07 de ago. de 2025·8 min
Noam Shazeer e a Arquitetura Transformer por Trás dos LLMs
Saiba como Noam Shazeer ajudou a moldar o Transformer: autoatenção, atenção multi-cabeça e por que esse projeto se tornou a espinha dorsal dos LLMs modernos.
Saiba como Noam Shazeer ajudou a moldar o Transformer: autoatenção, atenção multi-cabeça e por que esse projeto se tornou a espinha dorsal dos LLMs modernos.
Um Transformer é uma forma de ajudar computadores a entender sequências — coisas em que a ordem e o contexto importam, como frases, código ou uma série de consultas. Em vez de ler um token por vez e carregar uma memória frágil adiante, os Transformers olham para toda a sequência e decidem onde prestar atenção ao interpretar cada parte.
Essa mudança simples acabou sendo enorme. É uma razão principal pela qual os grandes modelos de linguagem modernos (LLMs) conseguem manter contexto, seguir instruções, escrever parágrafos coerentes e gerar código que referencia funções e variáveis anteriores.
Se você já usou um chatbot, um recurso de “resumir isto”, busca semântica ou um assistente de programação, você interagiu com sistemas baseados em Transformer. A mesma planta básica sustenta:
Vamos decompor as partes-chave — autoatenção, atenção multi-cabeça, codificação posicional e o bloco Transformer básico — e explicar por que esse desenho escala tão bem à medida que os modelos crescem.
Também mencionaremos variantes modernas que mantêm a ideia central, mas a ajustam por velocidade, custo ou janelas de contexto maiores.
Este é um tour de alto nível com explicações em linguagem simples e matemática mínima. O objetivo é construir intuição: o que as peças fazem, por que funcionam juntas e como isso se traduz em capacidades reais de produto.
Noam Shazeer é um pesquisador e engenheiro de IA mais conhecido como um dos coautores do artigo de 2017 “Attention Is All You Need.” Esse artigo introduziu a arquitetura Transformer, que mais tarde se tornou a base para muitos LLMs modernos. O trabalho de Shazeer faz parte de um esforço de equipe: o Transformer foi criado por um grupo de pesquisadores no Google, e é importante creditar dessa forma.
Antes do Transformer, muitos sistemas de PNL dependiam de modelos recorrentes que processavam texto passo a passo. A proposta do Transformer mostrou que era possível modelar sequências de forma eficaz sem recorrência, usando atenção como o mecanismo principal para combinar informações em uma sentença.
Essa mudança importou porque tornou o treinamento mais fácil de paralelizar (você pode processar muitos tokens ao mesmo tempo) e abriu a porta para escalar modelos e datasets de um modo que rapidamente se tornou prático para produtos reais.
A contribuição de Shazeer — junto com os demais autores — não ficou confinada a benchmarks acadêmicos. O Transformer se converteu em um módulo reutilizável que equipes podiam adaptar: trocar componentes, mudar o tamanho, ajustá-lo para tarefas e mais tarde pré-treiná-lo em larga escala.
É assim que muitos avanços viajam: um artigo introduz uma receita limpa e geral; engenheiros a refinam; empresas a operacionalizam; e, eventualmente, ela vira escolha padrão para construir funcionalidades de linguagem.
É correto dizer que Shazeer foi um contribuinte chave e coautor do artigo do Transformer. Não é correto enquadrá-lo como o inventor único. O impacto vem do desenho coletivo — e das muitas melhorias posteriores que a comunidade construiu sobre aquele roteiro original.
Antes dos Transformers, a maioria dos problemas de sequência (tradução, fala, geração de texto) era dominada por Redes Neurais Recorrentes (RNNs) e depois LSTMs (Long Short-Term Memory). A grande ideia era simples: ler o texto um token por vez, manter uma “memória” (estado oculto) e usar esse estado para prever o que vem a seguir.
