14 de out. de 2025·8 min
O que é GraphQL? Um guia claro para APIs e busca de dados
Saiba o que é GraphQL, como funcionam consultas, mutações e esquemas, e quando usá-lo em vez de REST — além de prós, contras e exemplos práticos.
Saiba o que é GraphQL, como funcionam consultas, mutações e esquemas, e quando usá-lo em vez de REST — além de prós, contras e exemplos práticos.
GraphQL é uma linguagem de consulta e um runtime para APIs. Simplificando: é uma forma de um app (web, mobile ou outro serviço) pedir dados a uma API usando uma requisição clara e estruturada — e de o servidor retornar uma resposta que corresponda a essa requisição.
Muitas APIs obrigam os clientes a aceitar o que um endpoint fixo retorna. Isso gera dois problemas comuns:
Com GraphQL, o cliente pode requisitar exatamente os campos que precisa, nem mais nem menos. Isso é especialmente útil quando telas diferentes (ou apps diferentes) precisam de “pedaços” distintos dos mesmos dados subjacentes.
GraphQL normalmente fica entre apps clientes e suas fontes de dados. Essas fontes podem ser:
O servidor GraphQL recebe uma query, decide como buscar cada campo solicitado no lugar certo e então monta a resposta JSON final.
Pense no GraphQL como pedir uma resposta em formato personalizado:
GraphQL costuma ser mal compreendido, então algumas clarificações:
Se você mantiver a definição central — linguagem de consulta + runtime para APIs — terá a base certa para entender o resto.
GraphQL foi criado para resolver um problema prático de produto: equipes gastavam muito tempo fazendo APIs se ajustarem às telas reais de UI.
APIs tradicionais baseadas em endpoints frequentemente forçam uma escolha entre enviar dados que você não precisa ou fazer chamadas extras para obter o que precisa. À medida que produtos crescem, essa fricção aparece como páginas mais lentas, código cliente mais complicado e coordenação dolorosa entre frontend e backend.
Over-fetching acontece quando um endpoint retorna um objeto “completo” mesmo que uma tela precise de poucos campos. Uma tela de perfil móvel pode precisar só de nome e avatar, mas a API retorna endereços, preferências, campos de auditoria e mais. Isso desperdiça banda e pode prejudicar a experiência.
Under-fetching é o inverso: nenhum endpoint único tem tudo que a visão precisa, então o cliente precisa fazer múltiplas requisições e montar os resultados. Isso adiciona latência e aumenta chances de falhas parciais.
Muitas APIs no estilo REST respondem a mudanças adicionando novos endpoints ou versionando (v1, v2, v3). Versionamento pode ser necessário, mas cria trabalho de manutenção de longa duração: clientes antigos continuam usando versões antigas enquanto novas features se acumulam em outros lugares.
A abordagem do GraphQL é evoluir o esquema adicionando campos e tipos ao longo do tempo, mantendo campos existentes estáveis. Isso costuma reduzir a pressão de criar “novas versões” só para suportar novas necessidades de UI.
Produtos modernos raramente têm só um consumidor. Web, iOS, Android e integrações de parceiros precisam de formas de dados diferentes.
GraphQL foi projetado para que cada cliente solicite exatamente os campos que precisa — sem que o backend precise criar um endpoint separado para cada tela ou dispositivo.
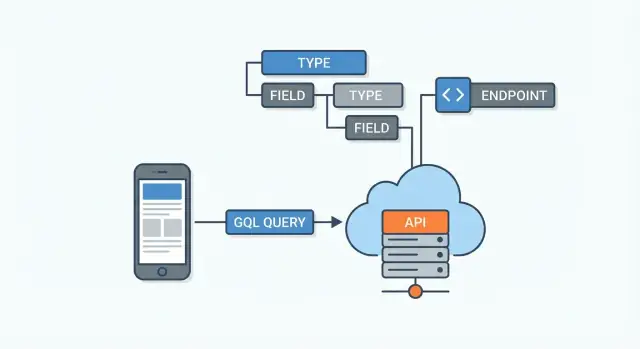
Uma API GraphQL é definida pelo seu esquema. Pense nele como o acordo entre o servidor e todos os clientes: lista quais dados existem, como estão conectados e o que pode ser pedido ou alterado. Clientes não adivinham endpoints — leem o esquema e pedem campos específicos.
O esquema é composto por tipos (como User ou Post) e campos (como name ou title). Campos podem apontar para outros tipos, e é assim que o GraphQL modela relacionamentos.
Aqui vai um exemplo simples em Schema Definition Language (SDL):
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
Como o esquema é fortemente tipado, o GraphQL pode validar uma requisição antes de executá-la. Se um cliente pede um campo que não existe (por exemplo, Post.publishDate quando o esquema não tem esse campo), o servidor pode rejeitar ou cumprir parcialmente a requisição com erros claros — sem comportamentos ambíguos de “talvez funcione”.
