Por que apps em tempo real parecem lentos mesmo quando o código é rápido
A velocidade tem duas faces: throughput e latência. Throughput é quanto trabalho você finaliza por segundo (requisições, mensagens, frames). Latência é quanto tempo uma unidade de trabalho leva do começo ao fim.
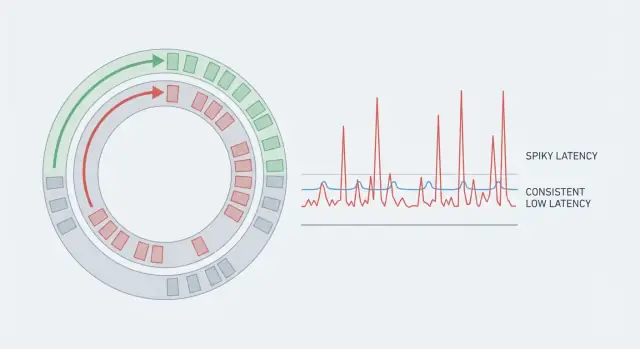
Um sistema pode ter ótimo throughput e ainda assim parecer lento se algumas requisições demoram muito mais que outras. Por isso médias enganam. Se 99 ações levam 5 ms e uma ação leva 80 ms, a média parece boa, mas a pessoa que caiu no caso de 80 ms sente a tremida. Em sistemas em tempo real, esses picos raros são a história inteira porque quebram o ritmo.
Latência previsível significa que você não mira apenas numa média baixa. Você mira consistência, para que a maioria das operações termine dentro de uma faixa estreita. Por isso equipes observam a cauda (p95, p99). É aí que as pausas se escondem.
Um pico de 50 ms pode importar em lugares como voz e vídeo (glitches de áudio), jogos multiplayer (rubber-banding), trading em tempo real (preços perdidos), monitoramento industrial (alarmas atrasados) e dashboards ao vivo (números pulam, alertas parecem não confiáveis).
Um exemplo simples: um app de chat pode entregar mensagens rapidamente na maior parte do tempo. Mas se uma pausa em background faz uma mensagem chegar 60 ms atrasada, indicadores de digitação piscam e a conversa parece lenta mesmo que o servidor pareça “rápido” na média.
Se você quer que o tempo real pareça real, precisa de menos surpresas, não apenas código mais rápido.
Noções básicas de latência: onde o tempo realmente vai
A maioria dos sistemas em tempo real não é lenta porque a CPU está sofrendo. Eles parecem lentos porque o trabalho passa a maior parte do tempo esperando: esperando para ser escalonado, esperando numa fila, esperando na rede ou esperando pelo armazenamento.
A latência ponta a ponta é o tempo total desde “algo aconteceu” até “o usuário vê o resultado”. Mesmo que seu handler rode em 2 ms, a requisição ainda pode levar 80 ms se pausar em cinco lugares diferentes.
Uma forma útil de dividir o caminho é:
- Tempo de rede (cliente para borda, serviço para serviço, retries)
- Tempo de escalonamento (sua thread espera para rodar)
- Tempo em fila (trabalho aguardando atrás de outro trabalho)
- Tempo de armazenamento (disco, locks no banco, misses no cache)
- Tempo de serialização (codificar e decodificar dados)
Essas esperas se acumulam. Alguns milissegundos aqui e ali transformam um caminho de código “rápido” numa experiência lenta.
A latência de cauda é onde os usuários começam a reclamar. A latência média pode parecer boa, mas p95 ou p99 significa os 5% ou 1% mais lentos das requisições. Outliers geralmente vêm de pausas raras: um ciclo de GC, um vizinho barulhento no host, uma contenção breve de lock, um refill de cache ou uma rajada que cria uma fila.
Exemplo concreto: uma atualização de preço chega pela rede em 5 ms, espera 10 ms por um worker ocupado, fica 15 ms atrás de outros eventos e então sofre um bloqueio no banco por 30 ms. Seu código ainda rodou em 2 ms, mas o usuário esperou 62 ms. O objetivo é tornar cada etapa previsível, não apenas a computação rápida.
As fontes usuais de jitter além da velocidade do código
Um algoritmo rápido ainda pode parecer lento se o tempo por requisição oscila. Usuários notam picos, não médias. Essa oscilação é jitter, e muitas vezes vem de coisas que seu código não controla totalmente.
