22 de set. de 2025·8 min
O que é o Kafka e como ele é usado em sistemas modernos?
Saiba o que é o Apache Kafka, como funcionam tópicos e partições, e onde o Kafka se encaixa em sistemas modernos para eventos em tempo real, logs e pipelines de dados.
Kafka em linguagem simples
Apache Kafka é uma plataforma distribuída de streaming de eventos. Em termos simples, é um “canal” compartilhado e durável que permite que muitos sistemas publiquem fatos sobre o que aconteceu e que outros sistemas leiam esses fatos—rápido, em escala e em ordem.
Equipes usam Kafka quando dados precisam se mover de forma confiável entre sistemas sem acoplamento rígido. Em vez de uma aplicação chamar outra diretamente (e falhar quando ela está fora ou lenta), produtores escrevem eventos no Kafka. Consumidores os leem quando estiverem prontos. O Kafka armazena eventos por um período configurável, então sistemas podem se recuperar de indisponibilidades e até reprocessar o histórico.
Alguns termos que você verá
- Evento / Mensagem: Um registro de algo que aconteceu (por exemplo, “OrderPlaced” ou “PaymentFailed”). Usuários de Kafka costumam dizer “mensagem”, mas “evento” enfatiza que representa uma mudança no mundo real.
- Stream: Um fluxo contínuo de eventos ao longo do tempo.
- Log: O Kafka organiza eventos como um log apenas-apend—novos eventos são adicionados ao fim, e leitores avançam no seu próprio ritmo.
Para quem é este guia (e o que você vai aprender)
Este guia é para engenheiros com foco em produto, profissionais de dados e líderes técnicos que querem um modelo mental prático do Kafka.
Você aprenderá os blocos centrais (produtores, consumidores, tópicos, brokers), como o Kafka escala com partições, como ele armazena e reproduz eventos, e onde ele se encaixa na arquitetura orientada a eventos. Também cobriremos casos de uso comuns, garantias de entrega, noções básicas de segurança, planejamento de operações e quando o Kafka é (ou não é) a ferramenta certa.
Conceitos centrais: Produtores, Consumidores, Tópicos, Brokers
Kafka é mais fácil de entender como um log de eventos compartilhado: aplicações escrevem eventos nele, e outras aplicações leem esses eventos depois—frequentemente em tempo real, às vezes horas ou dias depois.
Produtores e consumidores
Produtores são os escritores. Um produtor pode publicar um evento como “pedido realizado”, “pagamento confirmado” ou “leitura de temperatura”. Produtores não enviam eventos diretamente para apps específicos—eles enviam para o Kafka.
Consumidores são os leitores. Um consumidor pode alimentar um painel, acionar um fluxo de envio ou carregar dados para analytics. Consumidores decidem o que fazer com os eventos e podem lê-los no seu próprio ritmo.
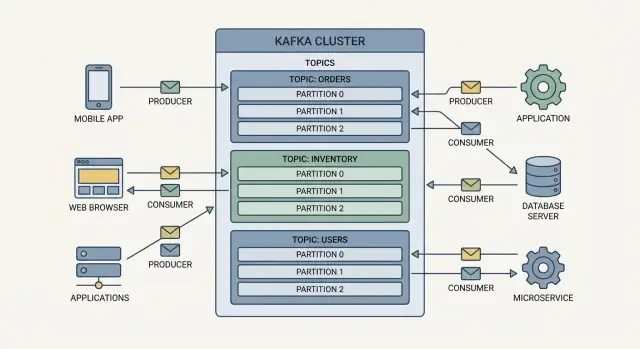
Tópicos: organizando eventos
Eventos no Kafka são agrupados em tópicos, que são basicamente categorias nomeadas. Por exemplo:
orderspara eventos relacionados a pedidospaymentspara eventos de pagamentoinventorypara mudanças de estoque
Um tópico torna-se o fluxo “fonte da verdade” para esse tipo de evento, o que facilita que várias equipes reaproveitem os mesmos dados sem construir integrações pontuais.