Uma RNN processa uma sentença como uma cadeia. Cada passo atualiza o estado oculto com base na palavra atual e no estado anterior. LSTMs melhoraram isso adicionando portas que decidem o que manter, esquecer ou emitir — facilitando reter sinais úteis por mais tempo.
Na prática, a memória sequencial tem um gargalo: muita informação precisa ser comprimida em um único estado à medida que a sentença cresce. Mesmo com LSTMs, sinais de palavras muito anteriores podem desaparecer ou ser sobrescritos.
Isso tornava certas relações difíceis de aprender de forma confiável — como ligar um pronome ao substantivo correto muitas palavras antes, ou acompanhar um tópico ao longo de várias cláusulas.
RNNs e LSTMs também são lentos para treinar porque não podem paralelizar totalmente no tempo. Você pode agrupar diferentes sentenças em batch, mas dentro de uma sentença, o passo 50 depende do 49, que depende do 48, e assim por diante.
Essa computação passo-a-passo vira uma limitação séria quando você quer modelos maiores, mais dados e experimentação mais rápida.
Pesquisadores precisavam de um desenho que pudesse relacionar palavras entre si sem marchar estritamente da esquerda para a direita durante o treinamento — uma forma de modelar relações de longa distância diretamente e tirar melhor proveito do hardware moderno. Essa pressão preparou o terreno para a abordagem focada em atenção apresentada em Attention Is All You Need.
Atenção é a forma do modelo perguntar: “Quais outras palavras devo olhar agora para entender esta palavra?” Em vez de ler uma sentença estritamente da esquerda para a direita e torcer para que a memória segure, atenção permite que o modelo espiem as partes mais relevantes da sentença no momento em que precisa.
Um modelo mental útil é um pequeno motor de busca rodando dentro da sentença.
Assim, o modelo forma uma query para a posição atual, compara-a com as keys de todas as posições e então recupera uma mistura de values.
Essas comparações produzem pontuações de relevância: sinais de “quão relacionado está isso?”. O modelo então as transforma em pesos de atenção, que são proporções que somam 1.
Se uma palavra for muito relevante, ela recebe maior fatia do foco do modelo. Se várias palavras importarem, a atenção pode se espalhar entre elas.
Pense: “Maria disse a Jenna que ela ligaria mais tarde.”
Para interpretar ela, o modelo deve olhar para candidatas como “Maria” e “Jenna.” A atenção atribui maior peso ao nome que melhor se encaixa no contexto.
Ou considere: “As chaves do armário estão faltando.” A atenção ajuda a ligar “estão” a “chaves” (o sujeito real), não a “armário”, mesmo que “armário” esteja mais perto. Esse é o benefício central: atenção conecta significado à distância, sob demanda.
Autoatenção é a ideia de que cada token em uma sequência pode olhar para outros tokens nessa mesma sequência para decidir o que importa agora. Em vez de processar palavras estritamente da esquerda para a direita (como modelos recorrentes antigos), o Transformer permite que todo token colete pistas de qualquer ponto do input.
Imagine a frase: “Eu derramei a água no copo porque ele estava vazio.” A palavra “ele” deveria conectar-se a “copo”, não a “água”. Com autoatenção, o token para “ele” atribui maior importância a tokens que ajudam a resolver seu significado (“copo”, “vazio”) e menor importância a irrelevantes.
Depois da autoatenção, cada token deixa de ser apenas ele mesmo. Torna-se uma versão ciente do contexto — uma mistura ponderada de informações de outros tokens. Você pode pensar que cada token cria um resumo personalizado da sentença inteira, ajustado ao que aquele token precisa.
Na prática, isso significa que a representação de “copo” pode carregar sinais de “derramei”, “água” e “vazio”, enquanto “vazio” pode puxar o que descreve.
Porque cada token pode calcular sua atenção sobre a sequência inteira ao mesmo tempo, o treinamento não precisa esperar que tokens anteriores sejam processados passo a passo. Essa paralelização é uma razão principal pela qual Transformers treinam de forma eficiente em grandes datasets e escalam para modelos enormes.
