/7, enquanto Nginx cobre os casos comuns de forma limpa (e pode ser estendido dependendo da edição/módulos).
Persistência de sessão (stickiness)
Stickiness mantém um usuário roteado para o mesmo backend ao longo das requisições.
- Persistência por cookie é normalmente a melhor para apps web: explícita, funciona através de NAT e permite failover controlado se o backend sumir.
- Persistência por IP de origem é fácil de habilitar, mas pode ser injusta (muitos usuários atrás de um IP só ficam no mesmo backend) e pode quebrar se a visibilidade do IP do cliente mudar (CDNs, proxies).
Use persistência só quando for necessário (sessões legadas no servidor). Apps stateless normalmente escalam e se recuperam melhor sem ela.
Health checks: ativos vs passivos
Health checks ativos sondam periodicamente os backends (endpoint HTTP, connect TCP, status esperado). Eles detectam falhas mesmo quando o tráfego é baixo.
Health checks passivos reagem ao tráfego real: timeouts, erros de conexão ou respostas ruins marcam um servidor como não saudável. São mais leves, mas podem demorar mais para detectar problemas.
HAProxy é amplamente conhecido por controles de health check e tratamento de falhas ricos (limiares, contagens de subida/descida, checks detalhados). Nginx suporta checagens sólidas também, com capacidades dependendo do build e da edição.
Deploys sem downtime: draining e retries
Para deploys rolling, procure:
- Draining de conexões: parar de enviar novas requisições para um backend, mas deixar as requisições em voo terminarem.
- Retries e redispatch: se um backend falhar durante a requisição, re-tentar com segurança (apenas para requisições idempotentes) ou enviar para outro servidor saudável.
Qualquer que seja sua escolha, combine draining com timeouts curtos e bem definidos e um endpoint de “ready/unready” para que o tráfego migre suavemente durante deploys.
Protocolos e TLS: HTTP, HTTP/2 e Proxy TCP
Teste mobile e API
Adicione um cliente Flutter à sua API e valide conexões duradouras e retentativas.
Proxies reversos ficam na borda do seu sistema, então escolhas de protocolo e TLS afetam tudo, desde performance no browser até como serviços falam entre si.
Terminação TLS e gerenciamento de certificados
Tanto Nginx quanto HAProxy podem “terminar” TLS: aceitar conexões criptografadas de clientes, descriptografar e então encaminhar requisições para suas aplicações via HTTP ou TLS recriptografado.
A realidade operacional é o gerenciamento de certificados. Você precisará de um plano para:
- Obter e renovar certs (frequentemente via ACME/Let’s Encrypt)
- Armazenar chaves privadas de forma segura e limitar quem pode acessá-las
- Recarregar configurações sem dropar conexões
Nginx é frequentemente escolhido quando a terminação TLS vem acompanhada de recursos de servidor web (arquivos estáticos, redirects). HAProxy costuma ser escolhido quando TLS faz parte principalmente de uma camada de gerenciamento de tráfego (balanceamento, manejo de conexões).
HTTP/2: desempenho e compatibilidade
HTTP/2 pode reduzir tempos de carregamento em browsers ao multiplexar múltiplas requisições sobre uma única conexão. Ambos suportam HTTP/2 no lado cliente.
Considerações chave:
- Compatibilidade do cliente: a maioria dos browsers modernos suporta HTTP/2, mas alguns clientes antigos e ferramentas automatizadas podem não.
- Suporte ao backend: é comum terminar HTTP/2 no proxy e falar HTTP/1.1 com os upstreams, pois é mais simples.
Quando proxy TCP importa
Se você precisa rotear tráfego não-HTTP (bancos de dados, SMTP, Redis, protocolos customizados), precisa de proxy TCP em vez de roteamento HTTP. HAProxy é amplamente usado para balanceamento TCP de alto desempenho com controles finos de conexão. Nginx também pode proxyar TCP (via suas capacidades stream), o que pode ser suficiente para setups de passagem simples.