Brokers e clusters
Um broker é um servidor Kafka que armazena eventos e os serve para consumidores. Na prática, o Kafka roda como um cluster (múltiplos brokers trabalhando juntos) para lidar com mais tráfego e continuar funcionando mesmo se uma máquina falhar.
Grupos de consumidores: escalar leitores sem duplicar trabalho
Consumidores frequentemente rodam em um consumer group. O Kafka divide o trabalho de leitura entre o grupo, então você pode adicionar mais instâncias consumidoras para escalar o processamento—sem que cada instância faça o mesmo trabalho duplicado.
Como tópicos e partições fazem o Kafka escalar
O Kafka escala dividindo o trabalho em tópicos (fluxos de eventos relacionados) e então dividindo cada tópico em partições (fatias menores e independentes do fluxo).
Partições = paralelismo e throughput
Um tópico com uma partição só pode ser lido por uma única instância de consumidor dentro de um grupo. Adicione mais partições e você pode adicionar mais consumidores para processar eventos em paralelo. É assim que o Kafka suporta alto throughput de streaming de eventos e pipelines de dados em tempo real sem transformar cada sistema em um gargalo.
Partições também ajudam a espalhar a carga entre brokers. Em vez de uma única máquina lidar com todas as escritas e leituras de um tópico, múltiplos brokers podem hospedar partições diferentes e compartilhar o tráfego.
Ordenação: o que o Kafka garante (e o que não garante)
Kafka garante ordenção dentro de uma mesma partição. Se os eventos A, B e C são escritos na mesma partição nessa ordem, consumidores os lerão A → B → C.
A ordenação entre partições não é garantida. Se você precisa de ordenação estrita para uma entidade específica (como um cliente ou pedido), normalmente garante que todos os eventos dessa entidade vão para a mesma partição.
Chaves decidem para onde os eventos vão
Quando produtores enviam um evento, podem incluir uma key (por exemplo, order_id). O Kafka usa a chave para rotear consistentemente eventos relacionados para a mesma partição. Isso dá ordenação previsível para aquela chave, enquanto o tópico como um todo escala por muitas partições.
Réplicas mantêm os dados disponíveis
Cada partição pode ser replicada em outros brokers. Se um broker falhar, outro broker com uma réplica pode assumir. A replicação é uma razão importante pela qual o Kafka é confiável para mensageria pub-sub e sistemas orientados a eventos: melhora a disponibilidade e suporta tolerância a falhas sem exigir que cada aplicação implemente sua própria lógica de failover.
Armazenamento, retenção e reprodução de eventos
Uma ideia chave do Apache Kafka é que eventos não são apenas encaminhados e esquecidos. Eles são escritos em disco em um log ordenado, então consumidores podem lê-los agora—ou mais tarde. Isso torna o Kafka útil não só para mover dados, mas também para manter um histórico durável do que aconteceu.
Eventos são persistidos, não apenas “em trânsito”
Quando um produtor envia um evento para um tópico, o Kafka o anexa ao armazenamento do broker. Consumidores então leem desse log armazenado no seu próprio ritmo. Se um consumidor ficar fora por uma hora, os eventos ainda existem e podem ser consumidos quando ele se recuperar.
Retenção: por quanto tempo o Kafka guarda dados
O Kafka mantém eventos segundo políticas de retenção:
- Retenção baseada em tempo: manter eventos por um período definido (por exemplo, 7 dias).
- Retenção baseada em tamanho: manter eventos até que o log atinja um tamanho configurado e então excluir os dados mais antigos.
A retenção é configurada por tópico, o que permite tratar tópicos de trilha de auditoria de forma diferente de tópicos de telemetria de alto volume.
Compactação: manter o último valor por chave
Alguns tópicos se parecem mais com um changelog do que com um arquivo histórico—por exemplo, “configurações atuais do cliente”. A compactação de log mantém pelo menos o registro mais recente para cada chave, enquanto registros antigos substituídos podem ser removidos. Assim você tem uma fonte durável da versão mais recente, sem crescimento ilimitado.