Caches de CPU e comportamento de memória são custos escondidos. Se dados quentes não cabem no cache, a CPU fica parada esperando a RAM. Estruturas com muitos objetos, memória espalhada e “mais uma busca” podem virar misses de cache repetidos.
Alocação de memória adiciona aleatoriedade. Alocar muitos objetos de vida curta aumenta pressão no heap, que depois aparece como pausas (garbage collection) ou contenção do alocador. Mesmo sem GC, alocações frequentes podem fragmentar memória e prejudicar localidade.
Escalonamento de threads é outra fonte comum. Quando uma thread é desscalonada, você paga o overhead de context switch e perde o aquecimento de cache. Em uma máquina ocupada, sua thread “em tempo real” pode esperar atrás de trabalho não relacionado.
Contenção de locks é onde sistemas previsíveis frequentemente desmoronam. Um lock que “geralmente está livre” pode virar um comboio: threads acordam, disputam o lock e se colocam para dormir novamente. O trabalho ainda é feito, mas a latência de cauda se estica.
Esperas de I/O podem superar tudo. Uma syscall, um buffer de rede cheio, um handshake TLS, um flush de disco ou uma busca DNS lenta podem criar um pico acentuado que nenhuma micro-otimização resolve.
Se você caça jitter, comece procurando por misses de cache (frequentemente causados por estruturas com muitos ponteiros e acesso aleatório), alocações frequentes, context switches por muitas threads ou vizinhos barulhentos, contenção de locks e qualquer I/O bloqueante (rede, disco, logging, chamadas síncronas).
Exemplo: um serviço de ticker de preços pode calcular atualizações em microssegundos, mas uma chamada de logger sincronizado ou um lock de métricas contendido pode intermitentemente somar dezenas de milissegundos.
Martin Thompson e o que é o padrão Disruptor
Martin Thompson é conhecido em engenharia de baixa latência por focar em como sistemas se comportam sob pressão: não apenas velocidade média, mas velocidade previsível. Junto com a equipe da LMAX, ele ajudou a popularizar o padrão Disruptor, uma abordagem de referência para mover eventos por um sistema com atrasos pequenos e consistentes.
A abordagem Disruptor responde ao que torna muitos apps “rápidos” imprevisíveis: contenção e coordenação. Filas típicas costumam usar locks ou atomics pesados, acordam threads para cima e para baixo e criam rajadas de espera quando produtores e consumidores disputam estruturas compartilhadas.
Em vez de uma fila, o Disruptor usa um ring buffer: um array circular de tamanho fixo que contém eventos em slots. Produtores reivindicam o próximo slot, escrevem dados e então publicam um número de sequência. Consumidores leem em ordem seguindo essa sequência. Como o buffer é pré-alocado, você evita alocações frequentes e reduz pressão no garbage collector.
Uma ideia chave é o princípio do escritor único: mantenha um componente responsável por um certo estado compartilhado (por exemplo, o cursor que avança pelo ring). Menos escritores significam menos momentos de “quem é o próximo?”.
O backpressure é explícito. Quando consumidores ficam para trás, produtores eventualmente alcançam um slot que ainda está em uso. Nesse ponto o sistema precisa esperar, descartar ou desacelerar, mas faz isso de forma controlada e visível em vez de esconder o problema dentro de uma fila que cresce sem limites.
Ideias centrais de design que mantêm a latência consistente
O que torna designs no estilo Disruptor rápidos não é uma micro-otimização esperta. É remover as pausas imprevisíveis que acontecem quando um sistema briga com suas próprias partes móveis: alocações, misses de cache, contenção de locks e trabalho lento misturado no caminho quente.
Um modelo mental útil é uma linha de montagem. Eventos se movem por uma rota fixa com entregas claras. Isso reduz estado compartilhado e torna cada etapa mais fácil de manter simples e mensurável.
Mantenha memória e dados previsíveis
Sistemas rápidos evitam alocações-surpresa. Se você prealoca buffers e reutiliza objetos de mensagem, reduz os picos “às vezes” causados por garbage collection, crescimento do heap e locks do alocador.
Também ajuda manter mensagens pequenas e estáveis. Quando os dados tocados por evento cabem no cache da CPU, você gasta menos tempo esperando por memória.