Autoatenção facilita conectar partes distantes do texto. Um token pode focar diretamente em uma palavra relevante distante — sem passar informação por uma longa cadeia de passos intermediários.
Esse caminho direto ajuda em tarefas como correferência (“ela”, “isso”, “eles”), acompanhar tópicos ao longo de parágrafos e lidar com instruções que dependem de detalhes anteriores.
Um único mecanismo de atenção é poderoso, mas ainda pode ser como tentar entender uma conversa vendo apenas um ângulo de câmera. Sentenças frequentemente contêm várias relações ao mesmo tempo: quem fez o quê, a que “isso” se refere, quais palavras definem o tom e qual é o tópico geral.
Quando você lê “O troféu não coube na mala porque ela era muito pequena”, pode ser necessário rastrear várias pistas ao mesmo tempo (gramática, sentido e conhecimento de mundo). Uma cabeça de atenção pode travar no substantivo mais próximo; outra pode usar a frase verbal para decidir a que “ela” se refere.
A atenção multi-cabeça executa várias contas de atenção em paralelo. Cada “cabeça” tende a olhar a sentença por uma lente diferente — muitas vezes descrita como diferentes subespaços. Na prática, isso significa que cabeças podem se especializar em padrões como:
Depois que cada cabeça produz seu conjunto de insights, o modelo não escolhe apenas um. Ele concatena as saídas das cabeças (empilhando-as lado a lado) e então as projeta de volta ao “espaço de trabalho” principal do modelo com uma camada linear aprendida.
Pense nisso como mesclar várias notas parciais em um resumo limpo que a próxima camada pode usar. O resultado é uma representação que captura muitas relações ao mesmo tempo — uma das razões pelas quais Transformers funcionam tão bem em escala.
A autoatenção é ótima para detectar relações — mas por si só não sabe quem veio primeiro. Se você embaralhar as palavras em uma sentença, uma camada de autoatenção simples pode tratar a versão embaralhada como igualmente válida, porque compara tokens sem senso de posição.
A codificação posicional resolve isso injetando informação de “onde estou na sequência?” nas representações dos tokens. Uma vez que a posição está anexada, a atenção pode aprender padrões como “a palavra logo após não importa muito” ou “o sujeito geralmente aparece antes do verbo” sem ter que inferir ordem do zero.
A ideia central é simples: cada embedding de token é combinado com um sinal de posição antes de entrar no bloco Transformer. Esse sinal de posição pode ser pensado como um conjunto extra de características que marcam um token como o 1º, 2º, 3º… no input.
Existem algumas abordagens comuns:
Escolhas posicionais podem afetar significativamente modelagem de contexto longo — coisas como resumir um relatório extenso, acompanhar entidades em vários parágrafos ou recuperar um detalhe mencionado milhares de tokens antes.
Com entradas longas, o modelo não está apenas aprendendo linguagem; está aprendendo onde olhar. Esquemas relativos e estilo rotary tendem a facilitar comparar tokens distantes e preservar padrões conforme o contexto cresce, enquanto alguns esquemas absolutos podem degradar mais rápido quando extrapolados além da janela de treinamento.
Na prática, a codificação posicional é uma daquelas decisões discretas que podem moldar se um LLM parece preciso e consistente em 2.000 tokens — e ainda coerente em 100.000.