Reproduzir eventos: reconstruir estado e recuperar de bugs
Porque os eventos permanecem armazenados, você pode reproduzi-los para reconstruir estado:
- Reconstruir um índice de busca ou uma view materializada do zero
- Recuperar um serviço após um deploy com problema reprocessando a partir de um ponto anterior
- Incluir um novo consumidor e deixá-lo ler dados históricos
Na prática, a reprodução é controlada por onde um consumidor “começa a ler” (seu offset), dando às equipes uma rede de segurança poderosa quando sistemas evoluem.
Noções de confiabilidade e tolerância a falhas
O Kafka foi construído para manter os dados fluindo mesmo quando partes do sistema falham. Faz isso com replicação, regras claras sobre quem é “o líder” de cada partição e confirmações de escrita configuráveis.
Replicação: líder e seguidores (alto nível)
Cada partição de tópico tem um broker líder e um ou mais seguidores (réplicas) em outros brokers. Produtores e consumidores conversam com o líder daquela partição.
Seguidores copiam continuamente os dados do líder. Se o líder cair, o Kafka pode promover um seguidor suficientemente atualizado a novo líder, de modo que a partição continue disponível.
O que acontece durante a falha de um broker (resumido)
Se um broker falhar, quaisquer partições que ele hospedava como líderes ficam indisponíveis por um momento. O controlador do Kafka detecta a falha e aciona a eleição de líder para essas partições.
Se pelo menos um seguidor em sincronia estiver atualizado, ele pode assumir como líder e os clientes retomam a produção/consumo. Se não houver réplicas em sincronia, o Kafka pode pausar escritas (dependendo das configurações) para evitar perda de dados já reconhecidos.
Durabilidade: acknowledgments e fator de replicação
Dois parâmetros principais moldam a durabilidade:
- Fator de replicação: quantas cópias de cada partição existem (por exemplo, 3 cópias em 3 brokers).
- Acknowledgments (acks): quando o produtor considera uma gravação bem-sucedida.
Em termos gerais:
- acks=0: o produtor não espera—rápido, mas pode perder mensagens.
- acks=1: o líder confirma a gravação—melhor, mas se o líder falhar antes que seguidores copiem, mensagens recentes podem ser perdidas.
- acks=all (ou -1): o líder espera réplicas “in sync” confirmarem—mais seguro, geralmente um pouco mais lento.
Para reduzir duplicatas durante retries, equipes combinam acks mais seguros com produtores idempotentes e tratamento robusto no consumidor (coberto mais adiante).
Latência vs segurança
Maior segurança normalmente significa esperar mais confirmações e manter mais réplicas em sincronia, o que pode aumentar a latência e reduzir o throughput máximo.
Configurações de baixa latência podem ser adequadas para telemetria ou clickstream onde perda ocasional é aceitável, mas pagamentos, inventário e logs de auditoria geralmente justificam a segurança adicional.
O papel do Kafka na arquitetura orientada a eventos
Protótipo de serviço EDA
Prototipe um serviço orientado a eventos com UI em React, backend em Go e PostgreSQL no Koder.ai.
Arquitetura orientada a eventos (EDA) é uma forma de construir sistemas em que ocorrências de negócio—um pedido feito, um pagamento confirmado, um pacote enviado—são representadas como eventos que outras partes do sistema podem reagir.
Publicar eventos, reagir com consumidores
O Kafka frequentemente fica no centro da EDA como o “fluxo de eventos” compartilhado. Em vez do Serviço A chamar o Serviço B diretamente, o Serviço A publica um evento (por exemplo, OrderCreated) em um tópico do Kafka. Vários serviços podem consumir esse evento e agir—enviar e-mail, reservar estoque, iniciar verificações de fraude—sem que o Serviço A precise conhecê-los.