Esquemas são feitos para crescer. Geralmente você pode adicionar novos campos (como User.bio) sem quebrar clientes existentes, porque clientes só recebem o que pedem. Remover ou mudar campos é mais sensível, então times costumam depreciar campos antes e migrar clientes gradualmente.
Uma API GraphQL normalmente é exposta através de um endpoint único (por exemplo, /graphql). Em vez de ter muitas URLs para recursos diferentes (como /users, /users/123, /users/123/posts), você envia uma query para um único lugar e descreve exatamente os dados que quer de volta.
Uma query é basicamente uma “lista de compras” de campos. Você pode pedir campos simples (como id e name) e também dados aninhados (como posts recentes de um usuário) na mesma requisição — sem baixar campos extras que não precisa.
Aqui está um pequeno exemplo:
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
Respostas GraphQL são previsíveis: o JSON que você recebe espelha a estrutura da query. Isso facilita o trabalho no frontend, porque você não precisa adivinhar onde os dados aparecerão ou parsear formatos diferentes.
Um esboço simplificado de resposta pode ser assim:
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
Se você não pedir um campo, ele não será incluído. Se pedir, pode esperar encontrá-lo no lugar correspondente — tornando as queries GraphQL uma forma limpa de buscar exatamente o que cada tela ou feature precisa.
Queries são para leitura; mutations são como você altera dados em uma API GraphQL — criar, atualizar ou apagar registros.
A maioria das mutations segue o mesmo padrão:
input) com os campos a atualizar.Mutations geralmente retornam dados de propósito, ao invés de apenas success: true. Retornar o objeto atualizado (ou ao menos seu id e campos chave) ajuda a UI a:
Um design comum é usar um tipo “payload” que inclua tanto a entidade atualizada quanto quaisquer erros.
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
Para APIs voltadas à UI, uma boa regra é: retorne o que você precisa para renderizar o próximo estado (por exemplo, o user atualizado e quaisquer errors). Isso mantém o cliente simples, evita adivinhar o que mudou e torna falhas mais fáceis de tratar com elegância.
Um esquema GraphQL descreve o que pode ser pedido. Resolvers descrevem como de fato obter isso. Um resolver é uma função associada a um campo específico no esquema. Quando um cliente solicita esse campo, o GraphQL chama o resolver para buscar ou calcular o valor.
O GraphQL executa uma query percorrendo a forma solicitada. Para cada campo, encontra o resolver correspondente e o executa. Alguns resolvers simplesmente retornam uma propriedade de um objeto já em memória; outros chamam um banco, outro serviço ou combinam múltiplas fontes.
Por exemplo, se seu esquema tem User.posts, o resolver posts pode consultar a tabela posts por userId, ou chamar um serviço de Posts separado.
Resolvers são a cola entre o esquema e seus sistemas reais:
Esse mapeamento é flexível: você pode mudar a implementação do backend sem alterar a forma da consulta do cliente — desde que o esquema permaneça consistente.
Como resolvers podem rodar por campo e por item em uma lista, é fácil disparar muitas chamadas pequenas (por exemplo, buscar posts para 100 usuários com 100 consultas separadas). Esse padrão “N+1” pode deixar respostas lentas.
Correções comuns incluem batching e caching (por exemplo, coletar IDs e buscar em uma única consulta) e ser intencional sobre quais campos aninhados você incentiva os clientes a pedir.
Autorização costuma ser aplicada em resolvers (ou middleware compartilhado) porque os resolvers sabem quem está pedindo (via contexto) e que dado está sendo acessado. Validação ocorre em dois níveis: o GraphQL cuida de validações de tipo/forma automaticamente, enquanto resolvers impõem regras de negócio (por exemplo, “apenas admins podem definir este campo”).
Algo que surpreende quem é novo em GraphQL é que uma requisição pode “ter sucesso” e ainda incluir erros. Isso acontece porque o GraphQL é orientado a campos: se alguns campos podem ser resolvidos e outros não, você pode receber dados parciais.
Uma resposta GraphQL típica pode conter tanto data quanto um array errors:
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
Isso é útil: o cliente ainda pode renderizar o que tem (por exemplo, o perfil do usuário) enquanto trata o campo faltante.
data costuma ser null.Escreva mensagens de erro para o usuário final, não para depuração. Evite expor stack traces, nomes de bancos ou IDs internos. Um bom padrão é:
message curta e seguraextensions.code legível por máquina e estávelretryable: true)Registre o erro detalhado no servidor com um ID de requisição para investigar sem expor internals.
Defina um pequeno “contrato” de erros que web e mobile compartilhem: valores comuns em extensions.code (como UNAUTHENTICATED, FORBIDDEN, BAD_USER_INPUT), quando mostrar um toast vs. erro inline por campo, e como lidar com dados parciais. Consistência evita que cada cliente invente suas próprias regras.