Mutual TLS (mTLS)
mTLS valida ambos os lados: clientes apresentam certificados, não apenas servidores. É adequado para comunicação serviço-a-serviço, integrações com parceiros ou designs zero-trust. Qualquer um dos proxies pode impor validação de certificado cliente na borda, e muitas equipes também usam mTLS internamente entre proxy e upstreams para reduzir suposições de “rede confiável”.
Observabilidade: Logs, Métricas e Debug
Proxies reversos ficam no meio de cada requisição, então frequentemente são o melhor lugar para responder “o que aconteceu?”. Boa observabilidade significa logs consistentes, um conjunto pequeno de métricas de alto sinal e uma maneira repetível de debugar timeouts e erros de gateway.
Logs necessários: access, error e timing dos upstreams
No mínimo, mantenha access logs e error logs habilitados em produção. Para access logs, inclua timing do upstream para que você saiba se a lentidão veio do proxy ou da aplicação.
No Nginx, campos comuns são o tempo da requisição e timing do upstream (ex.: $request_time, $upstream_response_time, $upstream_status). No HAProxy, habilite o modo de log HTTP e capture campos de timing (queue/connect/response) para separar “esperando por uma vaga no backend” de “backend lento”.
Mantenha logs estruturados (JSON se possível) e adicione um request ID (de um header recebido ou gerado) para correlacionar logs do proxy com os logs da aplicação.
Métricas que você deve exportar
Quer você scrape Prometheus ou envie métricas a outro lugar, exporte um conjunto consistente:
- Requisições e códigos de resposta (2xx/4xx/5xx)
- Contadores de erro (retries, health checks falhos, 502/504)
- Latência (p50/p95/p99; idealmente proxy vs upstream)
- Conexões (ativas, enfileiradas, rejeitadas)
Nginx costuma usar o endpoint stub status ou um exporter Prometheus; HAProxy tem um endpoint de stats embutido que muitos exporters consomem.
Endpoints de health e readiness
Exponha um leve /health (processo está vivo) e /ready (consegue alcançar dependências). Use ambos em automação: health checks do balanceador, deploys e decisões de auto-scaling.
Debugando timeouts, resets, 502/504
- 502: backend recusou/fechou conexão, DNS, ou mismatch de protocolo.
- 504: proxy expirou esperando o backend.
- Resets/timeouts: verifique configurações de keep-alive, saturação do backend e comprimento de fila.
Ao diagnosticar, compare timing do proxy (connect/queue) com tempo de resposta do upstream. Se connect/queue estiver alto, adicione capacidade ou ajuste balanceamento; se o tempo do upstream estiver alto, foque na aplicação e no banco de dados.
Configuração e Operação no Dia a Dia
Ganhe créditos por conteúdo
Compartilhe o que aprendeu construindo com Koder.ai e ganhe créditos na plataforma.
Rodar um proxy reverso não é só sobre throughput de pico — é também sobre quão rápido sua equipe consegue fazer mudanças seguras às 14h (ou 2h da manhã).
Estilo de configuração e onboarding
A configuração do Nginx é baseada em diretivas e hierárquica. Ela se lê como “blocos dentro de blocos” (http → server → location), o que muitos acham acessível quando pensam em sites e rotas.
A configuração do HAProxy é mais “em pipeline”: você define frontends (o que aceitar), backends (para onde enviar) e então anexa regras (ACLs) para conectar os dois. Pode parecer mais explícito e previsível depois que você internaliza o modelo, especialmente para lógica de roteamento de tráfego.
Reloads e gerenciamento de mudanças em deploy
Nginx normalmente recarrega a config iniciando novos workers e drainando graciosaente os antigos. Isso é amigável a atualizações frequentes de rota e renovações de certificado.
HAProxy também pode fazer reloads sem interrupção, mas equipes frequentemente o tratam mais como uma “appliance”: controle de mudanças mais estrito, config versionada e coordenação cuidadosa ao executar reloads.
Validação, templates e manter DRY
Ambos suportam testes de configuração antes do reload (imprescindível para CI/CD). Na prática, você provavelmente manterá configs DRY gerando-as:
- Use templates (Helm, Ansible, Terraform ou ferramentas internas)
- Mantenha trechos compartilhados para logging, headers, timeouts e padrões de segurança
O hábito operacional chave: trate a config do proxy como código — revisada, testada e implantada como mudanças de aplicação.