Baixo acoplamento (menos dependências diretas)
Como os serviços se comunicam por eventos, não precisam coordenar APIs request/response para cada interação. Isso reduz dependências rígidas entre equipes e facilita adicionar novos recursos: você pode introduzir um novo consumidor para um evento existente sem mudar o produtor.
Workflows assíncronos e resistência a picos
EDA é naturalmente assíncrona: produtores escrevem eventos rápido, e consumidores processam no seu próprio ritmo. Durante picos de tráfego, o Kafka ajuda a absorver a onda para que sistemas downstream não entrem em colapso imediato. Consumidores podem escalar para recuperar o atraso, e se um consumidor cair temporariamente, ele pode retomar de onde parou.
Modelo mental prático
Pense no Kafka como o “feed de atividade” do sistema. Produtores publicam fatos; consumidores se inscrevem nos fatos que interessam. Esse padrão habilita pipelines de dados em tempo real e workflows orientados a eventos mantendo serviços mais simples e independentes.
Casos de uso comuns do Kafka em sistemas modernos
O Kafka costuma aparecer quando equipes precisam mover muitos “fatos que aconteceram” (eventos) entre sistemas—rápido, de forma confiável e para que múltiplos consumidores possam reaproveitar.
Rastreio de atividade e logs de auditoria
Aplicações frequentemente precisam de um histórico apenas-apend: logins de usuários, mudanças de permissões, atualizações de registros ou ações administrativas. O Kafka funciona bem como um fluxo central desses eventos, para que ferramentas de segurança, relatórios e exportações de conformidade leiam a mesma fonte sem sobrecarregar o banco de produção. Como os eventos são retidos por um período, você pode reproduzi-los para reconstruir uma visão de auditoria após um bug ou mudança de esquema.
Comunicação entre microserviços via eventos
Em vez de serviços se chamarem diretamente, eles podem publicar eventos como “order created” ou “payment received”. Outros serviços se inscrevem e reagem no seu tempo. Isso reduz acoplamento, ajuda a manter o funcionamento durante falhas parciais e facilita adicionar novas capacidades (por exemplo, verificações de fraude) apenas consumindo o fluxo existente.
Pipelines de dados para analytics e warehouses
O Kafka é uma espinha dorsal comum para mover dados de sistemas operacionais para plataformas analíticas. Equipes podem transmitir mudanças dos bancos de aplicação e entregá-las a um data warehouse ou data lake com baixa latência, mantendo a aplicação de produção separada de consultas analíticas pesadas.
IoT e telemetria com tráfego em rajadas
Sensores, dispositivos e telemetria de apps frequentemente chegam em picos. O Kafka pode absorver rajadas, armazená-las de forma segura e permitir que o processamento downstream recupere o atraso—útil para monitoramento, alertas e análise de longo prazo.
Ecossistema Kafka: Connect, Streams e ferramentas
O Kafka é mais que brokers e tópicos. A maioria das equipes depende de ferramentas complementares que tornam o Kafka prático para movimentação de dados, processamento de streams e operações.
Kafka Connect: mover dados sem código customizado
Kafka Connect é o framework de integração do Kafka para levar dados para o Kafka (sources) e fora do Kafka (sinks). Em vez de construir pipelines pontuais, você roda o Connect e configura conectores.
Exemplos comuns incluem puxar mudanças de bancos de dados, ingerir eventos de SaaS ou entregar dados do Kafka a um warehouse ou armazenamento de objetos. O Connect também padroniza preocupações operacionais como retries, offsets e paralelismo.
Kafka Streams: processamento em tempo real dentro das apps
Se o Connect é para integração, Kafka Streams é para computação. É uma biblioteca que você adiciona à aplicação para transformar streams em tempo real—filtrar eventos, enriquecer, juntar streams e construir agregados (como “pedidos por minuto”).
Como apps Streams leem de tópicos e escrevem de volta em tópicos, elas se encaixam naturalmente em sistemas orientados a eventos e podem escalar adicionando instâncias.