Na prática, os hábitos que mais importam são: reutilizar objetos em vez de criar novos por evento, manter dados de evento compactos, preferir um escritor único para estado compartilhado e agrupar (batch) com cuidado para que você pague os custos de coordenação com menos frequência.
Torne caminhos lentos óbvios
Apps em tempo real frequentemente precisam de extras como logging, métricas, retries ou gravações em banco. A mentalidade Disruptor é isolar isso do loop principal para que não possa bloqueá-lo.
Em um feed de preços ao vivo, o caminho quente pode apenas validar um tick e publicar o próximo snapshot de preço. Qualquer coisa que possa travar (disco, chamadas de rede, serialização pesada) vai para um consumidor separado ou canal lateral, assim o caminho previsível permanece previsível.
Escolhas de arquitetura para latência previsível
Latência previsível é, na maior parte, um problema de arquitetura. Você pode ter código rápido e ainda ter picos se muitas threads brigam pelo mesmo dado, ou se mensagens pulam pela rede sem necessidade.
Comece decidindo quantos escritores e leitores tocam na mesma fila ou buffer. Um produtor único é mais fácil de manter suave porque evita coordenação. Configurações com múltiplos produtores podem aumentar throughput, mas geralmente adicionam contenção e tornam o pior caso menos previsível. Se precisar de múltiplos produtores, reduza escritas compartilhadas fragmentando eventos por chave (por exemplo, por userId ou instrumentId) para que cada shard tenha seu próprio caminho quente.
No lado do consumidor, um consumidor único dá o timing mais estável quando ordenação importa, porque o estado permanece local a uma thread. Pools de workers ajudam quando tarefas são realmente independentes, mas adicionam atrasos de escalonamento e podem reordenar trabalho a menos que você seja cuidadoso.
Batching é outro trade-off. Lotes pequenos cortam overhead (menos wakeups, menos misses de cache), mas batching também pode adicionar espera se você segurar eventos para encher um lote. Se agrupar em um sistema em tempo real, limite o tempo de espera (por exemplo, “até 16 eventos ou 200 microssegundos, o que ocorrer primeiro”).
Fronteiras de serviço também importam. Mensageria in-process geralmente é melhor quando você precisa de latência apertada. Saltos de rede podem valer a pena para escalabilidade, mas cada salto adiciona filas, retries e atraso variável. Se precisar de um salto, mantenha o protocolo simples e evite fan-out no caminho quente.
Um conjunto prático de regras: mantenha um caminho single-writer por shard quando possível, escale por sharding de chaves em vez de compartilhar uma fila quente, faça batching apenas com um teto de tempo rígido, adicione pools de workers somente para trabalho paralelo e independente, e trate cada salto de rede como uma possível fonte de jitter até que você o tenha medido.
Passo a passo: desenhando um pipeline de baixa variância
Comece com um orçamento de latência escrito antes de tocar no código. Escolha um alvo (o que “bom” parece) e um p99 (o que você deve ficar abaixo). Divida esse número entre estágios como entrada, validação, matching, persistência e atualizações de saída. Se um estágio não tem orçamento, ele não tem limite.
Em seguida, desenhe o fluxo de dados completo e marque cada entrega: fronteiras de thread, filas, saltos na rede e chamadas de armazenamento. Cada handoff é um lugar onde o jitter se esconde. Quando você pode vê-los, você pode reduzi-los.
Um fluxo de trabalho que mantém o design honesto:
- Escreva um orçamento por estágio (alvo e p99), mais uma pequena margem para desconhecidos.
- Mapeie o pipeline e rotule filas, locks, alocações e chamadas bloqueantes.
- Escolha um modelo de concorrência que você consiga raciocinar (escritor único, partição por chave, ou thread dedicada de I/O).
- Defina a forma da mensagem cedo: esquemas estáveis, payloads compactos e cópias mínimas.
- Decida regras de backpressure desde o início: dropar, atrasar, degradar ou shed load. Torne isso visível e mensurável.
Depois, decida o que pode ser assíncrono sem quebrar a experiência do usuário. Uma regra simples: tudo que muda o que o usuário vê “agora” fica no caminho crítico. Todo o resto sai.