Subscriptions são a forma do GraphQL de enviar dados para clientes conforme mudam, ao invés de o cliente perguntar repetidamente. Normalmente são entregues por uma conexão persistente (mais comumente WebSockets), para que o servidor possa enviar eventos no momento em que algo acontece.
Uma subscription se parece bastante com uma query, mas o resultado não é uma resposta única. É um fluxo de resultados — cada um representando um evento.
Por baixo, o cliente “se inscreve” em um tópico (por exemplo, messageAdded em um chat). Quando o servidor publica um evento, assinantes conectados recebem um payload que corresponde ao conjunto de seleção da subscription.
Subscriptions brilham quando usuários esperam mudanças instantâneas:
Com polling, o cliente pergunta “Há algo novo?” a cada N segundos. É simples, mas pode desperdiçar requisições (especialmente quando nada muda) e ainda parecer atrasado.
Com subscriptions, o servidor envia a atualização imediatamente. Isso reduz tráfego desnecessário e melhora a percepção de velocidade — ao custo de manter conexões abertas e gerenciar infraestrutura em tempo real.
Subscriptions nem sempre valem a pena. Se atualizações são raras, não são sensíveis ao tempo ou fáceis de agrupar, polling (ou re-fetch após ações do usuário) costuma bastar.
Elas também adicionam overhead operacional: escalabilidade de conexões, autenticação em sessões longas, retries e monitoramento. Uma boa regra: use subscriptions apenas quando tempo real for um requisito do produto, e não só um nice-to-have.
GraphQL é frequentemente descrito como “poder para o cliente”, mas esse poder tem custos. Conhecer os trade-offs ajuda a decidir quando GraphQL é uma boa escolha — e quando pode ser exagero.
O maior ganho é a flexibilidade na busca de dados: clientes podem pedir exatamente os campos que precisam, reduzindo over-fetching e acelerando mudanças de UI.
Outra vantagem importante é o contrato forte fornecido pelo esquema GraphQL. O esquema vira uma fonte única de verdade para tipos e operações disponíveis, o que melhora colaboração e ferramentas.
Times costumam ver maior produtividade no cliente porque desenvolvedores frontend iteram sem esperar por novas variações de endpoint, e ferramentas como Apollo Client geram tipos e simplificam fetch de dados.
GraphQL pode tornar cache mais complexo. No REST, cache é muitas vezes “por URL”. No GraphQL, muitas queries usam o mesmo endpoint, então o cache depende da forma da query, caches normalizados e configuração cuidadosa no servidor/cliente.
No servidor, há armadilhas de performance. Uma query pequena pode disparar muitas chamadas ao backend a menos que você desenhe resolvers com batching, evite N+1 e controle campos caros.
Também há uma curva de aprendizado: esquemas, resolvers e padrões de cliente podem ser estranhos para times acostumados a APIs baseadas em endpoints.
Como clientes podem pedir muito, APIs GraphQL devem impor limites de profundidade e complexidade de query para evitar requisições abusivas ou acidentalmente “grandes demais”.
Autenticação e autorização devem ser aplicadas por campo, não só no nível da rota, já que campos diferentes podem ter regras de acesso distintas.
Operacionalmente, invista em logging, tracing e monitoramento que entendam GraphQL: rastreie nomes de operações, variáveis (com cuidado), tempos de resolvers e taxas de erro para identificar queries lentas e regressões cedo.
GraphQL e REST ambos ajudam apps a conversar com servidores, mas estruturam essa conversa de formas bem diferentes.
REST é baseado em recursos. Você busca dados chamando vários endpoints (URLs) que representam “coisas” como /users/123 ou /orders?userId=123. Cada endpoint retorna uma forma de dados fixa decidida pelo servidor.
REST também se apoia em semântica HTTP: métodos como GET/POST/PUT/DELETE, códigos de status e regras de cache. Isso torna o REST natural quando você faz CRUD simples ou trabalha com caches em browser/proxy.
GraphQL é baseado em esquema. Em vez de muitos endpoints, você geralmente tem um único endpoint, e o cliente envia uma query descrevendo os campos exatos que quer. O servidor valida essa requisição contra o esquema e retorna uma resposta que corresponde à forma da query.
Essa “seleção conduzida pelo cliente” é por que o GraphQL pode reduzir over-fetching (dados demais) e under-fetching (dados de menos), especialmente para telas que precisam de dados de vários modelos relacionados.
REST costuma ser a opção certa quando:
Muitas equipes misturam ambos:
A pergunta prática não é “Qual é melhor?” mas “O que se encaixa neste caso com a menor complexidade?”.
Projetar uma API GraphQL é mais fácil quando você a trata como um produto para quem constrói telas, não como um espelho do seu banco de dados. Comece pequeno, valide com casos reais e expanda conforme as necessidades.