Gerenciamento de esquemas: manter eventos consistentes
À medida que múltiplas equipes publicam eventos, consistência importa. O gerenciamento de esquemas (frequentemente via schema registry) define quais campos um evento deve ter e como eles evoluem ao longo do tempo. Isso ajuda a prevenir que um produtor renomeie um campo que um consumidor depende.
Ferramentas: monitorar o que importa
O Kafka é sensível operacionalmente, então monitoramento básico é essencial:
- Consumer lag: os consumidores estão ficando para trás?
- Throughput: quantos eventos por segundo estão fluindo?
- Erros: fetches falharam, erros de produção, falhas em tarefas de conector
A maioria das equipes também usa UIs de gerenciamento e automação para deploys, configuração de tópicos e políticas de controle de acesso (veja /blog/kafka-security-governance).
Garantias de entrega e padrões de processamento
Lance um painel de consumidores
Crie um painel interno leve que leia do Kafka e mostre lag e throughput.
Kafka é frequentemente descrito como “log durável + consumidores”, mas o que importa para muitas equipes é: vou processar cada evento uma vez, e o que acontece quando algo falha? O Kafka fornece blocos de construção, e você escolhe os trade-offs.
Garantias de entrega (alto nível)
At-most-once significa que você pode perder eventos, mas não vai processar duplicatas. Isso pode ocorrer se um consumidor comitar sua posição primeiro e depois falhar antes de terminar o trabalho.
At-least-once significa que você não perderá eventos, mas duplicatas são possíveis (por exemplo, o consumidor processa um evento, cai e depois reprocessa ao reiniciar). Esse é o padrão mais comum.
Exactly-once busca evitar perda e duplicatas end-to-end. No Kafka, isso tipicamente envolve produtores transacionais e processamento compatível (frequentemente via Kafka Streams). É poderoso, mas mais restrito e requer configuração cuidadosa.
Idempotência e deduplicação
Na prática, muitos sistemas abraçam at-least-once e adicionam salvaguardas:
- Gravações idempotentes: faça com que o passo “aplicar evento” seja seguro de repetir (por exemplo, upserts, atualizações condicionais, chaves únicas).
- Deduplicação: armazene um id do evento (ou chave de negócio) e ignore repetições dentro de uma janela.
Offsets do consumidor: seu “marcador”
Um offset é a posição do último registro processado de uma partição. Ao comitar offsets, você diz “terminei até aqui”. Comitar cedo demais arrisca perda; comitar tarde demais aumenta duplicatas após falhas.
Retries e mensagens venenosas
Retries devem ser limitados e visíveis. Um padrão comum é:
- tentar novamente com backoff para erros transitórios,
- então enviar o registro com falha para um tópico dead-letter para inspeção e reprodução.
Isso evita que uma única “mensagem venenosa” bloqueie um grupo inteiro de consumidores enquanto preserva os dados para correções futuras.
Segurança e governança
O Kafka frequentemente carrega eventos críticos de negócio (pedidos, pagamentos, atividade de usuários). Isso torna segurança e governança parte do projeto, não um detalhe posterior.
Autenticação e autorização
Autenticação responde “quem é você?” Autorização responde “o que você pode fazer?” No Kafka, autenticação é comumente feita com SASL (por exemplo, SCRAM ou Kerberos), enquanto autorização é aplicada com ACLs (listas de controle de acesso) em nível de tópico, grupo de consumidores e cluster.
Um padrão prático é privilégio mínimo: produtores só escrevem nos tópicos que possuem, e consumidores leem apenas os tópicos que precisam. Isso reduz exposição acidental de dados e limita o raio de impacto se credenciais vazarem.
Criptografia em trânsito (TLS)
TLS criptografa os dados enquanto se movem entre apps, brokers e ferramentas. Sem TLS, eventos podem ser interceptados em redes internas, não apenas na internet pública. TLS também ajuda a prevenir ataques de “man-in-the-middle” ao validar identidades dos brokers.