Analytics, logs de auditoria e indexação secundária costumam ser seguros para empurrar para fora do caminho quente. Validação, ordenação e passos necessários para produzir o próximo estado geralmente não podem ser.
Escolhas de runtime e SO que afetam a latência de cauda
Código rápido ainda pode parecer lento quando o runtime ou o SO pausa seu trabalho no momento errado. O objetivo não é só alto throughput. É menos surpresas no 1% mais lento das requisições.
Runtimes com garbage collector (JVM, Go, .NET) podem ser ótimos para produtividade, mas podem introduzir pausas quando a memória precisa ser limpa. Coletores modernos são muito melhores do que antes, ainda assim a latência de cauda pode pular se você criar muitos objetos de vida curta sob carga. Linguagens sem GC (Rust, C, C++) evitam pausas de GC, mas empurram o custo para disciplina de ownership e alocação manual. De qualquer forma, o comportamento da memória importa tanto quanto a velocidade da CPU.
O hábito prático é simples: encontre onde as alocações acontecem e torne-as monótonas. Reuse objetos, pré-dimensione buffers e evite transformar dados do caminho quente em strings temporárias ou mapas.
Escolhas de threading também aparecem como jitter. Cada fila extra, salto assíncrono ou handoff de pool de threads adiciona espera e aumenta a variância. Prefira um pequeno número de threads de longa vida, mantenha fronteiras produtor-consumidor claras e evite chamadas bloqueantes no caminho quente.
Algumas configurações de SO e container frequentemente decidem se sua cauda é limpa ou cheia de picos. Throttling de CPU por limites apertados, vizinhos barulhentos em hosts compartilhados e logging/metrics mal colocados podem criar lentidões súbitas. Se você mudar só uma coisa, comece medindo taxa de alocação e trocas de contexto durante picos de latência.
Dados, armazenamento e limites de serviço sem pausas-surpresa
Muitos picos de latência não são “código lento”. São esperas que você não planejou: um lock no banco, uma tempestade de retries, uma chamada cross-service que trava, ou um cache miss que vira uma viagem completa.
Mantenha o caminho crítico curto. Cada salto extra adiciona escalonamento, serialização, filas de rede e mais lugares para bloquear. Se você pode responder a uma requisição de um processo e um datastore, faça isso primeiro. Separe em mais serviços só quando cada chamada for opcional ou estritamente limitada.
Espera limitada é a diferença entre médias rápidas e latência previsível. Coloque timeouts duros em chamadas remotas e falhe rápido quando uma dependência estiver doente. Circuit breakers não servem só para salvar servidores — eles limitam quanto tempo usuários podem ficar presos.
Quando acesso a dados bloqueia, separe caminhos. Leitura costuma querer formas indexadas, denormalizadas e amigáveis a cache. Escritas querem durabilidade e ordenação. Separá-las pode remover contenção e reduzir tempo de lock. Se suas necessidades de consistência permitirem, registros append-only (um event log) costumam se comportar mais previsivelmente que atualizações in-place que disparam hot-row locking ou manutenção em background.
Uma regra simples para apps em tempo real: persistência não deve ficar no caminho crítico a menos que você realmente precise dela para correção. Frequentemente a melhor forma é: atualizar na memória, responder, e então persistir assincronamente com um mecanismo de replay (como outbox ou write-ahead log).
Em muitos pipelines com ring buffer isso acaba assim: publique no buffer em memória, atualize estado, responda, e deixe um consumidor separado agrupar escritas para PostgreSQL.
Imagine um app de colaboração ao vivo (ou um pequeno jogo multiplayer) que empurra atualizações a cada 16 ms (cerca de 60 vezes por segundo). O objetivo não é “rápido na média”. É “geralmente abaixo de 16 ms”, mesmo quando a conexão de um usuário está ruim.
Um fluxo ao estilo Disruptor simples parece com isto: input do usuário vira um evento pequeno, é publicado num ring buffer prealocado, então processado por um conjunto fixo de handlers em ordem (validate -> apply -> prepare outbound messages) e finalmente transmitido aos clientes.
Batching pode ajudar nas bordas. Por exemplo, agrupar writes de saída por cliente uma vez por tick para chamar a camada de rede menos vezes. Mas não faça batching dentro do caminho quente de uma forma que espere “só mais um pouco” por mais eventos. Esperar é como perder o tick.