Operando em escala: muitos apps, rotas e certificados
À medida que o número de serviços cresce, a dispersão de certificados e rotas se torna o verdadeiro ponto de dor. Planeje para:
- Nomeação e propriedade padrão (quem é dono de quais hostnames)
- Emissão/rotação automatizada de certificados
- Convenções claras para timeouts e retries por app
Se você espera centenas de hosts, considere centralizar padrões e gerar configs a partir de metadados de serviço em vez de editar arquivos manualmente.
Onde o Koder.ai se encaixa nesse fluxo
Se você está construindo e iterando múltiplos serviços, um proxy reverso é só uma parte do pipeline de entrega — você ainda precisa de scaffolding repetível de app, paridade de ambiente e rollouts seguros.
Koder.ai pode ajudar equipes a mover mais rápido da “ideia” para serviços rodando ao gerar React web apps, backends Go + PostgreSQL e apps móveis Flutter via fluxo de chat, além de suportar exportação de código, deploy/hosting, domínios customizados e snapshots com rollback. Na prática, isso permite prototipar uma API + frontend, deployar e então decidir se Nginx ou HAProxy é a melhor porta de entrada com base em padrões reais de tráfego em vez de suposições.
Segurança e Considerações de Hardening
Segurança raramente é sobre uma funcionalidade “mágica” — trata-se de reduzir raio de ação e apertar padrões ao redor de tráfego que você não controla totalmente.
Hardening básico (least privilege, permissões, regras de rede)
Execute o proxy com o mínimo privilégio necessário: vincule portas privilegiadas via capabilities (Linux) ou um serviço de fronting, e mantenha processos workers sem privilégios. Tranque configs e material de chaves (chaves privadas TLS, parâmetros DH) como leitura apenas pela conta de serviço.
Na camada de rede, permita inbound apenas de fontes esperadas (internet → proxy; proxy → backends). Negue acesso direto aos backends sempre que possível, assim o proxy é o ponto único para autenticação, rate limits e logging.
Rate limiting e proteção contra abuso
Nginx tem primitivas de primeira classe como limit_req / limit_conn. HAProxy tipicamente usa stick tables para rastrear taxas de requisição, conexões concorrentes ou padrões de erro e então negar, “tarp” ou desacelerar clientes abusivos.
Escolha um approach que combine com seu modelo de ameaça:
- Controle de rajadas para endpoints de login/API
- Caps de conexão para proteger workers de clientes lentos
- Bans baseados em padrões repetidos de 4xx/5xx (use com cuidado para evitar causar outages auto-infligidos)
Armadilhas de headers (X-Forwarded-For, Host)
Seja explícito sobre quais headers você confia. Aceite X-Forwarded-For (e similares) apenas de upstreams conhecidos; caso contrário, atacantes podem falsificar IPs de cliente e burlar controles baseados em IP. De modo similar, valide ou defina Host para prevenir ataques por host-header e envenenamento de cache.
Uma regra prática: o proxy deve definir headers de forwarded, não apenas repassá-los cegamente.
Padrões mais seguros contra smuggling e inputs inválidos
Request smuggling frequentemente explora parsing ambíguo (Content-Length vs Transfer-Encoding, espaços estranhos, headers mal formatados). Prefira modos de parsing HTTP estritos, rejeite headers malformados e defina limites conservadores:
- Tamanho máximo de header / contagem
- Timeouts razoáveis para headers/corpo (proteção slowloris)
- Tratamento claro para
Connection,Upgradee headers hop-by-hop
Esses controles têm sintaxe diferente entre Nginx e HAProxy, mas o resultado deve ser o mesmo: falhar fechado diante de ambiguidade e manter limites explícitos.