Kafka multi-tenant e convenções de nomenclatura
Quando várias equipes compartilham um cluster, guardrails importam. Convenções claras de nomes de tópico (por exemplo, <team>.<domain>.<event>.<version>) tornam a propriedade óbvia e ajudam ferramentas a aplicar políticas consistentemente.
Combine nomenclatura com cotas e templates de ACL para que uma carga ruidosa não prive outras e para que novos serviços comecem com padrões seguros.
Governança de dados: PII, retenção e alinhamento
Trate o Kafka como sistema de registro de histórico somente quando essa for a intenção. Se eventos incluem PII, minimize dados (envie IDs em vez de perfis completos), considere criptografia por campo e documente quais tópicos são sensíveis.
Configurações de retenção devem corresponder a requisitos legais e de negócio. Se a política exige “excluir após 30 dias”, não mantenha 6 meses “só por precaução”. Revisões e auditorias regulares mantêm as configurações alinhadas conforme os sistemas evoluem.
Operar Kafka: o que as equipes precisam planejar
Tenha controle do código-fonte
Mantenha controle total exportando o código-fonte quando estiver pronto para ir além do protótipo.
Executar Apache Kafka não é apenas “instalar e esquecer”. Ele se comporta mais como um utilitário compartilhado: muitas equipes dependem dele, e pequenos deslizes podem se propagar para apps downstream.
Noções básicas de planejamento de capacidade
Capacidade do Kafka é principalmente um problema de cálculo que você revisita regularmente. As maiores alavancas são partições (paralelismo), throughput (MB/s de entrada e saída) e crescimento de armazenamento (por quanto tempo você retém dados).
Se o tráfego dobrar, você pode precisar de mais partições para espalhar a carga entre brokers, mais disco para manter retenção e mais capacidade de rede para replicação. Um hábito prático é projetar a taxa de escrita no pico, multiplicar pela retenção para estimar crescimento de disco e adicionar margem para replicação e “sucesso inesperado”.
Tarefas operacionais do dia a dia
Espere trabalho rotineiro além de manter servidores no ar:
- Upgrades: planeje rolling upgrades, teste compatibilidade dos clientes e agende mudanças quando o tráfego for menor.
- Rebalanceamento: rebalances de grupos consumidores podem causar pausas breves; tenha padrões seguros de deploy e propriedade clara.
- Resposta a incidentes: tenha playbooks para falhas de broker, disco cheio e produtores malconfigurados enchendo um tópico.
Diretores de custo e opções de deployment
Os custos são dirigidos por discos, egresso de rede e número/tamanho de brokers. Kafka gerenciado pode reduzir ônus de time e simplificar upgrades, enquanto self-hosted pode ser mais barato em escala se você tiver operadores experientes. O trade-off é tempo de recuperação e ônus de on-call.
O que medir (para não chutar)
Equipes normalmente monitoram:
- Latência ponta a ponta (do produce ao consume)
- Consumer lag (quão atrasados estão os consumidores)
- Saúde dos brokers (uso de disco, partições sub-replicadas, taxas de erro de requisições)
Bons dashboards e alertas transformam o Kafka de uma “caixa preta” em um serviço compreensível.
Quando usar Kafka (e quando não usar)
O Kafka é adequado quando você precisa mover muitos eventos de forma confiável, mantê-los por um tempo e permitir que múltiplos sistemas reajam ao mesmo fluxo no seu ritmo. É especialmente útil quando os dados precisam ser reproduzíveis (para backfills, auditorias ou reconstrução de um serviço) e quando você espera adicionar produtores/consumidores ao longo do tempo.