Liste suas telas-chave (por exemplo, “Lista de produtos”, “Detalhes do produto”, “Checkout”). Para cada tela, escreva os campos exatos que ela precisa e as interações que suporta.
Isso ajuda a evitar “queries deus”, reduz over-fetching e deixa claro onde você precisará de filtros, ordenação e paginação.
Defina seus tipos principais primeiro (por exemplo, User, Product, Order) e seus relacionamentos. Depois adicione:
Prefira nomes em linguagem de negócio ao invés de nomes de banco. “placeOrder” comunica intenção melhor que “createOrderRecord”.
Mantenha nomes consistentes: singular para item (product), plural para coleções (products). Para paginação, geralmente escolha uma:
Decida cedo—mesmo de forma alta—porque isso molda a estrutura de resposta da API.
GraphQL suporta descrições diretamente no esquema — use-as para campos, argumentos e casos borda. Depois adicione alguns exemplos copy-paste na documentação (incluindo paginação e cenários comuns de erro). Um esquema bem descrito torna introspecção e exploradores de API muito mais úteis.
Começar com GraphQL é principalmente escolher algumas ferramentas bem suportadas e montar um fluxo de trabalho confiável. Você não precisa adotar tudo de uma vez — faça uma query funcionar ponta a ponta e depois expanda.
Escolha um servidor conforme sua stack e quanto “baterias incluídas” você quer:
Um passo prático: defina um esquema pequeno (alguns tipos + uma query), implemente resolvers e conecte a uma fonte de dados real (mesmo que seja uma lista em memória stubada).
Se quiser ir mais rápido do "ideia" a uma API funcionando, uma plataforma de vibe-coding como Koder.ai pode ajudar a scaffoldingar uma pequena aplicação full-stack (React no frontend, Go + PostgreSQL no backend) e iterar em esquema/resolvers via chat — depois exporte o código quando estiver pronto para assumir a implementação.
No frontend, sua escolha depende de querer convenções opinativas ou flexibilidade:
Se estiver migrando de REST, comece usando GraphQL para uma tela ou feature, mantendo REST para o resto até a abordagem se provar.
Trate seu esquema como um contrato de API. Camadas úteis de teste incluem:
Para aprofundar, continue com:
GraphQL é uma linguagem de consulta e um runtime para APIs. Clientes enviam uma consulta descrevendo os campos exatos que querem, e o servidor retorna uma resposta JSON que espelha essa forma.
Pense nele como uma camada entre clientes e uma ou mais fontes de dados (bancos de dados, serviços REST, APIs de terceiros, microserviços).
GraphQL ajuda principalmente com:
Ao permitir que o cliente peça apenas campos específicos (incluindo campos aninhados), o GraphQL pode reduzir transferência de dados desnecessária e simplificar o código do cliente.
GraphQL não é:
Trate-o como um contrato de API + mecanismo de execução, não como uma solução mágica de armazenamento ou desempenho.
A maioria das APIs GraphQL expõe um endpoint único (frequentemente /graphql). Em vez de várias URLs, você envia diferentes operações (queries/mutations) para esse único endpoint.
Implicação prática: cache e observabilidade normalmente se baseiam no nome da operação + variáveis, não na URL.
O esquema é o contrato da API. Ele define:
User, Post)User.name)User.posts)Por ser , o servidor pode validar consultas antes de executá-las e retornar erros claros quando campos não existem.
Consultas GraphQL são operações de leitura. Você especifica os campos que precisa, e o JSON de resposta corresponde à estrutura da consulta.
Dicas:
query GetUserWithPosts) para facilitar debug e monitoramento.posts(limit: 2)).Mutations são operações de escrita (criar/atualizar/apagar). Um padrão comum é:
inputRetornar dados (não apenas success: true) ajuda a UI a atualizar imediatamente e mantém caches consistentes.
Resolvers são funções a nível de campo que dizem ao GraphQL como obter ou calcular cada campo.
Na prática, resolvers podem:
A autorização costuma ser aplicada nos resolvers (ou em middleware compartilhado), porque eles sabem quem está pedindo e que dado está sendo acessado.
É fácil criar um padrão N+1 (por exemplo, carregar posts separadamente para cada um de 100 usuários).
Mitigações comuns:
Meça o tempo dos resolvers e verifique chamadas repetidas a serviços descendentes durante uma única requisição.
GraphQL pode retornar dados parciais junto com um array errors. Isso ocorre quando alguns campos resolvem com sucesso e outros falham (por exemplo, campo proibido ou timeout num serviço downstream).
Boas práticas:
extensions.code (por exemplo, FORBIDDEN, BAD_USER_INPUT)Os clientes devem decidir quando renderizar dados parciais ou tratar a operação como falha total.