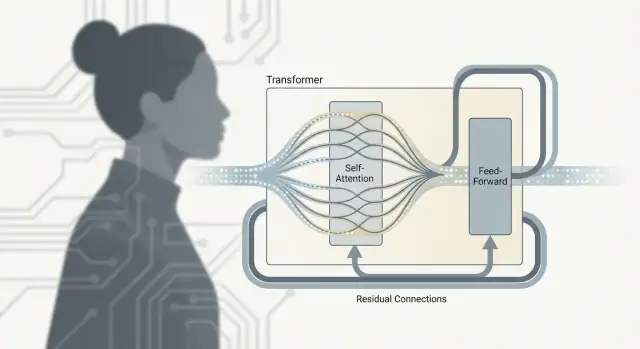
Um Transformer não é apenas “atenção”. O trabalho real acontece dentro de uma unidade repetida — frequentemente chamada de bloco Transformer — que mistura informação entre tokens e então a refina. Empilhe muitos desses blocos e você obtém a profundidade que torna os modelos de linguagem tão capazes.
A autoatenção é a etapa de comunicação: cada token recolhe contexto de outros tokens.
A rede feed-forward (FFN), também chamada MLP, é a etapa de raciocínio: pega a representação atualizada de cada token e aplica a mesma pequena rede neural independentemente.
Em termos simples, o FFN transforma e reconfigura o que cada token agora sabe, ajudando o modelo a construir features mais ricas (como padrões de sintaxe, fatos ou traços de estilo) depois de ter coletado o contexto relevante.
A alternância importa porque as duas partes fazem trabalhos diferentes:
Repetir esse padrão permite que o modelo gradualmente construa significado de nível superior: comunicar, computar, comunicar novamente, computar novamente.
Cada subcamada (atenção ou FFN) é embrulhada com uma conexão residual: a entrada é somada à saída. Isso ajuda modelos profundos a treinar porque os gradientes podem fluir pela “faixa de escape” mesmo que uma camada específica ainda esteja aprendendo. Também permite que uma camada faça ajustes pequenos em vez de ter que reaprender tudo do zero.
A normalização de camada é um estabilizador que evita que ativações cresçam ou diminuam demais à medida que passam por muitas camadas. Pense nisso como manter o volume consistente para que camadas posteriores não sejam sobrecarregadas ou privadas de sinal — tornando o treinamento mais suave e confiável, especialmente em escala de LLM.
O Transformer original em Attention Is All You Need foi construído para tradução, onde você converte uma sequência (francês) em outra (inglês). Essa tarefa naturalmente se divide em dois papéis: ler bem a entrada e escrever a saída fluentemente.
Em um Transformer codificador–decodificador, o codificador processa toda a sentença de entrada de uma vez e produz um conjunto rico de representações. O decodificador então gera a saída um token por vez.
Crucialmente, o decodificador não depende apenas de seus próprios tokens passados. Ele também usa cross-attention para olhar para a saída do codificador, ajudando a manter-se ancorado no texto fonte.
Essa configuração ainda é excelente quando você precisa condicionar fortemente em uma entrada — tradução, sumarização ou perguntas e respostas com um trecho específico.
A maioria dos modelos de linguagem modernos é apenas-decoder. Eles são treinados para uma tarefa simples e poderosa: prever o próximo token.
Para isso funcionar, usam autoatenção mascarada (causal). Cada posição pode atender apenas a tokens anteriores, não aos futuros, de forma que a geração permaneça consistente: o modelo escreve da esquerda para a direita, estendendo continuamente a sequência.
Isso domina os LLMs porque é direto treinar em corpora massivos de texto, corresponde diretamente ao caso de uso de geração e escala de forma eficiente com dados e compute.
Modelos apenas-codificador (estilo BERT) não geram texto; leem toda a entrada bidirecionalmente. Eles são ótimos para classificação, busca e embeddings — qualquer coisa em que entender um texto importa mais do que produzir uma longa continuação.
Transformers mostraram ser notavelmente amigáveis ao escalonamento: se você der mais texto, mais compute e modelos maiores, eles tendem a melhorar de forma previsível.
Uma grande razão é a simplicidade estrutural. Um Transformer é construído a partir de blocos repetidos (autoatenção + uma pequena rede feed-forward, mais normalização), e esses blocos se comportam de forma semelhante esteja você treinando em um milhão de palavras ou um trilhão.