Bons momentos para escolher Kafka
Kafka costuma brilhar quando você tem:
- Streams de alto throughput (cliques, pedidos, dados de sensores)
- Muitos consumidores que precisam dos mesmos eventos (analytics, monitoramento, fraude, notificações)
- Necessidade de replay e histórico de longa duração, não apenas “entregar e esquecer”
- Trabalho de integração onde desacoplar equipes e serviços importa
Quando o Kafka pode ser pesado demais
O Kafka pode ser exagerado se suas necessidades forem simples:
- Uma fila de baixo volume entre dois serviços
- Tarefas de vida curta (jobs em background) onde replay não é valioso
- Equipes sem tempo para operar e monitorar um sistema distribuído
Nesses casos, o ônus operacional (dimensionamento de cluster, upgrades, monitoramento, on-call) pode superar os benefícios.
Alternativas e complementos
- RabbitMQ: ótimo para filas clássicas de trabalho e padrões de roteamento.
- NATS: mensageria leve com baixa latência.
- Cloud pub/sub: bom quando você quer infraestrutura gerenciada e operações mais simples.
O Kafka também complementa—não substitui—bancos de dados (sistema de registro), caches (leituras rápidas) e ferramentas de ETL em batch (transformações periódicas grandes).
Checklist rápido de decisão
Pergunte-se:
- Precisamos de múltiplos consumidores e de replay?
- O throughput tende a crescer significativamente?
- Precisamos do histórico/retenção de eventos como recurso?
- Podemos suportar propriedade operacional (ou usar Kafka gerenciado)?
- Estamos transmitindo eventos, não apenas enviando comandos/tarefas?
Se a maioria das respostas for “sim”, o Kafka costuma ser uma escolha sensata.
Começando: um caminho simples de adoção
O Kafka funciona melhor quando você precisa de uma “fonte de verdade” compartilhada para streams de eventos em tempo real: muitos sistemas produzindo fatos (pedidos criados, pagamentos autorizados, estoque alterado) e muitos sistemas consumindo esses fatos para alimentar pipelines, analytics e recursos reativos.
Passo 1: escolha um caso de uso concreto
Comece com um fluxo estreito e de alto valor—como publicar eventos “OrderPlaced” para serviços downstream (email, verificações de fraude, fulfillment). Evite transformar o Kafka numa fila catch-all no primeiro dia.
Passo 2: defina seus eventos e tópicos
Anote:
- Eventos: o que aconteceu, em termos de negócio simples
- Tópicos: onde esses eventos vivem (frequentemente um tópico por tipo de evento ou domínio)
- Consumidores: quais times/serviços precisam dos eventos e por quê
Mantenha esquemas iniciais simples e consistentes (timestamps, IDs e um nome claro de evento). Decida se vai impor esquemas desde o início ou evoluir com cuidado.
Passo 3: estabeleça propriedade e operacional básico
O Kafka funciona quando alguém é responsável por:
- Criação de tópicos e convenções de nomes
- Políticas de retenção e acesso
- Responsabilidades de on-call e runbooks
Adicione monitoramento imediatamente (consumer lag, saúde dos brokers, throughput, taxas de erro). Se ainda não tiver um time de plataforma, comece com uma oferta gerenciada e limites claros.
Passo 4: construa um pipeline “fino” primeiro
Produza eventos de um sistema, consuma-os em um lugar e prove o loop ponta a ponta. Só então expanda para mais consumidores, partições e integrações.
Se você quer ir rápido do “ideia” para um serviço orientado a eventos funcionando, ferramentas como Koder.ai podem ajudar a prototipar a aplicação ao redor (UI React, backend Go, PostgreSQL) e adicionar produtores/consumidores Kafka de forma iterativa via fluxo guiado por chat. É útil para construir dashboards internos e serviços leves que consomem tópicos, com recursos como modo de planejamento, exportação de código-fonte, deployment/hosting e snapshots com rollback.
Se estiver mapeando isso para uma abordagem orientada a eventos, veja /blog/event-driven-architecture. Para planejar custos e ambientes, confira /pricing.
Perguntas frequentes
O que é o Apache Kafka em linguagem simples?
O Kafka é uma plataforma distribuída de streaming de eventos que armazena eventos em logs duráveis e apenas-apend.
Produtores escrevem eventos em tópicos, e consumidores os leem de forma independente (frequentemente em tempo real, mas também mais tarde), porque o Kafka mantém os dados por um período configurado.