Padrões Comuns de Implantação (e Quando Usá-los)
Proxies reversos tendem a ser introduzidos de duas maneiras: como uma porta dedicada para uma única aplicação, ou como um gateway compartilhado na frente de muitos serviços. Ambos Nginx e HAProxy podem fazer os dois — o que importa é quanto lógica de roteamento você precisa na borda e como quer operar isso no dia a dia.
1) Uma app, um proxy (simples e previsível)
Esse padrão coloca um proxy reverso diretamente na frente de uma aplicação web única (ou um pequeno conjunto de serviços fortemente relacionados). É ótimo quando você precisa principalmente de terminação TLS, HTTP/2, compressão, cache (se usar Nginx) ou separação clara entre “internet pública” e “app privado”.
Use quando:
- Você tem um domínio de aplicação primário e um backend alvo claro.
- Quer rollbacks simples e regras de roteamento mínimas.
- Prefere configuração específica da app que pode entregar junto com a aplicação.
2) Gateway compartilhado para muitos apps (roteamento centralizado)
Aqui, um (ou um pequeno cluster) de proxies roteia tráfego para múltiplas aplicações com base em hostname, caminho, headers ou outras propriedades. Isso reduz o número de pontos de entrada públicos mas aumenta a importância do gerenciamento limpo de configuração e controle de mudanças.
Use quando:
- Você hospeda múltiplas apps (ex.:
app1.example.com,app2.example.com) e quer uma camada de ingress única. - Precisa de políticas consistentes (config TLS, redirects, rate limiting) entre serviços.
- Quer centralizar certificados e logging de acesso.
3) Blue/green e canary releases na camada do proxy
Proxies podem dividir tráfego entre a versão “antiga” e a “nova” sem mudar DNS ou código da aplicação. Uma abordagem comum é definir dois pools upstream (blue e green) ou dois backends (v1 e v2) e deslocar tráfego gradualmente.
Usos típicos:
- Blue/green: mover 100% do tráfego de blue para green quando validado.
- Canary: enviar 1–10% para a nova versão (por peso, cookie, header ou hostname canário) e então aumentar.
Isso é útil quando a sua ferramenta de deploy não faz rollouts ponderados ou quando você quer um mecanismo de rollout consistente entre equipes.
4) Alta disponibilidade: active/passive, VRRP e além
Um proxy único é um ponto único de falha. Padrões comuns de HA incluem:
- Active/passive com VRRP: dois nós de proxy compartilham um IP virtual; um é primário e o outro assume em caso de falha.
- Active/active atrás de um balanceador: múltiplos proxies recebem tráfego, frequentemente via um balanceador gerenciado por cloud ou hardware.
- Anycast (avançado): o mesmo IP é anunciado de múltiplas localidades; o roteamento manda usuários para o site saudável mais próximo.
Escolha baseado no seu ambiente: VRRP é popular em VMs/bare metal tradicionais; load balancers gerenciados costumam ser a opção mais simples na nuvem.
5) Onde CDN e WAF se encaixam
Uma cadeia típica “frente-para-trás” é: CDN (opcional) → WAF (opcional) → proxy reverso → aplicação.
- CDN reduz carga na origem e melhora latência para conteúdo estático e cacheável.
- WAF filtra requisições maliciosas antes de atingirem seu proxy/app.
- Seu proxy reverso permanece o ponto de controle para roteamento, política TLS e comportamento de saúde dos upstreams.
Se você já usa CDN/WAF, mantenha o proxy focado em entrega de aplicação e roteamento, em vez de tentar transformá-lo na sua única camada de segurança.
Kubernetes e Stacks de Aplicações Modernas
Implemente um backend com verificações de integridade
Suba um backend em Go com PostgreSQL e endpoints compatíveis com health checks e readiness.
Kubernetes muda a forma como você “frontaliza” aplicações: serviços são efêmeros, IPs mudam e decisões de roteamento frequentemente acontecem na borda do cluster via um controller de Ingress. Tanto Nginx quanto HAProxy podem se encaixar bem aqui, mas tendem a brilhar em papéis ligeiramente diferentes.