Modelos de sequência anteriores (como RNNs) tinham que processar tokens um a um, o que limita quanto trabalho se pode fazer de uma vez. Transformers, por contraste, podem processar todos os tokens de uma sequência em paralelo durante o treinamento.
Isso os torna um ótimo ajuste para GPUs/TPUs e setups distribuídos grandes — exatamente o que você precisa ao treinar LLMs modernos.
A janela de contexto é o pedaço de texto que o modelo pode “ver” de uma vez — seu prompt mais qualquer conversa recente ou texto de documento. Uma janela maior permite que o modelo conecte ideias por mais sentenças ou páginas, acompanhe restrições e responda a perguntas que dependem de detalhes anteriores.
Mas contexto não é gratuito.
A autoatenção compara tokens entre si. À medida que a sequência fica mais longa, o número de comparações cresce rapidamente (aproximadamente com o quadrado do comprimento).
Por isso janelas de contexto muito extensas podem ser caras em memória e compute, e por isso muitos esforços modernos focam em tornar a atenção mais eficiente.
Quando Transformers são treinados em escala, eles não apenas ficam melhores numa tarefa estreita. Frequentemente começam a demonstrar capacidades amplas e flexíveis — resumir, traduzir, escrever, codificar e raciocinar — porque a mesma máquina de aprendizado geral é aplicada sobre dados massivos e variados.
O desenho original do Transformer ainda é o ponto de referência, mas a maioria dos LLMs de produção é “Transformer plus”: pequenas edições práticas que mantêm o bloco central (atenção + MLP) enquanto melhoram velocidade, estabilidade ou comprimento de contexto.
Muitas atualizações tratam menos do que o modelo é e mais de fazê-lo treinar e rodar melhor:
Essas mudanças geralmente não alteram a “essência Transformer” — elas a refinam.
Estender contexto de alguns milhares de tokens para dezenas ou centenas de milhares normalmente depende de atenção esparsa (atender só a tokens selecionados) ou variantes eficientes de atenção (aproximar ou reestruturar atenção para cortar a computação).
A troca costuma ser entre acurácia, memória e complexidade de engenharia.
Modelos MoE adicionam múltiplas sub-redes “especialistas” e roteiam cada token por apenas um subconjunto. Conceitualmente: você tem um cérebro maior, mas não ativa tudo o tempo todo.
Isso pode reduzir compute por token para uma dada contagem de parâmetros, mas aumenta a complexidade do sistema (roteamento, balanceamento de especialistas, serving).
Quando um modelo anuncia uma nova variante Transformer, peça por:
A maioria das melhorias é real — mas raramente é gratuita.
Ideias de Transformer como autoatenção e escalabilidade são fascinantes — mas equipes de produto geralmente as sentem como trade-offs: quanto texto você pode alimentar, quão rápido obtém resposta e quanto custa por requisição.
Comprimento de contexto: Maior contexto permite incluir mais documentos, histórico de chat e instruções. Também aumenta gasto em tokens e pode desacelerar respostas. Se seu recurso depende de “ler estas 30 páginas e responder”, priorize janela de contexto.
Latência: Experiências de chat e copilots dependem de tempo de resposta. Saída em streaming ajuda, mas escolha de modelo, região e batching também importam.
Custo: Preço costuma ser por token (entrada + saída). Um modelo 10% “melhor” pode custar 2–5× mais. Use comparações de preço para decidir que nível de qualidade compensa pagar.
Qualidade: Defina para seu caso de uso: acurácia factual, seguir instruções, tom, uso de ferramentas ou código. Avalie com exemplos reais do seu domínio, não só benchmarks genéricos.
Se você precisa principalmente de busca, deduplicação, clustering, recomendações ou “encontrar similar”, embeddings (frequentemente modelos estilo codificador) costumam ser mais baratos, rápidos e estáveis do que pedir geração a um chat model. Use geração apenas na etapa final (resumos, explicações, rascunhos) após recuperação.