Quando uma equipe deve escolher Kafka em vez de chamadas diretas entre serviços?
Use Kafka quando múltiplos sistemas precisam do mesmo fluxo de eventos, você quer baixo acoplamento e pode precisar reprocessar o histórico.
É especialmente útil para:
- Microserviços orientados a eventos (publicar fatos e reagir assincronamente)
- Pipelines em tempo real para analytics/data warehouses
- Rastreio de atividade, logs de auditoria e telemetria com tráfego em rajadas
Qual a diferença entre um tópico e uma partição?
Um tópico é uma categoria nomeada de eventos (como orders ou payments).
Uma partição é uma fatia de um tópico que permite:
- Maior taxa de transferência (escritas/leitura distribuídas entre brokers)
- Consumo em paralelo (múltiplos consumidores em um grupo)
O Kafka garante ordenação apenas dentro de uma única partição.
Como as chaves afetam ordenação e escalabilidade?
O Kafka usa a chave do registro (por exemplo, order_id) para rotear consistentemente eventos relacionados para a mesma partição.
Regra prática: se precisar de ordenação por entidade (todos os eventos de um pedido/cliente em sequência), escolha uma chave que represente essa entidade para que esses eventos caiam na mesma partição.
O que é um consumer group e por que isso importa?
Um grupo de consumidores é um conjunto de instâncias consumidoras que compartilham o trabalho de um tópico.
Dentro de um grupo:
- Cada partição é processada por no máximo uma instância por vez
- Aumentar instâncias aumenta o paralelismo até o número de partições
Se dois apps diferentes precisarem receber todo evento, eles devem usar grupos de consumidores distintos.
Por quanto tempo o Kafka mantém os dados e para que serve a retenção?
O Kafka retém eventos em disco segundo políticas do tópico, para que consumidores possam recuperar o atraso ou reprocessar histórico.
Tipos comuns de retenção:
- Baseada em tempo (manter por N dias)
- Baseada em tamanho (manter até o log atingir N GB)
A retenção é por tópico, então streams de auditoria de alto valor podem ser mantidos por mais tempo que telemetria de alto volume.
O que é log compaction e quando é melhor que retenção normal?
A compactação de log mantém pelo menos o registro mais recente por chave, removendo registros antigos substituídos ao longo do tempo.
É útil para streams de “estado atual” (como configurações ou perfis) em que você se importa com o último valor por chave, não com cada alteração histórica — preservando uma fonte durável da última versão sem crescimento indefinido.
O Kafka entrega eventos exatamente uma vez?
O padrão mais comum de ponta a ponta é at-least-once: você não perde eventos, porém duplicatas podem ocorrer.
Para operar com segurança:
- Torne consumidores idempotentes (aplicar o mesmo evento mais de uma vez é seguro)
- Use IDs únicos de evento ou chaves de negócio para deduplicação, quando necessário
- Comite offsets somente após concluir o trabalho para reduzir o risco de perda
O que são offsets de consumidor, e como retries e dead-letter topics se encaixam?
Offsets são o “marcador” do consumidor por partição.
Comitar offsets cedo demais pode causar perda de trabalho em caso de crash; comitar tarde demais aumenta chance de reprocessamento e duplicatas.
Um padrão operacional comum é tentativas limitadas com backoff e, em seguida, publicar falhas em um tópico de dead-letter para que uma mensagem problemática não bloqueie todo o grupo de consumidores.
O que são Kafka Connect e Kafka Streams, e quando devo usar cada um?
Kafka Connect move dados para dentro/fora do Kafka usando conectores (sources e sinks) em vez de código de pipeline personalizado.
Kafka Streams é uma biblioteca para transformar e agregar streams em tempo real dentro das suas aplicações (filtrar, juntar, enriquecer, agregar), lendo tópicos e escrevendo resultados de volta em tópicos.
Connect é normalmente usado para integração; Streams é usado para computação.