Kubernetes: opções de Ingress controller e trade-offs
- Nginx é escolha muito comum para Ingress porque o ecossistema é amplo e o modelo de configuração mapeia naturalmente para roteamento HTTP (hosts, paths, redirects, rewrites). Muitas equipes gostam quando precisam de comportamento L7 flexível.
- HAProxy é frequentemente escolhido quando você quer foco forte em comportamento de load balancing, manejo de conexões e performance previsível sob alta concorrência.
Na prática, a decisão raramente é “qual é melhor” e mais “qual se ajusta aos seus padrões de tráfego e quanto manipulação HTTP você precisa na borda”.
Usar um proxy junto com service mesh
Se você roda um service mesh (ex.: mTLS e políticas de tráfego entre serviços), ainda pode manter Nginx/HAProxy na periferia para tráfego norte–sul (internet → cluster). A malha cuida do tráfego leste–oeste (serviço a serviço). Essa divisão mantém preocupações de borda — terminação TLS, WAF/rate limiting, roteamento básico — separadas de recursos internos de confiabilidade como retries e circuit breaking.
Lidando com gRPC e conexões longas (WebSockets, SSE)
gRPC e conexões longas stressam proxies de forma diferente do que requisições HTTP curtas. Observe:
- Suporte e tuning de HTTP/2 para gRPC (timeouts, max concurrent streams).
- Timeouts de conexão e keepalives para WebSockets e Server-Sent Events.
- Comportamento de balanceamento que não quebre tráfego “sticky” conversacional quando isso importa.
Qualquer que seja a escolha, teste com durações realistas (minutos/horas), não apenas testes rápidos.
Manter configs no Git e implantar via CI/CD
Trate a config do proxy como código: mantenha no Git, valide mudanças no CI (linting, teste de config) e faça rollout via CD usando deploys controlados (canary ou blue/green). Isso torna upgrades mais seguros e fornece trilha de auditoria quando uma mudança de roteamento ou TLS afeta produção.
Checklist de Decisão: Qual Devo Escolher?
A forma mais rápida de decidir é começar pelo que você espera que o proxy faça no dia a dia: servir conteúdo, moldar tráfego HTTP, ou gerenciar conexões e lógica de balanceamento de forma estrita.
Escolha Nginx quando você precisa…
Se seu proxy é também uma “porta de entrada” web, Nginx costuma ser o default conveniente.
- Cache para reduzir carga nos upstreams (respostas de API, assets, micro-cache)
- Servir arquivos estáticos eficientemente (assets, downloads, landing pages)
- Roteamento HTTP simples (host/path, redirects, normalização de headers)
- Recursos adjacentes à app como compressão e terminação TLS direta
Escolha HAProxy quando você precisa…
Se sua prioridade é distribuição precisa de tráfego e controle sob carga, HAProxy tende a se destacar.
- Opções avançadas de balanceamento e comportamento por backend
- Controle estrito de conexões (limits, filas, timeouts afinados para alta concorrência)
- Checagens de saúde profundas e failover mais seguro para pools complexos
- Proxy Layer 4 (TCP) como caso de uso de primeira classe além do HTTP
Quando faz sentido usar os dois
Usar ambos é comum quando você quer conveniências de servidor web e balanceamento especializado:
- Nginx na borda para arquivos estáticos, cache e roteamento HTTP
- HAProxy atrás dele para distribuir tráfego entre muitas instâncias de app com políticas de conexão mais estritas
Essa separação também ajuda a dividir responsabilidades: preocupações web vs engenharia de tráfego.
Checklist rápido
Pergunte a si mesmo:
- Precisamos de cache ou servir arquivos estáticos no proxy? → Nginx
- Precisamos de limites/algoritmos de balanceamento muito específicos para proteger backends? → HAProxy
- A maior parte do tráfego é HTTP com roteamento simples? → Nginx
- Estamos balanceando serviços TCP mistos junto com HTTP? → HAProxy
- Queremos uma ferramenta só ou uma arquitetura em duas camadas (edge + balancer)? → escolha conforme
Perguntas frequentes
What’s the difference between a reverse proxy and a forward proxy?