Para uma análise mais profunda, encaminhe sua equipe para um explicador técnico como /blog/embeddings-vs-generation.
Ao transformar capacidades de Transformer em produto, o trabalho difícil geralmente é menos sobre a arquitetura e mais sobre o fluxo ao redor dela: iteração de prompts, ancoragem (grounding), avaliação e implantação segura.
Uma rota prática é usar uma plataforma de vibe-coding como Koder.ai para prototipar e lançar funcionalidades com LLMs mais rápido: você descreve o web app, endpoints do backend e modelo de dados no chat, itera em modo de planejamento e depois exporta código-fonte ou faz deploy com hosting, domínios personalizados e rollback via snapshots. Isso é especialmente útil quando você está experimentando com recuperação, embeddings ou loops de chamada de ferramentas e quer ciclos de iteração apertados sem reconstruir a mesma infraestrutura.
Um Transformer é uma arquitetura de rede neural para dados sequenciais que usa autoatenção para relacionar cada token a todos os outros no mesmo input.
Em vez de carregar informação passo a passo (como RNNs/LSTMs), ele constrói contexto decidindo o que merece atenção em toda a sequência, o que melhora o entendimento de longo alcance e torna o treinamento mais paralelizável.
RNNs e LSTMs processam texto um token por vez, o que dificulta a paralelização do treinamento e cria um gargalo para dependências de longo alcance.
Transformers usam atenção para conectar tokens distantes diretamente e podem computar muitas interações token-a-token em paralelo durante o treinamento — tornando-os mais rápidos para escalar com mais dados e compute.
Atenção é um mecanismo para responder: “Quais outros tokens importam mais para entender este token agora?”
Você pode pensar nisso como uma recuperação interna na frase:
A saída é uma mistura ponderada dos tokens relevantes, dando a cada posição uma representação sensível ao contexto.
Autoatenção significa que os tokens em uma sequência atendem a outros tokens na mesma sequência.
É a ferramenta principal que permite ao modelo resolver coisas como correferência (por exemplo, a que “isso” se refere), relações sujeito–verbo através de orações e dependências distantes no texto — sem empurrar tudo por uma única “memória” recorrente.
Atenção multi-cabeça executa várias operações de atenção em paralelo, e cada cabeça pode se especializar em padrões diferentes.
Na prática, diferentes cabeças costumam focar em relações distintas (sintaxe, vínculos de longo alcance, resolução de pronomes, sinais de tópico). O modelo então combina essas visões para representar vários tipos de estrutura ao mesmo tempo.
A autoatenção por si só não tem noção de ordem — sem informação posicional, embaralhar as palavras pode parecer similar.
Codificações posicionais injetam sinais de posição nas representações dos tokens para que o modelo aprenda padrões como “o que vem logo depois de não importa” ou estruturas típicas sujeito–verbo.
Opções comuns incluem sinusoidal (fixa), posições absolutas aprendidas e métodos relativos/rotary.
Um bloco Transformer normalmente combina:
O Transformer original é codificador–decodificador:
A maioria dos LLMs hoje são . Eles são treinados para prever o próximo token usando , o que corresponde à geração da esquerda para a direita e escala bem em grandes corpora.
Noam Shazeer foi um coautor do artigo de 2017 “Attention Is All You Need”, que introduziu o Transformer.
É correto reconhecê-lo como um contribuinte chave, mas a arquitetura foi criada por uma equipe no Google, e o impacto também vem das muitas melhorias posteriores que a comunidade e a indústria construíram sobre esse projeto original.
Para entradas longas, a autoatenção padrão fica cara porque as comparações crescem aproximadamente com o quadrado do comprimento da sequência, impactando memória e compute.
Maneiras práticas de lidar com isso incluem:
Empilhar muitos blocos gera a profundidade que possibilita recursos mais ricos e comportamento robusto em escala.