Quando algo fica lento, trate como um problema de contenção. Se um handler desacelera, isole-o atrás do seu próprio buffer e publique um item de trabalho leve em vez de bloquear o loop principal. Se um cliente é lento, não deixe que ele afete o broadcaster; dê a cada cliente uma pequena fila de envio e descarte ou coalesce atualizações antigas para manter o estado mais recente. Se a profundidade do buffer crescer, aplique backpressure na borda (pare de aceitar inputs extras para aquele tick, ou degrade funcionalidades).
Você sabe que está funcionando quando os números ficam monótonos: profundidade de backlog paira perto de zero, eventos descartados/coalescidos são raros e explicáveis, e p99 fica abaixo do seu orçamento de tick sob carga realista.
Erros comuns que criam picos de latência
A maioria dos picos de latência é autoinfligida. O código pode ser rápido, mas o sistema ainda pausa quando espera por outras threads, o SO ou qualquer coisa fora do cache da CPU.
Alguns erros aparecem repetidamente:
- Usar locks compartilhados em todo lugar porque parece simples. Um lock contendido pode travar muitas requisições.
- Misturar I/O lento no caminho quente, como logging síncrono, writes no banco ou chamadas remotas.
- Manter filas sem limites. Elas escondem sobrecarga até você ter segundos de backlog.
- Olhar médias em vez de p95 e p99.
- Over-tuning cedo. Fixar threads não ajuda se os atrasos vêm de GC, contenção ou espera num socket.
Uma forma rápida de reduzir picos é tornar as esperas visíveis e limitadas. Coloque trabalho lento em um caminho separado, limite filas e decida o que acontece quando elas enchem (dropar, shed load ou degradar funcionalidades).
Checklist rápido para latência previsível
Trate latência previsível como uma feature de produto, não um acidente. Antes de tunar código, certifique-se de que o sistema tem metas claras e guardrails.
- Defina um alvo explícito de p99 (e p99.9 se importar) e escreva um orçamento de latência por estágio.
- Mantenha o caminho quente livre de I/O bloqueante. Se I/O for necessário, mova para um caminho lateral e decida o que fazer quando atrasar.
- Use filas limitadas e defina comportamento de overload (dropar, shed load, coalescer ou backpressure).
- Meça continuamente: profundidade de backlog, tempo por estágio e latência de cauda.
- Minimize alocação no loop quente e torne isso fácil de identificar em perfis.
Um teste simples: simule uma rajada (10x tráfego normal por 30 segundos). Se o p99 explodir, pergunte onde a espera acontece: filas crescendo, um consumidor lento, uma pausa de GC ou um recurso compartilhado.
Próximos passos: como aplicar isso no seu app
Trate o padrão Disruptor como um fluxo de trabalho, não como uma escolha de biblioteca. Prove latência previsível com uma fatia fina antes de adicionar features.
Escolha uma ação do usuário que deve parecer instantânea (por exemplo, “novo preço chega, UI atualiza”). Escreva o orçamento ponta a ponta e depois meça p50, p95 e p99 desde o primeiro dia.
Uma sequência que costuma funcionar:
- Construa um pipeline fino com uma entrada, um loop central e uma saída. Valide o p99 sob carga cedo.
- Torne responsabilidades explícitas (quem é dono do estado, quem publica, quem consome) e mantenha estado compartilhado pequeno.
- Adicione concorrência e buffering em passos pequenos e mantenha as mudanças reversíveis.
- Faça deploy perto dos usuários quando o orçamento for apertado, então re-meça sob carga realista (mesmos tamanhos de payload, mesmos padrões de rajada).
Se você está construindo no Koder.ai (koder.ai), pode ajudar mapear o fluxo de eventos primeiro no Planning Mode para que filas, locks e fronteiras de serviço não apareçam por acidente. Snapshots e rollback também facilitam rodar experimentos de latência repetidos e reverter mudanças que melhoram throughput mas pioram p99.
Mantenha as medições honestas. Use um script de teste fixo, aqueça o sistema e registre throughput e latência. Quando o p99 pular com carga, não comece otimizando o código imediatamente. Procure pausas vindas do GC, vizinhos barulhentos, rajadas de logging, escalonamento de threads ou chamadas bloqueantes ocultas.