Um proxy reverso fica na frente das suas aplicações: os clientes conectam-se ao proxy, que encaminha as requisições para o serviço de backend correto e retorna a resposta.
Um proxy direto (forward proxy) fica na frente dos clientes e controla o acesso à internet (comum em redes corporativas).
Is a load balancer the same thing as a reverse proxy?
Um balanceador de carga foca em distribuir tráfego entre múltiplas instâncias de backend. Muitos balanceadores de carga são implementados como proxies reversos, por isso os termos se sobrepõem.
Na prática, você frequentemente usa uma ferramenta (como Nginx ou HAProxy) para fazer as duas coisas: proxy reverso + balanceamento de carga.
Where should a reverse proxy sit in an architecture?
Coloque-o na fronteira onde você quer um ponto único de controle:
- Borda (internet pública → seu sistema): terminação TLS, roteamento, proteção básica e logging consistente.
- Interno (serviço → serviço): modelagem de tráfego controlada, gerenciamento de conexões e rollouts mais seguros.
O importante é evitar que clientes atinjam os backends diretamente, para que o proxy seja o ponto de controle para políticas e observabilidade.
What does “TLS/SSL termination” mean, and why is it useful?
Terminar TLS significa que o proxy lida com HTTPS: ele aceita conexões criptografadas do cliente, descriptografa e encaminha o tráfego para os upstreams via HTTP ou TLS recriptografado.
Operacionalmente, você precisa planejar:
- Emissão/renovação automatizada de certificados (frequentemente ACME/Let’s Encrypt)
- Armazenamento seguro das chaves privadas
- Reloads seguros sem derrubar conexões ativas
When is Nginx usually the better choice?
Escolha Nginx quando seu proxy também for a “porta de entrada” web:
- Servir arquivos estáticos de forma eficiente
- Cache (incluindo micro-caching) para reduzir carga nos upstreams
- Roteamento HTTP simples (host/path), redirects e normalização de headers
- Configuração centrada em HTTP conveniente para stacks web típicos
When is HAProxy usually the better choice?
Escolha HAProxy quando o gerenciamento de tráfego e previsibilidade sob carga forem prioridade:
- Lidar com muitas conexões concorrentes de forma eficiente
- Controles avançados de balanceamento de carga e algoritmos
- Health checks ricos e manipulação segura de falhas
- Proxy TCP (Camada 4) como caso de uso principal, junto com HTTP (Camada 7)
How do I choose between round-robin, least-connections, and weighted balancing?
Use round-robin para backends semelhantes e carga com custo uniforme por requisição.
Use least connections quando a duração das requisições variar (downloads, chamadas longas de API, conexões longas) para evitar sobrecarregar instâncias mais lentas.
Use variantes ponderadas quando os backends diferirem (tamanhos diversos, hardware misto, migrações graduais) para direcionar tráfego de forma intencional.
Do I need session persistence (sticky sessions), and which type is best?
Stickiness mantém um usuário roteado para o mesmo backend entre requisições.
- Prefira persistência por cookie para apps web (explícita e justa através de NAT).
- Tenha cuidado com persistência por IP de origem (muitos usuários atrás de um NAT/CDN podem cair no mesmo backend).
Evite stickiness quando possível: serviços stateless escalam e fazem failover/rollout de forma mais limpa sem ela.
How can proxy buffering affect latency and streaming workloads?
O buffering pode ajudar ao suavizar clientes lentos ou tráfegar em rajadas, fazendo com que o app veja tráfego mais estável.
Pode prejudicar quando você precisa de comportamento de streaming (SSE, WebSockets, downloads grandes), pois buffering extra aumenta pressão de memória e pode piorar a latência nas caudas.
Se seu app for orientado a streams, teste e ajuste o buffering explicitamente em vez de confiar nos padrões.
How should I troubleshoot 502/504 errors and timeouts?
Comece separando atraso do proxy do atraso do backend usando logs e métricas.
Significados comuns:
- 502: backend recusou/fechou a conexão, problemas de DNS ou incompatibilidade de protocolo.
- 504: proxy excedeu o tempo de espera aguardando o backend.
Sinais úteis a comparar: